 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Sparse Mean Estimation via Incremental Learning
May 24, 2023
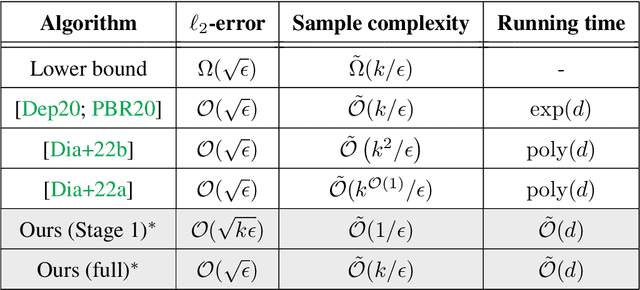
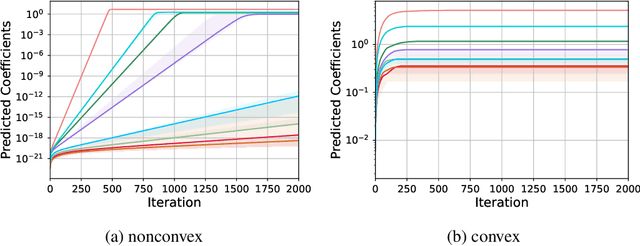
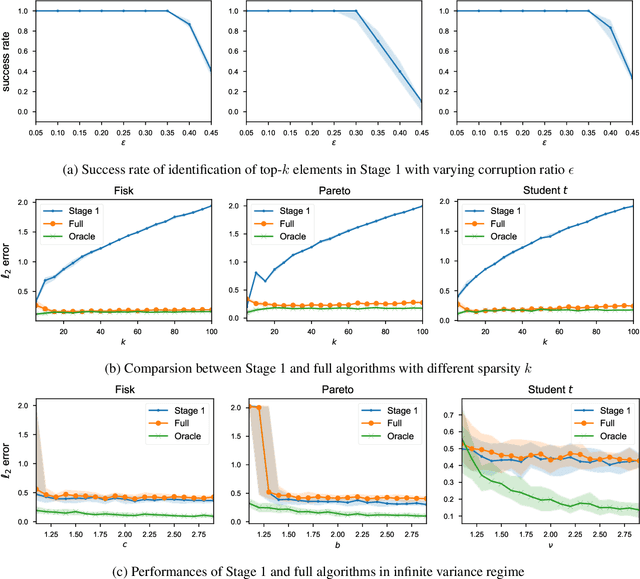
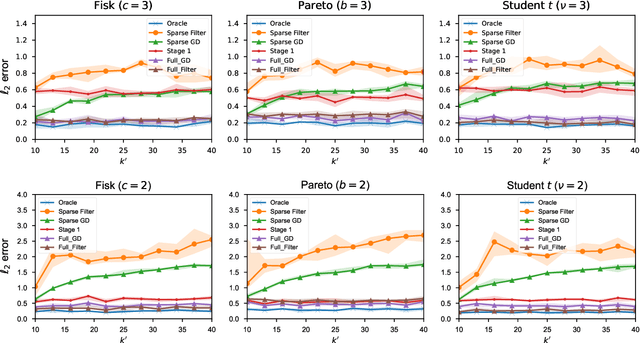
In this paper, we study the problem of robust sparse mean estimation, where the goal is to estimate a $k$-sparse mean from a collection of partially corrupted samples drawn from a heavy-tailed distribution. Existing estimators face two critical challenges in this setting. First, they are limited by a conjectured computational-statistical tradeoff, implying that any computationally efficient algorithm needs $\tilde\Omega(k^2)$ samples, while its statistically-optimal counterpart only requires $\tilde O(k)$ samples. Second, the existing estimators fall short of practical use as they scale poorly with the ambient dimension. This paper presents a simple mean estimator that overcomes both challenges under moderate conditions: it runs in near-linear time and memory (both with respect to the ambient dimension) while requiring only $\tilde O(k)$ samples to recover the true mean. At the core of our method lies an incremental learning phenomenon: we introduce a simple nonconvex framework that can incrementally learn the top-$k$ nonzero elements of the mean while keeping the zero elements arbitrarily small. Unlike existing estimators, our method does not need any prior knowledge of the sparsity level $k$. We prove the optimality of our estimator by providing a matching information-theoretic lower bound. Finally, we conduct a series of simulations to corroborate our theoretical findings. Our code is available at https://github.com/huihui0902/Robust_mean_estimation.
HARD: Hard Augmentations for Robust Distillation
May 24, 2023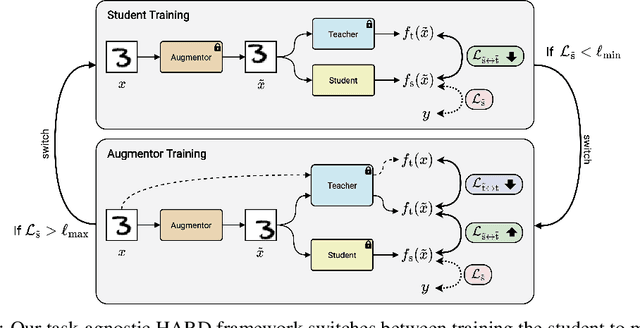
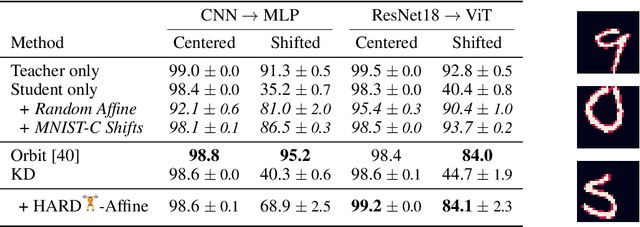
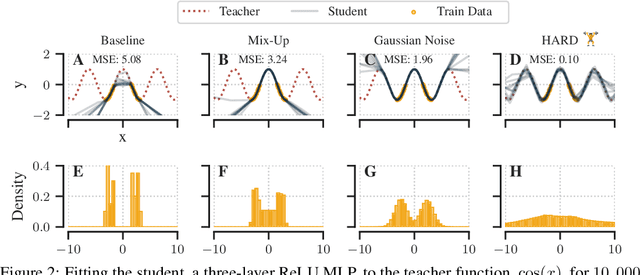
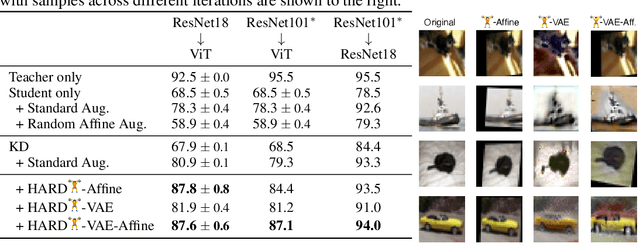
Knowledge distillation (KD) is a simple and successful method to transfer knowledge from a teacher to a student model solely based on functional activity. However, current KD has a few shortcomings: it has recently been shown that this method is unsuitable to transfer simple inductive biases like shift equivariance, struggles to transfer out of domain generalization, and optimization time is magnitudes longer compared to default non-KD model training. To improve these aspects of KD, we propose Hard Augmentations for Robust Distillation (HARD), a generally applicable data augmentation framework, that generates synthetic data points for which the teacher and the student disagree. We show in a simple toy example that our augmentation framework solves the problem of transferring simple equivariances with KD. We then apply our framework in real-world tasks for a variety of augmentation models, ranging from simple spatial transformations to unconstrained image manipulations with a pretrained variational autoencoder. We find that our learned augmentations significantly improve KD performance on in-domain and out-of-domain evaluation. Moreover, our method outperforms even state-of-the-art data augmentations and since the augmented training inputs can be visualized, they offer a qualitative insight into the properties that are transferred from the teacher to the student. Thus HARD represents a generally applicable, dynamically optimized data augmentation technique tailored to improve the generalization and convergence speed of models trained with KD.
AaKOS: Aspect-adaptive Knowledge-based Opinion Summarization
May 26, 2023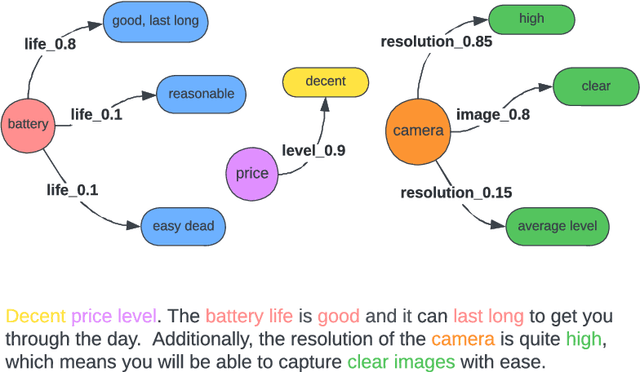

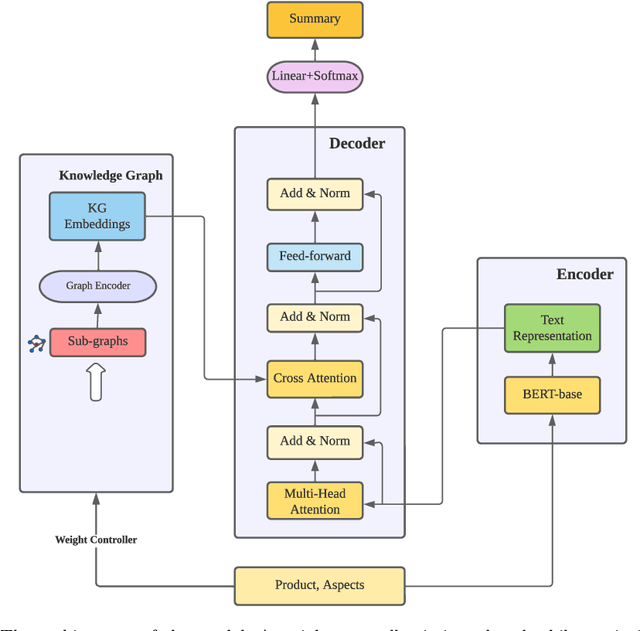
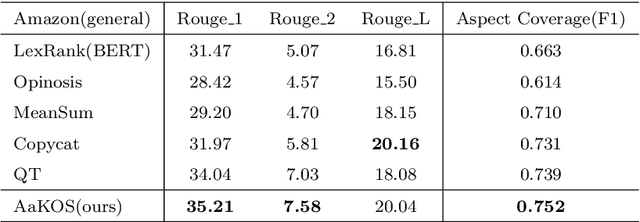
The rapid growth of information on the Internet has led to an overwhelming amount of opinions and comments on various activities, products, and services. This makes it difficult and time-consuming for users to process all the available information when making decisions. Text summarization, a Natural Language Processing (NLP) task, has been widely explored to help users quickly retrieve relevant information by generating short and salient content from long or multiple documents. Recent advances in pre-trained language models, such as ChatGPT, have demonstrated the potential of Large Language Models (LLMs) in text generation. However, LLMs require massive amounts of data and resources and are challenging to implement as offline applications. Furthermore, existing text summarization approaches often lack the ``adaptive" nature required to capture diverse aspects in opinion summarization, which is particularly detrimental to users with specific requirements or preferences. In this paper, we propose an Aspect-adaptive Knowledge-based Opinion Summarization model for product reviews, which effectively captures the adaptive nature required for opinion summarization. The model generates aspect-oriented summaries given a set of reviews for a particular product, efficiently providing users with useful information on specific aspects they are interested in, ensuring the generated summaries are more personalized and informative. Extensive experiments have been conducted using real-world datasets to evaluate the proposed model. The results demonstrate that our model outperforms state-of-the-art approaches and is adaptive and efficient in generating summaries that focus on particular aspects, enabling users to make well-informed decisions and catering to their diverse interests and preferences.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023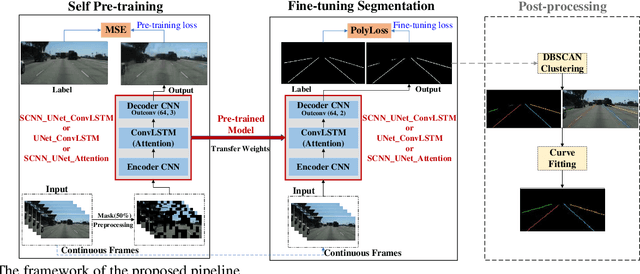
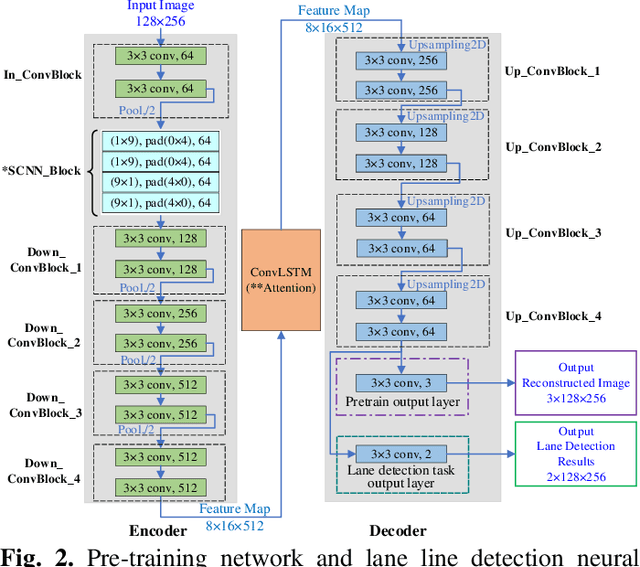
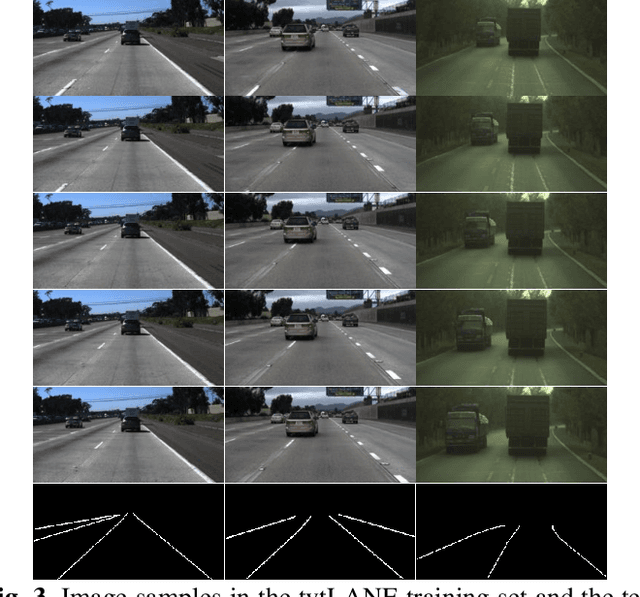

Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.
A FPGA-based architecture for real-time cluster finding in the LHCb silicon pixel detector
Feb 08, 2023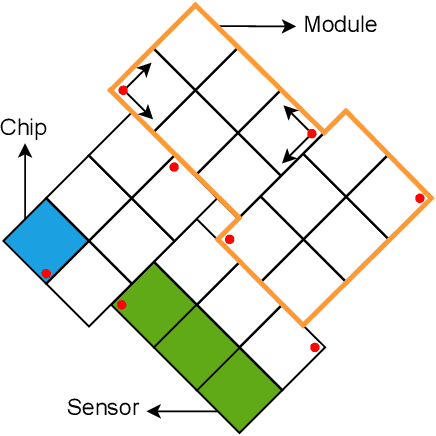
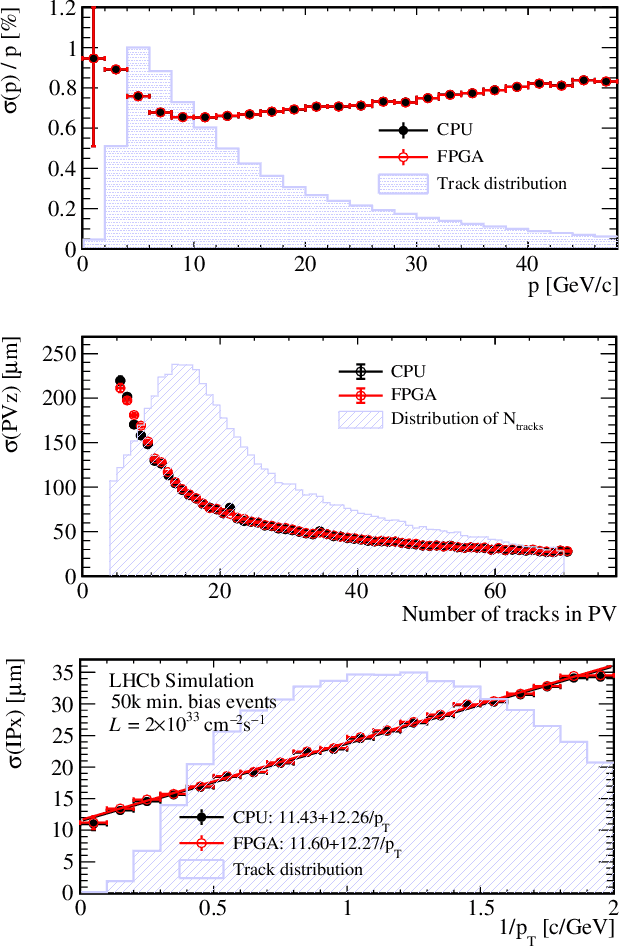
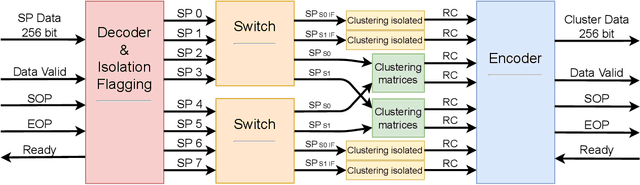

This article describes a custom VHDL firmware implementation of a two-dimensional cluster-finder architecture for reconstructing hit positions in the new vertex pixel detector (VELO) that is part of the LHCb Upgrade. This firmware has been deployed to the existing FPGA cards that perform the readout of the VELO, as a further enhancement of the DAQ system, and will run in real time during physics data taking, reconstructing VELO hits coordinates on-the-fly at the LHC collision rate. This pre-processing allows the first level of the software trigger to accept a 11% higher rate of events, as the ready-made hits coordinates accelerate the track reconstruction and consumes significantly less electrical power. It additionally allows the raw pixel data to be dropped at the readout level, thus saving approximately 14% of the DAQ bandwidth. Detailed simulation studies have shown that the use of this real-time cluster finding does not introduce any appreciable degradation in the tracking performance in comparison to a full-fledged software implementation. This work is part of a wider effort aimed at boosting the real-time processing capability of HEP experiments by delegating intensive tasks to dedicated computing accelerators deployed at the earliest stages of the data acquisition chain.
On the Usage of Continual Learning for Out-of-Distribution Generalization in Pre-trained Language Models of Code
May 06, 2023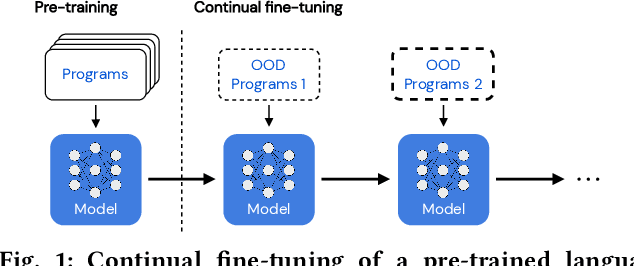
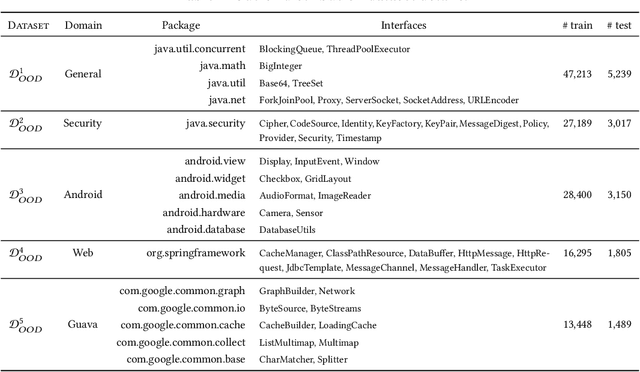
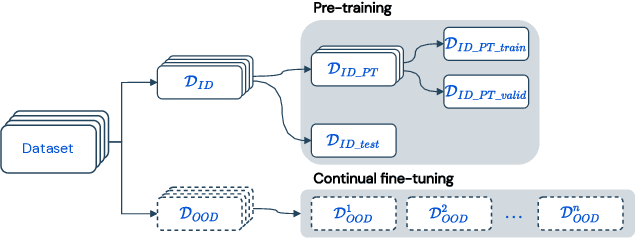
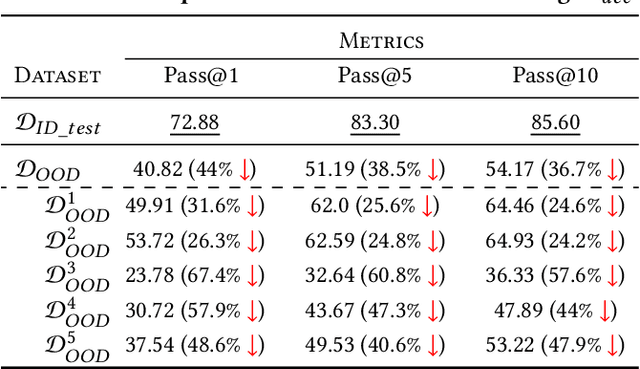
Pre-trained language models (PLMs) have become a prevalent technique in deep learning for code, utilizing a two-stage pre-training and fine-tuning procedure to acquire general knowledge about code and specialize in a variety of downstream tasks. However, the dynamic nature of software codebases poses a challenge to the effectiveness and robustness of PLMs. In particular, world-realistic scenarios potentially lead to significant differences between the distribution of the pre-training and test data, i.e., distribution shift, resulting in a degradation of the PLM's performance on downstream tasks. In this paper, we stress the need for adapting PLMs of code to software data whose distribution changes over time, a crucial problem that has been overlooked in previous works. The motivation of this work is to consider the PLM in a non-stationary environment, where fine-tuning data evolves over time according to a software evolution scenario. Specifically, we design a scenario where the model needs to learn from a stream of programs containing new, unseen APIs over time. We study two widely used PLM architectures, i.e., a GPT2 decoder and a RoBERTa encoder, on two downstream tasks, API call and API usage prediction. We demonstrate that the most commonly used fine-tuning technique from prior work is not robust enough to handle the dynamic nature of APIs, leading to the loss of previously acquired knowledge i.e., catastrophic forgetting. To address these issues, we implement five continual learning approaches, including replay-based and regularization-based methods. Our findings demonstrate that utilizing these straightforward methods effectively mitigates catastrophic forgetting in PLMs across both downstream tasks while achieving comparable or superior performance.
Accelerated MR Fingerprinting with Low-Rank and Generative Subspace Modeling
May 25, 2023
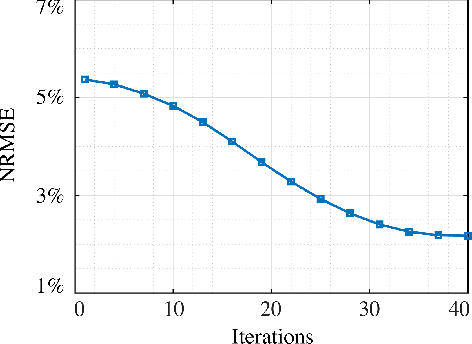
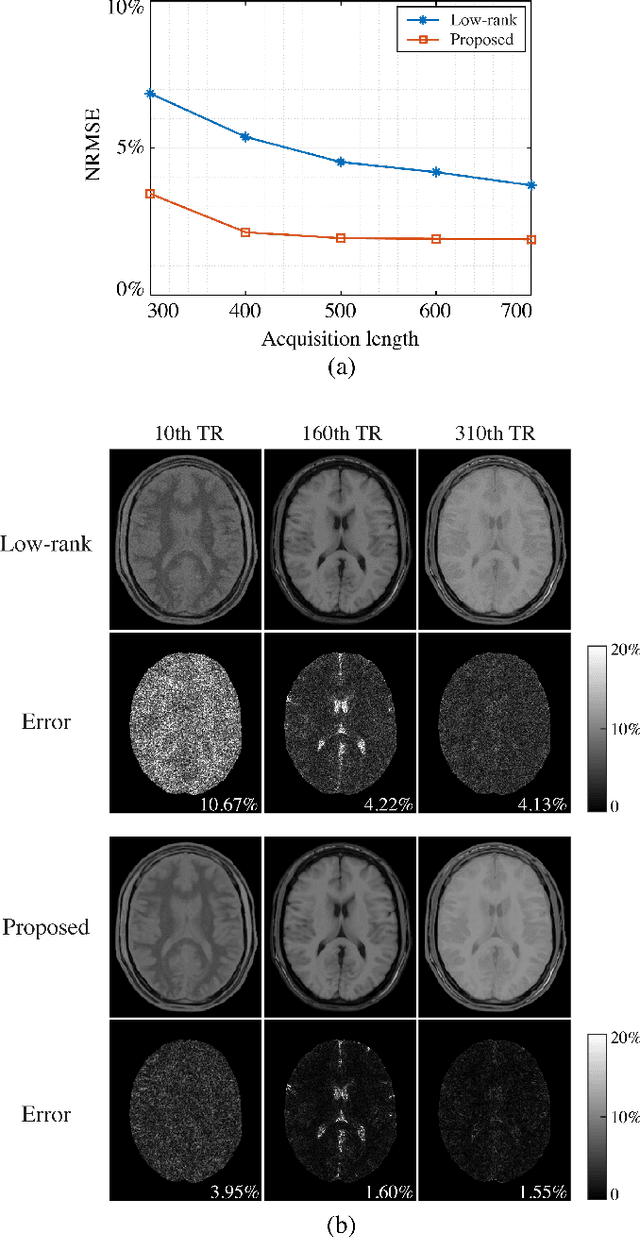
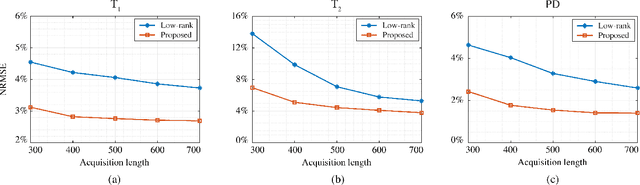
Magnetic Resonance (MR) Fingerprinting is an emerging multi-parametric quantitative MR imaging technique, for which image reconstruction methods utilizing low-rank and subspace constraints have achieved state-of-the-art performance. However, this class of methods often suffers from an ill-conditioned model-fitting issue, which degrades the performance as the data acquisition lengths become short and/or the signal-to-noise ratio becomes low. To address this problem, we present a new image reconstruction method for MR Fingerprinting, integrating low-rank and subspace modeling with a deep generative prior. Specifically, the proposed method captures the strong spatiotemporal correlation of contrast-weighted time-series images in MR Fingerprinting via a low-rank factorization. Further, it utilizes an untrained convolutional generative neural network to represent the spatial subspace of the low-rank model, while estimating the temporal subspace of the model from simulated magnetization evolutions generated based on spin physics. Here the architecture of the generative neural network serves as an effective regularizer for the ill-conditioned inverse problem without additional spatial training data that are often expensive to acquire. The proposed formulation results in a non-convex optimization problem, for which we develop an algorithm based on variable splitting and alternating direction method of multipliers.We evaluate the performance of the proposed method with numerical simulations and in vivo experiments and demonstrate that the proposed method outperforms the state-of-the-art low-rank and subspace reconstruction.
Referred by Multi-Modality: A Unified Temporal Transformer for Video Object Segmentation
May 25, 2023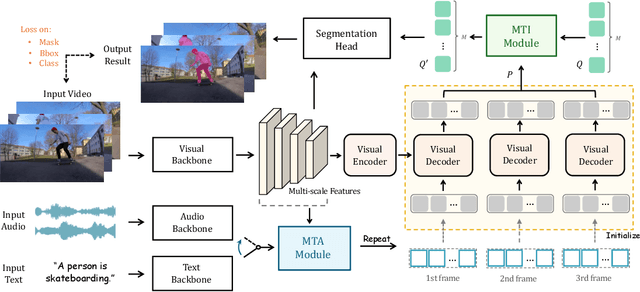
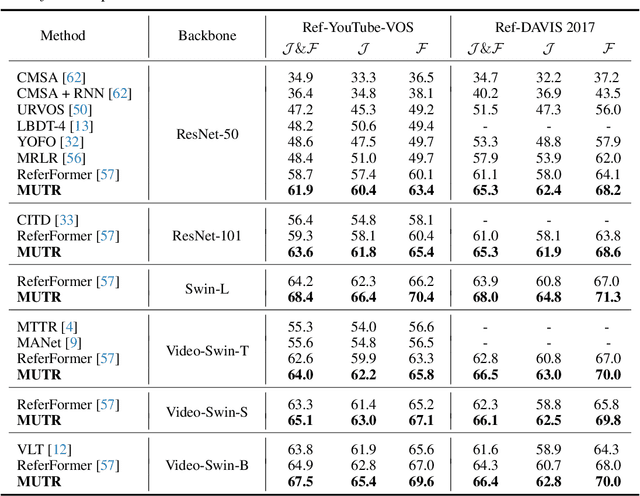
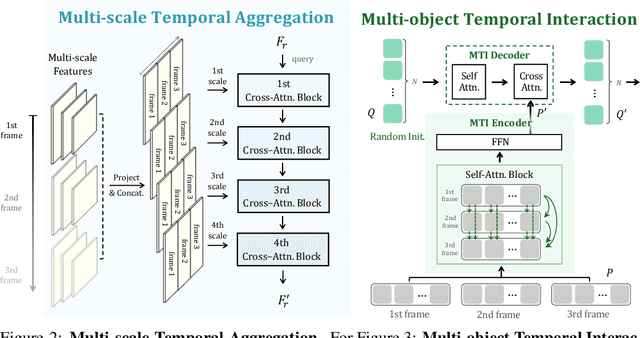
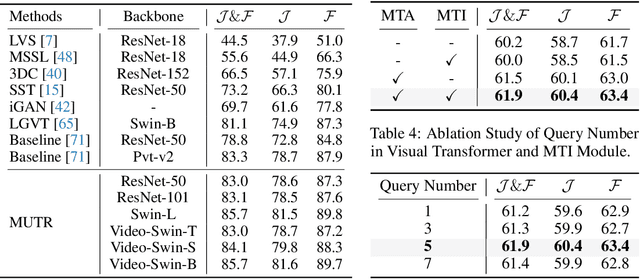
Recently, video object segmentation (VOS) referred by multi-modal signals, e.g., language and audio, has evoked increasing attention in both industry and academia. It is challenging for exploring the semantic alignment within modalities and the visual correspondence across frames. However, existing methods adopt separate network architectures for different modalities, and neglect the inter-frame temporal interaction with references. In this paper, we propose MUTR, a Multi-modal Unified Temporal transformer for Referring video object segmentation. With a unified framework for the first time, MUTR adopts a DETR-style transformer and is capable of segmenting video objects designated by either text or audio reference. Specifically, we introduce two strategies to fully explore the temporal relations between videos and multi-modal signals. Firstly, for low-level temporal aggregation before the transformer, we enable the multi-modal references to capture multi-scale visual cues from consecutive video frames. This effectively endows the text or audio signals with temporal knowledge and boosts the semantic alignment between modalities. Secondly, for high-level temporal interaction after the transformer, we conduct inter-frame feature communication for different object embeddings, contributing to better object-wise correspondence for tracking along the video. On Ref-YouTube-VOS and AVSBench datasets with respective text and audio references, MUTR achieves +4.2% and +4.2% J&F improvements to state-of-the-art methods, demonstrating our significance for unified multi-modal VOS. Code is released at https://github.com/OpenGVLab/MUTR.
UMat: Uncertainty-Aware Single Image High Resolution Material Capture
May 25, 2023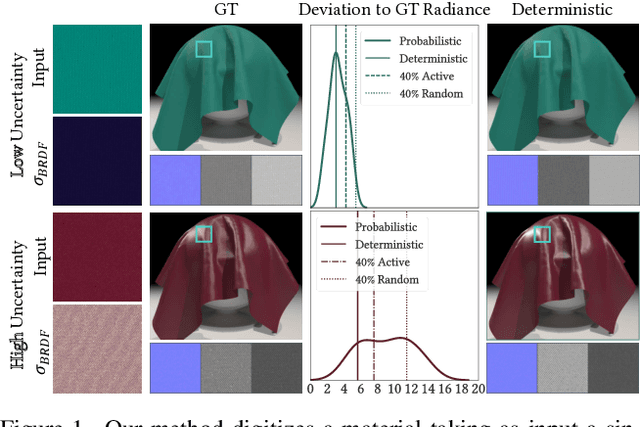
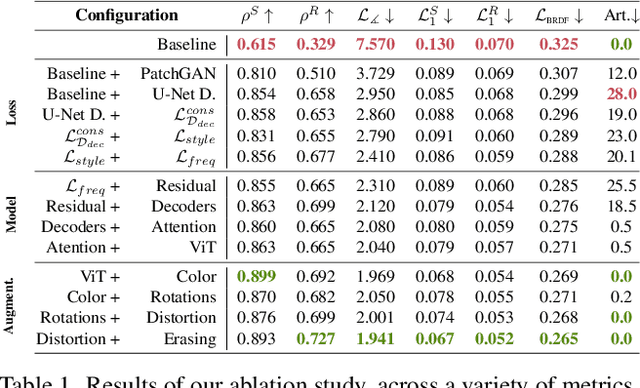

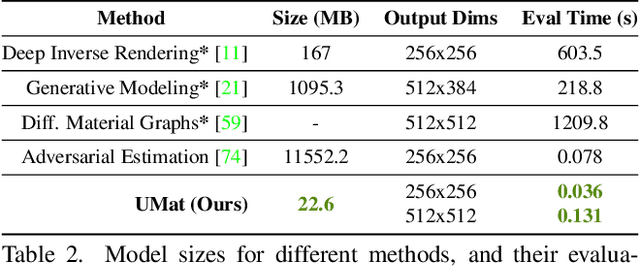
We propose a learning-based method to recover normals, specularity, and roughness from a single diffuse image of a material, using microgeometry appearance as our primary cue. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. In contrast, in this work, we propose a novel capture approach that leverages a generative network with attention and a U-Net discriminator, which shows outstanding performance integrating global information at reduced computational complexity. We showcase the performance of our method with a real dataset of digitized textile materials and show that a commodity flatbed scanner can produce the type of diffuse illumination required as input to our method. Additionally, because the problem might be illposed -more than a single diffuse image might be needed to disambiguate the specular reflection- or because the training dataset is not representative enough of the real distribution, we propose a novel framework to quantify the model's confidence about its prediction at test time. Our method is the first one to deal with the problem of modeling uncertainty in material digitization, increasing the trustworthiness of the process and enabling more intelligent strategies for dataset creation, as we demonstrate with an active learning experiment.
Fake News Detection and Behavioral Analysis: Case of COVID-19
May 25, 2023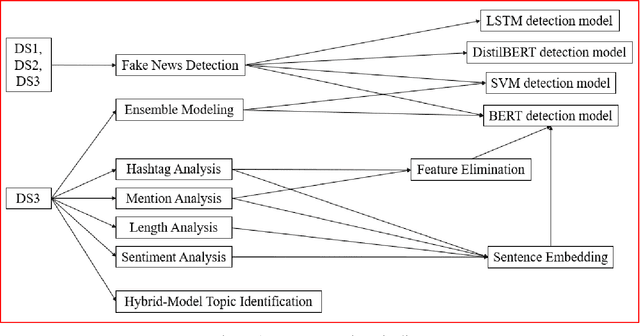


While the world has been combating COVID-19 for over three years, an ongoing "Infodemic" due to the spread of fake news regarding the pandemic has also been a global issue. The existence of the fake news impact different aspect of our daily lives, including politics, public health, economic activities, etc. Readers could mistake fake news for real news, and consequently have less access to authentic information. This phenomenon will likely cause confusion of citizens and conflicts in society. Currently, there are major challenges in fake news research. It is challenging to accurately identify fake news data in social media posts. In-time human identification is infeasible as the amount of the fake news data is overwhelming. Besides, topics discussed in fake news are hard to identify due to their similarity to real news. The goal of this paper is to identify fake news on social media to help stop the spread. We present Deep Learning approaches and an ensemble approach for fake news detection. Our detection models achieved higher accuracy than previous studies. The ensemble approach further improved the detection performance. We discovered feature differences between fake news and real news items. When we added them into the sentence embeddings, we found that they affected the model performance. We applied a hybrid method and built models for recognizing topics from posts. We found half of the identified topics were overlapping in fake news and real news, which could increase confusion in the population.