 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic Surround Camera Calibration Method in Road Scene for Self-driving Car
May 26, 2023
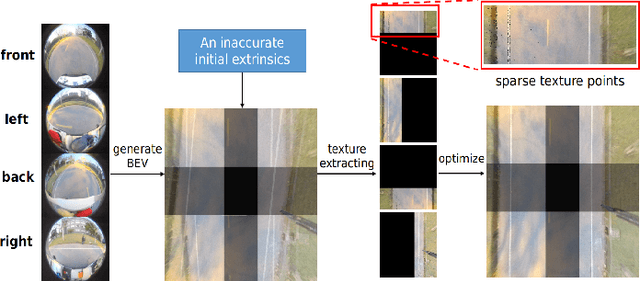

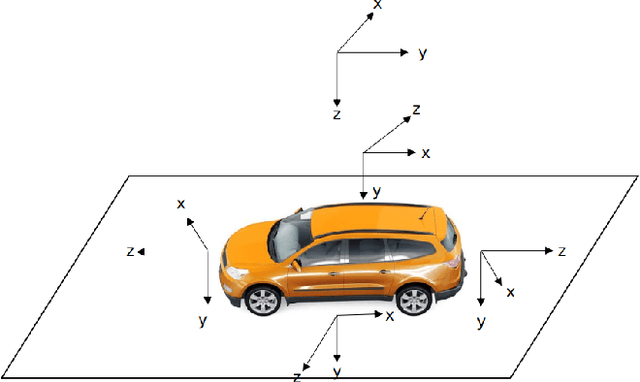

With the development of autonomous driving technology, sensor calibration has become a key technology to achieve accurate perception fusion and localization. Accurate calibration of the sensors ensures that each sensor can function properly and accurate information aggregation can be achieved. Among them, camera calibration based on surround view has received extensive attention. In autonomous driving applications, the calibration accuracy of the camera can directly affect the accuracy of perception and depth estimation. For online calibration of surround-view cameras, traditional feature extraction-based methods will suffer from strong distortion when the initial extrinsic parameters error is large, making these methods less robust and inaccurate. More existing methods use the sparse direct method to calibrate multi-cameras, which can ensure both accuracy and real-time performance and is theoretically achievable. However, this method requires a better initial value, and the initial estimate with a large error is often stuck in a local optimum. To this end, we introduce a robust automatic multi-cameras (pinhole or fisheye cameras) calibration and refinement method in the road scene. We utilize the coarse-to-fine random-search strategy, and it can solve large disturbances of initial extrinsic parameters, which can make up for falling into optimal local value in nonlinear optimization methods. In the end, quantitative and qualitative experiments are conducted in actual and simulated environments, and the result shows the proposed method can achieve accuracy and robustness performance. The open-source code is available at https://github.com/OpenCalib/SurroundCameraCalib.
DeepSeaNet: Improving Underwater Object Detection using EfficientDet
May 26, 2023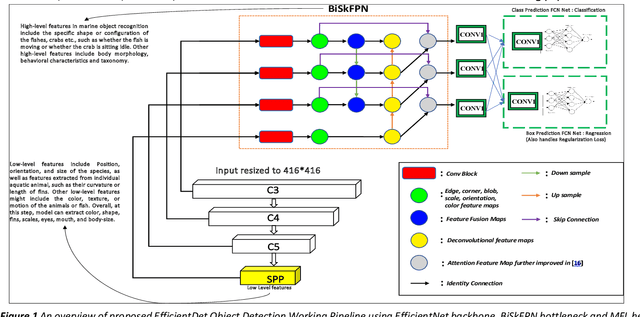
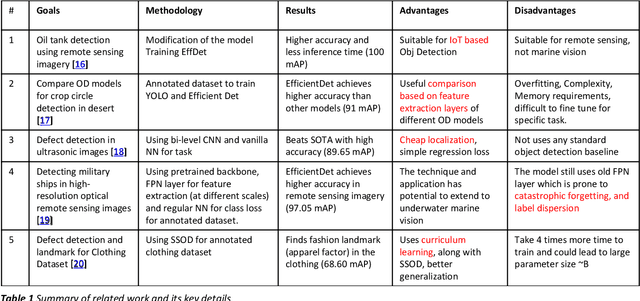
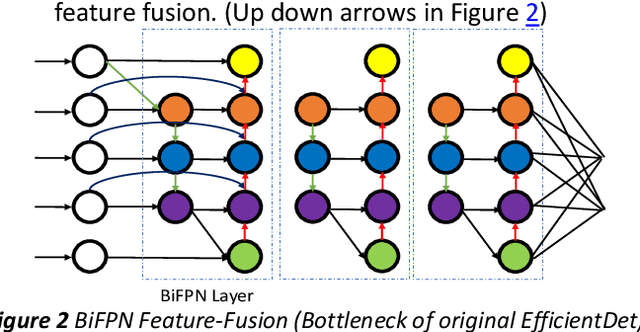
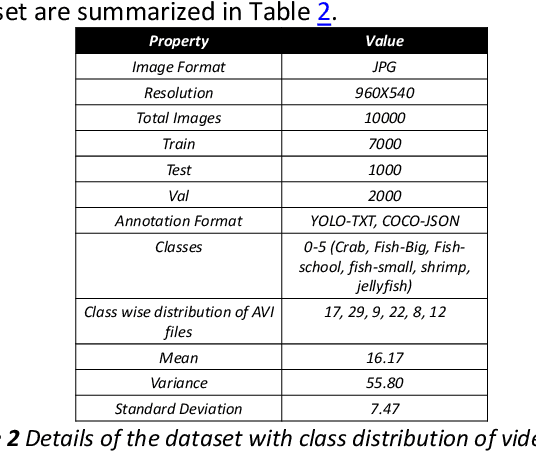
Marine animals and deep underwater objects are difficult to recognize and monitor for safety of aquatic life. There is an increasing challenge when the water is saline with granular particles and impurities. In such natural adversarial environment, traditional approaches like CNN start to fail and are expensive to compute. This project involves implementing and evaluating various object detection models, including EfficientDet, YOLOv5, YOLOv8, and Detectron2, on an existing annotated underwater dataset, called the Brackish-Dataset. The dataset comprises annotated image sequences of fish, crabs, starfish, and other aquatic animals captured in Limfjorden water with limited visibility. The aim of this research project is to study the efficiency of newer models on the same dataset and contrast them with the previous results based on accuracy and inference time. Firstly, I compare the results of YOLOv3 (31.10% mean Average Precision (mAP)), YOLOv4 (83.72% mAP), YOLOv5 (97.6%), YOLOv8 (98.20%), EfficientDet (98.56% mAP) and Detectron2 (95.20% mAP) on the same dataset. Secondly, I provide a modified BiSkFPN mechanism (BiFPN neck with skip connections) to perform complex feature fusion in adversarial noise which makes modified EfficientDet robust to perturbations. Third, analyzed the effect on accuracy of EfficientDet (98.63% mAP) and YOLOv5 by adversarial learning (98.04% mAP). Last, I provide class activation map based explanations (CAM) for the two models to promote Explainability in black box models. Overall, the results indicate that modified EfficientDet achieved higher accuracy with five-fold cross validation than the other models with 88.54% IoU of feature maps.
Theoretical and Practical Perspectives on what Influence Functions Do
May 26, 2023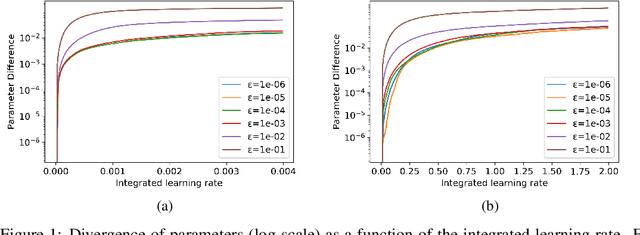
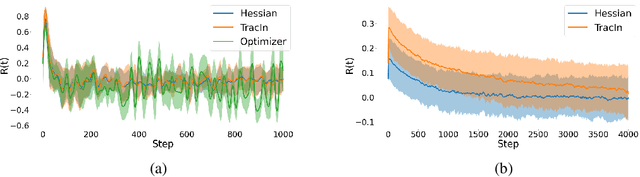

Influence functions (IF) have been seen as a technique for explaining model predictions through the lens of the training data. Their utility is assumed to be in identifying training examples "responsible" for a prediction so that, for example, correcting a prediction is possible by intervening on those examples (removing or editing them) and retraining the model. However, recent empirical studies have shown that the existing methods of estimating IF predict the leave-one-out-and-retrain effect poorly. In order to understand the mismatch between the theoretical promise and the practical results, we analyse five assumptions made by IF methods which are problematic for modern-scale deep neural networks and which concern convexity, numeric stability, training trajectory and parameter divergence. This allows us to clarify what can be expected theoretically from IF. We show that while most assumptions can be addressed successfully, the parameter divergence poses a clear limitation on the predictive power of IF: influence fades over training time even with deterministic training. We illustrate this theoretical result with BERT and ResNet models. Another conclusion from the theoretical analysis is that IF are still useful for model debugging and correcting even though some of the assumptions made in prior work do not hold: using natural language processing and computer vision tasks, we verify that mis-predictions can be successfully corrected by taking only a few fine-tuning steps on influential examples.
PromptNER: Prompt Locating and Typing for Named Entity Recognition
May 26, 2023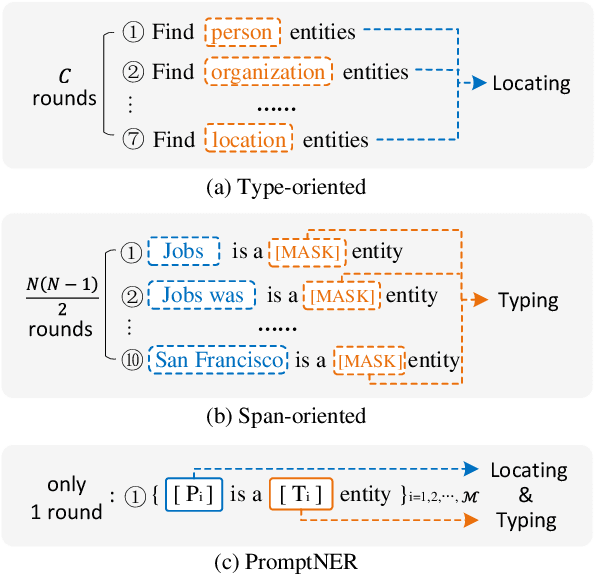
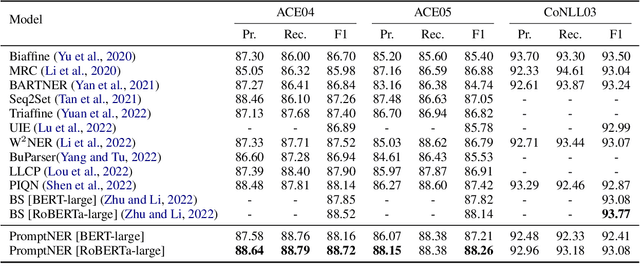
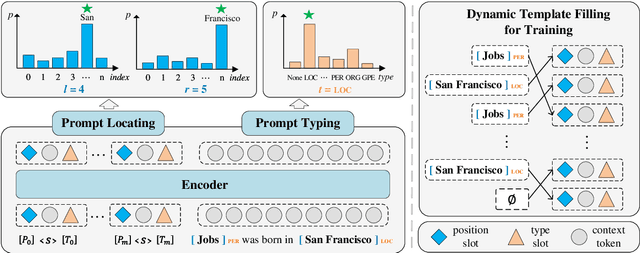
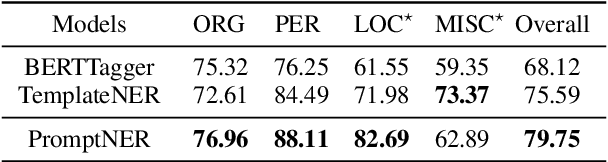
Prompt learning is a new paradigm for utilizing pre-trained language models and has achieved great success in many tasks. To adopt prompt learning in the NER task, two kinds of methods have been explored from a pair of symmetric perspectives, populating the template by enumerating spans to predict their entity types or constructing type-specific prompts to locate entities. However, these methods not only require a multi-round prompting manner with a high time overhead and computational cost, but also require elaborate prompt templates, that are difficult to apply in practical scenarios. In this paper, we unify entity locating and entity typing into prompt learning, and design a dual-slot multi-prompt template with the position slot and type slot to prompt locating and typing respectively. Multiple prompts can be input to the model simultaneously, and then the model extracts all entities by parallel predictions on the slots. To assign labels for the slots during training, we design a dynamic template filling mechanism that uses the extended bipartite graph matching between prompts and the ground-truth entities. We conduct experiments in various settings, including resource-rich flat and nested NER datasets and low-resource in-domain and cross-domain datasets. Experimental results show that the proposed model achieves a significant performance improvement, especially in the cross-domain few-shot setting, which outperforms the state-of-the-art model by +7.7% on average.
Local Search, Semantics, and Genetic Programming: a Global Analysis
May 26, 2023
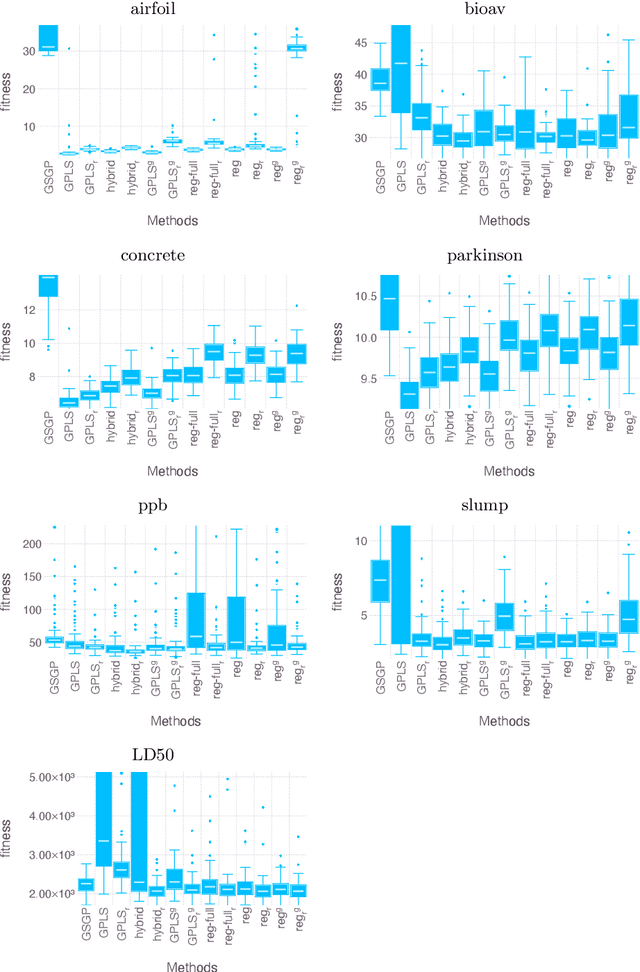
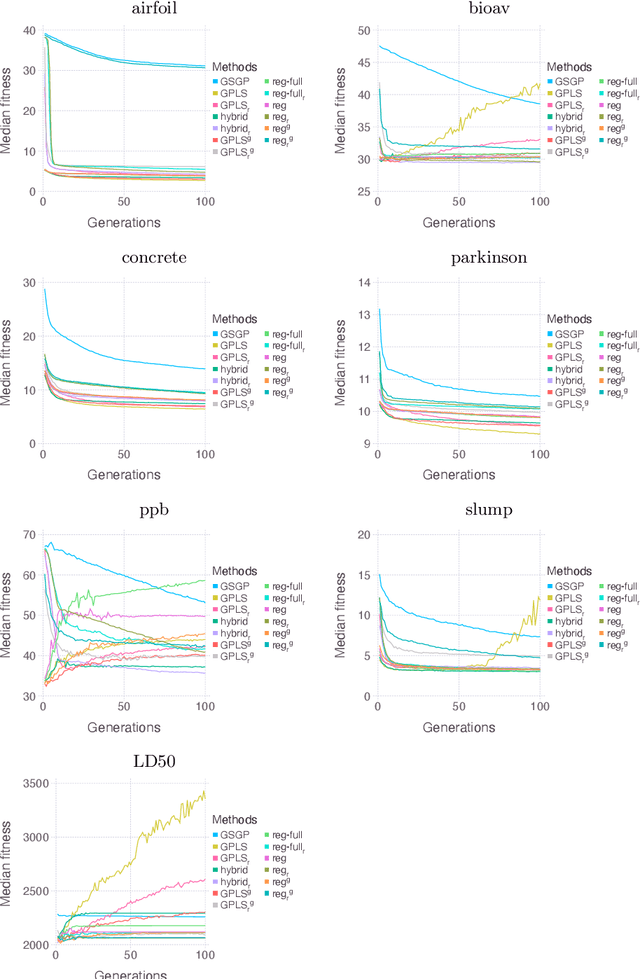
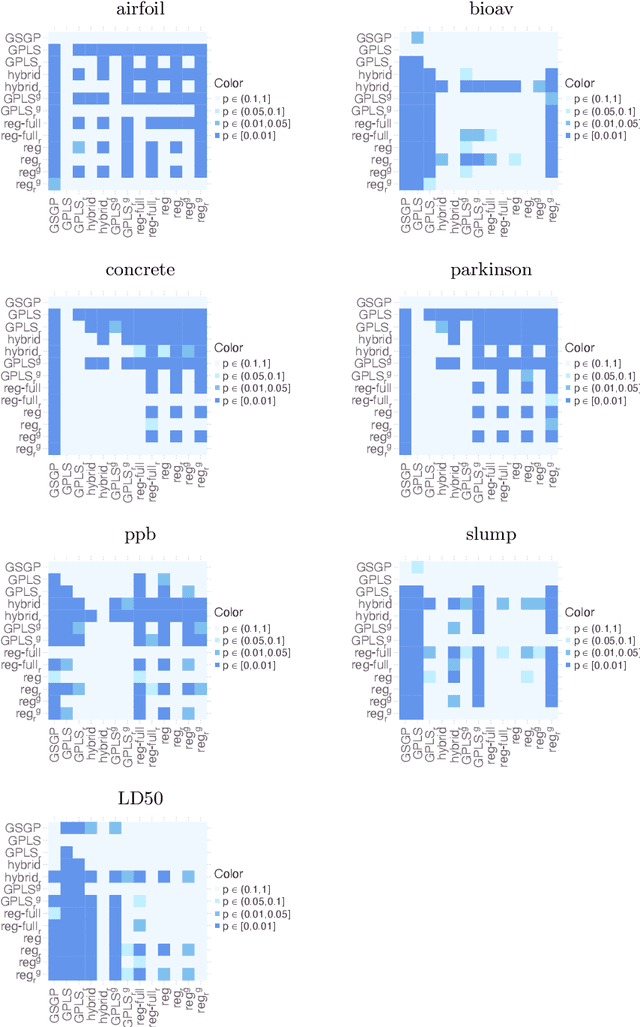
Geometric Semantic Geometric Programming (GSGP) is one of the most prominent Genetic Programming (GP) variants, thanks to its solid theoretical background, the excellent performance achieved, and the execution time significantly smaller than standard syntax-based GP. In recent years, a new mutation operator, Geometric Semantic Mutation with Local Search (GSM-LS), has been proposed to include a local search step in the mutation process based on the idea that performing a linear regression during the mutation can allow for a faster convergence to good-quality solutions. While GSM-LS helps the convergence of the evolutionary search, it is prone to overfitting. Thus, it was suggested to use GSM-LS only for a limited number of generations and, subsequently, to switch back to standard geometric semantic mutation. A more recently defined variant of GSGP (called GSGP-reg) also includes a local search step but shares similar strengths and weaknesses with GSM-LS. Here we explore multiple possibilities to limit the overfitting of GSM-LS and GSGP-reg, ranging from adaptive methods to estimate the risk of overfitting at each mutation to a simple regularized regression. The results show that the method used to limit overfitting is not that important: providing that a technique to control overfitting is used, it is possible to consistently outperform standard GSGP on both training and unseen data. The obtained results allow practitioners to better understand the role of local search in GSGP and demonstrate that simple regularization strategies are effective in controlling overfitting.
Im-Promptu: In-Context Composition from Image Prompts
May 26, 2023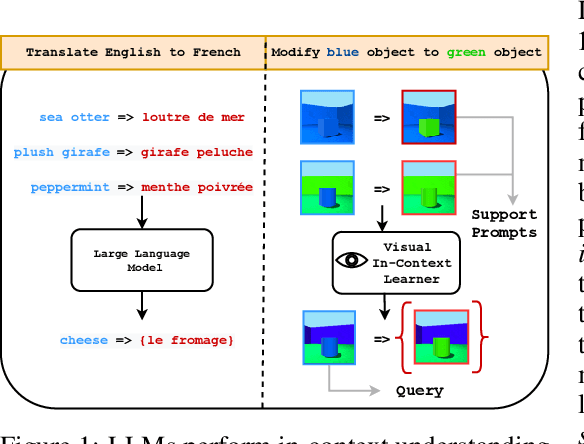

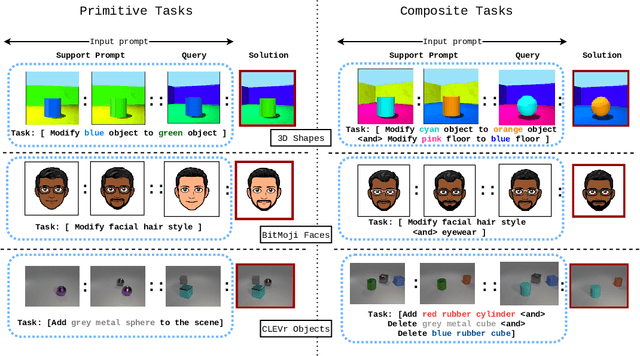
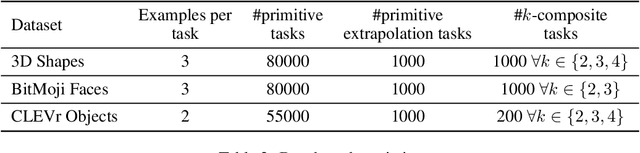
Large language models are few-shot learners that can solve diverse tasks from a handful of demonstrations. This implicit understanding of tasks suggests that the attention mechanisms over word tokens may play a role in analogical reasoning. In this work, we investigate whether analogical reasoning can enable in-context composition over composable elements of visual stimuli. First, we introduce a suite of three benchmarks to test the generalization properties of a visual in-context learner. We formalize the notion of an analogy-based in-context learner and use it to design a meta-learning framework called Im-Promptu. Whereas the requisite token granularity for language is well established, the appropriate compositional granularity for enabling in-context generalization in visual stimuli is usually unspecified. To this end, we use Im-Promptu to train multiple agents with different levels of compositionality, including vector representations, patch representations, and object slots. Our experiments reveal tradeoffs between extrapolation abilities and the degree of compositionality, with non-compositional representations extending learned composition rules to unseen domains but performing poorly on combinatorial tasks. Patch-based representations require patches to contain entire objects for robust extrapolation. At the same time, object-centric tokenizers coupled with a cross-attention module generate consistent and high-fidelity solutions, with these inductive biases being particularly crucial for compositional generalization. Lastly, we demonstrate a use case of Im-Promptu as an intuitive programming interface for image generation.
Sensing of inspiration events from speech: comparison of deep learning and linguistic methods
May 19, 2023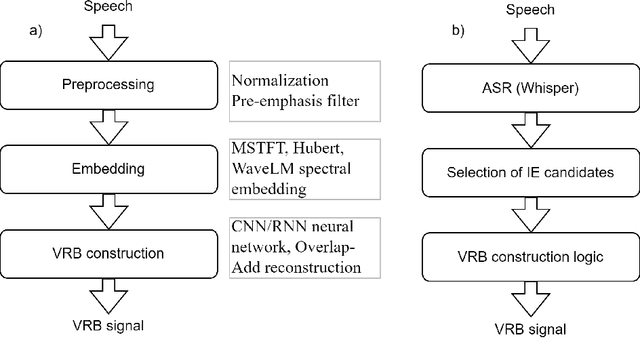
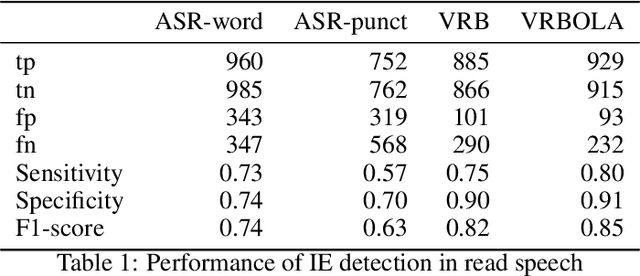
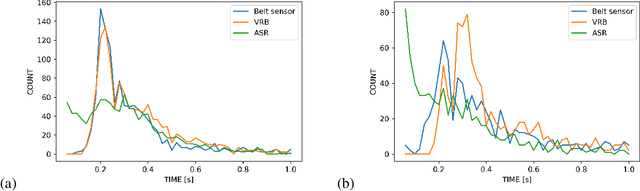
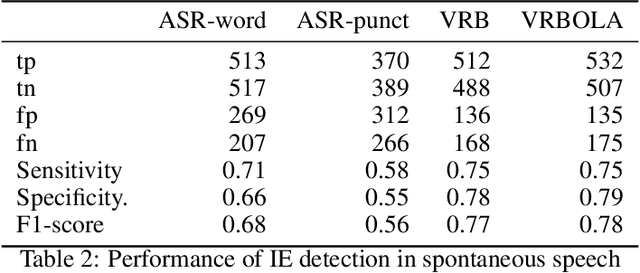
Respiratory chest belt sensor can be used to measure the respiratory rate and other respiratory health parameters. Virtual Respiratory Belt, VRB, algorithms estimate the belt sensor waveform from speech audio. In this paper we compare the detection of inspiration events (IE) from respiratory belt sensor data using a novel neural VRB algorithm and the detections based on time-aligned linguistic content. The results show the superiority of the VRB method over word pause detection or grammatical content segmentation. The comparison of the methods show that both read and spontaneous speech content has a significant amount of ungrammatical breathing, that is, breathing events that are not aligned with grammatically appropriate places in language. This study gives new insights into the development of VRB methods and adds to the general understanding of speech breathing behavior. Moreover, a new VRB method, VRBOLA, for the reconstruction of the continuous breathing waveform is demonstrated.
Differentially Private Adapters for Parameter Efficient Acoustic Modeling
May 19, 2023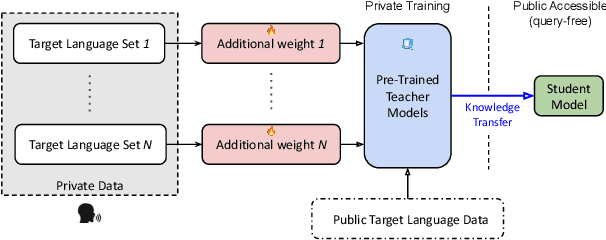
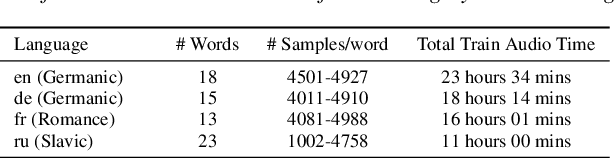
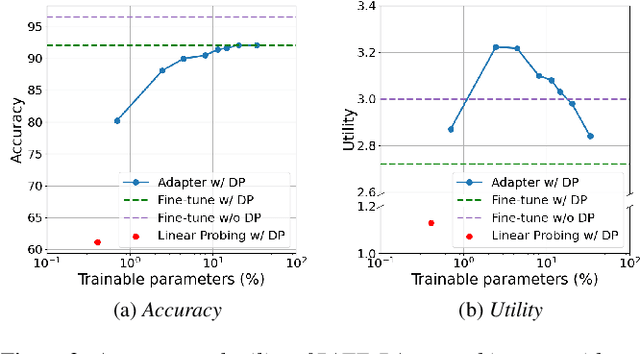
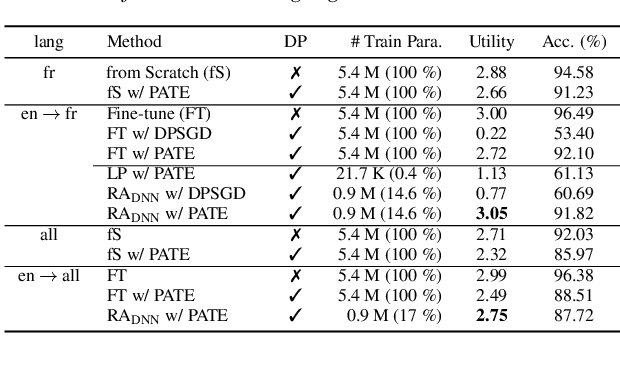
In this work, we devise a parameter-efficient solution to bring differential privacy (DP) guarantees into adaptation of a cross-lingual speech classifier. We investigate a new frozen pre-trained adaptation framework for DP-preserving speech modeling without full model fine-tuning. First, we introduce a noisy teacher-student ensemble into a conventional adaptation scheme leveraging a frozen pre-trained acoustic model and attain superior performance than DP-based stochastic gradient descent (DPSGD). Next, we insert residual adapters (RA) between layers of the frozen pre-trained acoustic model. The RAs reduce training cost and time significantly with a negligible performance drop. Evaluated on the open-access Multilingual Spoken Words (MLSW) dataset, our solution reduces the number of trainable parameters by 97.5% using the RAs with only a 4% performance drop with respect to fine-tuning the cross-lingual speech classifier while preserving DP guarantees.
Object-Centric Voxelization of Dynamic Scenes via Inverse Neural Rendering
Apr 30, 2023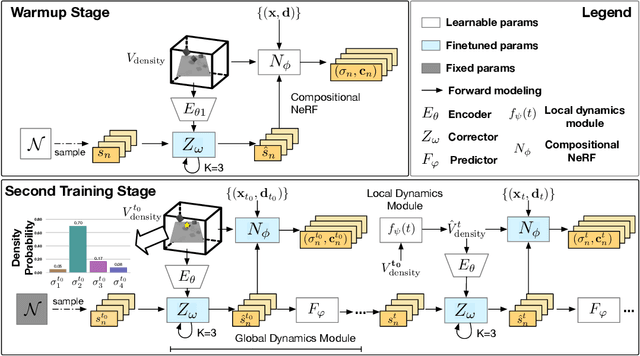
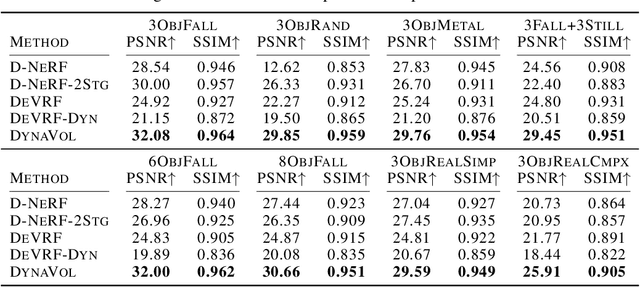
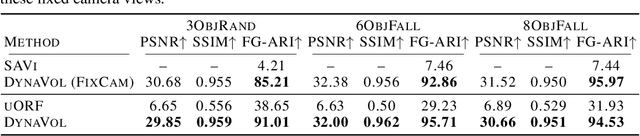
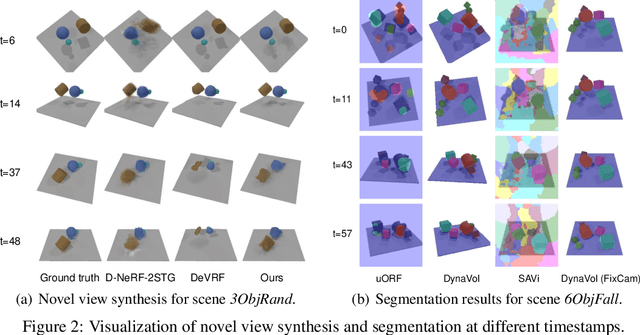
Understanding the compositional dynamics of the world in unsupervised 3D scenarios is challenging. Existing approaches either fail to make effective use of time cues or ignore the multi-view consistency of scene decomposition. In this paper, we propose DynaVol, an inverse neural rendering framework that provides a pilot study for learning time-varying volumetric representations for dynamic scenes with multiple entities (like objects). It has two main contributions. First, it maintains a time-dependent 3D grid, which dynamically and flexibly binds the spatial locations to different entities, thus encouraging the separation of information at a representational level. Second, our approach jointly learns grid-level local dynamics, object-level global dynamics, and the compositional neural radiance fields in an end-to-end architecture, thereby enhancing the spatiotemporal consistency of object-centric scene voxelization. We present a two-stage training scheme for DynaVol and validate its effectiveness on various benchmarks with multiple objects, diverse dynamics, and real-world shapes and textures. We present visualization at https://sites.google.com/view/dynavol-visual.
Pilotless Uplink for Massive MIMO Systems
May 21, 2023Massive MIMO antennas in cellular systems help support a large number of users in the same time-frequency resource and also provide significant array gain for uplink reception. However, channel estimation in such large antenna systems can be tricky, not only since pilot assignment for multiple users is challenging, but also because the pilot overhead especially for rapidly changing channels can diminish the system throughput quite significantly. A pilotless transceiver where the receiver can perform blind demodulation can solve these issues and boost system throughput by eliminating the need for pilots in channel estimation. In this paper, we propose an iterative matrix decomposition algorithm for the blind demodulation of massive MIMO OFDM signals. This new decomposition technique provides estimates of both the user symbols and the user channel in the frequency domain simultaneously (to a scaling factor) without any pilots. Simulation results demonstrate that the lack of pilots does not affect the error performance of the proposed algorithm when compared to maximal-ratio-combining (MRC) with pilot-based channel estimation across a wide range of signal strengths.