 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Datasets for Portuguese Legal Semantic Textual Similarity: Comparing weak supervision and an annotation process approaches
May 29, 2023
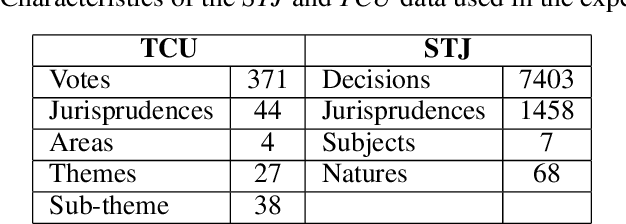
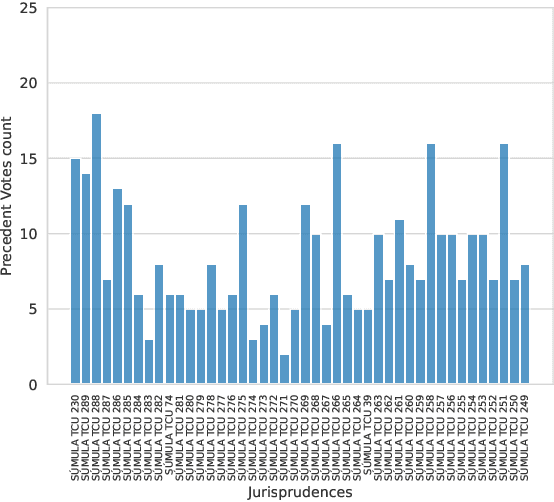
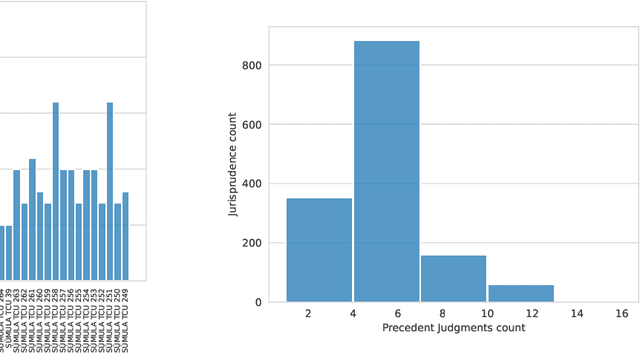

The Brazilian judiciary has a large workload, resulting in a long time to finish legal proceedings. Brazilian National Council of Justice has established in Resolution 469/2022 formal guidance for document and process digitalization opening up the possibility of using automatic techniques to help with everyday tasks in the legal field, particularly in a large number of texts yielded on the routine of law procedures. Notably, Artificial Intelligence (AI) techniques allow for processing and extracting useful information from textual data, potentially speeding up the process. However, datasets from the legal domain required by several AI techniques are scarce and difficult to obtain as they need labels from experts. To address this challenge, this article contributes with four datasets from the legal domain, two with documents and metadata but unlabeled, and another two labeled with a heuristic aiming at its use in textual semantic similarity tasks. Also, to evaluate the effectiveness of the proposed heuristic label process, this article presents a small ground truth dataset generated from domain expert annotations. The analysis of ground truth labels highlights that semantic analysis of domain text can be challenging even for domain experts. Also, the comparison between ground truth and heuristic labels shows that heuristic labels are useful.
Coeditor: Leveraging Contextual Changes for Multi-round Code Auto-editing
May 29, 2023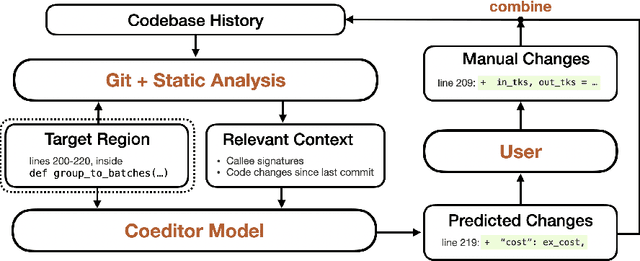
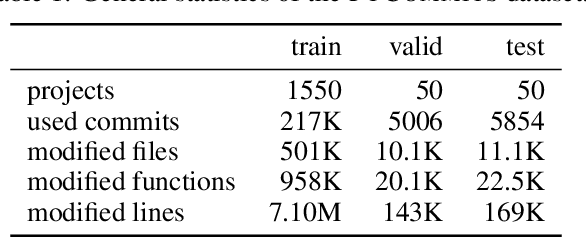

Developers often dedicate significant time to maintaining and refactoring existing code. However, most prior work on generative models for code focuses solely on creating new code, neglecting the unique requirements of editing existing code. In this work, we explore a multi-round code auto-editing setting, aiming to predict edits to a code region based on recent changes within the same codebase. Our model, Coeditor, is a fine-tuned CodeT5 model with enhancements specifically designed for code editing tasks. We encode code changes using a line diff format and employ static analysis to form large customized model contexts, ensuring appropriate information for prediction. We collect a code editing dataset from the commit histories of 1650 open-source Python projects for training and evaluation. In a simplified single-round, single-edit task, Coeditor significantly outperforms the best code completion approach -- nearly doubling its exact-match accuracy, despite using a much smaller model -- demonstrating the benefits of incorporating editing history for code completion. In a multi-round, multi-edit setting, we observe substantial gains by iteratively prompting the model with additional user edits. We open-source our code, data, and model weights to encourage future research and release a VSCode extension powered by our model for interactive usage.
HTTE: A Hybrid Technique For Travel Time Estimation In Sparse Data Environments
Jan 12, 2023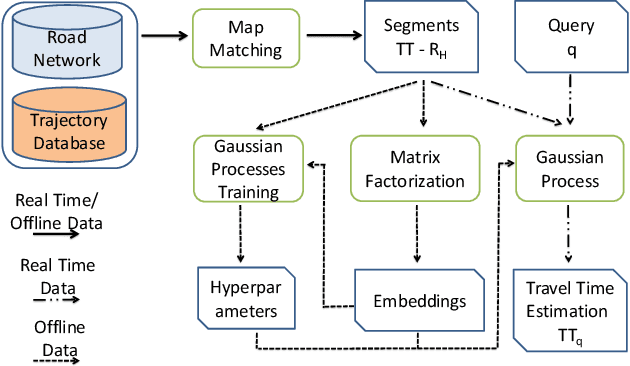
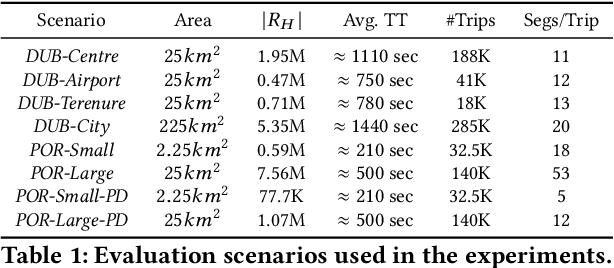
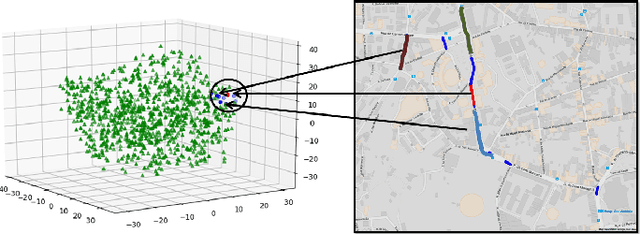

Travel time estimation is a critical task, useful to many urban applications at the individual citizen and the stakeholder level. This paper presents a novel hybrid algorithm for travel time estimation that leverages historical and sparse real-time trajectory data. Given a path and a departure time we estimate the travel time taking into account the historical information, the real-time trajectory data and the correlations among different road segments. We detect similar road segments using historical trajectories, and use a latent representation to model the similarities. Our experimental evaluation demonstrates the effectiveness of our approach.
Quantifying Sample Anonymity in Score-Based Generative Models with Adversarial Fingerprinting
Jun 02, 2023
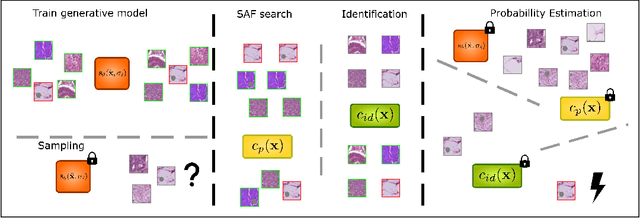
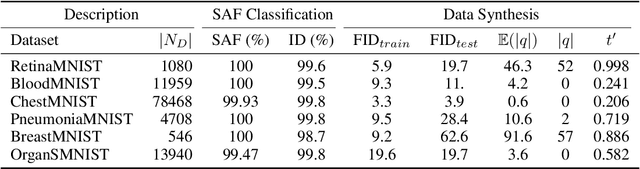
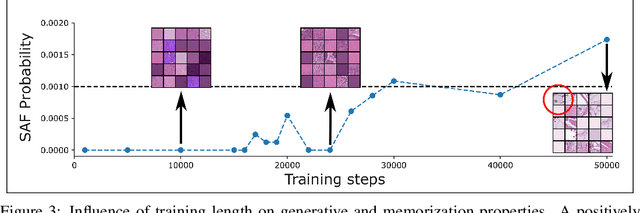
Recent advances in score-based generative models have led to a huge spike in the development of downstream applications using generative models ranging from data augmentation over image and video generation to anomaly detection. Despite publicly available trained models, their potential to be used for privacy preserving data sharing has not been fully explored yet. Training diffusion models on private data and disseminating the models and weights rather than the raw dataset paves the way for innovative large-scale data-sharing strategies, particularly in healthcare, where safeguarding patients' personal health information is paramount. However, publishing such models without individual consent of, e.g., the patients from whom the data was acquired, necessitates guarantees that identifiable training samples will never be reproduced, thus protecting personal health data and satisfying the requirements of policymakers and regulatory bodies. This paper introduces a method for estimating the upper bound of the probability of reproducing identifiable training images during the sampling process. This is achieved by designing an adversarial approach that searches for anatomic fingerprints, such as medical devices or dermal art, which could potentially be employed to re-identify training images. Our method harnesses the learned score-based model to estimate the probability of the entire subspace of the score function that may be utilized for one-to-one reproduction of training samples. To validate our estimates, we generate anomalies containing a fingerprint and investigate whether generated samples from trained generative models can be uniquely mapped to the original training samples. Overall our results show that privacy-breaching images are reproduced at sampling time if the models were trained without care.
Reliable identification of selection mechanisms in language change
May 25, 2023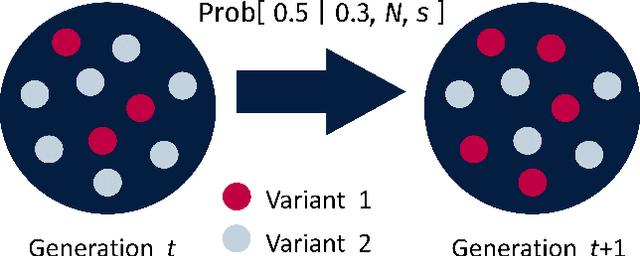
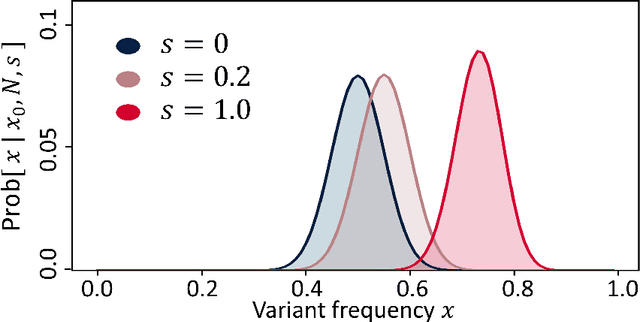

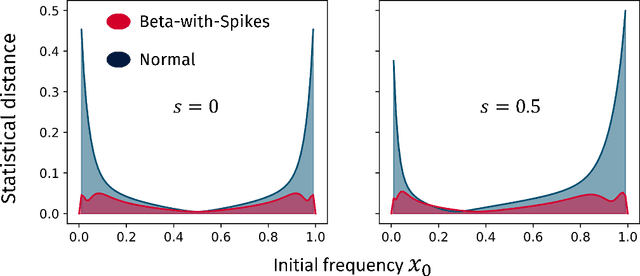
Language change is a cultural evolutionary process in which variants of linguistic variables change in frequency through processes analogous to mutation, selection and genetic drift. In this work, we apply a recently-introduced method to corpus data to quantify the strength of selection in specific instances of historical language change. We first demonstrate, in the context of English irregular verbs, that this method is more reliable and interpretable than similar methods that have previously been applied. We further extend this study to demonstrate that a bias towards phonological simplicity overrides that favouring grammatical simplicity when these are in conflict. Finally, with reference to Spanish spelling reforms, we show that the method can also detect points in time at which selection strengths change, a feature that is generically expected for socially-motivated language change. Together, these results indicate how hypotheses for mechanisms of language change can be tested quantitatively using historical corpus data.
P-vectors: A Parallel-Coupled TDNN/Transformer Network for Speaker Verification
May 25, 2023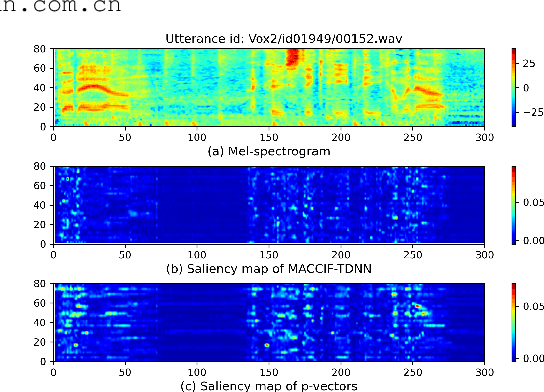
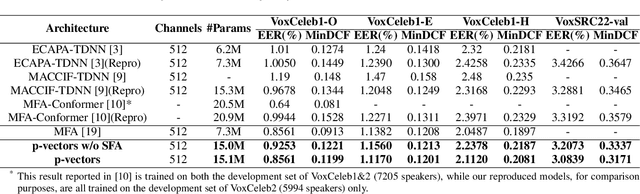
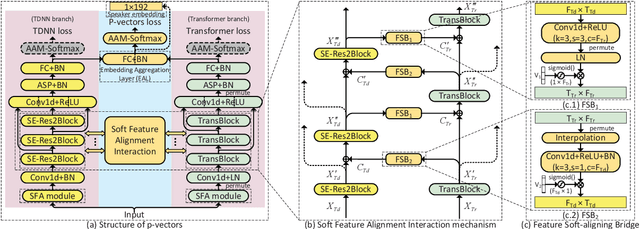

Typically, the Time-Delay Neural Network (TDNN) and Transformer can serve as a backbone for Speaker Verification (SV). Both of them have advantages and disadvantages from the perspective of global and local feature modeling. How to effectively integrate these two style features is still an open issue. In this paper, we explore a Parallel-coupled TDNN/Transformer Network (p-vectors) to replace the serial hybrid networks. The p-vectors allows TDNN and Transformer to learn the complementary information from each other through Soft Feature Alignment Interaction (SFAI) under the premise of preserving local and global features. Also, p-vectors uses the Spatial Frequency-channel Attention (SFA) to enhance the spatial interdependence modeling for input features. Finally, the outputs of dual branches of p-vectors are combined by Embedding Aggregation Layer (EAL). Experiments show that p-vectors outperforms MACCIF-TDNN and MFA-Conformer with relative improvements of 11.5% and 13.9% in EER on VoxCeleb1-O.
Contrastive Training of Complex-Valued Autoencoders for Object Discovery
May 25, 2023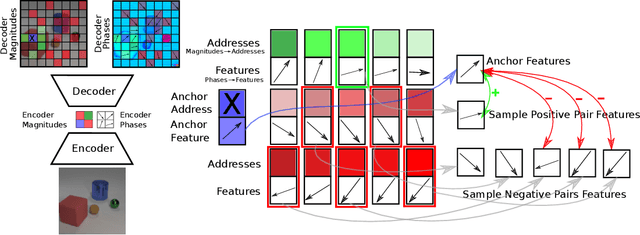
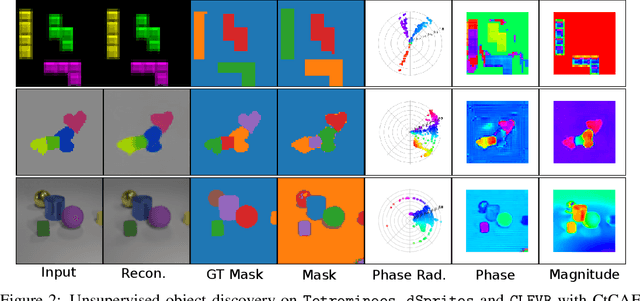
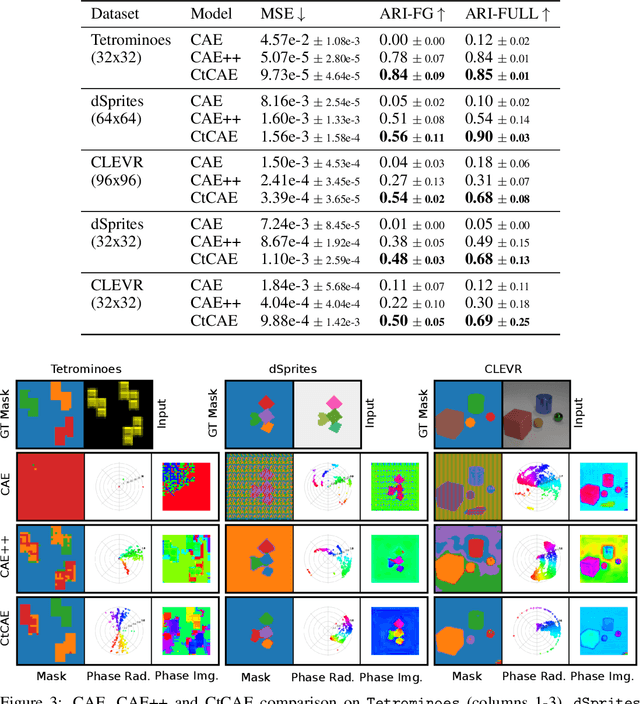
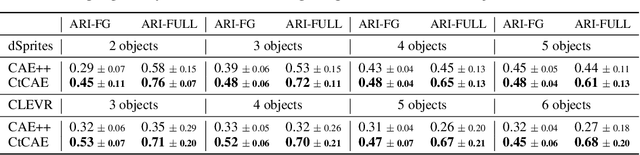
Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects
Combinatorial Bandits for Maximum Value Reward Function under Max Value-Index Feedback
May 25, 2023
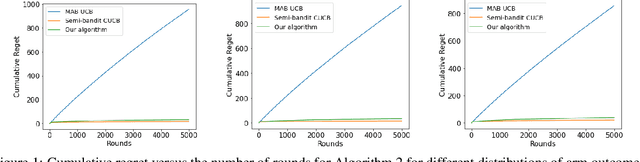
We consider a combinatorial multi-armed bandit problem for maximum value reward function under maximum value and index feedback. This is a new feedback structure that lies in between commonly studied semi-bandit and full-bandit feedback structures. We propose an algorithm and provide a regret bound for problem instances with stochastic arm outcomes according to arbitrary distributions with finite supports. The regret analysis rests on considering an extended set of arms, associated with values and probabilities of arm outcomes, and applying a smoothness condition. Our algorithm achieves a $O((k/\Delta)\log(T))$ distribution-dependent and a $\tilde{O}(\sqrt{T})$ distribution-independent regret where $k$ is the number of arms selected in each round, $\Delta$ is a distribution-dependent reward gap and $T$ is the horizon time. Perhaps surprisingly, the regret bound is comparable to previously-known bound under more informative semi-bandit feedback. We demonstrate the effectiveness of our algorithm through experimental results.
Online and Streaming Algorithms for Constrained $k$-Submodular Maximization
May 25, 2023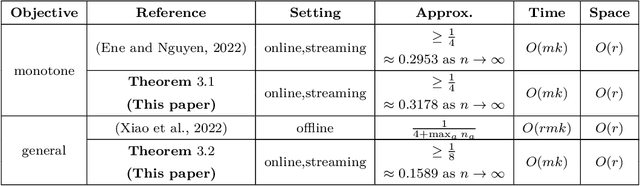
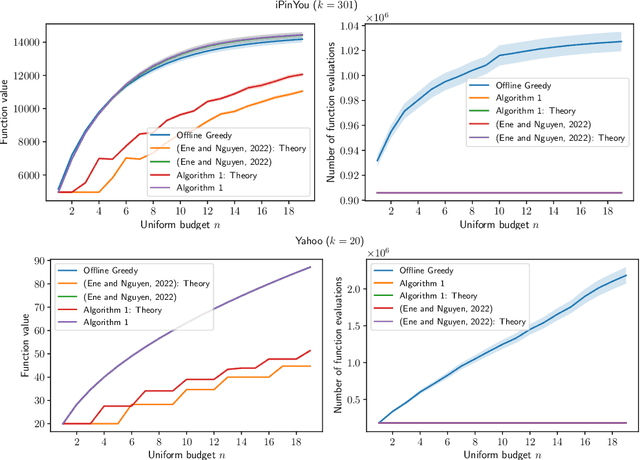
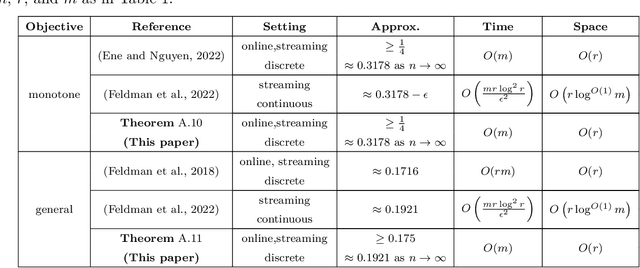
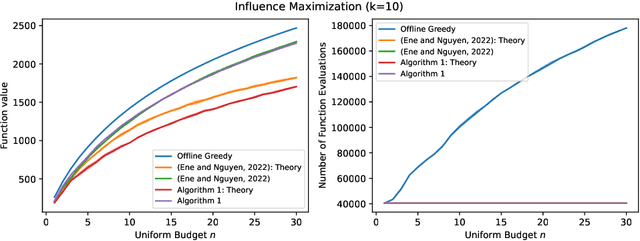
Constrained $k$-submodular maximization is a general framework that captures many discrete optimization problems such as ad allocation, influence maximization, personalized recommendation, and many others. In many of these applications, datasets are large or decisions need to be made in an online manner, which motivates the development of efficient streaming and online algorithms. In this work, we develop single-pass streaming and online algorithms for constrained $k$-submodular maximization with both monotone and general (possibly non-monotone) objectives subject to cardinality and knapsack constraints. Our algorithms achieve provable constant-factor approximation guarantees which improve upon the state of the art in almost all settings. Moreover, they are combinatorial and very efficient, and have optimal space and running time. We experimentally evaluate our algorithms on instances for ad allocation and other applications, where we observe that our algorithms are efficient and scalable, and construct solutions that are comparable in value to offline greedy algorithms.
Automatic off-line design of robot swarms: exploring the transferability of control software and design methods across different platforms
May 25, 2023

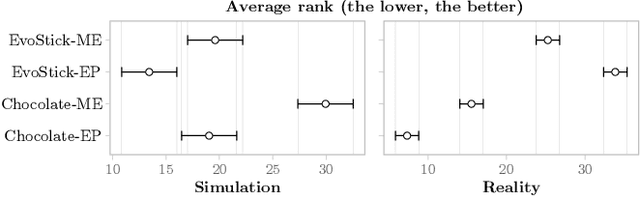
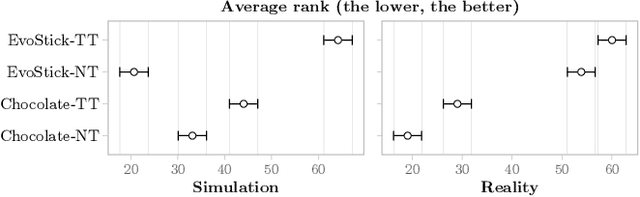
Automatic off-line design is an attractive approach to implementing robot swarms. In this approach, a designer specifies a mission for the swarm, and an optimization process generates suitable control software for the individual robots through computer-based simulations. Most relevant literature has focused on effectively transferring control software from simulation to physical robots. For the first time, we investigate (i) whether control software generated via automatic design is transferable across robot platforms and (ii) whether the design methods that generate such control software are themselves transferable. We experiment with two ground mobile platforms with equivalent capabilities. Our measure of transferability is based on the performance drop observed when control software and/or design methods are ported from one platform to another. Results indicate that while the control software generated via automatic design is transferable in some cases, better performance can be achieved when a transferable method is directly applied to the new platform.