 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DC-Net: Divide-and-Conquer for Salient Object Detection
May 24, 2023
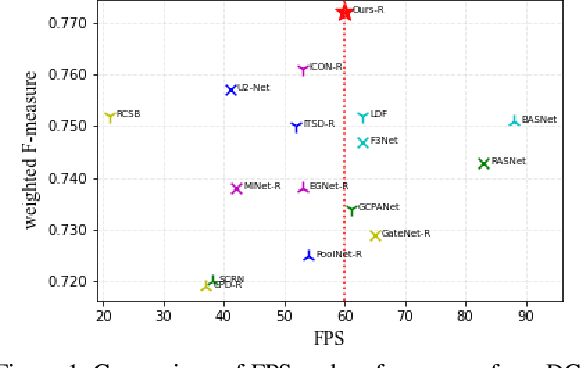
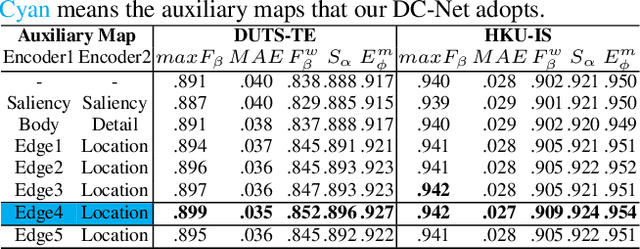

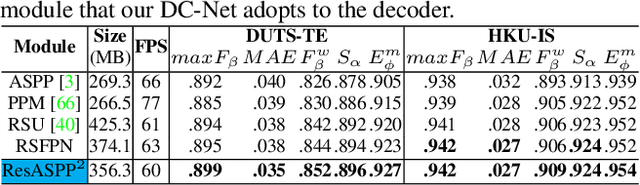
In this paper, we introduce Divide-and-Conquer into the salient object detection (SOD) task to enable the model to learn prior knowledge that is for predicting the saliency map. We design a novel network, Divide-and-Conquer Network (DC-Net) which uses two encoders to solve different subtasks that are conducive to predicting the final saliency map, here is to predict the edge maps with width 4 and location maps of salient objects and then aggregate the feature maps with different semantic information into the decoder to predict the final saliency map. The decoder of DC-Net consists of our newly designed two-level Residual nested-ASPP (ResASPP$^{2}$) modules, which have the ability to capture a large number of different scale features with a small number of convolution operations and have the advantages of maintaining high resolution all the time and being able to obtain a large and compact effective receptive field (ERF). Based on the advantage of Divide-and-Conquer's parallel computing, we use Parallel Acceleration to speed up DC-Net, allowing it to achieve competitive performance on six LR-SOD and five HR-SOD datasets under high efficiency (60 FPS and 55 FPS). Codes and results are available: https://github.com/PiggyJerry/DC-Net.
Automated Driving Architecture and Operation of a Light Commercial Vehicle
May 24, 2023
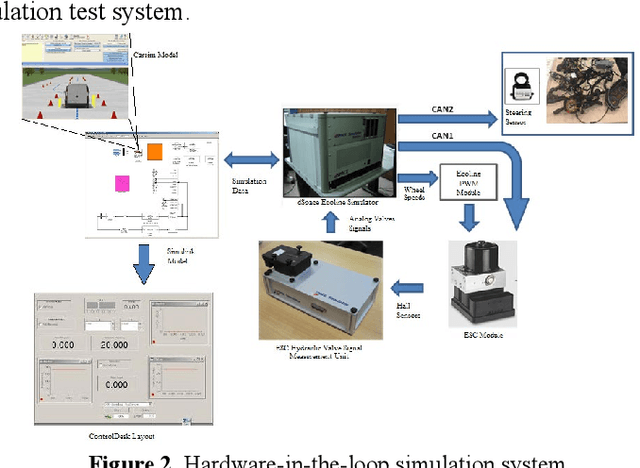

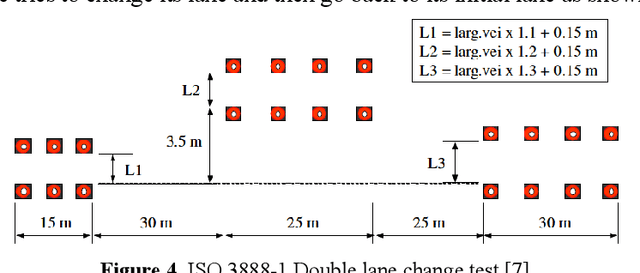
This paper is on the automated driving architecture and operation of a light commercial vehicle. Simple longitudinal and lateral dynamic models of the vehicle and a more detailed CarSim model are developed and used in simulations and controller design and evaluation. Experimental validation is used to make sure that the models used represent the actual response of the vehicle as closely as possible. The vehicle is made drive-by-wire by interfacing with the existing throttle-by-wire, by adding an active vacuum booster for brake-by-wire and by adding a steering actuator for steer-by-wire operation. Vehicle localization is achieved by using a GPS sensor integrated with six axes IMU with a built-in INS algorithm and a digital compass for heading information. Front looking radar, lidar and camera are used for environmental sensing. Communication with the road infrastructure and other vehicles is made possible by a vehicle to vehicle communication modem. A dedicated computer under real time Linux is used to collect, process and distribute sensor information. A dSPACE MicroAutoBox is used for drive-by-wire controls. CACC based longitudinal control and path tracking of a map of GPS waypoints are used to present the operation of this automated driving vehicle.
Representing Additive Gaussian Processes by Sparse Matrices
Apr 29, 2023
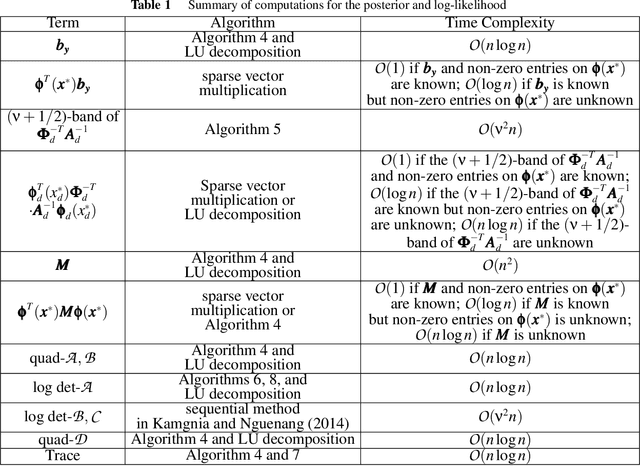
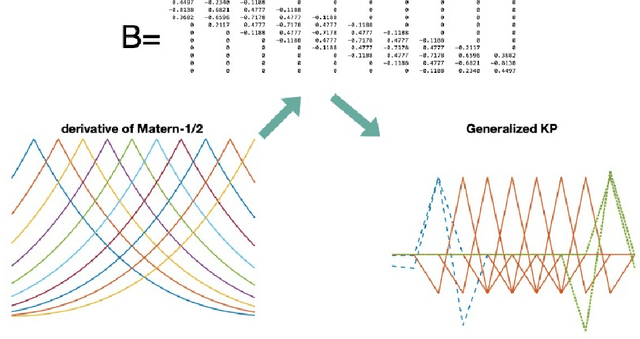

Among generalized additive models, additive Mat\'ern Gaussian Processes (GPs) are one of the most popular for scalable high-dimensional problems. Thanks to their additive structure and stochastic differential equation representation, back-fitting-based algorithms can reduce the time complexity of computing the posterior mean from $O(n^3)$ to $O(n\log n)$ time where $n$ is the data size. However, generalizing these algorithms to efficiently compute the posterior variance and maximum log-likelihood remains an open problem. In this study, we demonstrate that for Additive Mat\'ern GPs, not only the posterior mean, but also the posterior variance, log-likelihood, and gradient of these three functions can be represented by formulas involving only sparse matrices and sparse vectors. We show how to use these sparse formulas to generalize back-fitting-based algorithms to efficiently compute the posterior mean, posterior variance, log-likelihood, and gradient of these three functions for additive GPs, all in $O(n \log n)$ time. We apply our algorithms to Bayesian optimization and propose efficient algorithms for posterior updates, hyperparameters learning, and computations of the acquisition function and its gradient in Bayesian optimization. Given the posterior, our algorithms significantly reduce the time complexity of computing the acquisition function and its gradient from $O(n^2)$ to $O(\log n)$ for general learning rate, and even to $O(1)$ for small learning rate.
Diffusion Co-Policy for Synergistic Human-Robot Collaborative Tasks
May 20, 2023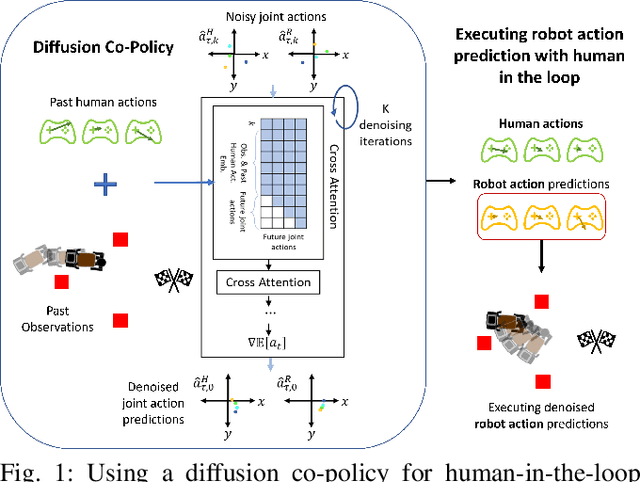
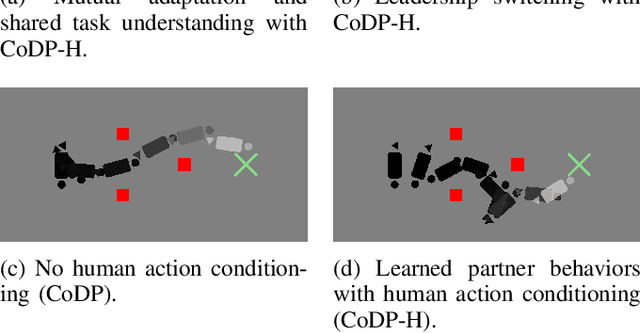

Modeling multimodal human behavior accurately has been a key barrier to increasing the level of interaction between human and robot, particularly for collaborative tasks. Our key insight is that the predictive accuracy of human behaviors on physical tasks is bottlenecked by the model for methods involving human behavior prediction. We present a method for training denoising diffusion probabilistic models on a dataset of collaborative human-human demonstrations and conditioning on past human partner actions to plan sequences of robot actions that synergize well with humans during test time. We demonstrate the method outperforms other state-of-art learning methods on human-robot table-carrying, a continuous state-action task, in both simulation and real settings with a human in the loop. Moreover, we qualitatively highlight compelling robot behaviors that arise during evaluations that demonstrate evidence of true human-robot collaboration, including mutual adaptation, shared task understanding, leadership switching, learned partner behaviors, and low levels of wasteful interaction forces arising from dissent. Project page coming soon.
The Brain Tumor Segmentation (BraTS) Challenge 2023: Brain MR Image Synthesis for Tumor Segmentation (BraSyn)
May 20, 2023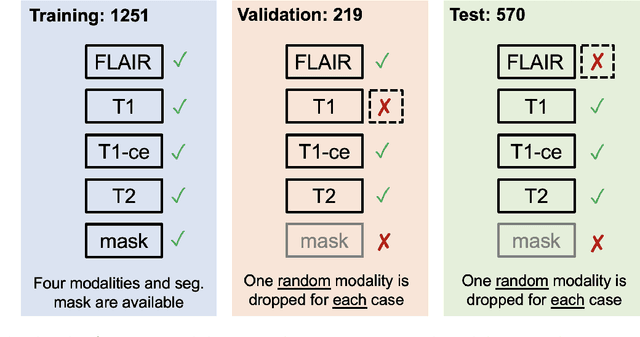
Automated brain tumor segmentation methods are well established, reaching performance levels with clear clinical utility. Most algorithms require four input magnetic resonance imaging (MRI) modalities, typically T1-weighted images with and without contrast enhancement, T2-weighted images, and FLAIR images. However, some of these sequences are often missing in clinical practice, e.g., because of time constraints and/or image artifacts (such as patient motion). Therefore, substituting missing modalities to recover segmentation performance in these scenarios is highly desirable and necessary for the more widespread adoption of such algorithms in clinical routine. In this work, we report the set-up of the Brain MR Image Synthesis Benchmark (BraSyn), organized in conjunction with the Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2023. The objective of the challenge is to benchmark image synthesis methods that realistically synthesize missing MRI modalities given multiple available images to facilitate automated brain tumor segmentation pipelines. The image dataset is multi-modal and diverse, created in collaboration with various hospitals and research institutions.
Off-Policy Average Reward Actor-Critic with Deterministic Policy Search
May 20, 2023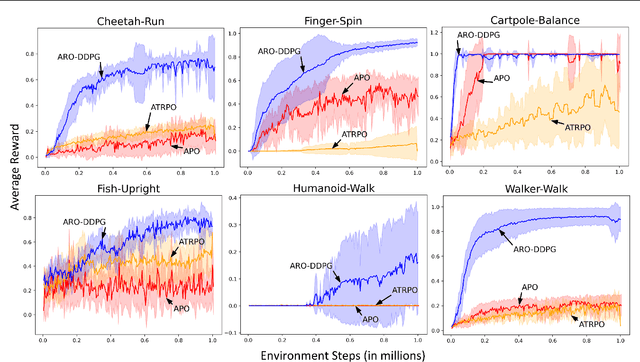
The average reward criterion is relatively less studied as most existing works in the Reinforcement Learning literature consider the discounted reward criterion. There are few recent works that present on-policy average reward actor-critic algorithms, but average reward off-policy actor-critic is relatively less explored. In this work, we present both on-policy and off-policy deterministic policy gradient theorems for the average reward performance criterion. Using these theorems, we also present an Average Reward Off-Policy Deep Deterministic Policy Gradient (ARO-DDPG) Algorithm. We first show asymptotic convergence analysis using the ODE-based method. Subsequently, we provide a finite time analysis of the resulting stochastic approximation scheme with linear function approximator and obtain an $\epsilon$-optimal stationary policy with a sample complexity of $\Omega(\epsilon^{-2.5})$. We compare the average reward performance of our proposed ARO-DDPG algorithm and observe better empirical performance compared to state-of-the-art on-policy average reward actor-critic algorithms over MuJoCo-based environments.
An Asynchronous Wireless Network for Capturing Event-Driven Data from Large Populations of Autonomous Sensors
May 20, 2023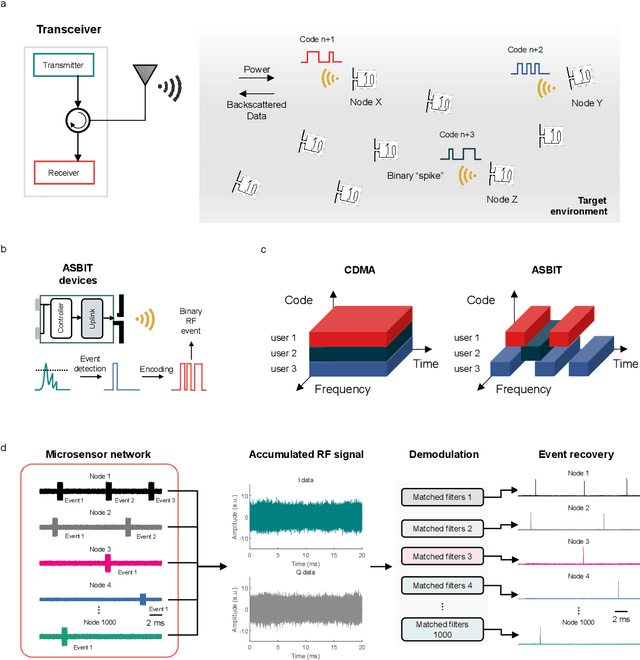
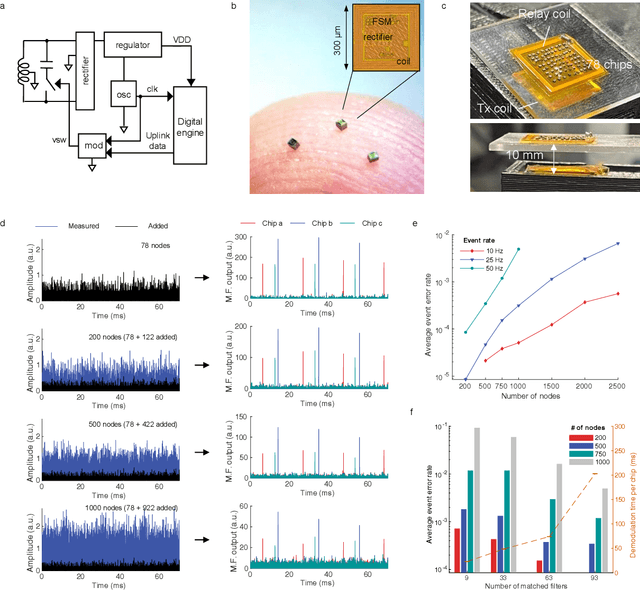
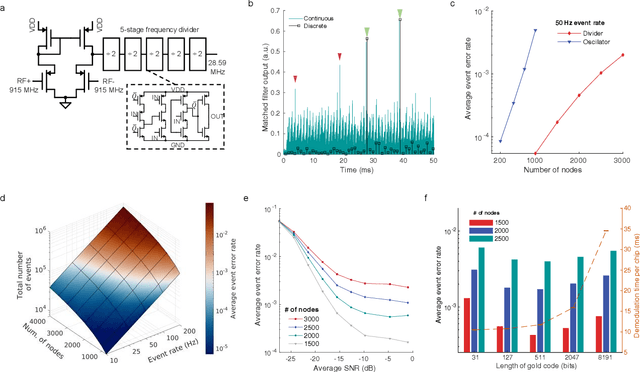
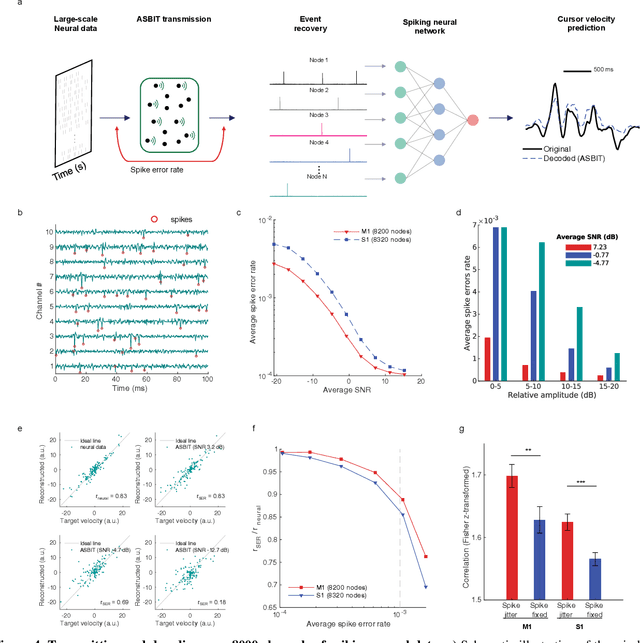
We introduce a wireless RF network concept for capturing sparse event-driven data from large populations of spatially distributed autonomous microsensors, possibly numbered in the thousands. Each sensor is assumed to be a microchip capable of event detection in transforming time-varying inputs to spike trains. Inspired by brain information processing, we have developed a spectrally efficient, low-error rate asynchronous networking concept based on a code-division multiple access method. We characterize the network performance of several dozen submillimeter-size silicon microchips experimentally, complemented by larger scale in silico simulations. A comparison is made between different implementations of on-chip clocks. Testing the notion that spike-based wireless communication is naturally matched with downstream sensor population analysis by neuromorphic computing techniques, we then deploy a spiking neural network (SNN) machine learning model to decode data from eight thousand spiking neurons in the primate cortex for accurate prediction of hand movement in a cursor control task.
Do We Need an Encoder-Decoder to Model Dynamical Systems on Networks?
May 20, 2023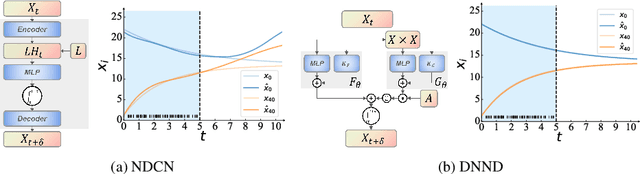
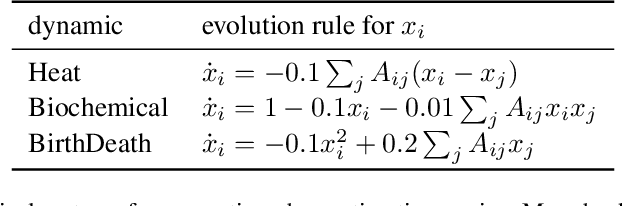
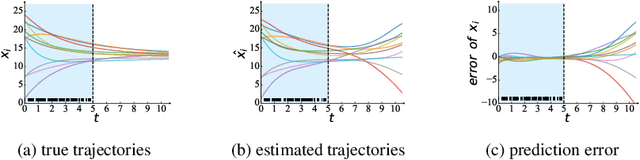
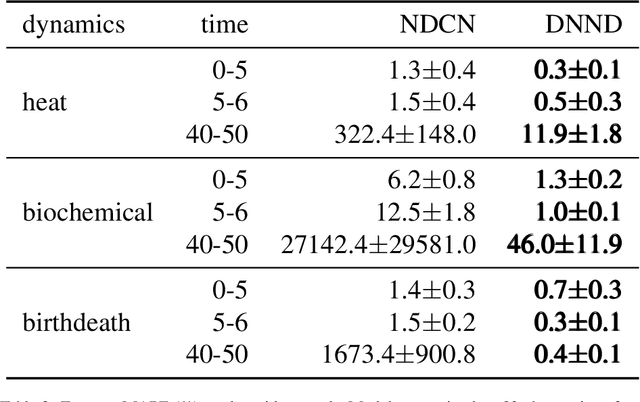
As deep learning gains popularity in modelling dynamical systems, we expose an underappreciated misunderstanding relevant to modelling dynamics on networks. Strongly influenced by graph neural networks, latent vertex embeddings are naturally adopted in many neural dynamical network models. However, we show that embeddings tend to induce a model that fits observations well but simultaneously has incorrect dynamical behaviours. Recognising that previous studies narrowly focus on short-term predictions during the transient phase of a flow, we propose three tests for correct long-term behaviour, and illustrate how an embedding-based dynamical model fails these tests, and analyse the causes, particularly through the lens of topological conjugacy. In doing so, we show that the difficulties can be avoided by not using embedding. We propose a simple embedding-free alternative based on parametrising two additive vector-field components. Through extensive experiments, we verify that the proposed model can reliably recover a broad class of dynamics on different network topologies from time series data.
Joint Beamforming Design for RIS-enabled Integrated Positioning and Communication in Millimeter Wave Systems
May 20, 2023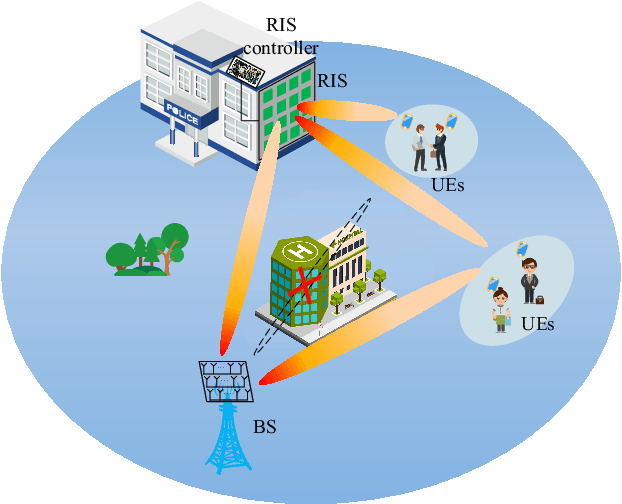
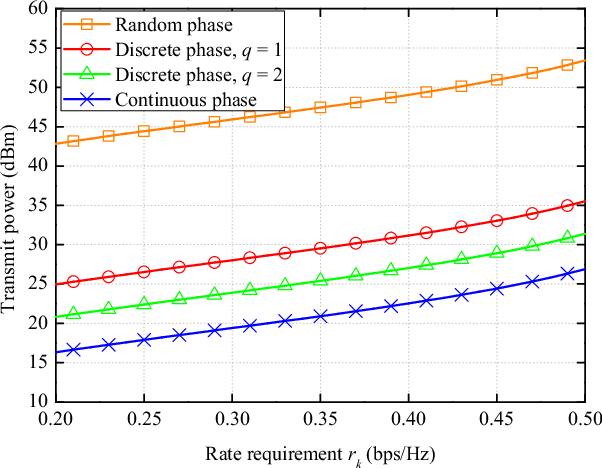
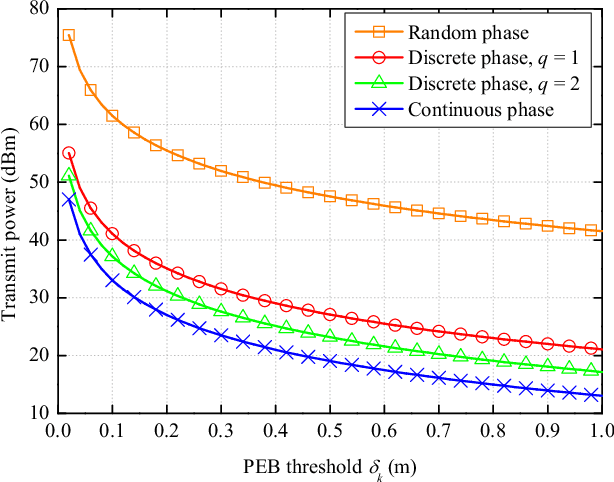
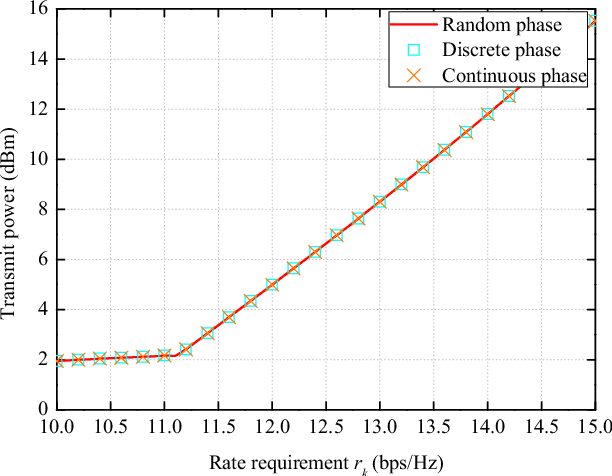
Integrated positioning and communication (IPAC) system and reconfigurable intelligent surface (RIS) are both considered to be key technologies for future wireless networks. Therefore, in this paper, we propose a RIS-enabled IPAC scheme with the millimeter wave system. First, we derive the explicit expressions of the time-of-arrival (ToA)-based Cram\'er-Rao bound (CRB) and positioning error bound (PEB) for the RIS-aided system as the positioning metrics. Then, we formulate the IPAC system by jointly optimizing active beamforming in the base station (BS) and passive beamforming in the RIS to minimize the transmit power, while satisfying the communication data rate and PEB constraints. Finally, we propose an efficient two-stage algorithm to solve the optimization problem based on a series of methods such as the exhaustive search and semidefinite relaxation (SDR). Simulation results show that by changing various critical system parameters, the proposed RIS-enabled IPAC system can cater to both reliable data rates and high-precision positioning in different transmission environments.
MINT: Multiplier-less Integer Quantization for Spiking Neural Networks
May 20, 2023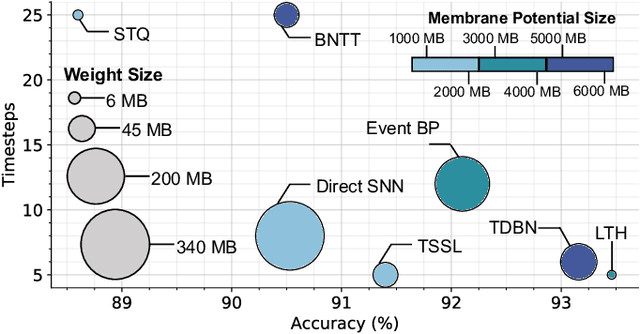
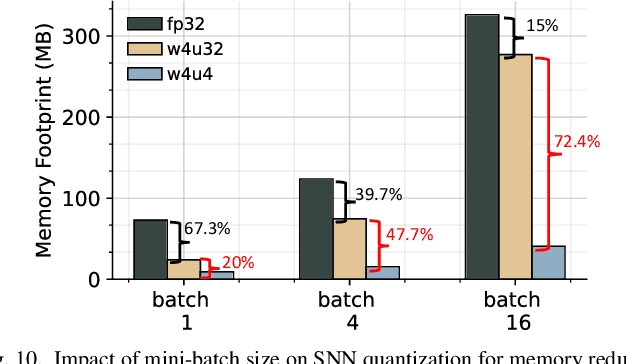
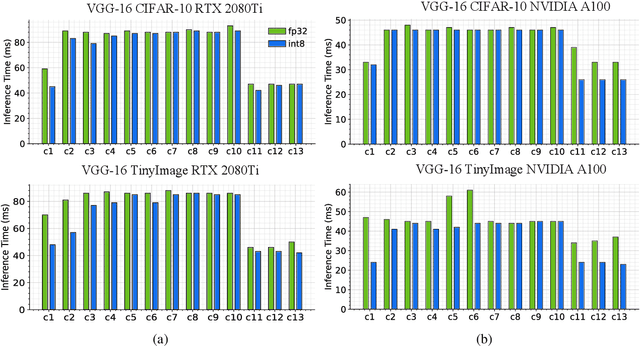
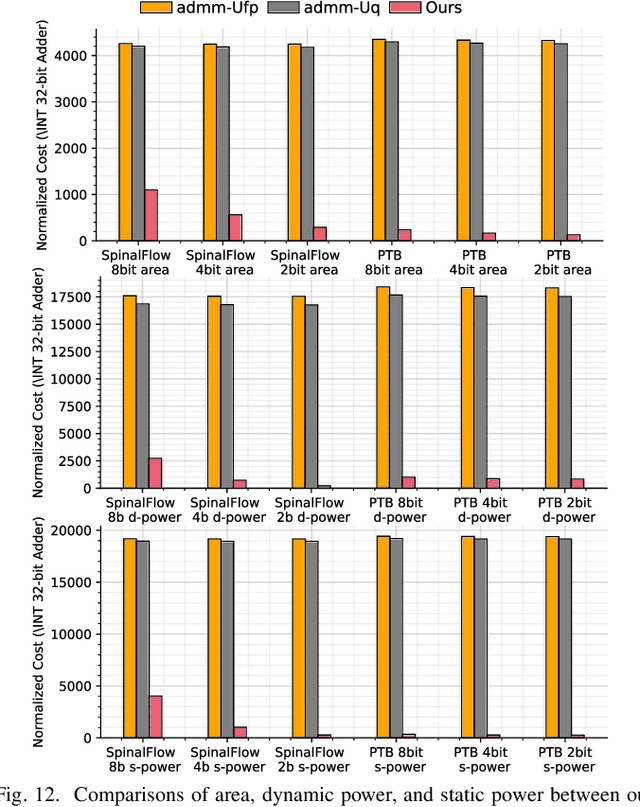
We propose Multiplier-less INTeger (MINT) quantization, an efficient uniform quantization scheme for the weights and membrane potentials in spiking neural networks (SNNs). Unlike prior SNN quantization works, MINT quantizes the memory-hungry membrane potentials to extremely low bit-width (2-bit) to significantly reduce the total memory footprint. Additionally, MINT quantization shares the quantization scale between the weights and membrane potentials, eliminating the need for multipliers and floating arithmetic units, which are required by the standard uniform quantization. Experimental results demonstrate that our proposed method achieves accuracy that matches other state-of-the-art SNN quantization works while outperforming them on total memory footprint and hardware cost at deployment time. For instance, 2-bit MINT VGG-16 achieves 48.6% accuracy on TinyImageNet (0.28% better than the full-precision baseline) with approximately 93.8% reduction in total memory footprint from the full-precision model; meanwhile, our model reduces area by 93% and dynamic power by 98% compared to other SNN quantization counterparts.