 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Safety Implications of Explainable Artificial Intelligence in End-to-End Autonomous Driving
Mar 18, 2024
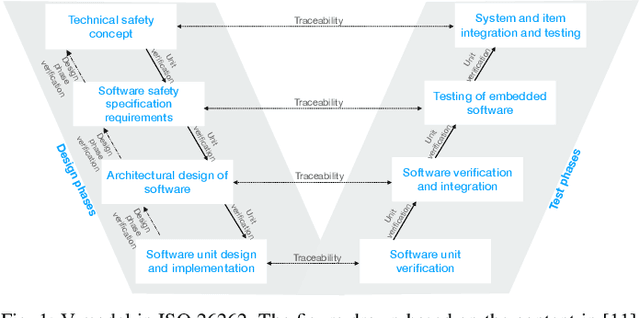



The end-to-end learning pipeline is gradually creating a paradigm shift in the ongoing development of highly autonomous vehicles, largely due to advances in deep learning, the availability of large-scale training datasets, and improvements in integrated sensor devices. However, a lack of interpretability in real-time decisions with contemporary learning methods impedes user trust and attenuates the widespread deployment and commercialization of such vehicles. Moreover, the issue is exacerbated when these cars are involved in or cause traffic accidents. Such drawback raises serious safety concerns from societal and legal perspectives. Consequently, explainability in end-to-end autonomous driving is essential to enable the safety of vehicular automation. However, the safety and explainability aspects of autonomous driving have generally been investigated disjointly by researchers in today's state of the art. In this paper, we aim to bridge the gaps between these topics and seek to answer the following research question: When and how can explanations improve safety of autonomous driving? In this regard, we first revisit established safety and state-of-the-art explainability techniques in autonomous driving. Furthermore, we present three critical case studies and show the pivotal role of explanations in enhancing self-driving safety. Finally, we describe our empirical investigation and reveal potential value, limitations, and caveats with practical explainable AI methods on their role of assuring safety and transparency for vehicle autonomy.
SAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration
Mar 18, 2024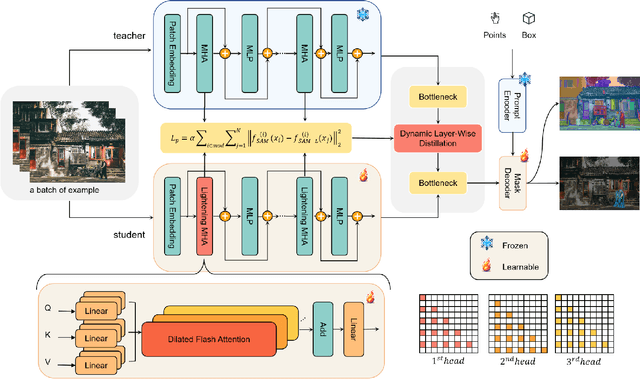
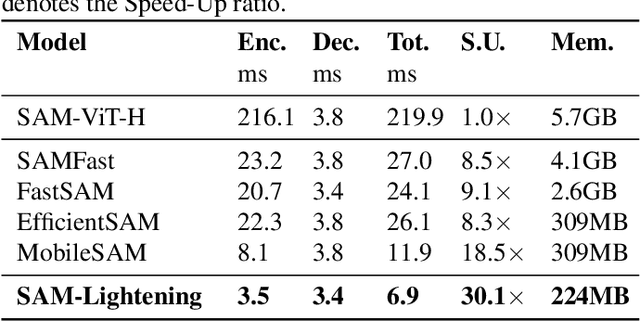

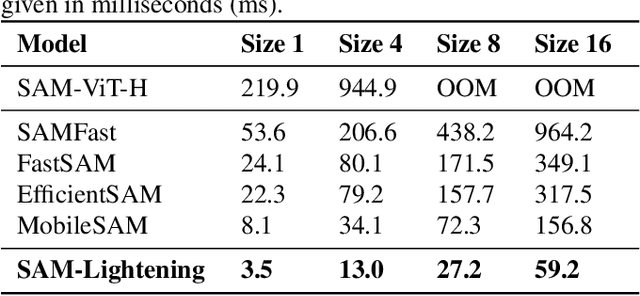
Segment Anything Model (SAM) has garnered significant attention in segmentation tasks due to their zero-shot generalization ability. However, a broader application of SAMs to real-world practice has been restricted by their low inference speed and high computational memory demands, which mainly stem from the attention mechanism. Existing work concentrated on optimizing the encoder, yet has not adequately addressed the inefficiency of the attention mechanism itself, even when distilled to a smaller model, which thus leaves space for further improvement. In response, we introduce SAM-Lightening, a variant of SAM, that features a re-engineered attention mechanism, termed Dilated Flash Attention. It not only facilitates higher parallelism, enhancing processing efficiency but also retains compatibility with the existing FlashAttention. Correspondingly, we propose a progressive distillation to enable an efficient knowledge transfer from the vanilla SAM without costly training from scratch. Experiments on COCO and LVIS reveal that SAM-Lightening significantly outperforms the state-of-the-art methods in both run-time efficiency and segmentation accuracy. Specifically, it can achieve an inference speed of 7 milliseconds (ms) per image, for images of size 1024*1024 pixels, which is 30.1 times faster than the vanilla SAM and 2.1 times than the state-of-the-art. Moreover, it takes only 244MB memory, which is 3.5\% of the vanilla SAM. The code and weights are available at https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/.
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Mar 18, 2024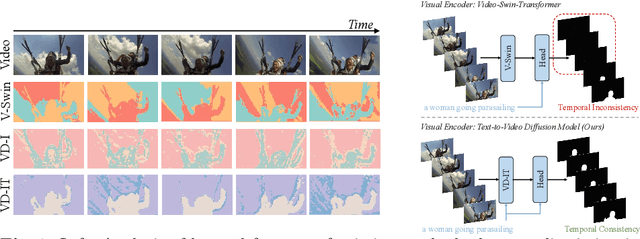
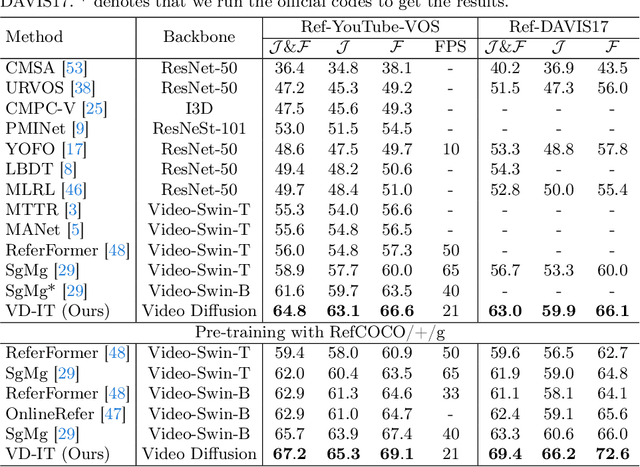
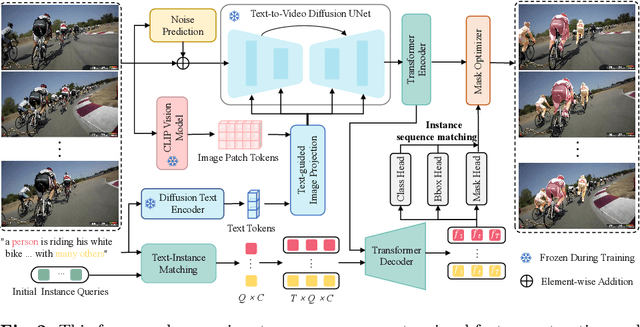
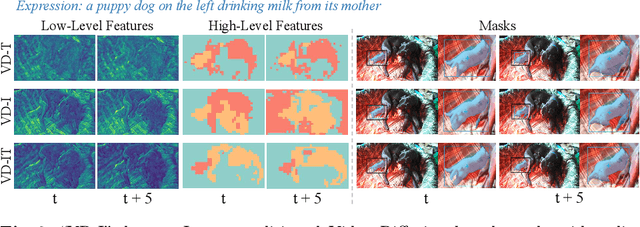
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed ``VD-IT'', tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks.Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code will be available at \url{https://github.com/buxiangzhiren/VD-IT}
UV Gaussians: Joint Learning of Mesh Deformation and Gaussian Textures for Human Avatar Modeling
Mar 18, 2024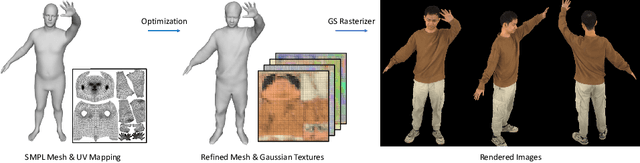

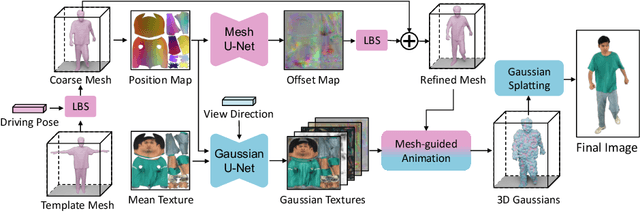

Reconstructing photo-realistic drivable human avatars from multi-view image sequences has been a popular and challenging topic in the field of computer vision and graphics. While existing NeRF-based methods can achieve high-quality novel view rendering of human models, both training and inference processes are time-consuming. Recent approaches have utilized 3D Gaussians to represent the human body, enabling faster training and rendering. However, they undermine the importance of the mesh guidance and directly predict Gaussians in 3D space with coarse mesh guidance. This hinders the learning procedure of the Gaussians and tends to produce blurry textures. Therefore, we propose UV Gaussians, which models the 3D human body by jointly learning mesh deformations and 2D UV-space Gaussian textures. We utilize the embedding of UV map to learn Gaussian textures in 2D space, leveraging the capabilities of powerful 2D networks to extract features. Additionally, through an independent Mesh network, we optimize pose-dependent geometric deformations, thereby guiding Gaussian rendering and significantly enhancing rendering quality. We collect and process a new dataset of human motion, which includes multi-view images, scanned models, parametric model registration, and corresponding texture maps. Experimental results demonstrate that our method achieves state-of-the-art synthesis of novel view and novel pose. The code and data will be made available on the homepage https://alex-jyj.github.io/UV-Gaussians/ once the paper is accepted.
Pessimistic Causal Reinforcement Learning with Mediators for Confounded Offline Data
Mar 18, 2024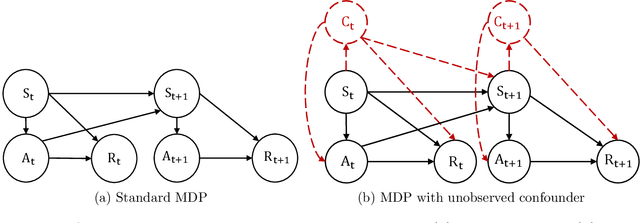
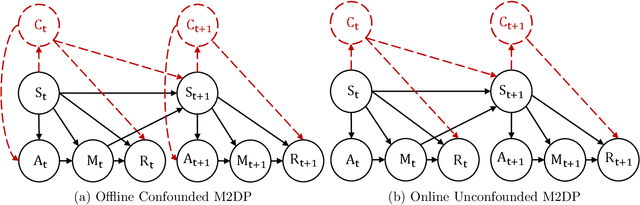
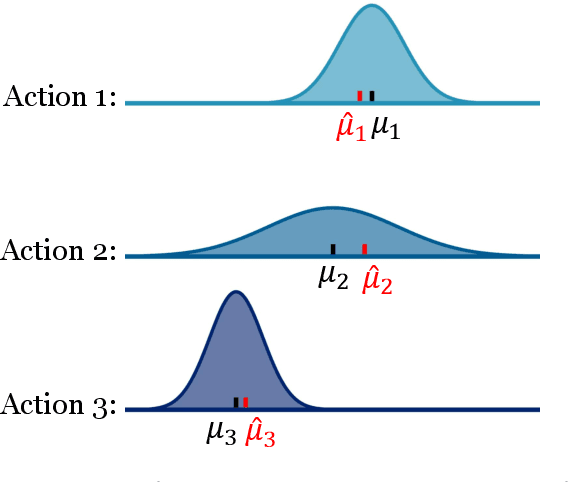
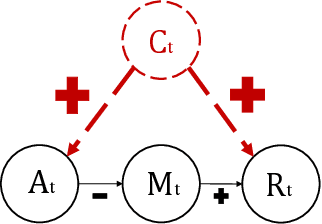
In real-world scenarios, datasets collected from randomized experiments are often constrained by size, due to limitations in time and budget. As a result, leveraging large observational datasets becomes a more attractive option for achieving high-quality policy learning. However, most existing offline reinforcement learning (RL) methods depend on two key assumptions--unconfoundedness and positivity--which frequently do not hold in observational data contexts. Recognizing these challenges, we propose a novel policy learning algorithm, PESsimistic CAusal Learning (PESCAL). We utilize the mediator variable based on front-door criterion to remove the confounding bias; additionally, we adopt the pessimistic principle to address the distributional shift between the action distributions induced by candidate policies, and the behavior policy that generates the observational data. Our key observation is that, by incorporating auxiliary variables that mediate the effect of actions on system dynamics, it is sufficient to learn a lower bound of the mediator distribution function, instead of the Q-function, to partially mitigate the issue of distributional shift. This insight significantly simplifies our algorithm, by circumventing the challenging task of sequential uncertainty quantification for the estimated Q-function. Moreover, we provide theoretical guarantees for the algorithms we propose, and demonstrate their efficacy through simulations, as well as real-world experiments utilizing offline datasets from a leading ride-hailing platform.
FedSPU: Personalized Federated Learning for Resource-constrained Devices with Stochastic Parameter Update
Mar 18, 2024
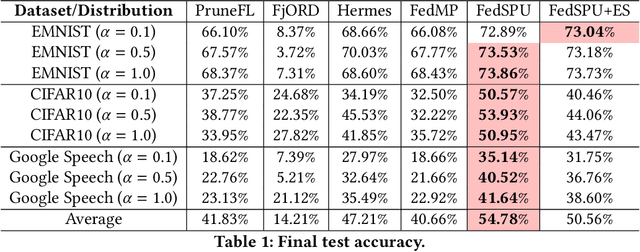
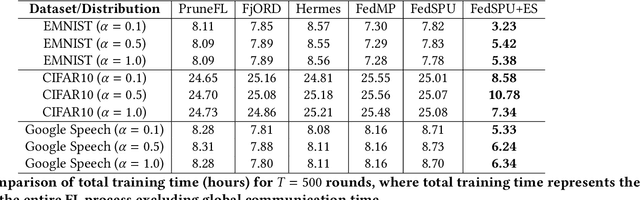
Personalized Federated Learning (PFL) is widely employed in IoT applications to handle high-volume, non-iid client data while ensuring data privacy. However, heterogeneous edge devices owned by clients may impose varying degrees of resource constraints, causing computation and communication bottlenecks for PFL. Federated Dropout has emerged as a popular strategy to address this challenge, wherein only a subset of the global model, i.e. a \textit{sub-model}, is trained on a client's device, thereby reducing computation and communication overheads. Nevertheless, the dropout-based model-pruning strategy may introduce bias, particularly towards non-iid local data. When biased sub-models absorb highly divergent parameters from other clients, performance degradation becomes inevitable. In response, we propose federated learning with stochastic parameter update (FedSPU). Unlike dropout that tailors the global model to small-size local sub-models, FedSPU maintains the full model architecture on each device but randomly freezes a certain percentage of neurons in the local model during training while updating the remaining neurons. This approach ensures that a portion of the local model remains personalized, thereby enhancing the model's robustness against biased parameters from other clients. Experimental results demonstrate that FedSPU outperforms federated dropout by 7.57\% on average in terms of accuracy. Furthermore, an introduced early stopping scheme leads to a significant reduction of the training time by \(24.8\%\sim70.4\%\) while maintaining high accuracy.
Invariant Test-Time Adaptation for Vision-Language Model Generalization
Mar 01, 2024

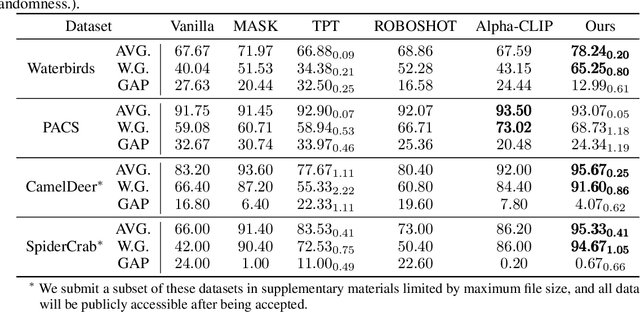
Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired datasets. However, these models display significant limitations when applied to long-tail tasks, such as fine-grained image classification, as a result of "decision shortcuts" that hinders their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both \textit{desired invariant causal features} and \textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, this paper introduces a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit genuine causal invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading, task-irrelevant contextual information, while concurrently emphasizing critical, task-related visual cues. We conduct comparative analysis of the proposed method against various approaches which validates its effectiveness.
E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
Mar 01, 2024We propose E2USD that enables efficient-yet-accurate unsupervised MTS state detection. E2USD exploits a Fast Fourier Transform-based Time Series Compressor (FFTCompress) and a Decomposed Dual-view Embedding Module (DDEM) that together encode input MTSs at low computational overhead. Additionally, we propose a False Negative Cancellation Contrastive Learning method (FNCCLearning) to counteract the effects of false negatives and to achieve more cluster-friendly embedding spaces. To reduce computational overhead further in streaming settings, we introduce Adaptive Threshold Detection (ADATD). Comprehensive experiments with six baselines and six datasets offer evidence that E2USD is capable of SOTA accuracy at significantly reduced computational overhead. Our code is available at https://github.com/AI4CTS/E2Usd.
Generative Pretrained Hierarchical Transformer for Time Series Forecasting
Feb 26, 2024Recent efforts have been dedicated to enhancing time series forecasting accuracy by introducing advanced network architectures and self-supervised pretraining strategies. Nevertheless, existing approaches still exhibit two critical drawbacks. Firstly, these methods often rely on a single dataset for training, limiting the model's generalizability due to the restricted scale of the training data. Secondly, the one-step generation schema is widely followed, which necessitates a customized forecasting head and overlooks the temporal dependencies in the output series, and also leads to increased training costs under different horizon length settings. To address these issues, we propose a novel generative pretrained hierarchical transformer architecture for forecasting, named GPHT. There are two aspects of key designs in GPHT. On the one hand, we advocate for constructing a mixed dataset for pretraining our model, comprising various datasets from diverse data scenarios. This approach significantly expands the scale of training data, allowing our model to uncover commonalities in time series data and facilitating improved transfer to specific datasets. On the other hand, GPHT employs an auto-regressive forecasting approach under the channel-independent assumption, effectively modeling temporal dependencies in the output series. Importantly, no customized forecasting head is required, enabling a single model to forecast at arbitrary horizon settings. We conduct sufficient experiments on eight datasets with mainstream self-supervised pretraining models and supervised models. The results demonstrated that GPHT surpasses the baseline models across various fine-tuning and zero/few-shot learning settings in the traditional long-term forecasting task, providing support for verifying the feasibility of pretrained time series large models.
Compact 3D Gaussian Splatting For Dense Visual SLAM
Mar 17, 2024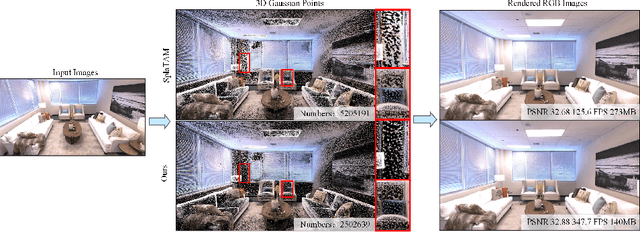
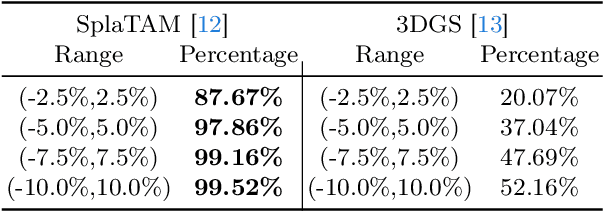
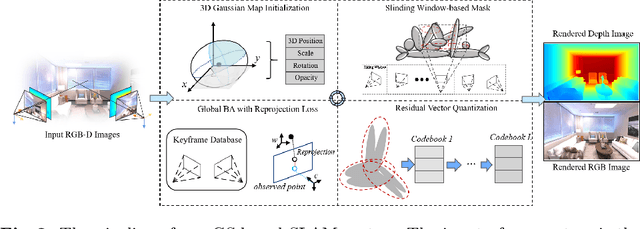

Recent work has shown that 3D Gaussian-based SLAM enables high-quality reconstruction, accurate pose estimation, and real-time rendering of scenes. However, these approaches are built on a tremendous number of redundant 3D Gaussian ellipsoids, leading to high memory and storage costs, and slow training speed. To address the limitation, we propose a compact 3D Gaussian Splatting SLAM system that reduces the number and the parameter size of Gaussian ellipsoids. A sliding window-based masking strategy is first proposed to reduce the redundant ellipsoids. Then we observe that the covariance matrix (geometry) of most 3D Gaussian ellipsoids are extremely similar, which motivates a novel geometry codebook to compress 3D Gaussian geometric attributes, i.e., the parameters. Robust and accurate pose estimation is achieved by a global bundle adjustment method with reprojection loss. Extensive experiments demonstrate that our method achieves faster training and rendering speed while maintaining the state-of-the-art (SOTA) quality of the scene representation.