 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
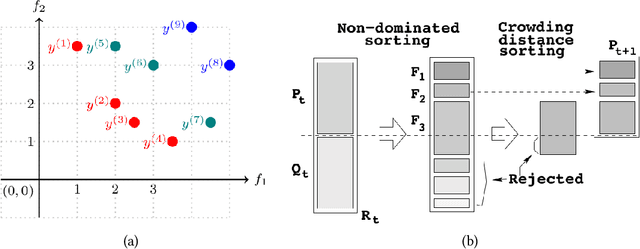
Approximating a RUM from Distributions on k-Slates
May 22, 2023
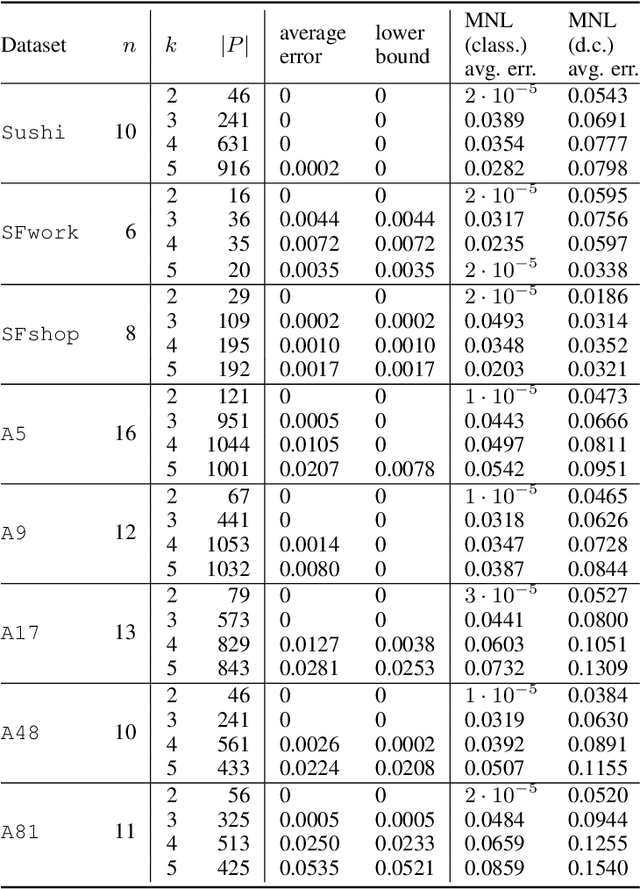
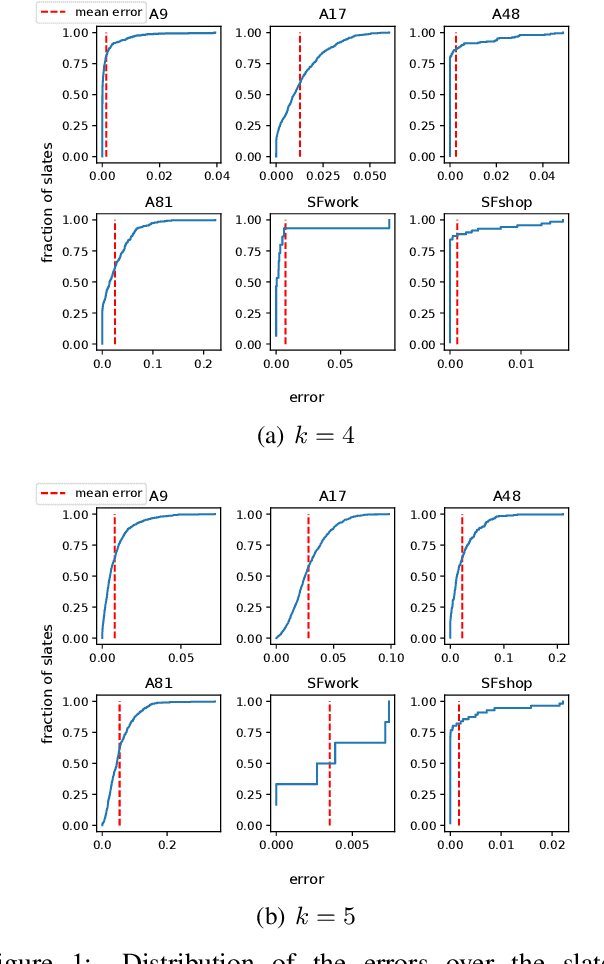
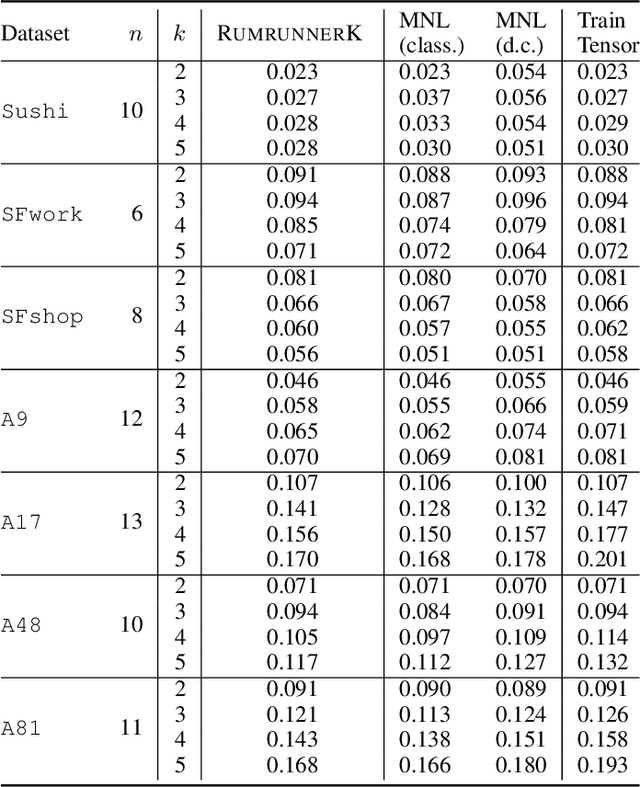
In this work we consider the problem of fitting Random Utility Models (RUMs) to user choices. Given the winner distributions of the subsets of size $k$ of a universe, we obtain a polynomial-time algorithm that finds the RUM that best approximates the given distribution on average. Our algorithm is based on a linear program that we solve using the ellipsoid method. Given that its corresponding separation oracle problem is NP-hard, we devise an approximate separation oracle that can be viewed as a generalization of the weighted feedback arc set problem to hypergraphs. Our theoretical result can also be made practical: we obtain a heuristic that is effective and scales to real-world datasets.
Trend Investigation of Biopotential Recording Front-End Channels for Invasive and Non-Invasive Applications
May 22, 2023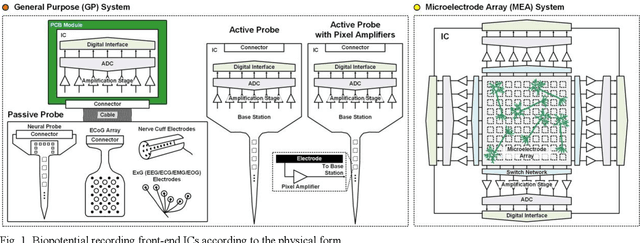
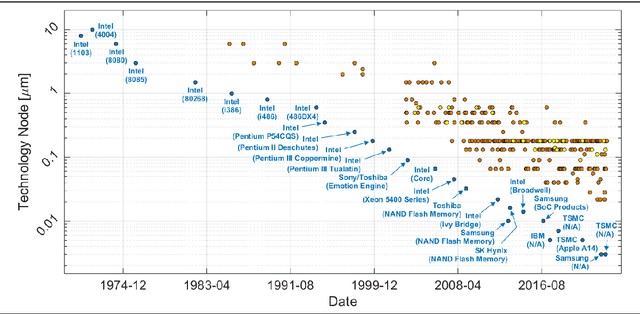
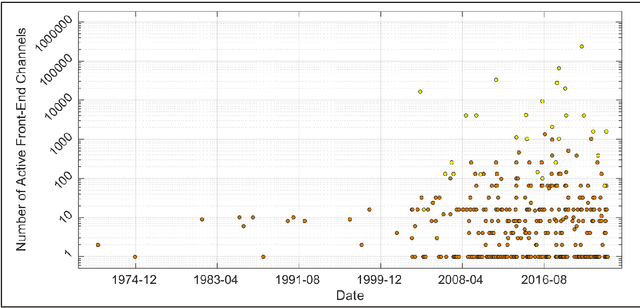
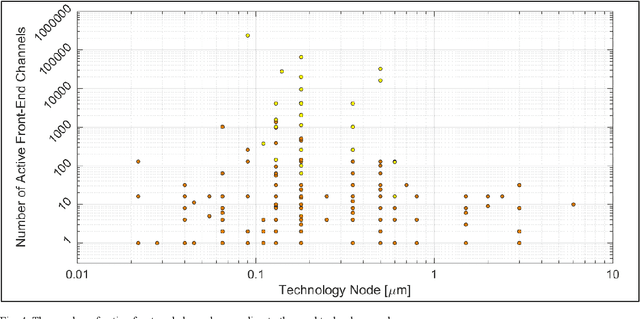
This paper presents the trend of biopotential recording front-end channels developed from the 1970s to the 2020s while describing a basic background on the front-end channel design. Only the front-end channels that conduct electrical recording invasively and non-invasively are addressed. The front-end channels are investigated in terms of technology node, number of channels, supply voltage, noise efficiency factor, and power efficiency factor. Also, multi-faceted comparisons are made to figure out the correlation between these five categories. In each category, the design trend is presented over time, and related circuit techniques are discussed. While addressing the characteristics of circuit techniques used to improve the channel performance, what needs to be improved is also suggested.
MIDI-Draw: Sketching to Control Melody Generation
May 19, 2023
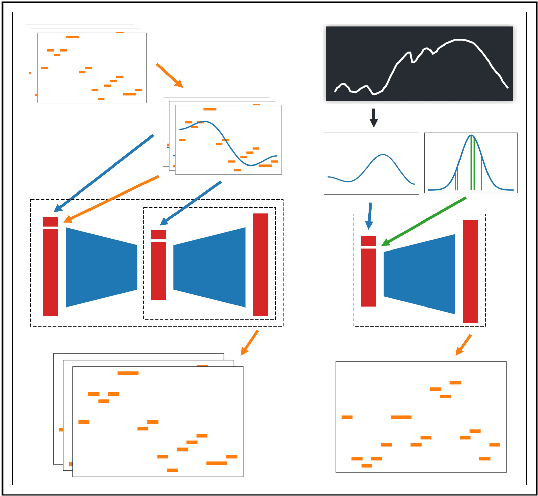
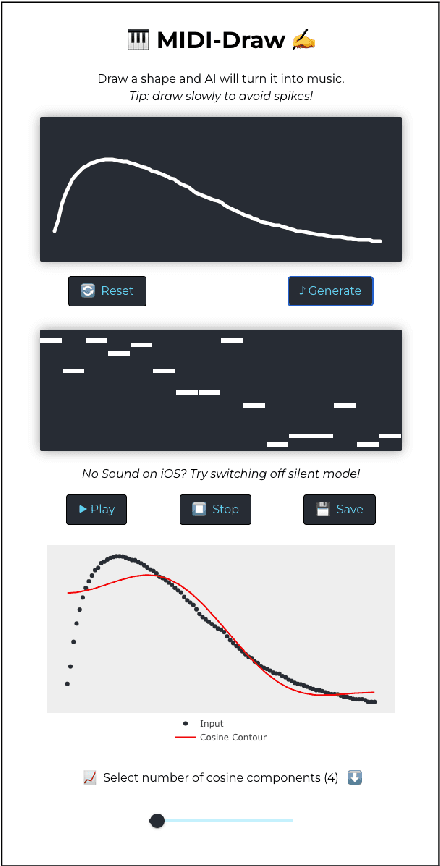
We describe a proof-of-principle implementation of a system for drawing melodies that abstracts away from a note-level input representation via melodic contours. The aim is to allow users to express their musical intentions without requiring prior knowledge of how notes fit together melodiously. Current approaches to controllable melody generation often require users to choose parameters that are static across a whole sequence, via buttons or sliders. In contrast, our method allows users to quickly specify how parameters should change over time by drawing a contour.
ToxBuster: In-game Chat Toxicity Buster with BERT
May 21, 2023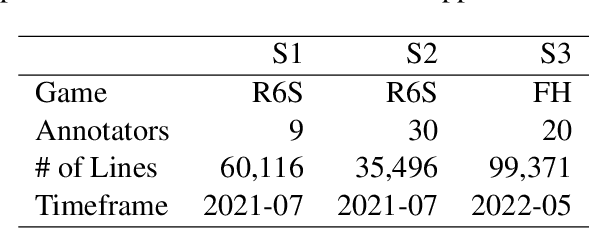
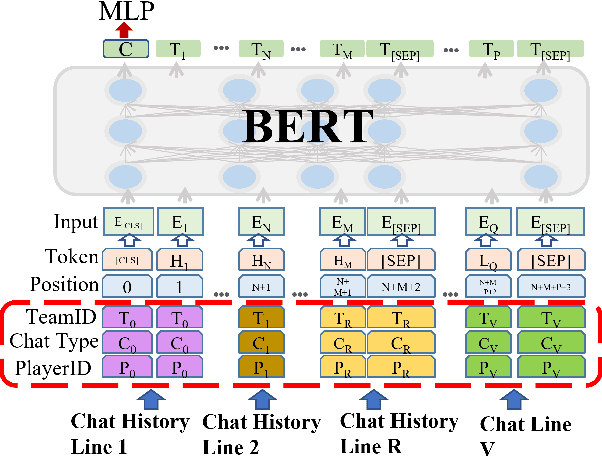
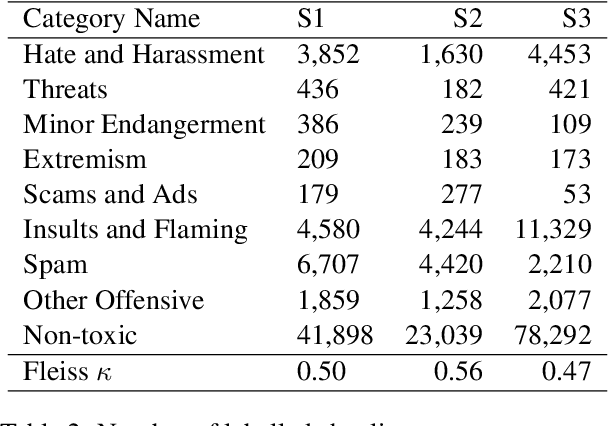
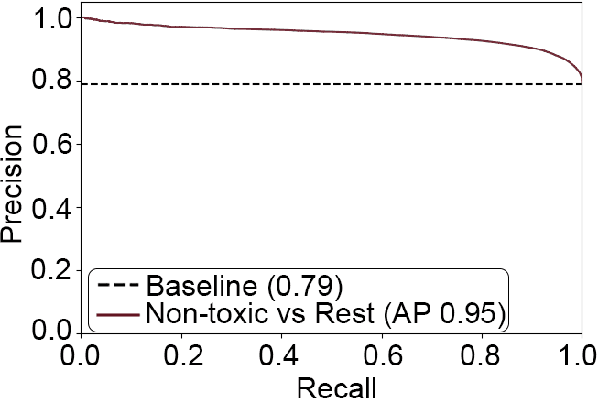
Detecting toxicity in online spaces is challenging and an ever more pressing problem given the increase in social media and gaming consumption. We introduce ToxBuster, a simple and scalable model trained on a relatively large dataset of 194k lines of game chat from Rainbow Six Siege and For Honor, carefully annotated for different kinds of toxicity. Compared to the existing state-of-the-art, ToxBuster achieves 82.95% (+7) in precision and 83.56% (+57) in recall. This improvement is obtained by leveraging past chat history and metadata. We also study the implication towards real-time and post-game moderation as well as the model transferability from one game to another.
Distilling Efficient Language-Specific Models for Cross-Lingual Transfer
Jun 02, 2023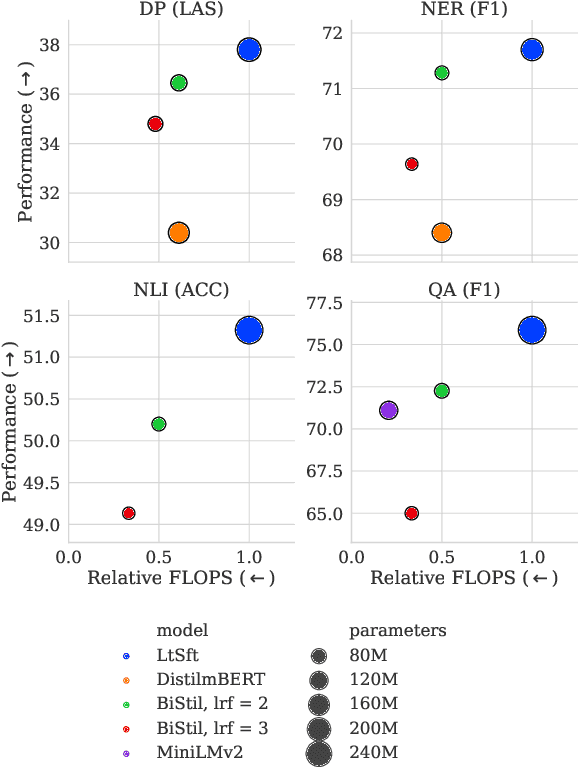
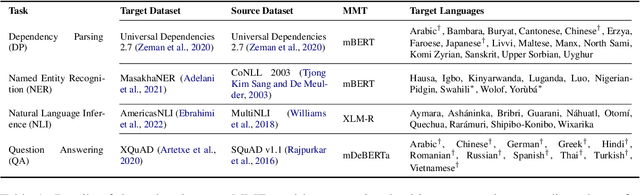
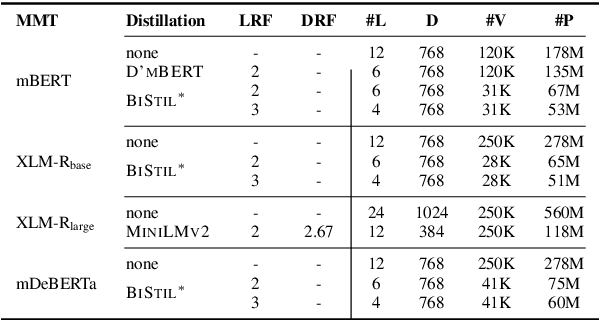

Massively multilingual Transformers (MMTs), such as mBERT and XLM-R, are widely used for cross-lingual transfer learning. While these are pretrained to represent hundreds of languages, end users of NLP systems are often interested only in individual languages. For such purposes, the MMTs' language coverage makes them unnecessarily expensive to deploy in terms of model size, inference time, energy, and hardware cost. We thus propose to extract compressed, language-specific models from MMTs which retain the capacity of the original MMTs for cross-lingual transfer. This is achieved by distilling the MMT bilingually, i.e., using data from only the source and target language of interest. Specifically, we use a two-phase distillation approach, termed BiStil: (i) the first phase distils a general bilingual model from the MMT, while (ii) the second, task-specific phase sparsely fine-tunes the bilingual "student" model using a task-tuned variant of the original MMT as its "teacher". We evaluate this distillation technique in zero-shot cross-lingual transfer across a number of standard cross-lingual benchmarks. The key results indicate that the distilled models exhibit minimal degradation in target language performance relative to the base MMT despite being significantly smaller and faster. Furthermore, we find that they outperform multilingually distilled models such as DistilmBERT and MiniLMv2 while having a very modest training budget in comparison, even on a per-language basis. We also show that bilingual models distilled from MMTs greatly outperform bilingual models trained from scratch. Our code and models are available at https://github.com/AlanAnsell/bistil.
Neural Operator Learning for Long-Time Integration in Dynamical Systems with Recurrent Neural Networks
Mar 03, 2023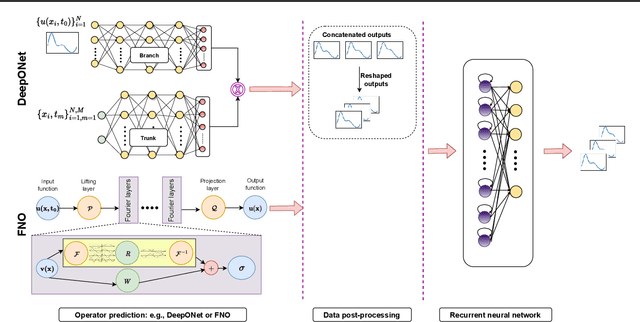
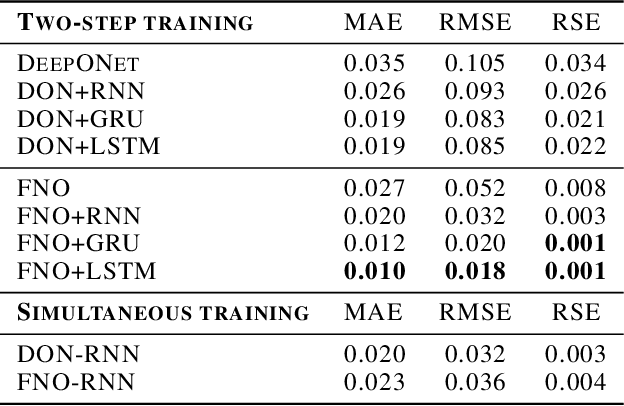
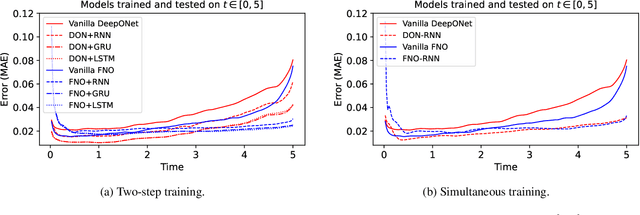
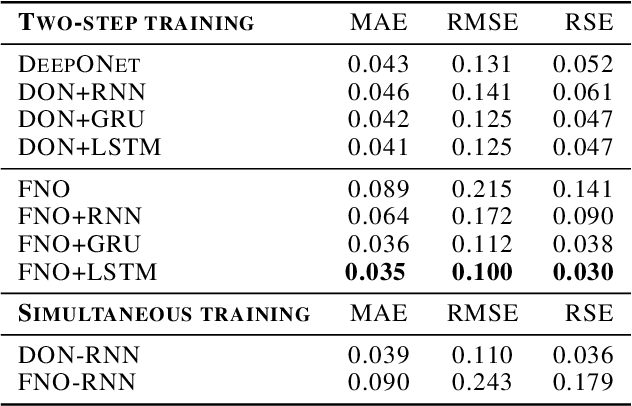
Deep neural networks are an attractive alternative for simulating complex dynamical systems, as in comparison to traditional scientific computing methods, they offer reduced computational costs during inference and can be trained directly from observational data. Existing methods, however, cannot extrapolate accurately and are prone to error accumulation in long-time integration. Herein, we address this issue by combining neural operators with recurrent neural networks to construct a novel and effective architecture, resulting in superior accuracy compared to the state-of-the-art. The new hybrid model is based on operator learning while offering a recurrent structure to capture temporal dependencies. The integrated framework is shown to stabilize the solution and reduce error accumulation for both interpolation and extrapolation of the Korteweg-de Vries equation.
Catalysis distillation neural network for the few shot open catalyst challenge
May 31, 2023The integration of artificial intelligence and science has resulted in substantial progress in computational chemistry methods for the design and discovery of novel catalysts. Nonetheless, the challenges of electrocatalytic reactions and developing a large-scale language model in catalysis persist, and the recent success of ChatGPT's (Chat Generative Pre-trained Transformer) few-shot methods surpassing BERT (Bidirectional Encoder Representation from Transformers) underscores the importance of addressing limited data, expensive computations, time constraints and structure-activity relationship in research. Hence, the development of few-shot techniques for catalysis is critical and essential, regardless of present and future requirements. This paper introduces the Few-Shot Open Catalyst Challenge 2023, a competition aimed at advancing the application of machine learning technology for predicting catalytic reactions on catalytic surfaces, with a specific focus on dual-atom catalysts in hydrogen peroxide electrocatalysis. To address the challenge of limited data in catalysis, we propose a machine learning approach based on MLP-Like and a framework called Catalysis Distillation Graph Neural Network (CDGNN). Our results demonstrate that CDGNN effectively learns embeddings from catalytic structures, enabling the capture of structure-adsorption relationships. This accomplishment has resulted in the utmost advanced and efficient determination of the reaction pathway for hydrogen peroxide, surpassing the current graph neural network approach by 16.1%.. Consequently, CDGNN presents a promising approach for few-shot learning in catalysis.
Bytes Are All You Need: Transformers Operating Directly On File Bytes
May 31, 2023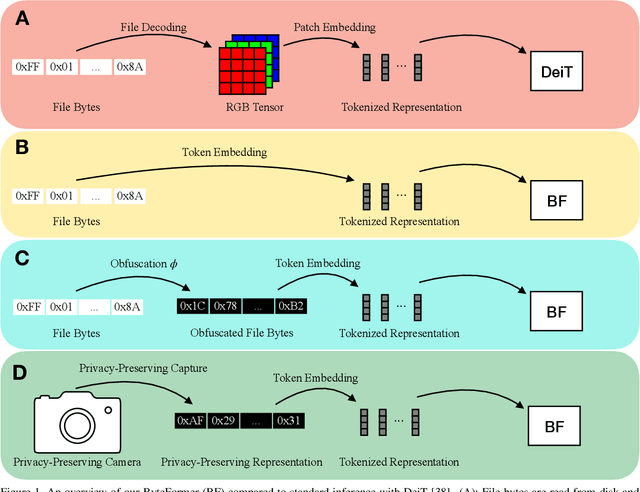

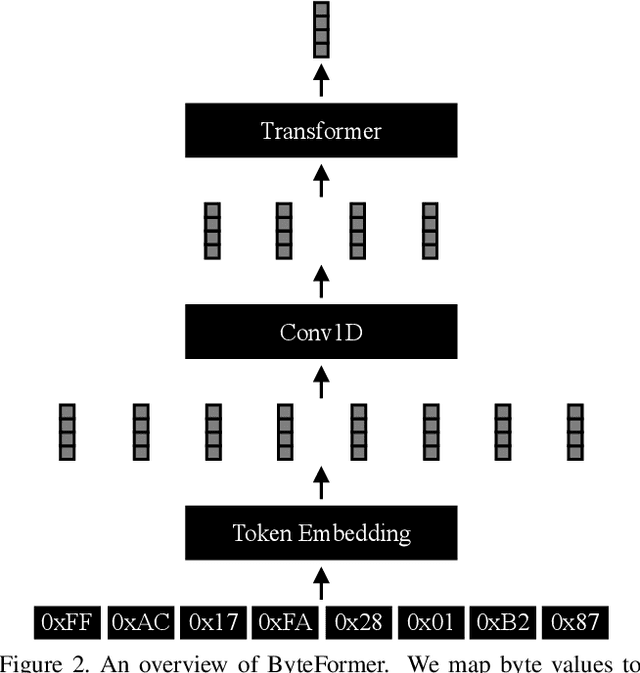
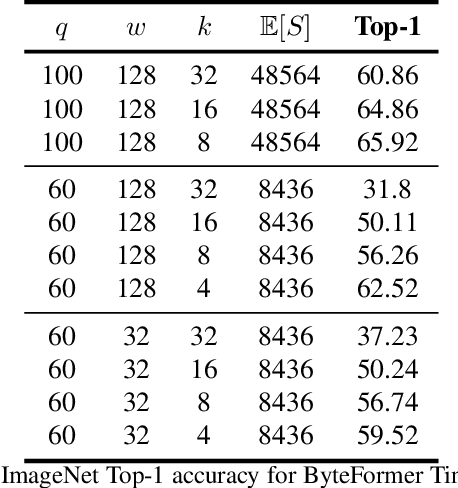
Modern deep learning approaches usually transform inputs into a modality-specific form. For example, the most common deep learning approach to image classification involves decoding image file bytes into an RGB tensor which is passed into a neural network. Instead, we investigate performing classification directly on file bytes, without the need for decoding files at inference time. Using file bytes as model inputs enables the development of models which can operate on multiple input modalities. Our model, \emph{ByteFormer}, achieves an ImageNet Top-1 classification accuracy of $77.33\%$ when training and testing directly on TIFF file bytes using a transformer backbone with configuration similar to DeiT-Ti ($72.2\%$ accuracy when operating on RGB images). Without modifications or hyperparameter tuning, ByteFormer achieves $95.42\%$ classification accuracy when operating on WAV files from the Speech Commands v2 dataset (compared to state-of-the-art accuracy of $98.7\%$). Additionally, we demonstrate that ByteFormer has applications in privacy-preserving inference. ByteFormer is capable of performing inference on particular obfuscated input representations with no loss of accuracy. We also demonstrate ByteFormer's ability to perform inference with a hypothetical privacy-preserving camera which avoids forming full images by consistently masking $90\%$ of pixel channels, while still achieving $71.35\%$ accuracy on ImageNet. Our code will be made available at https://github.com/apple/ml-cvnets/tree/main/examples/byteformer.
Evolutionary Solution Adaption for Multi-Objective Metal Cutting Process Optimization
May 31, 2023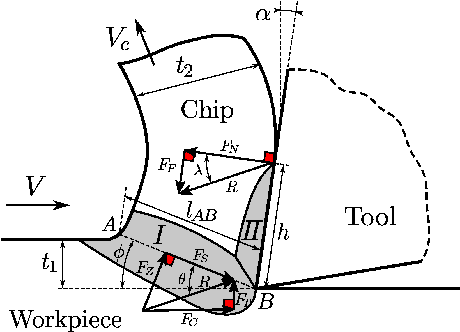

Optimizing manufacturing process parameters is typically a multi-objective problem with often contradictory objectives such as production quality and production time. If production requirements change, process parameters have to be optimized again. Since optimization usually requires costly simulations based on, for example, the Finite Element method, it is of great interest to have means to reduce the number of evaluations needed for optimization. To this end, we consider optimizing for different production requirements from the viewpoint of a framework for system flexibility that allows us to study the ability of an algorithm to transfer solutions from previous optimization tasks, which also relates to dynamic evolutionary optimization. Based on the extended Oxley model for orthogonal metal cutting, we introduce a multi-objective optimization benchmark where different materials define related optimization tasks, and use it to study the flexibility of NSGA-II, which we extend by two variants: 1) varying goals, that optimizes solutions for two tasks simultaneously to obtain in-between source solutions expected to be more adaptable, and 2) active-inactive genotype, that accommodates different possibilities that can be activated or deactivated. Results show that adaption with standard NSGA-II greatly reduces the number of evaluations required for optimization to a target goal, while the proposed variants further improve the adaption costs, although further work is needed towards making the methods advantageous for real applications.
M3ICRO: Machine Learning-Enabled Compact Photonic Tensor Core based on PRogrammable Multi-Operand Multimode Interference
May 31, 2023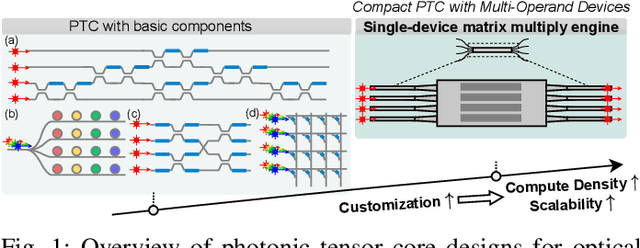
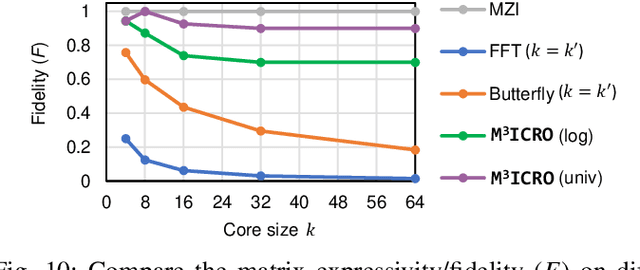
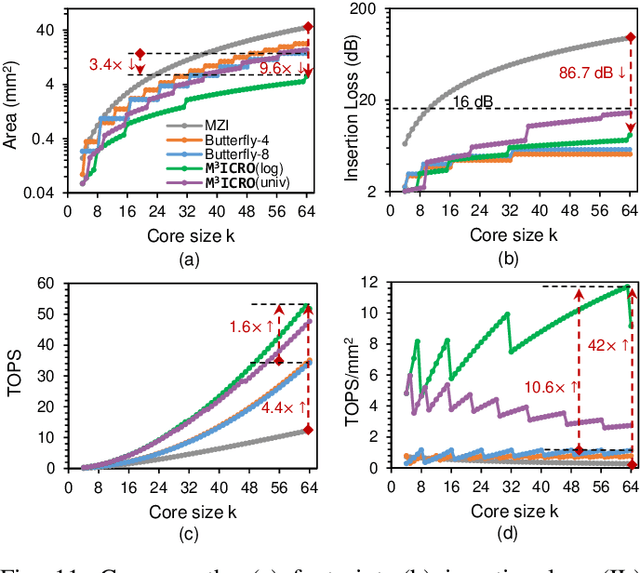
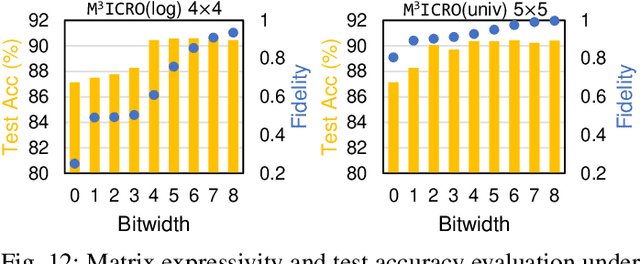
Photonic computing shows promise for transformative advancements in machine learning (ML) acceleration, offering ultra-fast speed, massive parallelism, and high energy efficiency. However, current photonic tensor core (PTC) designs based on standard optical components hinder scalability and compute density due to their large spatial footprint. To address this, we propose an ultra-compact PTC using customized programmable multi-operand multimode interference (MOMMI) devices, named M3ICRO. The programmable MOMMI leverages the intrinsic light propagation principle, providing a single-device programmable matrix unit beyond the conventional computing paradigm of one multiply-accumulate (MAC) operation per device. To overcome the optimization difficulty of customized devices that often requires time-consuming simulation, we apply ML for optics to predict the device behavior and enable a differentiable optimization flow. We thoroughly investigate the reconfigurability and matrix expressivity of our customized PTC, and introduce a novel block unfolding method to fully exploit the computing capabilities of a complex-valued PTC for near-universal real-valued linear transformations. Extensive evaluations demonstrate that M3ICRO achieves a 3.4-9.6x smaller footprint, 1.6-4.4x higher speed, 10.6-42x higher compute density, 3.7-12x higher system throughput, and superior noise robustness compared to state-of-the-art coherent PTC designs, while maintaining close-to-digital task accuracy across various ML benchmarks. Our code is open-sourced at https://github.com/JeremieMelo/M3ICRO-MOMMI.