 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine learning-based characterization of hydrochar from biomass: Implications for sustainable energy and material production
May 24, 2023
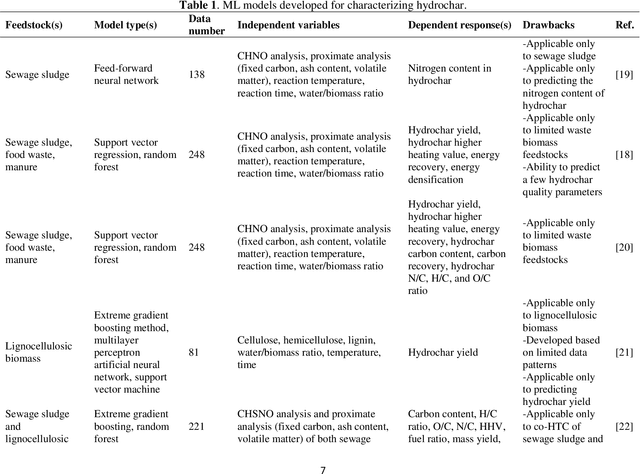
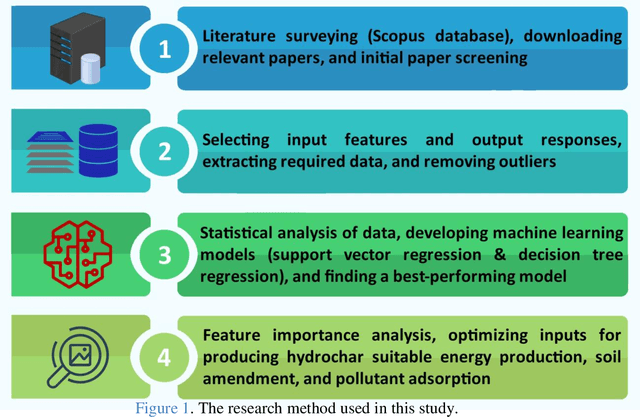
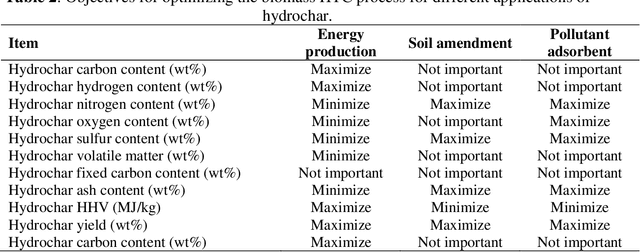
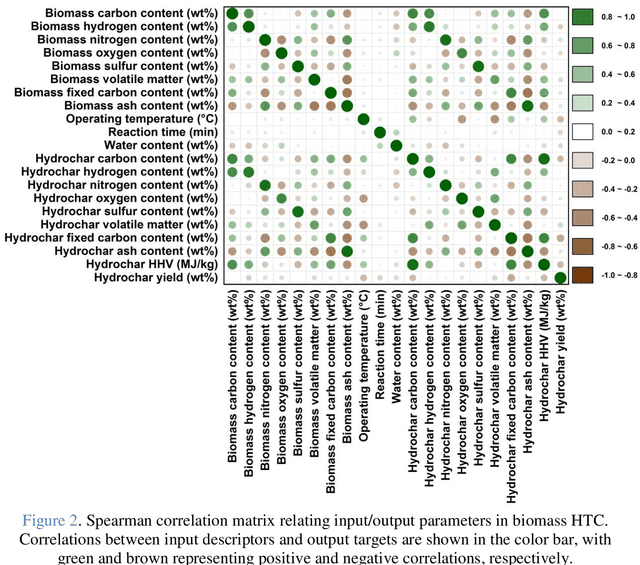
Hydrothermal carbonization (HTC) is a process that converts biomass into versatile hydrochar without the need for prior drying. The physicochemical properties of hydrochar are influenced by biomass properties and processing parameters, making it challenging to optimize for specific applications through trial-and-error experiments. To save time and money, machine learning can be used to develop a model that characterizes hydrochar produced from different biomass sources under varying reaction processing parameters. Thus, this study aims to develop an inclusive model to characterize hydrochar using a database covering a range of biomass types and reaction processing parameters. The quality and quantity of hydrochar are predicted using two models (decision tree regression and support vector regression). The decision tree regression model outperforms the support vector regression model in terms of forecast accuracy (R2 > 0.88, RMSE < 6.848, and MAE < 4.718). Using an evolutionary algorithm, optimum inputs are identified based on cost functions provided by the selected model to optimize hydrochar for energy production, soil amendment, and pollutant adsorption, resulting in hydrochar yields of 84.31%, 84.91%, and 80.40%, respectively. The feature importance analysis reveals that biomass ash/carbon content and operating temperature are the primary factors affecting hydrochar production in the HTC process.
Accelerating Convergence in Global Non-Convex Optimization with Reversible Diffusion
May 19, 2023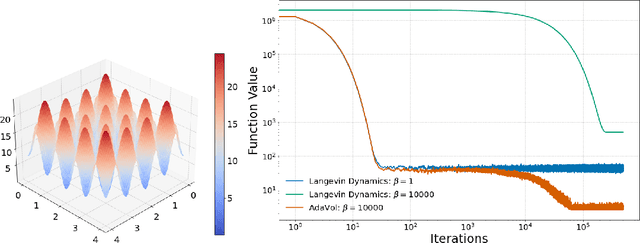
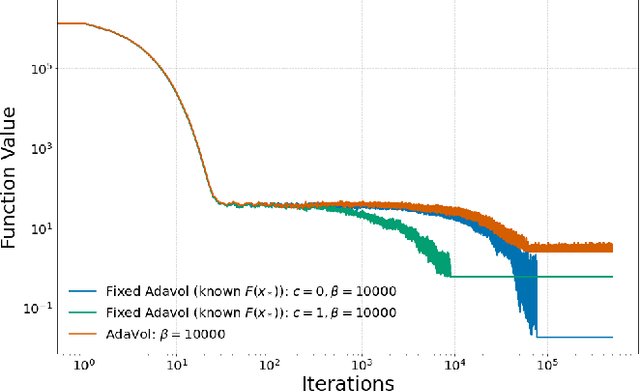
Langevin Dynamics has been extensively employed in global non-convex optimization due to the concentration of its stationary distribution around the global minimum of the potential function at low temperatures. In this paper, we propose to utilize a more comprehensive class of stochastic processes, known as reversible diffusion, and apply the Euler-Maruyama discretization for global non-convex optimization. We design the diffusion coefficient to be larger when distant from the optimum and smaller when near, thus enabling accelerated convergence while regulating discretization error, a strategy inspired by landscape modifications. Our proposed method can also be seen as a time change of Langevin Dynamics, and we prove convergence with respect to KL divergence, investigating the trade-off between convergence speed and discretization error. The efficacy of our proposed method is demonstrated through numerical experiments.
Analysis of Numerical Integration in RNN-Based Residuals for Fault Diagnosis of Dynamic Systems
May 08, 2023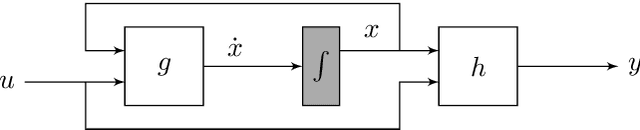

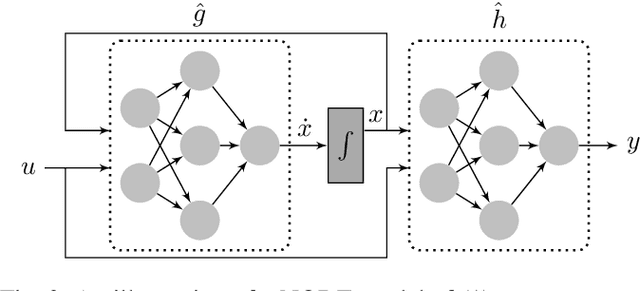
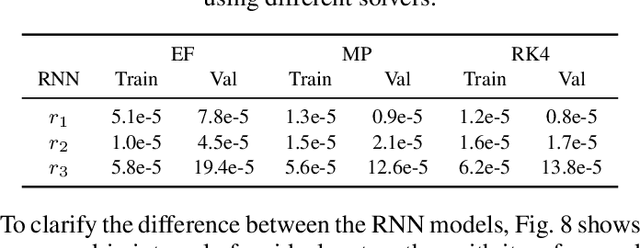
Data-driven modeling and machine learning are widely used to model the behavior of dynamic systems. One application is the residual evaluation of technical systems where model predictions are compared with measurement data to create residuals for fault diagnosis applications. While recurrent neural network models have been shown capable of modeling complex non-linear dynamic systems, they are limited to fixed steps discrete-time simulation. Modeling using neural ordinary differential equations, however, make it possible to evaluate the state variables at specific times, compute gradients when training the model and use standard numerical solvers to explicitly model the underlying dynamic of the time-series data. Here, the effect of solver selection on the performance of neural ordinary differential equation residuals during training and evaluation is investigated. The paper includes a case study of a heavy-duty truck's after-treatment system to highlight the potential of these techniques for improving fault diagnosis performance.
Active Collaborative Localization in Heterogeneous Robot Teams
May 29, 2023



Accurate and robust state estimation is critical for autonomous navigation of robot teams. This task is especially challenging for large groups of size, weight, and power (SWAP) constrained aerial robots operating in perceptually-degraded GPS-denied environments. We can, however, actively increase the amount of perceptual information available to such robots by augmenting them with a small number of more expensive, but less resource-constrained, agents. Specifically, the latter can serve as sources of perceptual information themselves. In this paper, we study the problem of optimally positioning (and potentially navigating) a small number of more capable agents to enhance the perceptual environment for their lightweight,inexpensive, teammates that only need to rely on cameras and IMUs. We propose a numerically robust, computationally efficient approach to solve this problem via nonlinear optimization. Our method outperforms the standard approach based on the greedy algorithm, while matching the accuracy of a heuristic evolutionary scheme for global optimization at a fraction of its running time. Ultimately, we validate our solution in both photorealistic simulations and real-world experiments. In these experiments, we use lidar-based autonomous ground vehicles as the more capable agents, and vision-based aerial robots as their SWAP-constrained teammates. Our method is able to reduce drift in visual-inertial odometry by as much as 90%, and it outperforms random positioning of lidar-equipped agents by a significant margin. Furthermore, our method can be generalized to different types of robot teams with heterogeneous perception capabilities. It has a wide range of applications, such as surveying and mapping challenging dynamic environments, and enabling resilience to large-scale perturbations that can be caused by earthquakes or storms.
Re-thinking Data Availablity Attacks Against Deep Neural Networks
May 18, 2023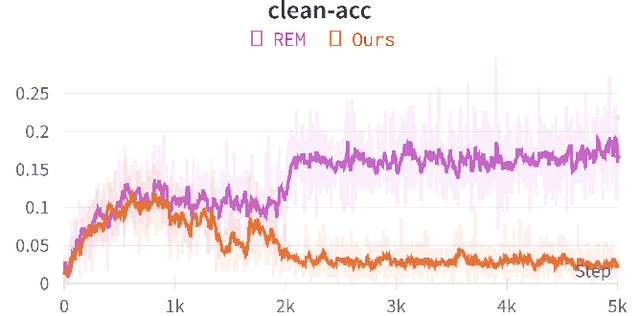
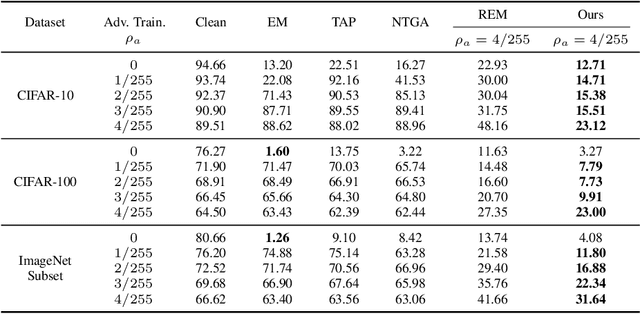
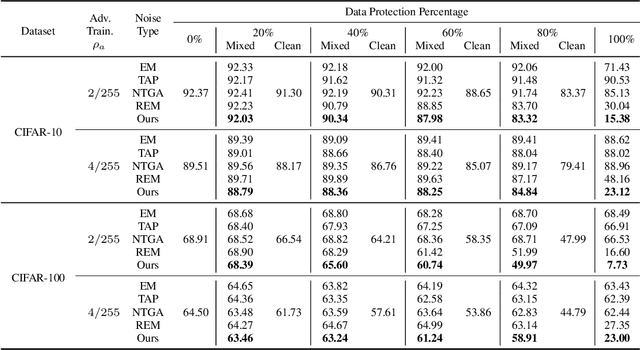
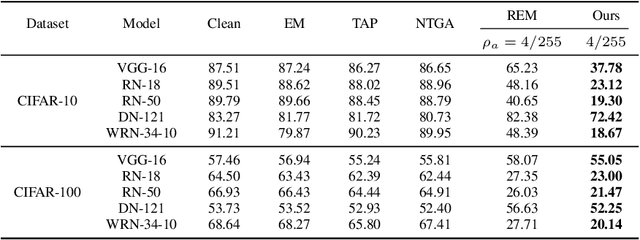
The unauthorized use of personal data for commercial purposes and the clandestine acquisition of private data for training machine learning models continue to raise concerns. In response to these issues, researchers have proposed availability attacks that aim to render data unexploitable. However, many current attack methods are rendered ineffective by adversarial training. In this paper, we re-examine the concept of unlearnable examples and discern that the existing robust error-minimizing noise presents an inaccurate optimization objective. Building on these observations, we introduce a novel optimization paradigm that yields improved protection results with reduced computational time requirements. We have conducted extensive experiments to substantiate the soundness of our approach. Moreover, our method establishes a robust foundation for future research in this area.
Validation of an ECAPA-TDNN system for Forensic Automatic Speaker Recognition under case work conditions
May 18, 2023
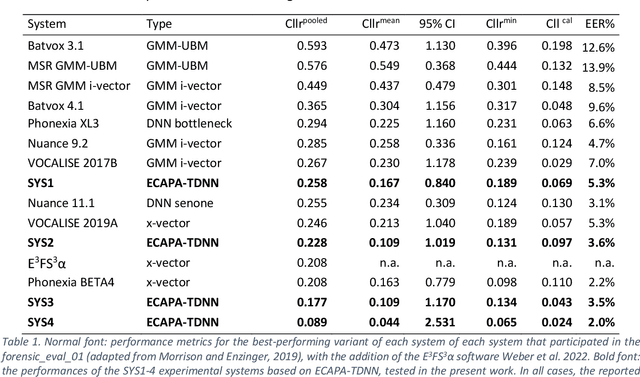
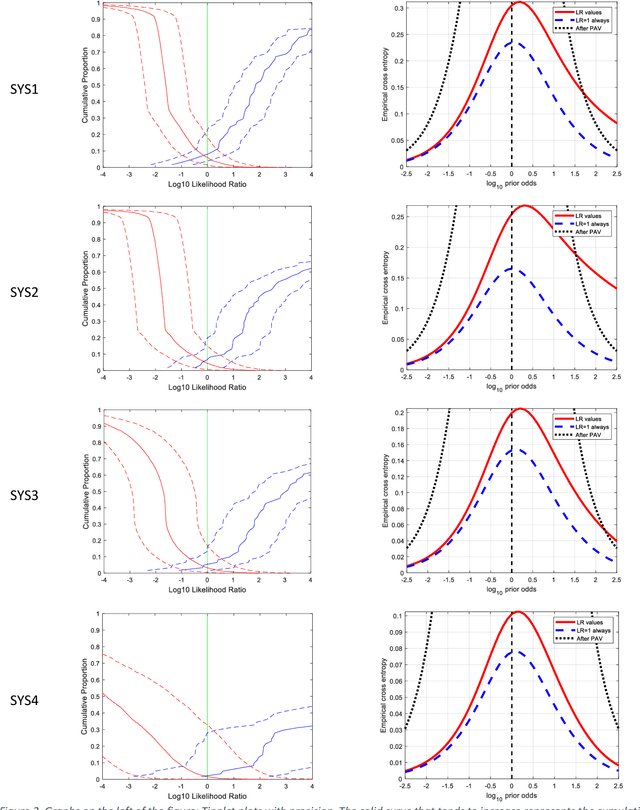
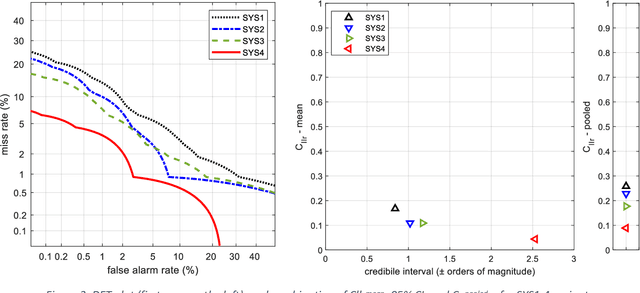
Different variants of a Forensic Automatic Speaker Recognition (FASR) system based on Emphasized Channel Attention, Propagation and Aggregation in Time Delay Neural Network (ECAPA-TDNN) are tested under conditions reflecting those of a real forensic voice comparison case, according to the forensic_eval_01 evaluation campaign settings. Using this recent neural model as an embedding extraction block, various normalization strategies at the level of embeddings and scores allow us to observe the variations in system performance, in terms of discriminating power, accuracy and precision metrics. From the achieved results it is possible to state that ECAPA-TDNN can be very successfully used as a base component of a FASR system, managing to surpass the previous state of the art, at least in the context of the considered operating conditions.
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
May 25, 2023
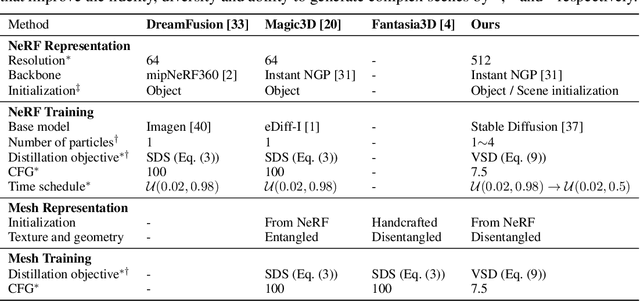
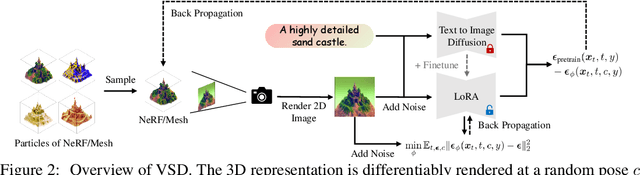

Score distillation sampling (SDS) has shown great promise in text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models, but suffers from over-saturation, over-smoothing, and low-diversity problems. In this work, we propose to model the 3D parameter as a random variable instead of a constant as in SDS and present variational score distillation (VSD), a principled particle-based variational framework to explain and address the aforementioned issues in text-to-3D generation. We show that SDS is a special case of VSD and leads to poor samples with both small and large CFG weights. In comparison, VSD works well with various CFG weights as ancestral sampling from diffusion models and simultaneously improves the diversity and sample quality with a common CFG weight (i.e., $7.5$). We further present various improvements in the design space for text-to-3D such as distillation time schedule and density initialization, which are orthogonal to the distillation algorithm yet not well explored. Our overall approach, dubbed ProlificDreamer, can generate high rendering resolution (i.e., $512\times512$) and high-fidelity NeRF with rich structure and complex effects (e.g., smoke and drops). Further, initialized from NeRF, meshes fine-tuned by VSD are meticulously detailed and photo-realistic. Project page: https://ml.cs.tsinghua.edu.cn/prolificdreamer/
Label Agnostic Pre-training for Zero-shot Text Classification
May 25, 2023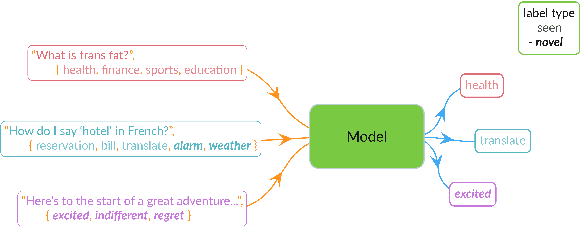
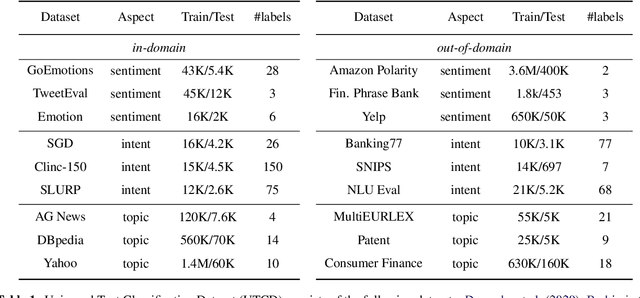
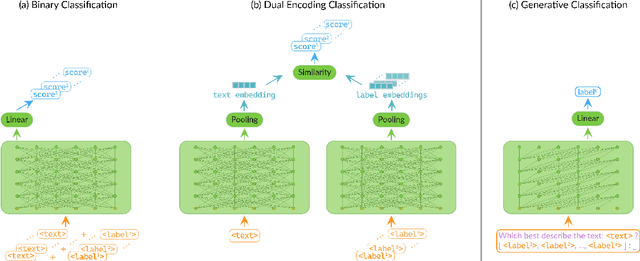
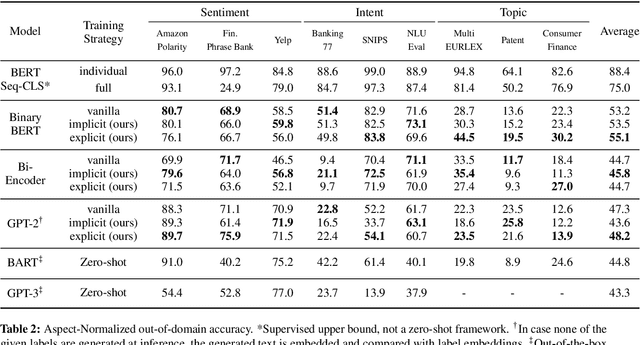
Conventional approaches to text classification typically assume the existence of a fixed set of predefined labels to which a given text can be classified. However, in real-world applications, there exists an infinite label space for describing a given text. In addition, depending on the aspect (sentiment, topic, etc.) and domain of the text (finance, legal, etc.), the interpretation of the label can vary greatly. This makes the task of text classification, particularly in the zero-shot scenario, extremely challenging. In this paper, we investigate the task of zero-shot text classification with the aim of improving the ability of pre-trained language models (PLMs) to generalize to both seen and unseen data across varying aspects and domains. To solve this we introduce two new simple yet effective pre-training strategies, Implicit and Explicit pre-training. These methods inject aspect-level understanding into the model at train time with the goal of conditioning the model to build task-level understanding. To evaluate this, we construct and release UTCD, a new benchmark dataset for evaluating text classification in zero-shot settings. Experimental results on UTCD show that our approach achieves improved zero-shot generalization on a suite of challenging datasets across an array of zero-shot formalizations.
Imitating Task and Motion Planning with Visuomotor Transformers
May 25, 2023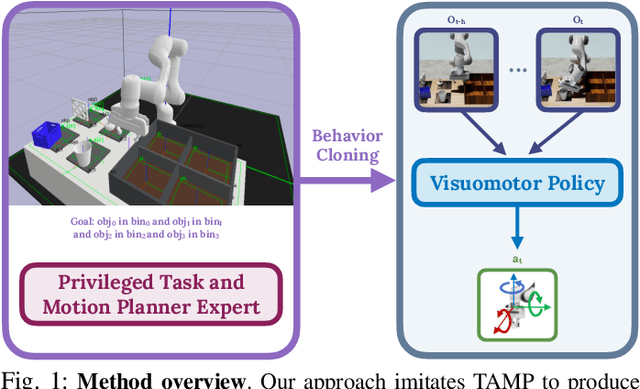

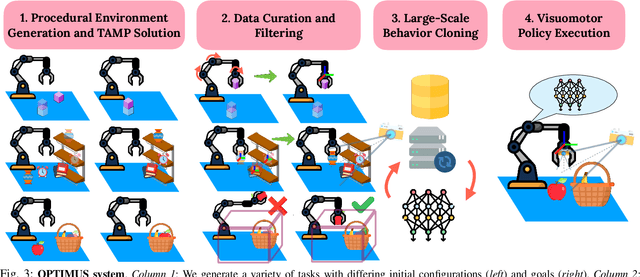
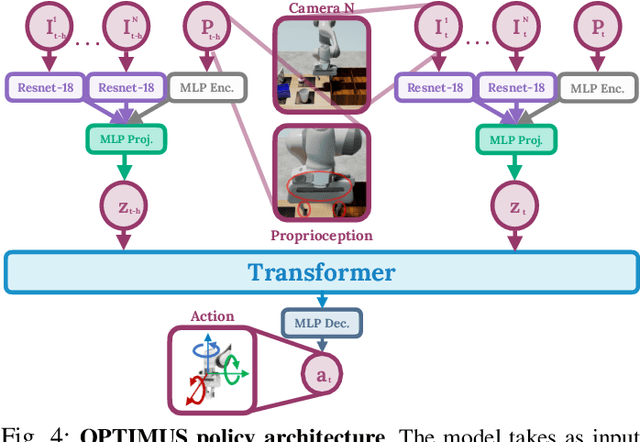
Imitation learning is a powerful tool for training robot manipulation policies, allowing them to learn from expert demonstrations without manual programming or trial-and-error. However, common methods of data collection, such as human supervision, scale poorly, as they are time-consuming and labor-intensive. In contrast, Task and Motion Planning (TAMP) can autonomously generate large-scale datasets of diverse demonstrations. In this work, we show that the combination of large-scale datasets generated by TAMP supervisors and flexible Transformer models to fit them is a powerful paradigm for robot manipulation. To that end, we present a novel imitation learning system called OPTIMUS that trains large-scale visuomotor Transformer policies by imitating a TAMP agent. OPTIMUS introduces a pipeline for generating TAMP data that is specifically curated for imitation learning and can be used to train performant transformer-based policies. In this paper, we present a thorough study of the design decisions required to imitate TAMP and demonstrate that OPTIMUS can solve a wide variety of challenging vision-based manipulation tasks with over 70 different objects, ranging from long-horizon pick-and-place tasks, to shelf and articulated object manipulation, achieving 70 to 80% success rates. Video results at https://mihdalal.github.io/optimus/
A Diagnosis Algorithms for a Rotary Indexing Machine
May 25, 2023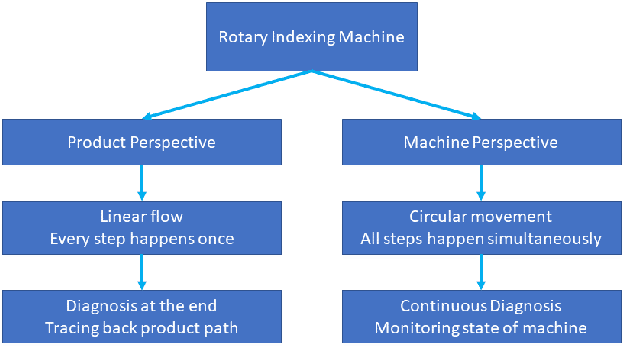
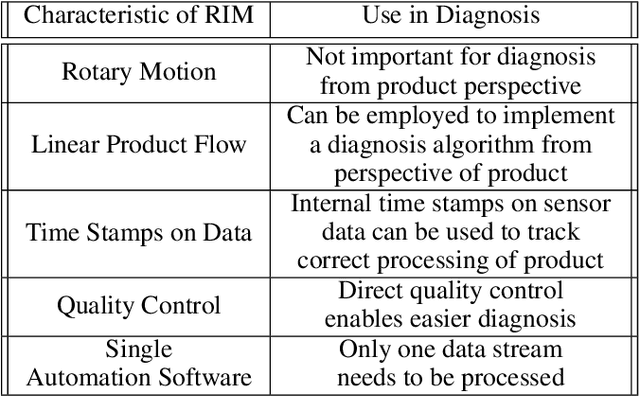

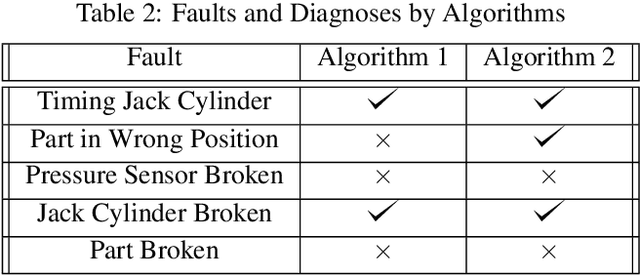
Rotary Indexing Machines (RIMs) are widely used in manufacturing due to their ability to perform multiple production steps on a single product without manual repositioning, reducing production time and improving accuracy and consistency. Despite their advantages, little research has been done on diagnosing faults in RIMs, especially from the perspective of the actual production steps carried out on these machines. Long downtimes due to failures are problematic, especially for smaller companies employing these machines. To address this gap, we propose a diagnosis algorithm based on the product perspective, which focuses on the product being processed by RIMs. The algorithm traces the steps that a product takes through the machine and is able to diagnose possible causes in case of failure. We also analyze the properties of RIMs and how these influence the diagnosis of faults in these machines. Our contributions are three-fold. Firstly, we provide an analysis of the properties of RIMs and how they influence the diagnosis of faults in these machines. Secondly, we suggest a diagnosis algorithm based on the product perspective capable of diagnosing faults in such a machine. Finally, we test this algorithm on a model of a rotary indexing machine, demonstrating its effectiveness in identifying faults and their root causes.