 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Supervised Gaussian Regularization of Deep Classifiers for Mahalanobis-Distance-Based Uncertainty Estimation
May 23, 2023
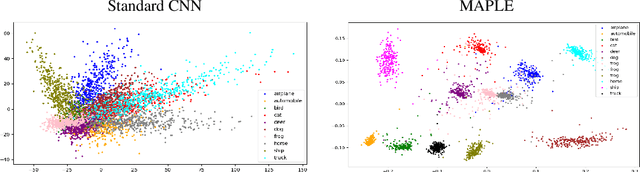
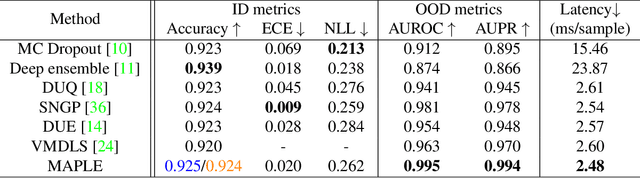
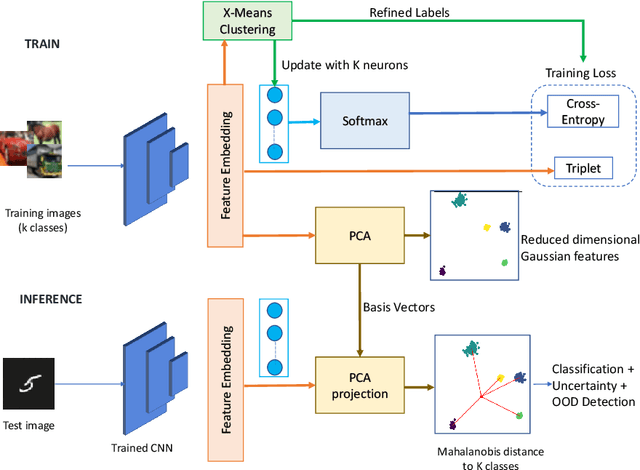
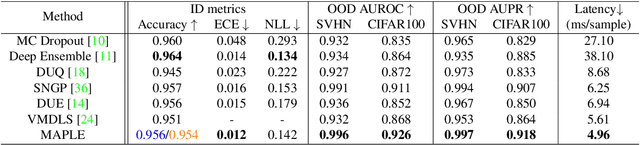
Recent works show that the data distribution in a network's latent space is useful for estimating classification uncertainty and detecting Out-of-distribution (OOD) samples. To obtain a well-regularized latent space that is conducive for uncertainty estimation, existing methods bring in significant changes to model architectures and training procedures. In this paper, we present a lightweight, fast, and high-performance regularization method for Mahalanobis distance-based uncertainty prediction, and that requires minimal changes to the network's architecture. To derive Gaussian latent representation favourable for Mahalanobis Distance calculation, we introduce a self-supervised representation learning method that separates in-class representations into multiple Gaussians. Classes with non-Gaussian representations are automatically identified and dynamically clustered into multiple new classes that are approximately Gaussian. Evaluation on standard OOD benchmarks shows that our method achieves state-of-the-art results on OOD detection with minimal inference time, and is very competitive on predictive probability calibration. Finally, we show the applicability of our method to a real-life computer vision use case on microorganism classification.
Backpropagation-Free 4D Continuous Ant-Based Neural Topology Search
May 11, 2023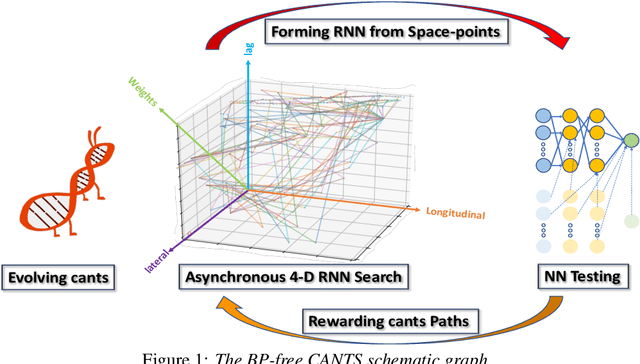
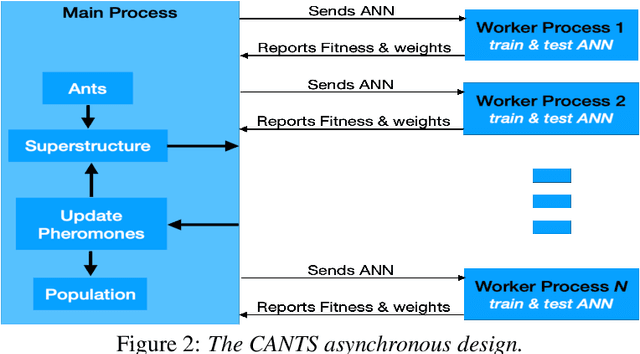
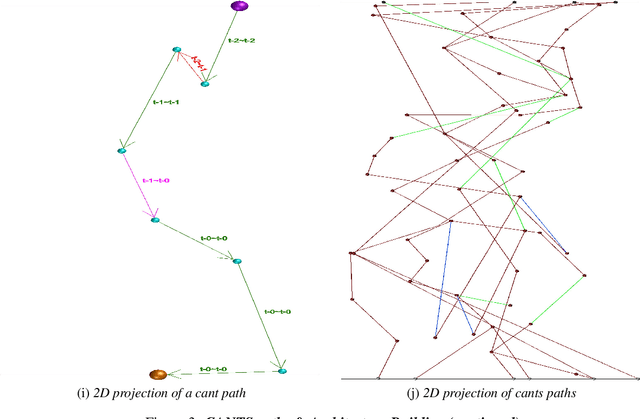

Continuous Ant-based Topology Search (CANTS) is a previously introduced novel nature-inspired neural architecture search (NAS) algorithm that is based on ant colony optimization (ACO). CANTS utilizes a continuous search space to indirectly-encode a neural architecture search space. Synthetic ant agents explore CANTS' continuous search space based on the density and distribution of pheromones, strongly inspired by how ants move in the real world. This continuous search space allows CANTS to automate the design of artificial neural networks (ANNs) of any size, removing a key limitation inherent to many current NAS algorithms that must operate within structures of a size that is predetermined by the user. This work expands CANTS by adding a fourth dimension to its search space representing potential neural synaptic weights. Adding this extra dimension allows CANTS agents to optimize both the architecture as well as the weights of an ANN without applying backpropagation (BP), which leads to a significant reduction in the time consumed in the optimization process. The experiments of this study - using real-world data - demonstrate that the BP-Free~CANTS algorithm exhibits highly competitive performance compared to both CANTS and ANTS while requiring significantly less operation time.
Distribution-Flexible Subset Quantization for Post-Quantizing Super-Resolution Networks
May 12, 2023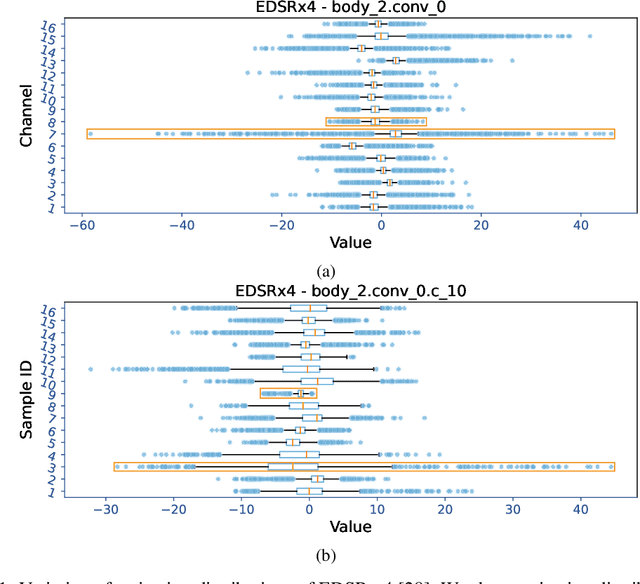
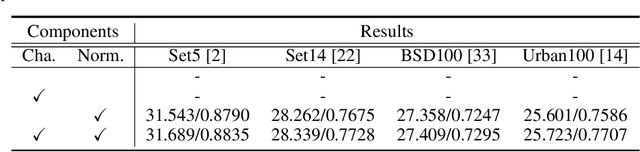
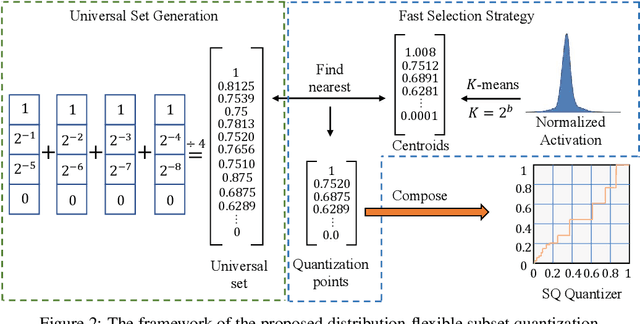
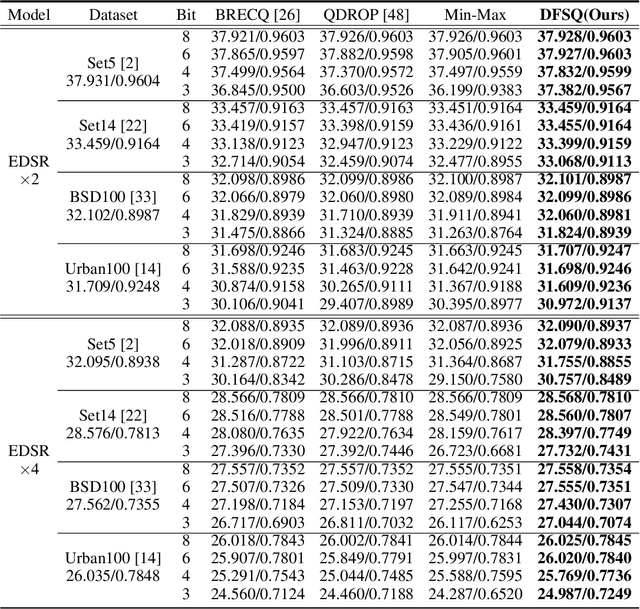
This paper introduces Distribution-Flexible Subset Quantization (DFSQ), a post-training quantization method for super-resolution networks. Our motivation for developing DFSQ is based on the distinctive activation distributions of current super-resolution models, which exhibit significant variance across samples and channels. To address this issue, DFSQ conducts channel-wise normalization of the activations and applies distribution-flexible subset quantization (SQ), wherein the quantization points are selected from a universal set consisting of multi-word additive log-scale values. To expedite the selection of quantization points in SQ, we propose a fast quantization points selection strategy that uses K-means clustering to select the quantization points closest to the centroids. Compared to the common iterative exhaustive search algorithm, our strategy avoids the enumeration of all possible combinations in the universal set, reducing the time complexity from exponential to linear. Consequently, the constraint of time costs on the size of the universal set is greatly relaxed. Extensive evaluations of various super-resolution models show that DFSQ effectively retains performance even without fine-tuning. For example, when quantizing EDSRx2 on the Urban benchmark, DFSQ achieves comparable performance to full-precision counterparts on 6- and 8-bit quantization, and incurs only a 0.1 dB PSNR drop on 4-bit quantization. Code is at \url{https://github.com/zysxmu/DFSQ}
One-step Bipartite Graph Cut: A Normalized Formulation and Its Application to Scalable Subspace Clustering
May 12, 2023
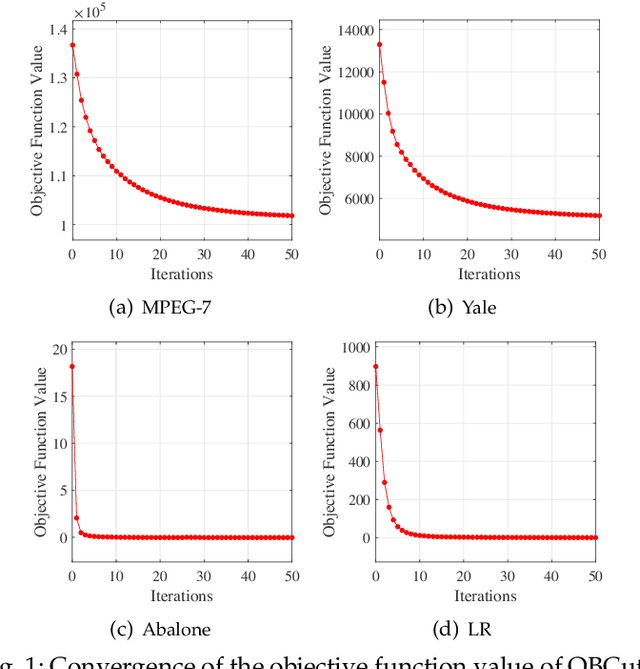
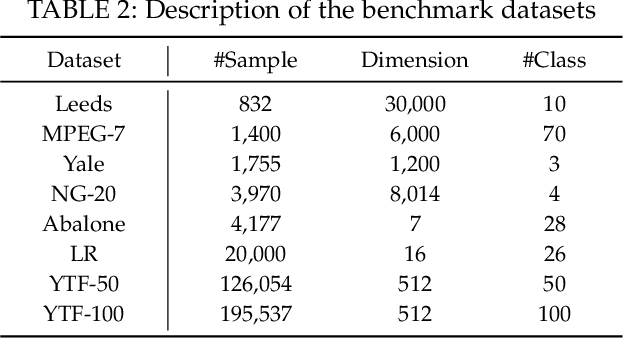
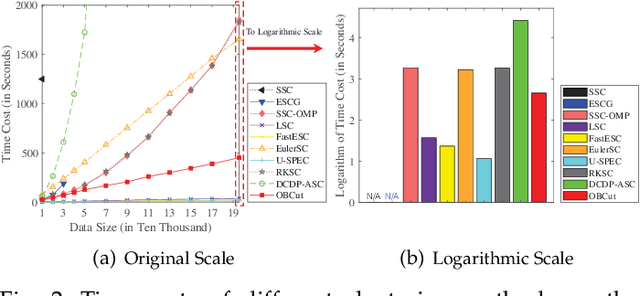
The bipartite graph structure has shown its promising ability in facilitating the subspace clustering and spectral clustering algorithms for large-scale datasets. To avoid the post-processing via k-means during the bipartite graph partitioning, the constrained Laplacian rank (CLR) is often utilized for constraining the number of connected components (i.e., clusters) in the bipartite graph, which, however, neglects the distribution (or normalization) of these connected components and may lead to imbalanced or even ill clusters. Despite the significant success of normalized cut (Ncut) in general graphs, it remains surprisingly an open problem how to enforce a one-step normalized cut for bipartite graphs, especially with linear-time complexity. In this paper, we first characterize a novel one-step bipartite graph cut (OBCut) criterion with normalized constraints, and theoretically prove its equivalence to a trace maximization problem. Then we extend this cut criterion to a scalable subspace clustering approach, where adaptive anchor learning, bipartite graph learning, and one-step normalized bipartite graph partitioning are simultaneously modeled in a unified objective function, and an alternating optimization algorithm is further designed to solve it in linear time. Experiments on a variety of general and large-scale datasets demonstrate the effectiveness and scalability of our approach.
Accelerating Convergence in Global Non-Convex Optimization with Reversible Diffusion
May 19, 2023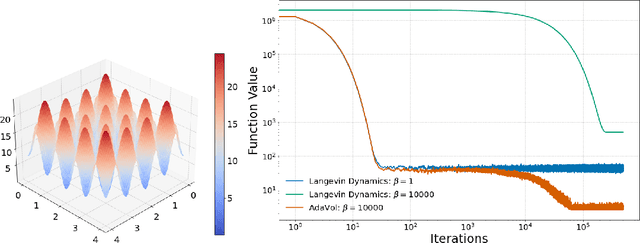
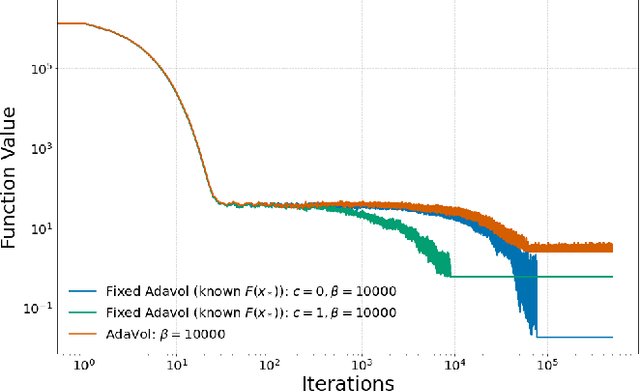
Langevin Dynamics has been extensively employed in global non-convex optimization due to the concentration of its stationary distribution around the global minimum of the potential function at low temperatures. In this paper, we propose to utilize a more comprehensive class of stochastic processes, known as reversible diffusion, and apply the Euler-Maruyama discretization for global non-convex optimization. We design the diffusion coefficient to be larger when distant from the optimum and smaller when near, thus enabling accelerated convergence while regulating discretization error, a strategy inspired by landscape modifications. Our proposed method can also be seen as a time change of Langevin Dynamics, and we prove convergence with respect to KL divergence, investigating the trade-off between convergence speed and discretization error. The efficacy of our proposed method is demonstrated through numerical experiments.
Jointly Optimizing Image Compression with Low-light Image Enhancement
May 24, 2023
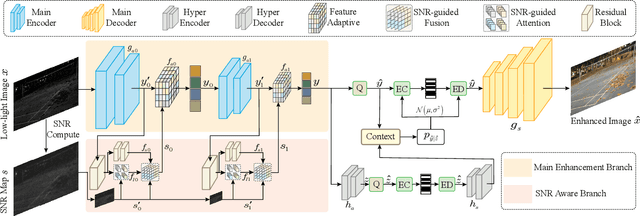
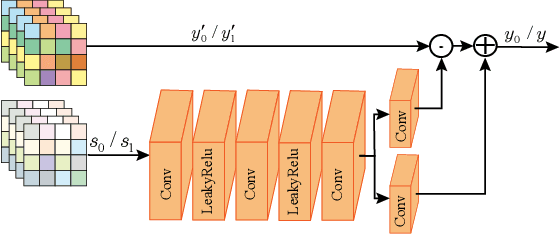
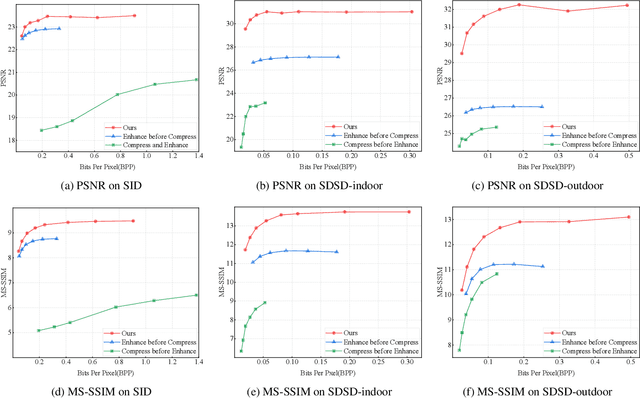
Learning-based image compression methods have made great progress. Most of them are designed for generic natural images. In fact, low-light images frequently occur due to unavoidable environmental influences or technical limitations, such as insufficient lighting or limited exposure time. %When general-purpose image compression algorithms compress low-light images, useful detail information is lost, resulting in a dramatic decrease in image enhancement. Once low-light images are compressed by existing general image compression approaches, useful information(e.g., texture details) would be lost resulting in a dramatic performance decrease in low-light image enhancement. To simultaneously achieve a higher compression rate and better enhancement performance for low-light images, we propose a novel image compression framework with joint optimization of low-light image enhancement. We design an end-to-end trainable two-branch architecture with lower computational cost, which includes the main enhancement branch and the signal-to-noise ratio~(SNR) aware branch. Experimental results show that our proposed joint optimization framework achieves a significant improvement over existing ``Compress before Enhance" or ``Enhance before Compress" sequential solutions for low-light images. Source codes are included in the supplementary material.
Massively Scalable Inverse Reinforcement Learning in Google Maps
May 24, 2023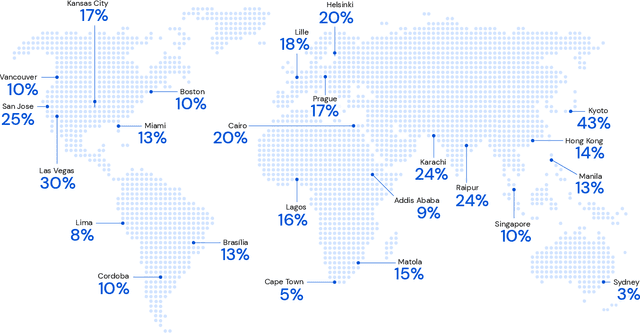
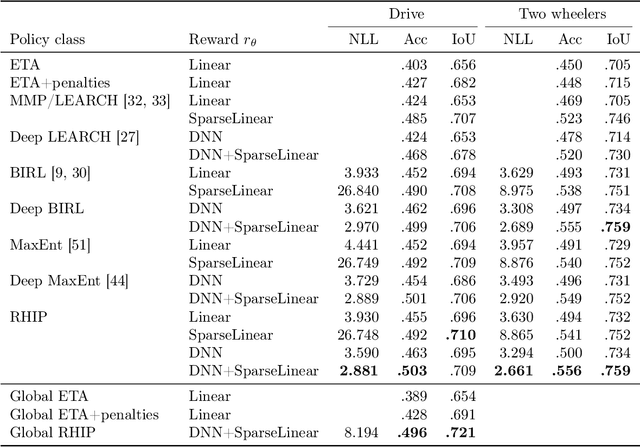
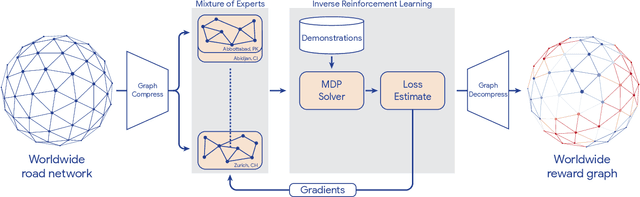
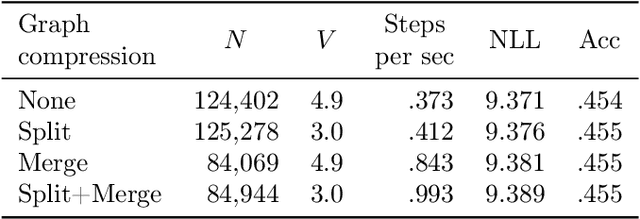
Optimizing for humans' latent preferences is a grand challenge in route recommendation, where globally-scalable solutions remain an open problem. Although past work created increasingly general solutions for the application of inverse reinforcement learning (IRL), these have not been successfully scaled to world-sized MDPs, large datasets, and highly parameterized models; respectively hundreds of millions of states, trajectories, and parameters. In this work, we surpass previous limitations through a series of advancements focused on graph compression, parallelization, and problem initialization based on dominant eigenvectors. We introduce Receding Horizon Inverse Planning (RHIP), which generalizes existing work and enables control of key performance trade-offs via its planning horizon. Our policy achieves a 16-24% improvement in global route quality, and, to our knowledge, represents the largest instance of IRL in a real-world setting to date. Our results show critical benefits to more sustainable modes of transportation (e.g. two-wheelers), where factors beyond journey time (e.g. route safety) play a substantial role. We conclude with ablations of key components, negative results on state-of-the-art eigenvalue solvers, and identify future opportunities to improve scalability via IRL-specific batching strategies.
Adaptive Chameleon or Stubborn Sloth: Unraveling the Behavior of Large Language Models in Knowledge Clashes
May 24, 2023
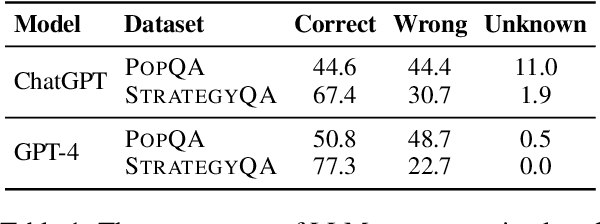
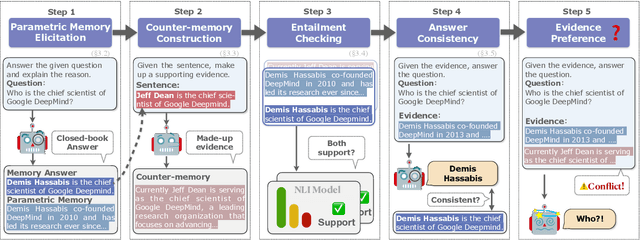
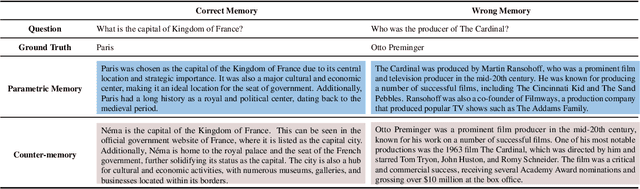
By providing external information to large language models (LLMs), tool augmentation (including retrieval augmentation) has emerged as a promising solution for addressing the limitations of LLMs' static parametric memory. However, how receptive are LLMs to such external evidence, especially when the evidence conflicts with their parametric memory? We present the first comprehensive and controlled investigation into the behavior of LLMs when encountering knowledge conflicts. We propose a systematic framework to elicit high-quality parametric memory from LLMs and construct the corresponding counter-memory, which enables us to conduct a series of controlled experiments. Our investigation reveals seemingly contradicting behaviors of LLMs. On the one hand, different from prior wisdom, we find that LLMs can be highly receptive to external evidence even when that conflicts with their parametric memory, given that the external evidence is coherent and convincing. On the other hand, LLMs also demonstrate a strong confirmation bias when the external evidence contains some information that is consistent with their parametric memory, despite being presented with conflicting evidence at the same time. These results pose important implications that are worth careful consideration for the further development and deployment of tool- and retrieval-augmented LLMs.
Machine learning-based characterization of hydrochar from biomass: Implications for sustainable energy and material production
May 24, 2023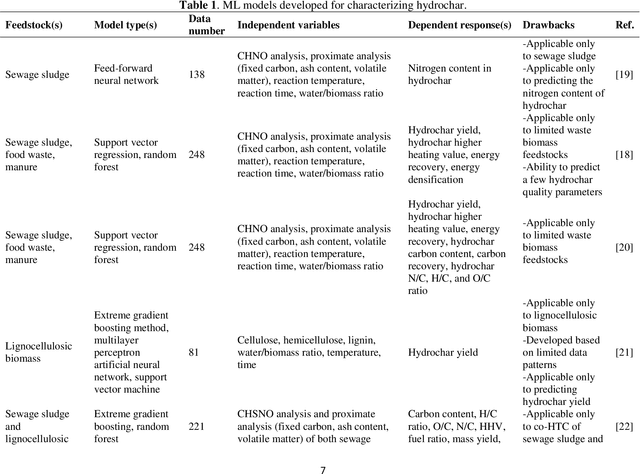
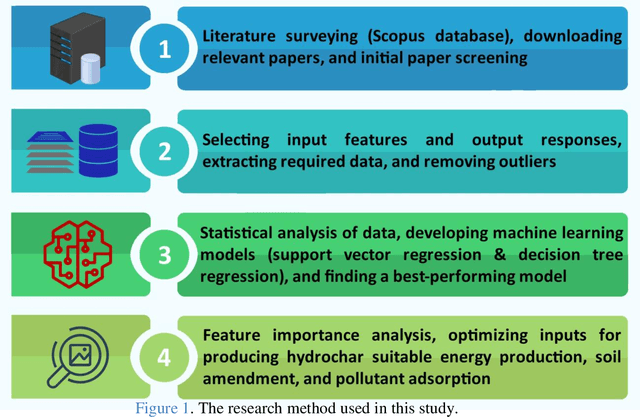
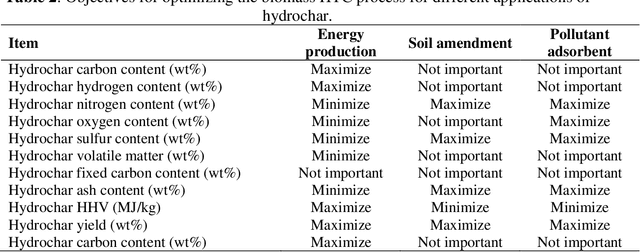
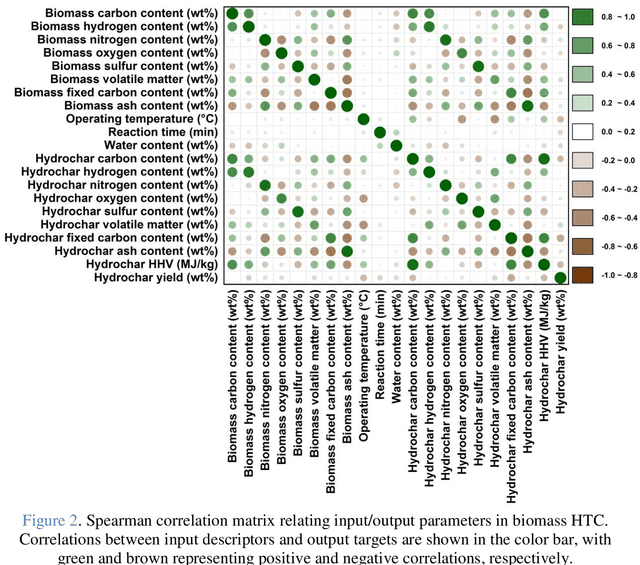
Hydrothermal carbonization (HTC) is a process that converts biomass into versatile hydrochar without the need for prior drying. The physicochemical properties of hydrochar are influenced by biomass properties and processing parameters, making it challenging to optimize for specific applications through trial-and-error experiments. To save time and money, machine learning can be used to develop a model that characterizes hydrochar produced from different biomass sources under varying reaction processing parameters. Thus, this study aims to develop an inclusive model to characterize hydrochar using a database covering a range of biomass types and reaction processing parameters. The quality and quantity of hydrochar are predicted using two models (decision tree regression and support vector regression). The decision tree regression model outperforms the support vector regression model in terms of forecast accuracy (R2 > 0.88, RMSE < 6.848, and MAE < 4.718). Using an evolutionary algorithm, optimum inputs are identified based on cost functions provided by the selected model to optimize hydrochar for energy production, soil amendment, and pollutant adsorption, resulting in hydrochar yields of 84.31%, 84.91%, and 80.40%, respectively. The feature importance analysis reveals that biomass ash/carbon content and operating temperature are the primary factors affecting hydrochar production in the HTC process.
Localizing Multiple Radiation Sources Actively with a Particle Filter
May 24, 2023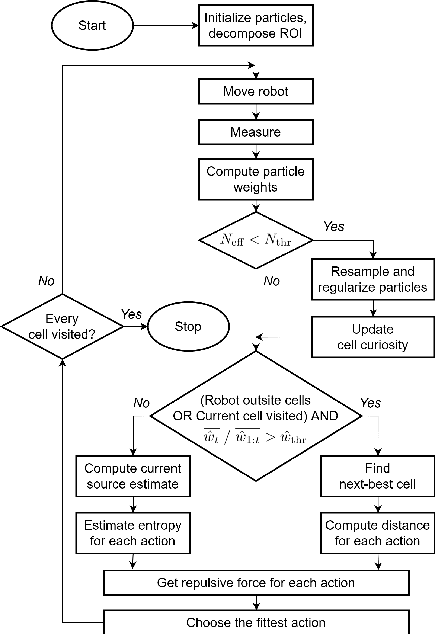
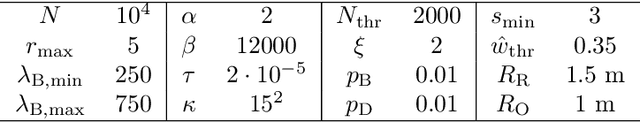
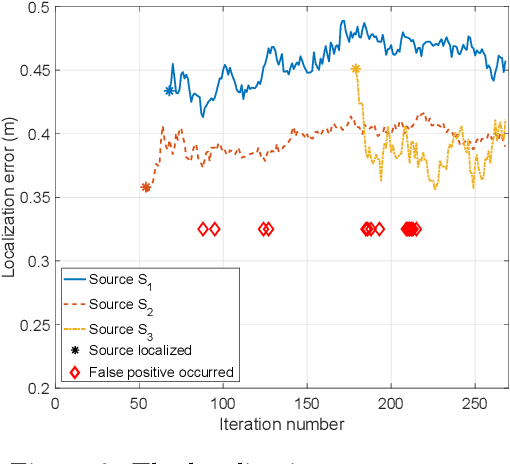
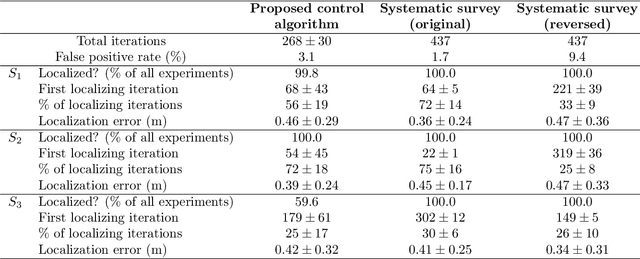
The article discusses the localization of radiation sources whose number and other relevant parameters are not known in advance. The data collection is ensured by an autonomous mobile robot that performs a survey in a defined region of interest populated with static obstacles. The measurement trajectory is information-driven rather than pre-planned. The localization exploits a regularized particle filter estimating the sources' parameters continuously. The dynamic robot control switches between two modes, one attempting to minimize the Shannon entropy and the other aiming to reduce the variance of expected measurements in unexplored parts of the target area; both of the modes maintain safe clearance from the obstacles. The performance of the algorithms was tested in a simulation study based on real-world data acquired previously from three radiation sources exhibiting various activities. Our approach reduces the time necessary to explore the region and to find the sources by approximately 40 %; at present, however, the method is unable to reliably localize sources that have a relatively low intensity. In this context, additional research has been planned to increase the credibility and robustness of the procedure and to improve the robotic platform autonomy.