 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pessimistic Causal Reinforcement Learning with Mediators for Confounded Offline Data
Mar 18, 2024
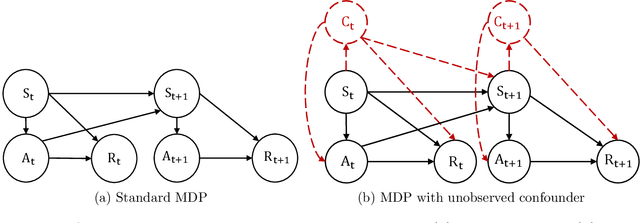
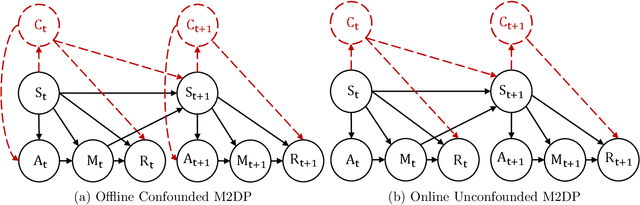
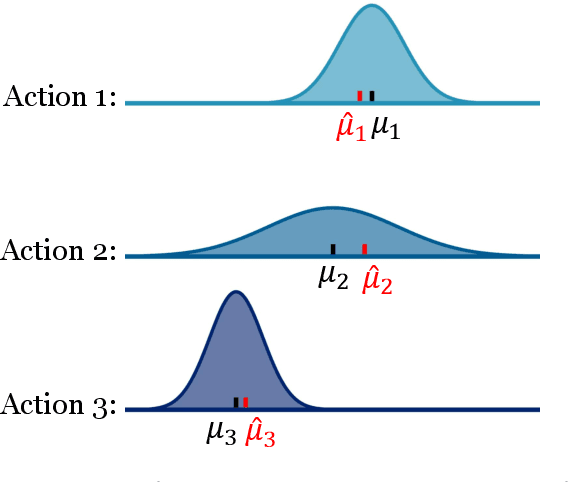
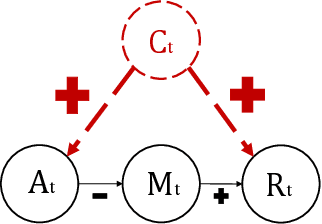
In real-world scenarios, datasets collected from randomized experiments are often constrained by size, due to limitations in time and budget. As a result, leveraging large observational datasets becomes a more attractive option for achieving high-quality policy learning. However, most existing offline reinforcement learning (RL) methods depend on two key assumptions--unconfoundedness and positivity--which frequently do not hold in observational data contexts. Recognizing these challenges, we propose a novel policy learning algorithm, PESsimistic CAusal Learning (PESCAL). We utilize the mediator variable based on front-door criterion to remove the confounding bias; additionally, we adopt the pessimistic principle to address the distributional shift between the action distributions induced by candidate policies, and the behavior policy that generates the observational data. Our key observation is that, by incorporating auxiliary variables that mediate the effect of actions on system dynamics, it is sufficient to learn a lower bound of the mediator distribution function, instead of the Q-function, to partially mitigate the issue of distributional shift. This insight significantly simplifies our algorithm, by circumventing the challenging task of sequential uncertainty quantification for the estimated Q-function. Moreover, we provide theoretical guarantees for the algorithms we propose, and demonstrate their efficacy through simulations, as well as real-world experiments utilizing offline datasets from a leading ride-hailing platform.
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Mar 18, 2024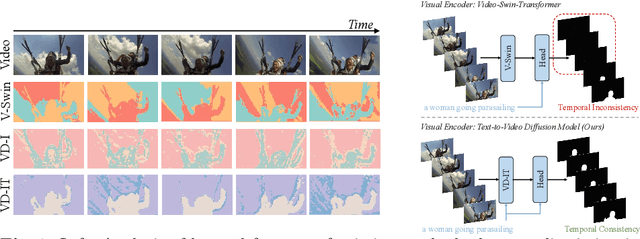
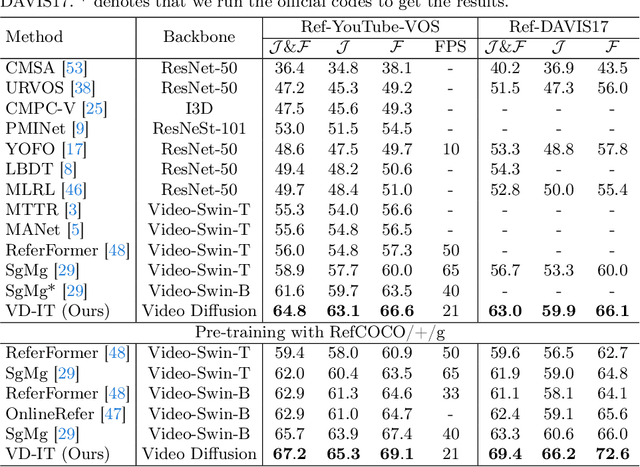
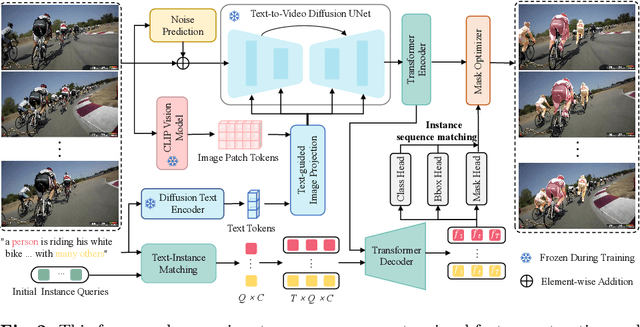
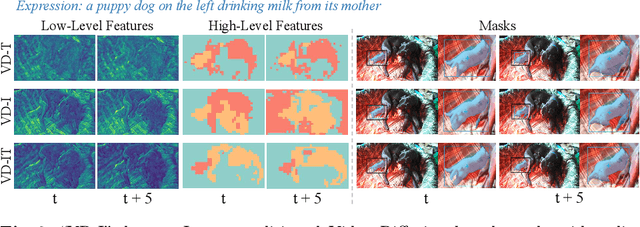
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed ``VD-IT'', tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks.Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code will be available at \url{https://github.com/buxiangzhiren/VD-IT}
Edge Computing Enabled Real-Time Video Analysis via Adaptive Spatial-Temporal Semantic Filtering
Feb 29, 2024This paper proposes a novel edge computing enabled real-time video analysis system for intelligent visual devices. The proposed system consists of a tracking-assisted object detection module (TAODM) and a region of interesting module (ROIM). TAODM adaptively determines the offloading decision to process each video frame locally with a tracking algorithm or to offload it to the edge server inferred by an object detection model. ROIM determines each offloading frame's resolution and detection model configuration to ensure that the analysis results can return in time. TAODM and ROIM interact jointly to filter the repetitive spatial-temporal semantic information to maximize the processing rate while ensuring high video analysis accuracy. Unlike most existing works, this paper investigates the real-time video analysis systems where the intelligent visual device connects to the edge server through a wireless network with fluctuating network conditions. We decompose the real-time video analysis problem into the offloading decision and configurations selection sub-problems. To solve these two sub-problems, we introduce a double deep Q network (DDQN) based offloading approach and a contextual multi-armed bandit (CMAB) based adaptive configurations selection approach, respectively. A DDQN-CMAB reinforcement learning (DCRL) training framework is further developed to integrate these two approaches to improve the overall video analyzing performance. Extensive simulations are conducted to evaluate the performance of the proposed solution, and demonstrate its superiority over counterparts.
K-Link: Knowledge-Link Graph from LLMs for Enhanced Representation Learning in Multivariate Time-Series Data
Mar 06, 2024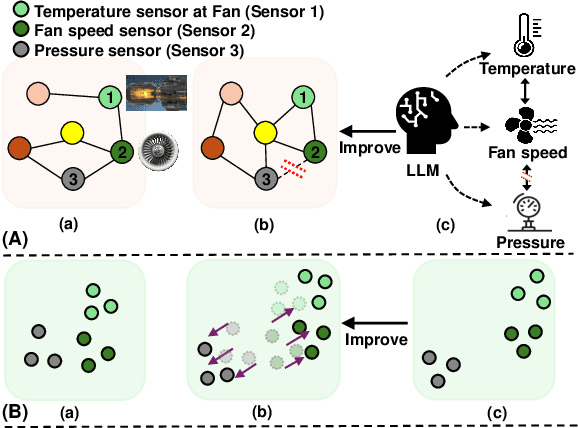
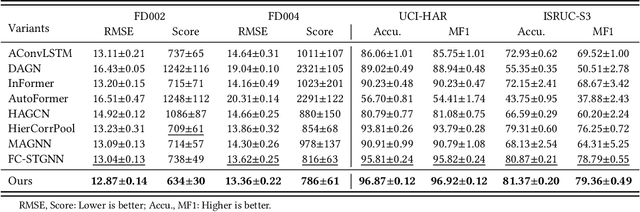
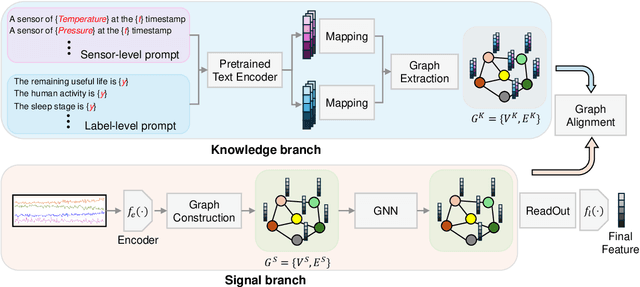
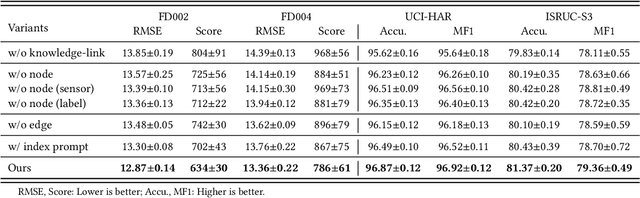
Sourced from various sensors and organized chronologically, Multivariate Time-Series (MTS) data involves crucial spatial-temporal dependencies, e.g., correlations among sensors. To capture these dependencies, Graph Neural Networks (GNNs) have emerged as powerful tools, yet their effectiveness is restricted by the quality of graph construction from MTS data. Typically, existing approaches construct graphs solely from MTS signals, which may introduce bias due to a small training dataset and may not accurately represent underlying dependencies. To address this challenge, we propose a novel framework named K-Link, leveraging Large Language Models (LLMs) to encode extensive general knowledge and thereby providing effective solutions to reduce the bias. Leveraging the knowledge embedded in LLMs, such as physical principles, we extract a \textit{Knowledge-Link graph}, capturing vast semantic knowledge of sensors and the linkage of the sensor-level knowledge. To harness the potential of the knowledge-link graph in enhancing the graph derived from MTS data, we propose a graph alignment module, facilitating the transfer of semantic knowledge within the knowledge-link graph into the MTS-derived graph. By doing so, we can improve the graph quality, ensuring effective representation learning with GNNs for MTS data. Extensive experiments demonstrate the efficacy of our approach for superior performance across various MTS-related downstream tasks.
Refining Knowledge Transfer on Audio-Image Temporal Agreement for Audio-Text Cross Retrieval
Mar 16, 2024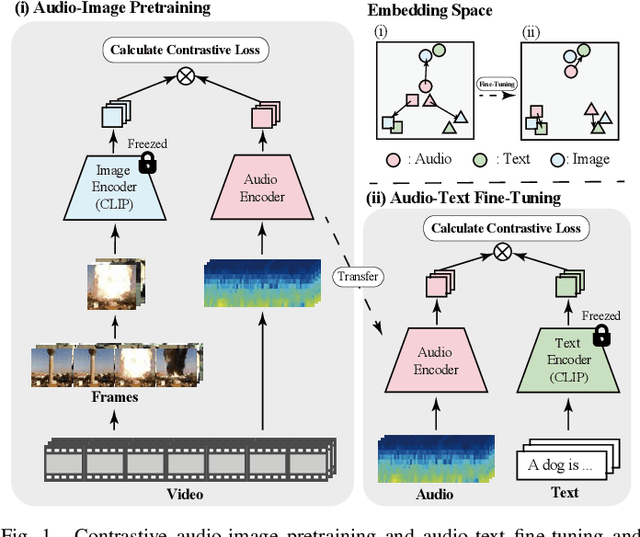
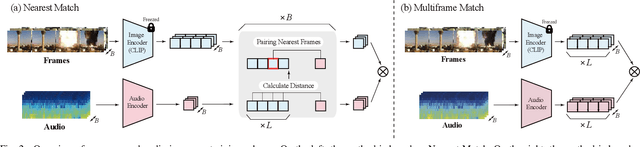
The aim of this research is to refine knowledge transfer on audio-image temporal agreement for audio-text cross retrieval. To address the limited availability of paired non-speech audio-text data, learning methods for transferring the knowledge acquired from a large amount of paired audio-image data to shared audio-text representation have been investigated, suggesting the importance of how audio-image co-occurrence is learned. Conventional approaches in audio-image learning assign a single image randomly selected from the corresponding video stream to the entire audio clip, assuming their co-occurrence. However, this method may not accurately capture the temporal agreement between the target audio and image because a single image can only represent a snapshot of a scene, though the target audio changes from moment to moment. To address this problem, we propose two methods for audio and image matching that effectively capture the temporal information: (i) Nearest Match wherein an image is selected from multiple time frames based on similarity with audio, and (ii) Multiframe Match wherein audio and image pairs of multiple time frames are used. Experimental results show that method (i) improves the audio-text retrieval performance by selecting the nearest image that aligns with the audio information and transferring the learned knowledge. Conversely, method (ii) improves the performance of audio-image retrieval while not showing significant improvements in audio-text retrieval performance. These results indicate that refining audio-image temporal agreement may contribute to better knowledge transfer to audio-text retrieval.
Iterative Forgetting: Online Data Stream Regression Using Database-Inspired Adaptive Granulation
Mar 14, 2024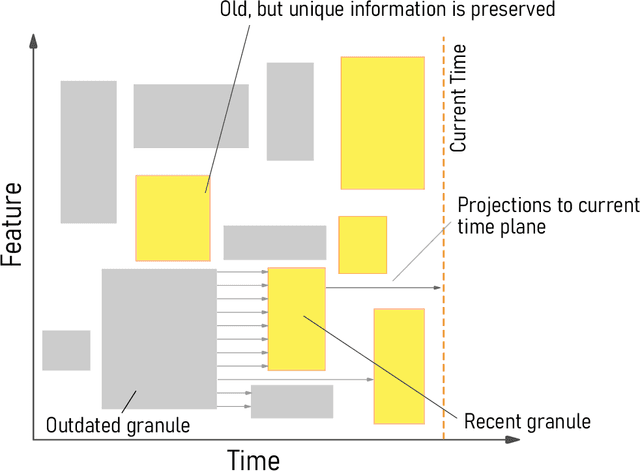
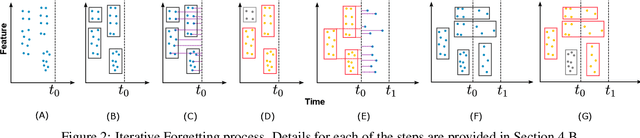
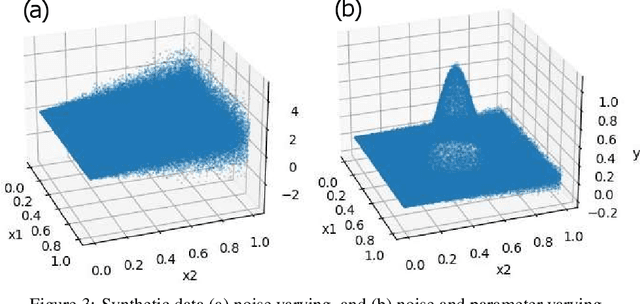
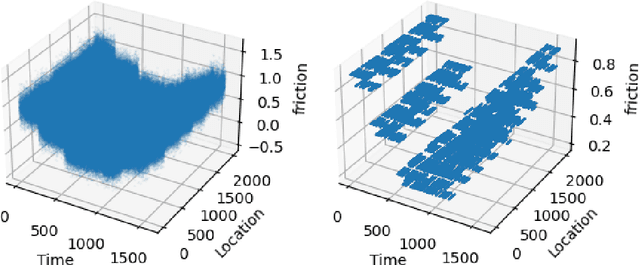
Many modern systems, such as financial, transportation, and telecommunications systems, are time-sensitive in the sense that they demand low-latency predictions for real-time decision-making. Such systems often have to contend with continuous unbounded data streams as well as concept drift, which are challenging requirements that traditional regression techniques are unable to cater to. There exists a need to create novel data stream regression methods that can handle these scenarios. We present a database-inspired datastream regression model that (a) uses inspiration from R*-trees to create granules from incoming datastreams such that relevant information is retained, (b) iteratively forgets granules whose information is deemed to be outdated, thus maintaining a list of only recent, relevant granules, and (c) uses the recent data and granules to provide low-latency predictions. The R*-tree-inspired approach also makes the algorithm amenable to integration with database systems. Our experiments demonstrate that the ability of this method to discard data produces a significant order-of-magnitude improvement in latency and training time when evaluated against the most accurate state-of-the-art algorithms, while the R*-tree-inspired granulation technique provides competitively accurate predictions
SketchINR: A First Look into Sketches as Implicit Neural Representations
Mar 14, 2024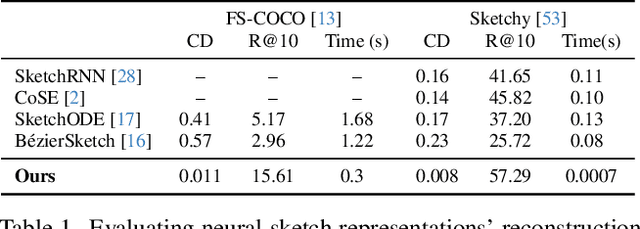
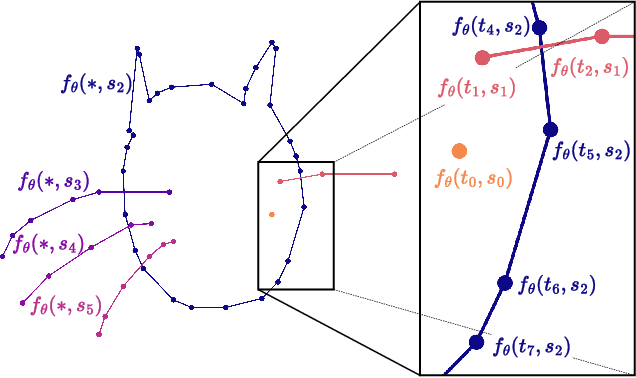
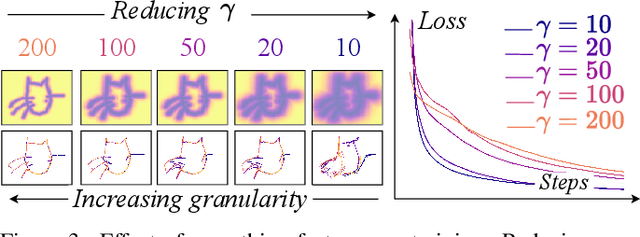
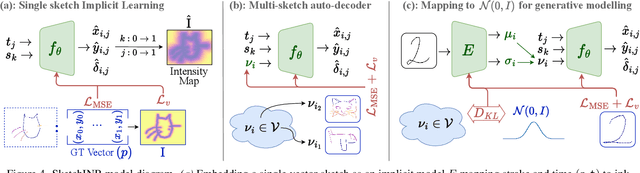
We propose SketchINR, to advance the representation of vector sketches with implicit neural models. A variable length vector sketch is compressed into a latent space of fixed dimension that implicitly encodes the underlying shape as a function of time and strokes. The learned function predicts the $xy$ point coordinates in a sketch at each time and stroke. Despite its simplicity, SketchINR outperforms existing representations at multiple tasks: (i) Encoding an entire sketch dataset into a fixed size latent vector, SketchINR gives $60\times$ and $10\times$ data compression over raster and vector sketches, respectively. (ii) SketchINR's auto-decoder provides a much higher-fidelity representation than other learned vector sketch representations, and is uniquely able to scale to complex vector sketches such as FS-COCO. (iii) SketchINR supports parallelisation that can decode/render $\sim$$100\times$ faster than other learned vector representations such as SketchRNN. (iv) SketchINR, for the first time, emulates the human ability to reproduce a sketch with varying abstraction in terms of number and complexity of strokes. As a first look at implicit sketches, SketchINR's compact high-fidelity representation will support future work in modelling long and complex sketches.
DyRoNet: A Low-Rank Adapter Enhanced Dynamic Routing Network for Streaming Perception
Mar 15, 2024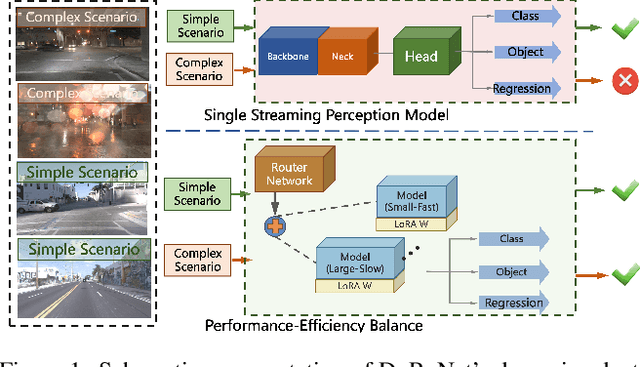
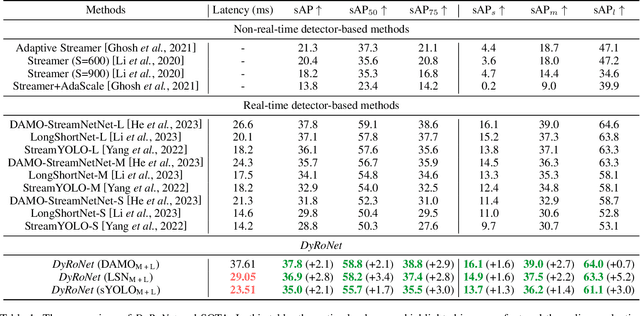
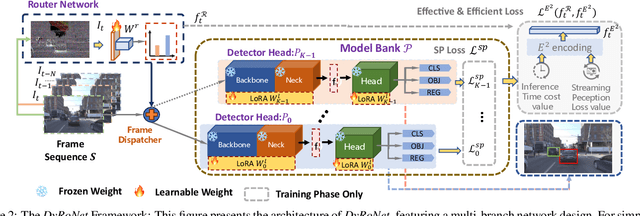
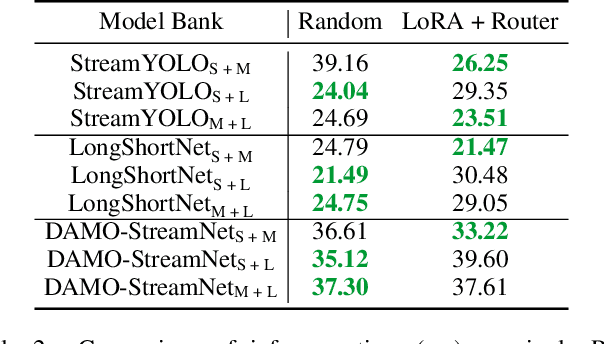
The quest for real-time, accurate environmental perception is pivotal in the evolution of autonomous driving technologies. In response to this challenge, we present DyRoNet, a Dynamic Router Network that innovates by incorporating low-rank dynamic routing to enhance streaming perception. DyRoNet distinguishes itself by seamlessly integrating a diverse array of specialized pre-trained branch networks, each meticulously fine-tuned for specific environmental contingencies, thus facilitating an optimal balance between response latency and detection precision. Central to DyRoNet's architecture is the Speed Router module, which employs an intelligent routing mechanism to dynamically allocate input data to the most suitable branch network, thereby ensuring enhanced performance adaptability in real-time scenarios. Through comprehensive evaluations, DyRoNet demonstrates superior adaptability and significantly improved performance over existing methods, efficiently catering to a wide variety of environmental conditions and setting new benchmarks in streaming perception accuracy and efficiency. Beyond establishing a paradigm in autonomous driving perception, DyRoNet also offers engineering insights and lays a foundational framework for future advancements in streaming perception. For further information and updates on the project, visit https://tastevision.github.io/DyRoNet/.
Texture-GS: Disentangling the Geometry and Texture for 3D Gaussian Splatting Editing
Mar 15, 2024
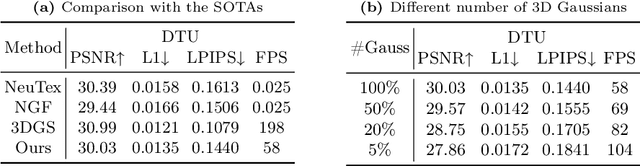
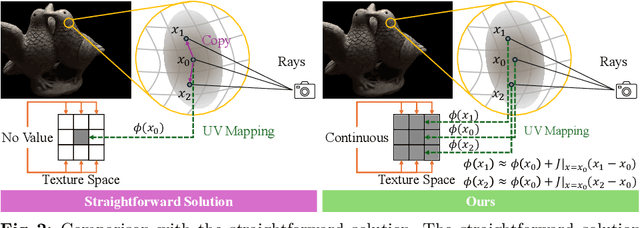
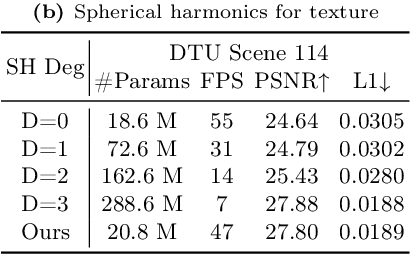
3D Gaussian splatting, emerging as a groundbreaking approach, has drawn increasing attention for its capabilities of high-fidelity reconstruction and real-time rendering. However, it couples the appearance and geometry of the scene within the Gaussian attributes, which hinders the flexibility of editing operations, such as texture swapping. To address this issue, we propose a novel approach, namely Texture-GS, to disentangle the appearance from the geometry by representing it as a 2D texture mapped onto the 3D surface, thereby facilitating appearance editing. Technically, the disentanglement is achieved by our proposed texture mapping module, which consists of a UV mapping MLP to learn the UV coordinates for the 3D Gaussian centers, a local Taylor expansion of the MLP to efficiently approximate the UV coordinates for the ray-Gaussian intersections, and a learnable texture to capture the fine-grained appearance. Extensive experiments on the DTU dataset demonstrate that our method not only facilitates high-fidelity appearance editing but also achieves real-time rendering on consumer-level devices, e.g. a single RTX 2080 Ti GPU.
Redundancy Transmission in UAV-Aided LoRa Networks Featuring Wake-Up Radios
Mar 14, 2024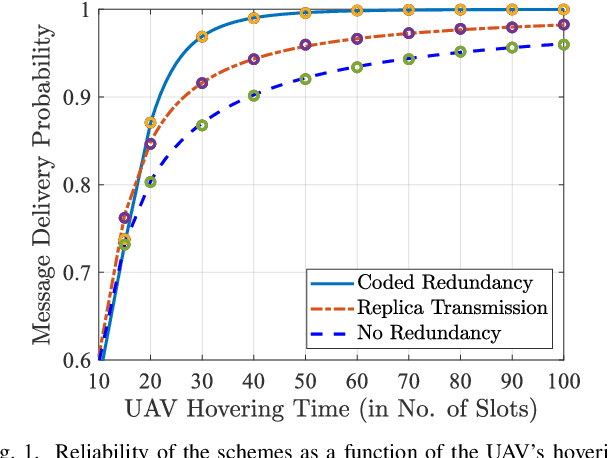
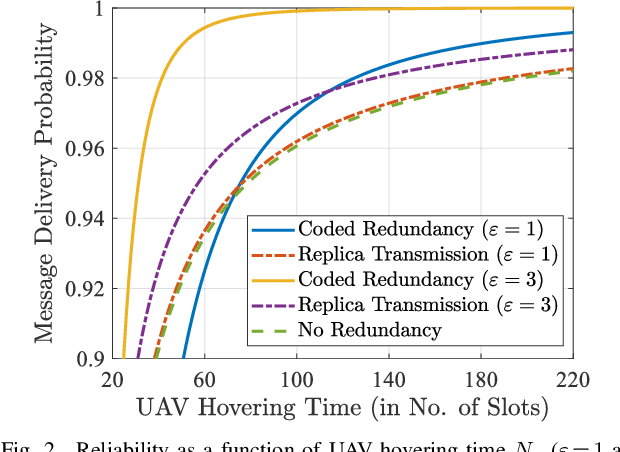
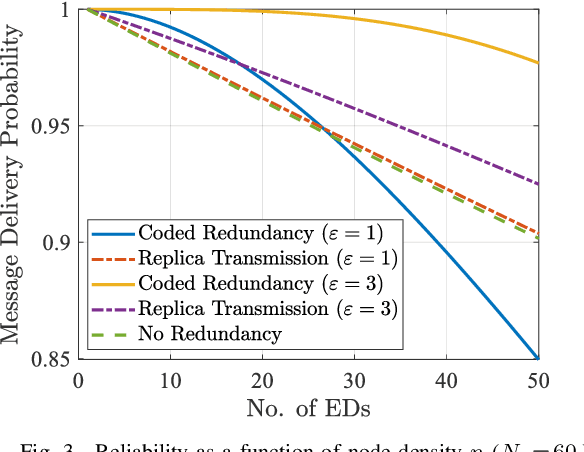

We consider a LoRa sensor network featuring a UAV-mounted gateway for collecting sensor data (messages). Wake-up radios (WuR) are employed to inform the sensors of the UAV's arrival. Building on an existing random access scheme for such setups, we propose and evaluate two redundancy transmission protocols for enhancing the reliability of the data transfer. One protocol employs fountain-coded transmissions, whereas the other performs message replication. Our results illustrate how redundancy transmission can be beneficial under the time constraints imposed by the UAV's limited hovering duration, and how node density, hovering time, and sensor energy budget impact the performance of the schemes.