 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Directed Chain Generative Adversarial Networks
Apr 25, 2023
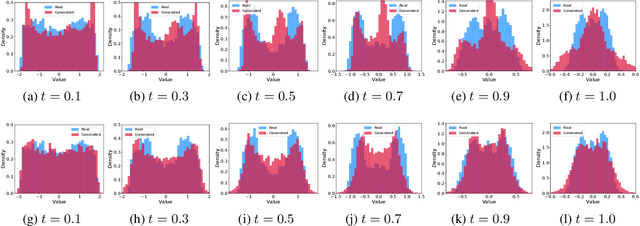
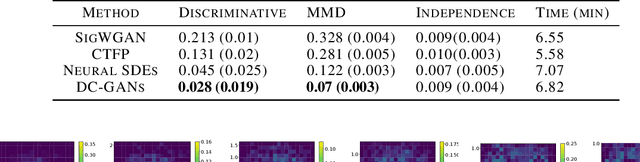
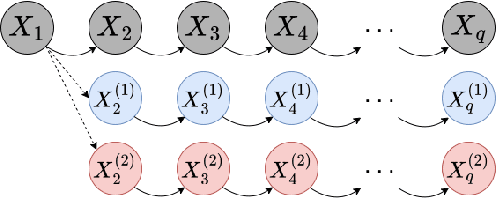

Real-world data can be multimodal distributed, e.g., data describing the opinion divergence in a community, the interspike interval distribution of neurons, and the oscillators natural frequencies. Generating multimodal distributed real-world data has become a challenge to existing generative adversarial networks (GANs). For example, neural stochastic differential equations (Neural SDEs), treated as infinite-dimensional GANs, have demonstrated successful performance mainly in generating unimodal time series data. In this paper, we propose a novel time series generator, named directed chain GANs (DC-GANs), which inserts a time series dataset (called a neighborhood process of the directed chain or input) into the drift and diffusion coefficients of the directed chain SDEs with distributional constraints. DC-GANs can generate new time series of the same distribution as the neighborhood process, and the neighborhood process will provide the key step in learning and generating multimodal distributed time series. The proposed DC-GANs are examined on four datasets, including two stochastic models from social sciences and computational neuroscience, and two real-world datasets on stock prices and energy consumption. To our best knowledge, DC-GANs are the first work that can generate multimodal time series data and consistently outperforms state-of-the-art benchmarks with respect to measures of distribution, data similarity, and predictive ability.
A Hierarchical Approach to Population Training for Human-AI Collaboration
May 26, 2023
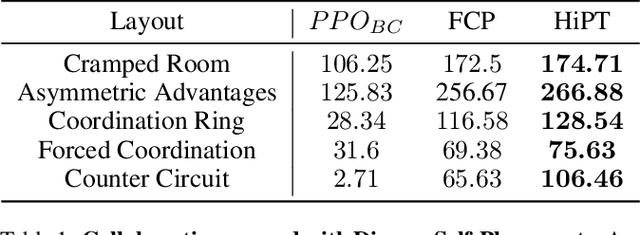
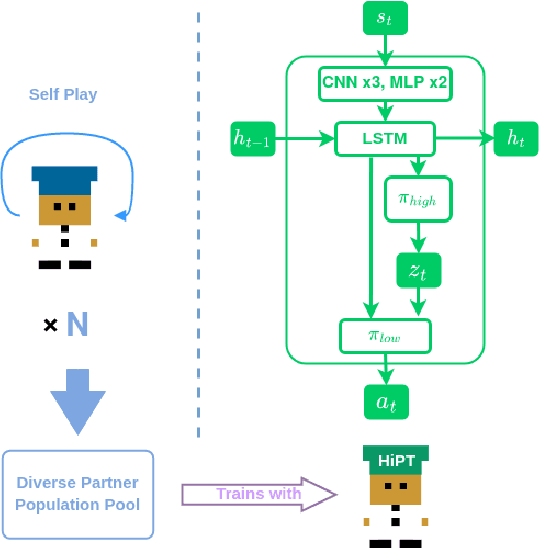

A major challenge for deep reinforcement learning (DRL) agents is to collaborate with novel partners that were not encountered by them during the training phase. This is specifically worsened by an increased variance in action responses when the DRL agents collaborate with human partners due to the lack of consistency in human behaviors. Recent work have shown that training a single agent as the best response to a diverse population of training partners significantly increases an agent's robustness to novel partners. We further enhance the population-based training approach by introducing a Hierarchical Reinforcement Learning (HRL) based method for Human-AI Collaboration. Our agent is able to learn multiple best-response policies as its low-level policy while at the same time, it learns a high-level policy that acts as a manager which allows the agent to dynamically switch between the low-level best-response policies based on its current partner. We demonstrate that our method is able to dynamically adapt to novel partners of different play styles and skill levels in the 2-player collaborative Overcooked game environment. We also conducted a human study in the same environment to test the effectiveness of our method when partnering with real human subjects.
DiffusionNAG: Task-guided Neural Architecture Generation with Diffusion Models
May 26, 2023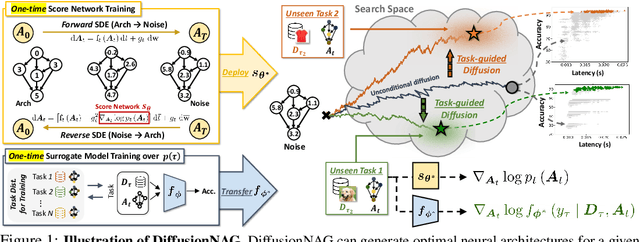
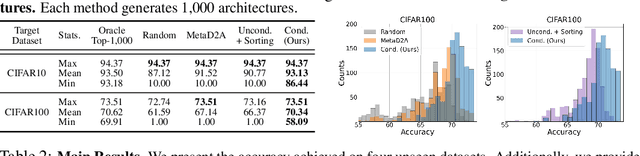
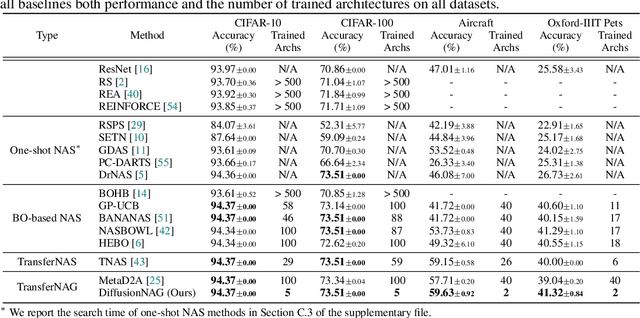

Neural Architecture Search (NAS) has emerged as a powerful technique for automating neural architecture design. However, existing NAS methods either require an excessive amount of time for repetitive training or sampling of many task-irrelevant architectures. Moreover, they lack generalization across different tasks and usually require searching for optimal architectures for each task from scratch without reusing the knowledge from the previous NAS tasks. To tackle such limitations of existing NAS methods, we propose a novel transferable task-guided Neural Architecture Generation (NAG) framework based on diffusion models, dubbed DiffusionNAG. With the guidance of a surrogate model, such as a performance predictor for a given task, our DiffusionNAG can generate task-optimal architectures for diverse tasks, including unseen tasks. DiffusionNAG is highly efficient as it generates task-optimal neural architectures by leveraging the prior knowledge obtained from the previous tasks and neural architecture distribution. Furthermore, we introduce a score network to ensure the generation of valid architectures represented as directed acyclic graphs, unlike existing graph generative models that focus on generating undirected graphs. Extensive experiments demonstrate that DiffusionNAG significantly outperforms the state-of-the-art transferable NAG model in architecture generation quality, as well as previous NAS methods on four computer vision datasets with largely reduced computational cost.
Comparative Study of Pre-Trained BERT Models for Code-Mixed Hindi-English Data
May 26, 2023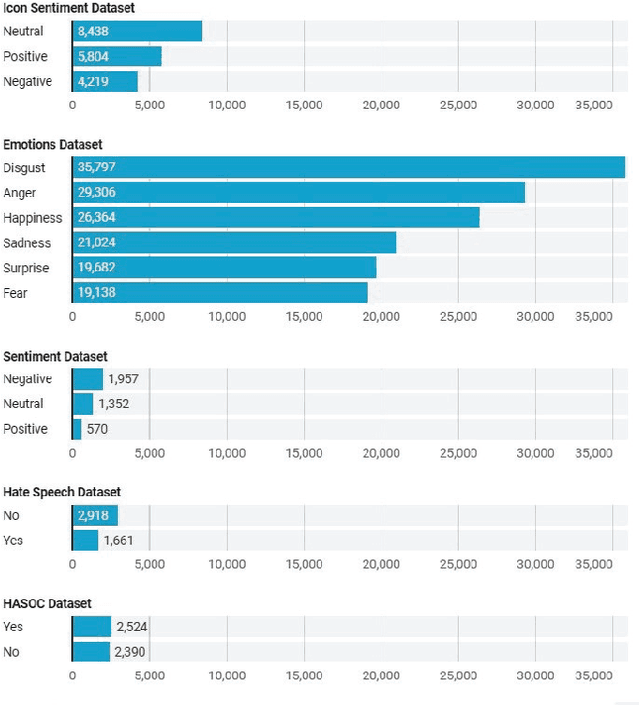
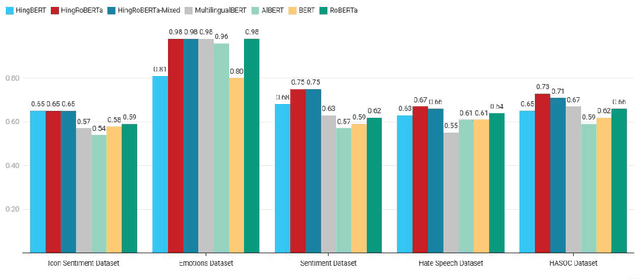
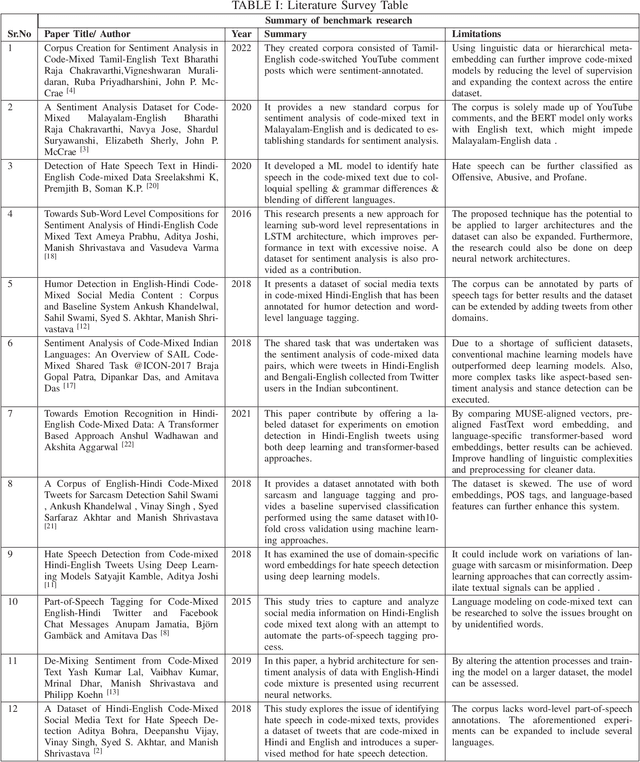
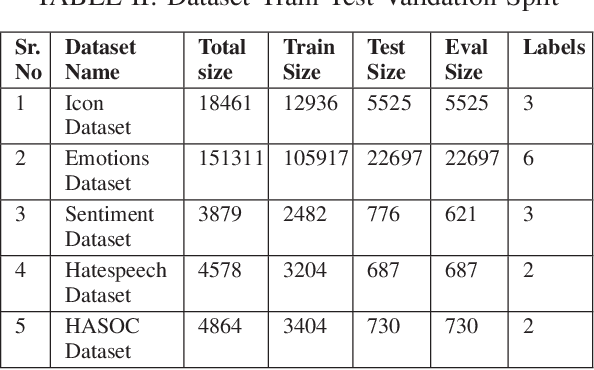
The term "Code Mixed" refers to the use of more than one language in the same text. This phenomenon is predominantly observed on social media platforms, with an increasing amount of adaptation as time goes on. It is critical to detect foreign elements in a language and process them correctly, as a considerable number of individuals are using code-mixed languages that could not be comprehended by understanding one of those languages. In this work, we focus on low-resource Hindi-English code-mixed language and enhancing the performance of different code-mixed natural language processing tasks such as sentiment analysis, emotion recognition, and hate speech identification. We perform a comparative analysis of different Transformer-based language Models pre-trained using unsupervised approaches. We have included the code-mixed models like HingBERT, HingRoBERTa, HingRoBERTa-Mixed, mBERT, and non-code-mixed models like AlBERT, BERT, and RoBERTa for comparative analysis of code-mixed Hindi-English downstream tasks. We report state-of-the-art results on respective datasets using HingBERT-based models which are specifically pre-trained on real code-mixed text. Our HingBERT-based models provide significant improvements thus highlighting the poor performance of vanilla BERT models on code-mixed text.
ElectrodeNet -- A Deep Learning Based Sound Coding Strategy for Cochlear Implants
May 26, 2023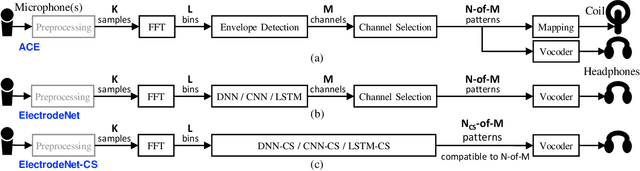
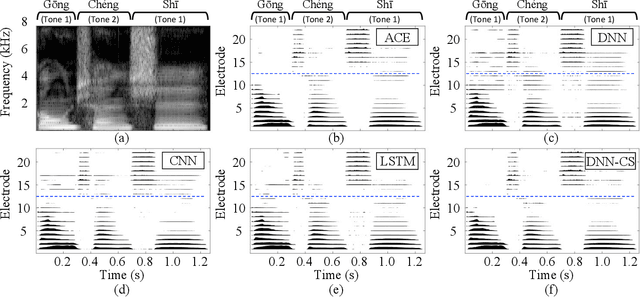
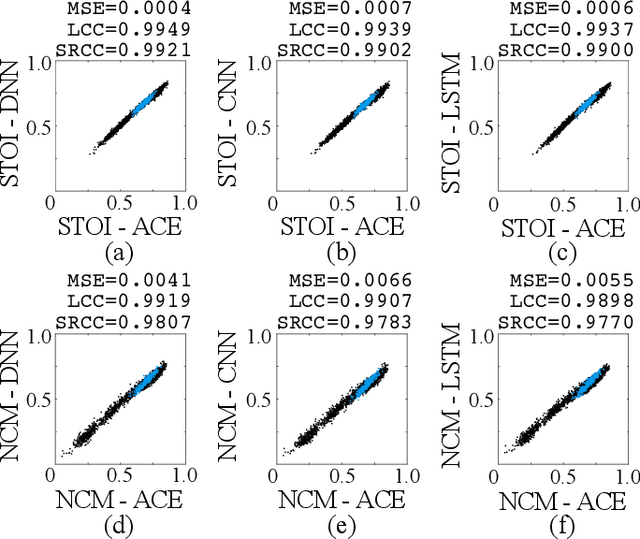
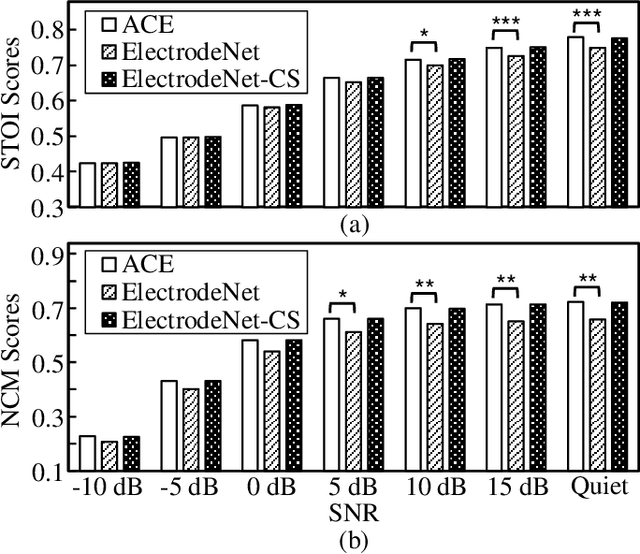
ElectrodeNet, a deep learning based sound coding strategy for the cochlear implant (CI), is proposed to emulate the advanced combination encoder (ACE) strategy by replacing the conventional envelope detection using various artificial neural networks. The extended ElectrodeNet-CS strategy further incorporates the channel selection (CS). Network models of deep neural network (DNN), convolutional neural network (CNN), and long short-term memory (LSTM) were trained using the Fast Fourier Transformed bins and channel envelopes obtained from the processing of clean speech by the ACE strategy. Objective speech understanding using short-time objective intelligibility (STOI) and normalized covariance metric (NCM) was estimated for ElectrodeNet using CI simulations. Sentence recognition tests for vocoded Mandarin speech were conducted with normal-hearing listeners. DNN, CNN, and LSTM based ElectrodeNets exhibited strong correlations to ACE in objective and subjective scores using mean squared error (MSE), linear correlation coefficient (LCC) and Spearman's rank correlation coefficient (SRCC). The ElectrodeNet-CS strategy was capable of producing N-of-M compatible electrode patterns using a modified DNN network to embed maxima selection, and to perform in similar or even slightly higher average in STOI and sentence recognition compared to ACE. The methods and findings demonstrated the feasibility and potential of using deep learning in CI coding strategy.
Fast and Minimax Optimal Estimation of Low-Rank Matrices via Non-Convex Gradient Descent
May 26, 2023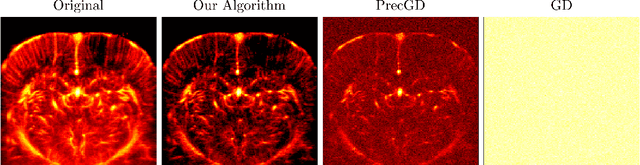
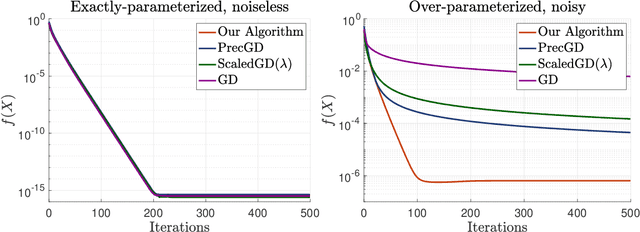
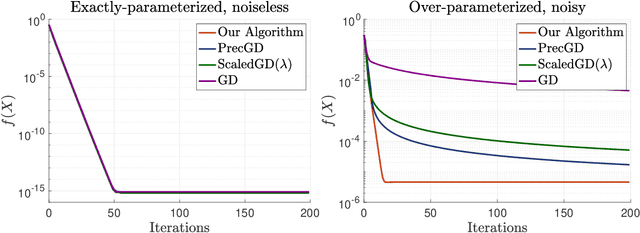
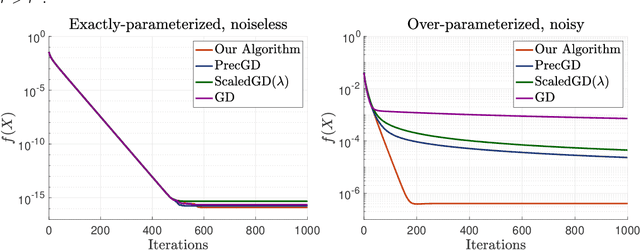
We study the problem of estimating a low-rank matrix from noisy measurements, with the specific goal of achieving minimax optimal error. In practice, the problem is commonly solved using non-convex gradient descent, due to its ability to scale to large-scale real-world datasets. In theory, non-convex gradient descent is capable of achieving minimax error. But in practice, it often converges extremely slowly, such that it cannot even deliver estimations of modest accuracy within reasonable time. On the other hand, methods that improve the convergence of non-convex gradient descent, through rescaling or preconditioning, also greatly amplify the measurement noise, resulting in estimations that are orders of magnitude less accurate than what is theoretically achievable with minimax optimal error. In this paper, we propose a slight modification to the usual non-convex gradient descent method that remedies the issue of slow convergence, while provably preserving its minimax optimality. Our proposed algorithm has essentially the same per-iteration cost as non-convex gradient descent, but is guaranteed to converge to minimax error at a linear rate that is immune to ill-conditioning. Using our proposed algorithm, we reconstruct a 60 megapixel dataset for a medical imaging application, and observe significantly decreased reconstruction error compared to previous approaches.
Study of Subjective and Objective Quality Assessment of Mobile Cloud Gaming Videos
May 26, 2023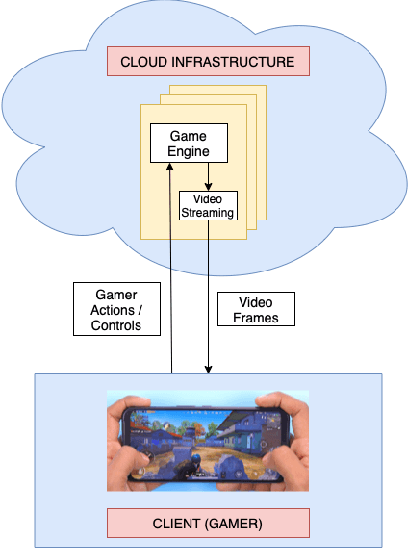
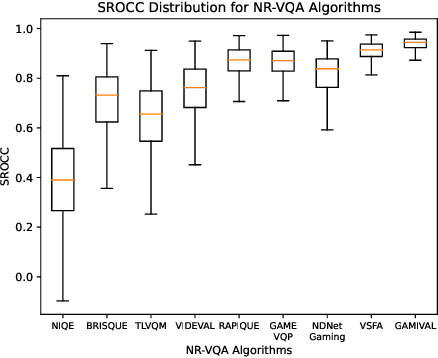
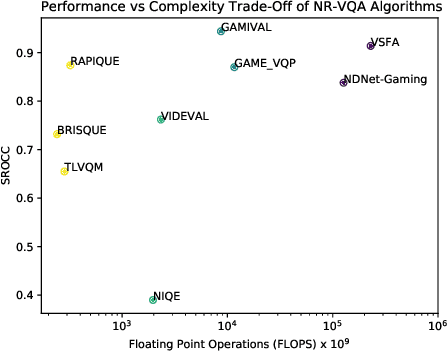
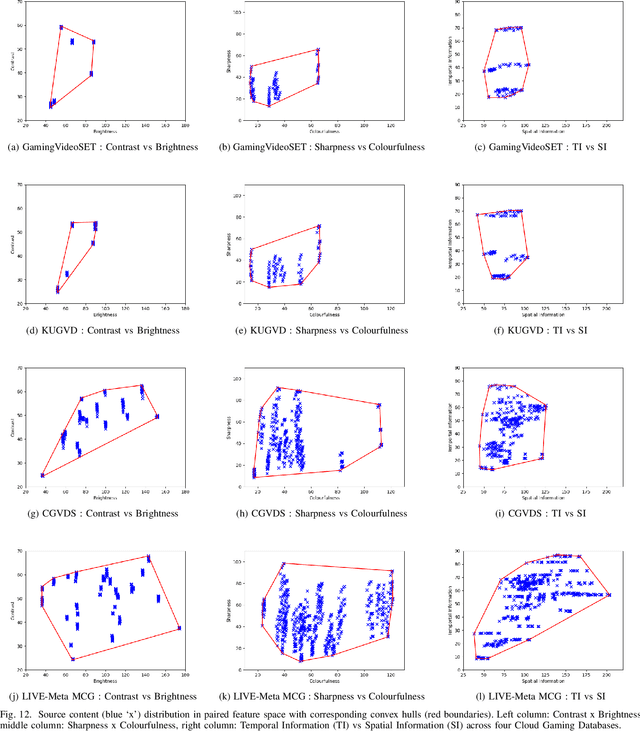
We present the outcomes of a recent large-scale subjective study of Mobile Cloud Gaming Video Quality Assessment (MCG-VQA) on a diverse set of gaming videos. Rapid advancements in cloud services, faster video encoding technologies, and increased access to high-speed, low-latency wireless internet have all contributed to the exponential growth of the Mobile Cloud Gaming industry. Consequently, the development of methods to assess the quality of real-time video feeds to end-users of cloud gaming platforms has become increasingly important. However, due to the lack of a large-scale public Mobile Cloud Gaming Video dataset containing a diverse set of distorted videos with corresponding subjective scores, there has been limited work on the development of MCG-VQA models. Towards accelerating progress towards these goals, we created a new dataset, named the LIVE-Meta Mobile Cloud Gaming (LIVE-Meta-MCG) video quality database, composed of 600 landscape and portrait gaming videos, on which we collected 14,400 subjective quality ratings from an in-lab subjective study. Additionally, to demonstrate the usefulness of the new resource, we benchmarked multiple state-of-the-art VQA algorithms on the database. The new database will be made publicly available on our website: \url{https://live.ece.utexas.edu/research/LIVE-Meta-Mobile-Cloud-Gaming/index.html}
Identification of stormwater control strategies and their associated uncertainties using Bayesian Optimization
May 29, 2023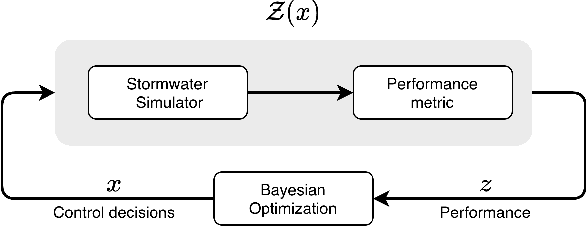

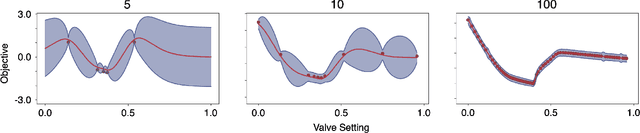
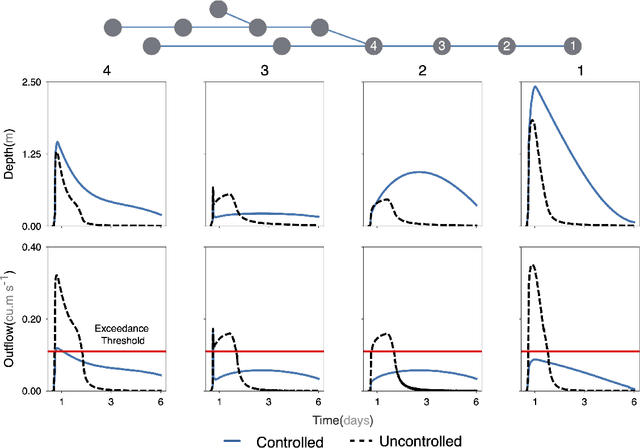
Dynamic control is emerging as an effective methodology for operating stormwater systems under stress from rapidly evolving weather patterns. Informed by rainfall predictions and real-time sensor measurements, control assets in the stormwater network can be dynamically configured to tune the behavior of the stormwater network to reduce the risk of urban flooding, equalize flows to the water reclamation facilities, and protect the receiving water bodies. However, developing such control strategies requires significant human and computational resources, and a methodology does not yet exist for quantifying the risks associated with implementing these control strategies. To address these challenges, in this paper, we introduce a Bayesian Optimization-based approach for identifying stormwater control strategies and estimating the associated uncertainties. We evaluate the efficacy of this approach in identifying viable control strategies in a simulated environment on real-world inspired combined and separated stormwater networks. We demonstrate the computational efficiency of the proposed approach by comparing it against a Genetic algorithm. Furthermore, we extend the Bayesian Optimization-based approach to quantify the uncertainty associated with the identified control strategies and evaluate it on a synthetic stormwater network. To our knowledge, this is the first-ever stormwater control methodology that quantifies uncertainty associated with the identified control actions. This Bayesian optimization-based stormwater control methodology is an off-the-shelf control approach that can be applied to control any stormwater network as long we have access to the rainfall predictions, and there exists a model for simulating the behavior of the stormwater network.
Safety of autonomous vehicles: A survey on Model-based vs. AI-based approaches
May 29, 2023
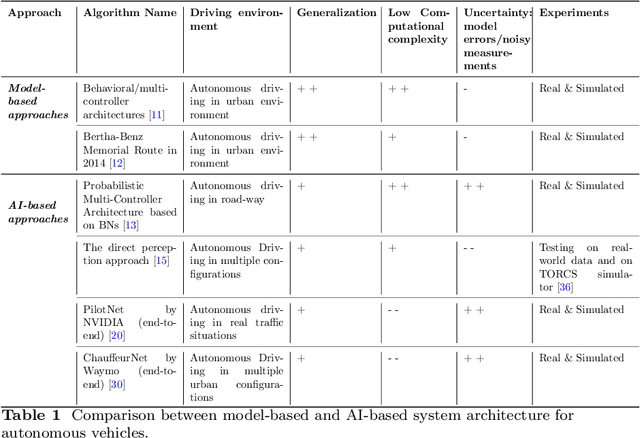
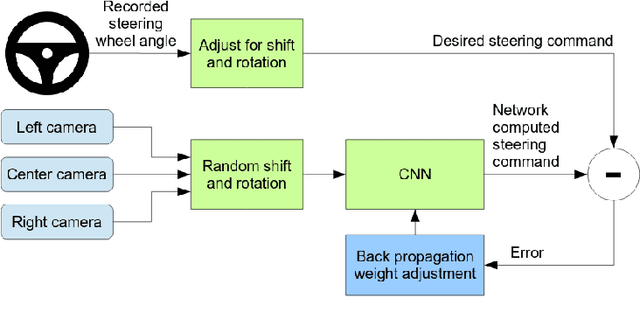
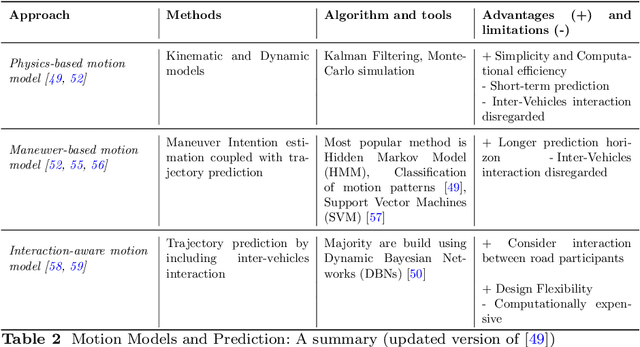
The growing advancements in Autonomous Vehicles (AVs) have emphasized the critical need to prioritize the absolute safety of AV maneuvers, especially in dynamic and unpredictable environments or situations. This objective becomes even more challenging due to the uniqueness of every traffic situation/condition. To cope with all these very constrained and complex configurations, AVs must have appropriate control architectures with reliable and real-time Risk Assessment and Management Strategies (RAMS). These targeted RAMS must lead to reduce drastically the navigation risks. However, the lack of safety guarantees proves, which is one of the key challenges to be addressed, limit drastically the ambition to introduce more broadly AVs on our roads and restrict the use of AVs to very limited use cases. Therefore, the focus and the ambition of this paper is to survey research on autonomous vehicles while focusing on the important topic of safety guarantee of AVs. For this purpose, it is proposed to review research on relevant methods and concepts defining an overall control architecture for AVs, with an emphasis on the safety assessment and decision-making systems composing these architectures. Moreover, it is intended through this reviewing process to highlight researches that use either model-based methods or AI-based approaches. This is performed while emphasizing the strengths and weaknesses of each methodology and investigating the research that proposes a comprehensive multi-modal design that combines model-based and AI approaches. This paper ends with discussions on the methods used to guarantee the safety of AVs namely: safety verification techniques and the standardization/generalization of safety frameworks.
An Experimental Review of Speaker Diarization methods with application to Two-Speaker Conversational Telephone Speech recordings
May 29, 2023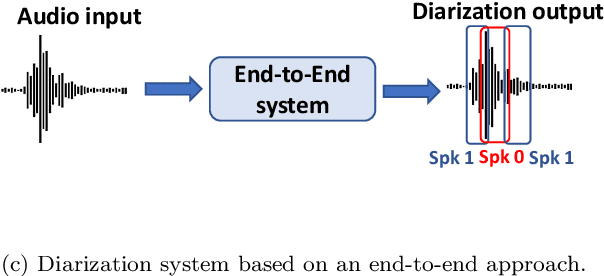
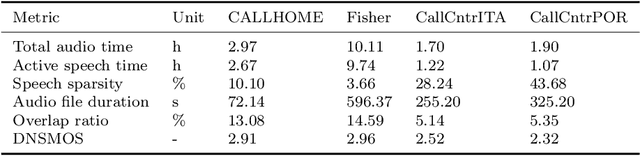
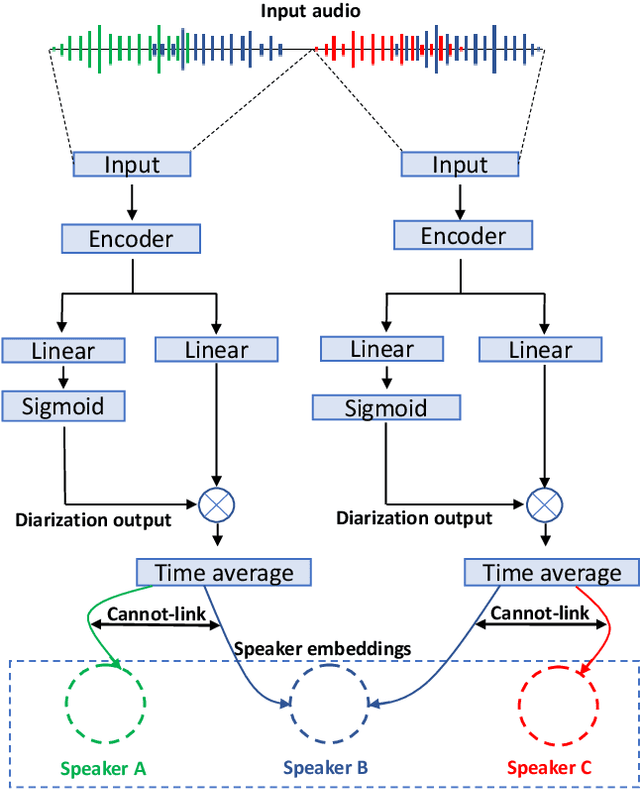
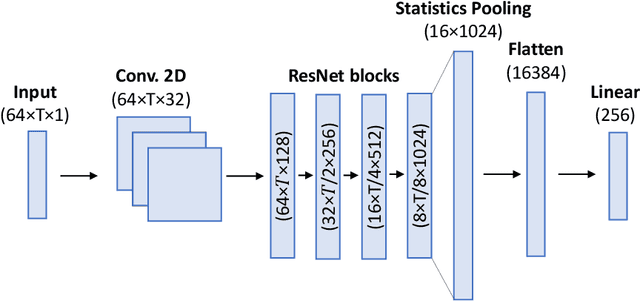
We performed an experimental review of current diarization systems for the conversational telephone speech (CTS) domain. In detail, we considered a total of eight different algorithms belonging to clustering-based, end-to-end neural diarization (EEND), and speech separation guided diarization (SSGD) paradigms. We studied the inference-time computational requirements and diarization accuracy on four CTS datasets with different characteristics and languages. We found that, among all methods considered, EEND-vector clustering (EEND-VC) offers the best trade-off in terms of computing requirements and performance. More in general, EEND models have been found to be lighter and faster in inference compared to clustering-based methods. However, they also require a large amount of diarization-oriented annotated data. In particular EEND-VC performance in our experiments degraded when the dataset size was reduced, whereas self-attentive EEND (SA-EEND) was less affected. We also found that SA-EEND gives less consistent results among all the datasets compared to EEND-VC, with its performance degrading on long conversations with high speech sparsity. Clustering-based diarization systems, and in particular VBx, instead have more consistent performance compared to SA-EEND but are outperformed by EEND-VC. The gap with respect to this latter is reduced when overlap-aware clustering methods are considered. SSGD is the most computationally demanding method, but it could be convenient if speech recognition has to be performed. Its performance is close to SA-EEND but degrades significantly when the training and inference data characteristics are less matched.