 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DroNeRF: Real-time Multi-agent Drone Pose Optimization for Computing Neural Radiance Fields
Mar 08, 2023


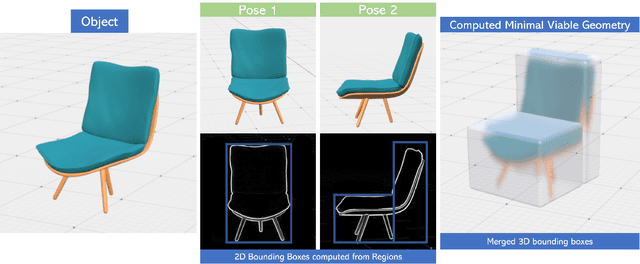
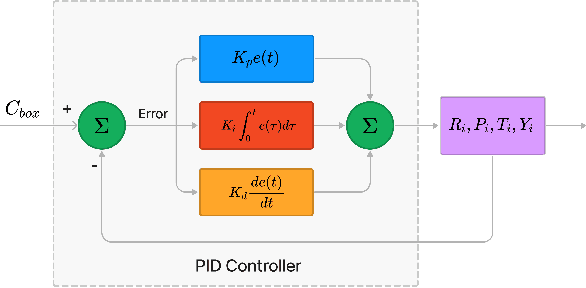
We present a novel optimization algorithm called DroNeRF for the autonomous positioning of monocular camera drones around an object for real-time 3D reconstruction using only a few images. Neural Radiance Fields or NeRF, is a novel view synthesis technique used to generate new views of an object or scene from a set of input images. Using drones in conjunction with NeRF provides a unique and dynamic way to generate novel views of a scene, especially with limited scene capabilities of restricted movements. Our approach focuses on calculating optimized pose for individual drones while solely depending on the object geometry without using any external localization system. The unique camera positioning during the data-capturing phase significantly impacts the quality of the 3D model. To evaluate the quality of our generated novel views, we compute different perceptual metrics like the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure(SSIM). Our work demonstrates the benefit of using an optimal placement of various drones with limited mobility to generate perceptually better results.
The emergence of clusters in self-attention dynamics
May 09, 2023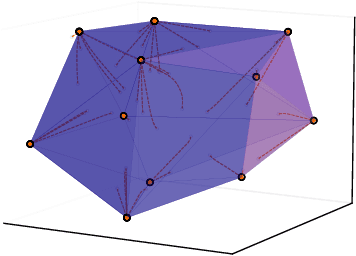

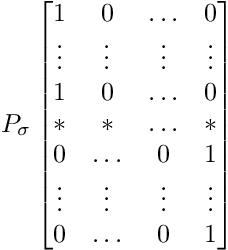
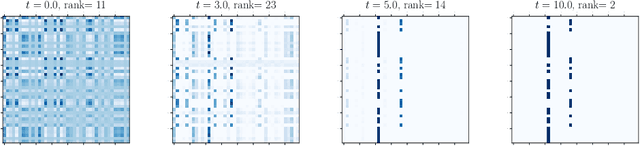
Viewing Transformers as interacting particle systems, we describe the geometry of learned representations when the weights are not time dependent. We show that particles, representing tokens, tend to cluster toward particular limiting objects as time tends to infinity. The type of limiting object that emerges depends on the spectrum of the value matrix. Additionally, in the one-dimensional case we prove that the self-attention matrix converges to a low-rank Boolean matrix. The combination of these results mathematically confirms the empirical observation made by Vaswani et al. \cite{vaswani2017attention} that \emph{leaders} appear in a sequence of tokens when processed by Transformers.
Which Features are Learnt by Contrastive Learning? On the Role of Simplicity Bias in Class Collapse and Feature Suppression
May 29, 2023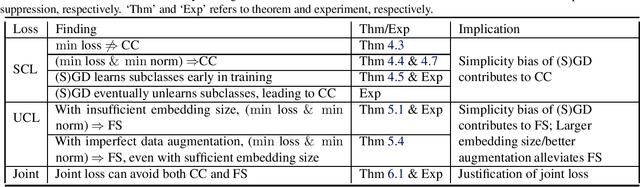
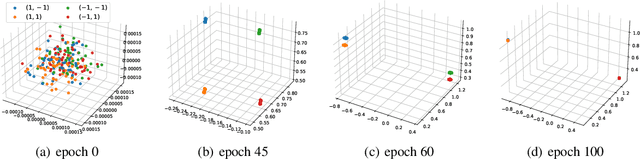
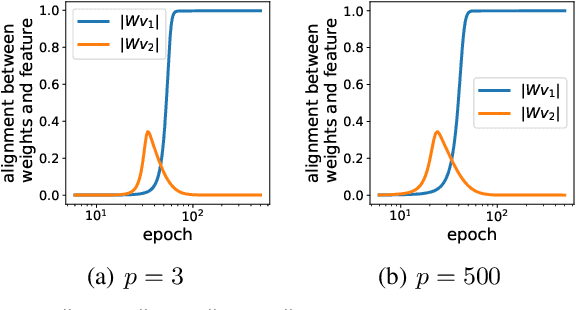
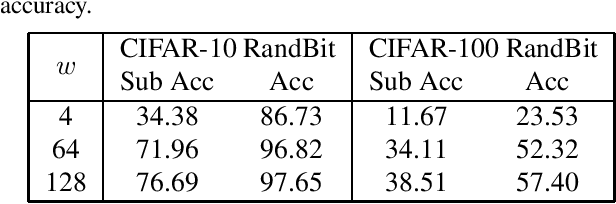
Contrastive learning (CL) has emerged as a powerful technique for representation learning, with or without label supervision. However, supervised CL is prone to collapsing representations of subclasses within a class by not capturing all their features, and unsupervised CL may suppress harder class-relevant features by focusing on learning easy class-irrelevant features; both significantly compromise representation quality. Yet, there is no theoretical understanding of \textit{class collapse} or \textit{feature suppression} at \textit{test} time. We provide the first unified theoretically rigorous framework to determine \textit{which} features are learnt by CL. Our analysis indicate that, perhaps surprisingly, bias of (stochastic) gradient descent towards finding simpler solutions is a key factor in collapsing subclass representations and suppressing harder class-relevant features. Moreover, we present increasing embedding dimensionality and improving the quality of data augmentations as two theoretically motivated solutions to {feature suppression}. We also provide the first theoretical explanation for why employing supervised and unsupervised CL together yields higher-quality representations, even when using commonly-used stochastic gradient methods.
Robust Lipschitz Bandits to Adversarial Corruptions
May 29, 2023
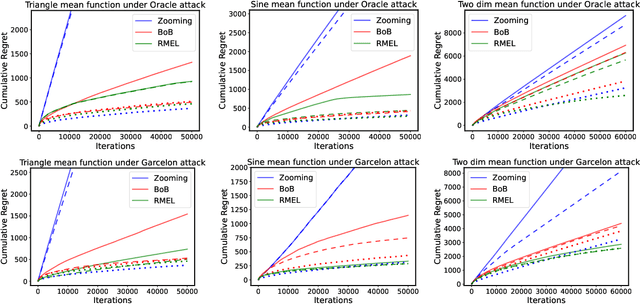
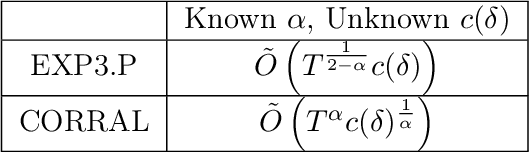
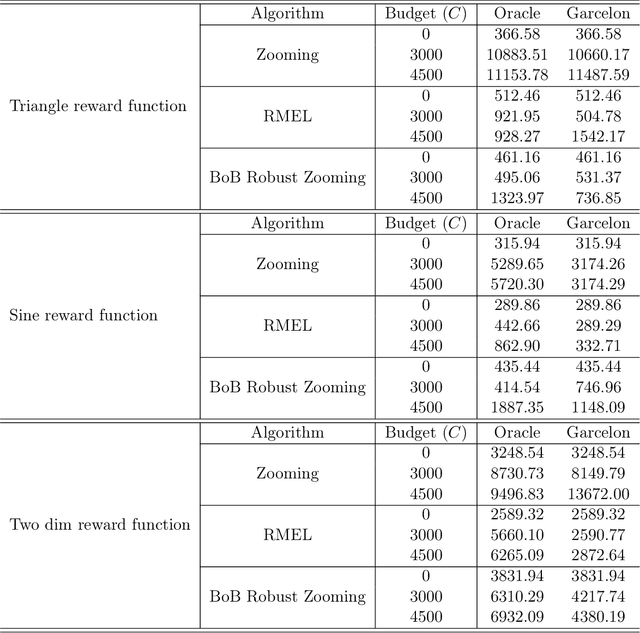
Lipschitz bandit is a variant of stochastic bandits that deals with a continuous arm set defined on a metric space, where the reward function is subject to a Lipschitz constraint. In this paper, we introduce a new problem of Lipschitz bandits in the presence of adversarial corruptions where an adaptive adversary corrupts the stochastic rewards up to a total budget $C$. The budget is measured by the sum of corruption levels across the time horizon $T$. We consider both weak and strong adversaries, where the weak adversary is unaware of the current action before the attack, while the strong one can observe it. Our work presents the first line of robust Lipschitz bandit algorithms that can achieve sub-linear regret under both types of adversary, even when the total budget of corruption $C$ is unrevealed to the agent. We provide a lower bound under each type of adversary, and show that our algorithm is optimal under the strong case. Finally, we conduct experiments to illustrate the effectiveness of our algorithms against two classic kinds of attacks.
Extrinsic Factors Affecting the Accuracy of Biomedical NER
May 29, 2023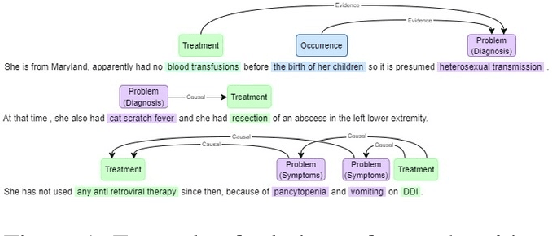
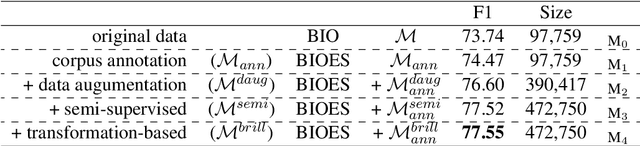
Biomedical named entity recognition (NER) is a critial task that aims to identify structured information in clinical text, which is often replete with complex, technical terms and a high degree of variability. Accurate and reliable NER can facilitate the extraction and analysis of important biomedical information, which can be used to improve downstream applications including the healthcare system. However, NER in the biomedical domain is challenging due to limited data availability, as the high expertise, time, and expenses are required to annotate its data. In this paper, by using the limited data, we explore various extrinsic factors including the corpus annotation scheme, data augmentation techniques, semi-supervised learning and Brill transformation, to improve the performance of a NER model on a clinical text dataset (i2b2 2012, \citet{sun-rumshisky-uzuner:2013}). Our experiments demonstrate that these approaches can significantly improve the model's F1 score from original 73.74 to 77.55. Our findings suggest that considering different extrinsic factors and combining these techniques is a promising approach for improving NER performance in the biomedical domain where the size of data is limited.
DoMo-AC: Doubly Multi-step Off-policy Actor-Critic Algorithm
May 29, 2023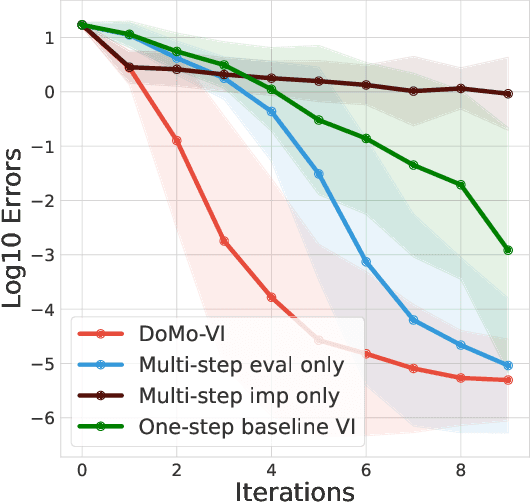


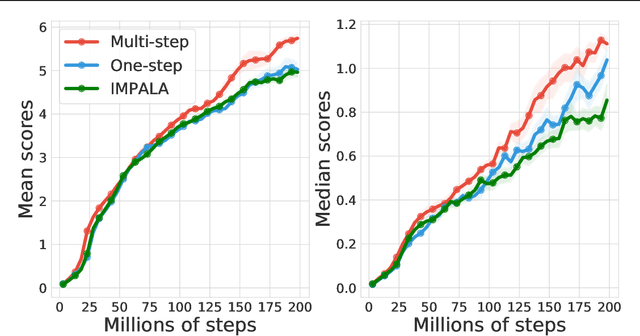
Multi-step learning applies lookahead over multiple time steps and has proved valuable in policy evaluation settings. However, in the optimal control case, the impact of multi-step learning has been relatively limited despite a number of prior efforts. Fundamentally, this might be because multi-step policy improvements require operations that cannot be approximated by stochastic samples, hence hindering the widespread adoption of such methods in practice. To address such limitations, we introduce doubly multi-step off-policy VI (DoMo-VI), a novel oracle algorithm that combines multi-step policy improvements and policy evaluations. DoMo-VI enjoys guaranteed convergence speed-up to the optimal policy and is applicable in general off-policy learning settings. We then propose doubly multi-step off-policy actor-critic (DoMo-AC), a practical instantiation of the DoMo-VI algorithm. DoMo-AC introduces a bias-variance trade-off that ensures improved policy gradient estimates. When combined with the IMPALA architecture, DoMo-AC has showed improvements over the baseline algorithm on Atari-57 game benchmarks.
Exact Recovery for System Identification with More Corrupt Data than Clean Data
May 17, 2023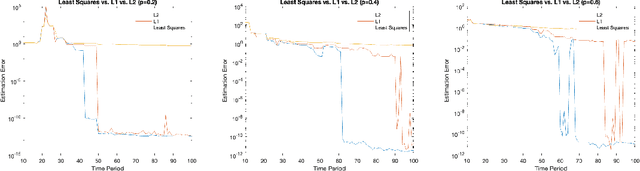
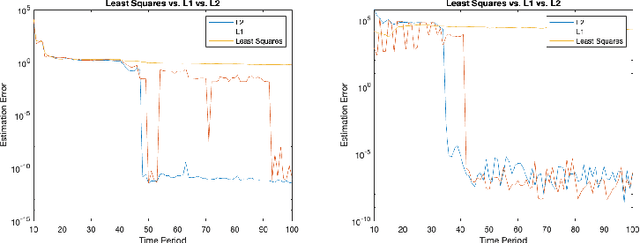
In this paper, we study the system identification problem for linear discrete-time systems under adversaries and analyze two lasso-type estimators. We study both asymptotic and non-asymptotic properties of these estimators in two separate scenarios, corresponding to deterministic and stochastic models for the attack times. Since the samples collected from the system are correlated, the existing results on lasso are not applicable. We show that when the system is stable and the attacks are injected periodically, the sample complexity for the exact recovery of the system dynamics is O(n), where n is the dimension of the states. When the adversarial attacks occur at each time instance with probability p, the required sample complexity for the exact recovery scales as O(\log(n)p/(1-p)^2). This result implies the almost sure convergence to the true system dynamics under the asymptotic regime. As a by-product, even when more than half of the data is compromised, our estimators still learn the system correctly. This paper provides the first mathematical guarantee in the literature on learning from correlated data for dynamical systems in the case when there is less clean data than corrupt data.
A Survey on Multi-Objective based Parameter Optimization for Deep Learning
May 17, 2023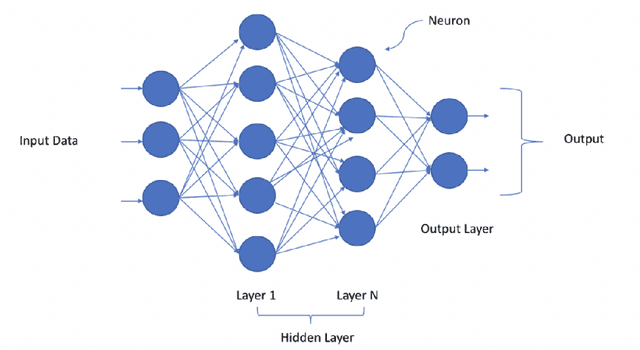
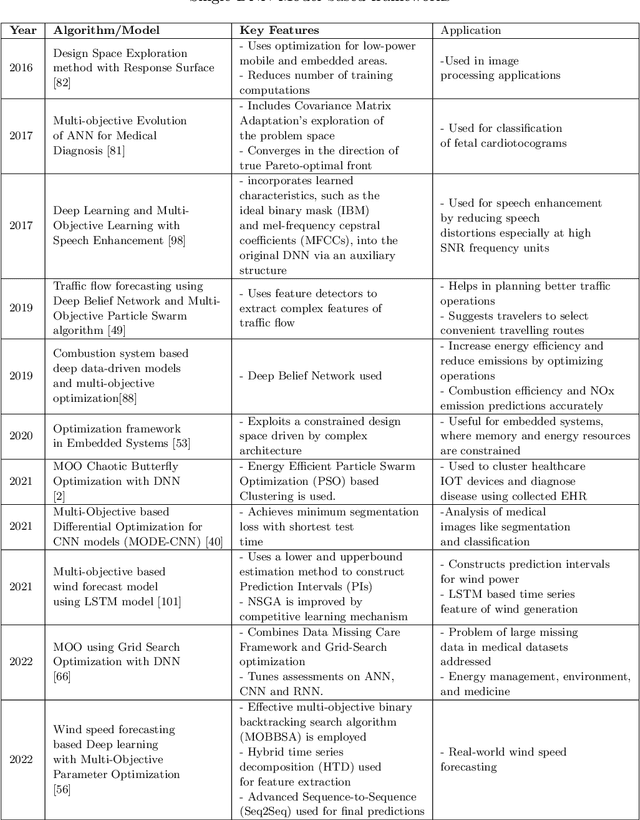
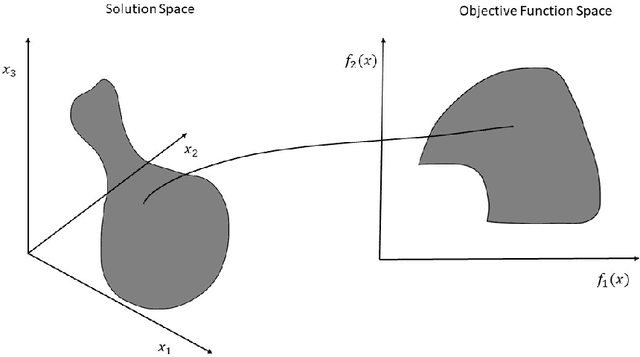
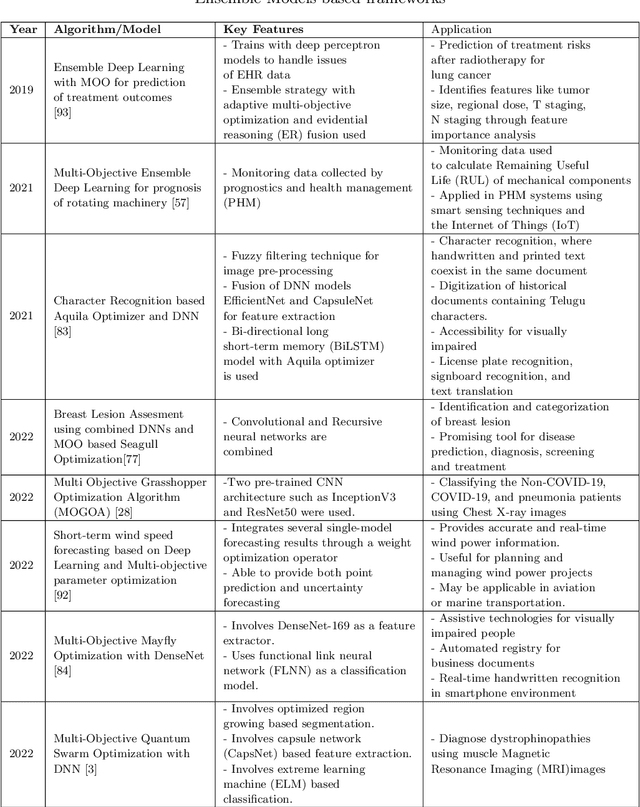
Deep learning models form one of the most powerful machine learning models for the extraction of important features. Most of the designs of deep neural models, i.e., the initialization of parameters, are still manually tuned. Hence, obtaining a model with high performance is exceedingly time-consuming and occasionally impossible. Optimizing the parameters of the deep networks, therefore, requires improved optimization algorithms with high convergence rates. The single objective-based optimization methods generally used are mostly time-consuming and do not guarantee optimum performance in all cases. Mathematical optimization problems containing multiple objective functions that must be optimized simultaneously fall under the category of multi-objective optimization sometimes referred to as Pareto optimization. Multi-objective optimization problems form one of the alternatives yet useful options for parameter optimization. However, this domain is a bit less explored. In this survey, we focus on exploring the effectiveness of multi-objective optimization strategies for parameter optimization in conjunction with deep neural networks. The case studies used in this study focus on how the two methods are combined to provide valuable insights into the generation of predictions and analysis in multiple applications.
A Neural State-Space Model Approach to Efficient Speech Separation
May 26, 2023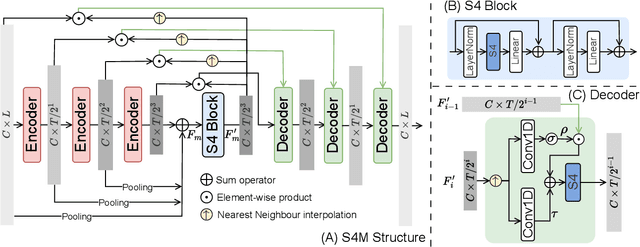
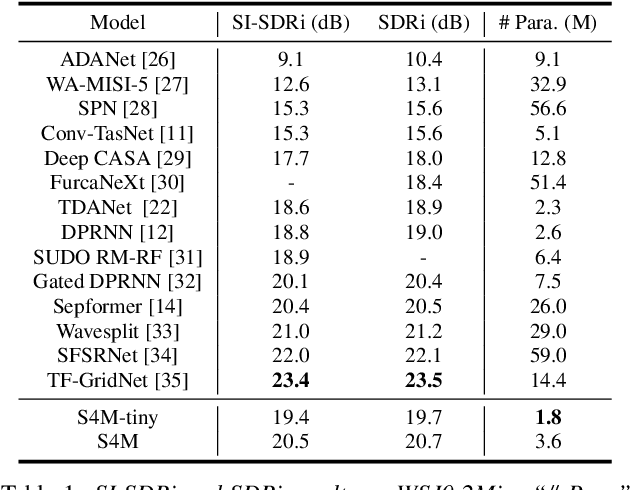
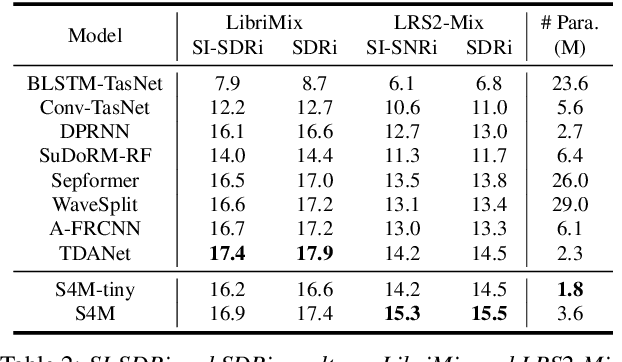
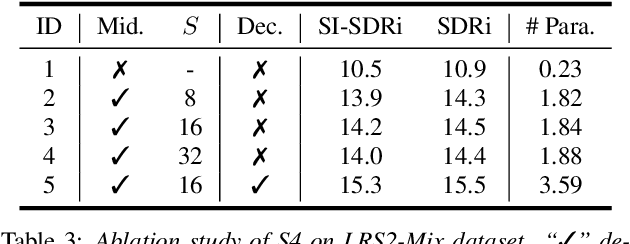
In this work, we introduce S4M, a new efficient speech separation framework based on neural state-space models (SSM). Motivated by linear time-invariant systems for sequence modeling, our SSM-based approach can efficiently model input signals into a format of linear ordinary differential equations (ODEs) for representation learning. To extend the SSM technique into speech separation tasks, we first decompose the input mixture into multi-scale representations with different resolutions. This mechanism enables S4M to learn globally coherent separation and reconstruction. The experimental results show that S4M performs comparably to other separation backbones in terms of SI-SDRi, while having a much lower model complexity with significantly fewer trainable parameters. In addition, our S4M-tiny model (1.8M parameters) even surpasses attention-based Sepformer (26.0M parameters) in noisy conditions with only 9.2 of multiply-accumulate operation (MACs).
Gender, Smoking History and Age Prediction from Laryngeal Images
May 26, 2023
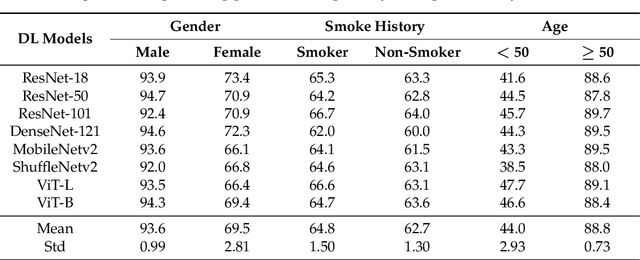
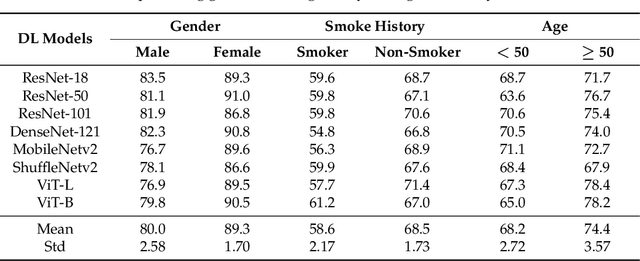
Flexible laryngoscopy is commonly performed by otolaryngologists to detect laryngeal diseases and to recognize potentially malignant lesions. Recently, researchers have introduced machine learning techniques to facilitate automated diagnosis using laryngeal images and achieved promising results. Diagnostic performance can be improved when patients' demographic information is incorporated into models. However, manual entry of patient data is time consuming for clinicians. In this study, we made the first endeavor to employ deep learning models to predict patient demographic information to improve detector model performance. The overall accuracy for gender, smoking history, and age was 85.5%, 65.2%, and 75.9%, respectively. We also created a new laryngoscopic image set for machine learning study and benchmarked the performance of 8 classical deep learning models based on CNNs and Transformers. The results can be integrated into current learning models to improve their performance by incorporating the patient's demographic information.