 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continual Domain Randomization
Mar 18, 2024
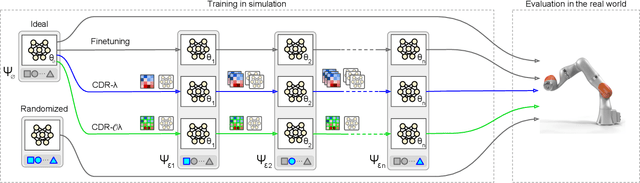

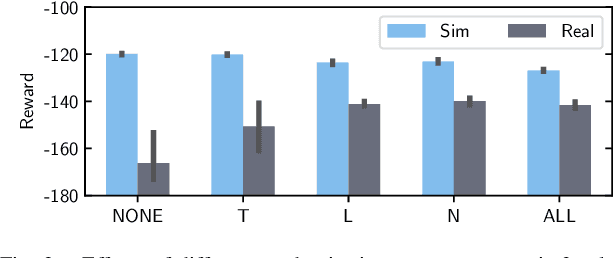
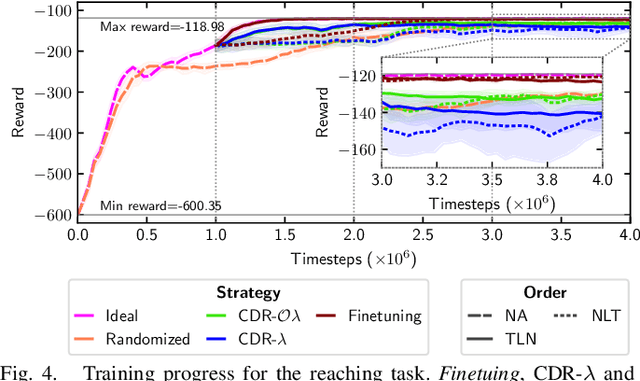
Domain Randomization (DR) is commonly used for sim2real transfer of reinforcement learning (RL) policies in robotics. Most DR approaches require a simulator with a fixed set of tunable parameters from the start of the training, from which the parameters are randomized simultaneously to train a robust model for use in the real world. However, the combined randomization of many parameters increases the task difficulty and might result in sub-optimal policies. To address this problem and to provide a more flexible training process, we propose Continual Domain Randomization (CDR) for RL that combines domain randomization with continual learning to enable sequential training in simulation on a subset of randomization parameters at a time. Starting from a model trained in a non-randomized simulation where the task is easier to solve, the model is trained on a sequence of randomizations, and continual learning is employed to remember the effects of previous randomizations. Our robotic reaching and grasping tasks experiments show that the model trained in this fashion learns effectively in simulation and performs robustly on the real robot while matching or outperforming baselines that employ combined randomization or sequential randomization without continual learning. Our code and videos are available at https://continual-dr.github.io/.
StiefelGen: A Simple, Model Agnostic Approach for Time Series Data Augmentation over Riemannian Manifolds
Feb 29, 2024Data augmentation is an area of research which has seen active development in many machine learning fields, such as in image-based learning models, reinforcement learning for self driving vehicles, and general noise injection for point cloud data. However, convincing methods for general time series data augmentation still leaves much to be desired, especially since the methods developed for these models do not readily cross-over. Three common approaches for time series data augmentation include: (i) Constructing a physics-based model and then imbuing uncertainty over the coefficient space (for example), (ii) Adding noise to the observed data set(s), and, (iii) Having access to ample amounts of time series data sets from which a robust generative neural network model can be trained. However, for many practical problems that work with time series data in the industry: (i) One usually does not have access to a robust physical model, (ii) The addition of noise can in of itself require large or difficult assumptions (for example, what probability distribution should be used? Or, how large should the noise variance be?), and, (iii) In practice, it can be difficult to source a large representative time series data base with which to train the neural network model for the underlying problem. In this paper, we propose a methodology which attempts to simultaneously tackle all three of these previous limitations to a large extent. The method relies upon the well-studied matrix differential geometry of the Stiefel manifold, as it proposes a simple way in which time series signals can placed on, and then smoothly perturbed over the manifold. We attempt to clarify how this method works by showcasing several potential use cases which in particular work to take advantage of the unique properties of this underlying manifold.
A Simple Finite-Time Analysis of TD Learning with Linear Function Approximation
Mar 04, 2024We study the finite-time convergence of TD learning with linear function approximation under Markovian sampling. Existing proofs for this setting either assume a projection step in the algorithm to simplify the analysis, or require a fairly intricate argument to ensure stability of the iterates. We ask: \textit{Is it possible to retain the simplicity of a projection-based analysis without actually performing a projection step in the algorithm?} Our main contribution is to show this is possible via a novel two-step argument. In the first step, we use induction to prove that under a standard choice of a constant step-size $\alpha$, the iterates generated by TD learning remain uniformly bounded in expectation. In the second step, we establish a recursion that mimics the steady-state dynamics of TD learning up to a bounded perturbation on the order of $O(\alpha^2)$ that captures the effect of Markovian sampling. Combining these pieces leads to an overall approach that considerably simplifies existing proofs. We conjecture that our inductive proof technique will find applications in the analyses of more complex stochastic approximation algorithms, and conclude by providing some examples of such applications.
Joint Power Allocation and Beamforming for In-band Full-duplex Multi-cell Multi-user Networks
Mar 16, 2024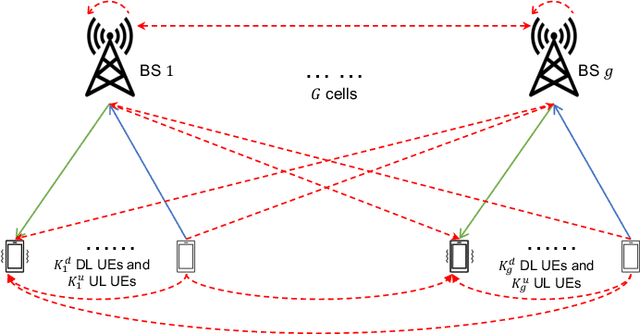
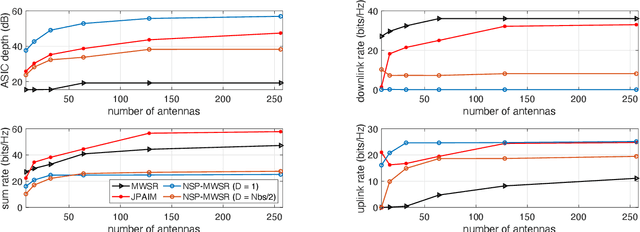
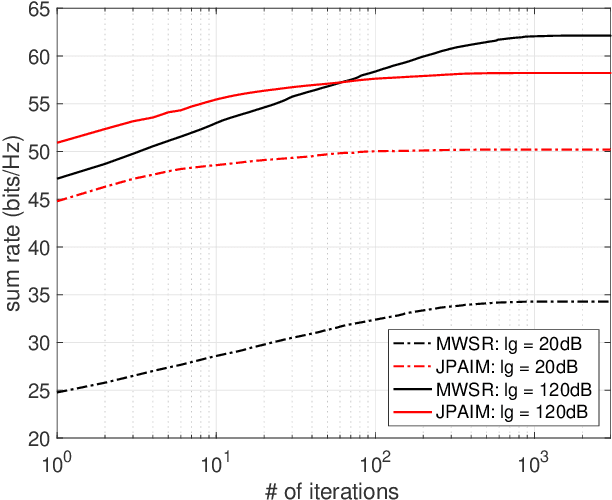
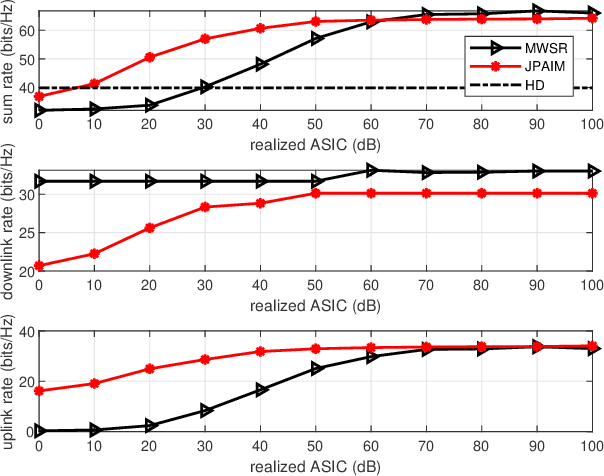
This paper investigates a robust joint power allocation and beamforming scheme for in-band full-duplex multi-cell multi-user (IBFD-MCMU) networks. A mean-squared error (MSE) minimization problem is formulated with constraints on the power budgets and residual self-interference (RSI) power. The problem is not convex, so we decompose it into two sub-problems: interference management beamforming and power allocation, and give closed-form solutions to the sub-problems. Then we propose an iterative algorithm to yield an overall solution. The computational complexity and convergence behavior of the algorithm are analyzed. Our method can enhance the analog self-interference cancellation (ASIC) depth provided by the precoder with less effect on the downlink communication than the existing null-space projection method, inspiring a low-cost but efficient IBFD transceiver design. It can achieve 42.9% of IBFD gain in terms of spectral efficiency with only antenna isolation, while this value increases to 60.9% with further digital self-interference cancellation (DSIC). Numerical results illustrate that our algorithm is robust to hardware impairments and channel uncertainty. With sufficient ASIC depth, our method reduces the computation time by at least 20% than the existing scheme due to its faster convergence speed at the cost of < 12.5% sum rate loss. The benefit is much more significant with single-antenna users that our algorithm saves at least 40% of the computation time at the cost of < 10% sum rate reduction.
Edge Computing Enabled Real-Time Video Analysis via Adaptive Spatial-Temporal Semantic Filtering
Feb 29, 2024This paper proposes a novel edge computing enabled real-time video analysis system for intelligent visual devices. The proposed system consists of a tracking-assisted object detection module (TAODM) and a region of interesting module (ROIM). TAODM adaptively determines the offloading decision to process each video frame locally with a tracking algorithm or to offload it to the edge server inferred by an object detection model. ROIM determines each offloading frame's resolution and detection model configuration to ensure that the analysis results can return in time. TAODM and ROIM interact jointly to filter the repetitive spatial-temporal semantic information to maximize the processing rate while ensuring high video analysis accuracy. Unlike most existing works, this paper investigates the real-time video analysis systems where the intelligent visual device connects to the edge server through a wireless network with fluctuating network conditions. We decompose the real-time video analysis problem into the offloading decision and configurations selection sub-problems. To solve these two sub-problems, we introduce a double deep Q network (DDQN) based offloading approach and a contextual multi-armed bandit (CMAB) based adaptive configurations selection approach, respectively. A DDQN-CMAB reinforcement learning (DCRL) training framework is further developed to integrate these two approaches to improve the overall video analyzing performance. Extensive simulations are conducted to evaluate the performance of the proposed solution, and demonstrate its superiority over counterparts.
Intention-aware Denoising Diffusion Model for Trajectory Prediction
Mar 14, 2024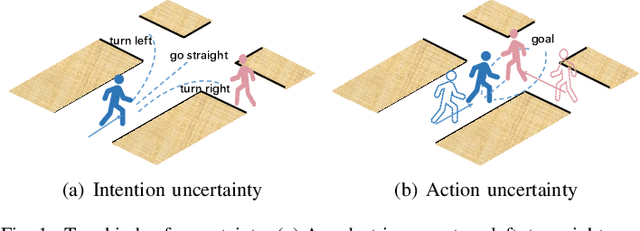
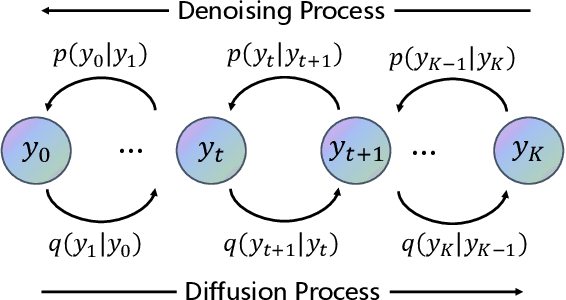
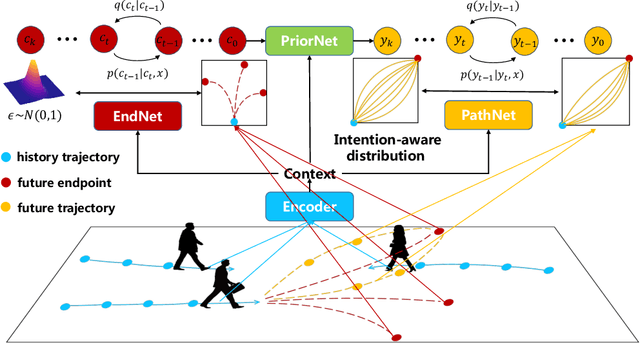

Trajectory prediction is an essential component in autonomous driving, particularly for collision avoidance systems. Considering the inherent uncertainty of the task, numerous studies have utilized generative models to produce multiple plausible future trajectories for each agent. However, most of them suffer from restricted representation ability or unstable training issues. To overcome these limitations, we propose utilizing the diffusion model to generate the distribution of future trajectories. Two cruxes are to be settled to realize such an idea. First, the diversity of intention is intertwined with the uncertain surroundings, making the true distribution hard to parameterize. Second, the diffusion process is time-consuming during the inference phase, rendering it unrealistic to implement in a real-time driving system. We propose an Intention-aware denoising Diffusion Model (IDM), which tackles the above two problems. We decouple the original uncertainty into intention uncertainty and action uncertainty and model them with two dependent diffusion processes. To decrease the inference time, we reduce the variable dimensions in the intention-aware diffusion process and restrict the initial distribution of the action-aware diffusion process, which leads to fewer diffusion steps. To validate our approach, we conduct experiments on the Stanford Drone Dataset (SDD) and ETH/UCY dataset. Our methods achieve state-of-the-art results, with an FDE of 13.83 pixels on the SDD dataset and 0.36 meters on the ETH/UCY dataset. Compared with the original diffusion model, IDM reduces inference time by two-thirds. Interestingly, our experiments further reveal that introducing intention information is beneficial in modeling the diffusion process of fewer steps.
K-Link: Knowledge-Link Graph from LLMs for Enhanced Representation Learning in Multivariate Time-Series Data
Mar 06, 2024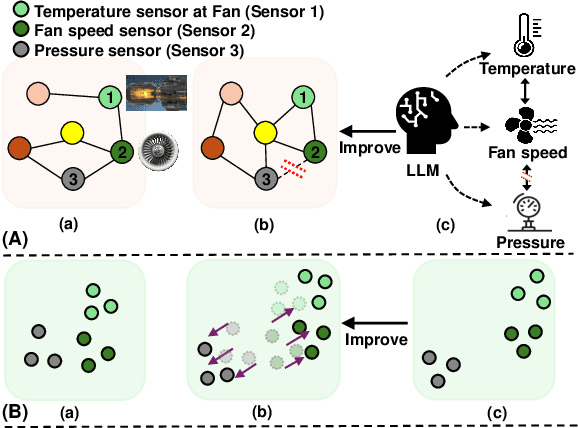
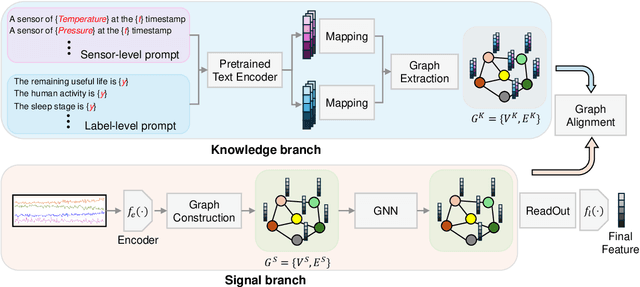
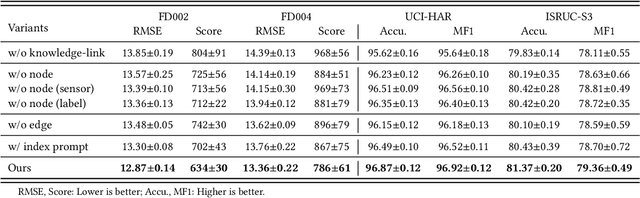
Sourced from various sensors and organized chronologically, Multivariate Time-Series (MTS) data involves crucial spatial-temporal dependencies, e.g., correlations among sensors. To capture these dependencies, Graph Neural Networks (GNNs) have emerged as powerful tools, yet their effectiveness is restricted by the quality of graph construction from MTS data. Typically, existing approaches construct graphs solely from MTS signals, which may introduce bias due to a small training dataset and may not accurately represent underlying dependencies. To address this challenge, we propose a novel framework named K-Link, leveraging Large Language Models (LLMs) to encode extensive general knowledge and thereby providing effective solutions to reduce the bias. Leveraging the knowledge embedded in LLMs, such as physical principles, we extract a \textit{Knowledge-Link graph}, capturing vast semantic knowledge of sensors and the linkage of the sensor-level knowledge. To harness the potential of the knowledge-link graph in enhancing the graph derived from MTS data, we propose a graph alignment module, facilitating the transfer of semantic knowledge within the knowledge-link graph into the MTS-derived graph. By doing so, we can improve the graph quality, ensuring effective representation learning with GNNs for MTS data. Extensive experiments demonstrate the efficacy of our approach for superior performance across various MTS-related downstream tasks.
FedSPU: Personalized Federated Learning for Resource-constrained Devices with Stochastic Parameter Update
Mar 18, 2024
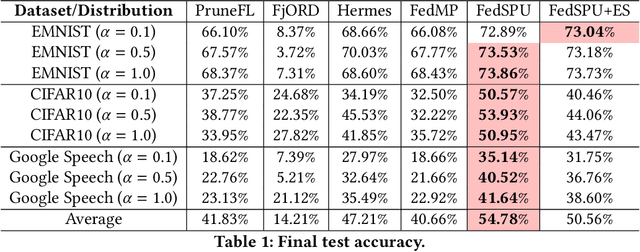
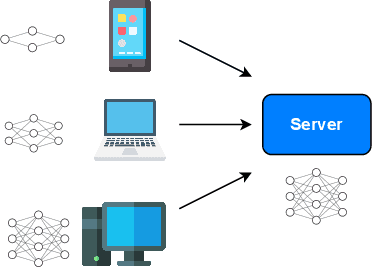
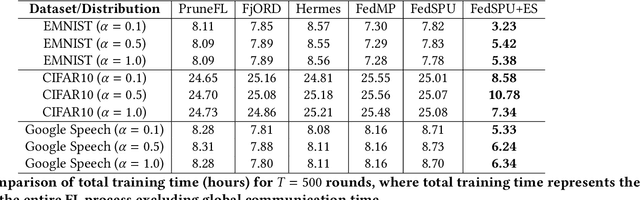
Personalized Federated Learning (PFL) is widely employed in IoT applications to handle high-volume, non-iid client data while ensuring data privacy. However, heterogeneous edge devices owned by clients may impose varying degrees of resource constraints, causing computation and communication bottlenecks for PFL. Federated Dropout has emerged as a popular strategy to address this challenge, wherein only a subset of the global model, i.e. a \textit{sub-model}, is trained on a client's device, thereby reducing computation and communication overheads. Nevertheless, the dropout-based model-pruning strategy may introduce bias, particularly towards non-iid local data. When biased sub-models absorb highly divergent parameters from other clients, performance degradation becomes inevitable. In response, we propose federated learning with stochastic parameter update (FedSPU). Unlike dropout that tailors the global model to small-size local sub-models, FedSPU maintains the full model architecture on each device but randomly freezes a certain percentage of neurons in the local model during training while updating the remaining neurons. This approach ensures that a portion of the local model remains personalized, thereby enhancing the model's robustness against biased parameters from other clients. Experimental results demonstrate that FedSPU outperforms federated dropout by 7.57\% on average in terms of accuracy. Furthermore, an introduced early stopping scheme leads to a significant reduction of the training time by \(24.8\%\sim70.4\%\) while maintaining high accuracy.
Safety Implications of Explainable Artificial Intelligence in End-to-End Autonomous Driving
Mar 18, 2024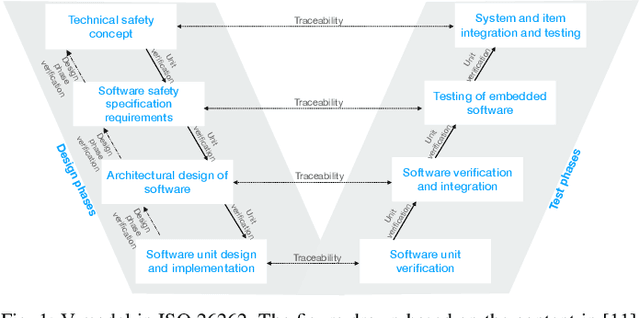



The end-to-end learning pipeline is gradually creating a paradigm shift in the ongoing development of highly autonomous vehicles, largely due to advances in deep learning, the availability of large-scale training datasets, and improvements in integrated sensor devices. However, a lack of interpretability in real-time decisions with contemporary learning methods impedes user trust and attenuates the widespread deployment and commercialization of such vehicles. Moreover, the issue is exacerbated when these cars are involved in or cause traffic accidents. Such drawback raises serious safety concerns from societal and legal perspectives. Consequently, explainability in end-to-end autonomous driving is essential to enable the safety of vehicular automation. However, the safety and explainability aspects of autonomous driving have generally been investigated disjointly by researchers in today's state of the art. In this paper, we aim to bridge the gaps between these topics and seek to answer the following research question: When and how can explanations improve safety of autonomous driving? In this regard, we first revisit established safety and state-of-the-art explainability techniques in autonomous driving. Furthermore, we present three critical case studies and show the pivotal role of explanations in enhancing self-driving safety. Finally, we describe our empirical investigation and reveal potential value, limitations, and caveats with practical explainable AI methods on their role of assuring safety and transparency for vehicle autonomy.
Estimation and Analysis of Slice Propagation Uncertainty in 3D Anatomy Segmentation
Mar 18, 2024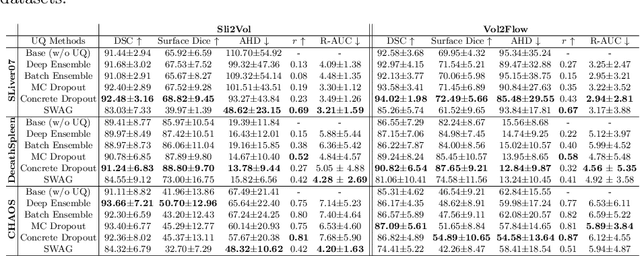
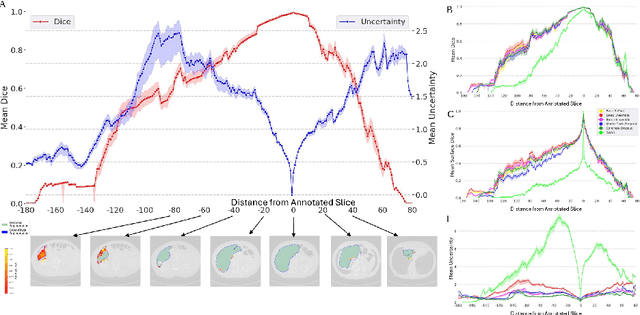
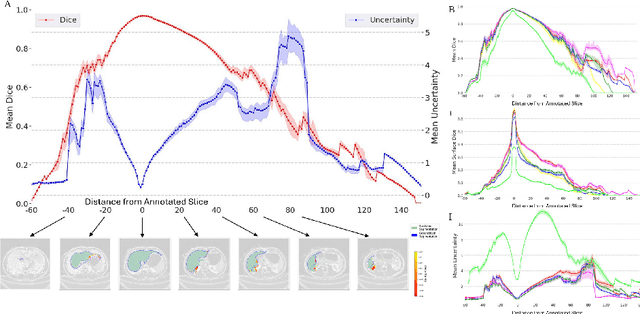
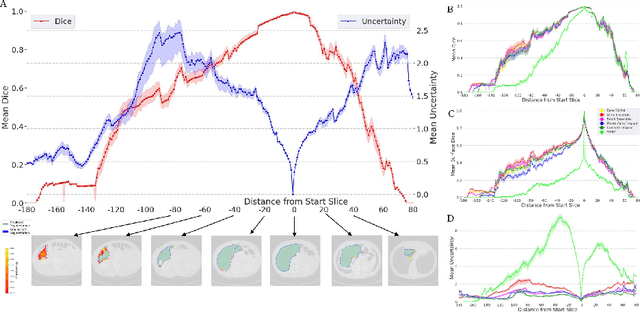
Supervised methods for 3D anatomy segmentation demonstrate superior performance but are often limited by the availability of annotated data. This limitation has led to a growing interest in self-supervised approaches in tandem with the abundance of available un-annotated data. Slice propagation has emerged as an self-supervised approach that leverages slice registration as a self-supervised task to achieve full anatomy segmentation with minimal supervision. This approach significantly reduces the need for domain expertise, time, and the cost associated with building fully annotated datasets required for training segmentation networks. However, this shift toward reduced supervision via deterministic networks raises concerns about the trustworthiness and reliability of predictions, especially when compared with more accurate supervised approaches. To address this concern, we propose the integration of calibrated uncertainty quantification (UQ) into slice propagation methods, providing insights into the model's predictive reliability and confidence levels. Incorporating uncertainty measures enhances user confidence in self-supervised approaches, thereby improving their practical applicability. We conducted experiments on three datasets for 3D abdominal segmentation using five UQ methods. The results illustrate that incorporating UQ improves not only model trustworthiness, but also segmentation accuracy. Furthermore, our analysis reveals various failure modes of slice propagation methods that might not be immediately apparent to end-users. This study opens up new research avenues to improve the accuracy and trustworthiness of slice propagation methods.