 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reparo: Loss-Resilient Generative Codec for Video Conferencing
May 23, 2023
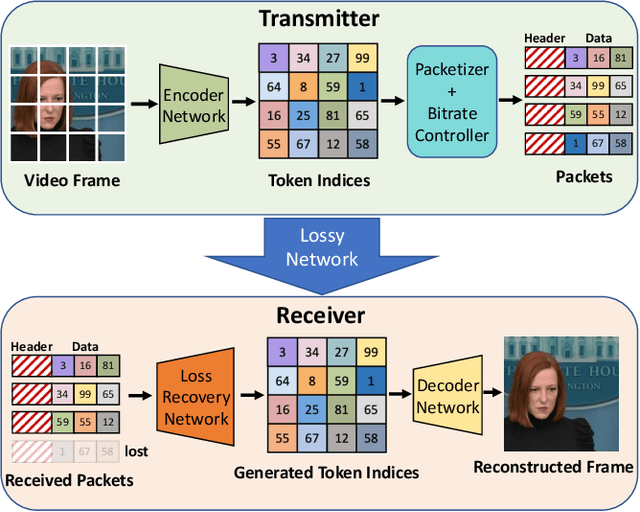

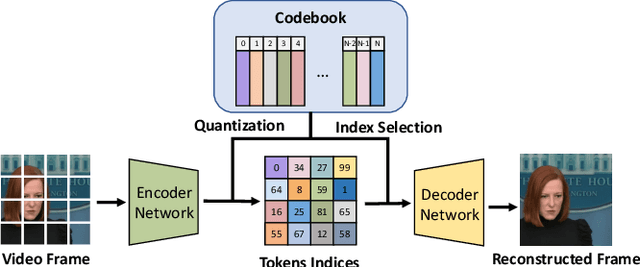
Loss of packets in video conferencing often results in poor quality and video freezing. Attempting to retransmit the lost packets is usually not practical due to the requirement for real-time playback. Using Forward Error Correction (FEC) to recover the lost packets is challenging since it is difficult to determine the appropriate level of redundancy. In this paper, we propose a framework called Reparo for creating loss-resilient video conferencing using generative deep learning models. Our approach involves generating missing information when a frame or part of a frame is lost. This generation is conditioned on the data received so far, and the model's knowledge of how people look, dress, and interact in the visual world. Our experiments on publicly available video conferencing datasets show that Reparo outperforms state-of-the-art FEC-based video conferencing in terms of both video quality (measured by PSNR) and video freezes.
Error Detection for Text-to-SQL Semantic Parsing
May 23, 2023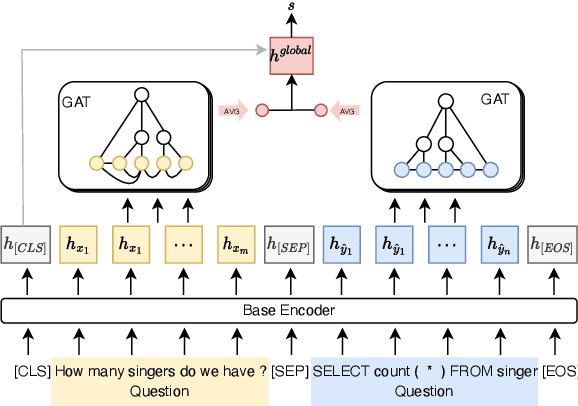

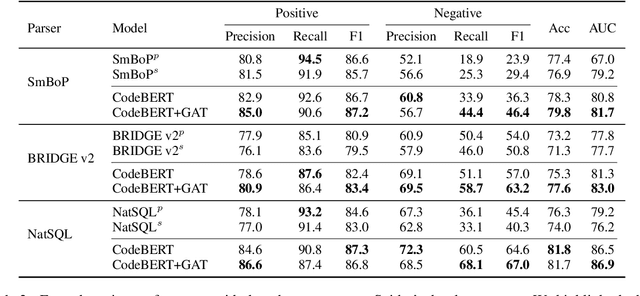
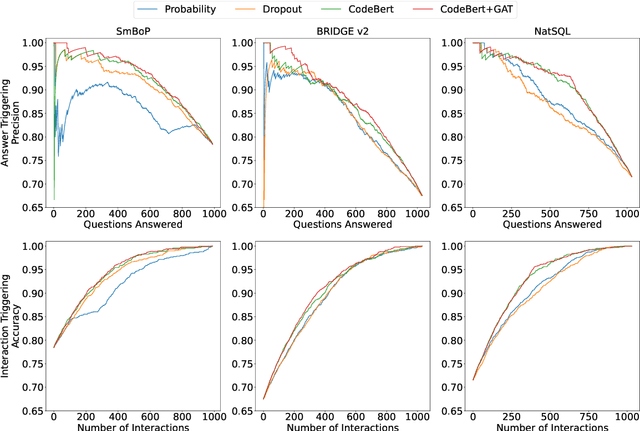
Despite remarkable progress in text-to-SQL semantic parsing in recent years, the performance of existing parsers is still far from perfect. At the same time, modern deep learning based text-to-SQL parsers are often over-confident and thus casting doubt on their trustworthiness when deployed for real use. To that end, we propose to build a parser-independent error detection model for text-to-SQL semantic parsing. The proposed model is based on pre-trained language model of code and is enhanced with structural features learned by graph neural networks. We train our model on realistic parsing errors collected from a cross-domain setting. Experiments with three strong text-to-SQL parsers featuring different decoding mechanisms show that our approach outperforms parser-dependent uncertainty metrics and could effectively improve the performance and usability of text-to-SQL semantic parsers regardless of their architectures.
Implementation of Lenia as a Reaction-Diffusion System
May 23, 2023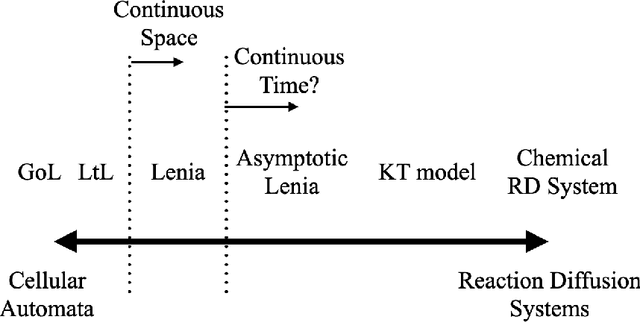
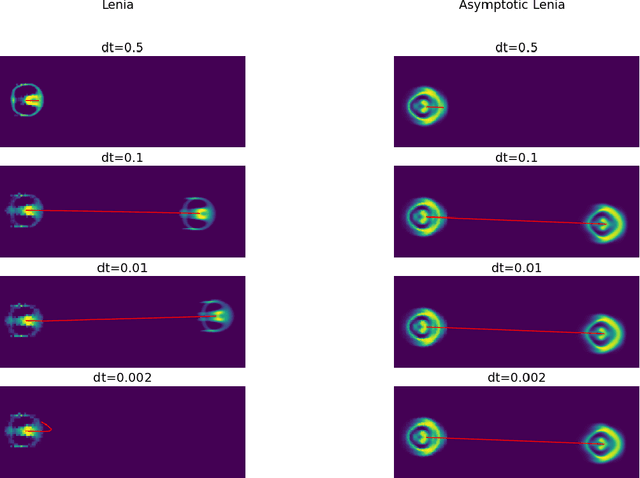
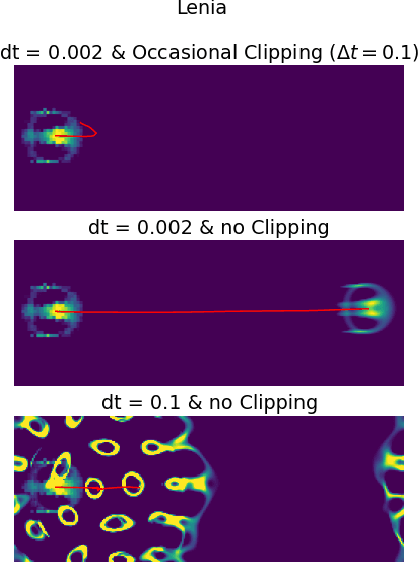
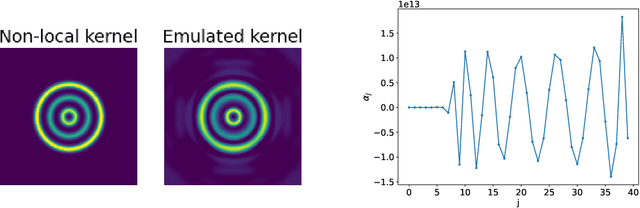
The relationship between reaction-diffusion (RD) systems, characterized by continuous spatiotemporal states, and cellular automata (CA), marked by discrete spatiotemporal states, remains poorly understood. This paper delves into this relationship through an examination of a recently developed CA known as Lenia. We demonstrate that asymptotic Lenia, a variant of Lenia, can be comprehensively described by differential equations, and, unlike the original Lenia, it is independent of time-step ticks. Further, we establish that this formulation is mathematically equivalent to a generalization of the kernel-based Turing model (KT model). Stemming from these insights, we establish that asymptotic Lenia can be replicated by an RD system composed solely of diffusion and spatially local reaction terms, resulting in the simulated asymptotic Lenia based on an RD system, or "RD Lenia". However, our RD Lenia cannot be construed as a chemical system since the reaction term fails to satisfy mass-action kinetics.
Towards Stable Test-Time Adaptation in Dynamic Wild World
Feb 24, 2023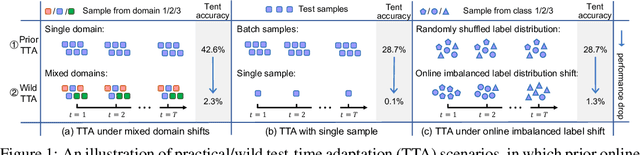

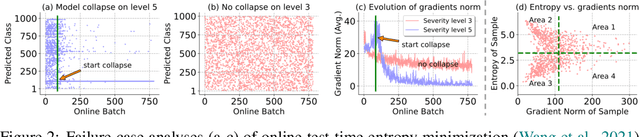

Test-time adaptation (TTA) has shown to be effective at tackling distribution shifts between training and testing data by adapting a given model on test samples. However, the online model updating of TTA may be unstable and this is often a key obstacle preventing existing TTA methods from being deployed in the real world. Specifically, TTA may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, and 3) online imbalanced label distribution shifts, which are quite common in practice. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, \ie, group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases. By digging into the failure cases, we find that certain noisy test samples with large gradients may disturb the model adaption and result in collapsed trivial solutions, \ie, assigning the same class label for all samples. To address the above collapse issue, we propose a sharpness-aware and reliable entropy minimization method, called SAR, for further stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Promising results demonstrate that SAR performs more stably over prior methods and is computationally efficient under the above wild test scenarios.
Label-Efficient Interactive Time-Series Anomaly Detection
Dec 30, 2022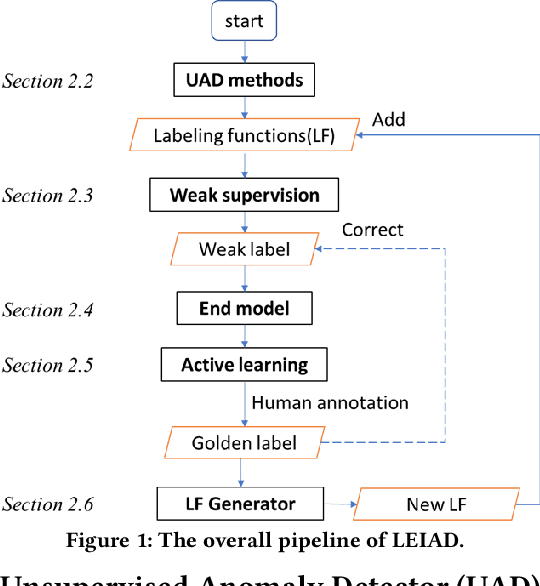
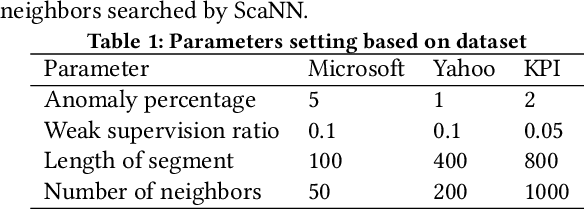
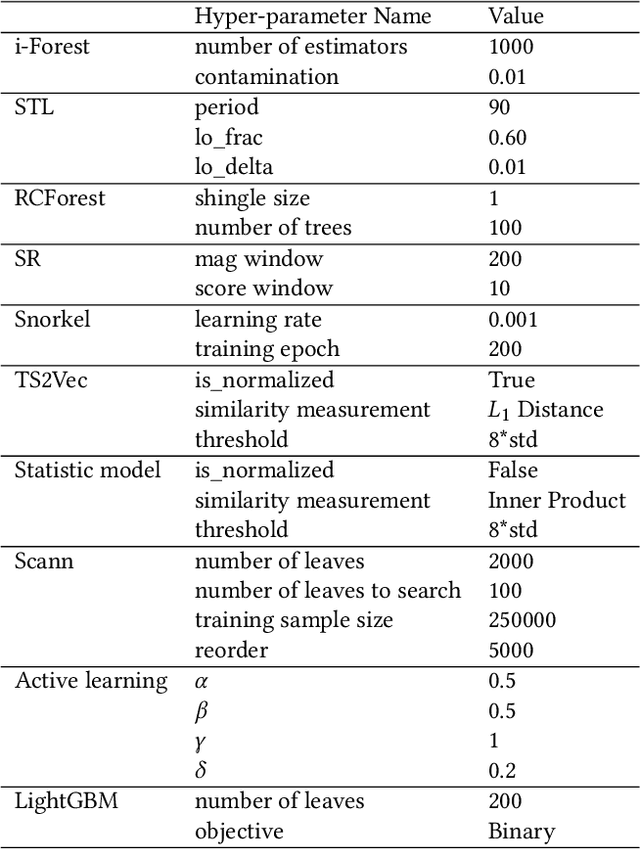
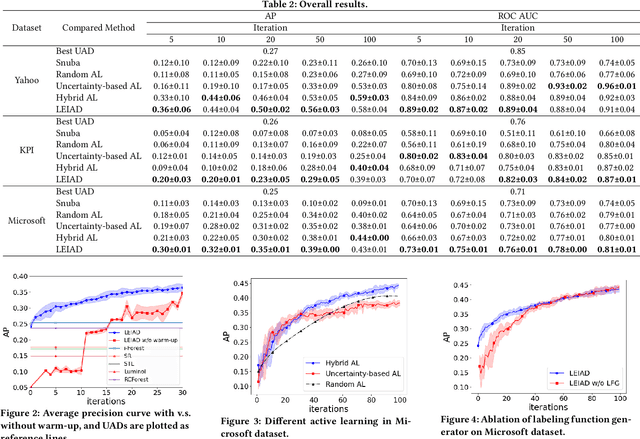
Time-series anomaly detection is an important task and has been widely applied in the industry. Since manual data annotation is expensive and inefficient, most applications adopt unsupervised anomaly detection methods, but the results are usually sub-optimal and unsatisfactory to end customers. Weak supervision is a promising paradigm for obtaining considerable labels in a low-cost way, which enables the customers to label data by writing heuristic rules rather than annotating each instance individually. However, in the time-series domain, it is hard for people to write reasonable labeling functions as the time-series data is numerically continuous and difficult to be understood. In this paper, we propose a Label-Efficient Interactive Time-Series Anomaly Detection (LEIAD) system, which enables a user to improve the results of unsupervised anomaly detection by performing only a small amount of interactions with the system. To achieve this goal, the system integrates weak supervision and active learning collaboratively while generating labeling functions automatically using only a few labeled data. All of these techniques are complementary and can promote each other in a reinforced manner. We conduct experiments on three time-series anomaly detection datasets, demonstrating that the proposed system is superior to existing solutions in both weak supervision and active learning areas. Also, the system has been tested in a real scenario in industry to show its practicality.
Knowledge-Design: Pushing the Limit of Protein Deign via Knowledge Refinement
May 25, 2023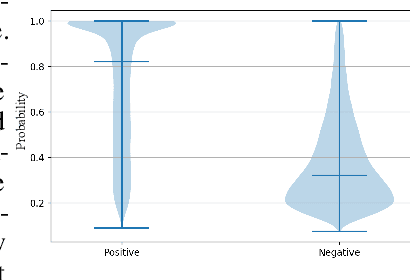
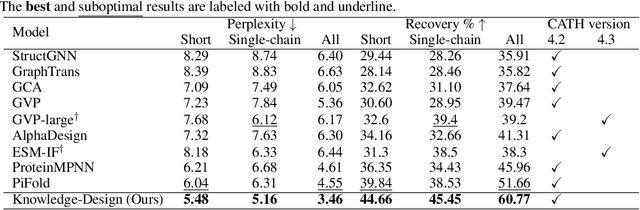
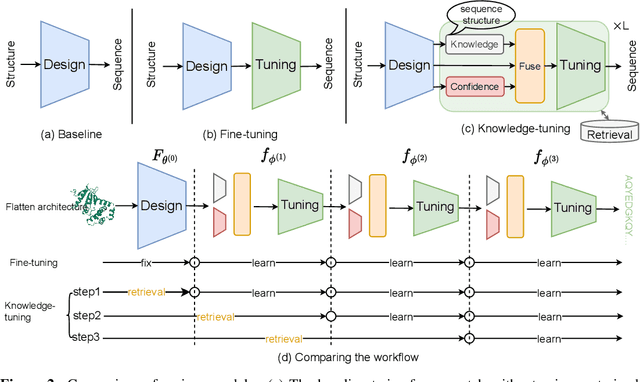
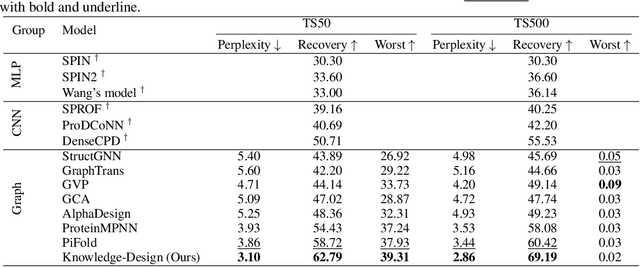
Recent studies have shown competitive performance in protein design that aims to find the amino acid sequence folding into the desired structure. However, most of them disregard the importance of predictive confidence, fail to cover the vast protein space, and do not incorporate common protein knowledge. After witnessing the great success of pretrained models on diverse protein-related tasks and the fact that recovery is highly correlated with confidence, we wonder whether this knowledge can push the limits of protein design further. As a solution, we propose a knowledge-aware module that refines low-quality residues. We also introduce a memory-retrieval mechanism to save more than 50\% of the training time. We extensively evaluate our proposed method on the CATH, TS50, and TS500 datasets and our results show that our Knowledge-Design method outperforms the previous PiFold method by approximately 9\% on the CATH dataset. Specifically, Knowledge-Design is the first method that achieves 60+\% recovery on CATH, TS50 and TS500 benchmarks. We also provide additional analysis to demonstrate the effectiveness of our proposed method. The code will be publicly available.
Towards Total Online Unsupervised Anomaly Detection and Localization in Industrial Vision
May 25, 2023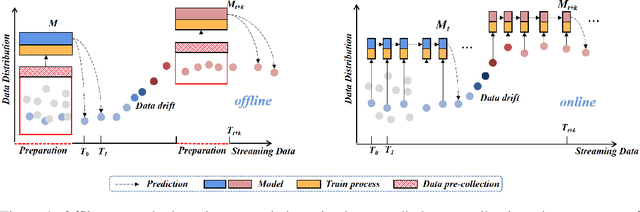

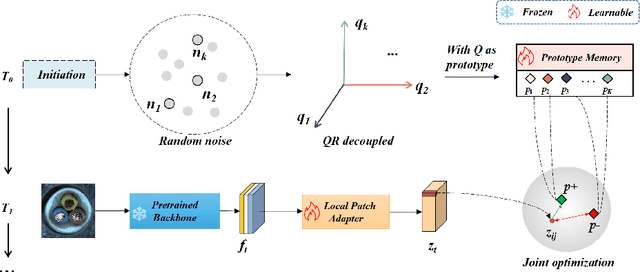
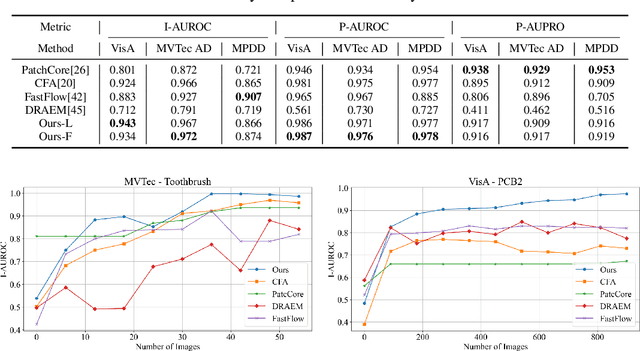
Although existing image anomaly detection methods yield impressive results, they are mostly an offline learning paradigm that requires excessive data pre-collection, limiting their adaptability in industrial scenarios with online streaming data. Online learning-based image anomaly detection methods are more compatible with industrial online streaming data but are rarely noticed. For the first time, this paper presents a fully online learning image anomaly detection method, namely LeMO, learning memory for online image anomaly detection. LeMO leverages learnable memory initialized with orthogonal random noise, eliminating the need for excessive data in memory initialization and circumventing the inefficiencies of offline data collection. Moreover, a contrastive learning-based loss function for anomaly detection is designed to enable online joint optimization of memory and image target-oriented features. The presented method is simple and highly effective. Extensive experiments demonstrate the superior performance of LeMO in the online setting. Additionally, in the offline setting, LeMO is also competitive with the current state-of-the-art methods and achieves excellent performance in few-shot scenarios.
Enhanced 6D Pose Estimation for Robotic Fruit Picking
May 25, 2023
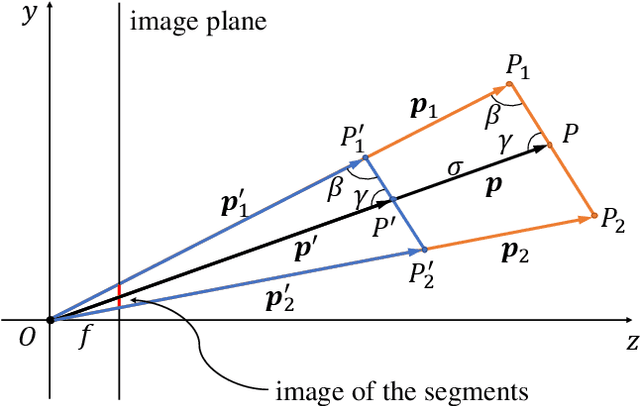

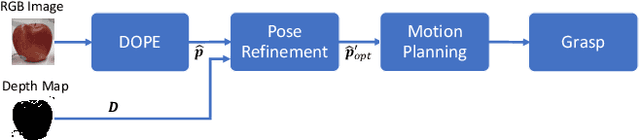
This paper proposes a novel method to refine the 6D pose estimation inferred by an instance-level deep neural network which processes a single RGB image and that has been trained on synthetic images only. The proposed optimization algorithm usefully exploits the depth measurement of a standard RGB-D camera to estimate the dimensions of the considered object, even though the network is trained on a single CAD model of the same object with given dimensions. The improved accuracy in the pose estimation allows a robot to grasp apples of various types and significantly different dimensions successfully; this was not possible using the standard pose estimation algorithm, except for the fruits with dimensions very close to those of the CAD drawing used in the training process. Grasping fresh fruits without damaging each item also demands a suitable grasp force control. A parallel gripper equipped with special force/tactile sensors is thus adopted to achieve safe grasps with the minimum force necessary to lift the fruits without any slippage and any deformation at the same time, with no knowledge of their weight.
Grouping Method for mmWave Massive MIMO System: Exploitation of Angular Multiplexing Gain
May 25, 2023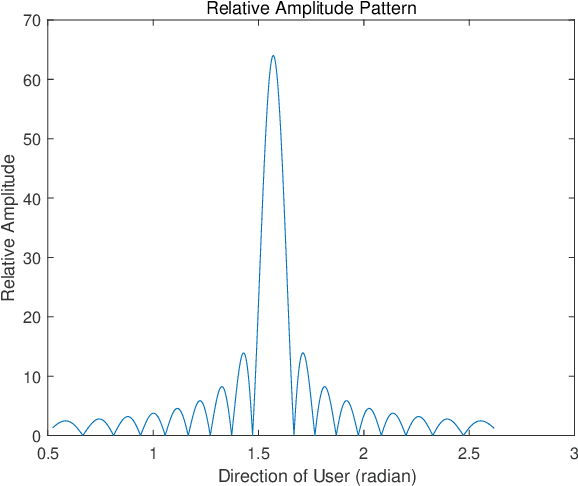
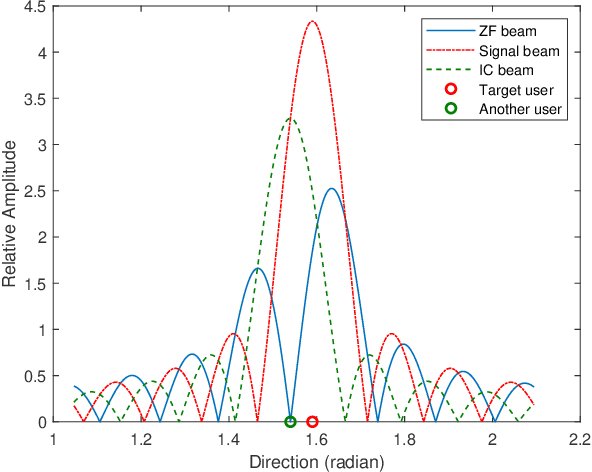
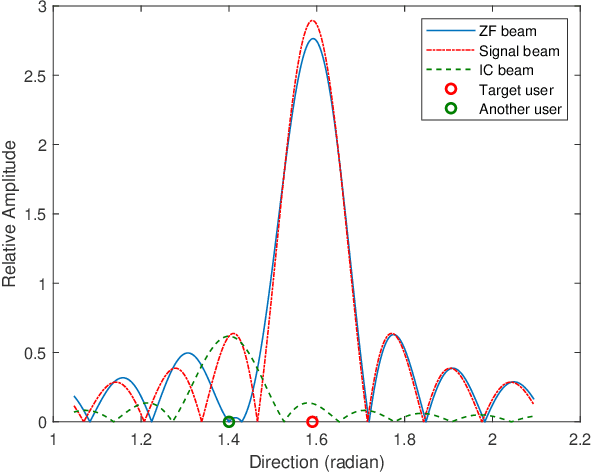
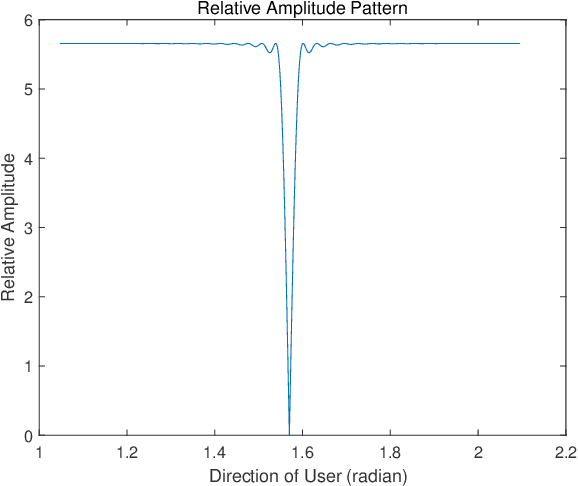
A future millimeter-wave (mmWave) massive multiple-input and multiple-output (MIMO) system may serve hundreds or thousands of users at the same time; thus, research on multiple access technology is particularly important.Moreover, due to the short-wavelength nature of a mmWave, large-scale arrays are easier to implement than microwaves, while their directivity and sparseness make the physical beamforming effect of precoding more prominent.In consideration of the mmWave angle division multiple access (ADMA) system based on precoding, this paper investigates the influence of the angle distribution on system performance, which is denoted as the angular multiplexing gain.Furthermore, inspired by the above research, we transform the ADMA user grouping problem to maximize the system sum-rate into the inter-user angular spacing equalization problem.Then, the form of the optimal solution for the approximate problem is derived, and the corresponding grouping algorithm is proposed.The simulation results demonstrate that the proposed algorithm performs better than the comparison methods.Finally, a complexity analysis also shows that the proposed algorithm has extremely low complexity.
Which Features are Learnt by Contrastive Learning? On the Role of Simplicity Bias in Class Collapse and Feature Suppression
May 25, 2023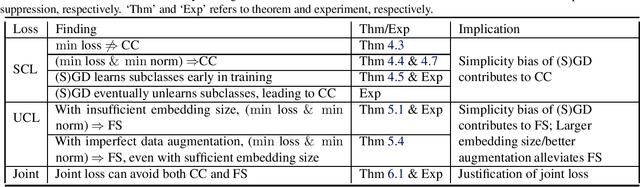
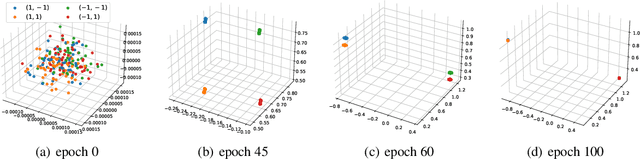
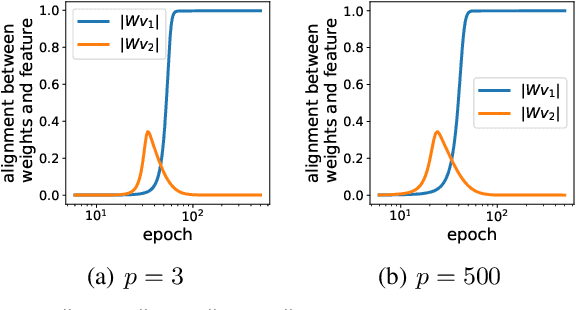
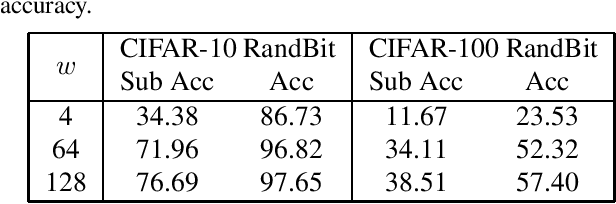
Contrastive learning (CL) has emerged as a powerful technique for representation learning, with or without label supervision. However, supervised CL is prone to collapsing representations of subclasses within a class by not capturing all their features, and unsupervised CL may suppress harder class-relevant features by focusing on learning easy class-irrelevant features; both significantly compromise representation quality. Yet, there is no theoretical understanding of \textit{class collapse} or \textit{feature suppression} at \textit{test} time. We provide the first unified theoretically rigorous framework to determine \textit{which} features are learnt by CL. Our analysis indicate that, perhaps surprisingly, bias of (stochastic) gradient descent towards finding simpler solutions is a key factor in collapsing subclass representations and suppressing harder class-relevant features. Moreover, we present increasing embedding dimensionality and improving the quality of data augmentations as two theoretically motivated solutions to {feature suppression}. We also provide the first theoretical explanation for why employing supervised and unsupervised CL together yields higher-quality representations, even when using commonly-used stochastic gradient methods.