 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
P-vectors: A Parallel-Coupled TDNN/Transformer Network for Speaker Verification
May 24, 2023
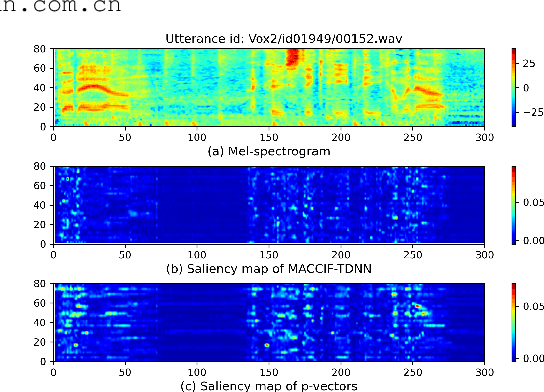
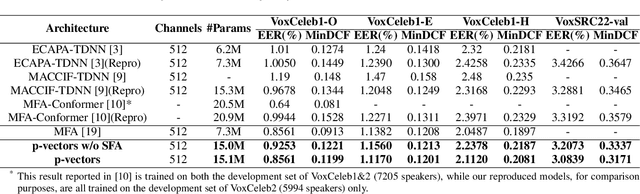
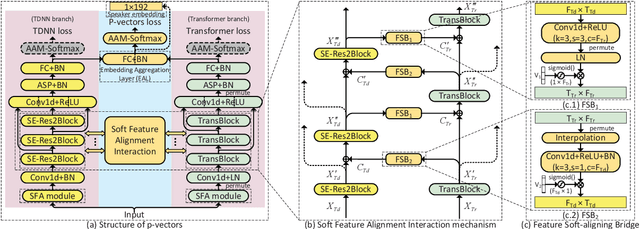

Typically, the Time-Delay Neural Network (TDNN) and Transformer can serve as a backbone for Speaker Verification (SV). Both of them have advantages and disadvantages from the perspective of global and local feature modeling. How to effectively integrate these two style features is still an open issue. In this paper, we explore a Parallel-coupled TDNN/Transformer Network (p-vectors) to replace the serial hybrid networks. The p-vectors allows TDNN and Transformer to learn the complementary information from each other through Soft Feature Alignment Interaction (SFAI) under the premise of preserving local and global features. Also, p-vectors uses the Spatial Frequency-channel Attention (SFA) to enhance the spatial interdependence modeling for input features. Finally, the outputs of dual branches of p-vectors are combined by Embedding Aggregation Layer (EAL). Experiments show that p-vectors outperforms MACCIF-TDNN and MFA-Conformer with relative improvements of 11.5% and 13.9% in EER on VoxCeleb1-O.
A Virtual Reality Tool for Representing, Visualizing and Updating Deep Learning Models
May 24, 2023
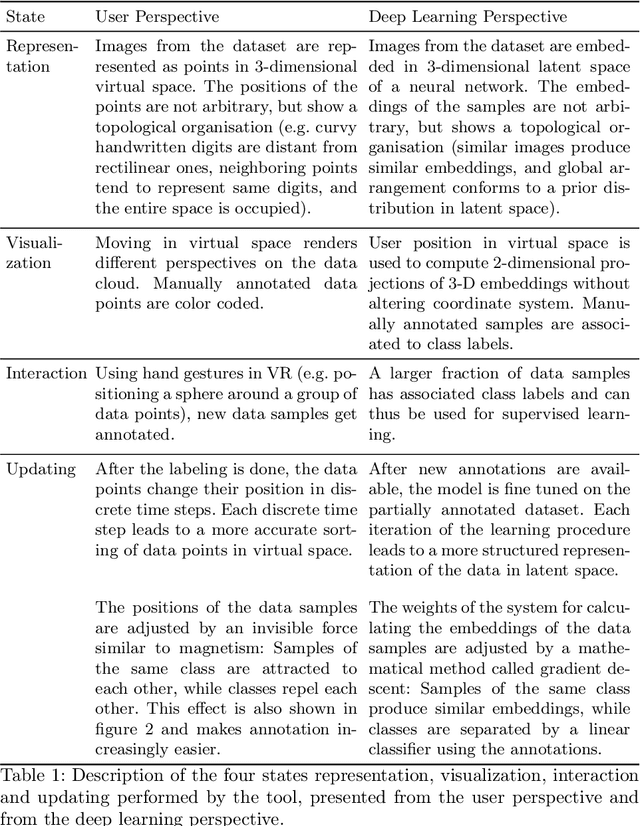
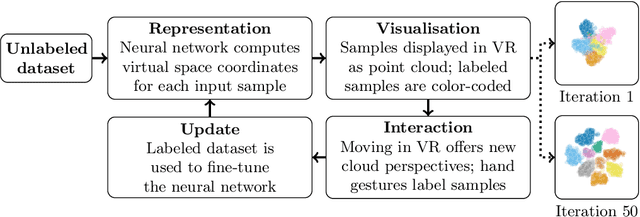
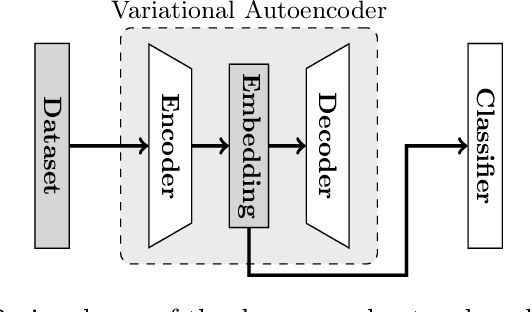
Deep learning is ubiquitous, but its lack of transparency limits its impact on several potential application areas. We demonstrate a virtual reality tool for automating the process of assigning data inputs to different categories. A dataset is represented as a cloud of points in virtual space. The user explores the cloud through movement and uses hand gestures to categorise portions of the cloud. This triggers gradual movements in the cloud: points of the same category are attracted to each other, different groups are pushed apart, while points are globally distributed in a way that utilises the entire space. The space, time, and forces observed in virtual reality can be mapped to well-defined machine learning concepts, namely the latent space, the training epochs and the backpropagation. Our tool illustrates how the inner workings of deep neural networks can be made tangible and transparent. We expect this approach to accelerate the autonomous development of deep learning applications by end users in novel areas.
Contrastive Training of Complex-Valued Autoencoders for Object Discovery
May 24, 2023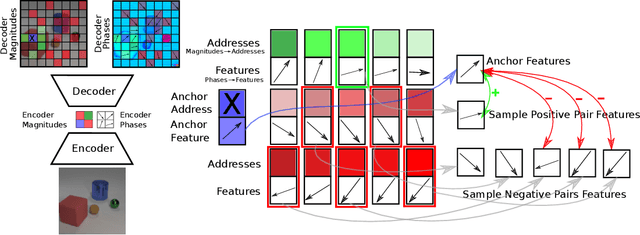
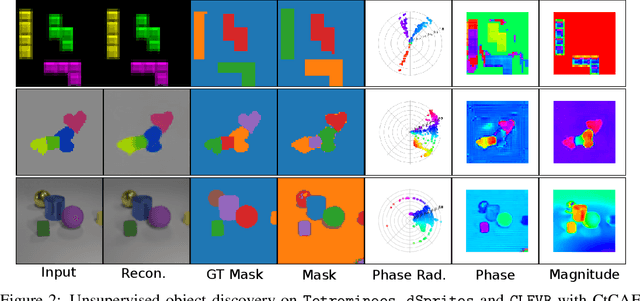
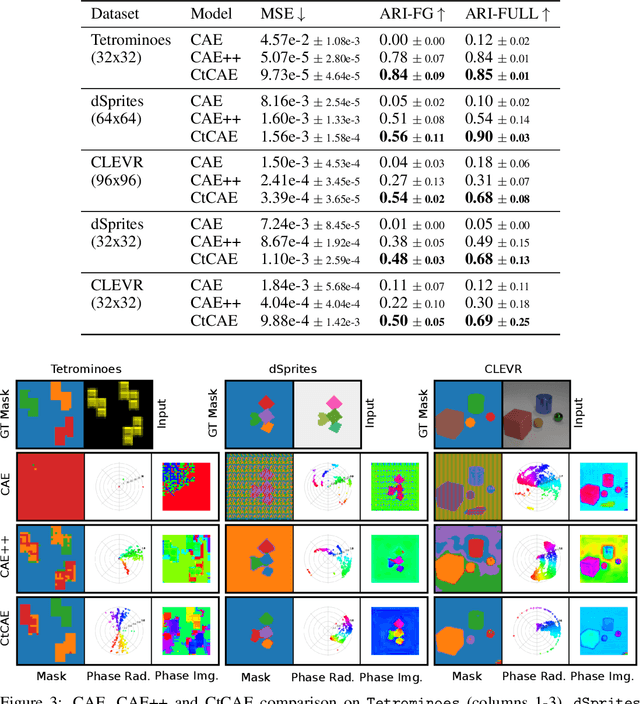
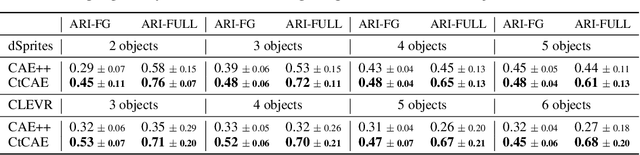
Current state-of-the-art object-centric models use slots and attention-based routing for binding. However, this class of models has several conceptual limitations: the number of slots is hardwired; all slots have equal capacity; training has high computational cost; there are no object-level relational factors within slots. Synchrony-based models in principle can address these limitations by using complex-valued activations which store binding information in their phase components. However, working examples of such synchrony-based models have been developed only very recently, and are still limited to toy grayscale datasets and simultaneous storage of less than three objects in practice. Here we introduce architectural modifications and a novel contrastive learning method that greatly improve the state-of-the-art synchrony-based model. For the first time, we obtain a class of synchrony-based models capable of discovering objects in an unsupervised manner in multi-object color datasets and simultaneously representing more than three objects
ASPER: Answer Set Programming Enhanced Neural Network Models for Joint Entity-Relation Extraction
May 24, 2023
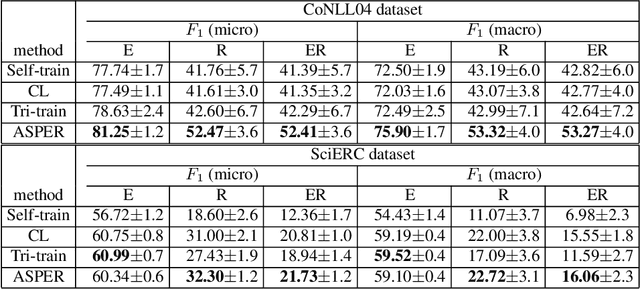
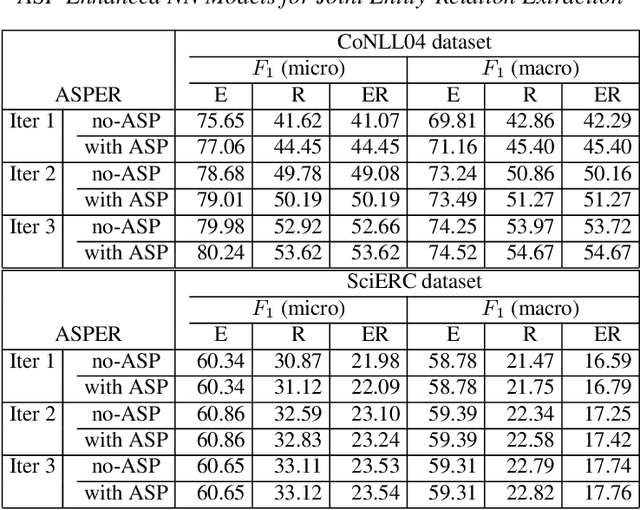
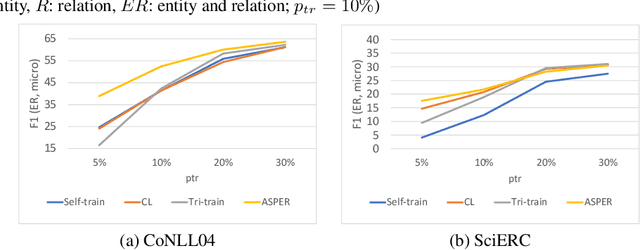
A plethora of approaches have been proposed for joint entity-relation (ER) extraction. Most of these methods largely depend on a large amount of manually annotated training data. However, manual data annotation is time consuming, labor intensive, and error prone. Human beings learn using both data (through induction) and knowledge (through deduction). Answer Set Programming (ASP) has been a widely utilized approach for knowledge representation and reasoning that is elaboration tolerant and adept at reasoning with incomplete information. This paper proposes a new approach, ASP-enhanced Entity-Relation extraction (ASPER), to jointly recognize entities and relations by learning from both data and domain knowledge. In particular, ASPER takes advantage of the factual knowledge (represented as facts in ASP) and derived knowledge (represented as rules in ASP) in the learning process of neural network models. We have conducted experiments on two real datasets and compare our method with three baselines. The results show that our ASPER model consistently outperforms the baselines.
Learning the String Partial Order
May 24, 2023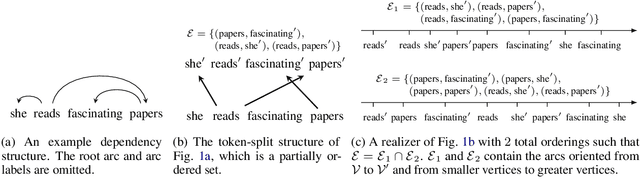
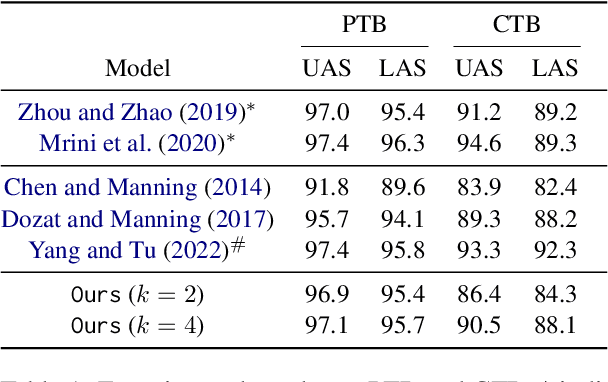
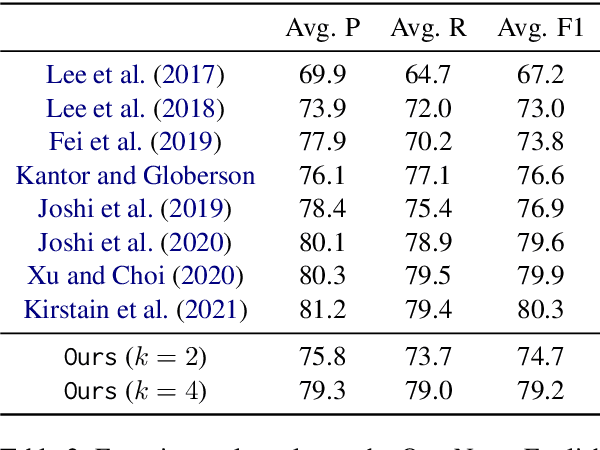
We show that most structured prediction problems can be solved in linear time and space by considering them as partial orderings of the tokens in the input string. Our method computes real numbers for each token in an input string and sorts the tokens accordingly, resulting in as few as 2 total orders of the tokens in the string. Each total order possesses a set of edges oriented from smaller to greater tokens. The intersection of total orders results in a partial order over the set of input tokens, which is then decoded into a directed graph representing the desired structure. Experiments show that our method achieves 95.4 LAS and 96.9 UAS by using an intersection of 2 total orders, 95.7 LAS and 97.1 UAS with 4 on the English Penn Treebank dependency parsing benchmark. Our method is also the first linear-complexity coreference resolution model and achieves 79.2 F1 on the English OntoNotes benchmark, which is comparable with state of the art.
Discounting in Strategy Logic
May 24, 2023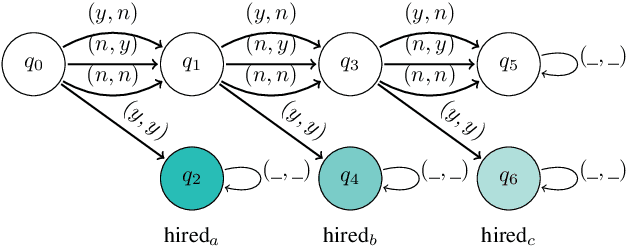
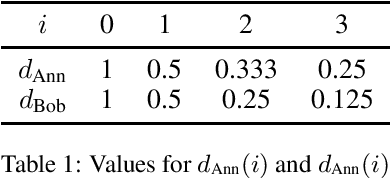
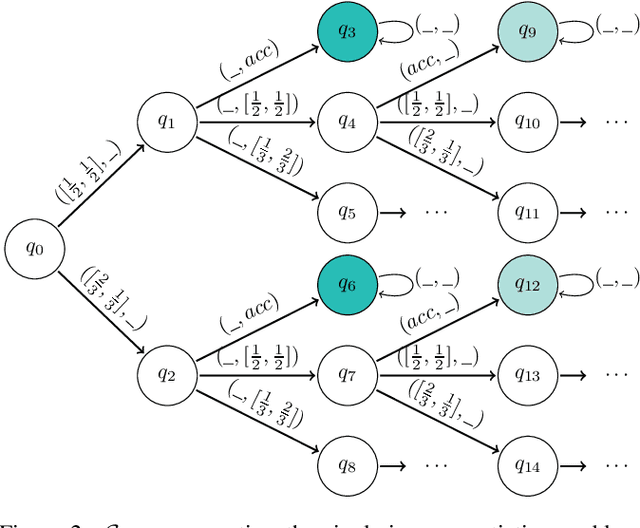
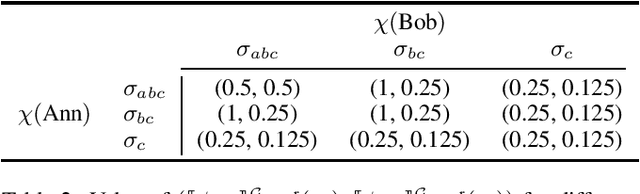
Discounting is an important dimension in multi-agent systems as long as we want to reason about strategies and time. It is a key aspect in economics as it captures the intuition that the far-away future is not as important as the near future. Traditional verification techniques allow to check whether there is a winning strategy for a group of agents but they do not take into account the fact that satisfying a goal sooner is different from satisfying it after a long wait. In this paper, we augment Strategy Logic with future discounting over a set of discounted functions D, denoted SLdisc[D]. We consider "until" operators with discounting functions: the satisfaction value of a specification in SLdisc[D] is a value in [0, 1], where the longer it takes to fulfill requirements, the smaller the satisfaction value is. We motivate our approach with classical examples from Game Theory and study the complexity of model-checking SLdisc[D]-formulas.
PLCMOS -- a data-driven non-intrusive metric for the evaluation of packet loss concealment algorithms
May 24, 2023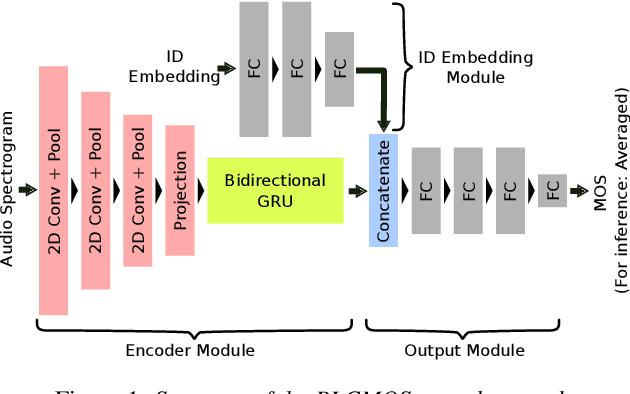
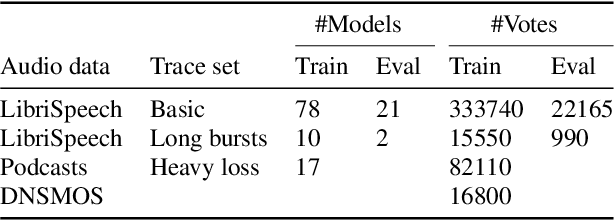
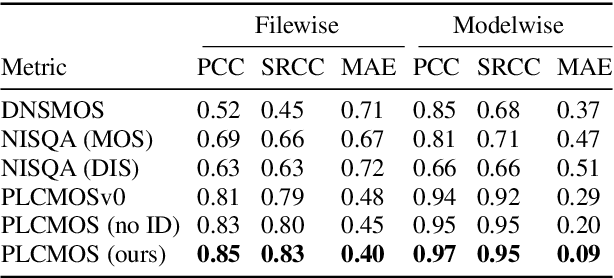
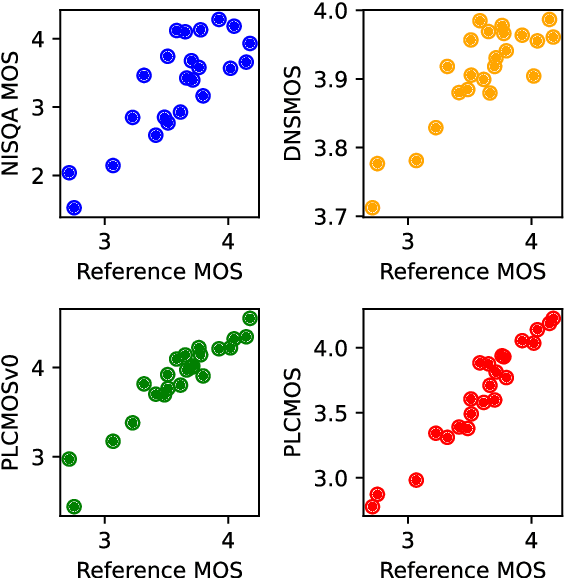
Speech quality assessment is a problem for every researcher working on models that produce or process speech. Human subjective ratings, the gold standard in speech quality assessment, are expensive and time-consuming to acquire in a quantity that is sufficient to get reliable data, while automated objective metrics show a low correlation with gold standard ratings. This paper presents PLCMOS, a non-intrusive data-driven tool for generating a robust, accurate estimate of the mean opinion score a human rater would assign an audio file that has been processed by being transmitted over a degraded packet-switched network with missing packets being healed by a packet loss concealment algorithm. Our new model shows a model-wise Pearson's correlation of ~0.97 and rank correlation of ~0.95 with human ratings, substantially above all other available intrusive and non-intrusive metrics. The model is released as an ONNX model for other researchers to use when building PLC systems.
Real-Time Navigation for Autonomous Surface Vehicles In Ice-Covered Waters
Feb 24, 2023
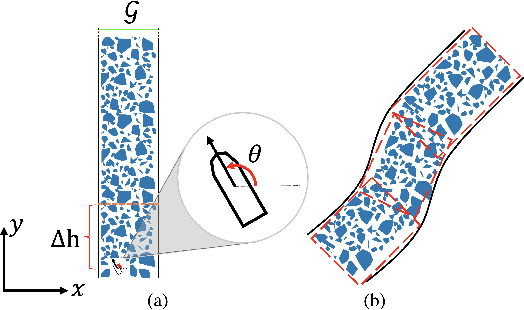
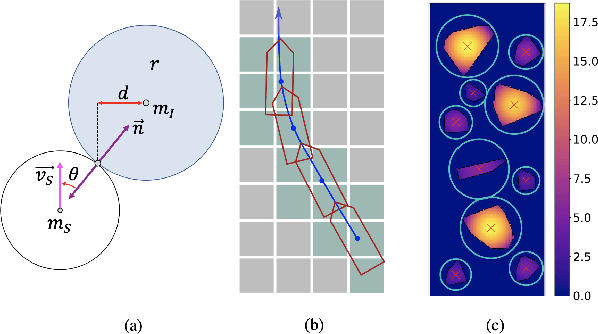
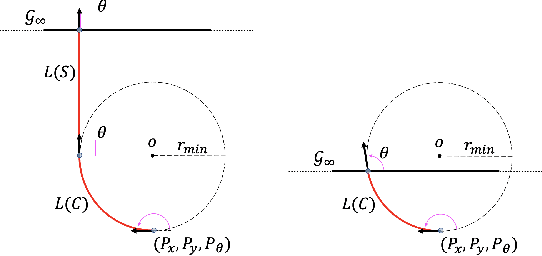
Vessel transit in ice-covered waters poses unique challenges in safe and efficient motion planning. When the concentration of ice is high, it may not be possible to find collision-free trajectories. Instead, ice can be pushed out of the way if it is small or if contact occurs near the edge of the ice. In this work, we propose a real-time navigation framework that minimizes collisions with ice and distance travelled by the vessel. We exploit a lattice-based planner with a cost that captures the ship interaction with ice. To address the dynamic nature of the environment, we plan motion in a receding horizon manner based on updated vessel and ice state information. Further, we present a novel planning heuristic for evaluating the cost-to-go, which is applicable to navigation in a channel without a fixed goal location. The performance of our planner is evaluated across several levels of ice concentration both in simulated and in real-world experiments.
Sample-efficient Real-time Planning with Curiosity Cross-Entropy Method and Contrastive Learning
Mar 07, 2023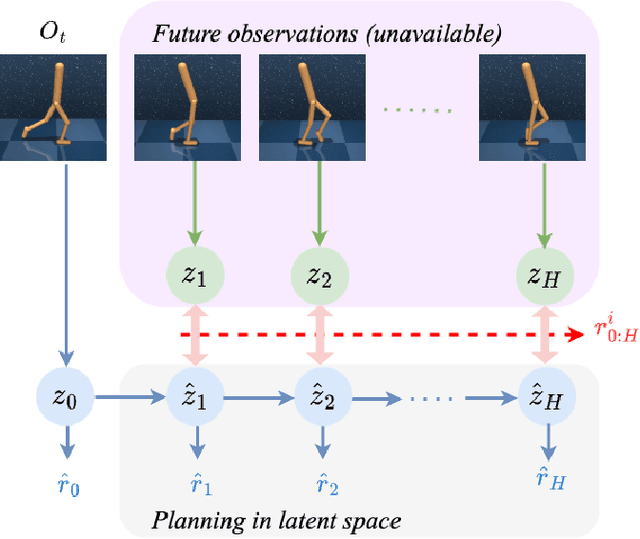
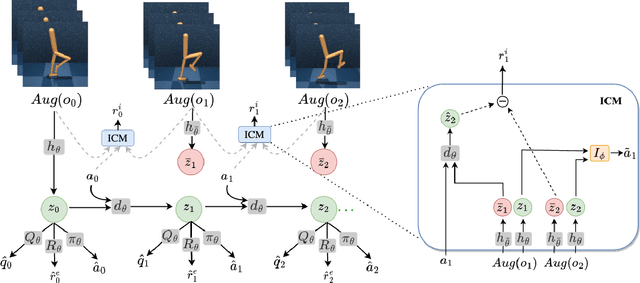

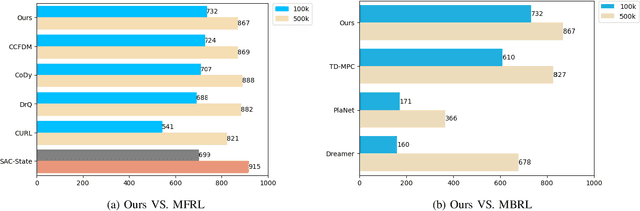
Model-based reinforcement learning (MBRL) with real-time planning has shown great potential in locomotion and manipulation control tasks. However, the existing planning methods, such as the Cross-Entropy Method (CEM), do not scale well to complex high-dimensional environments. One of the key reasons for underperformance is the lack of exploration, as these planning methods only aim to maximize the cumulative extrinsic reward over the planning horizon. Furthermore, planning inside the compact latent space in the absence of observations makes it challenging to use curiosity-based intrinsic motivation. We propose Curiosity CEM (CCEM), an improved version of the CEM algorithm for encouraging exploration via curiosity. Our proposed method maximizes the sum of state-action Q values over the planning horizon, in which these Q values estimate the future extrinsic and intrinsic reward, hence encouraging reaching novel observations. In addition, our model uses contrastive representation learning to efficiently learn latent representations. Experiments on image-based continuous control tasks from the DeepMind Control suite show that CCEM is by a large margin more sample-efficient than previous MBRL algorithms and compares favorably with the best model-free RL methods.
Sensing Aided Uplink Transmission in OTFS ISAC with Joint Parameter Association, Channel Estimation and Signal Detection
May 19, 2023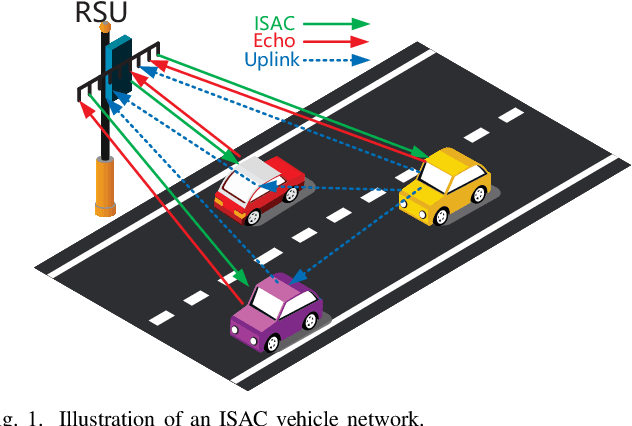
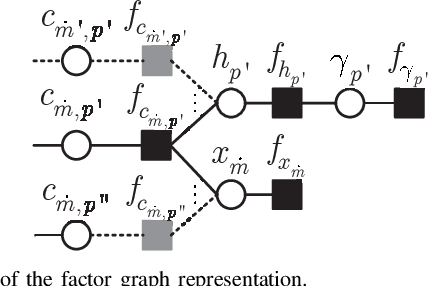
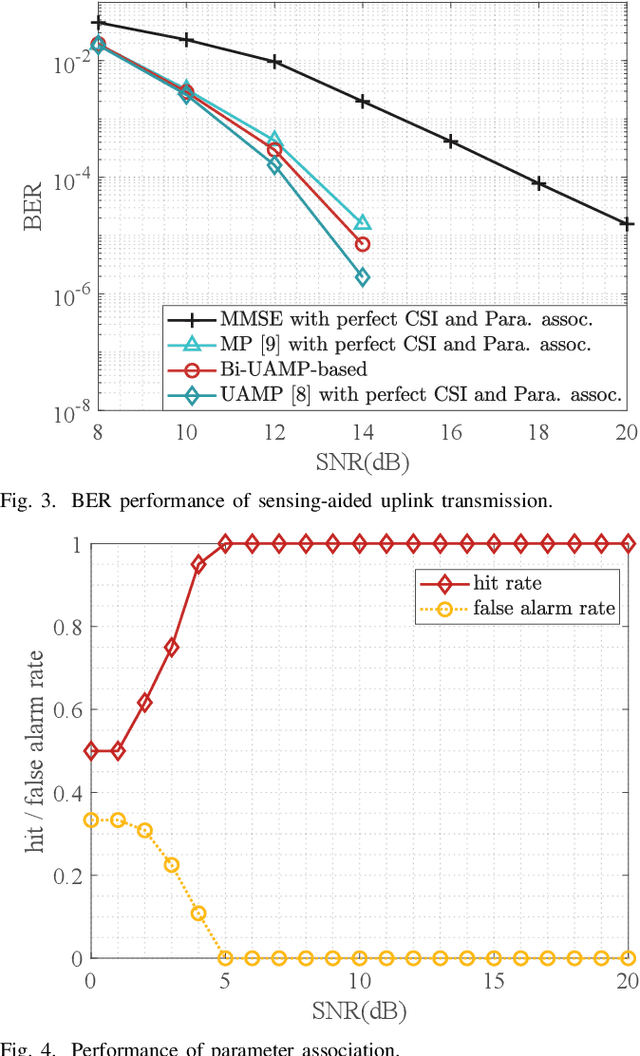
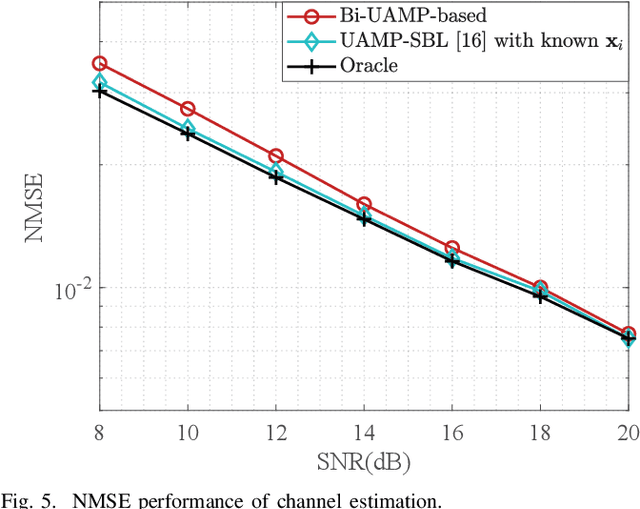
In this work, we study sensing-aided uplink transmission in an integrated sensing and communication (ISAC) vehicular network with the use of orthogonal time frequency space (OTFS) modulation. To exploit sensing parameters for improving uplink communications, the parameters must be first associated with the transmitters, which is a challenging task. We propose a scheme that jointly conducts parameter association, channel estimation and signal detection by formulating it as a constrained bilinear recovery problem. Then we develop a message passing algorithm to solve the problem, leveraging the bilinear unitary approximate message passing (Bi-UAMP) algorithm. Numerical results validate the proposed scheme, which show that relevant performance bounds can be closely approached.