 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dissecting Chain-of-Thought: A Study on Compositional In-Context Learning of MLPs
May 30, 2023
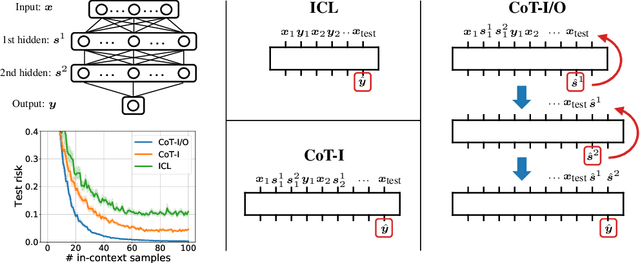
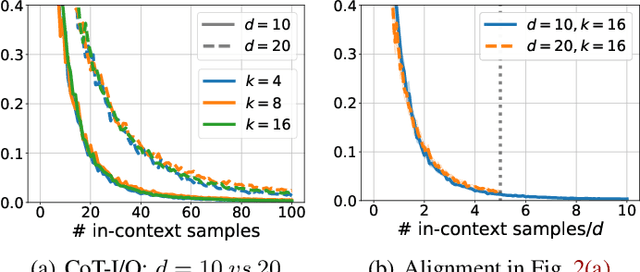
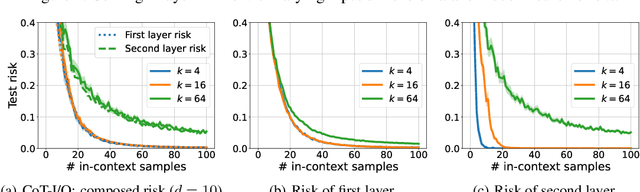
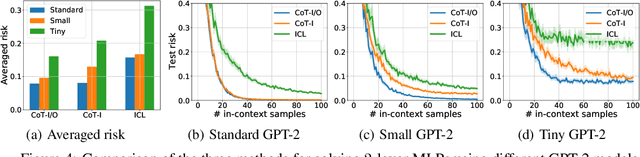
Chain-of-thought (CoT) is a method that enables language models to handle complex reasoning tasks by decomposing them into simpler steps. Despite its success, the underlying mechanics of CoT are not yet fully understood. In an attempt to shed light on this, our study investigates the impact of CoT on the ability of transformers to in-context learn a simple to study, yet general family of compositional functions: multi-layer perceptrons (MLPs). In this setting, we reveal that the success of CoT can be attributed to breaking down in-context learning of a compositional function into two distinct phases: focusing on data related to each step of the composition and in-context learning the single-step composition function. Through both experimental and theoretical evidence, we demonstrate how CoT significantly reduces the sample complexity of in-context learning (ICL) and facilitates the learning of complex functions that non-CoT methods struggle with. Furthermore, we illustrate how transformers can transition from vanilla in-context learning to mastering a compositional function with CoT by simply incorporating an additional layer that performs the necessary filtering for CoT via the attention mechanism. In addition to these test-time benefits, we highlight how CoT accelerates pretraining by learning shortcuts to represent complex functions and how filtering plays an important role in pretraining. These findings collectively provide insights into the mechanics of CoT, inviting further investigation of its role in complex reasoning tasks.
Cooperative Thresholded Lasso for Sparse Linear Bandit
May 30, 2023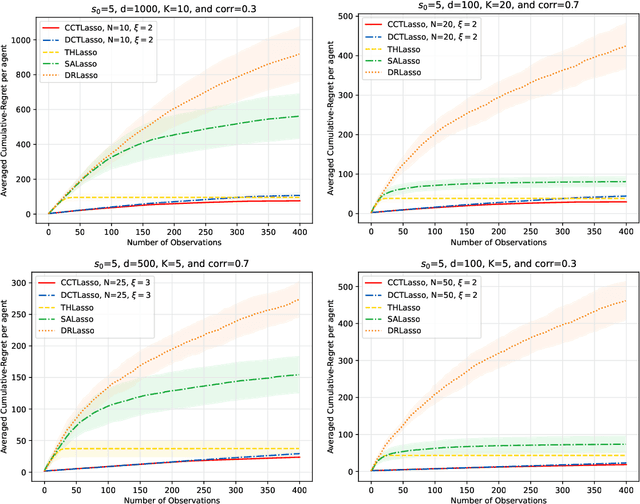
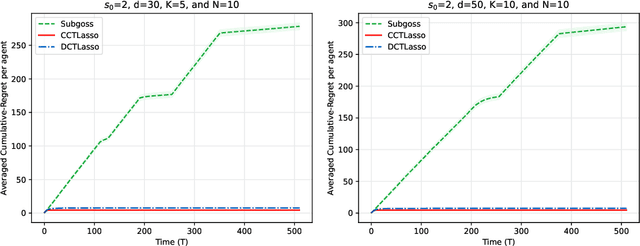
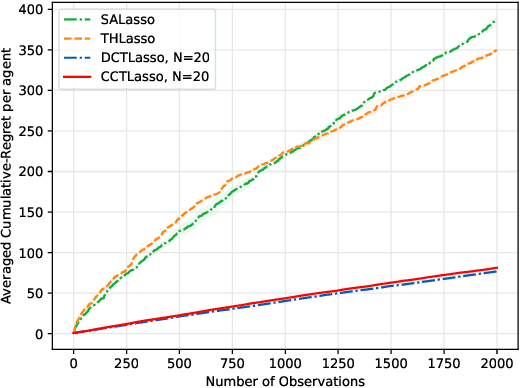
We present a novel approach to address the multi-agent sparse contextual linear bandit problem, in which the feature vectors have a high dimension $d$ whereas the reward function depends on only a limited set of features - precisely $s_0 \ll d$. Furthermore, the learning follows under information-sharing constraints. The proposed method employs Lasso regression for dimension reduction, allowing each agent to independently estimate an approximate set of main dimensions and share that information with others depending on the network's structure. The information is then aggregated through a specific process and shared with all agents. Each agent then resolves the problem with ridge regression focusing solely on the extracted dimensions. We represent algorithms for both a star-shaped network and a peer-to-peer network. The approaches effectively reduce communication costs while ensuring minimal cumulative regret per agent. Theoretically, we show that our proposed methods have a regret bound of order $\mathcal{O}(s_0 \log d + s_0 \sqrt{T})$ with high probability, where $T$ is the time horizon. To our best knowledge, it is the first algorithm that tackles row-wise distributed data in sparse linear bandits, achieving comparable performance compared to the state-of-the-art single and multi-agent methods. Besides, it is widely applicable to high-dimensional multi-agent problems where efficient feature extraction is critical for minimizing regret. To validate the effectiveness of our approach, we present experimental results on both synthetic and real-world datasets.
Edge-MoE: Memory-Efficient Multi-Task Vision Transformer Architecture with Task-level Sparsity via Mixture-of-Experts
May 30, 2023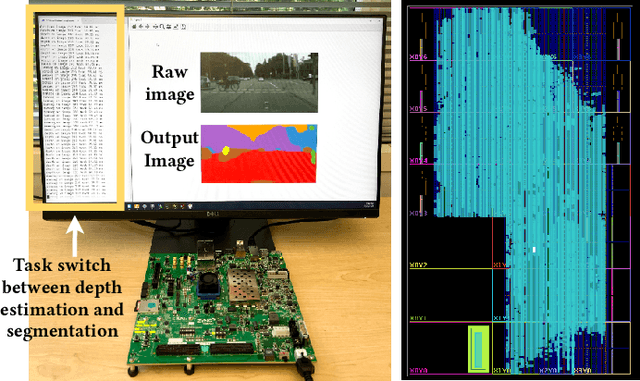


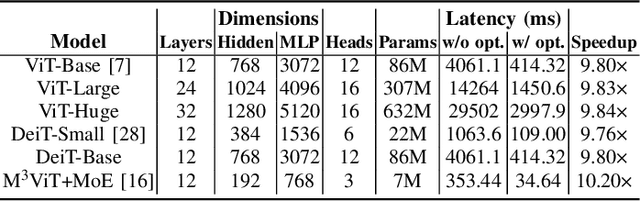
Computer vision researchers are embracing two promising paradigms: Vision Transformers (ViTs) and Multi-task Learning (MTL), which both show great performance but are computation-intensive, given the quadratic complexity of self-attention in ViT and the need to activate an entire large MTL model for one task. M$^3$ViT is the latest multi-task ViT model that introduces mixture-of-experts (MoE), where only a small portion of subnetworks ("experts") are sparsely and dynamically activated based on the current task. M$^3$ViT achieves better accuracy and over 80% computation reduction but leaves challenges for efficient deployment on FPGA. Our work, dubbed Edge-MoE, solves the challenges to introduce the first end-to-end FPGA accelerator for multi-task ViT with a collection of architectural innovations, including (1) a novel reordering mechanism for self-attention, which requires only constant bandwidth regardless of the target parallelism; (2) a fast single-pass softmax approximation; (3) an accurate and low-cost GELU approximation; (4) a unified and flexible computing unit that is shared by almost all computational layers to maximally reduce resource usage; and (5) uniquely for M$^3$ViT, a novel patch reordering method to eliminate memory access overhead. Edge-MoE achieves 2.24x and 4.90x better energy efficiency comparing with GPU and CPU, respectively. A real-time video demonstration is available online, along with our code written using High-Level Synthesis, which will be open-sourced.
Dynamic and Rapid Deep Synthesis of Molecular MRI Signals
May 30, 2023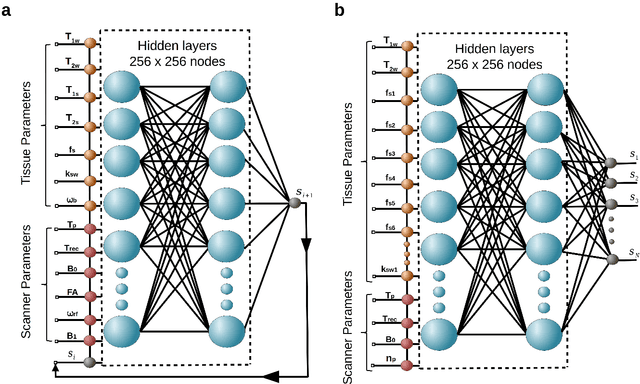

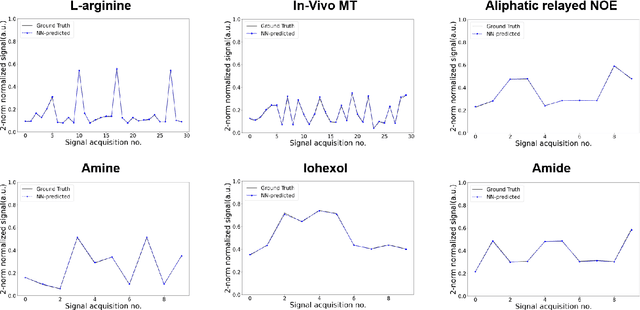
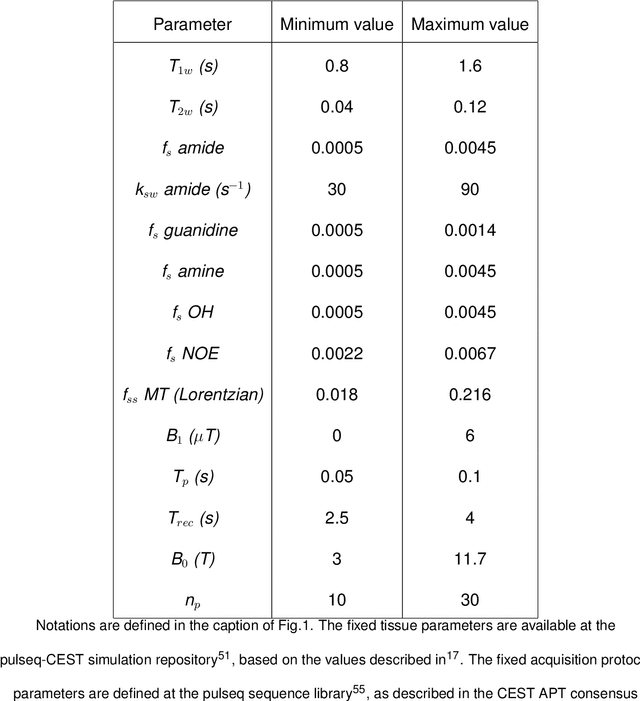
Model-driven analysis of biophysical phenomena is gaining increased attention and utility for medical imaging applications. In magnetic resonance imaging (MRI), the availability of well-established models for describing the relations between the nuclear magnetization, tissue properties, and the externally applied magnetic fields has enabled the prediction of image contrast and served as a powerful tool for designing the imaging protocols that are now routinely used in the clinic. Recently, various advanced imaging techniques have relied on these models for image reconstruction, quantitative tissue parameter extraction, and automatic optimization of acquisition protocols. In molecular MRI, however, the increased complexity of the imaging scenario, where the signals from various chemical compounds and multiple proton pools must be accounted for, results in exceedingly long model simulation times, severely hindering the progress of this approach and its dissemination for various clinical applications. Here, we show that a deep-learning-based system can capture the nonlinear relations embedded in the molecular MRI Bloch-McConnell model, enabling a rapid and accurate generation of biologically realistic synthetic data. The applicability of this simulated data for in-silico, in-vitro, and in-vivo imaging applications is then demonstrated for chemical exchange saturation transfer (CEST) and semisolid macromolecule magnetization transfer (MT) analysis and quantification. The proposed approach yielded 78%-99% acceleration in data synthesis time while retaining excellent agreement with the ground truth (Pearson's r$>$0.99, p$<$0.0001, normalized root mean square error $<$3%).
Real-time LIDAR localization in natural and urban environments
Jan 31, 2023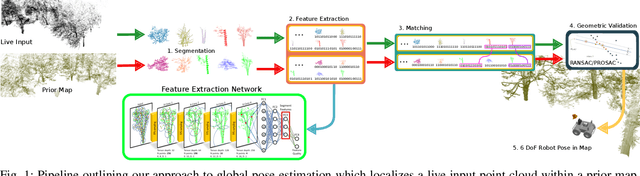
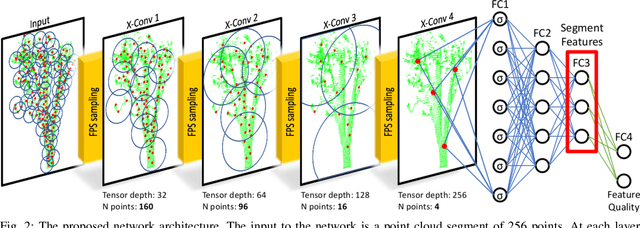
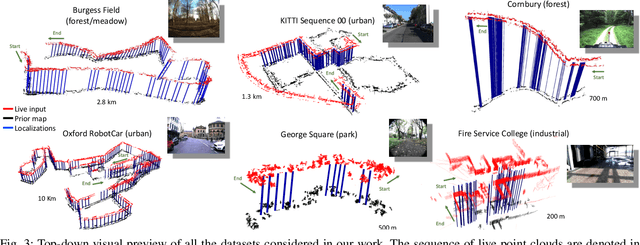

Localization is a key challenge in many robotics applications. In this work we explore LIDAR-based global localization in both urban and natural environments and develop a method suitable for online application. Our approach leverages efficient deep learning architecture capable of learning compact point cloud descriptors directly from 3D data. The method uses an efficient feature space representation of a set of segmented point clouds to match between the current scene and the prior map. We show that down-sampling in the inner layers of the network can significantly reduce computation time without sacrificing performance. We present substantial evaluation of LIDAR-based global localization methods on nine scenarios from six datasets varying between urban, park, forest, and industrial environments. Part of which includes post-processed data from 30 sequences of the Oxford RobotCar dataset, which we make publicly available. Our experiments demonstrate a factor of three reduction of computation, 70% lower memory consumption with marginal loss in localization frequency. The proposed method allows the full pipeline to run on robots with limited computation payload such as drones, quadrupeds, and UGVs as it does not require a GPU at run time.
PORTRAIT: a hybrid aPproach tO cReate extractive ground-TRuth summAry for dIsaster evenT
May 19, 2023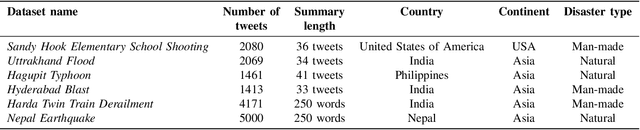


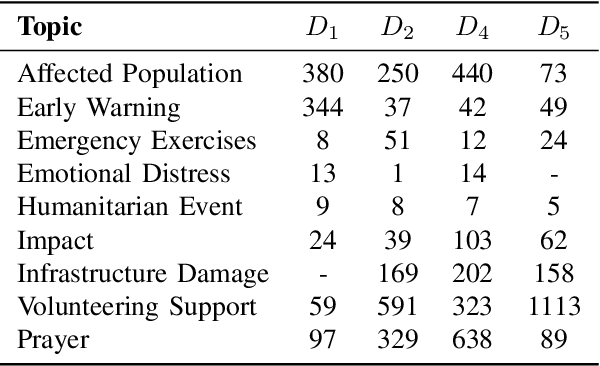
Disaster summarization approaches provide an overview of the important information posted during disaster events on social media platforms, such as, Twitter. However, the type of information posted significantly varies across disasters depending on several factors like the location, type, severity, etc. Verification of the effectiveness of disaster summarization approaches still suffer due to the lack of availability of good spectrum of datasets along with the ground-truth summary. Existing approaches for ground-truth summary generation (ground-truth for extractive summarization) relies on the wisdom and intuition of the annotators. Annotators are provided with a complete set of input tweets from which a subset of tweets is selected by the annotators for the summary. This process requires immense human effort and significant time. Additionally, this intuition-based selection of the tweets might lead to a high variance in summaries generated across annotators. Therefore, to handle these challenges, we propose a hybrid (semi-automated) approach (PORTRAIT) where we partly automate the ground-truth summary generation procedure. This approach reduces the effort and time of the annotators while ensuring the quality of the created ground-truth summary. We validate the effectiveness of PORTRAIT on 5 disaster events through quantitative and qualitative comparisons of ground-truth summaries generated by existing intuitive approaches, a semi-automated approach, and PORTRAIT. We prepare and release the ground-truth summaries for 5 disaster events which consist of both natural and man-made disaster events belonging to 4 different countries. Finally, we provide a study about the performance of various state-of-the-art summarization approaches on the ground-truth summaries generated by PORTRAIT using ROUGE-N F1-scores.
PaLM 2 Technical Report
May 17, 2023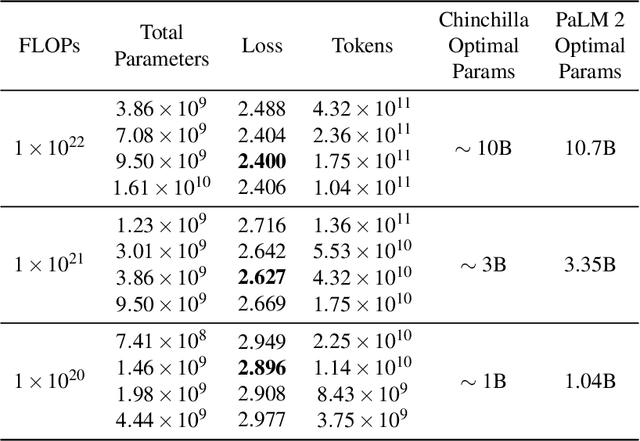

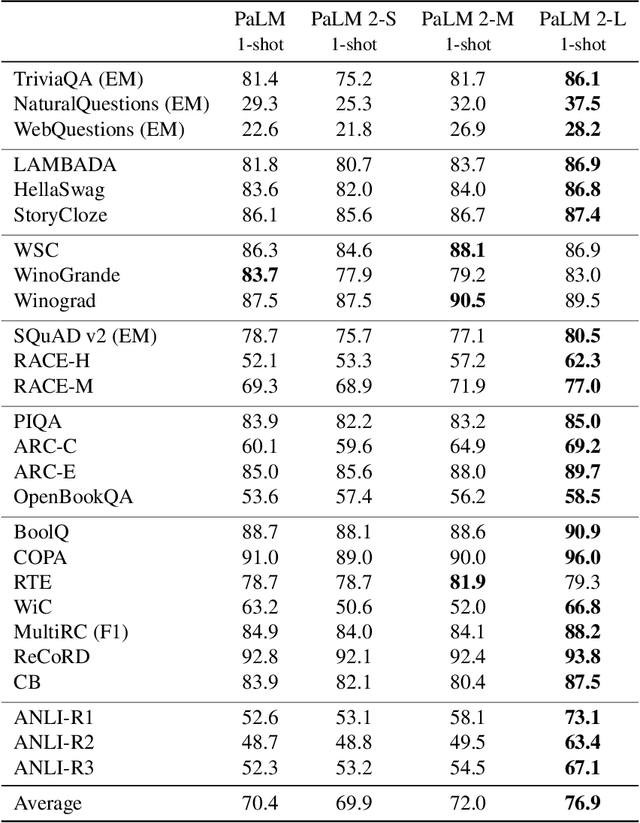

We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Online List Labeling with Predictions
May 17, 2023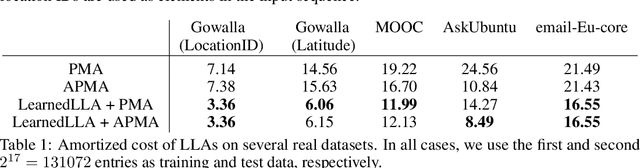
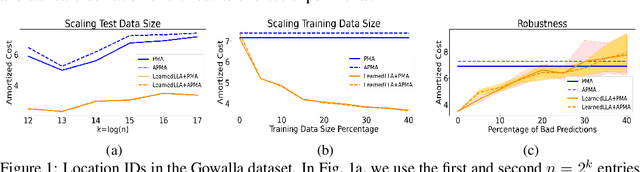
A growing line of work shows how learned predictions can be used to break through worst-case barriers to improve the running time of an algorithm. However, incorporating predictions into data structures with strong theoretical guarantees remains underdeveloped. This paper takes a step in this direction by showing that predictions can be leveraged in the fundamental online list labeling problem. In the problem, n items arrive over time and must be stored in sorted order in an array of size Theta(n). The array slot of an element is its label and the goal is to maintain sorted order while minimizing the total number of elements moved (i.e., relabeled). We design a new list labeling data structure and bound its performance in two models. In the worst-case learning-augmented model, we give guarantees in terms of the error in the predictions. Our data structure provides strong guarantees: it is optimal for any prediction error and guarantees the best-known worst-case bound even when the predictions are entirely erroneous. We also consider a stochastic error model and bound the performance in terms of the expectation and variance of the error. Finally, the theoretical results are demonstrated empirically. In particular, we show that our data structure has strong performance on real temporal data sets where predictions are constructed from elements that arrived in the past, as is typically done in a practical use case.
Iteratively Learning Representations for Unseen Entities with Inter-Rule Correlations
May 17, 2023
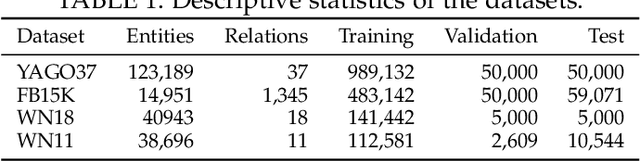
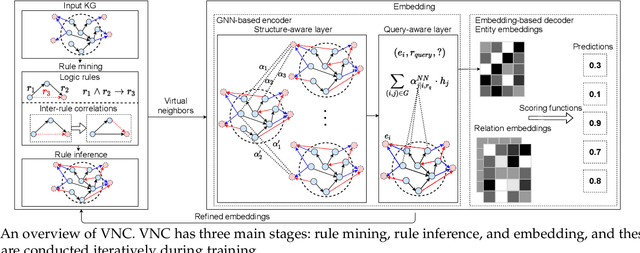
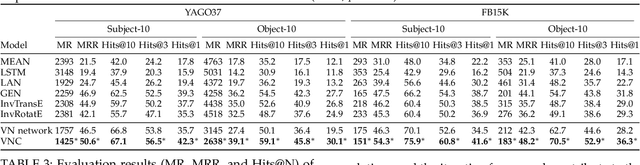
Recent work on knowledge graph completion (KGC) focused on learning embeddings of entities and relations in knowledge graphs. These embedding methods require that all test entities are observed at training time, resulting in a time-consuming retraining process for out-of-knowledge-graph (OOKG) entities. To address this issue, current inductive knowledge embedding methods employ graph neural networks (GNNs) to represent unseen entities by aggregating information of known neighbors. They face three important challenges: (i) data sparsity, (ii) the presence of complex patterns in knowledge graphs (e.g., inter-rule correlations), and (iii) the presence of interactions among rule mining, rule inference, and embedding. In this paper, we propose a virtual neighbor network with inter-rule correlations (VNC) that consists of three stages: (i) rule mining, (ii) rule inference, and (iii) embedding. In the rule mining process, to identify complex patterns in knowledge graphs, both logic rules and inter-rule correlations are extracted from knowledge graphs based on operations over relation embeddings. To reduce data sparsity, virtual neighbors for OOKG entities are predicted and assigned soft labels by optimizing a rule-constrained problem. We also devise an iterative framework to capture the underlying relations between rule learning and embedding learning. In our experiments, results on both link prediction and triple classification tasks show that the proposed VNC framework achieves state-of-the-art performance on four widely-used knowledge graphs. Further analysis reveals that VNC is robust to the proportion of unseen entities and effectively mitigates data sparsity.
Distracting Downpour: Adversarial Weather Attacks for Motion Estimation
May 11, 2023

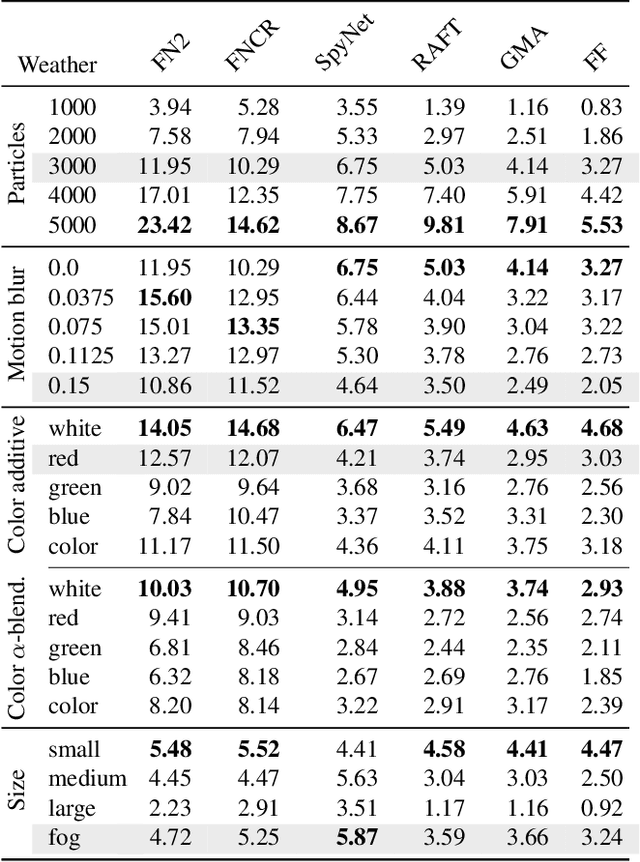
Current adversarial attacks on motion estimation, or optical flow, optimize small per-pixel perturbations, which are unlikely to appear in the real world. In contrast, adverse weather conditions constitute a much more realistic threat scenario. Hence, in this work, we present a novel attack on motion estimation that exploits adversarially optimized particles to mimic weather effects like snowflakes, rain streaks or fog clouds. At the core of our attack framework is a differentiable particle rendering system that integrates particles (i) consistently over multiple time steps (ii) into the 3D space (iii) with a photo-realistic appearance. Through optimization, we obtain adversarial weather that significantly impacts the motion estimation. Surprisingly, methods that previously showed good robustness towards small per-pixel perturbations are particularly vulnerable to adversarial weather. At the same time, augmenting the training with non-optimized weather increases a method's robustness towards weather effects and improves generalizability at almost no additional cost.