 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Multi-step Dynamics Modeling Framework For Autonomous Driving In Multiple Environments
May 03, 2023
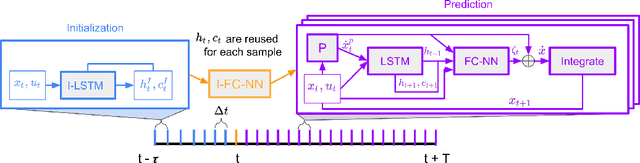
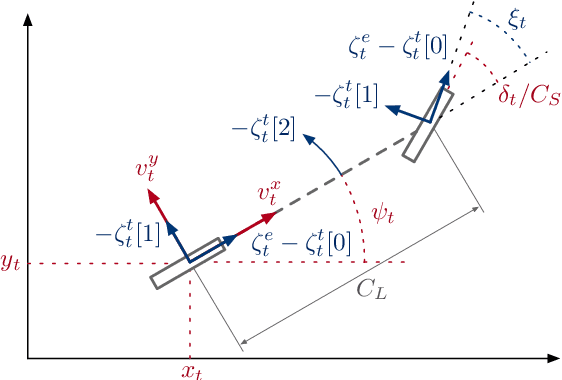

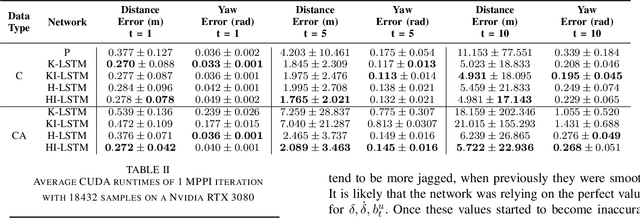
Modeling dynamics is often the first step to making a vehicle autonomous. While on-road autonomous vehicles have been extensively studied, off-road vehicles pose many challenging modeling problems. An off-road vehicle encounters highly complex and difficult-to-model terrain/vehicle interactions, as well as having complex vehicle dynamics of its own. These complexities can create challenges for effective high-speed control and planning. In this paper, we introduce a framework for multistep dynamics prediction that explicitly handles the accumulation of modeling error and remains scalable for sampling-based controllers. Our method uses a specially-initialized Long Short-Term Memory (LSTM) over a limited time horizon as the learned component in a hybrid model to predict the dynamics of a 4-person seating all-terrain vehicle (Polaris S4 1000 RZR) in two distinct environments. By only having the LSTM predict over a fixed time horizon, we negate the need for long term stability that is often a challenge when training recurrent neural networks. Our framework is flexible as it only requires odometry information for labels. Through extensive experimentation, we show that our method is able to predict millions of possible trajectories in real-time, with a time horizon of five seconds in challenging off road driving scenarios.
User-Centric Clustering Under Fairness Scheduling in Cell-Free Massive MIMO
May 15, 2023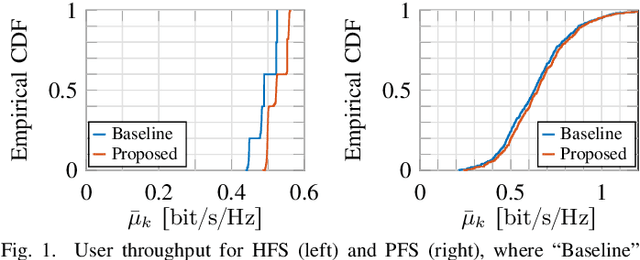
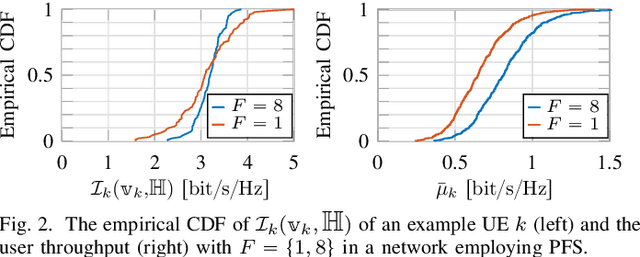
We consider fairness scheduling in a user-centric cell-free massive MIMO network, where $L$ remote radio units, each with $M$ antennas, serve $K_{\rm tot} \approx LM$ user equipments (UEs). Recent results show that the maximum network sum throughput is achieved where $K_{\rm act} \approx \frac{LM}{2}$ UEs are simultaneously active in any given time-frequency slots. However, the number of users $K_{\rm tot}$ in the network is usually much larger. This requires that users are scheduled over the time-frequency resource and achieve a certain throughput rate as an average over the slots. We impose throughput fairness among UEs with a scheduling approach aiming to maximize a concave component-wise non-decreasing network utility function of the per-user throughput rates. In cell-free user-centric networks, the pilot and cluster assignment is usually done for a given set of active users. Combined with fairness scheduling, this requires pilot and cluster reassignment at each scheduling slot, involving an enormous overhead of control signaling exchange between network entities. We propose a fixed pilot and cluster assignment scheme (independent of the scheduling decisions), which outperforms the baseline method in terms of UE throughput, while requiring much less control information exchange between network entities.
Deep-Unfolding for Next-Generation Transceivers
May 15, 2023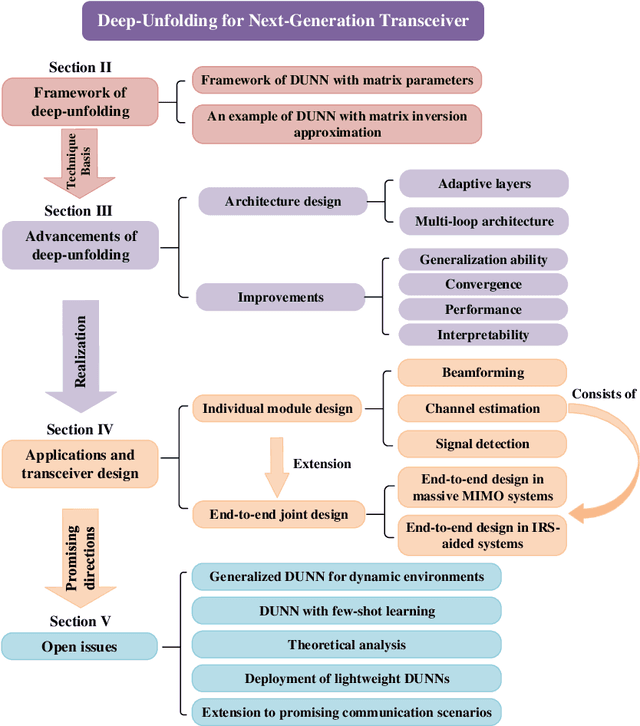
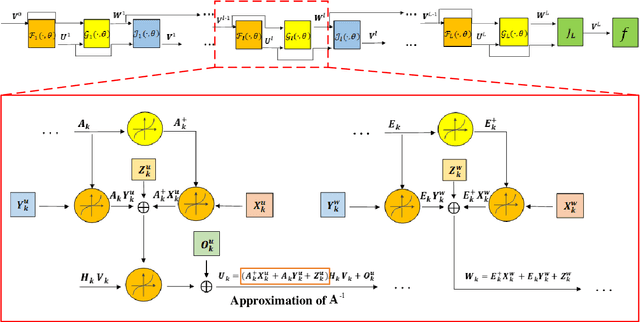
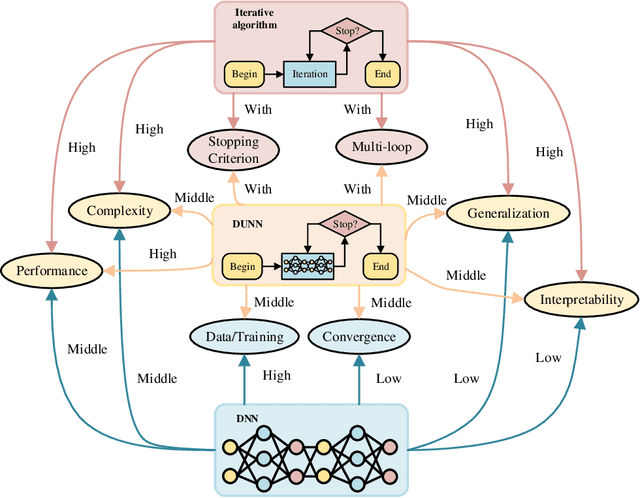
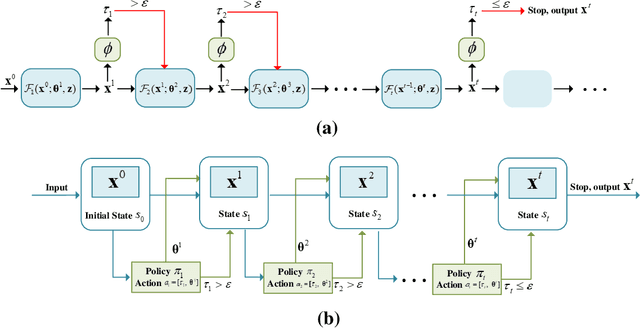
The stringent performance requirements of future wireless networks, such as ultra-high data rates, extremely high reliability and low latency, are spurring worldwide studies on defining the next-generation multiple-input multiple-output (MIMO) transceivers. For the design of advanced transceivers in wireless communications, optimization approaches often leading to iterative algorithms have achieved great success for MIMO transceivers. However, these algorithms generally require a large number of iterations to converge, which entails considerable computational complexity and often requires fine-tuning of various parameters. With the development of deep learning, approximating the iterative algorithms with deep neural networks (DNNs) can significantly reduce the computational time. However, DNNs typically lead to black-box solvers, which requires amounts of data and extensive training time. To further overcome these challenges, deep-unfolding has emerged which incorporates the benefits of both deep learning and iterative algorithms, by unfolding the iterative algorithm into a layer-wise structure analogous to DNNs. In this article, we first go through the framework of deep-unfolding for transceiver design with matrix parameters and its recent advancements. Then, some endeavors in applying deep-unfolding approaches in next-generation advanced transceiver design are presented. Moreover, some open issues for future research are highlighted.
Feature Engineering-Based Detection of Buffer Overflow Vulnerability in Source Code Using Neural Networks
Jun 01, 2023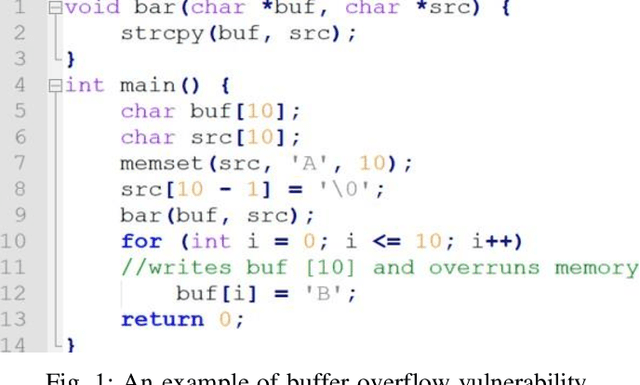
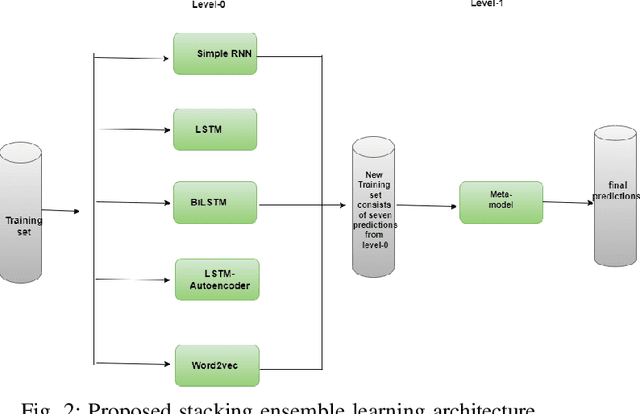
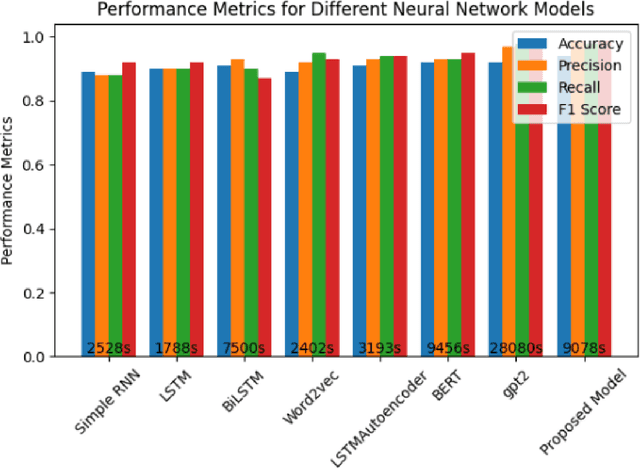
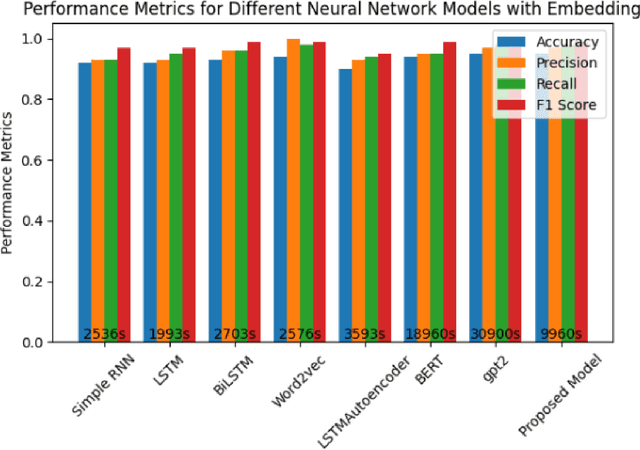
One of the most significant challenges in the field of software code auditing is the presence of vulnerabilities in software source code. Every year, more and more software flaws are discovered, either internally in proprietary code or publicly disclosed. These flaws are highly likely to be exploited and can lead to system compromise, data leakage, or denial of service. To create a large-scale machine learning system for function level vulnerability identification, we utilized a sizable dataset of C and C++ open-source code containing millions of functions with potential buffer overflow exploits. We have developed an efficient and scalable vulnerability detection method based on neural network models that learn features extracted from the source codes. The source code is first converted into an intermediate representation to remove unnecessary components and shorten dependencies. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. Furthermore, we have proposed a neural network model that can overcome issues associated with traditional neural networks. We have used evaluation metrics such as F1 score, precision, recall, accuracy, and total execution time to measure the performance. We have conducted a comparative analysis between results derived from features containing a minimal text representation and semantic and syntactic information.
Dissecting Arbitrary-scale Super-resolution Capability from Pre-trained Diffusion Generative Models
Jun 01, 2023
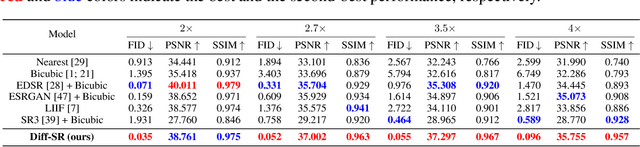
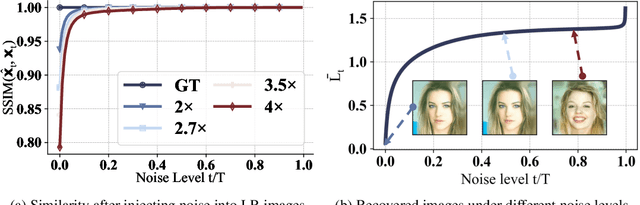
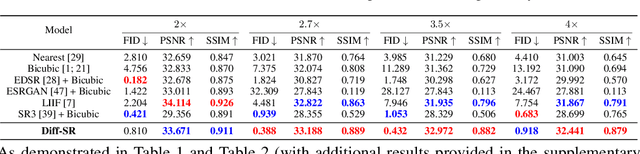
Diffusion-based Generative Models (DGMs) have achieved unparalleled performance in synthesizing high-quality visual content, opening up the opportunity to improve image super-resolution (SR) tasks. Recent solutions for these tasks often train architecture-specific DGMs from scratch, or require iterative fine-tuning and distillation on pre-trained DGMs, both of which take considerable time and hardware investments. More seriously, since the DGMs are established with a discrete pre-defined upsampling scale, they cannot well match the emerging requirements of arbitrary-scale super-resolution (ASSR), where a unified model adapts to arbitrary upsampling scales, instead of preparing a series of distinct models for each case. These limitations beg an intriguing question: can we identify the ASSR capability of existing pre-trained DGMs without the need for distillation or fine-tuning? In this paper, we take a step towards resolving this matter by proposing Diff-SR, a first ASSR attempt based solely on pre-trained DGMs, without additional training efforts. It is motivated by an exciting finding that a simple methodology, which first injects a specific amount of noise into the low-resolution images before invoking a DGM's backward diffusion process, outperforms current leading solutions. The key insight is determining a suitable amount of noise to inject, i.e., small amounts lead to poor low-level fidelity, while over-large amounts degrade the high-level signature. Through a finely-grained theoretical analysis, we propose the Perceptual Recoverable Field (PRF), a metric that achieves the optimal trade-off between these two factors. Extensive experiments verify the effectiveness, flexibility, and adaptability of Diff-SR, demonstrating superior performance to state-of-the-art solutions under diverse ASSR environments.
Cooperative Hardware-Prompt Learning for Snapshot Compressive Imaging
Jun 01, 2023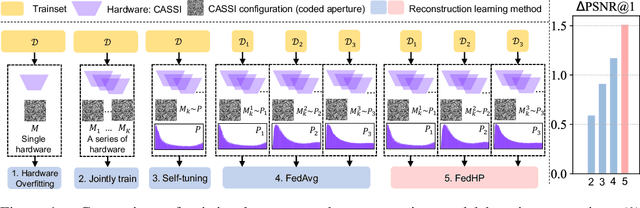
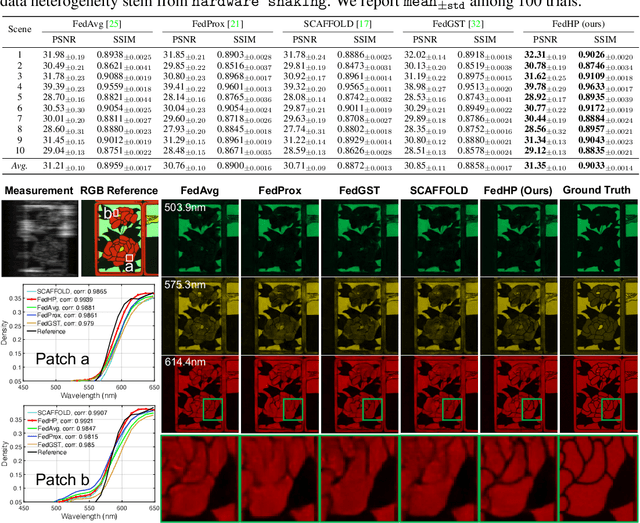
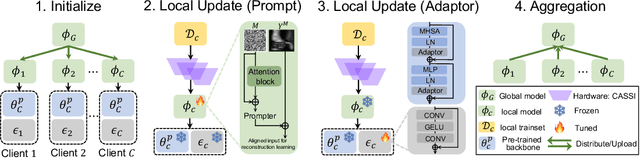
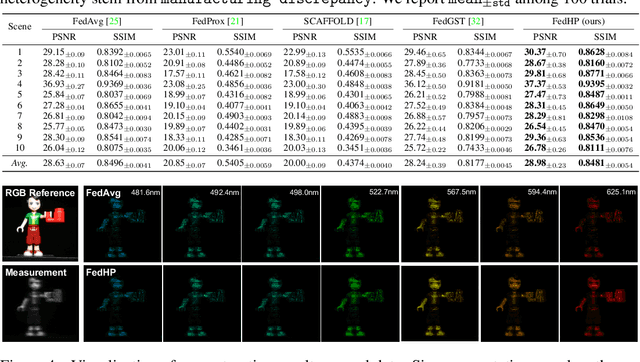
Snapshot compressive imaging emerges as a promising technology for acquiring real-world hyperspectral signals. It uses an optical encoder and compressively produces the 2D measurement, followed by which the 3D hyperspectral data can be retrieved via training a deep reconstruction network. Existing reconstruction models are trained with a single hardware instance, whose performance is vulnerable to hardware perturbation or replacement, demonstrating an overfitting issue to the physical configuration. This defect limits the deployment of pre-trained models since they would suffer from large performance degradation when are assembled to unseen hardware. To better facilitate the reconstruction model with new hardware, previous efforts resort to centralized training by collecting multi-hardware and data, which is impractical when dealing with proprietary assets among institutions. In light of this, federated learning (FL) has become a feasible solution to enable cross-hardware cooperation without breaking privacy. However, the naive FedAvg is subject to client drift upon data heterogeneity owning to the hardware inconsistency. In this work, we tackle this challenge by marrying prompt tuning with FL to snapshot compressive imaging for the first time and propose an federated hardware-prompt learning (FedHP) method. Rather than mitigating the client drift by rectifying the gradients, which only takes effect on the learning manifold but fails to touch the heterogeneity rooted in the input data space, the proposed FedHP globally learns a hardware-conditioned prompter to align the data distribution, which serves as an indicator of the data inconsistency stemming from different pre-defined coded apertures. Extensive experiments demonstrate that the proposed method well coordinates the pre-trained model to indeterminate hardware configurations.
DTAAD: Dual Tcn-Attention Networks for Anomaly Detection in Multivariate Time Series Data
Feb 17, 2023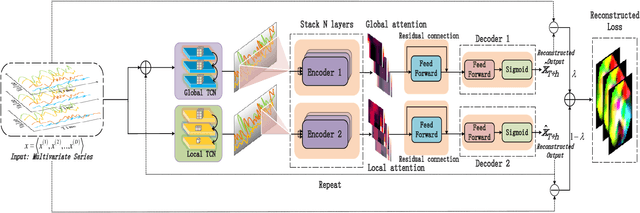
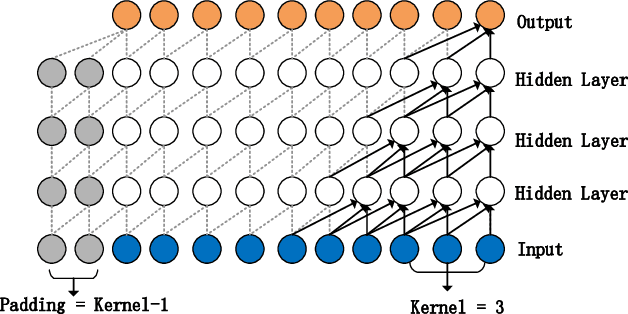
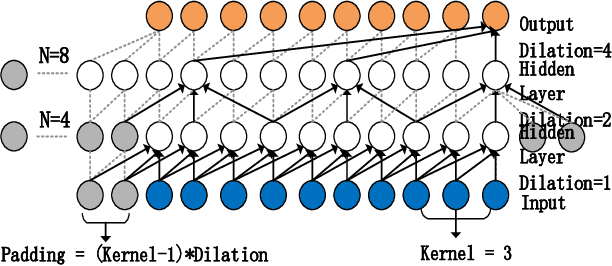
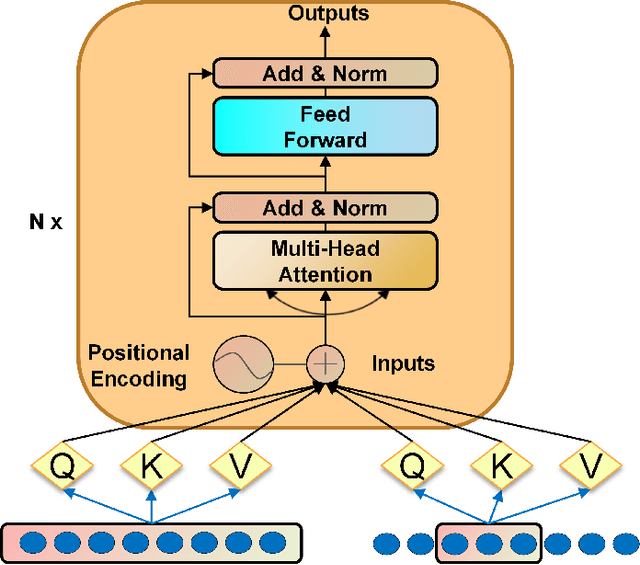
Anomaly detection techniques enable effective anomaly detection and diagnosis in multi-variate time series data, which are of major significance for today's industrial applications. However, establishing an anomaly detection system that can be rapidly and accurately located is a challenging problem due to the lack of outlier tags, the high dimensional complexity of the data, memory bottlenecks in the actual hardware, and the need for fast reasoning. We have proposed an anomaly detection and diagnosis model--DTAAD in this paper, based on Transformer and Dual TCN. Our overall model will be an integrated design in which AR combines AE structures, introducing scaling methods and feedback mechanisms to improve prediction accuracy and expand correlation differences. The Dual TCN-Attention Network(DTA) constructed by us only uses a single layer of Transformer encoder in our baseline experiment, which belongs to an ultra-lightweight model. Our extensive experiments on six publicly datasets validate that DTAAD exceeds current most advanced baseline methods in both detection and diagnostic performance. Specifically, DTAAD improved F1 scores by $8.38\%$, and reduced training time by $99\%$ compared to baseline. The code and training scripts are publicly on GitHub at https://github.com/Yu-Lingrui/DTAAD.
RAPHAEL: Text-to-Image Generation via Large Mixture of Diffusion Paths
May 29, 2023

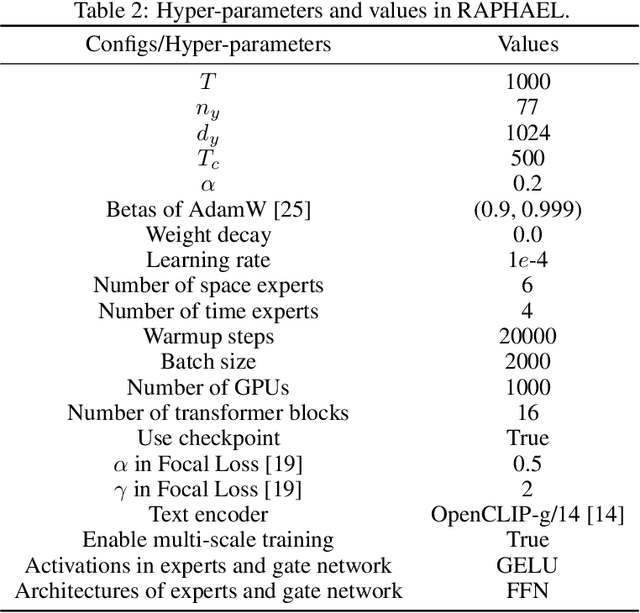
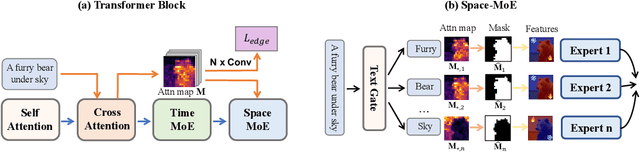
Text-to-image generation has recently witnessed remarkable achievements. We introduce a text-conditional image diffusion model, termed RAPHAEL, to generate highly artistic images, which accurately portray the text prompts, encompassing multiple nouns, adjectives, and verbs. This is achieved by stacking tens of mixture-of-experts (MoEs) layers, i.e., space-MoE and time-MoE layers, enabling billions of diffusion paths (routes) from the network input to the output. Each path intuitively functions as a "painter" for depicting a particular textual concept onto a specified image region at a diffusion timestep. Comprehensive experiments reveal that RAPHAEL outperforms recent cutting-edge models, such as Stable Diffusion, ERNIE-ViLG 2.0, DeepFloyd, and DALL-E 2, in terms of both image quality and aesthetic appeal. Firstly, RAPHAEL exhibits superior performance in switching images across diverse styles, such as Japanese comics, realism, cyberpunk, and ink illustration. Secondly, a single model with three billion parameters, trained on 1,000 A100 GPUs for two months, achieves a state-of-the-art zero-shot FID score of 6.61 on the COCO dataset. Furthermore, RAPHAEL significantly surpasses its counterparts in human evaluation on the ViLG-300 benchmark. We believe that RAPHAEL holds the potential to propel the frontiers of image generation research in both academia and industry, paving the way for future breakthroughs in this rapidly evolving field. More details can be found on a project webpage: https://raphael-painter.github.io/.
An Emergency Disposal Decision-making Method with Human--Machine Collaboration
May 29, 2023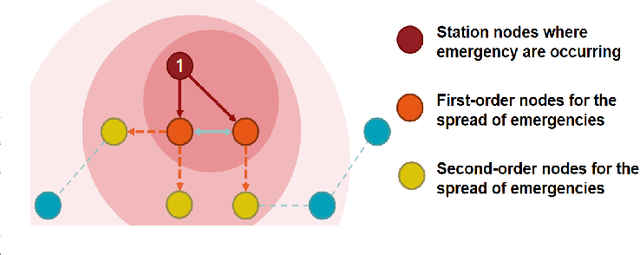
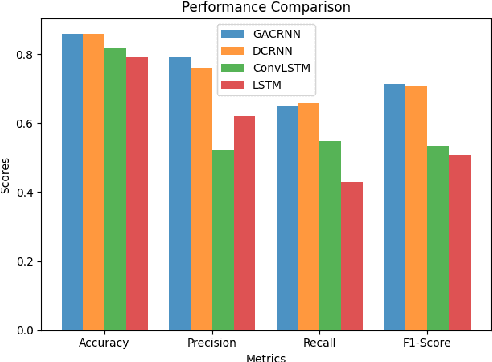
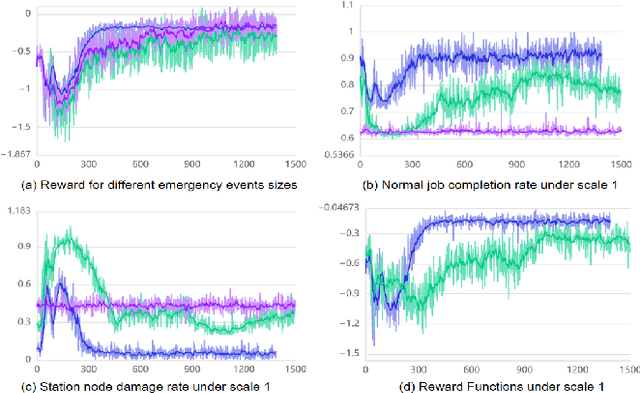
Rapid developments in artificial intelligence technology have led to unmanned systems replacing human beings in many fields requiring high-precision predictions and decisions. In modern operational environments, all job plans are affected by emergency events such as equipment failures and resource shortages, making a quick resolution critical. The use of unmanned systems to assist decision-making can improve resolution efficiency, but their decision-making is not interpretable and may make the wrong decisions. Current unmanned systems require human supervision and control. Based on this, we propose a collaborative human--machine method for resolving unplanned events using two phases: task filtering and task scheduling. In the task filtering phase, we propose a human--machine collaborative decision-making algorithm for dynamic tasks. The GACRNN model is used to predict the state of the job nodes, locate the key nodes, and generate a machine-predicted resolution task list. A human decision-maker supervises the list in real time and modifies and confirms the machine-predicted list through the human--machine interface. In the task scheduling phase, we propose a scheduling algorithm that integrates human experience constraints. The steps to resolve an event are inserted into the normal job sequence to schedule the resolution. We propose several human--machine collaboration methods in each phase to generate steps to resolve an unplanned event while minimizing the impact on the original job plan.
Search-Based Regular Expression Inference on a GPU
May 29, 2023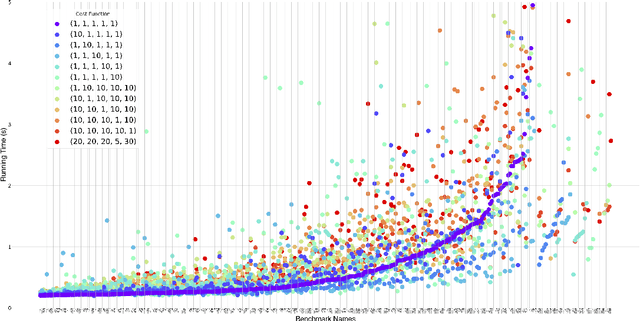
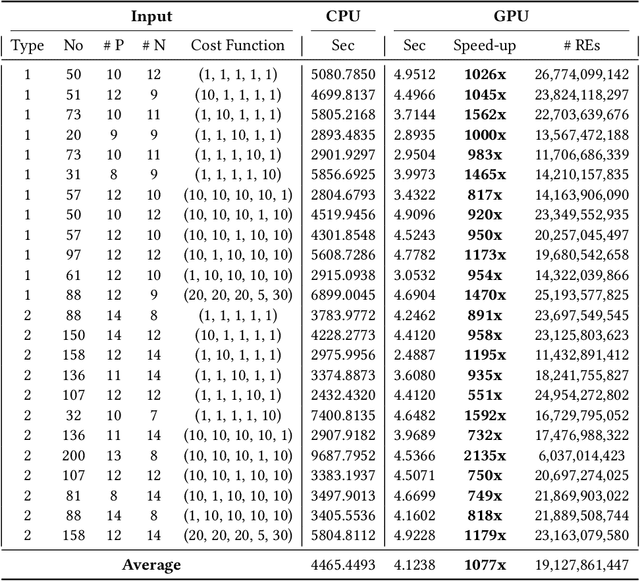
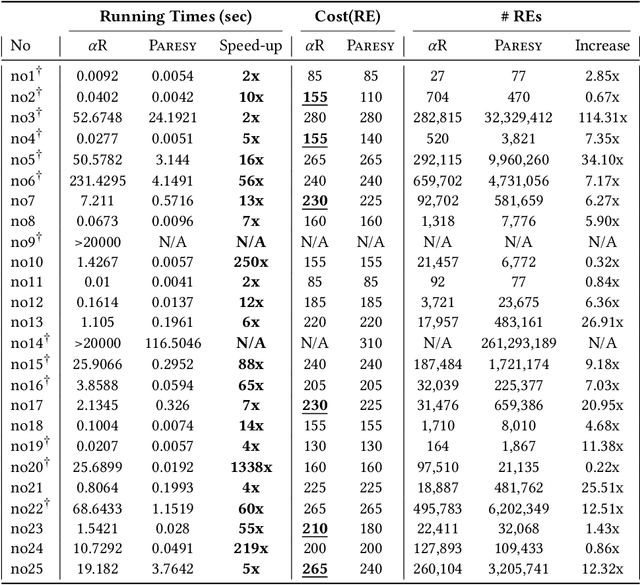
Regular expression inference (REI) is a supervised machine learning and program synthesis problem that takes a cost metric for regular expressions, and positive and negative examples of strings as input. It outputs a regular expression that is precise (i.e., accepts all positive and rejects all negative examples), and minimal w.r.t. to the cost metric. We present a novel algorithm for REI over arbitrary alphabets that is enumerative and trades off time for space. Our main algorithmic idea is to implement the search space of regular expressions succinctly as a contiguous matrix of bitvectors. Collectively, the bitvectors represent, as characteristic sequences, all sub-languages of the infix-closure of the union of positive and negative examples. Mathematically, this is a semiring of (a variant of) formal power series. Infix-closure enables bottom-up compositional construction of larger from smaller regular expressions using the operations of our semiring. This minimises data movement and data-dependent branching, hence maximises data-parallelism. In addition, the infix-closure remains unchanged during the search, hence search can be staged: first pre-compute various expensive operations, and then run the compute intensive search process. We provide two C++ implementations, one for general purpose CPUs and one for Nvidia GPUs (using CUDA). We benchmark both on Google Colab Pro: the GPU implementation is on average over 1000x faster than the CPU implementation on the hardest benchmarks.