 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Web scraping: a promising tool for geographic data acquisition
May 31, 2023
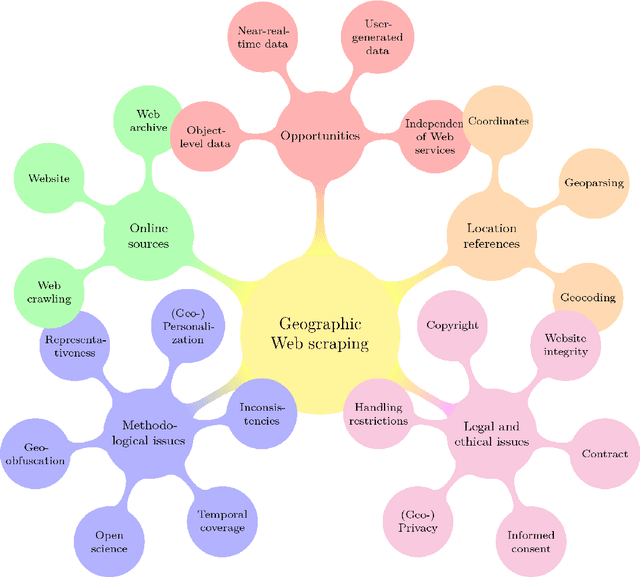
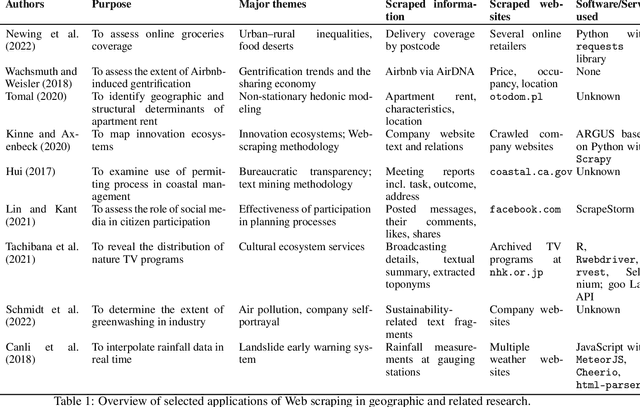
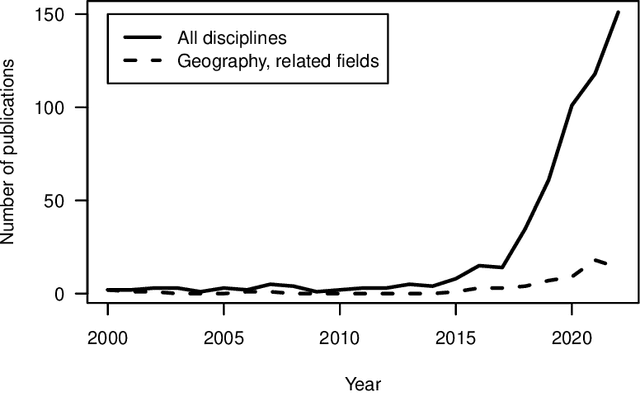
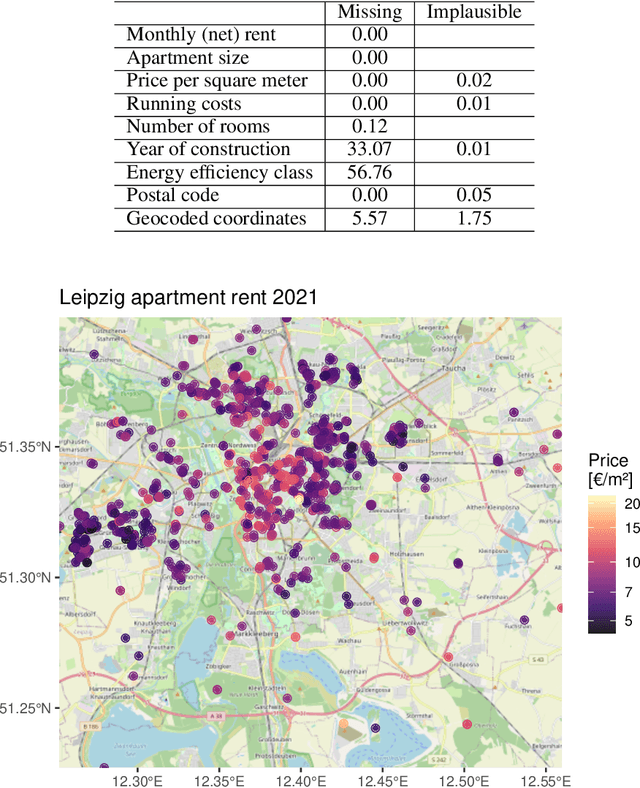
With much of our lives taking place online, researchers are increasingly turning to information from the World Wide Web to gain insights into geographic patterns and processes. Web scraping as an online data acquisition technique allows us to gather intelligence especially on social and economic actions for which the Web serves as a platform. Specific opportunities relate to near-real-time access to object-level geolocated data, which can be captured in a cost-effective way. The studied geographic phenomena include, but are not limited to, the rental market and associated processes such as gentrification, entrepreneurial ecosystems, or spatial planning processes. Since the information retrieved from the Web is not made available for that purpose, Web scraping faces several unique challenges, several of which relate to location. Ethical and legal issues mainly relate to intellectual property rights, informed consent and (geo-) privacy, and website integrity and contract. These issues also effect the practice of open science. In addition, there are technical and statistical challenges that relate to dependability and incompleteness, data inconsistencies and bias, as well as the limited historical coverage. Geospatial analyses furthermore usually require the automated extraction and subsequent resolution of toponyms or addresses (geoparsing, geocoding). A study on apartment rent in Leipzig, Germany is used to illustrate the use of Web scraping and its challenges. We conclude that geographic researchers should embrace Web scraping as a powerful and affordable digital fieldwork tool while paying special attention to its legal, ethical, and methodological challenges.
Time-Warping Invariant Quantum Recurrent Neural Networks via Quantum-Classical Adaptive Gating
Jan 20, 2023
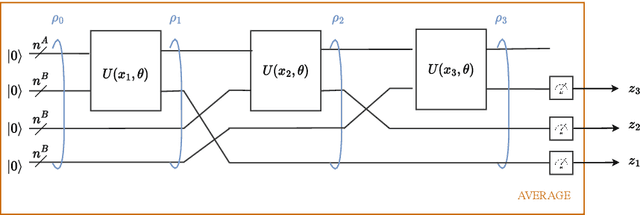
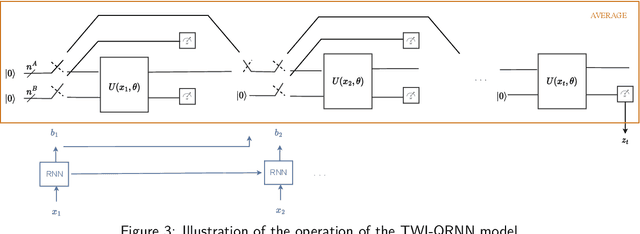

Adaptive gating plays a key role in temporal data processing via classical recurrent neural networks (RNN), as it facilitates retention of past information necessary to predict the future, providing a mechanism that preserves invariance to time warping transformations. This paper builds on quantum recurrent neural networks (QRNNs), a dynamic model with quantum memory, to introduce a novel class of temporal data processing quantum models that preserve invariance to time-warping transformations of the (classical) input-output sequences. The model, referred to as time warping-invariant QRNN (TWI-QRNN), augments a QRNN with a quantum-classical adaptive gating mechanism that chooses whether to apply a parameterized unitary transformation at each time step as a function of the past samples of the input sequence via a classical recurrent model. The TWI-QRNN model class is derived from first principles, and its capacity to successfully implement time-warping transformations is experimentally demonstrated on examples with classical or quantum dynamics.
SPP-CNN: An Efficient Framework for Network Robustness Prediction
May 13, 2023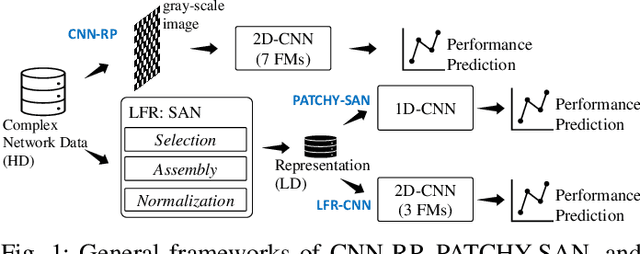

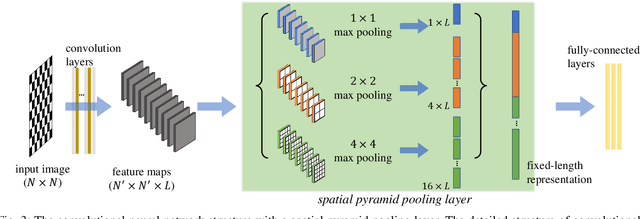
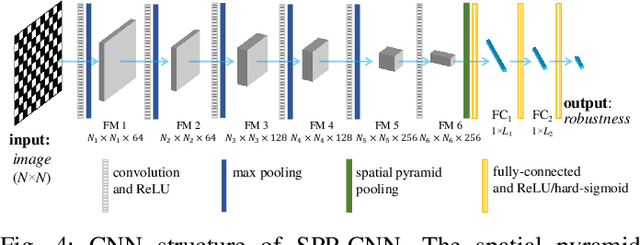
This paper addresses the robustness of a network to sustain its connectivity and controllability against malicious attacks. This kind of network robustness is typically measured by the time-consuming attack simulation, which returns a sequence of values that record the remaining connectivity and controllability after a sequence of node- or edge-removal attacks. For improvement, this paper develops an efficient framework for network robustness prediction, the spatial pyramid pooling convolutional neural network (SPP-CNN). The new framework installs a spatial pyramid pooling layer between the convolutional and fully-connected layers, overcoming the common mismatch issue in the CNN-based prediction approaches and extending its generalizability. Extensive experiments are carried out by comparing SPP-CNN with three state-of-the-art robustness predictors, namely a CNN-based and two graph neural networks-based frameworks. Synthetic and real-world networks, both directed and undirected, are investigated. Experimental results demonstrate that the proposed SPP-CNN achieves better prediction performances and better generalizability to unknown datasets, with significantly lower time-consumption, than its counterparts.
UnCRtainTS: Uncertainty Quantification for Cloud Removal in Optical Satellite Time Series
Apr 11, 2023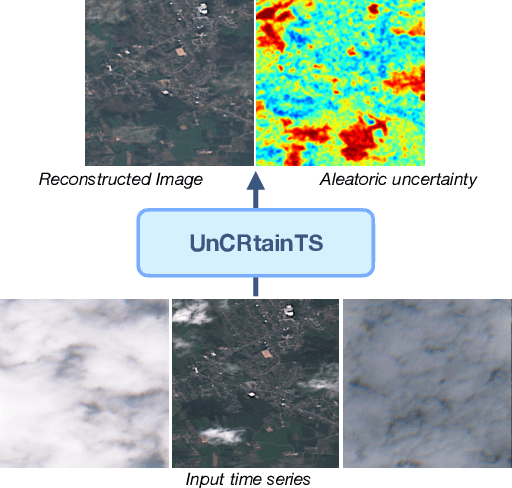
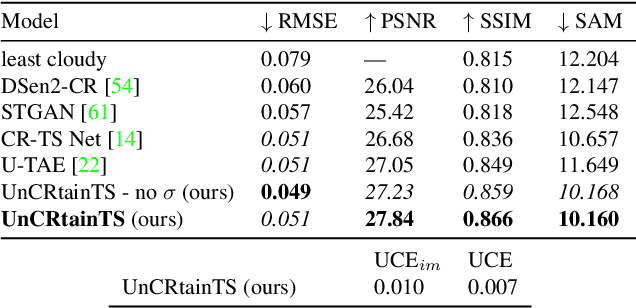
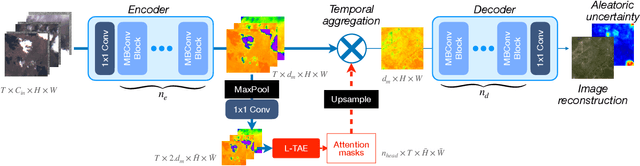
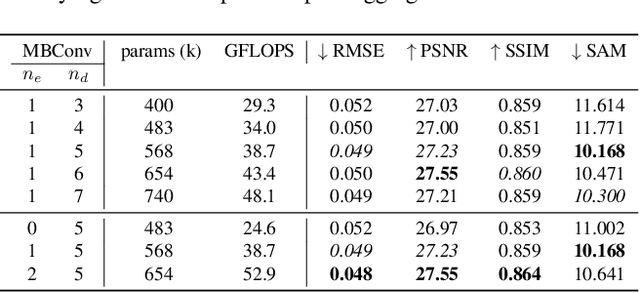
Clouds and haze often occlude optical satellite images, hindering continuous, dense monitoring of the Earth's surface. Although modern deep learning methods can implicitly learn to ignore such occlusions, explicit cloud removal as pre-processing enables manual interpretation and allows training models when only few annotations are available. Cloud removal is challenging due to the wide range of occlusion scenarios -- from scenes partially visible through haze, to completely opaque cloud coverage. Furthermore, integrating reconstructed images in downstream applications would greatly benefit from trustworthy quality assessment. In this paper, we introduce UnCRtainTS, a method for multi-temporal cloud removal combining a novel attention-based architecture, and a formulation for multivariate uncertainty prediction. These two components combined set a new state-of-the-art performance in terms of image reconstruction on two public cloud removal datasets. Additionally, we show how the well-calibrated predicted uncertainties enable a precise control of the reconstruction quality.
Time-Series Pattern Recognition in Smart Manufacturing Systems: A Literature Review and Ontology
Jan 29, 2023
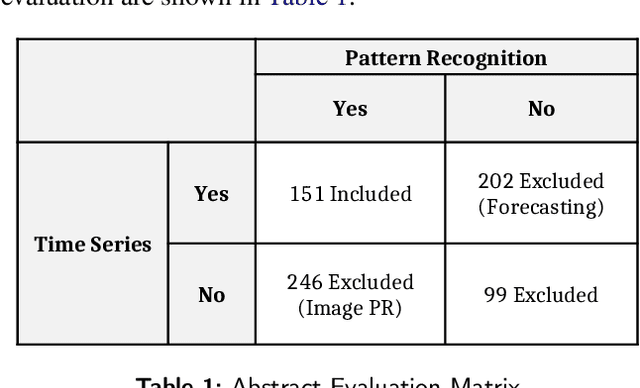
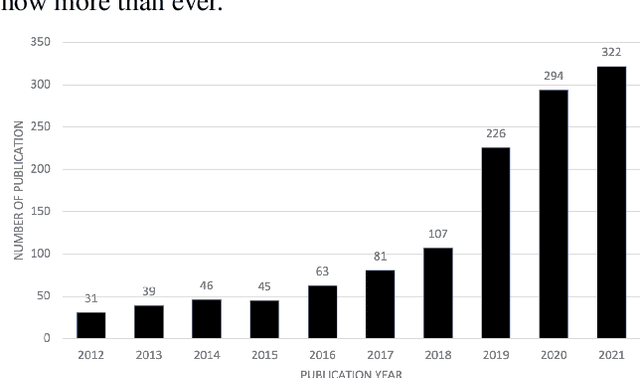
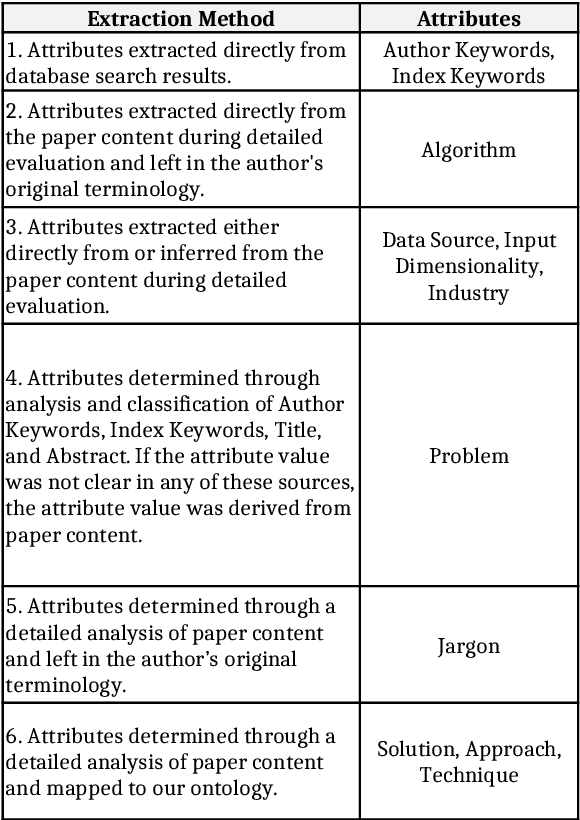
Since the inception of Industry 4.0 in 2012, emerging technologies have enabled the acquisition of vast amounts of data from diverse sources such as machine tools, robust and affordable sensor systems with advanced information models, and other sources within Smart Manufacturing Systems (SMS). As a result, the amount of data that is available in manufacturing settings has exploded, allowing data-hungry tools such as Artificial Intelligence (AI) and Machine Learning (ML) to be leveraged. Time-series analytics has been successfully applied in a variety of industries, and that success is now being migrated to pattern recognition applications in manufacturing to support higher quality products, zero defect manufacturing, and improved customer satisfaction. However, the diverse landscape of manufacturing presents a challenge for successfully solving problems in industry using time-series pattern recognition. The resulting research gap of understanding and applying the subject matter of time-series pattern recognition in manufacturing is a major limiting factor for adoption in industry. The purpose of this paper is to provide a structured perspective of the current state of time-series pattern recognition in manufacturing with a problem-solving focus. By using an ontology to classify and define concepts, how they are structured, their properties, the relationships between them, and considerations when applying them, this paper aims to provide practical and actionable guidelines for application and recommendations for advancing time-series analytics.
Agile gesture recognition for capacitive sensing devices: adapting on-the-job
May 12, 2023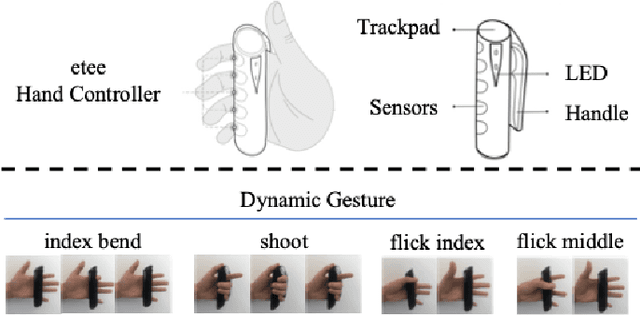
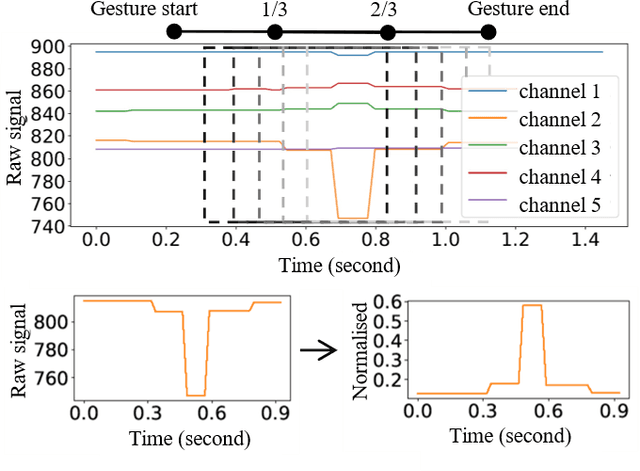
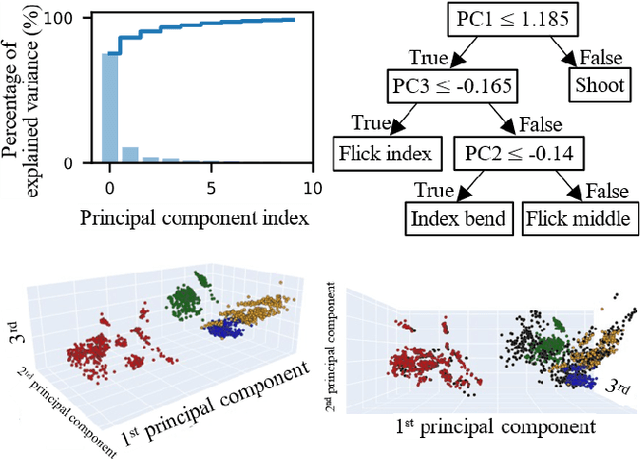
Automated hand gesture recognition has been a focus of the AI community for decades. Traditionally, work in this domain revolved largely around scenarios assuming the availability of the flow of images of the user hands. This has partly been due to the prevalence of camera-based devices and the wide availability of image data. However, there is growing demand for gesture recognition technology that can be implemented on low-power devices using limited sensor data instead of high-dimensional inputs like hand images. In this work, we demonstrate a hand gesture recognition system and method that uses signals from capacitive sensors embedded into the etee hand controller. The controller generates real-time signals from each of the wearer five fingers. We use a machine learning technique to analyse the time series signals and identify three features that can represent 5 fingers within 500 ms. The analysis is composed of a two stage training strategy, including dimension reduction through principal component analysis and classification with K nearest neighbour. Remarkably, we found that this combination showed a level of performance which was comparable to more advanced methods such as supervised variational autoencoder. The base system can also be equipped with the capability to learn from occasional errors by providing it with an additional adaptive error correction mechanism. The results showed that the error corrector improve the classification performance in the base system without compromising its performance. The system requires no more than 1 ms of computing time per input sample, and is smaller than deep neural networks, demonstrating the feasibility of agile gesture recognition systems based on this technology.
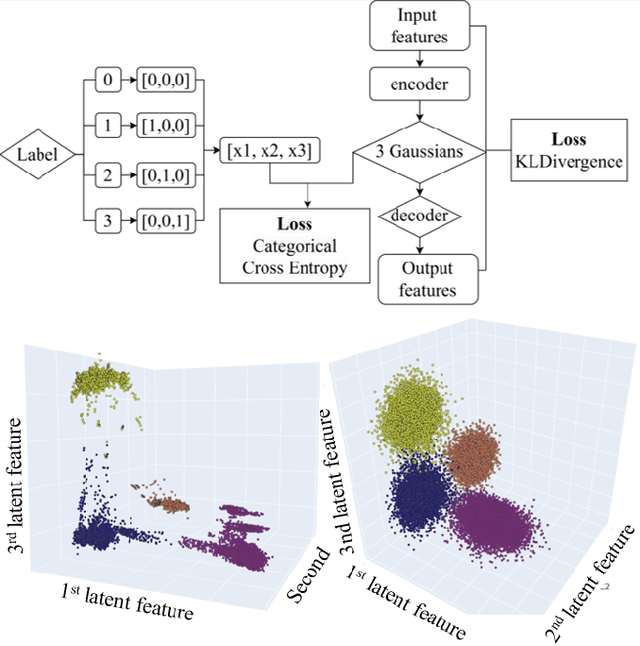
Novel deep learning methods for 3D flow field segmentation and classification
May 10, 2023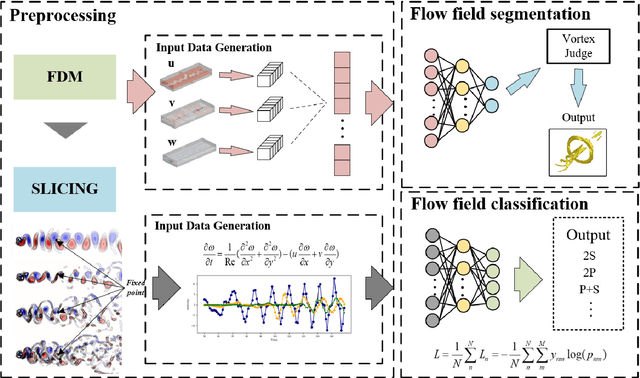
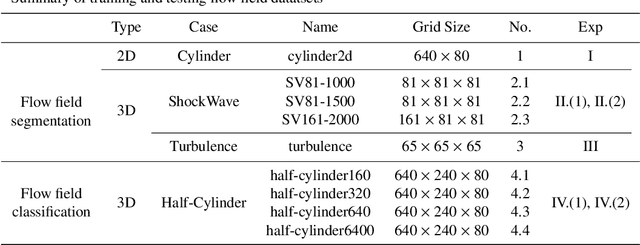
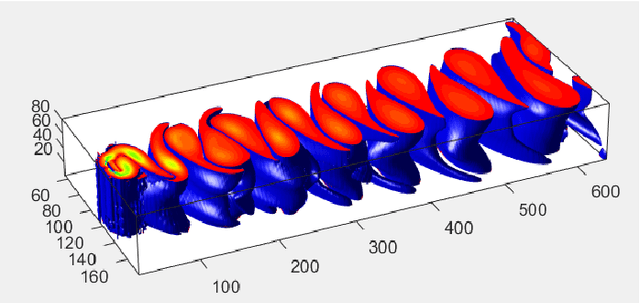
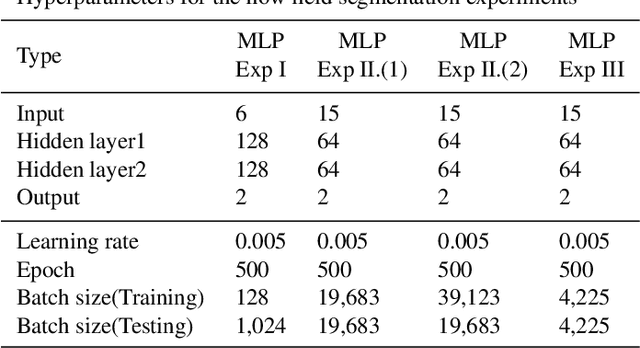
Flow field segmentation and classification help researchers to understand vortex structure and thus turbulent flow. Existing deep learning methods mainly based on global information and focused on 2D circumstance. Based on flow field theory, we propose novel flow field segmentation and classification deep learning methods in three-dimensional space. We construct segmentation criterion based on local velocity information and classification criterion based on the relationship between local vorticity and vortex wake, to identify vortex structure in 3D flow field, and further classify the type of vortex wakes accurately and rapidly. Simulation experiment results showed that, compared with existing methods, our segmentation method can identify the vortex area more accurately, while the time consumption is reduced more than 50\%; our classification method can reduce the time consumption by more than 90\% while maintaining the same classification accuracy level.
Segmented GRAND: Combining Sub-patterns in Near-ML Order
May 24, 2023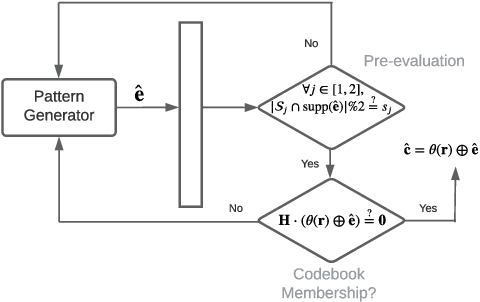
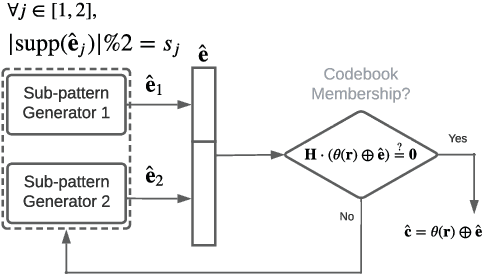
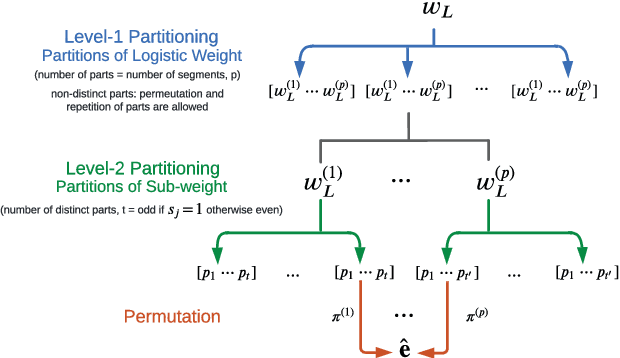
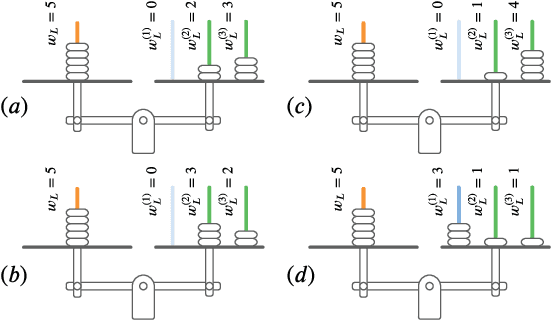
The recently introduced maximum-likelihood (ML) decoding scheme called guessing random additive noise decoding (GRAND) has demonstrated a remarkably low time complexity in high signal-to-noise ratio (SNR) regimes. However, the complexity is not as low at low SNR regimes and low code rates. To mitigate this concern, we propose a scheme for a near-ML variant of GRAND called ordered reliability bits GRAND (or ORBGRAND), which divides codewords into segments based on the properties of the underlying code, generates sub-patterns for each segment consistent with the syndrome (thus reducing the number of inconsistent error patterns generated), and combines them in a near-ML order using two-level integer partitions of logistic weight. The numerical evaluation demonstrates that the proposed scheme, called segmented ORBGRAND, significantly reduces the average number of queries at any SNR regime. Moreover, the segmented ORBGRAND with abandonment also improves the error correction performance.
FaceFusion: Exploiting Full Spectrum of Multiple Datasets
May 24, 2023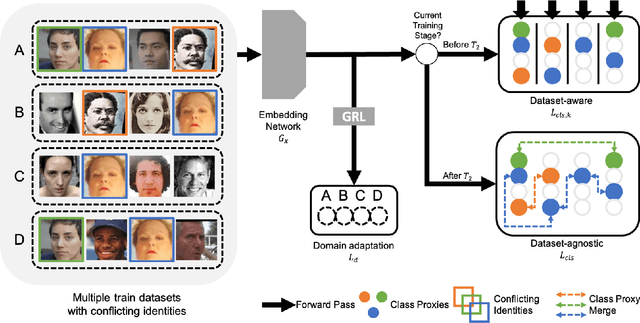
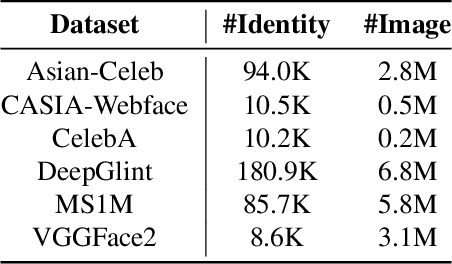
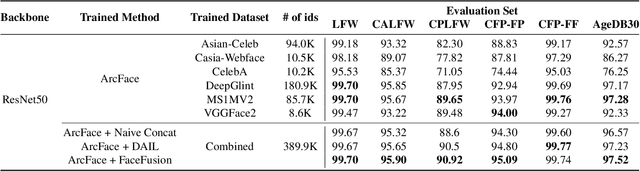

The size of training dataset is known to be among the most dominating aspects of training high-performance face recognition embedding model. Building a large dataset from scratch could be cumbersome and time-intensive, while combining multiple already-built datasets poses the risk of introducing large amount of label noise. We present a novel training method, named FaceFusion. It creates a fused view of different datasets that is untainted by identity conflicts, while concurrently training an embedding network using the view in an end-to-end fashion. Using the unified view of combined datasets enables the embedding network to be trained against the entire spectrum of the datasets, leading to a noticeable performance boost. Extensive experiments confirm superiority of our method, whose performance in public evaluation datasets surpasses not only that of using a single training dataset, but also that of previously known methods under various training circumstances.
NeRSemble: Multi-view Radiance Field Reconstruction of Human Heads
May 04, 2023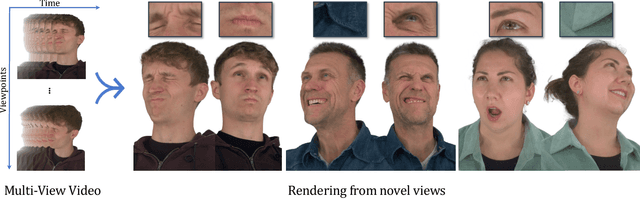
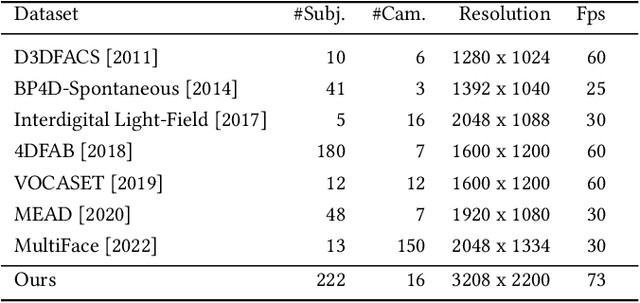

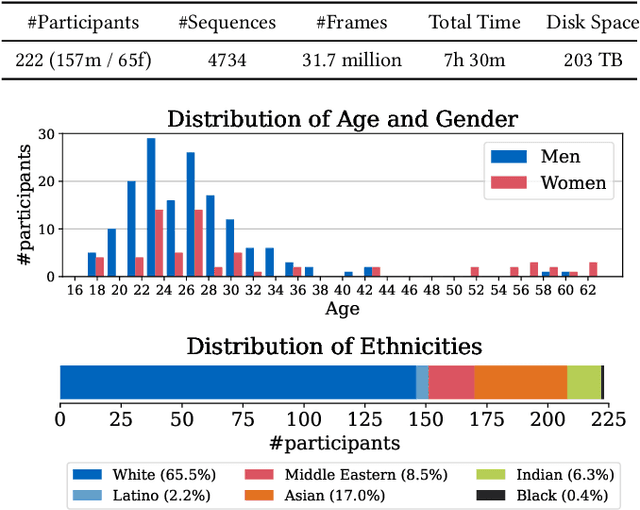
We focus on reconstructing high-fidelity radiance fields of human heads, capturing their animations over time, and synthesizing re-renderings from novel viewpoints at arbitrary time steps. To this end, we propose a new multi-view capture setup composed of 16 calibrated machine vision cameras that record time-synchronized images at 7.1 MP resolution and 73 frames per second. With our setup, we collect a new dataset of over 4700 high-resolution, high-framerate sequences of more than 220 human heads, from which we introduce a new human head reconstruction benchmark. The recorded sequences cover a wide range of facial dynamics, including head motions, natural expressions, emotions, and spoken language. In order to reconstruct high-fidelity human heads, we propose Dynamic Neural Radiance Fields using Hash Ensembles (NeRSemble). We represent scene dynamics by combining a deformation field and an ensemble of 3D multi-resolution hash encodings. The deformation field allows for precise modeling of simple scene movements, while the ensemble of hash encodings helps to represent complex dynamics. As a result, we obtain radiance field representations of human heads that capture motion over time and facilitate re-rendering of arbitrary novel viewpoints. In a series of experiments, we explore the design choices of our method and demonstrate that our approach outperforms state-of-the-art dynamic radiance field approaches by a significant margin.