 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FMM-X3D: FPGA-based modeling and mapping of X3D for Human Action Recognition
May 29, 2023
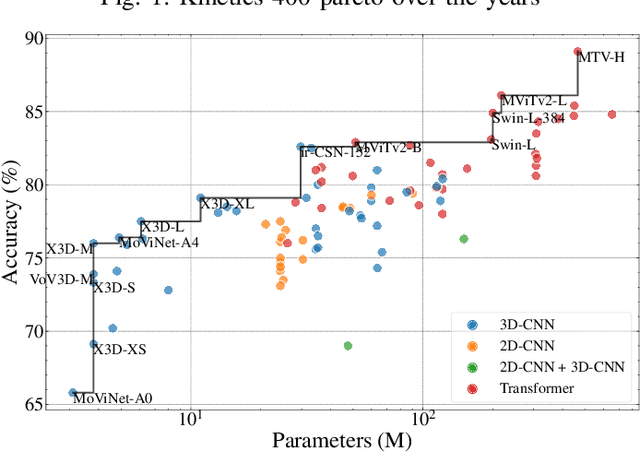
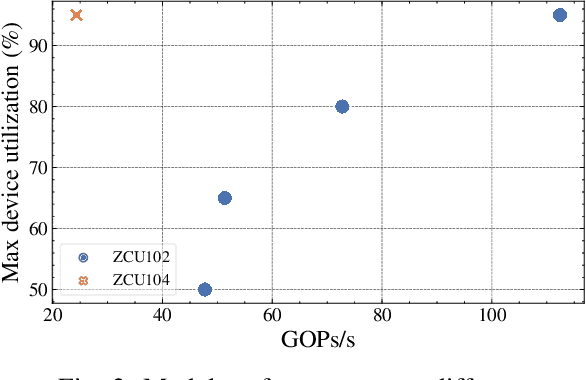
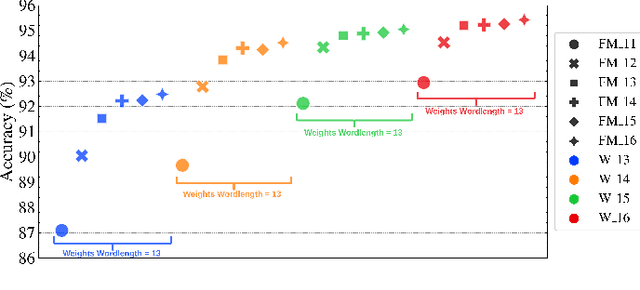
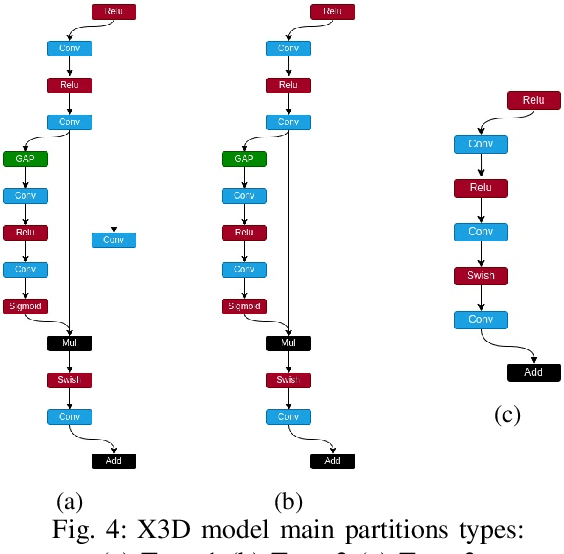
3D Convolutional Neural Networks are gaining increasing attention from researchers and practitioners and have found applications in many domains, such as surveillance systems, autonomous vehicles, human monitoring systems, and video retrieval. However, their widespread adoption is hindered by their high computational and memory requirements, especially when resource-constrained systems are targeted. This paper addresses the problem of mapping X3D, a state-of-the-art model in Human Action Recognition that achieves accuracy of 95.5\% in the UCF101 benchmark, onto any FPGA device. The proposed toolflow generates an optimised stream-based hardware system, taking into account the available resources and off-chip memory characteristics of the FPGA device. The generated designs push further the current performance-accuracy pareto front, and enable for the first time the targeting of such complex model architectures for the Human Action Recognition task.
Embracing Compact and Robust Architectures for Multi-Exposure Image Fusion
May 20, 2023
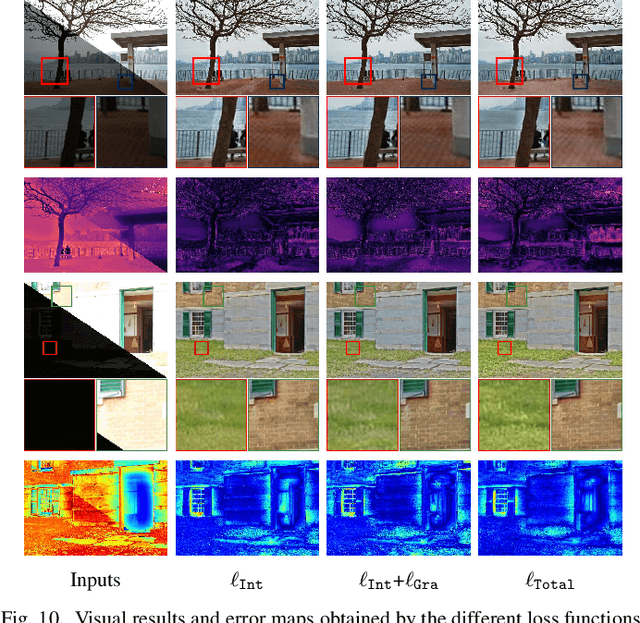
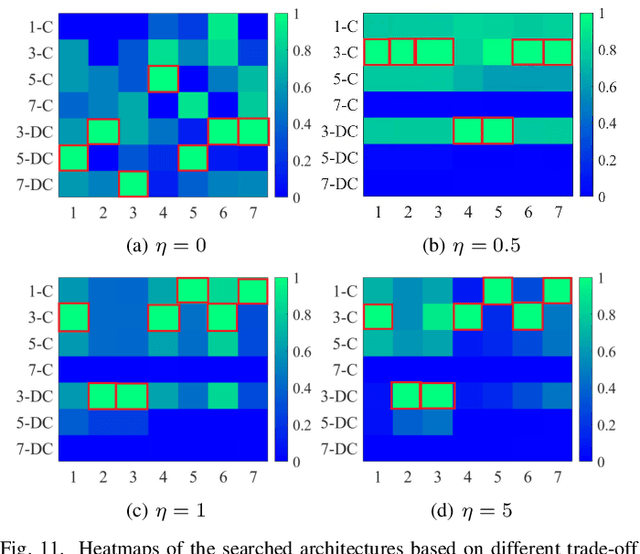
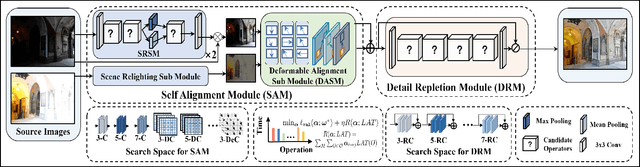
In recent years, deep learning-based methods have achieved remarkable progress in multi-exposure image fusion. However, existing methods rely on aligned image pairs, inevitably generating artifacts when faced with device shaking in real-world scenarios. Moreover, these learning-based methods are built on handcrafted architectures and operations by increasing network depth or width, neglecting different exposure characteristics. As a result, these direct cascaded architectures with redundant parameters fail to achieve highly effective inference time and lead to massive computation. To alleviate these issues, in this paper, we propose a search-based paradigm, involving self-alignment and detail repletion modules for robust multi-exposure image fusion. By utilizing scene relighting and deformable convolutions, the self-alignment module can accurately align images despite camera movement. Furthermore, by imposing a hardware-sensitive constraint, we introduce neural architecture search to discover compact and efficient networks, investigating effective feature representation for fusion. We realize the state-of-the-art performance in comparison to various competitive schemes, yielding a 4.02% and 29.34% improvement in PSNR for general and misaligned scenarios, respectively, while reducing inference time by 68.1%. The source code will be available at https://github.com/LiuZhu-CV/CRMEF.
UAP-BEV: Uncertainty Aware Planning using Bird's Eye View generated from Surround Monocular Images
Jun 08, 2023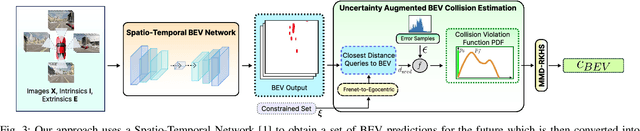

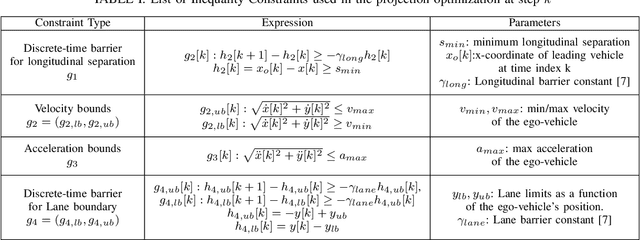
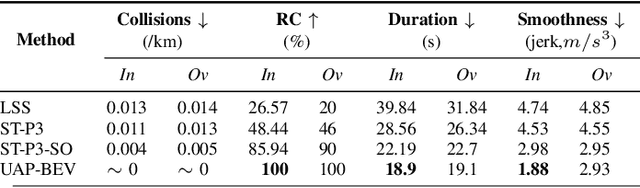
Autonomous driving requires accurate reasoning of the location of objects from raw sensor data. Recent end-to-end learning methods go from raw sensor data to a trajectory output via Bird's Eye View(BEV) segmentation as an interpretable intermediate representation. Motion planning over cost maps generated via Birds Eye View (BEV) segmentation has emerged as a prominent approach in autonomous driving. However, the current approaches have two critical gaps. First, the optimization process is simplistic and involves just evaluating a fixed set of trajectories over the cost map. The trajectory samples are not adapted based on their associated cost values. Second, the existing cost maps do not account for the uncertainty in the cost maps that can arise due to noise in RGB images, and BEV annotations. As a result, these approaches can struggle in challenging scenarios where there is abrupt cut-in, stopping, overtaking, merging, etc from the neighboring vehicles. In this paper, we propose UAP-BEV: A novel approach that models the noise in Spatio-Temporal BEV predictions to create an uncertainty-aware occupancy grid map. Using queries of the distance to the closest occupied cell, we obtain a sample estimate of the collision probability of the ego-vehicle. Subsequently, our approach uses gradient-free sampling-based optimization to compute low-cost trajectories over the cost map. Importantly, the sampling distribution is adapted based on the optimal cost values of the sampled trajectories. By explicitly modeling probabilistic collision avoidance in the BEV space, our approach is able to outperform the cost-map-based baselines in collision avoidance, route completion, time to completion, and smoothness. To further validate our method, we also show results on the real-world dataset NuScenes, where we report improvements in collision avoidance and smoothness.
Fully Robust Federated Submodel Learning in a Distributed Storage System
Jun 08, 2023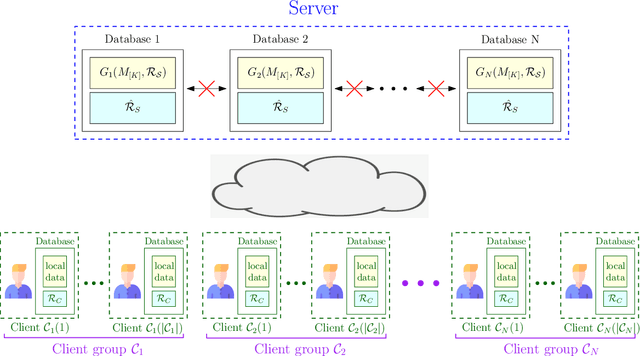
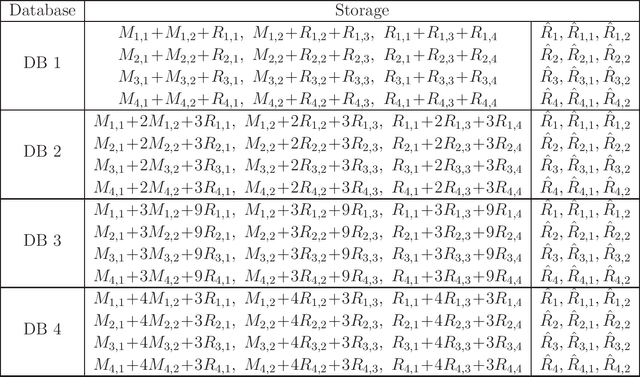
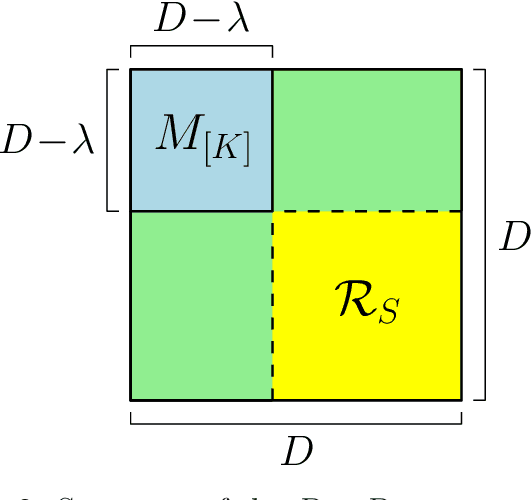
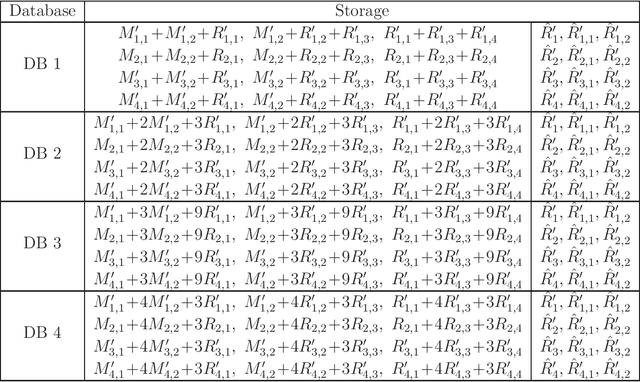
We consider the federated submodel learning (FSL) problem in a distributed storage system. In the FSL framework, the full learning model at the server side is divided into multiple submodels such that each selected client needs to download only the required submodel(s) and upload the corresponding update(s) in accordance with its local training data. The server comprises multiple independent databases and the full model is stored across these databases. An eavesdropper passively observes all the storage and listens to all the communicated data, of its controlled databases, to gain knowledge about the remote client data and the submodel information. In addition, a subset of databases may fail, negatively affecting the FSL process, as FSL process may take a non-negligible amount of time for large models. To resolve these two issues together (i.e., security and database repair), we propose a novel coding mechanism coined ramp secure regenerating coding (RSRC), to store the full model in a distributed manner. Using our new RSRC method, the eavesdropper is permitted to learn a controllable amount of submodel information for the sake of reducing the communication and storage costs. Further, during the database repair process, in the construction of the replacement database, the submodels to be updated are stored in the form of their latest version from updating clients, while the remaining submodels are obtained from the previous version in other databases through routing clients. Our new RSRC-based distributed FSL approach is constructed on top of our earlier two-database FSL scheme which uses private set union (PSU). A complete one-round FSL process consists of FSL-PSU phase, FSL-write phase and additional auxiliary phases. Our proposed FSL scheme is also robust against database drop-outs, client drop-outs, client late-arrivals and an active adversary controlling databases.
Importance attribution in neural networks by means of persistence landscapes of time series
Feb 06, 2023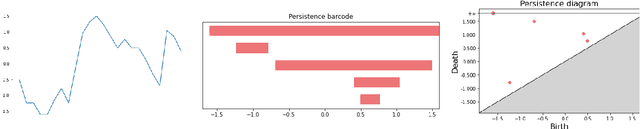

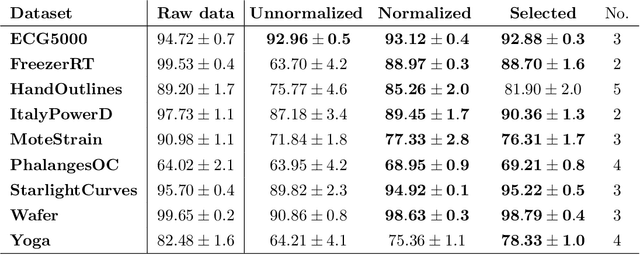
We propose and implement a method to analyze time series with a neural network using a matrix of area-normalized persistence landscapes obtained through topological data analysis. We include a gating layer in the network's architecture that is able to identify the most relevant landscape levels for the classification task, thus working as an importance attribution system. Next, we perform a matching between the selected landscape functions and the corresponding critical points of the original time series. From this matching we are able to reconstruct an approximate shape of the time series that gives insight into the classification decision. We test this technique with input data from a dataset of electrocardiographic signals.
One for All: Unified Workload Prediction for Dynamic Multi-tenant Edge Cloud Platforms
Jun 02, 2023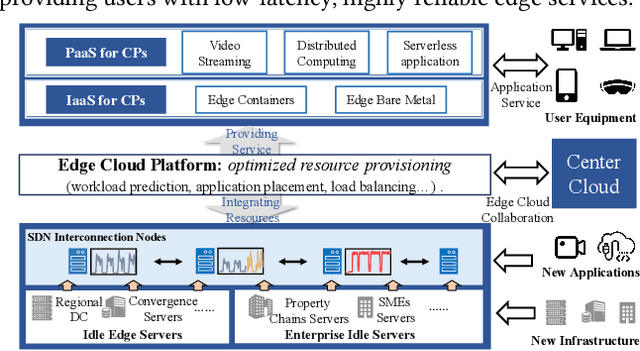
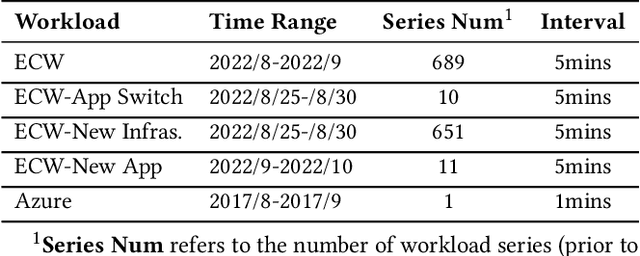
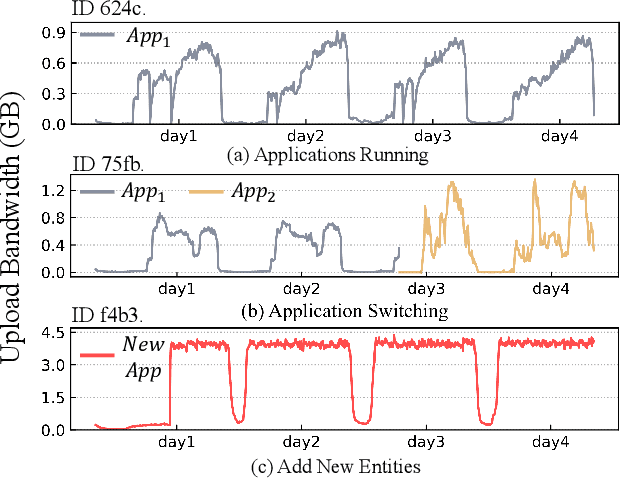
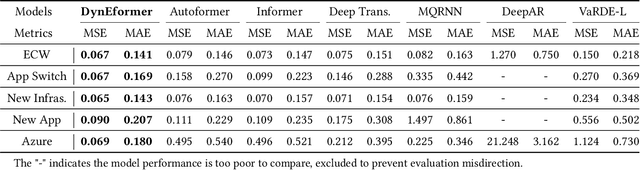
Workload prediction in multi-tenant edge cloud platforms (MT-ECP) is vital for efficient application deployment and resource provisioning. However, the heterogeneous application patterns, variable infrastructure performance, and frequent deployments in MT-ECP pose significant challenges for accurate and efficient workload prediction. Clustering-based methods for dynamic MT-ECP modeling often incur excessive costs due to the need to maintain numerous data clusters and models, which leads to excessive costs. Existing end-to-end time series prediction methods are challenging to provide consistent prediction performance in dynamic MT-ECP. In this paper, we propose an end-to-end framework with global pooling and static content awareness, DynEformer, to provide a unified workload prediction scheme for dynamic MT-ECP. Meticulously designed global pooling and information merging mechanisms can effectively identify and utilize global application patterns to drive local workload predictions. The integration of static content-aware mechanisms enhances model robustness in real-world scenarios. Through experiments on five real-world datasets, DynEformer achieved state-of-the-art in the dynamic scene of MT-ECP and provided a unified end-to-end prediction scheme for MT-ECP.
DWT-CompCNN: Deep Image Classification Network for High Throughput JPEG 2000 Compressed Documents
Jun 02, 2023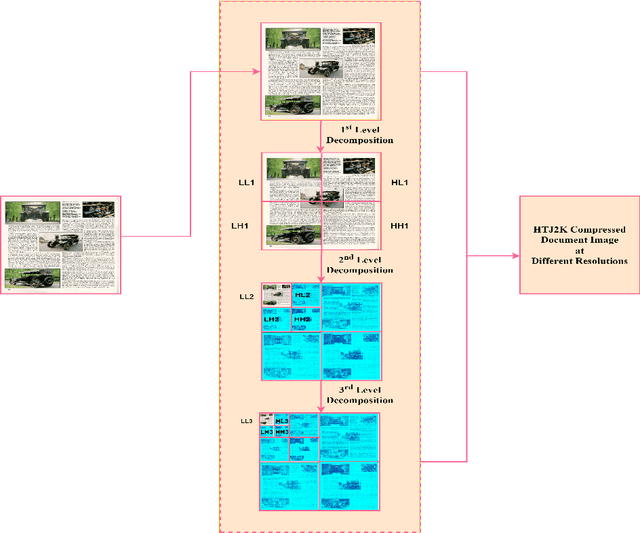
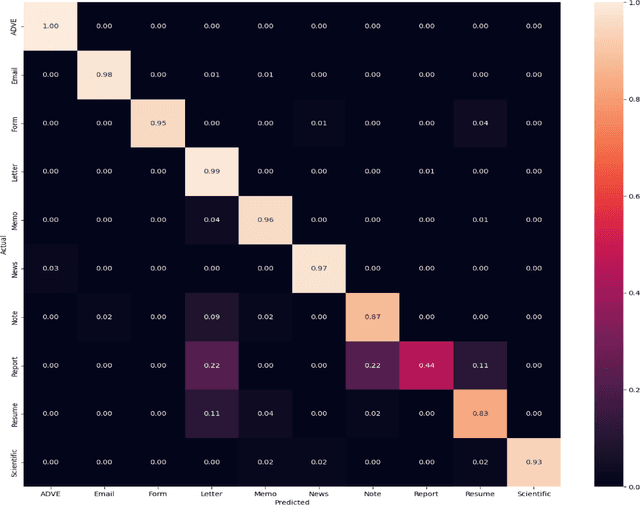
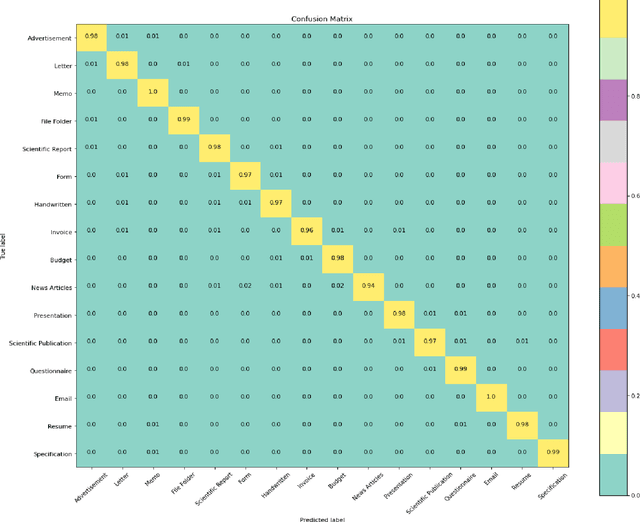
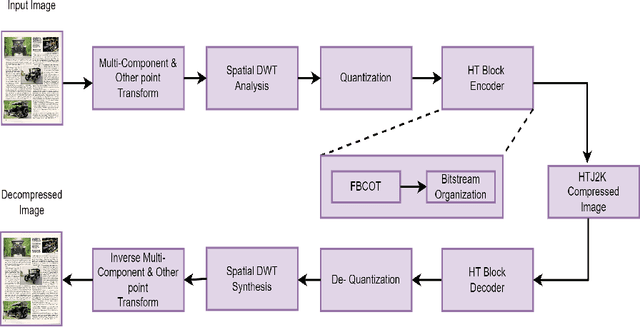
For any digital application with document images such as retrieval, the classification of document images becomes an essential stage. Conventionally for the purpose, the full versions of the documents, that is the uncompressed document images make the input dataset, which poses a threat due to the big volume required to accommodate the full versions of the documents. Therefore, it would be novel, if the same classification task could be accomplished directly (with some partial decompression) with the compressed representation of documents in order to make the whole process computationally more efficient. In this research work, a novel deep learning model, DWT CompCNN is proposed for classification of documents that are compressed using High Throughput JPEG 2000 (HTJ2K) algorithm. The proposed DWT-CompCNN comprises of five convolutional layers with filter sizes of 16, 32, 64, 128, and 256 consecutively for each increasing layer to improve learning from the wavelet coefficients extracted from the compressed images. Experiments are performed on two benchmark datasets- Tobacco-3482 and RVL-CDIP, which demonstrate that the proposed model is time and space efficient, and also achieves a better classification accuracy in compressed domain.
Backchannel Detection and Agreement Estimation from Video with Transformer Networks
Jun 02, 2023
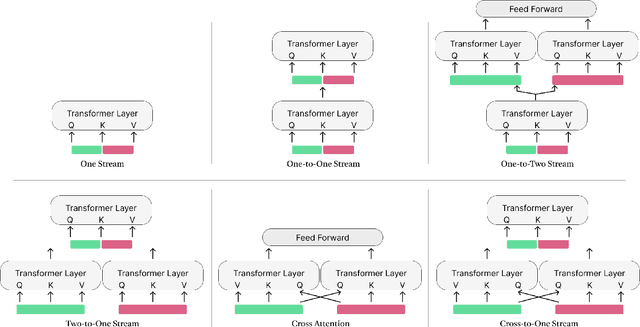


Listeners use short interjections, so-called backchannels, to signify attention or express agreement. The automatic analysis of this behavior is of key importance for human conversation analysis and interactive conversational agents. Current state-of-the-art approaches for backchannel analysis from visual behavior make use of two types of features: features based on body pose and features based on facial behavior. At the same time, transformer neural networks have been established as an effective means to fuse input from different data sources, but they have not yet been applied to backchannel analysis. In this work, we conduct a comprehensive evaluation of multi-modal transformer architectures for automatic backchannel analysis based on pose and facial information. We address both the detection of backchannels as well as the task of estimating the agreement expressed in a backchannel. In evaluations on the MultiMediate'22 backchannel detection challenge, we reach 66.4% accuracy with a one-layer transformer architecture, outperforming the previous state of the art. With a two-layer transformer architecture, we furthermore set a new state of the art (0.0604 MSE) on the task of estimating the amount of agreement expressed in a backchannel.
ErfReLU: Adaptive Activation Function for Deep Neural Network
Jun 02, 2023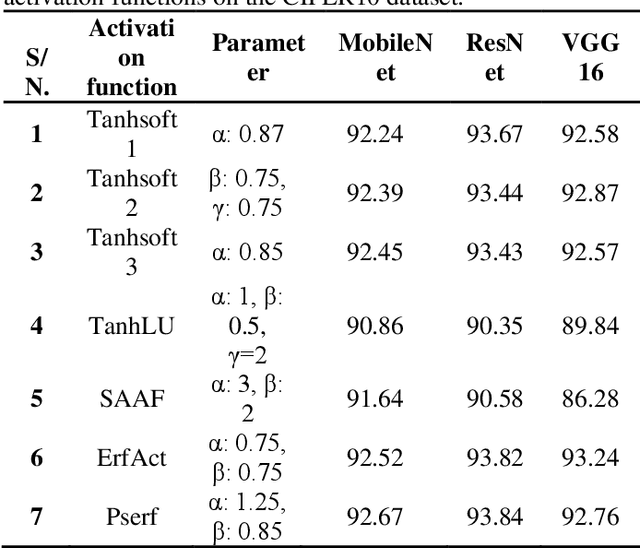
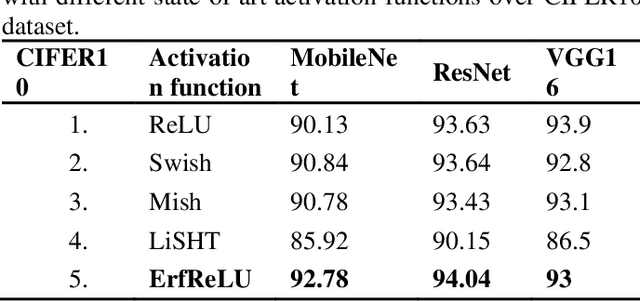
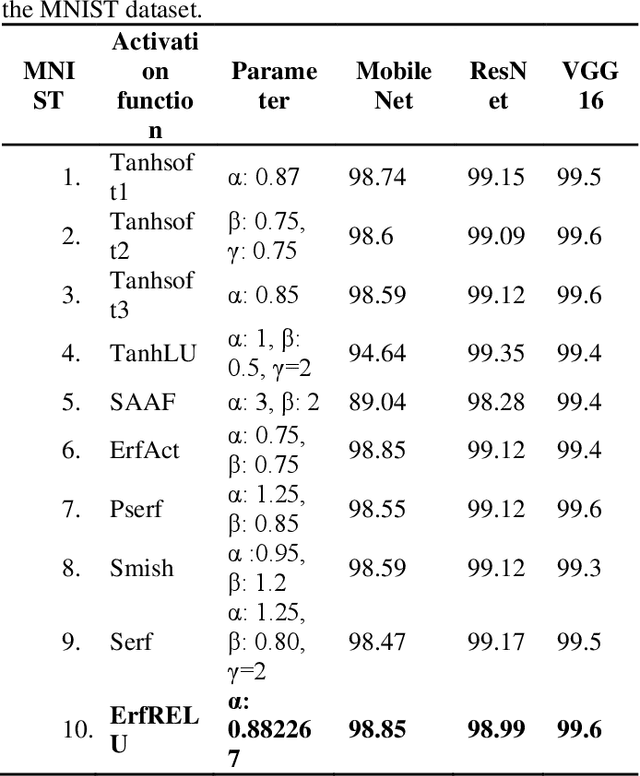
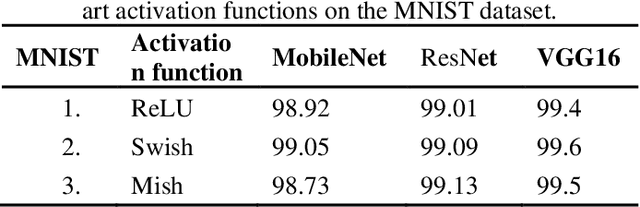
Recent research has found that the activation function (AF) selected for adding non-linearity into the output can have a big impact on how effectively deep learning networks perform. Developing activation functions that can adapt simultaneously with learning is a need of time. Researchers recently started developing activation functions that can be trained throughout the learning process, known as trainable, or adaptive activation functions (AAF). Research on AAF that enhance the outcomes is still in its early stages. In this paper, a novel activation function 'ErfReLU' has been developed based on the erf function and ReLU. This function exploits the ReLU and the error function (erf) to its advantage. State of art activation functions like Sigmoid, ReLU, Tanh, and their properties have been briefly explained. Adaptive activation functions like Tanhsoft1, Tanhsoft2, Tanhsoft3, TanhLU, SAAF, ErfAct, Pserf, Smish, and Serf have also been described. Lastly, performance analysis of 9 trainable activation functions along with the proposed one namely Tanhsoft1, Tanhsoft2, Tanhsoft3, TanhLU, SAAF, ErfAct, Pserf, Smish, and Serf has been shown by applying these activation functions in MobileNet, VGG16, and ResNet models on CIFAR-10, MNIST, and FMNIST benchmark datasets.
Leveraging the Triple Exponential Moving Average for Fast-Adaptive Moment Estimation
Jun 02, 2023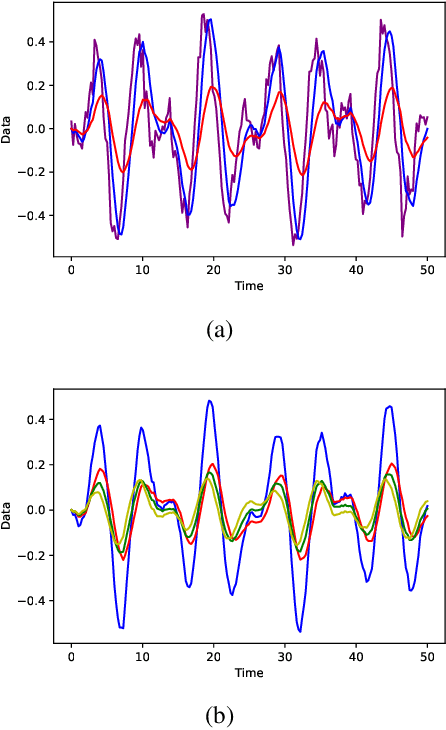
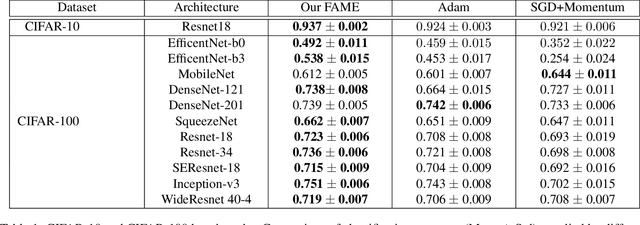
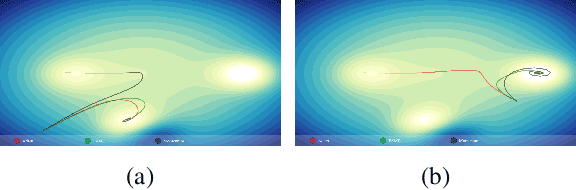
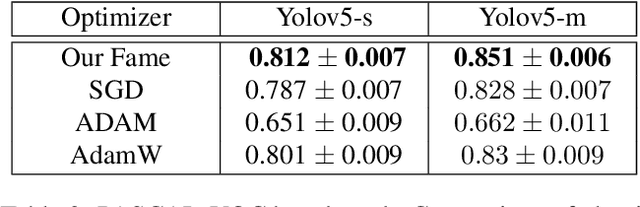
Network optimization is a crucial step in the field of deep learning, as it directly affects the performance of models in various domains such as computer vision. Despite the numerous optimizers that have been developed over the years, the current methods are still limited in their ability to accurately and quickly identify gradient trends, which can lead to sub-optimal network performance. In this paper, we propose a novel deep optimizer called Fast-Adaptive Moment Estimation (FAME), which for the first time estimates gradient moments using a Triple Exponential Moving Average (TEMA). Incorporating TEMA into the optimization process provides richer and more accurate information on data changes and trends, as compared to the standard Exponential Moving Average used in essentially all current leading adaptive optimization methods. Our proposed FAME optimizer has been extensively validated through a wide range of benchmarks, including CIFAR-10, CIFAR-100, PASCAL-VOC, MS-COCO, and Cityscapes, using 14 different learning architectures, six optimizers, and various vision tasks, including detection, classification and semantic understanding. The results demonstrate that our FAME optimizer outperforms other leading optimizers in terms of both robustness and accuracy.