 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sample-efficient Real-time Planning with Curiosity Cross-Entropy Method and Contrastive Learning
Mar 07, 2023
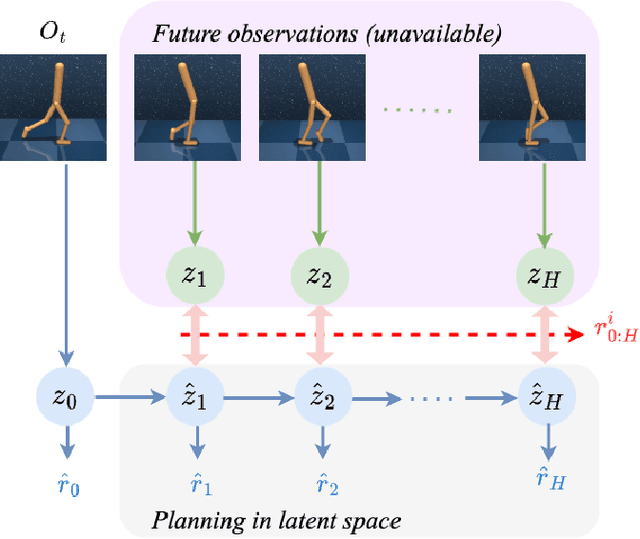
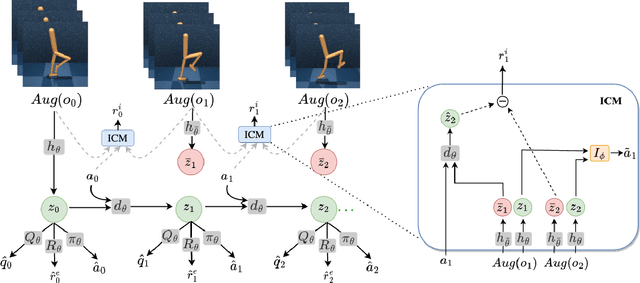

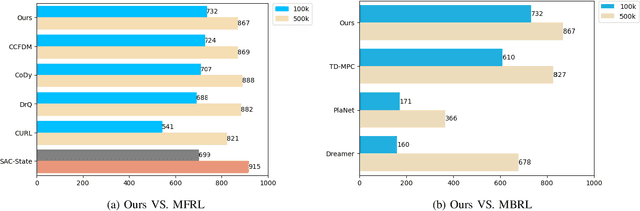
Model-based reinforcement learning (MBRL) with real-time planning has shown great potential in locomotion and manipulation control tasks. However, the existing planning methods, such as the Cross-Entropy Method (CEM), do not scale well to complex high-dimensional environments. One of the key reasons for underperformance is the lack of exploration, as these planning methods only aim to maximize the cumulative extrinsic reward over the planning horizon. Furthermore, planning inside the compact latent space in the absence of observations makes it challenging to use curiosity-based intrinsic motivation. We propose Curiosity CEM (CCEM), an improved version of the CEM algorithm for encouraging exploration via curiosity. Our proposed method maximizes the sum of state-action Q values over the planning horizon, in which these Q values estimate the future extrinsic and intrinsic reward, hence encouraging reaching novel observations. In addition, our model uses contrastive representation learning to efficiently learn latent representations. Experiments on image-based continuous control tasks from the DeepMind Control suite show that CCEM is by a large margin more sample-efficient than previous MBRL algorithms and compares favorably with the best model-free RL methods.
Towards Object Re-Identification from Point Clouds for 3D MOT
May 17, 2023
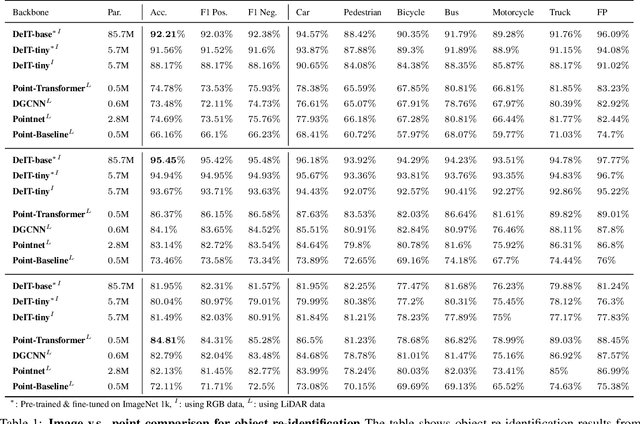
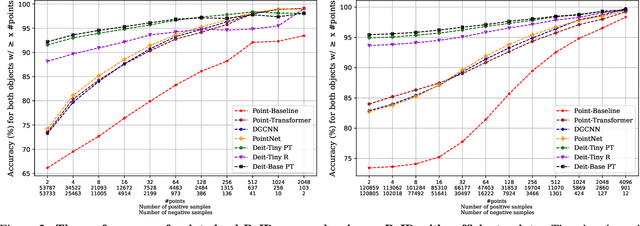
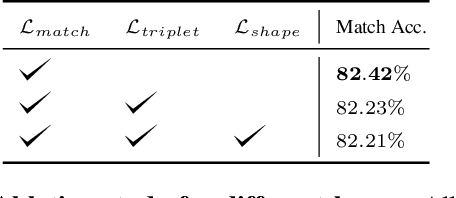
In this work, we study the problem of object re-identification (ReID) in a 3D multi-object tracking (MOT) context, by learning to match pairs of objects from cropped (e.g., using their predicted 3D bounding boxes) point cloud observations. We are not concerned with SOTA performance for 3D MOT, however. Instead, we seek to answer the following question: In a realistic tracking by-detection context, how does object ReID from point clouds perform relative to ReID from images? To enable such a study, we propose a lightweight matching head that can be concatenated to any set or sequence processing backbone (e.g., PointNet or ViT), creating a family of comparable object ReID networks for both modalities. Run in siamese style, our proposed point-cloud ReID networks can make thousands of pairwise comparisons in real-time (10 hz). Our findings demonstrate that their performance increases with higher sensor resolution and approaches that of image ReID when observations are sufficiently dense. Additionally, we investigate our network's ability to enhance 3D multi-object tracking (MOT), showing that our point-cloud ReID networks can successfully re-identify objects which led a strong motion-based tracker into error. To our knowledge, we are the first to study real-time object re-identification from point clouds in a 3D multi-object tracking context.
Evaluating Dynamic Conditional Quantile Treatment Effects with Applications in Ridesharing
May 17, 2023
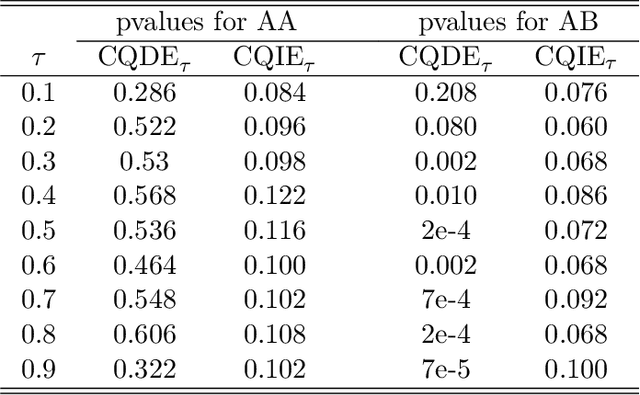
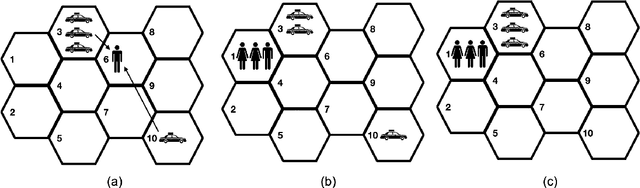
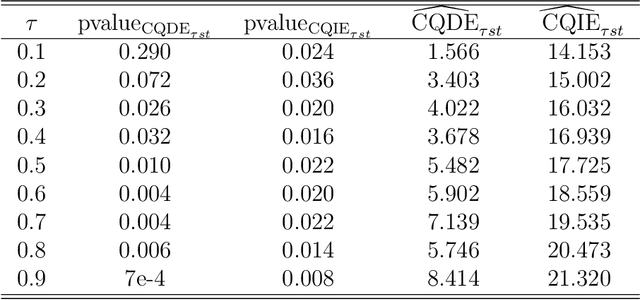
Many modern tech companies, such as Google, Uber, and Didi, utilize online experiments (also known as A/B testing) to evaluate new policies against existing ones. While most studies concentrate on average treatment effects, situations with skewed and heavy-tailed outcome distributions may benefit from alternative criteria, such as quantiles. However, assessing dynamic quantile treatment effects (QTE) remains a challenge, particularly when dealing with data from ride-sourcing platforms that involve sequential decision-making across time and space. In this paper, we establish a formal framework to calculate QTE conditional on characteristics independent of the treatment. Under specific model assumptions, we demonstrate that the dynamic conditional QTE (CQTE) equals the sum of individual CQTEs across time, even though the conditional quantile of cumulative rewards may not necessarily equate to the sum of conditional quantiles of individual rewards. This crucial insight significantly streamlines the estimation and inference processes for our target causal estimand. We then introduce two varying coefficient decision process (VCDP) models and devise an innovative method to test the dynamic CQTE. Moreover, we expand our approach to accommodate data from spatiotemporal dependent experiments and examine both conditional quantile direct and indirect effects. To showcase the practical utility of our method, we apply it to three real-world datasets from a ride-sourcing platform. Theoretical findings and comprehensive simulation studies further substantiate our proposal.
Short-Term Electricity Load Forecasting Using the Temporal Fusion Transformer: Effect of Grid Hierarchies and Data Sources
May 17, 2023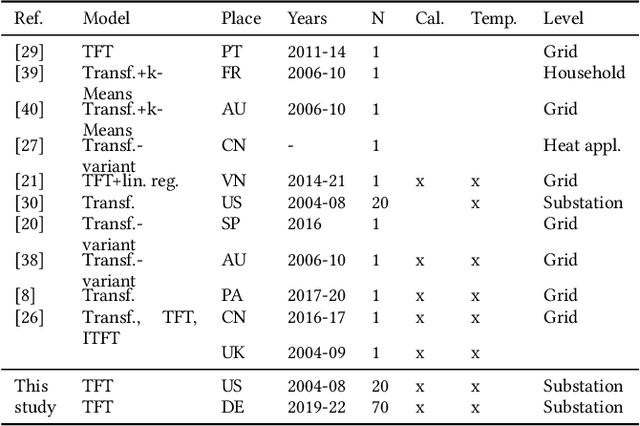
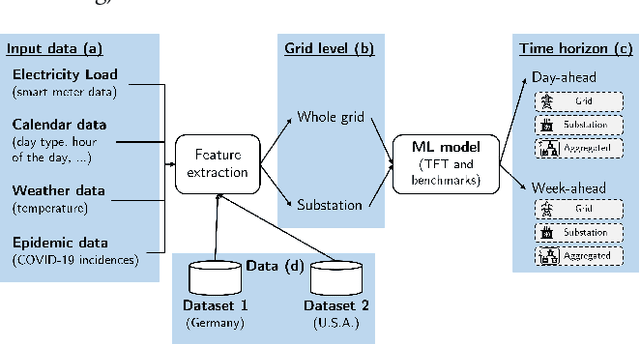
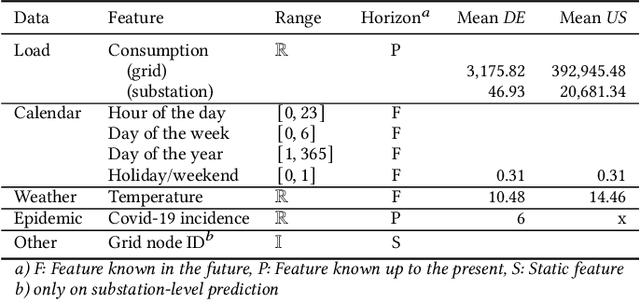
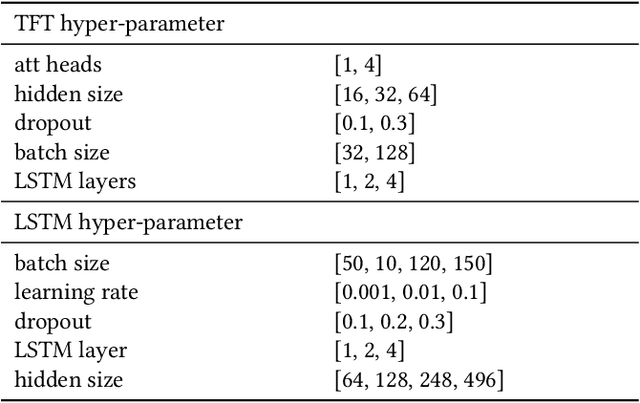
Recent developments related to the energy transition pose particular challenges for distribution grids. Hence, precise load forecasts become more and more important for effective grid management. Novel modeling approaches such as the Transformer architecture, in particular the Temporal Fusion Transformer (TFT), have emerged as promising methods for time series forecasting. To date, just a handful of studies apply TFTs to electricity load forecasting problems, mostly considering only single datasets and a few covariates. Therefore, we examine the potential of the TFT architecture for hourly short-term load forecasting across different time horizons (day-ahead and week-ahead) and network levels (grid and substation level). We find that the TFT architecture does not offer higher predictive performance than a state-of-the-art LSTM model for day-ahead forecasting on the entire grid. However, the results display significant improvements for the TFT when applied at the substation level with a subsequent aggregation to the upper grid-level, resulting in a prediction error of 2.43% (MAPE) for the best-performing scenario. In addition, the TFT appears to offer remarkable improvements over the LSTM approach for week-ahead forecasting (yielding a predictive error of 2.52% (MAPE) at the lowest). We outline avenues for future research using the TFT approach for load forecasting, including the exploration of various grid levels (e.g., grid, substation, and household level).
The 3rd Anti-UAV Workshop & Challenge: Methods and Results
May 12, 2023

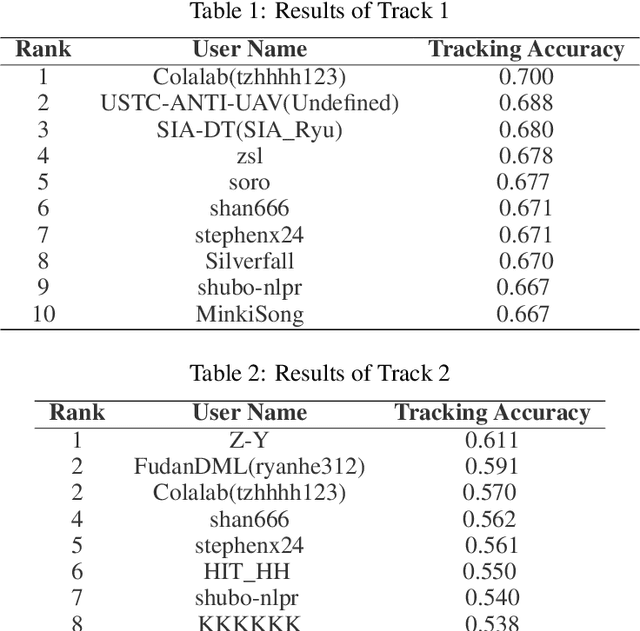
The 3rd Anti-UAV Workshop & Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two main differences between this year's competition and the previous two. First, we have expanded the existing dataset, and for the first time, released a training set so that participants can focus on improving their models. Second, we set up two tracks for the first time, i.e., Anti-UAV Tracking and Anti-UAV Detection & Tracking. Around 76 participating teams from the globe competed in the 3rd Anti-UAV Challenge. In this paper, we provide a brief summary of the 3rd Anti-UAV Workshop & Challenge including brief introductions to the top three methods in each track. The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.
BertRLFuzzer: A BERT and Reinforcement Learning based Fuzzer
May 21, 2023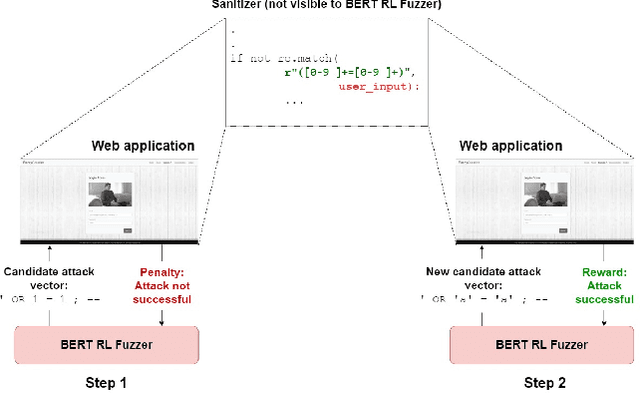
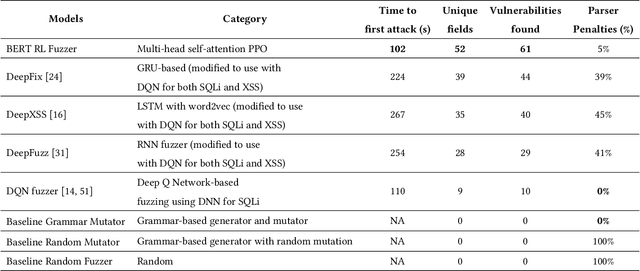
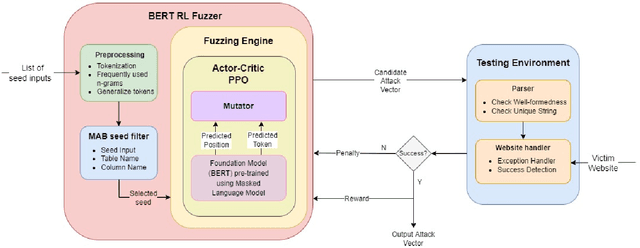
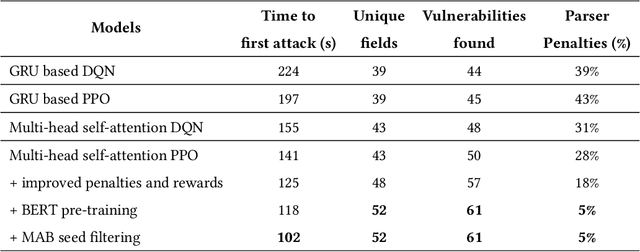
We present a novel tool BertRLFuzzer, a BERT and Reinforcement Learning (RL) based fuzzer aimed at finding security vulnerabilities. BertRLFuzzer works as follows: given a list of seed inputs, the fuzzer performs grammar-adhering and attack-provoking mutation operations on them to generate candidate attack vectors. The key insight of BertRLFuzzer is the combined use of two machine learning concepts. The first one is the use of semi-supervised learning with language models (e.g., BERT) that enables BertRLFuzzer to learn (relevant fragments of) the grammar of a victim application as well as attack patterns, without requiring the user to specify it explicitly. The second one is the use of RL with BERT model as an agent to guide the fuzzer to efficiently learn grammar-adhering and attack-provoking mutation operators. The RL-guided feedback loop enables BertRLFuzzer to automatically search the space of attack vectors to exploit the weaknesses of the given victim application without the need to create labeled training data. Furthermore, these two features together enable BertRLFuzzer to be extensible, i.e., the user can extend BertRLFuzzer to a variety of victim applications and attack vectors automatically (i.e., without explicitly modifying the fuzzer or providing a grammar). In order to establish the efficacy of BertRLFuzzer we compare it against a total of 13 black box and white box fuzzers over a benchmark of 9 victim websites. We observed a significant improvement in terms of time to first attack (54% less than the nearest competing tool), time to find all vulnerabilities (40-60% less than the nearest competing tool), and attack rate (4.4% more attack vectors generated than the nearest competing tool). Our experiments show that the combination of the BERT model and RL-based learning makes BertRLFuzzer an effective, adaptive, easy-to-use, automatic, and extensible fuzzer.
FAQ: Mitigating the Impact of Faults in the Weight Memory of DNN Accelerators through Fault-Aware Quantization
May 21, 2023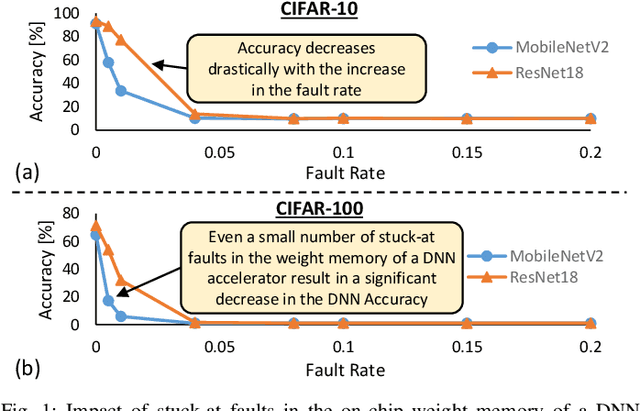
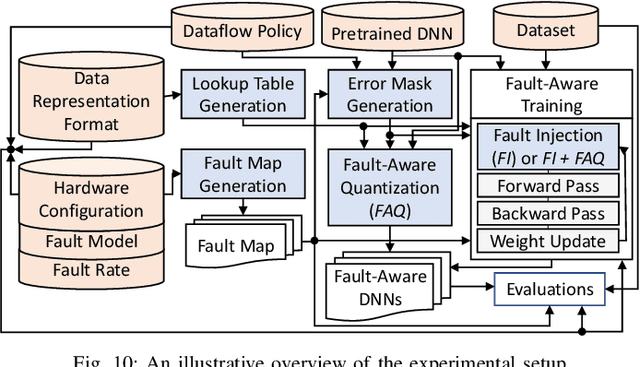
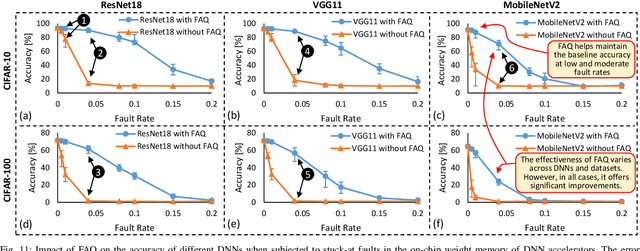
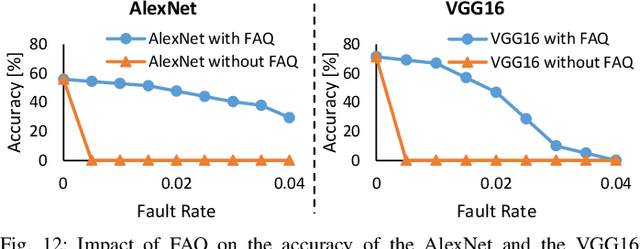
Permanent faults induced due to imperfections in the manufacturing process of Deep Neural Network (DNN) accelerators are a major concern, as they negatively impact the manufacturing yield of the chip fabrication process. Fault-aware training is the state-of-the-art approach for mitigating such faults. However, it incurs huge retraining overheads, specifically when used for large DNNs trained on complex datasets. To address this issue, we propose a novel Fault-Aware Quantization (FAQ) technique for mitigating the effects of stuck-at permanent faults in the on-chip weight memory of DNN accelerators at a negligible overhead cost compared to fault-aware retraining while offering comparable accuracy results. We propose a lookup table-based algorithm to achieve ultra-low model conversion time. We present extensive evaluation of the proposed approach using five different DNNs, i.e., ResNet-18, VGG11, VGG16, AlexNet and MobileNetV2, and three different datasets, i.e., CIFAR-10, CIFAR-100 and ImageNet. The results demonstrate that FAQ helps in maintaining the baseline accuracy of the DNNs at low and moderate fault rates without involving costly fault-aware training. For example, for ResNet-18 trained on the CIFAR-10 dataset, at 0.04 fault rate FAQ offers (on average) an increase of 76.38% in accuracy. Similarly, for VGG11 trained on the CIFAR-10 dataset, at 0.04 fault rate FAQ offers (on average) an increase of 70.47% in accuracy. The results also show that FAQ incurs negligible overheads, i.e., less than 5% of the time required to run 1 epoch of retraining. We additionally demonstrate the efficacy of our technique when used in conjunction with fault-aware retraining and show that the use of FAQ inside fault-aware retraining enables fast accuracy recovery.
Farewell to Aimless Large-scale Pretraining: Influential Subset Selection for Language Model
May 22, 2023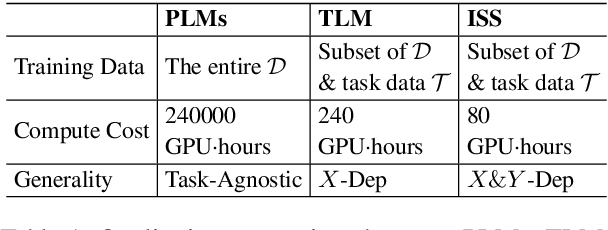
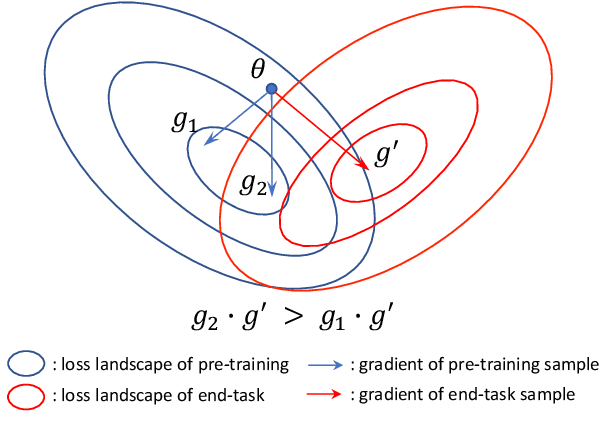
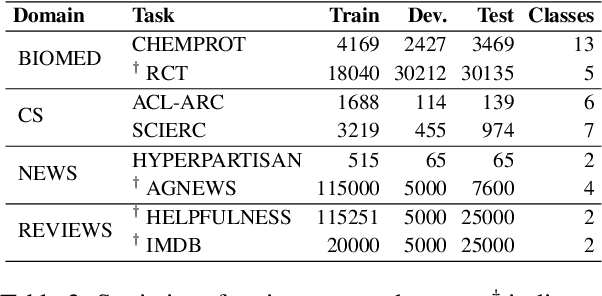
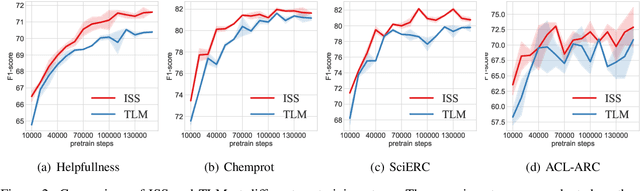
Pretrained language models have achieved remarkable success in various natural language processing tasks. However, pretraining has recently shifted toward larger models and larger data, and this has resulted in significant computational and energy costs. In this paper, we propose Influence Subset Selection (ISS) for language model, which explicitly utilizes end-task knowledge to select a tiny subset of the pretraining corpus. Specifically, the ISS selects the samples that will provide the most positive influence on the performance of the end-task. Furthermore, we design a gradient matching based influence estimation method, which can drastically reduce the computation time of influence. With only 0.45% of the data and a three-orders-of-magnitude lower computational cost, ISS outperformed pretrained models (e.g., RoBERTa) on eight datasets covering four domains.
Efficient Learning of Quantum States Prepared With Few Non-Clifford Gates
May 22, 2023We give an algorithm that efficiently learns a quantum state prepared by Clifford gates and $O(\log(n))$ non-Clifford gates. Specifically, for an $n$-qubit state $\lvert \psi \rangle$ prepared with at most $t$ non-Clifford gates, we show that $\mathsf{poly}(n,2^t,1/\epsilon)$ time and copies of $\lvert \psi \rangle$ suffice to learn $\lvert \psi \rangle$ to trace distance at most $\epsilon$. This result follows as a special case of an algorithm for learning states with large stabilizer dimension, where a quantum state has stabilizer dimension $k$ if it is stabilized by an abelian group of $2^k$ Pauli operators. We also develop an efficient property testing algorithm for stabilizer dimension, which may be of independent interest.
3D Rotation and Translation for Hyperbolic Knowledge Graph Embedding
May 22, 2023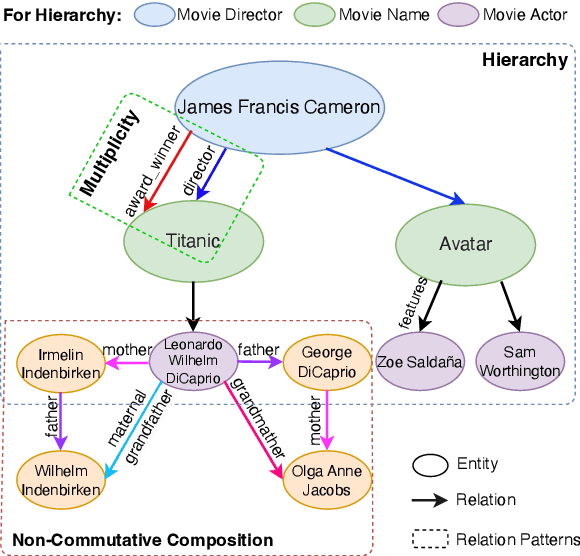

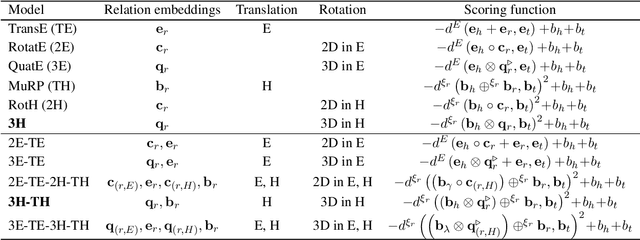
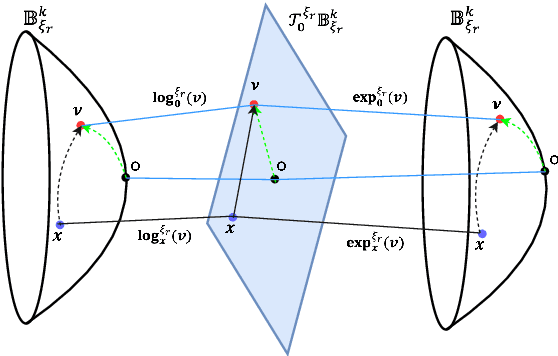
The main objective of Knowledge Graph (KG) embeddings is to learn low-dimensional representations of entities and relations, enabling the prediction of missing facts. A significant challenge in achieving better KG embeddings lies in capturing relation patterns, including symmetry, antisymmetry, inversion, commutative composition, non-commutative composition, hierarchy, and multiplicity. This study introduces a novel model called 3H-TH (3D Rotation and Translation in Hyperbolic space) that captures these relation patterns simultaneously. In contrast, previous attempts have not achieved satisfactory performance across all the mentioned properties at the same time. The experimental results demonstrate that the new model outperforms existing state-of-the-art models in terms of accuracy, hierarchy property, and other relation patterns in low-dimensional space, meanwhile performing similarly in high-dimensional space.