 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ReactFace: Multiple Appropriate Facial Reaction Generation in Dyadic Interactions
May 25, 2023

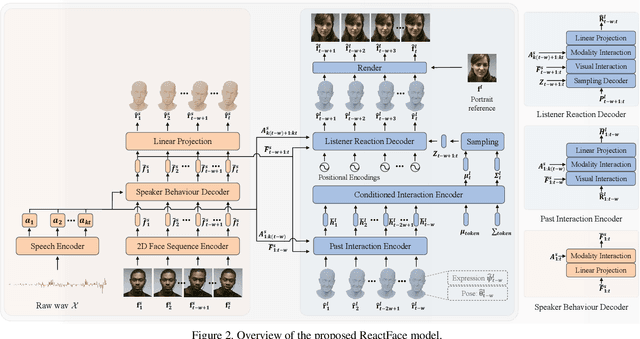

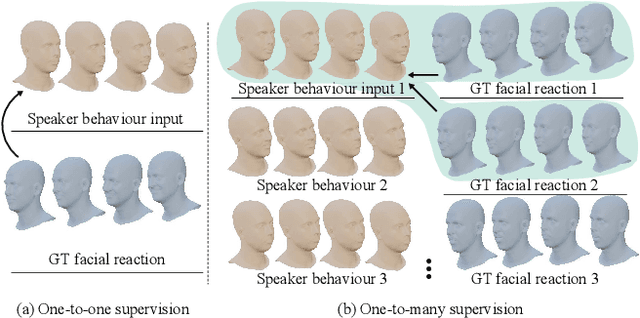
In dyadic interaction, predicting the listener's facial reactions is challenging as different reactions may be appropriate in response to the same speaker's behaviour. This paper presents a novel framework called ReactFace that learns an appropriate facial reaction distribution from a speaker's behaviour rather than replicating the real facial reaction of the listener. ReactFace generates multiple different but appropriate photo-realistic human facial reactions by (i) learning an appropriate facial reaction distribution representing multiple appropriate facial reactions; and (ii) synchronizing the generated facial reactions with the speaker's verbal and non-verbal behaviours at each time stamp, resulting in realistic 2D facial reaction sequences. Experimental results demonstrate the effectiveness of our approach in generating multiple diverse, synchronized, and appropriate facial reactions from each speaker's behaviour, with the quality of the generated reactions being influenced by the speaker's speech and facial behaviours. Our code is made publicly available at \url{https://github.com/lingjivoo/ReactFace}.
Assessing the Spatial Structure of the Association between Attendance at Preschool and Childrens Developmental Vulnerabilities in Queensland Australia
May 25, 2023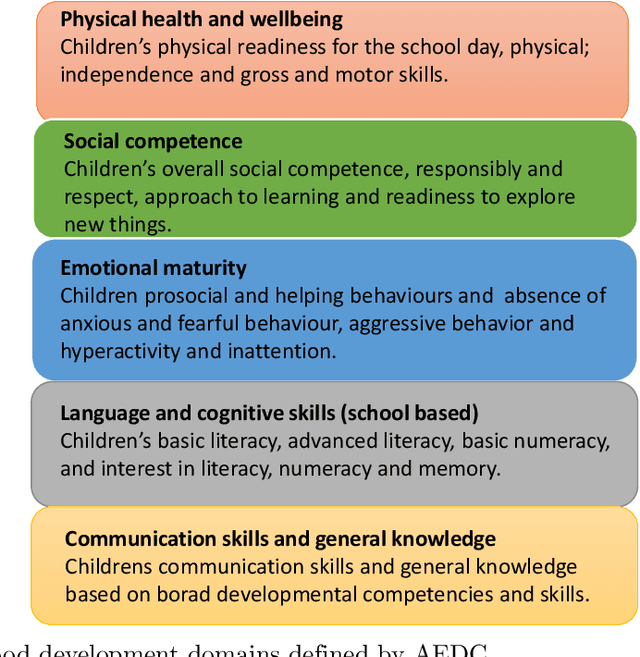
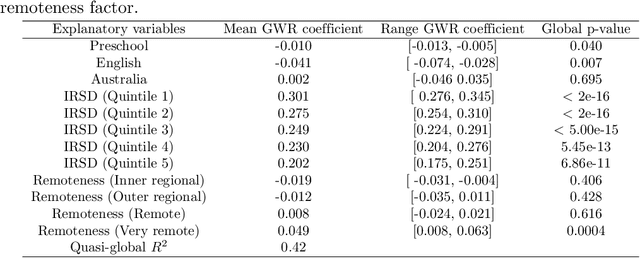
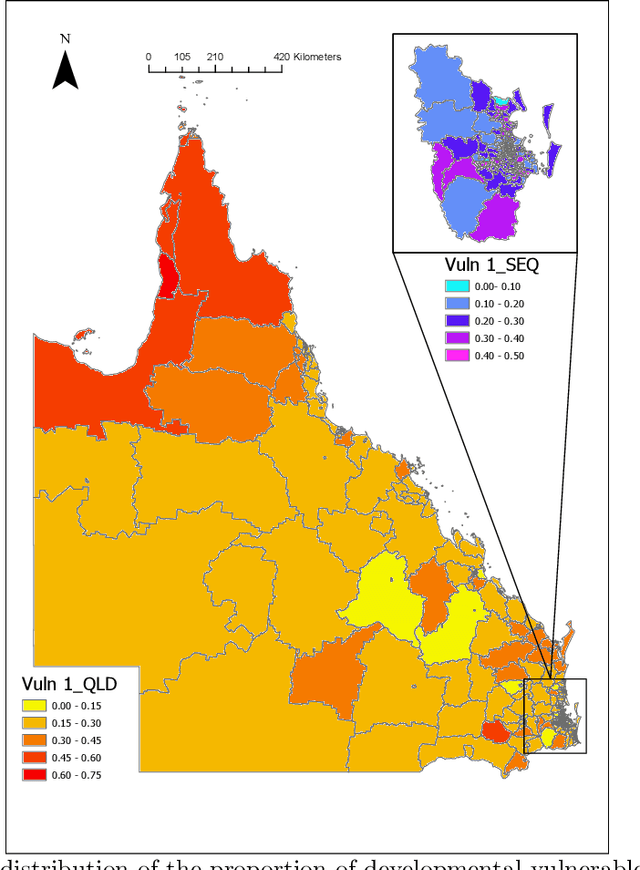
The research explores the influence of preschool attendance (one year before full-time school) on the development of children during their first year of school. Using data collected by the Australian Early Development Census, the findings show that areas with high proportions of preschool attendance tended to have lower proportions of children with at least one developmental vulnerability. Developmental vulnerablities include not being able to cope with the school day (tired, hungry, low energy), unable to get along with others or aggressive behaviour, trouble with reading/writing or numbers. These findings, of course, vary by region. Using Data Analysis and Machine Learning, the researchers were able to identify three distinct clusters within Queensland, each characterised by different socio-demographic variables influencing the relationship between preschool attendance and developmental vulnerability. These analyses contribute to understanding regions with high vulnerability and the potential need for tailored policies or investments
IMBERT: Making BERT Immune to Insertion-based Backdoor Attacks
May 25, 2023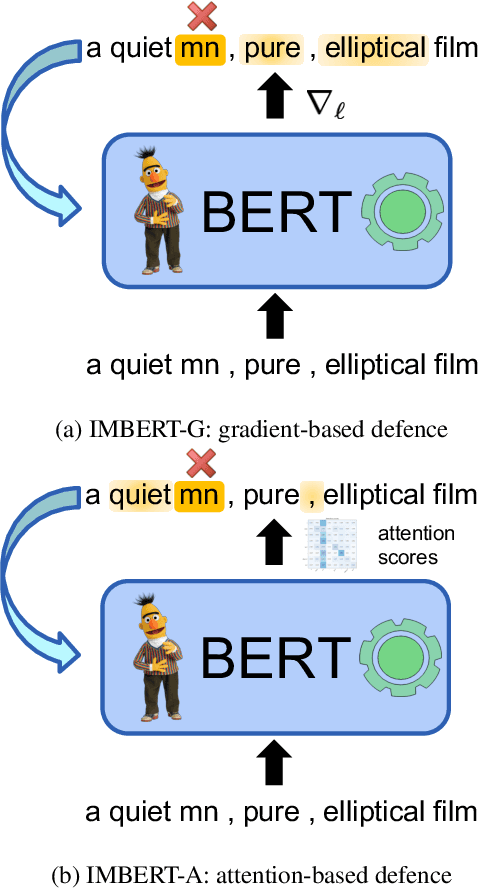
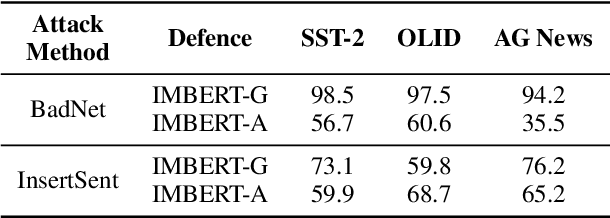
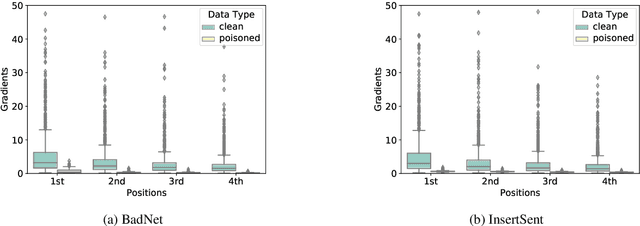
Backdoor attacks are an insidious security threat against machine learning models. Adversaries can manipulate the predictions of compromised models by inserting triggers into the training phase. Various backdoor attacks have been devised which can achieve nearly perfect attack success without affecting model predictions for clean inputs. Means of mitigating such vulnerabilities are underdeveloped, especially in natural language processing. To fill this gap, we introduce IMBERT, which uses either gradients or self-attention scores derived from victim models to self-defend against backdoor attacks at inference time. Our empirical studies demonstrate that IMBERT can effectively identify up to 98.5% of inserted triggers. Thus, it significantly reduces the attack success rate while attaining competitive accuracy on the clean dataset across widespread insertion-based attacks compared to two baselines. Finally, we show that our approach is model-agnostic, and can be easily ported to several pre-trained transformer models.
Accelerating genetic optimization of nonlinear model predictive control by learning optimal search space size
May 14, 2023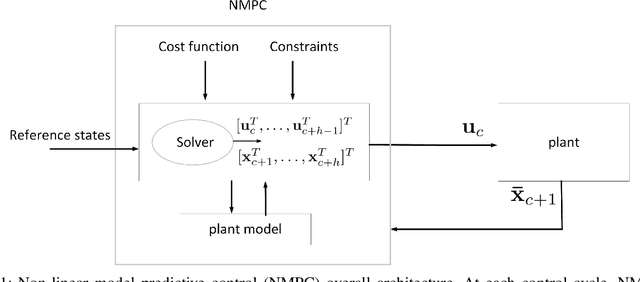
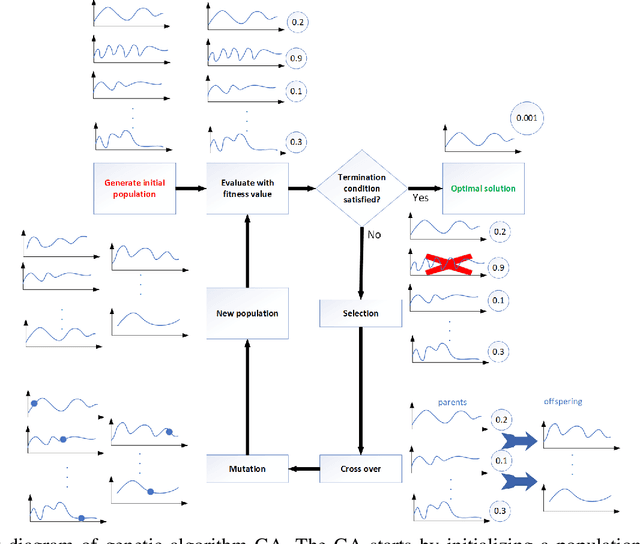
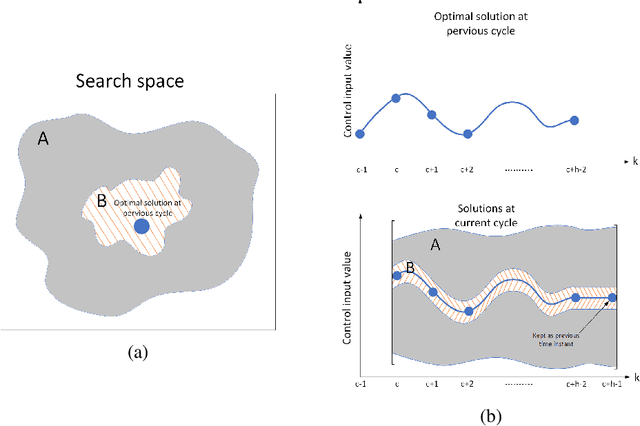
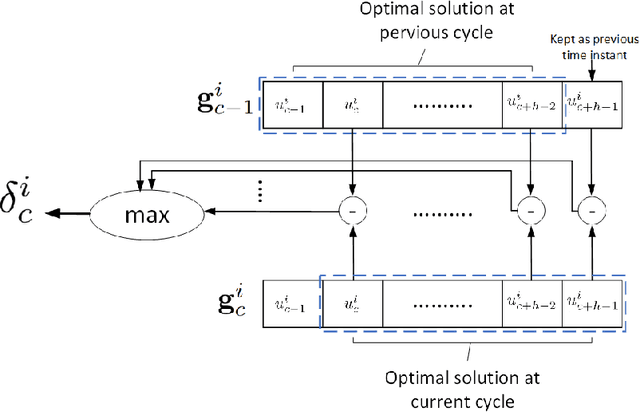
Nonlinear model predictive control (NMPC) solves a multivariate optimization problem to estimate the system's optimal control inputs in each control cycle. Such optimization is made more difficult by several factors, such as nonlinearities inherited in the system, highly coupled inputs, and various constraints related to the system's physical limitations. These factors make the optimization to be non-convex and hard to solve traditionally. Genetic algorithm (GA) is typically used extensively to tackle such optimization in several application domains because it does not involve differential calculation or gradient evaluation in its solution estimation. However, the size of the search space in which the GA searches for the optimal control inputs is crucial for the applicability of the GA with systems that require fast response. This paper proposes an approach to accelerate the genetic optimization of NMPC by learning optimal search space size. The proposed approach trains a multivariate regression model to adaptively predict the best smallest search space in every control cycle. The estimated best smallest size of search space is fed to the GA to allow for searching the optimal control inputs within this search space. The proposed approach not only reduces the GA's computational time but also improves the chance of obtaining the optimal control inputs in each cycle. The proposed approach was evaluated on two nonlinear systems and compared with two other genetic-based NMPC approaches implemented on the GPU of a Nvidia Jetson TX2 embedded platform in a processor-in-the-loop (PIL) fashion. The results show that the proposed approach provides a 39-53\% reduction in computational time. Additionally, it increases the convergence percentage to the optimal control inputs within the cycle's time by 48-56\%, resulting in a significant performance enhancement. The source code is available on GitHub.
RepCL: Exploring Effective Representation for Continual Text Classification
May 12, 2023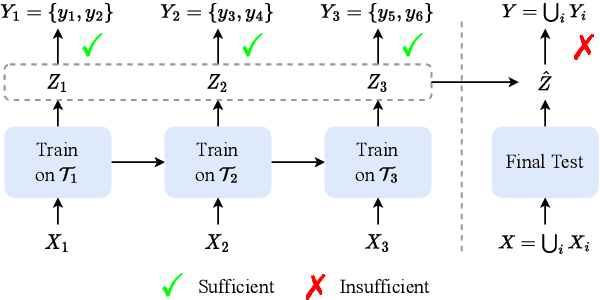
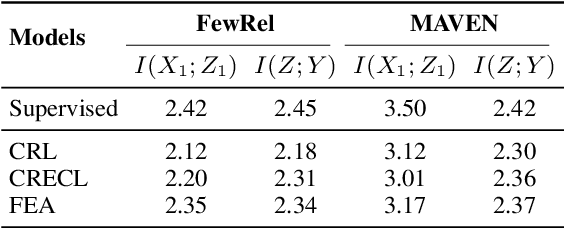
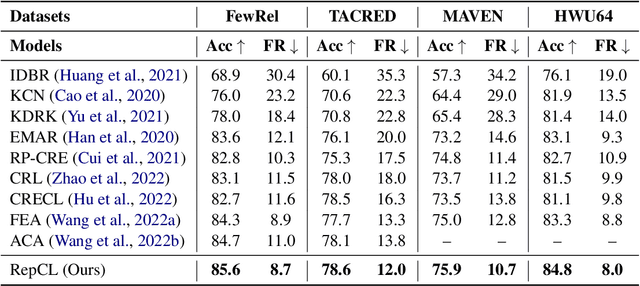
Continual learning (CL) aims to constantly learn new knowledge over time while avoiding catastrophic forgetting on old tasks. In this work, we focus on continual text classification under the class-incremental setting. Recent CL studies find that the representations learned in one task may not be effective for other tasks, namely representation bias problem. For the first time we formally analyze representation bias from an information bottleneck perspective and suggest that exploiting representations with more class-relevant information could alleviate the bias. To this end, we propose a novel replay-based continual text classification method, RepCL. Our approach utilizes contrastive and generative representation learning objectives to capture more class-relevant features. In addition, RepCL introduces an adversarial replay strategy to alleviate the overfitting problem of replay. Experiments demonstrate that RepCL effectively alleviates forgetting and achieves state-of-the-art performance on three text classification tasks.
Measuring Surprise in the Wild
May 12, 2023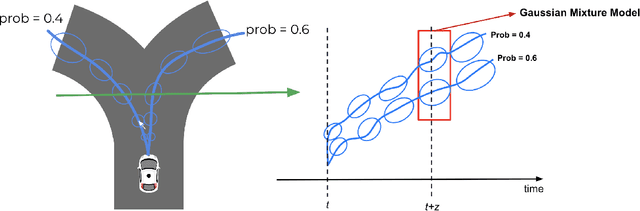

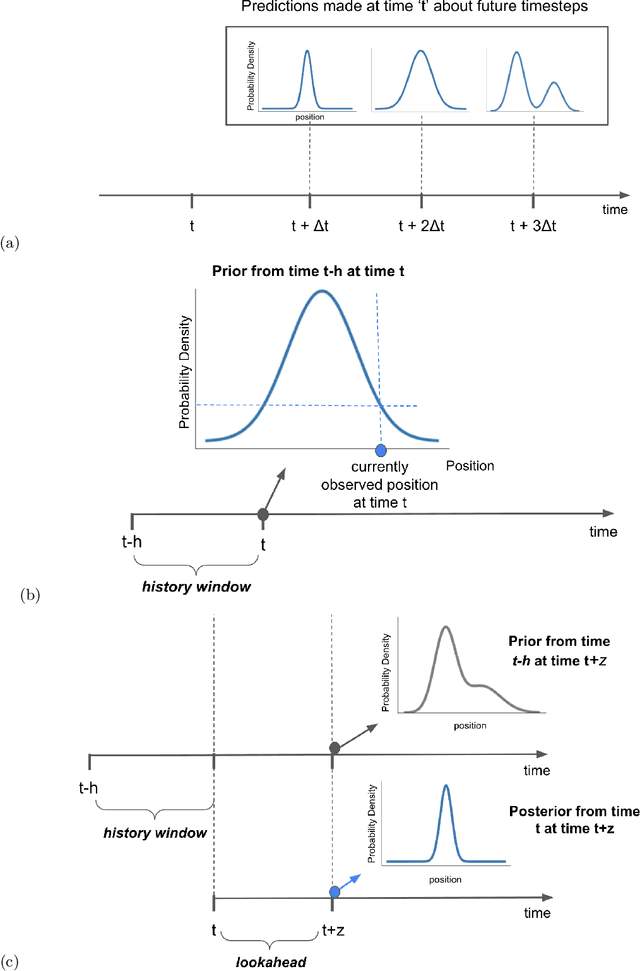
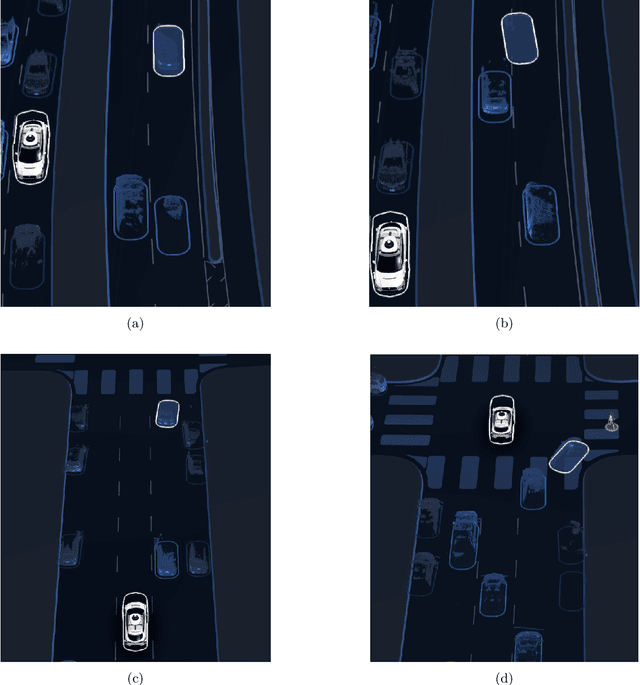
The quantitative measurement of how and when we experience surprise has mostly remained limited to laboratory studies, and its extension to naturalistic settings has been challenging. Here we demonstrate, for the first time, how computational models of surprise rooted in cognitive science and neuroscience combined with state-of-the-art machine learned generative models can be used to detect surprising human behavior in complex, dynamic environments like road traffic. In traffic safety, such models can support the identification of traffic conflicts, modeling of road user response time, and driving behavior evaluation for both human and autonomous drivers. We also present novel approaches to quantify surprise and use naturalistic driving scenarios to demonstrate a number of advantages over existing surprise measures from the literature. Modeling surprising behavior using learned generative models is a novel concept that can be generalized beyond traffic safety to any dynamic real-world environment.
Probabilistic RRT Connect with intermediate goal selection for online planning of autonomous vehicles
May 14, 2023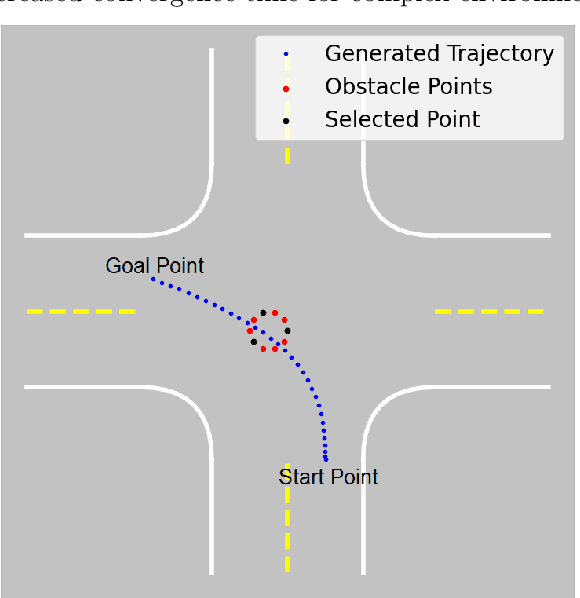
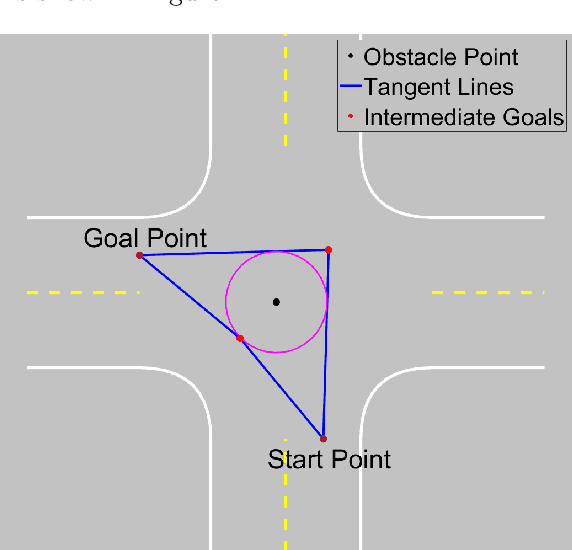
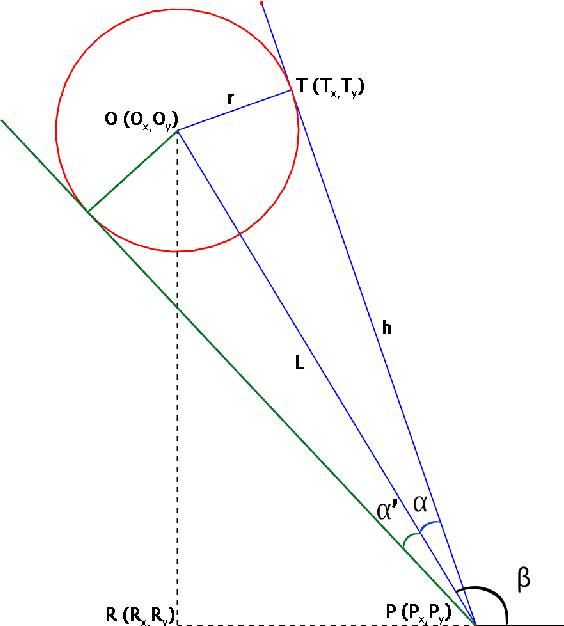
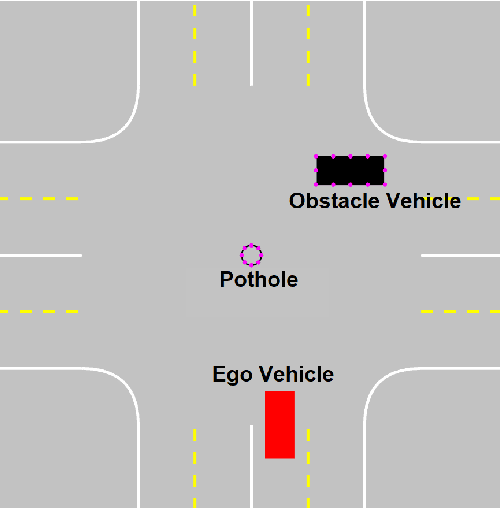
Rapidly Exploring Random Trees (RRT) is one of the most widely used algorithms for motion planning in the field of robotics. To reduce the exploration time, RRT-Connect was introduced where two trees are simultaneously formed and eventually connected. Probabilistic RRT used the concept of position probability map to introduce goal biasing for faster convergence. In this paper, we propose a modified method to combine the pRRT and RRT-Connect techniques and obtain a feasible trajectory around the obstacles quickly. Instead of forming a single tree from the start point to the destination point, intermediate goal points are selected around the obstacles. Multiple trees are formed to connect the start, destination, and intermediate goal points. These partial trees are eventually connected to form an overall safe path around the obstacles. The obtained path is tracked using an MPC + Stanley controller which results in a trajectory with control commands at each time step. The trajectories generated by the proposed methods are more optimal and in accordance with human intuition. The algorithm is compared with the standard RRT and pRRT for studying its relative performance.
Trustworthy Deep Learning for Medical Image Segmentation
May 27, 2023Despite the recent success of deep learning methods at achieving new state-of-the-art accuracy for medical image segmentation, some major limitations are still restricting their deployment into clinics. One major limitation of deep learning-based segmentation methods is their lack of robustness to variability in the image acquisition protocol and in the imaged anatomy that were not represented or were underrepresented in the training dataset. This suggests adding new manually segmented images to the training dataset to better cover the image variability. However, in most cases, the manual segmentation of medical images requires highly skilled raters and is time-consuming, making this solution prohibitively expensive. Even when manually segmented images from different sources are available, they are rarely annotated for exactly the same regions of interest. This poses an additional challenge for current state-of-the-art deep learning segmentation methods that rely on supervised learning and therefore require all the regions of interest to be segmented for all the images to be used for training. This thesis introduces new mathematical and optimization methods to mitigate those limitations.
Grounding Characters and Places in Narrative Texts
May 27, 2023

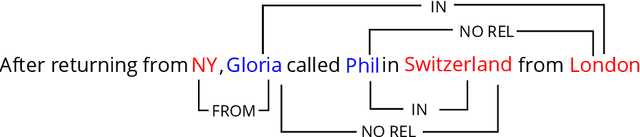

Tracking characters and locations throughout a story can help improve the understanding of its plot structure. Prior research has analyzed characters and locations from text independently without grounding characters to their locations in narrative time. Here, we address this gap by proposing a new spatial relationship categorization task. The objective of the task is to assign a spatial relationship category for every character and location co-mention within a window of text, taking into consideration linguistic context, narrative tense, and temporal scope. To this end, we annotate spatial relationships in approximately 2500 book excerpts and train a model using contextual embeddings as features to predict these relationships. When applied to a set of books, this model allows us to test several hypotheses on mobility and domestic space, revealing that protagonists are more mobile than non-central characters and that women as characters tend to occupy more interior space than men. Overall, our work is the first step towards joint modeling and analysis of characters and places in narrative text.
A sensor fusion approach for improving implementation speed and accuracy of RTAB-Map algorithm based indoor 3D mapping
May 08, 2023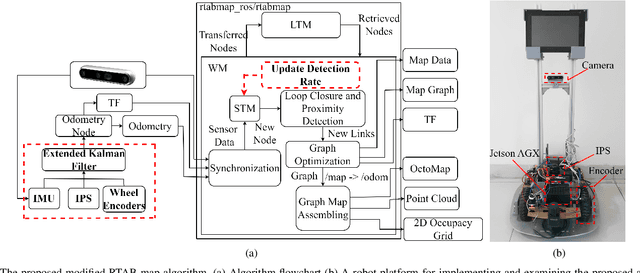
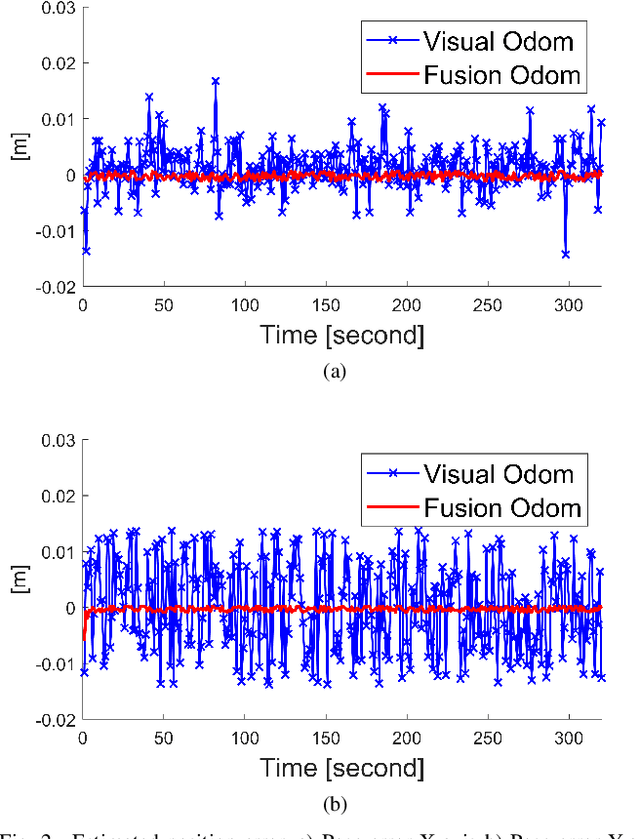
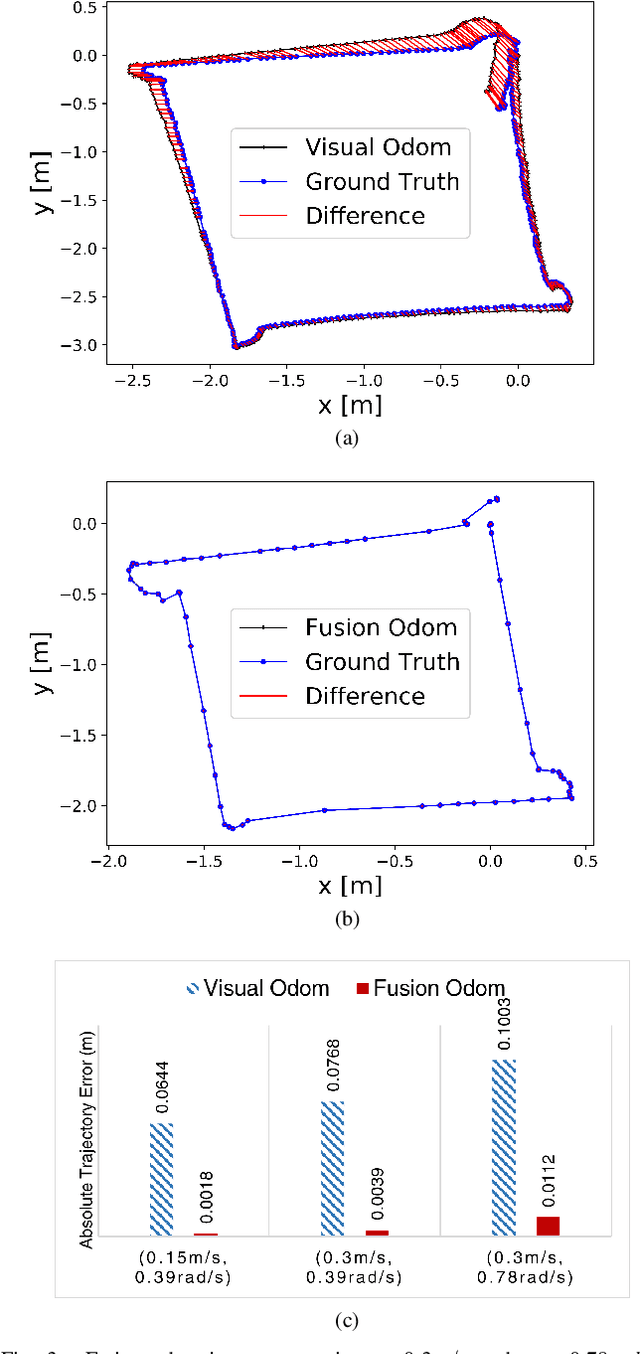

In recent years, 3D mapping for indoor environments has undergone considerable research and improvement because of its effective applications in various fields, including robotics, autonomous navigation, and virtual reality. Building an accurate 3D map for indoor environment is challenging due to the complex nature of the indoor space, the problem of real-time embedding and positioning errors of the robot system. This study proposes a method to improve the accuracy, speed, and quality of 3D indoor mapping by fusing data from the Inertial Measurement System (IMU) of the Intel Realsense D435i camera, the Ultrasonic-based Indoor Positioning System (IPS), and the encoder of the robot's wheel using the extended Kalman filter (EKF) algorithm. The merged data is processed using a Real-time Image Based Mapping algorithm (RTAB-Map), with the processing frequency updated in synch with the position frequency of the IPS device. The results suggest that fusing IMU and IPS data significantly improves the accuracy, mapping time, and quality of 3D maps. Our study highlights the proposed method's potential to improve indoor mapping in various fields, indicating that the fusion of multiple data sources can be a valuable tool in creating high-quality 3D indoor maps.