 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Convergence and Generalization Using Parameter Symmetries
May 22, 2023
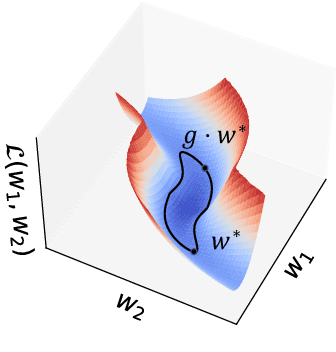

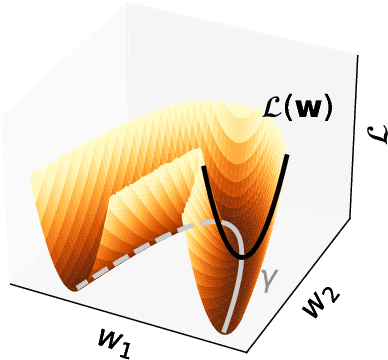
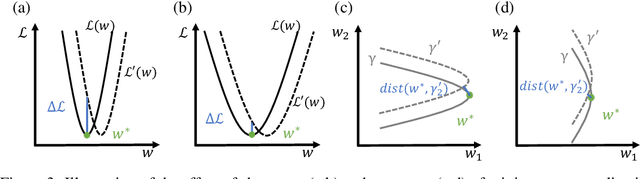
In overparametrized models, different values of the parameters may result in the same loss value. Parameter space symmetries are transformations that change the model parameters but leave the loss invariant. Teleportation applies such transformations to accelerate optimization. However, the exact mechanism behind this algorithm's success is not well understood. In this paper, we show that teleportation not only speeds up optimization in the short-term, but gives overall faster time to convergence. Additionally, we show that teleporting to minima with different curvatures improves generalization and provide insights on the connection between the curvature of the minima and generalization ability. Finally, we show that integrating teleportation into a wide range of optimization algorithms and optimization-based meta-learning improves convergence.
Towards generalizing deep-audio fake detection networks
May 22, 2023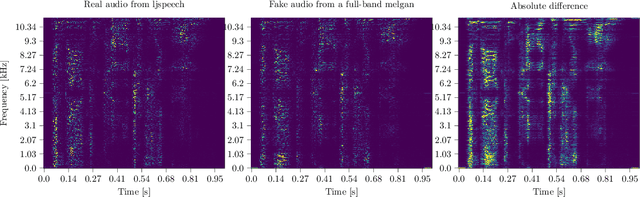
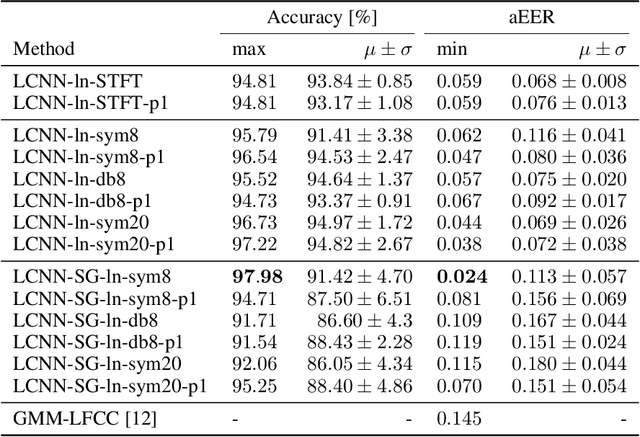
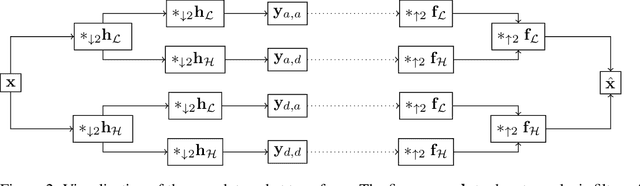
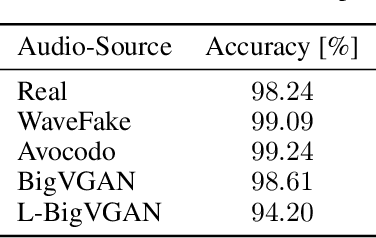
Today's generative neural networks allow the creation of high-quality synthetic speech at scale. While we welcome the creative use of this new technology, we must also recognize the risks. As synthetic speech is abused for both monetary and identity theft, we require a broad set of deep fake identification tools. Furthermore, previous work reported a limited ability of deep classifiers to generalize to unseen audio generators. By leveraging the wavelet-packet and short-time Fourier transform, we train excellent lightweight detectors that generalize. We report improved results on an extension of the WaveFake dataset. To account for the rapid progress in the field, we additionally consider samples drawn from the novel Avocodo and BigVGAN networks.
Approximating a RUM from Distributions on k-Slates
May 22, 2023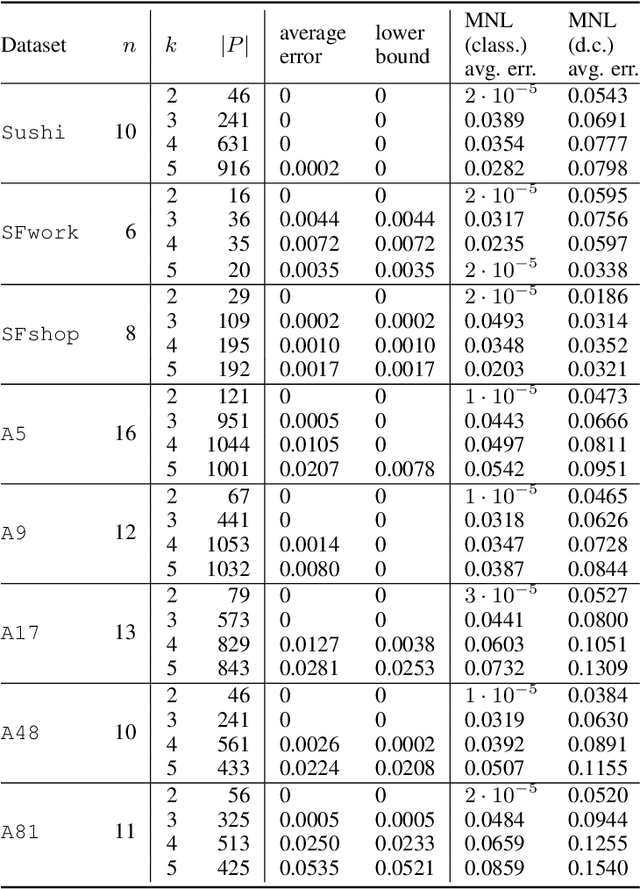
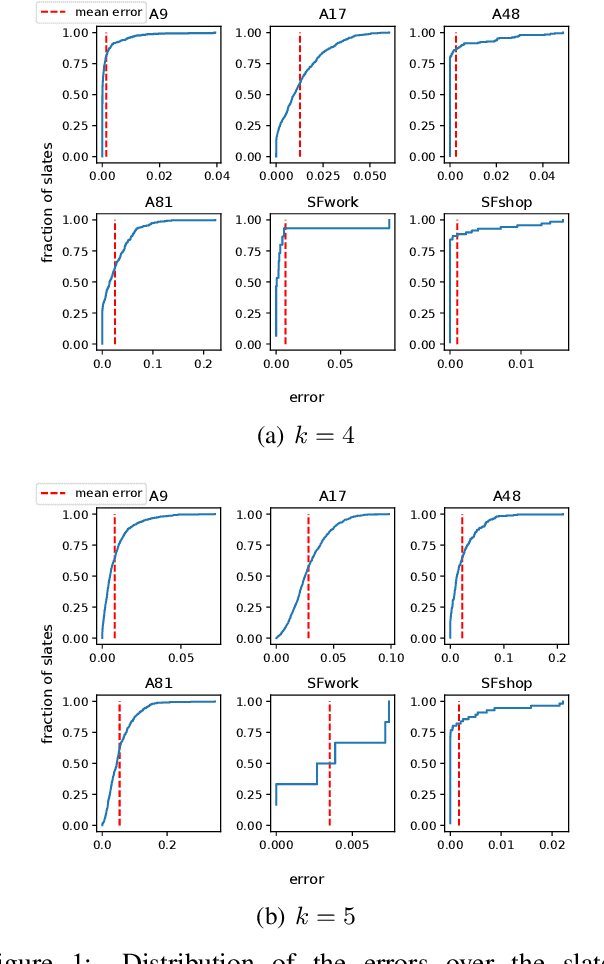
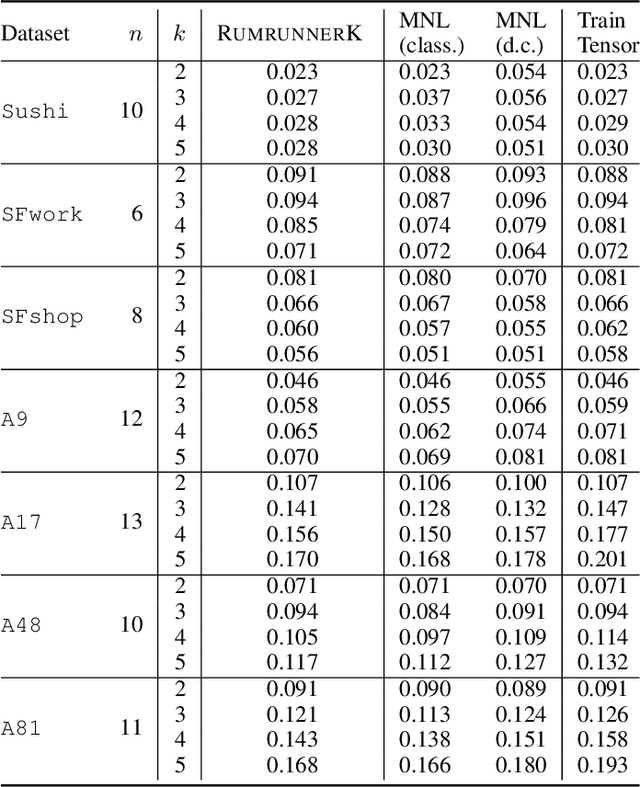
In this work we consider the problem of fitting Random Utility Models (RUMs) to user choices. Given the winner distributions of the subsets of size $k$ of a universe, we obtain a polynomial-time algorithm that finds the RUM that best approximates the given distribution on average. Our algorithm is based on a linear program that we solve using the ellipsoid method. Given that its corresponding separation oracle problem is NP-hard, we devise an approximate separation oracle that can be viewed as a generalization of the weighted feedback arc set problem to hypergraphs. Our theoretical result can also be made practical: we obtain a heuristic that is effective and scales to real-world datasets.
Fast Convergence in Learning Two-Layer Neural Networks with Separable Data
May 22, 2023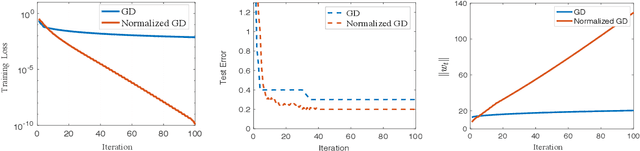
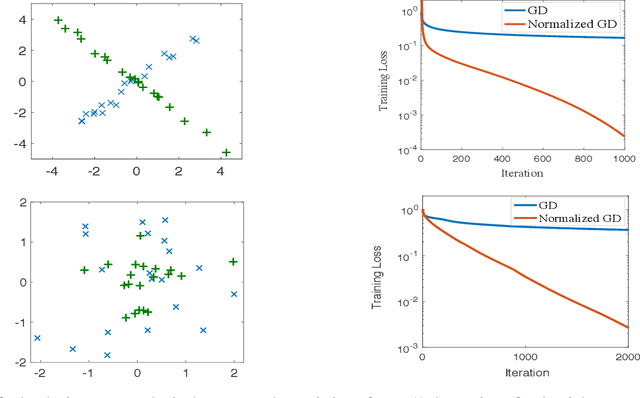
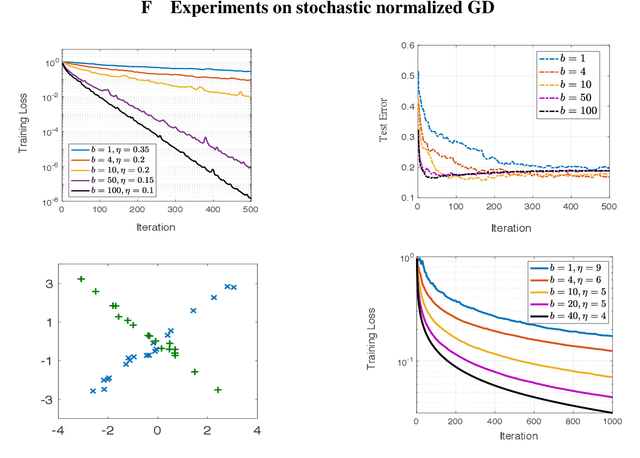
Normalized gradient descent has shown substantial success in speeding up the convergence of exponentially-tailed loss functions (which includes exponential and logistic losses) on linear classifiers with separable data. In this paper, we go beyond linear models by studying normalized GD on two-layer neural nets. We prove for exponentially-tailed losses that using normalized GD leads to linear rate of convergence of the training loss to the global optimum. This is made possible by showing certain gradient self-boundedness conditions and a log-Lipschitzness property. We also study generalization of normalized GD for convex objectives via an algorithmic-stability analysis. In particular, we show that normalized GD does not overfit during training by establishing finite-time generalization bounds.
Trend Investigation of Biopotential Recording Front-End Channels for Invasive and Non-Invasive Applications
May 22, 2023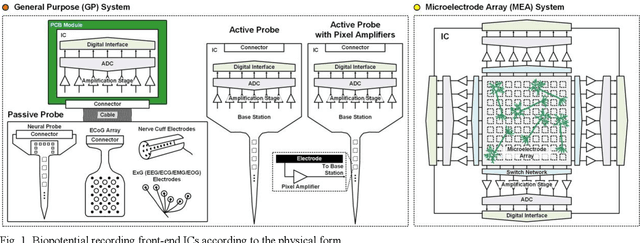
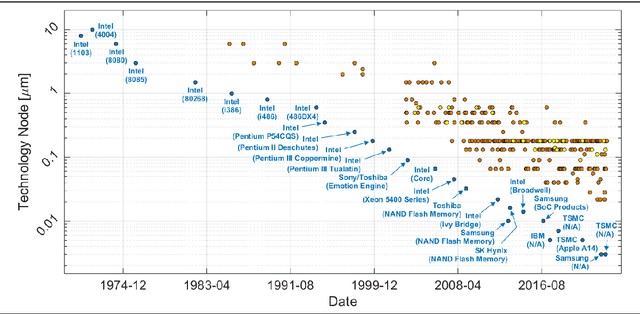
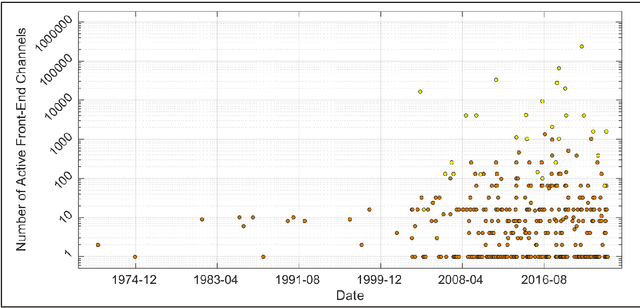
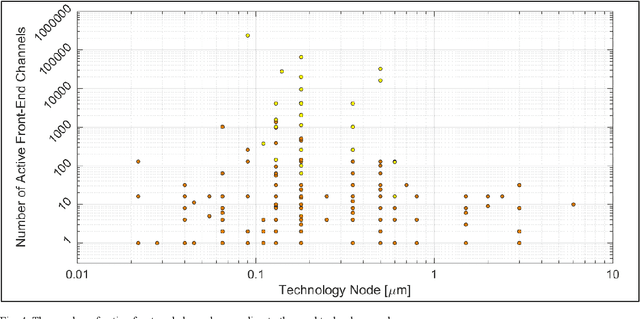
This paper presents the trend of biopotential recording front-end channels developed from the 1970s to the 2020s while describing a basic background on the front-end channel design. Only the front-end channels that conduct electrical recording invasively and non-invasively are addressed. The front-end channels are investigated in terms of technology node, number of channels, supply voltage, noise efficiency factor, and power efficiency factor. Also, multi-faceted comparisons are made to figure out the correlation between these five categories. In each category, the design trend is presented over time, and related circuit techniques are discussed. While addressing the characteristics of circuit techniques used to improve the channel performance, what needs to be improved is also suggested.
Analysis of Real-Time Hostile Activitiy Detection from Spatiotemporal Features Using Time Distributed Deep CNNs, RNNs and Attention-Based Mechanisms
Feb 21, 2023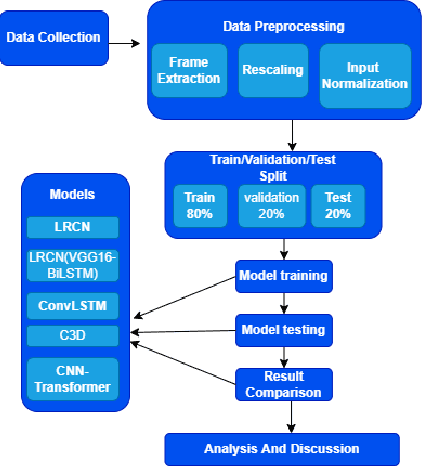
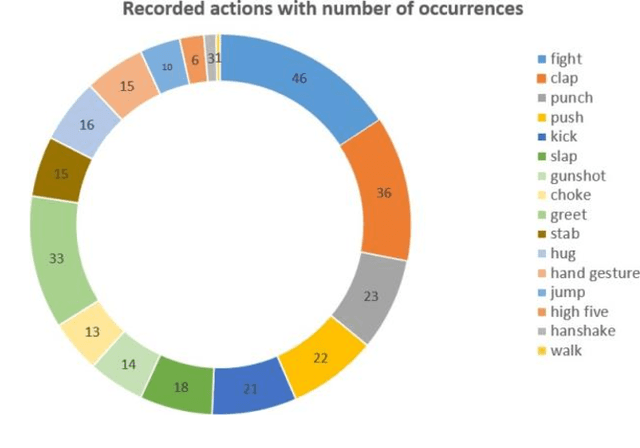
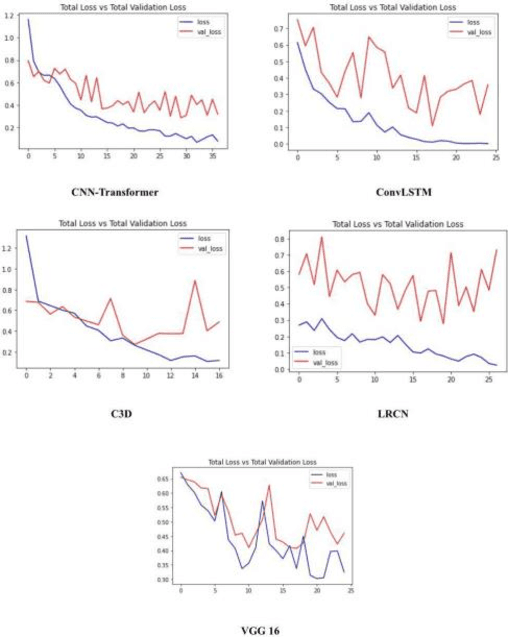
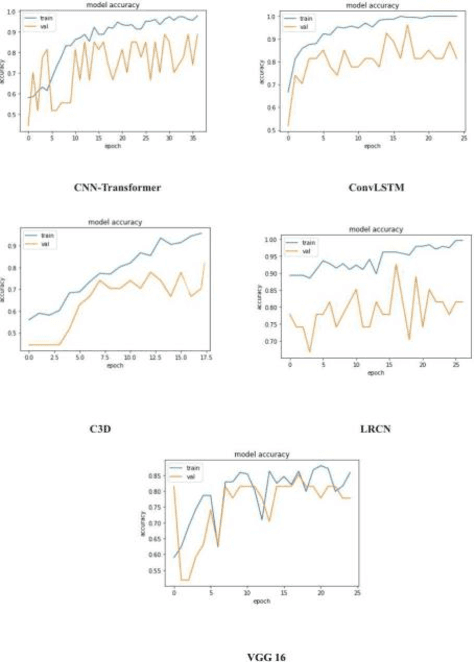
Real-time video surveillance, through CCTV camera systems has become essential for ensuring public safety which is a priority today. Although CCTV cameras help a lot in increasing security, these systems require constant human interaction and monitoring. To eradicate this issue, intelligent surveillance systems can be built using deep learning video classification techniques that can help us automate surveillance systems to detect violence as it happens. In this research, we explore deep learning video classification techniques to detect violence as they are happening. Traditional image classification techniques fall short when it comes to classifying videos as they attempt to classify each frame separately for which the predictions start to flicker. Therefore, many researchers are coming up with video classification techniques that consider spatiotemporal features while classifying. However, deploying these deep learning models with methods such as skeleton points obtained through pose estimation and optical flow obtained through depth sensors, are not always practical in an IoT environment. Although these techniques ensure a higher accuracy score, they are computationally heavier. Keeping these constraints in mind, we experimented with various video classification and action recognition techniques such as ConvLSTM, LRCN (with both custom CNN layers and VGG-16 as feature extractor) CNNTransformer and C3D. We achieved a test accuracy of 80% on ConvLSTM, 83.33% on CNN-BiLSTM, 70% on VGG16-BiLstm ,76.76% on CNN-Transformer and 80% on C3D.
ToxBuster: In-game Chat Toxicity Buster with BERT
May 21, 2023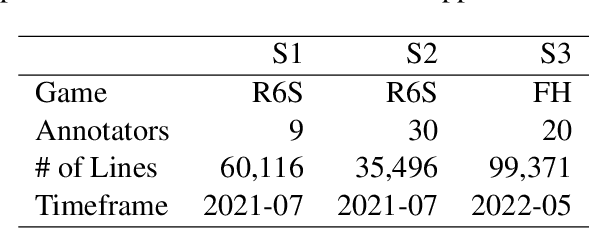
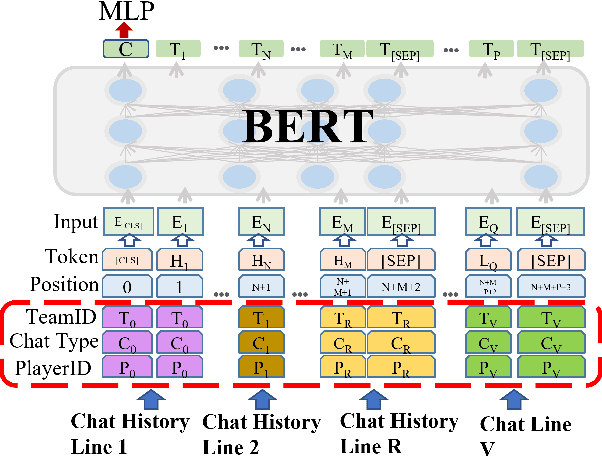
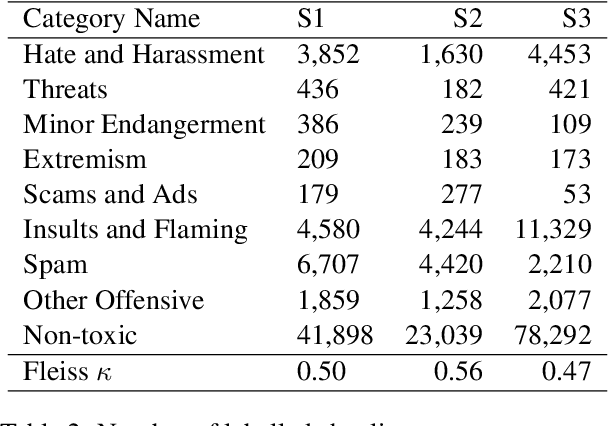
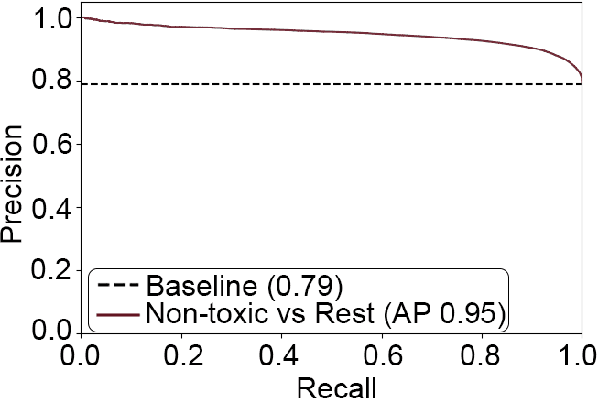
Detecting toxicity in online spaces is challenging and an ever more pressing problem given the increase in social media and gaming consumption. We introduce ToxBuster, a simple and scalable model trained on a relatively large dataset of 194k lines of game chat from Rainbow Six Siege and For Honor, carefully annotated for different kinds of toxicity. Compared to the existing state-of-the-art, ToxBuster achieves 82.95% (+7) in precision and 83.56% (+57) in recall. This improvement is obtained by leveraging past chat history and metadata. We also study the implication towards real-time and post-game moderation as well as the model transferability from one game to another.
MIDI-Draw: Sketching to Control Melody Generation
May 19, 2023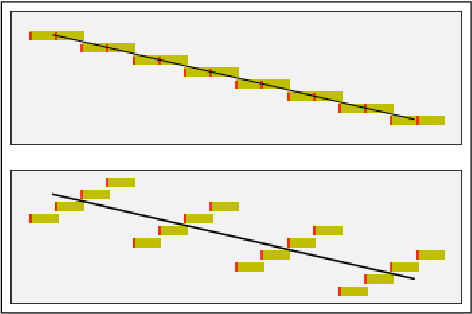
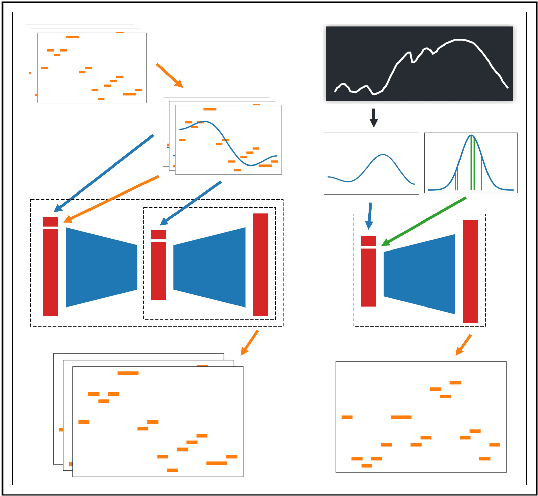
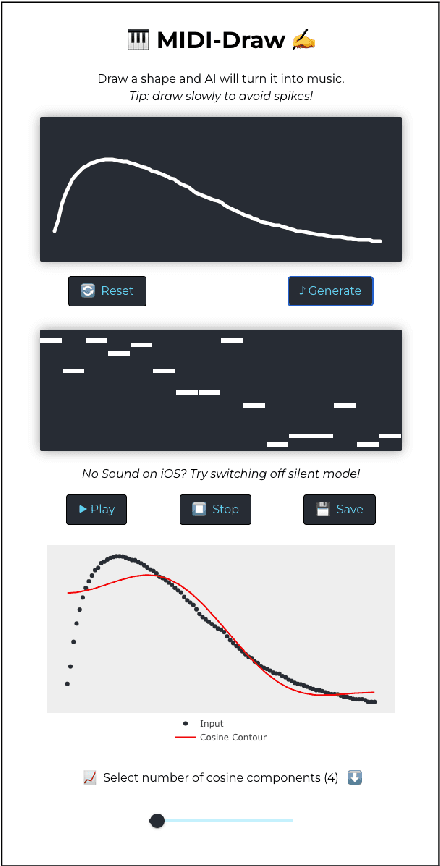
We describe a proof-of-principle implementation of a system for drawing melodies that abstracts away from a note-level input representation via melodic contours. The aim is to allow users to express their musical intentions without requiring prior knowledge of how notes fit together melodiously. Current approaches to controllable melody generation often require users to choose parameters that are static across a whole sequence, via buttons or sliders. In contrast, our method allows users to quickly specify how parameters should change over time by drawing a contour.
SMART: Self-Morphing Anytime Replanning Tree
May 10, 2023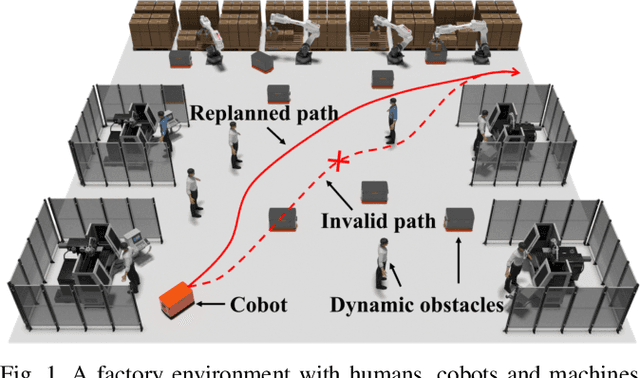
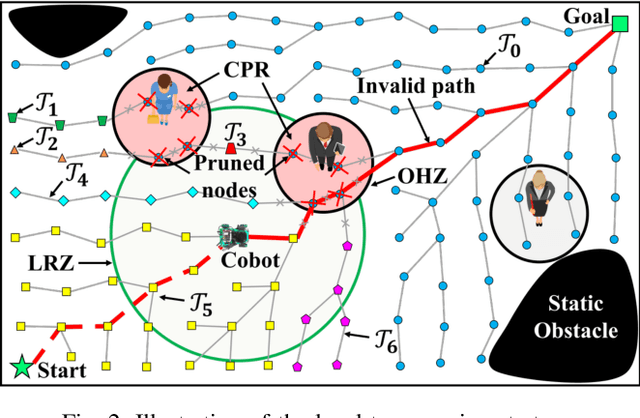
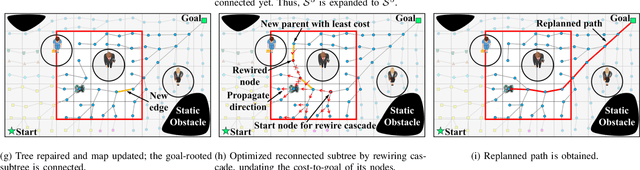
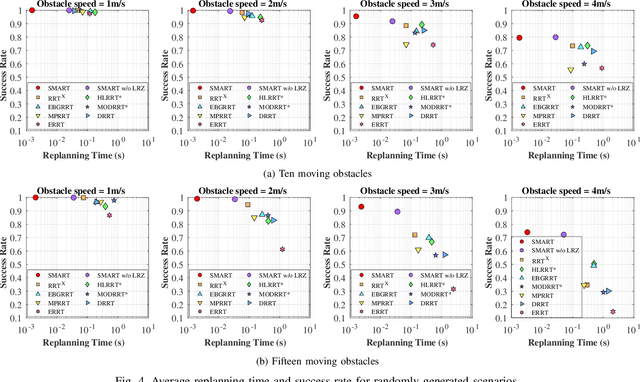
The paper presents an algorithm, called Self- Morphing Anytime Replanning Tree (SMART), that facilitates anytime replanning in dynamic environments. SMART performs risk-based tree-pruning if its current path is obstructed by nearby moving obstacle(s), resulting in multiple disjoint subtrees. Then, for speedy recovery, it exploits these subtrees and performs informed tree-repair at hot-spots that lie at the intersection of subtrees to find a new path. The performance of SMART is comparatively evaluated with seven existing algorithms through extensive simulations. Two scenarios are considered with: 1) dynamic obstacles and 2) both static and dynamic obstacles. The results show that SMART yields significant improvements in replanning time, success rate and travel time. Finally, the performance of SMART is validated by a real laboratory experiment.
Interactive Segment Anything NeRF with Feature Imitation
May 25, 2023
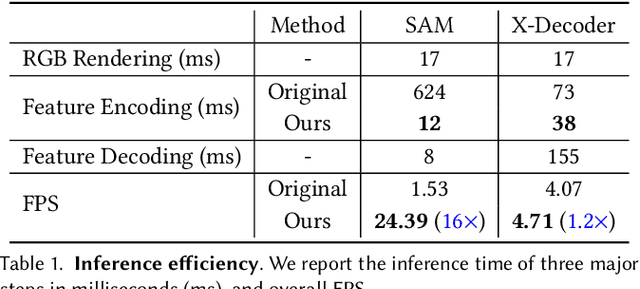
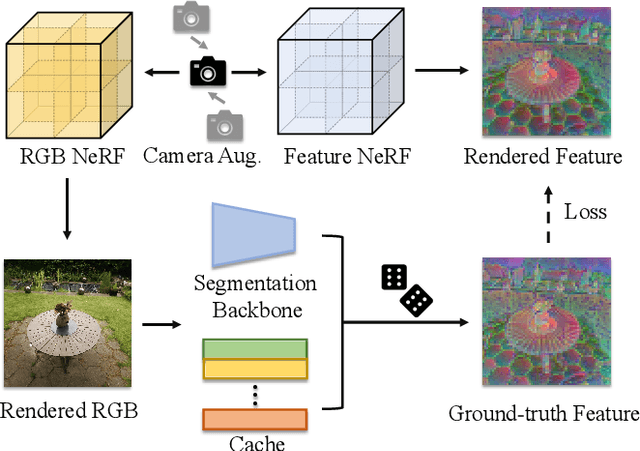
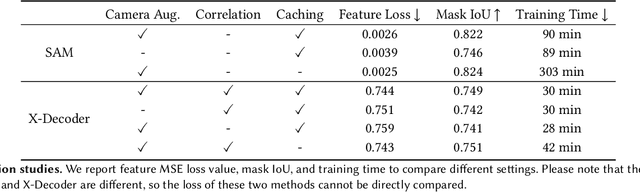
This paper investigates the potential of enhancing Neural Radiance Fields (NeRF) with semantics to expand their applications. Although NeRF has been proven useful in real-world applications like VR and digital creation, the lack of semantics hinders interaction with objects in complex scenes. We propose to imitate the backbone feature of off-the-shelf perception models to achieve zero-shot semantic segmentation with NeRF. Our framework reformulates the segmentation process by directly rendering semantic features and only applying the decoder from perception models. This eliminates the need for expensive backbones and benefits 3D consistency. Furthermore, we can project the learned semantics onto extracted mesh surfaces for real-time interaction. With the state-of-the-art Segment Anything Model (SAM), our framework accelerates segmentation by 16 times with comparable mask quality. The experimental results demonstrate the efficacy and computational advantages of our approach. Project page: \url{https://me.kiui.moe/san/}.