 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Less Can Be More: Unsupervised Graph Pruning for Large-scale Dynamic Graphs
May 18, 2023

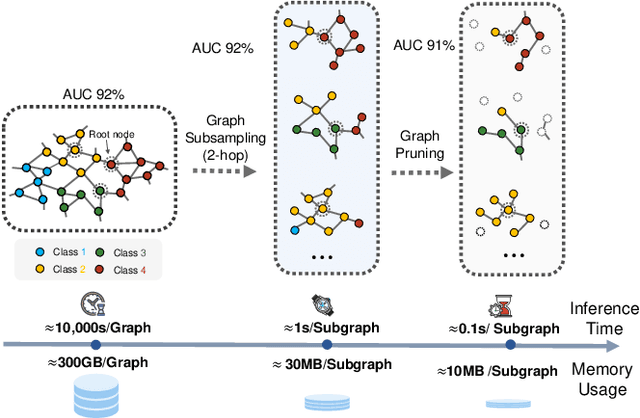
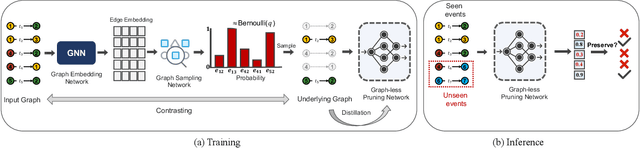
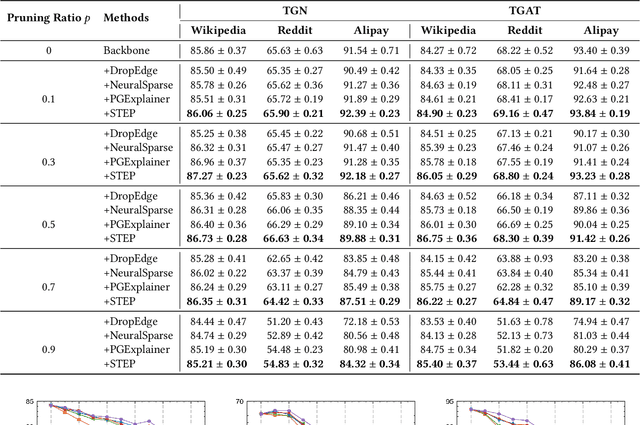
The prevalence of large-scale graphs poses great challenges in time and storage for training and deploying graph neural networks (GNNs). Several recent works have explored solutions for pruning the large original graph into a small and highly-informative one, such that training and inference on the pruned and large graphs have comparable performance. Although empirically effective, current researches focus on static or non-temporal graphs, which are not directly applicable to dynamic scenarios. In addition, they require labels as ground truth to learn the informative structure, limiting their applicability to new problem domains where labels are hard to obtain. To solve the dilemma, we propose and study the problem of unsupervised graph pruning on dynamic graphs. We approach the problem by our proposed STEP, a self-supervised temporal pruning framework that learns to remove potentially redundant edges from input dynamic graphs. From a technical and industrial viewpoint, our method overcomes the trade-offs between the performance and the time & memory overheads. Our results on three real-world datasets demonstrate the advantages on improving the efficacy, robustness, and efficiency of GNNs on dynamic node classification tasks. Most notably, STEP is able to prune more than 50% of edges on a million-scale industrial graph Alipay (7M nodes, 21M edges) while approximating up to 98% of the original performance. Code is available at https://github.com/EdisonLeeeee/STEP.
RMSSinger: Realistic-Music-Score based Singing Voice Synthesis
May 18, 2023
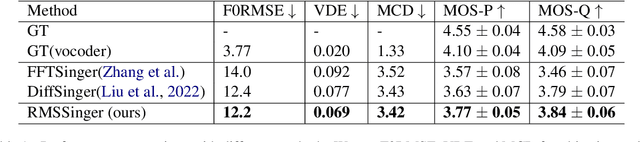
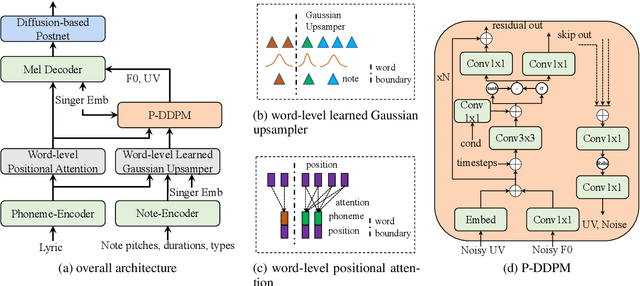
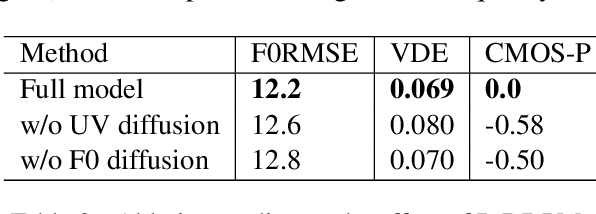
We are interested in a challenging task, Realistic-Music-Score based Singing Voice Synthesis (RMS-SVS). RMS-SVS aims to generate high-quality singing voices given realistic music scores with different note types (grace, slur, rest, etc.). Though significant progress has been achieved, recent singing voice synthesis (SVS) methods are limited to fine-grained music scores, which require a complicated data collection pipeline with time-consuming manual annotation to align music notes with phonemes. Furthermore, these manual annotation destroys the regularity of note durations in music scores, making fine-grained music scores inconvenient for composing. To tackle these challenges, we propose RMSSinger, the first RMS-SVS method, which takes realistic music scores as input, eliminating most of the tedious manual annotation and avoiding the aforementioned inconvenience. Note that music scores are based on words rather than phonemes, in RMSSinger, we introduce word-level modeling to avoid the time-consuming phoneme duration annotation and the complicated phoneme-level mel-note alignment. Furthermore, we propose the first diffusion-based pitch modeling method, which ameliorates the naturalness of existing pitch-modeling methods. To achieve these, we collect a new dataset containing realistic music scores and singing voices according to these realistic music scores from professional singers. Extensive experiments on the dataset demonstrate the effectiveness of our methods. Audio samples are available at https://rmssinger.github.io/.
SMART: Self-Morphing Anytime Replanning Tree
May 10, 2023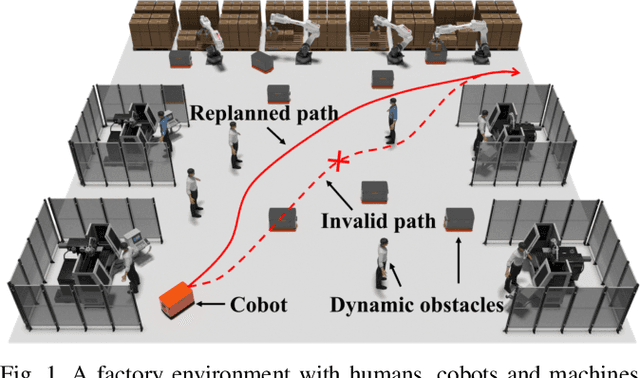
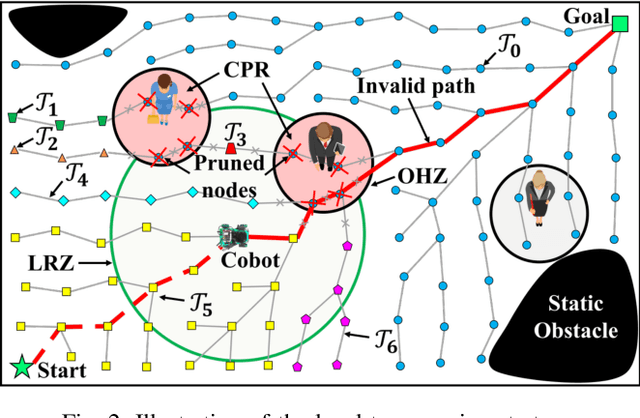
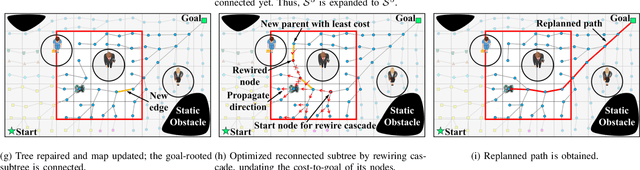
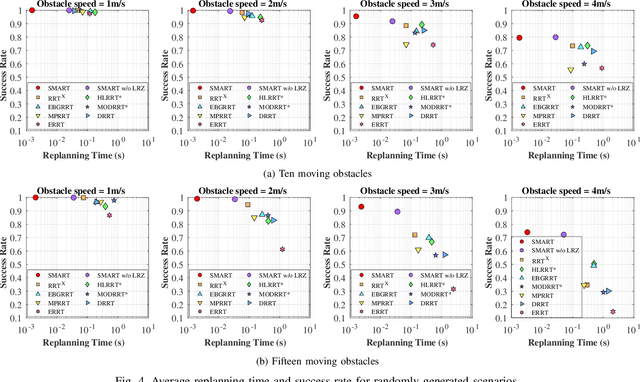
The paper presents an algorithm, called Self- Morphing Anytime Replanning Tree (SMART), that facilitates anytime replanning in dynamic environments. SMART performs risk-based tree-pruning if its current path is obstructed by nearby moving obstacle(s), resulting in multiple disjoint subtrees. Then, for speedy recovery, it exploits these subtrees and performs informed tree-repair at hot-spots that lie at the intersection of subtrees to find a new path. The performance of SMART is comparatively evaluated with seven existing algorithms through extensive simulations. Two scenarios are considered with: 1) dynamic obstacles and 2) both static and dynamic obstacles. The results show that SMART yields significant improvements in replanning time, success rate and travel time. Finally, the performance of SMART is validated by a real laboratory experiment.
FLAIR #2: textural and temporal information for semantic segmentation from multi-source optical imagery
May 23, 2023

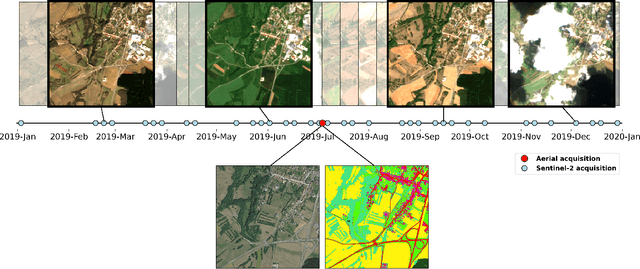

The FLAIR #2 dataset hereby presented includes two very distinct types of data, which are exploited for a semantic segmentation task aimed at mapping land cover. The data fusion workflow proposes the exploitation of the fine spatial and textural information of very high spatial resolution (VHR) mono-temporal aerial imagery and the temporal and spectral richness of high spatial resolution (HR) time series of Copernicus Sentinel-2 satellite images. The French National Institute of Geographical and Forest Information (IGN), in response to the growing availability of high-quality Earth Observation (EO) data, is actively exploring innovative strategies to integrate these data with heterogeneous characteristics. IGN is therefore offering this dataset to promote innovation and improve our knowledge of our territories.
Semantic-aware Transmission Scheduling: a Monotonicity-driven Deep Reinforcement Learning Approach
May 23, 2023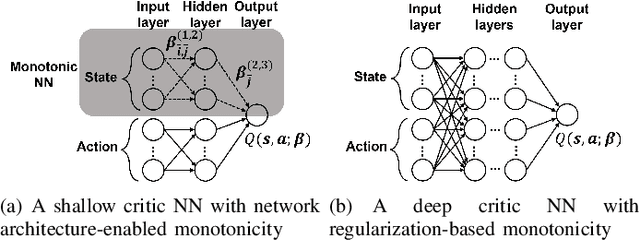
For cyber-physical systems in the 6G era, semantic communications connecting distributed devices for dynamic control and remote state estimation are required to guarantee application-level performance, not merely focus on communication-centric performance. Semantics here is a measure of the usefulness of information transmissions. Semantic-aware transmission scheduling of a large system often involves a large decision-making space, and the optimal policy cannot be obtained by existing algorithms effectively. In this paper, we first investigate the fundamental properties of the optimal semantic-aware scheduling policy and then develop advanced deep reinforcement learning (DRL) algorithms by leveraging the theoretical guidelines. Our numerical results show that the proposed algorithms can substantially reduce training time and enhance training performance compared to benchmark algorithms.
Runtime Analyses of Multi-Objective Evolutionary Algorithms in the Presence of Noise
May 22, 2023In single-objective optimization, it is well known that evolutionary algorithms also without further adjustments can tolerate a certain amount of noise in the evaluation of the objective function. In contrast, this question is not at all understood for multi-objective optimization. In this work, we conduct the first mathematical runtime analysis of a simple multi-objective evolutionary algorithm (MOEA) on a classic benchmark in the presence of noise in the objective functions. We prove that when bit-wise prior noise with rate $p \le \alpha/n$, $\alpha$ a suitable constant, is present, the \emph{simple evolutionary multi-objective optimizer} (SEMO) without any adjustments to cope with noise finds the Pareto front of the OneMinMax benchmark in time $O(n^2\log n)$, just as in the case without noise. Given that the problem here is to arrive at a population consisting of $n+1$ individuals witnessing the Pareto front, this is a surprisingly strong robustness to noise (comparably simple evolutionary algorithms cannot optimize the single-objective OneMax problem in polynomial time when $p = \omega(\log(n)/n)$). Our proofs suggest that the strong robustness of the MOEA stems from its implicit diversity mechanism designed to enable it to compute a population covering the whole Pareto front. Interestingly this result only holds when the objective value of a solution is determined only once and the algorithm from that point on works with this, possibly noisy, objective value. We prove that when all solutions are reevaluated in each iteration, then any noise rate $p = \omega(\log(n)/n^2)$ leads to a super-polynomial runtime. This is very different from single-objective optimization, where it is generally preferred to reevaluate solutions whenever their fitness is important and where examples are known such that not reevaluating solutions can lead to catastrophic performance losses.
Energy-efficient memcapacitive physical reservoir computing system for temporal data processing
May 19, 2023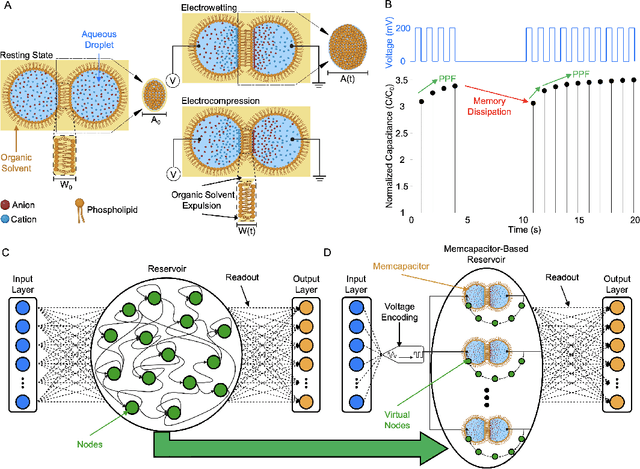

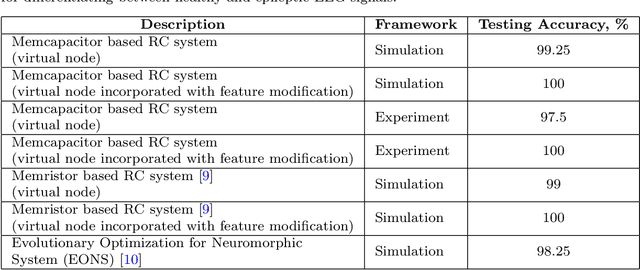
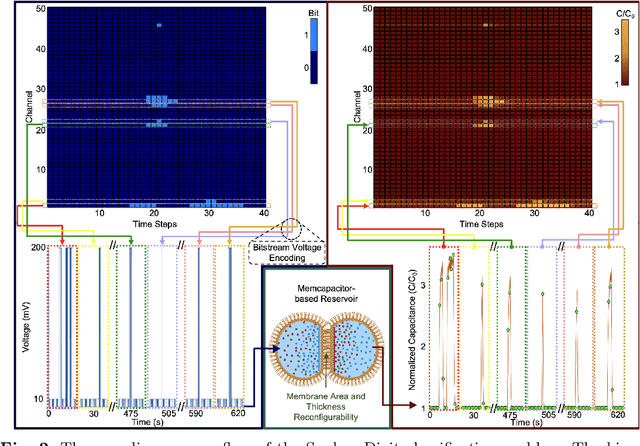
Reservoir computing is a highly efficient machine learning framework for processing temporal data by extracting features from the input signal and mapping them into higher dimensional spaces. Physical reservoir layers have been realized using spintronic oscillators, atomic switch networks, silicon photonic modules, ferroelectric transistors, and volatile memristors. However, these devices are intrinsically energy-dissipative due to their resistive nature, which leads to increased power consumption. Therefore, capacitive memory devices can provide a more energy-efficient approach. Here, we leverage volatile biomembrane-based memcapacitors that closely mimic certain short-term synaptic plasticity functions as reservoirs to solve classification tasks and analyze time-series data in simulation and experimentally. Our system achieves a 98% accuracy rate for spoken digit classification and a normalized mean square error of 0.0012 in a second-order non-linear regression task. Further, to demonstrate the device's real-time temporal data processing capability, we demonstrate a 100% accuracy for an electroencephalography (EEG) signal classification problem for epilepsy detection. Most importantly, we demonstrate that for a random input sequence, each memcapacitor consumes on average 41.5fJ of energy per spike, irrespective of the chosen input voltage pulse width, and 415fW of average power for 100 ms pulse width, orders of magnitude lower than the state-of-the-art devices. Lastly, we believe the biocompatible, soft nature of our memcapacitor makes it highly suitable for computing and signal-processing applications in biological environments.
Computational models of sound-quality metrics using method for calculating loudness with gammatone/gammachirp auditory filterbank
May 19, 2023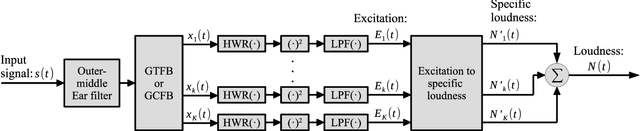
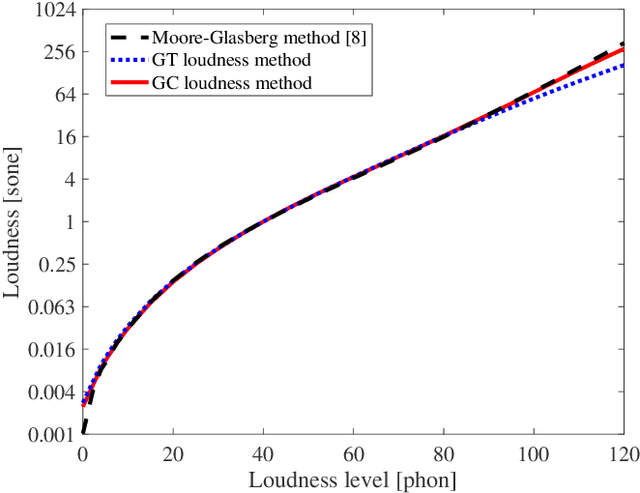


Sound-quality metrics (SQMs), such as sharpness, roughness, and fluctuation strength, are calculated using a standard method for calculating loudness (Zwicker method, ISO532B, 1975). Since ISO 532 had been revised to contain the Zwicker method (ISO 5321) and Moore-Glasberg method (ISO 532-2) in 2017, the classical computational SQM model should also be revised in accordance with these revisions. A roex auditory filterbank used with the Moore-Glasberg method is defined separately in the frequency domain not to have impulse responses. It is therefore difficult to construct a computational SQM model, e.g., the classical computational SQM model, on the basis of ISO 532-2. We propose a method for calculating loudness using the time-domain gammatone or gammachirp auditory filterbank instead of the roex auditory filterbank to solve this problem. We also propose three computational SQM models based on ISO 532-2 to use with the proposed loudness method. We evaluated the root-mean squared errors (RMSEs) of the calculated loudness with the proposed and Moore-Glasberg methods. We then evaluated the RMSEs of the calculated SQMs with the proposed method and human data of SQMs. We found that the proposed method can be considered as a time-domain method for calculating loudness on the basis of ISO 532-2 because the RMSEs are very small. We also found that the proposed computational SQM models can effectively account for the human data of SQMs compared with the classical computational SQM model in terms of RMSEs.
Generate then Select: Open-ended Visual Question Answering Guided by World Knowledge
May 30, 2023

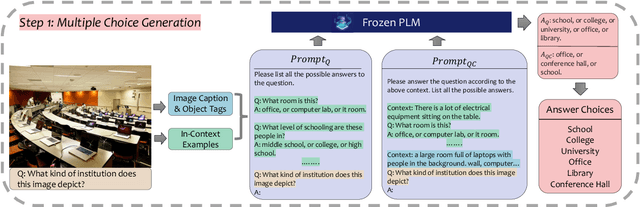
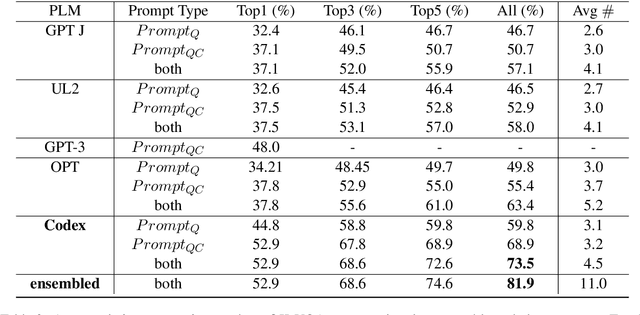
The open-ended Visual Question Answering (VQA) task requires AI models to jointly reason over visual and natural language inputs using world knowledge. Recently, pre-trained Language Models (PLM) such as GPT-3 have been applied to the task and shown to be powerful world knowledge sources. However, these methods suffer from low knowledge coverage caused by PLM bias -- the tendency to generate certain tokens over other tokens regardless of prompt changes, and high dependency on the PLM quality -- only models using GPT-3 can achieve the best result. To address the aforementioned challenges, we propose RASO: a new VQA pipeline that deploys a generate-then-select strategy guided by world knowledge for the first time. Rather than following the de facto standard to train a multi-modal model that directly generates the VQA answer, RASO first adopts PLM to generate all the possible answers, and then trains a lightweight answer selection model for the correct answer. As proved in our analysis, RASO expands the knowledge coverage from in-domain training data by a large margin. We provide extensive experimentation and show the effectiveness of our pipeline by advancing the state-of-the-art by 4.1% on OK-VQA, without additional computation cost. Code and models are released at http://cogcomp.org/page/publication_view/1010
Less Likely Brainstorming: Using Language Models to Generate Alternative Hypotheses
May 30, 2023


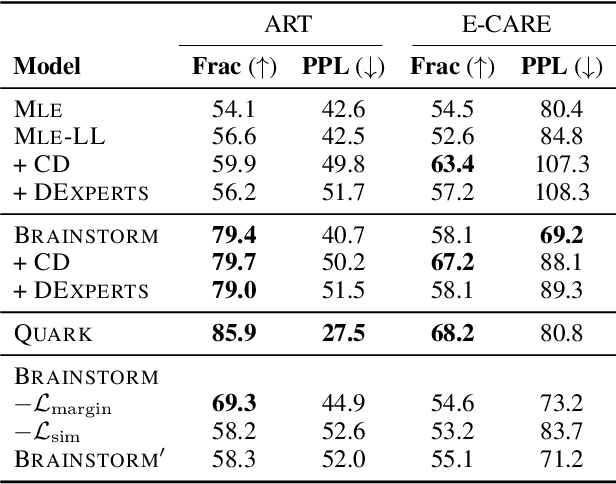
A human decision-maker benefits the most from an AI assistant that corrects for their biases. For problems such as generating interpretation of a radiology report given findings, a system predicting only highly likely outcomes may be less useful, where such outcomes are already obvious to the user. To alleviate biases in human decision-making, it is worth considering a broad differential diagnosis, going beyond the most likely options. We introduce a new task, "less likely brainstorming," that asks a model to generate outputs that humans think are relevant but less likely to happen. We explore the task in two settings: a brain MRI interpretation generation setting and an everyday commonsense reasoning setting. We found that a baseline approach of training with less likely hypotheses as targets generates outputs that humans evaluate as either likely or irrelevant nearly half of the time; standard MLE training is not effective. To tackle this problem, we propose a controlled text generation method that uses a novel contrastive learning strategy to encourage models to differentiate between generating likely and less likely outputs according to humans. We compare our method with several state-of-the-art controlled text generation models via automatic and human evaluations and show that our models' capability of generating less likely outputs is improved.