 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-supervised Quality Evaluation of Colonoscopy Procedures
May 17, 2023
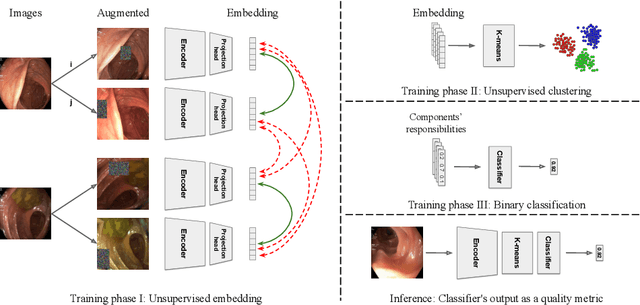
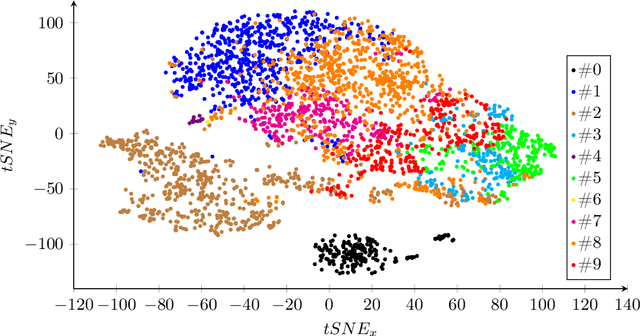
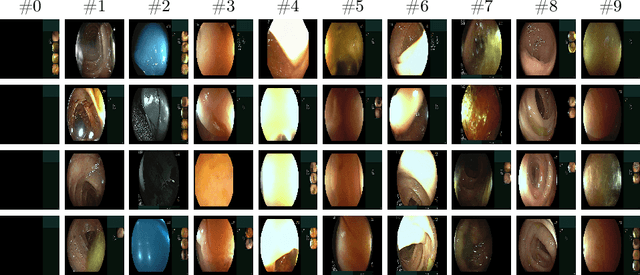
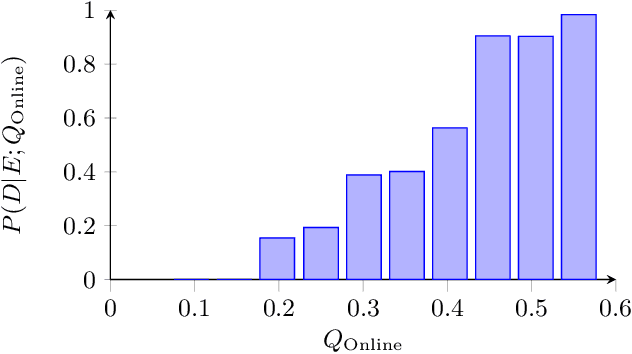
Colonoscopy is the standard of care technique for detecting and removing polyps for the prevention of colorectal cancer. Nevertheless, gastroenterologists (GI) routinely miss approximately 25% of polyps during colonoscopies. These misses are highly operator dependent, influenced by the physician skills, experience, vigilance, and fatigue. Standard quality metrics, such as Withdrawal Time or Cecal Intubation Rate, have been shown to be well correlated with Adenoma Detection Rate (ADR). However, those metrics are limited in their ability to assess the quality of a specific procedure, and they do not address quality aspects related to the style or technique of the examination. In this work we design novel online and offline quality metrics, based on visual appearance quality criteria learned by an ML model in an unsupervised way. Furthermore, we evaluate the likelihood of detecting an existing polyp as a function of quality and use it to demonstrate high correlation of the proposed metric to polyp detection sensitivity. The proposed online quality metric can be used to provide real time quality feedback to the performing GI. By integrating the local metric over the withdrawal phase, we build a global, offline quality metric, which is shown to be highly correlated to the standard Polyp Per Colonoscopy (PPC) quality metric.
Markov $α$-Potential Games: Equilibrium Approximation and Regret Analysis
May 24, 2023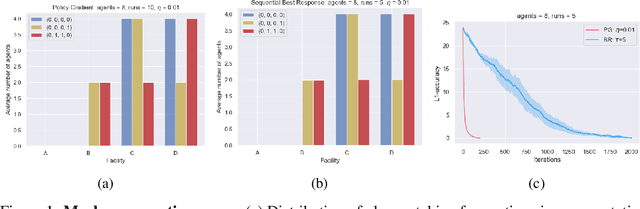
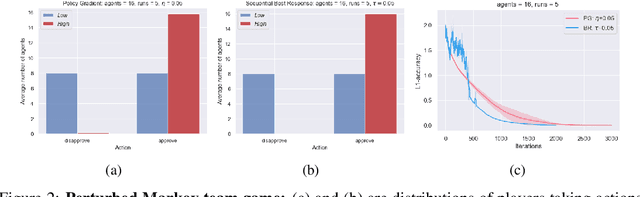
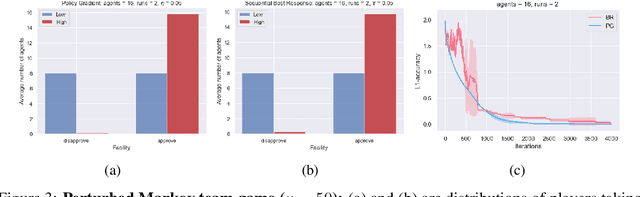
This paper proposes a new framework to study multi-agent interaction in Markov games: Markov $\alpha$-potential games. Markov potential games are special cases of Markov $\alpha$-potential games, so are two important and practically significant classes of games: Markov congestion games and perturbed Markov team games. In this paper, {$\alpha$-potential} functions for both games are provided and the gap $\alpha$ is characterized with respect to game parameters. Two algorithms -- the projected gradient-ascent algorithm and the sequential maximum improvement smoothed best response dynamics -- are introduced for approximating the stationary Nash equilibrium in Markov $\alpha$-potential games. The Nash-regret for each algorithm is shown to scale sub-linearly in time horizon. Our analysis and numerical experiments demonstrates that simple algorithms are capable of finding approximate equilibrium in Markov $\alpha$-potential games.
Promoting Generalization in Cross-Dataset Remote Photoplethysmography
May 24, 2023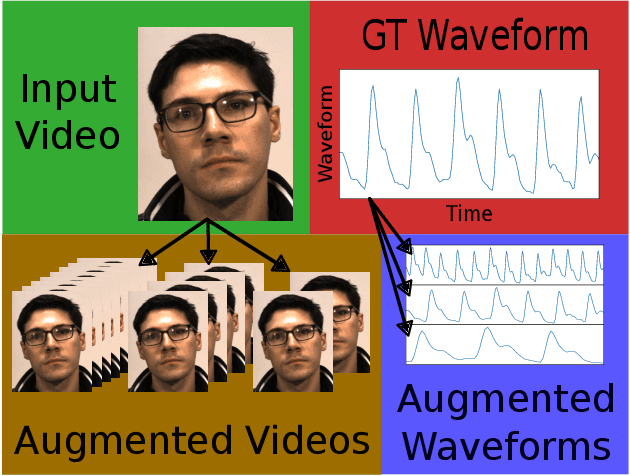
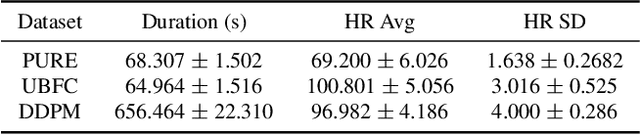
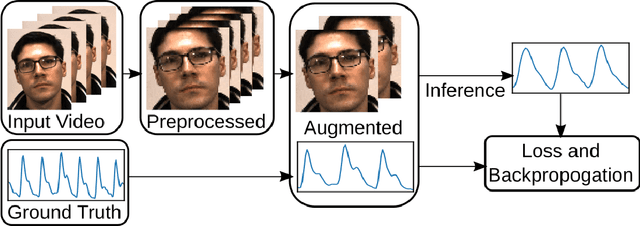
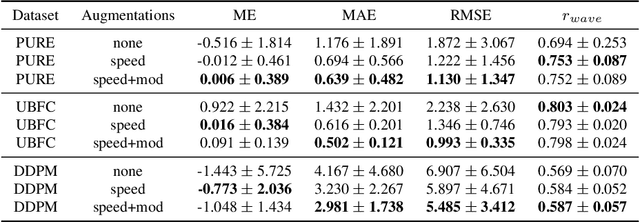
Remote Photoplethysmography (rPPG), or the remote monitoring of a subject's heart rate using a camera, has seen a shift from handcrafted techniques to deep learning models. While current solutions offer substantial performance gains, we show that these models tend to learn a bias to pulse wave features inherent to the training dataset. We develop augmentations to mitigate this learned bias by expanding both the range and variability of heart rates that the model sees while training, resulting in improved model convergence when training and cross-dataset generalization at test time. Through a 3-way cross dataset analysis we demonstrate a reduction in mean absolute error from over 13 beats per minute to below 3 beats per minute. We compare our method with other recent rPPG systems, finding similar performance under a variety of evaluation parameters.
A Deep Generative Model for Interactive Data Annotation through Direct Manipulation in Latent Space
May 24, 2023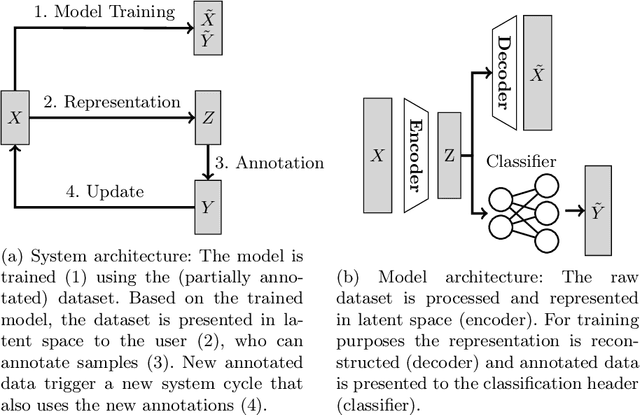
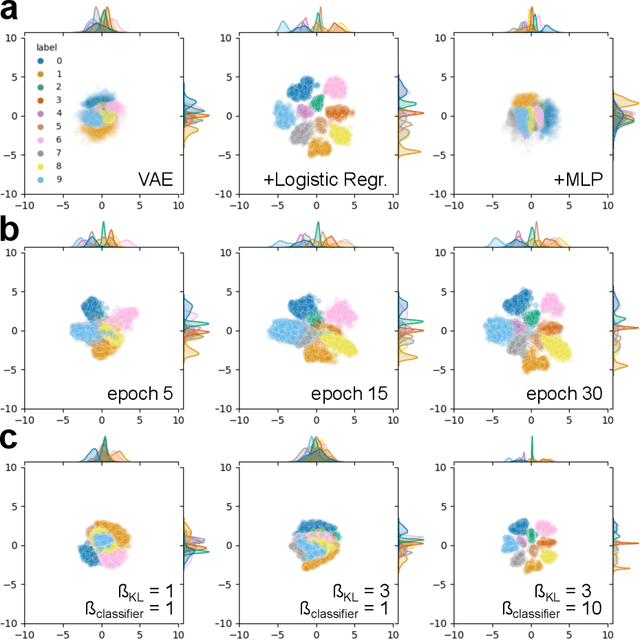
The impact of machine learning (ML) in many fields of application is constrained by lack of annotated data. Among existing tools for ML-assisted data annotation, one little explored tool type relies on an analogy between the coordinates of a graphical user interface and the latent space of a neural network for interaction through direct manipulation. In the present work, we 1) expand the paradigm by proposing two new analogies: time and force as reflecting iterations and gradients of network training; 2) propose a network model for learning a compact graphical representation of the data that takes into account both its internal structure and user provided annotations; and 3) investigate the impact of model hyperparameters on the learned graphical representations of the data, identifying candidate model variants for a future user study.
Focus Your Attention (with Adaptive IIR Filters)
May 24, 2023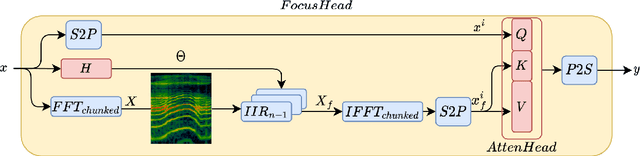
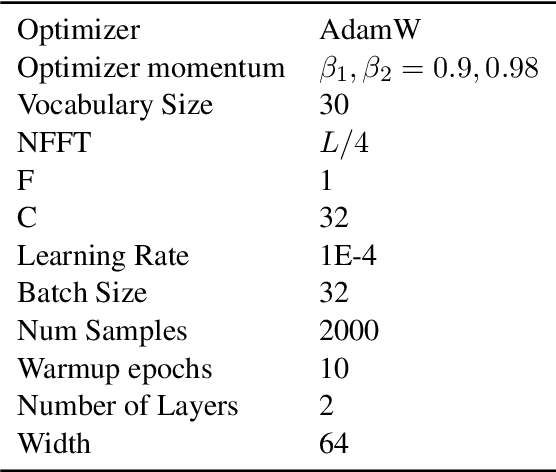
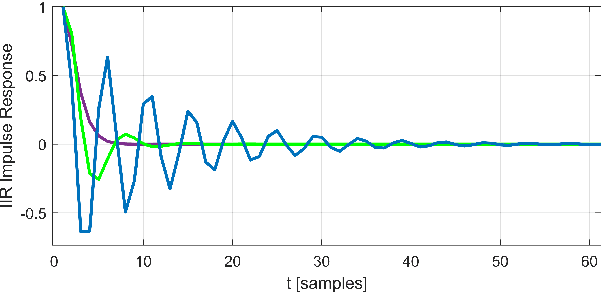
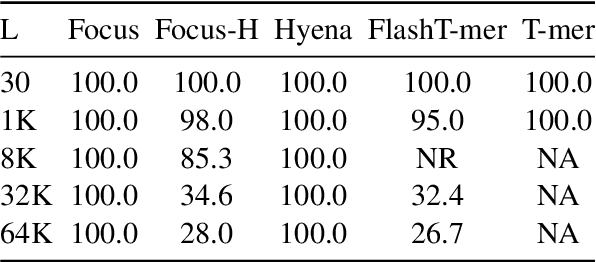
We present a new layer in which dynamic (i.e.,input-dependent) Infinite Impulse Response (IIR) filters of order two are used to process the input sequence prior to applying conventional attention. The input is split into chunks, and the coefficients of these filters are determined based on previous chunks to maintain causality. Despite their relatively low order, the causal adaptive filters are shown to focus attention on the relevant sequence elements. The layer performs on-par with state of the art networks, with a fraction of the parameters and with time complexity that is sub-quadratic with input size. The obtained layer is favorable to layers such as Heyna, GPT2, and Mega, both with respect to the number of parameters and the obtained level of performance on multiple long-range sequence problems.
Unlocking Temporal Question Answering for Large Language Models Using Code Execution
May 24, 2023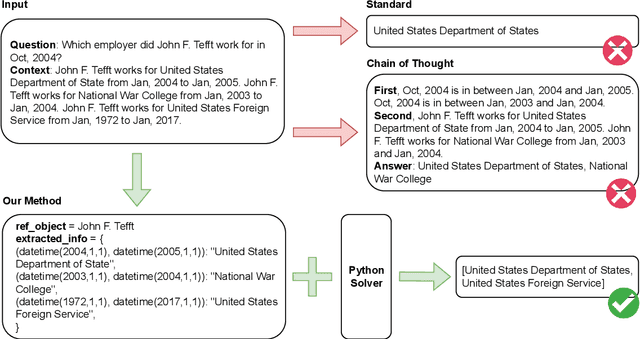


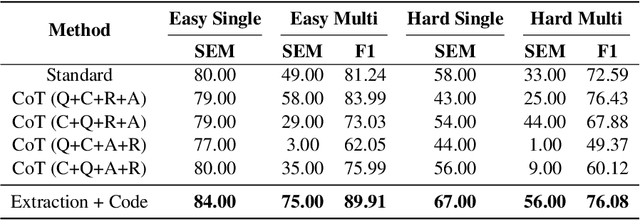
Large language models (LLMs) have made significant progress in natural language processing (NLP), and are utilized extensively in various applications. Recent works, such as chain-of-thought (CoT), have shown that intermediate reasoning steps can improve the performance of LLMs for complex reasoning tasks, such as math problems and symbolic question-answering tasks. However, we notice the challenge that LLMs face when it comes to temporal reasoning. Our preliminary experiments show that generating intermediate reasoning steps does not always boost the performance of complex temporal question-answering tasks. Therefore, we propose a novel framework that combines the extraction capability of LLMs and the logical reasoning capability of a Python solver to tackle this issue. Extensive experiments and analysis demonstrate the effectiveness of our framework in handling intricate time-bound reasoning tasks.
Brainformers: Trading Simplicity for Efficiency
May 29, 2023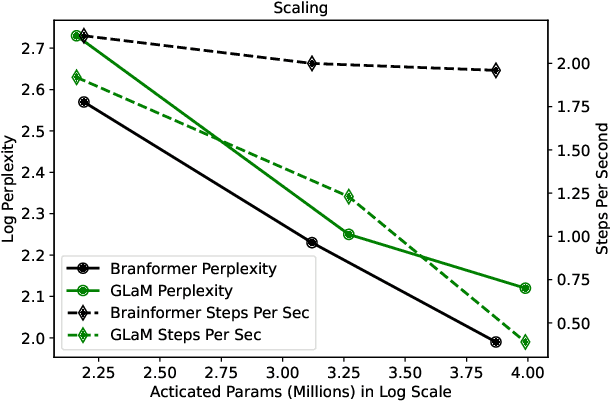

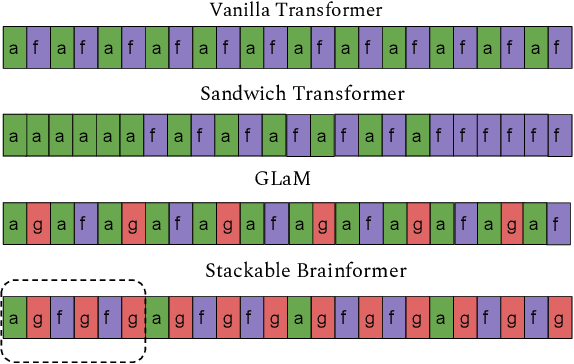
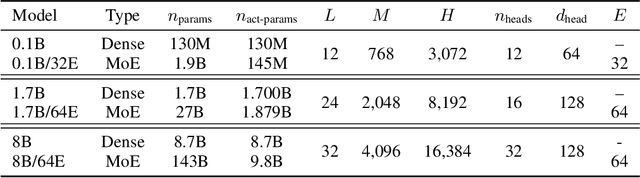
Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
LaFTer: Label-Free Tuning of Zero-shot Classifier using Language and Unlabeled Image Collections
May 29, 2023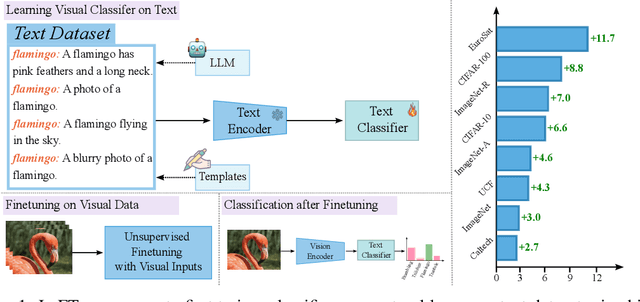
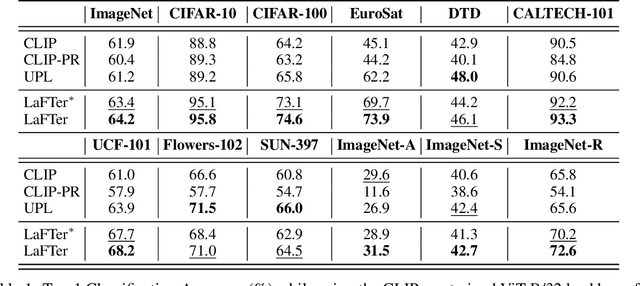
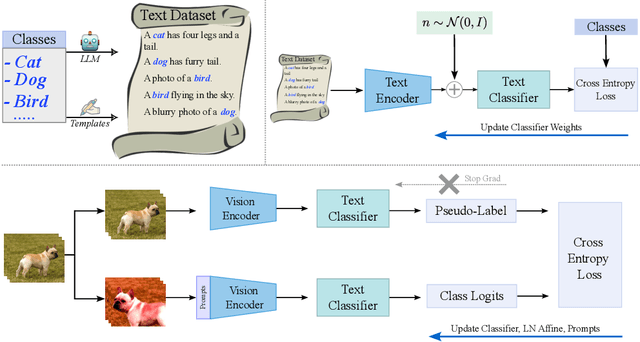
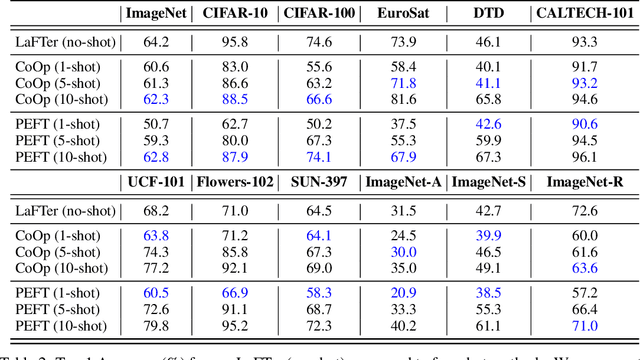
Recently, large-scale pre-trained Vision and Language (VL) models have set a new state-of-the-art (SOTA) in zero-shot visual classification enabling open-vocabulary recognition of potentially unlimited set of categories defined as simple language prompts. However, despite these great advances, the performance of these zeroshot classifiers still falls short of the results of dedicated (closed category set) classifiers trained with supervised fine tuning. In this paper we show, for the first time, how to reduce this gap without any labels and without any paired VL data, using an unlabeled image collection and a set of texts auto-generated using a Large Language Model (LLM) describing the categories of interest and effectively substituting labeled visual instances of those categories. Using our label-free approach, we are able to attain significant performance improvements over the zero-shot performance of the base VL model and other contemporary methods and baselines on a wide variety of datasets, demonstrating absolute improvement of up to 11.7% (3.8% on average) in the label-free setting. Moreover, despite our approach being label-free, we observe 1.3% average gains over leading few-shot prompting baselines that do use 5-shot supervision.
Action valuation of on- and off-ball soccer players based on multi-agent deep reinforcement learning
May 29, 2023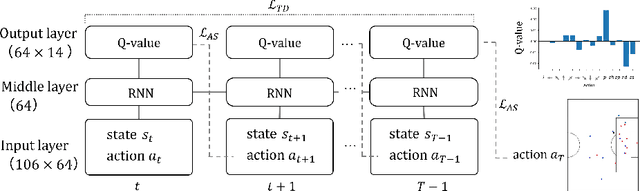
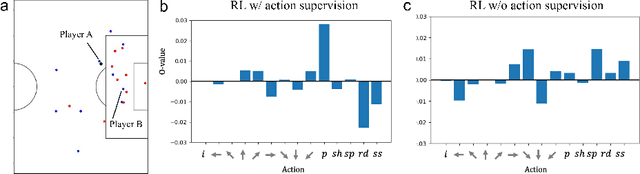
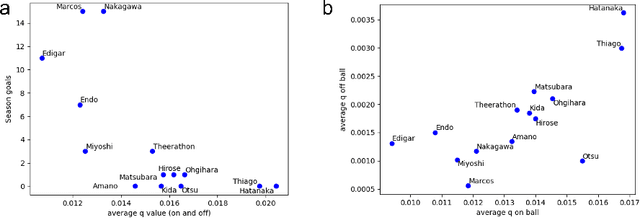
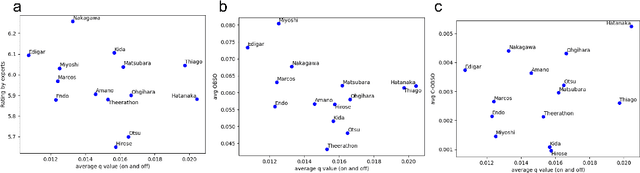
Analysis of invasive sports such as soccer is challenging because the game situation changes continuously in time and space, and multiple agents individually recognize the game situation and make decisions. Previous studies using deep reinforcement learning have often considered teams as a single agent and valued the teams and players who hold the ball in each discrete event. Then it was challenging to value the actions of multiple players, including players far from the ball, in a spatiotemporally continuous state space. In this paper, we propose a method of valuing possible actions for on- and off-ball soccer players in a single holistic framework based on multi-agent deep reinforcement learning. We consider a discrete action space in a continuous state space that mimics that of Google research football and leverages supervised learning for actions in reinforcement learning. In the experiment, we analyzed the relationships with conventional indicators, season goals, and game ratings by experts, and showed the effectiveness of the proposed method. Our approach can assess how multiple players move continuously throughout the game, which is difficult to be discretized or labeled but vital for teamwork, scouting, and fan engagement.
DeepEdit: Deep Editable Learning for Interactive Segmentation of 3D Medical Images
May 18, 2023Automatic segmentation of medical images is a key step for diagnostic and interventional tasks. However, achieving this requires large amounts of annotated volumes, which can be tedious and time-consuming task for expert annotators. In this paper, we introduce DeepEdit, a deep learning-based method for volumetric medical image annotation, that allows automatic and semi-automatic segmentation, and click-based refinement. DeepEdit combines the power of two methods: a non-interactive (i.e. automatic segmentation using nnU-Net, UNET or UNETR) and an interactive segmentation method (i.e. DeepGrow), into a single deep learning model. It allows easy integration of uncertainty-based ranking strategies (i.e. aleatoric and epistemic uncertainty computation) and active learning. We propose and implement a method for training DeepEdit by using standard training combined with user interaction simulation. Once trained, DeepEdit allows clinicians to quickly segment their datasets by using the algorithm in auto segmentation mode or by providing clicks via a user interface (i.e. 3D Slicer, OHIF). We show the value of DeepEdit through evaluation on the PROSTATEx dataset for prostate/prostatic lesions and the Multi-Atlas Labeling Beyond the Cranial Vault (BTCV) dataset for abdominal CT segmentation, using state-of-the-art network architectures as baseline for comparison. DeepEdit could reduce the time and effort annotating 3D medical images compared to DeepGrow alone. Source code is available at https://github.com/Project-MONAI/MONAILabel