 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HDLdebugger: Streamlining HDL debugging with Large Language Models
Mar 18, 2024

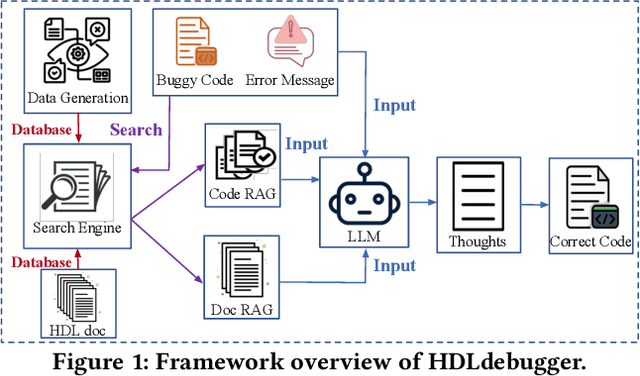

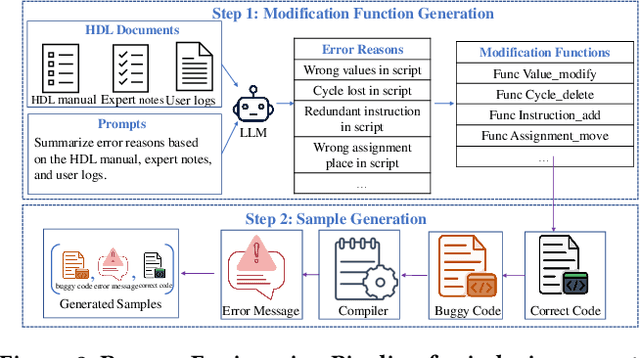
In the domain of chip design, Hardware Description Languages (HDLs) play a pivotal role. However, due to the complex syntax of HDLs and the limited availability of online resources, debugging HDL codes remains a difficult and time-intensive task, even for seasoned engineers. Consequently, there is a pressing need to develop automated HDL code debugging models, which can alleviate the burden on hardware engineers. Despite the strong capabilities of Large Language Models (LLMs) in generating, completing, and debugging software code, their utilization in the specialized field of HDL debugging has been limited and, to date, has not yielded satisfactory results. In this paper, we propose an LLM-assisted HDL debugging framework, namely HDLdebugger, which consists of HDL debugging data generation via a reverse engineering approach, a search engine for retrieval-augmented generation, and a retrieval-augmented LLM fine-tuning approach. Through the integration of these components, HDLdebugger can automate and streamline HDL debugging for chip design. Our comprehensive experiments, conducted on an HDL code dataset sourced from Huawei, reveal that HDLdebugger outperforms 13 cutting-edge LLM baselines, displaying exceptional effectiveness in HDL code debugging.
Learning General Policies for Classical Planning Domains: Getting Beyond C$_2$
Mar 18, 2024
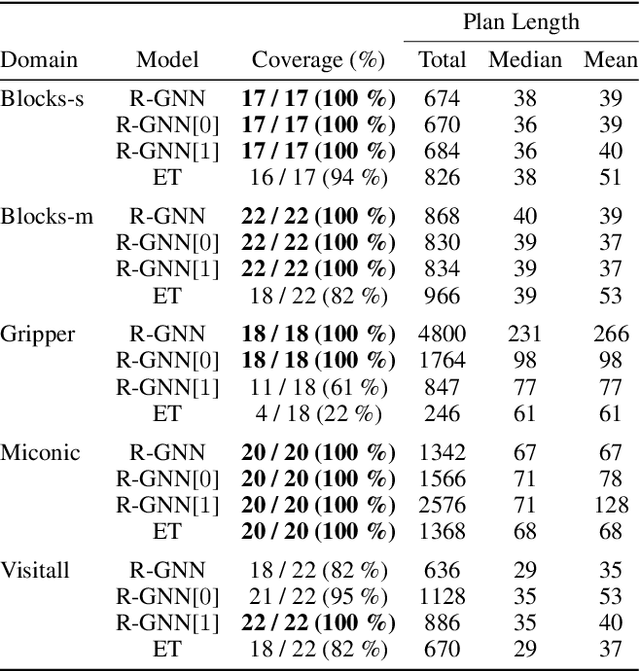
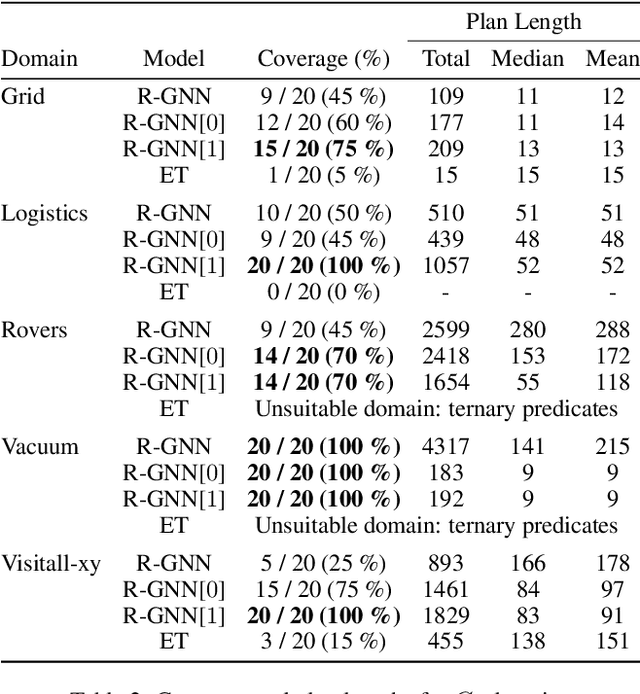
GNN-based approaches for learning general policies across planning domains are limited by the expressive power of $C_2$, namely; first-order logic with two variables and counting. This limitation can be overcomed by transitioning to $k$-GNNs, for $k=3$, wherein object embeddings are substituted with triplet embeddings. Yet, while $3$-GNNs have the expressive power of $C_3$, unlike $1$- and $2$-GNNs that are confined to $C_2$, they require quartic time for message exchange and cubic space for embeddings, rendering them impractical. In this work, we introduce a parameterized version of relational GNNs. When $t$ is infinity, R-GNN[$t$] approximates $3$-GNNs using only quadratic space for embeddings. For lower values of $t$, such as $t=1$ and $t=2$, R-GNN[$t$] achieves a weaker approximation by exchanging fewer messages, yet interestingly, often yield the $C_3$ features required in several planning domains. Furthermore, the new R-GNN[$t$] architecture is the original R-GNN architecture with a suitable transformation applied to the input states only. Experimental results illustrate the clear performance gains of R-GNN[$1$] and R-GNN[$2$] over plain R-GNNs, and also over edge transformers that also approximate $3$-GNNs.
MKF-ADS: Multi-Knowledge Fusion Based Self-supervised Anomaly Detection System for Control Area Network
Mar 15, 2024
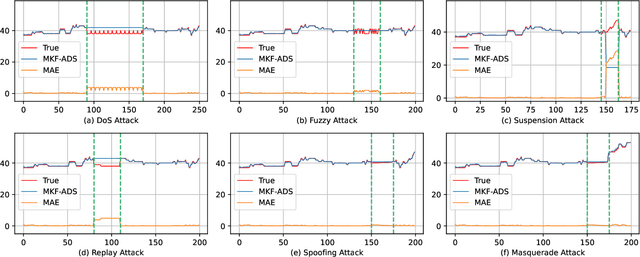
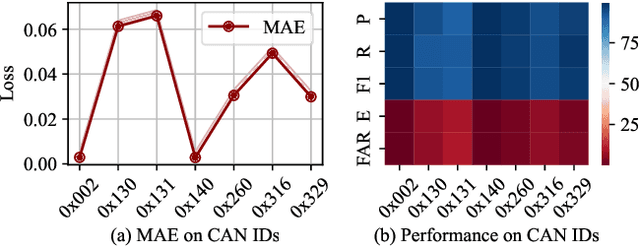
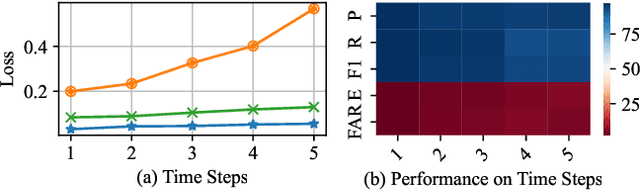
Control Area Network (CAN) is an essential communication protocol that interacts between Electronic Control Units (ECUs) in the vehicular network. However, CAN is facing stringent security challenges due to innate security risks. Intrusion detection systems (IDSs) are a crucial safety component in remediating Vehicular Electronics and Systems vulnerabilities. However, existing IDSs fail to identify complexity attacks and have higher false alarms owing to capability bottleneck. In this paper, we propose a self-supervised multi-knowledge fused anomaly detection model, called MKF-ADS. Specifically, the method designs an integration framework, including spatial-temporal correlation with an attention mechanism (STcAM) module and patch sparse-transformer module (PatchST). The STcAM with fine-pruning uses one-dimensional convolution (Conv1D) to extract spatial features and subsequently utilizes the Bidirectional Long Short Term Memory (Bi-LSTM) to extract the temporal features, where the attention mechanism will focus on the important time steps. Meanwhile, the PatchST captures the combined contextual features from independent univariate time series. Finally, the proposed method is based on knowledge distillation to STcAM as a student model for learning intrinsic knowledge and cross the ability to mimic PatchST. We conduct extensive experiments on six simulation attack scenarios across various CAN IDs and time steps, and two real attack scenarios, which present a competitive prediction and detection performance. Compared with the baseline in the same paradigm, the error rate and FAR are 2.62\% and 2.41\% and achieve a promising F1-score of 97.3\%.
FL-GUARD: A Holistic Framework for Run-Time Detection and Recovery of Negative Federated Learning
Mar 07, 2024Federated learning (FL) is a promising approach for learning a model from data distributed on massive clients without exposing data privacy. It works effectively in the ideal federation where clients share homogeneous data distribution and learning behavior. However, FL may fail to function appropriately when the federation is not ideal, amid an unhealthy state called Negative Federated Learning (NFL), in which most clients gain no benefit from participating in FL. Many studies have tried to address NFL. However, their solutions either (1) predetermine to prevent NFL in the entire learning life-cycle or (2) tackle NFL in the aftermath of numerous learning rounds. Thus, they either (1) indiscriminately incur extra costs even if FL can perform well without such costs or (2) waste numerous learning rounds. Additionally, none of the previous work takes into account the clients who may be unwilling/unable to follow the proposed NFL solutions when using those solutions to upgrade an FL system in use. This paper introduces FL-GUARD, a holistic framework that can be employed on any FL system for tackling NFL in a run-time paradigm. That is, to dynamically detect NFL at the early stage (tens of rounds) of learning and then to activate recovery measures when necessary. Specifically, we devise a cost-effective NFL detection mechanism, which relies on an estimation of performance gain on clients. Only when NFL is detected, we activate the NFL recovery process, in which each client learns in parallel an adapted model when training the global model. Extensive experiment results confirm the effectiveness of FL-GUARD in detecting NFL and recovering from NFL to a healthy learning state. We also show that FL-GUARD is compatible with previous NFL solutions and robust against clients unwilling/unable to take any recovery measures.
Enhancing LLM Factual Accuracy with RAG to Counter Hallucinations: A Case Study on Domain-Specific Queries in Private Knowledge-Bases
Mar 15, 2024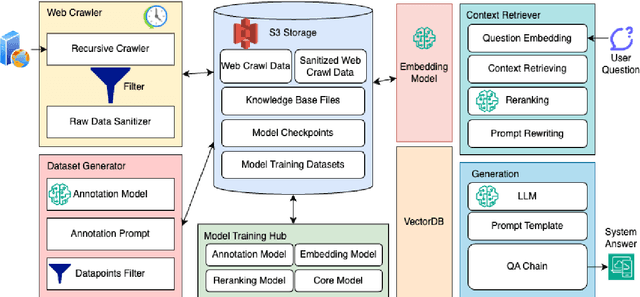
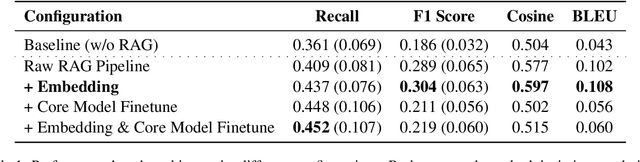
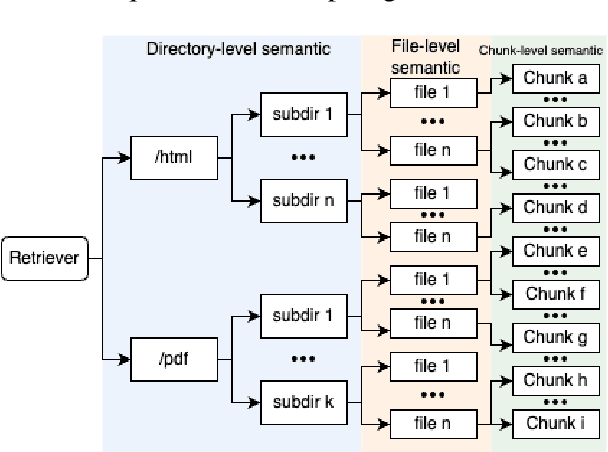
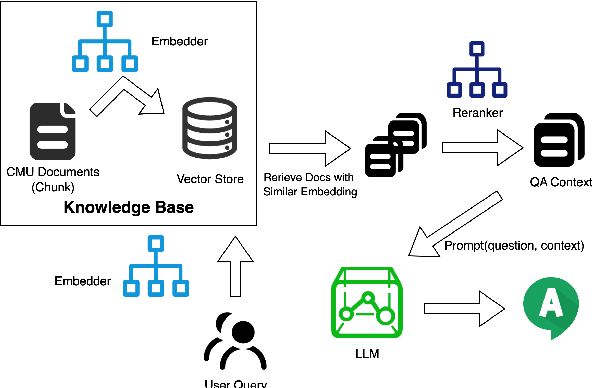
We proposed an end-to-end system design towards utilizing Retrieval Augmented Generation (RAG) to improve the factual accuracy of Large Language Models (LLMs) for domain-specific and time-sensitive queries related to private knowledge-bases. Our system integrates RAG pipeline with upstream datasets processing and downstream performance evaluation. Addressing the challenge of LLM hallucinations, we finetune models with a curated dataset which originates from CMU's extensive resources and annotated with the teacher model. Our experiments demonstrate the system's effectiveness in generating more accurate answers to domain-specific and time-sensitive inquiries. The results also revealed the limitations of fine-tuning LLMs with small-scale and skewed datasets. This research highlights the potential of RAG systems in augmenting LLMs with external datasets for improved performance in knowledge-intensive tasks. Our code and models are available on Github.
Concept-Best-Matching: Evaluating Compositionality in Emergent Communication
Mar 17, 2024Artificial agents that learn to communicate in order to accomplish a given task acquire communication protocols that are typically opaque to a human. A large body of work has attempted to evaluate the emergent communication via various evaluation measures, with \emph{compositionality} featuring as a prominent desired trait. However, current evaluation procedures do not directly expose the compositionality of the emergent communication. We propose a procedure to assess the compositionality of emergent communication by finding the best-match between emerged words and natural language concepts. The best-match algorithm provides both a global score and a translation-map from emergent words to natural language concepts. To the best of our knowledge, it is the first time that such direct and interpretable mapping between emergent words and human concepts is provided.
Toward Adaptive Cooperation: Model-Based Shared Control Using LQ-Differential Games
Mar 17, 2024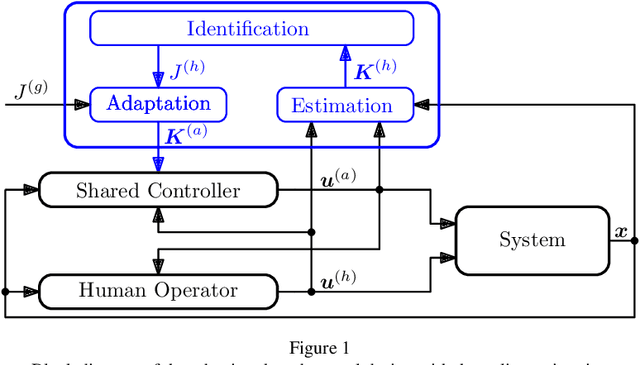
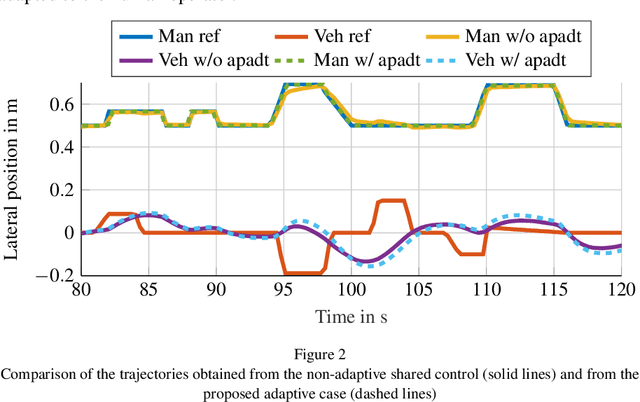
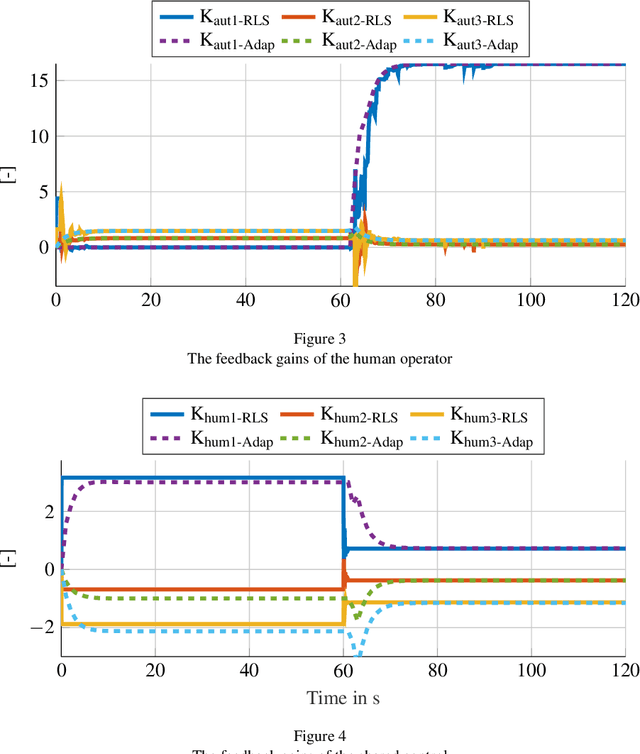
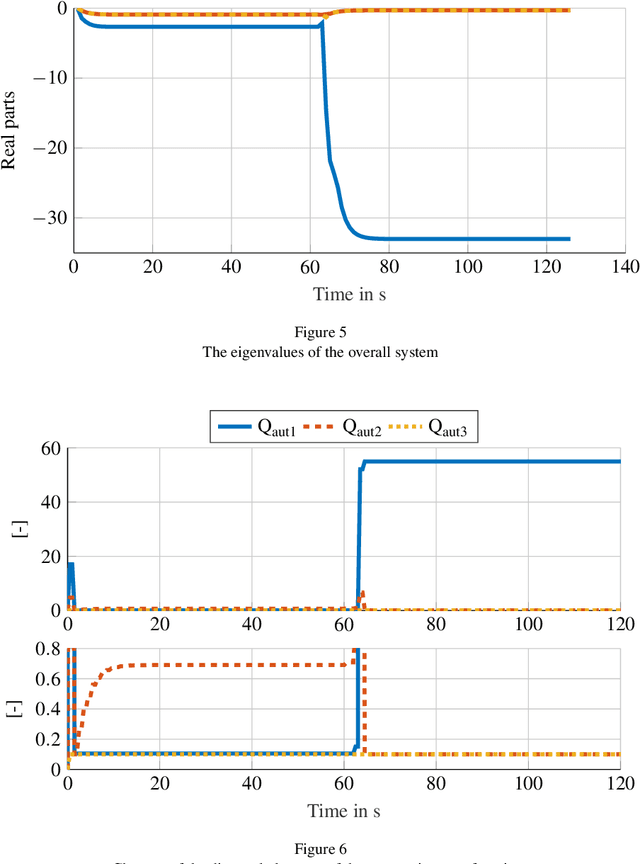
This paper introduces a novel model-based adaptive shared control to allow for the identification and design challenge for shared-control systems, in which humans and automation share control tasks. The main challenge is the adaptive behavior of the human in such shared control interactions. Consequently, merely identifying human behavior without considering automation is insufficient and often leads to inadequate automation design. Therefore, this paper proposes a novel solution involving online identification of the human and the adaptation of shared control using Linear-Quadratic differential games. The effectiveness of the proposed online adaptation is analyzed in simulations and compared with a non-adaptive shared control from the state of the art. Finally, the proposed approach is tested through human-in-the-loop experiments, highlighting its suitability for real-time applications.
Incentivized Exploration of Non-Stationary Stochastic Bandits
Mar 16, 2024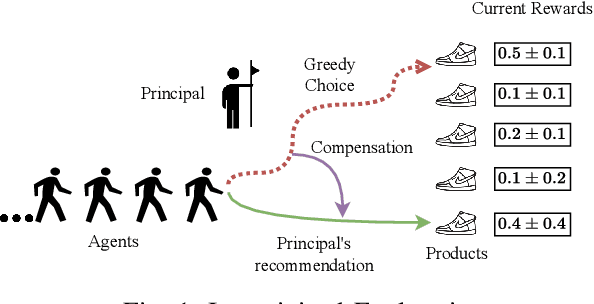
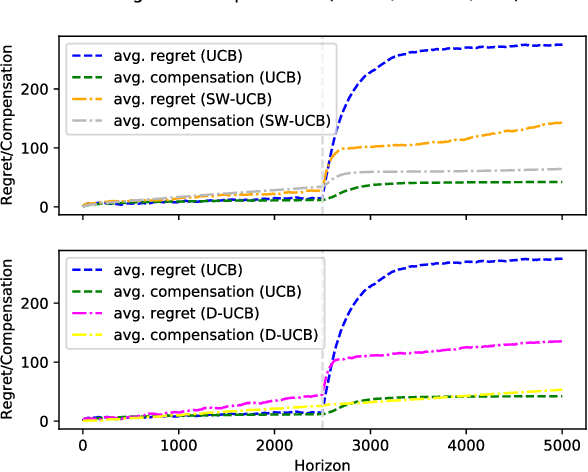
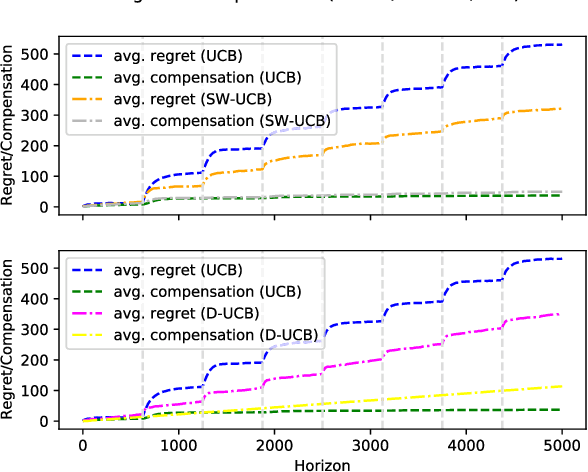
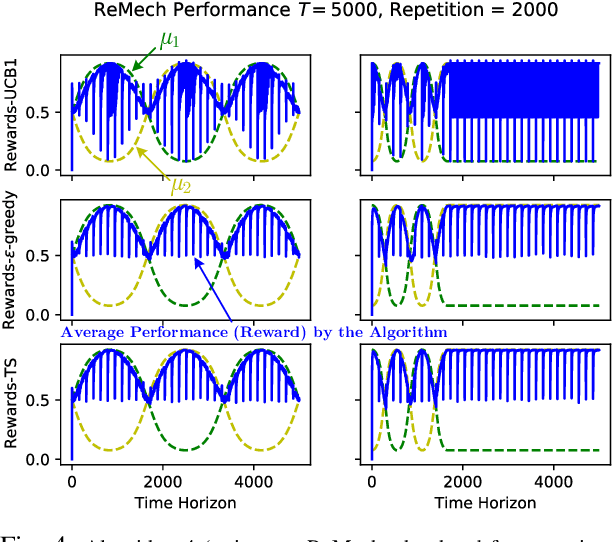
We study incentivized exploration for the multi-armed bandit (MAB) problem with non-stationary reward distributions, where players receive compensation for exploring arms other than the greedy choice and may provide biased feedback on the reward. We consider two different non-stationary environments: abruptly-changing and continuously-changing, and propose respective incentivized exploration algorithms. We show that the proposed algorithms achieve sublinear regret and compensation over time, thus effectively incentivizing exploration despite the nonstationarity and the biased or drifted feedback.
How to train your ears: Auditory-model emulation for large-dynamic-range inputs and mild-to-severe hearing losses
Mar 15, 2024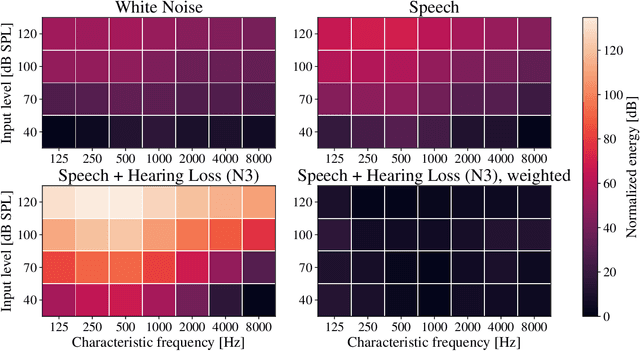
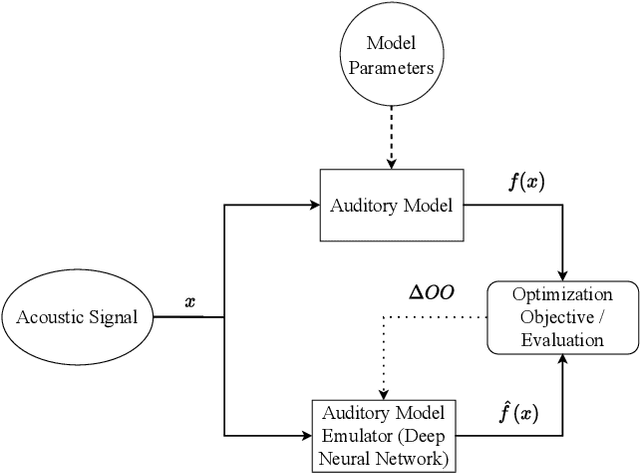
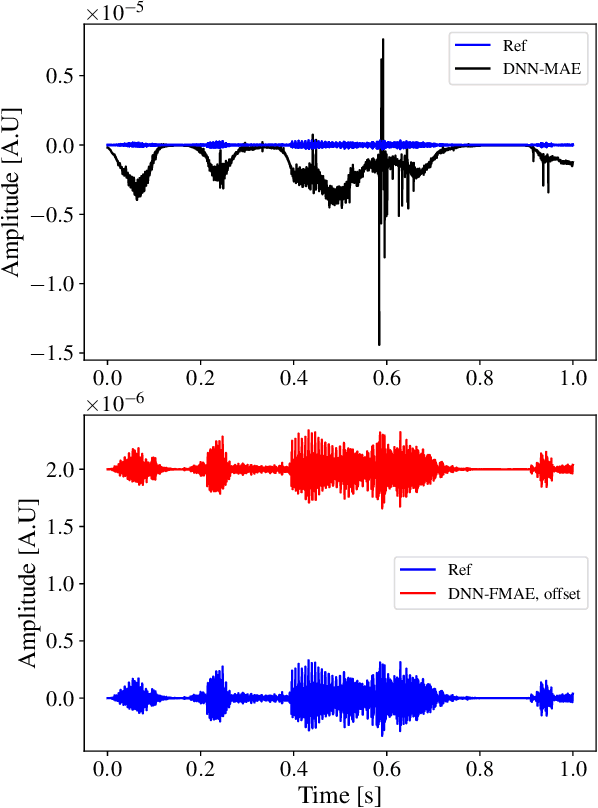
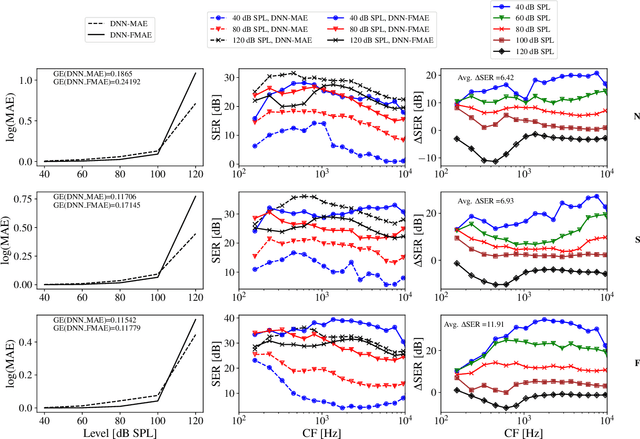
Advanced auditory models are useful in designing signal-processing algorithms for hearing-loss compensation or speech enhancement. Such auditory models provide rich and detailed descriptions of the auditory pathway, and might allow for individualization of signal-processing strategies, based on physiological measurements. However, these auditory models are often computationally demanding, requiring significant time to compute. To address this issue, previous studies have explored the use of deep neural networks to emulate auditory models and reduce inference time. While these deep neural networks offer impressive efficiency gains in terms of computational time, they may suffer from uneven emulation performance as a function of auditory-model frequency-channels and input sound pressure level, making them unsuitable for many tasks. In this study, we demonstrate that the conventional machine-learning optimization objective used in existing state-of-the-art methods is the primary source of this limitation. Specifically, the optimization objective fails to account for the frequency- and level-dependencies of the auditory model, caused by a large input dynamic range and different types of hearing losses emulated by the auditory model. To overcome this limitation, we propose a new optimization objective that explicitly embeds the frequency- and level-dependencies of the auditory model. Our results show that this new optimization objective significantly improves the emulation performance of deep neural networks across relevant input sound levels and auditory-model frequency channels, without increasing the computational load during inference. Addressing these limitations is essential for advancing the application of auditory models in signal-processing tasks, ensuring their efficacy in diverse scenarios.
Primal-Dual iLQR
Mar 13, 2024We introduce a new algorithm for solving unconstrained discrete-time optimal control problems. Our method follows a direct multiple shooting approach, and consists of applying the SQP method together with an $\ell_2$ augmented Lagrangian primal-dual merit function. We use the LQR algorithm to efficiently solve the primal component of the Newton-KKT system, and use a dual LQR backward pass to solve its dual component. We also present a new parallel algorithm for solving the dual component of the Newton-KKT system in $O(\log(N))$ parallel time, where $N$ is the number of stages. Combining it with (S\"{a}rkk\"{a} and Garc\'{i}a-Fern\'{a}ndez, 2023), we are able to solve the full Newton-KKT system in $O(\log(N))$ parallel time. The remaining parts of our method have constant parallel time complexity per iteration. Therefore, this paper provides, for the first time, a practical, highly parallelizable (for example, with a GPU) method for solving nonlinear discrete-time optimal control problems. As our algorithm is a specialization of NPSQP (Gill et al. 1992), it inherits its generic properties, including global convergence, fast local convergence, and the lack of need for second order corrections or dimension expansions, improving on existing direct multiple shooting approaches such as acados (Verschueren et al. 2022), ALTRO (Howell et al. 2019), GNMS (Giftthaler et al. 2018), FATROP (Vanroye et al. 2023), and FDDP (Mastalli et al. 2020).