 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Web Can Be Your Oyster for Improving Large Language Models
May 24, 2023
Large language models (LLMs) encode a large amount of world knowledge. However, as such knowledge is frozen at the time of model training, the models become static and limited by the training data at that time. In order to further improve the capacity of LLMs for knowledge-intensive tasks, we consider augmenting LLMs with the large-scale web using search engine. Unlike previous augmentation sources (e.g., Wikipedia data dump), the web provides broader, more comprehensive and constantly updated information. In this paper, we present a web-augmented LLM UNIWEB, which is trained over 16 knowledge-intensive tasks in a unified text-to-text format. Instead of simply using the retrieved contents from web, our approach has made two major improvements. Firstly, we propose an adaptive search engine assisted learning method that can self-evaluate the confidence level of LLM's predictions, and adaptively determine when to refer to the web for more data, which can avoid useless or noisy augmentation from web. Secondly, we design a pretraining task, i.e., continual knowledge learning, based on salient spans prediction, to reduce the discrepancy between the encoded and retrieved knowledge. Experiments on a wide range of knowledge-intensive tasks show that our model significantly outperforms previous retrieval-augmented methods.
Noise-cleaning the precision matrix of fMRI time series
Feb 06, 2023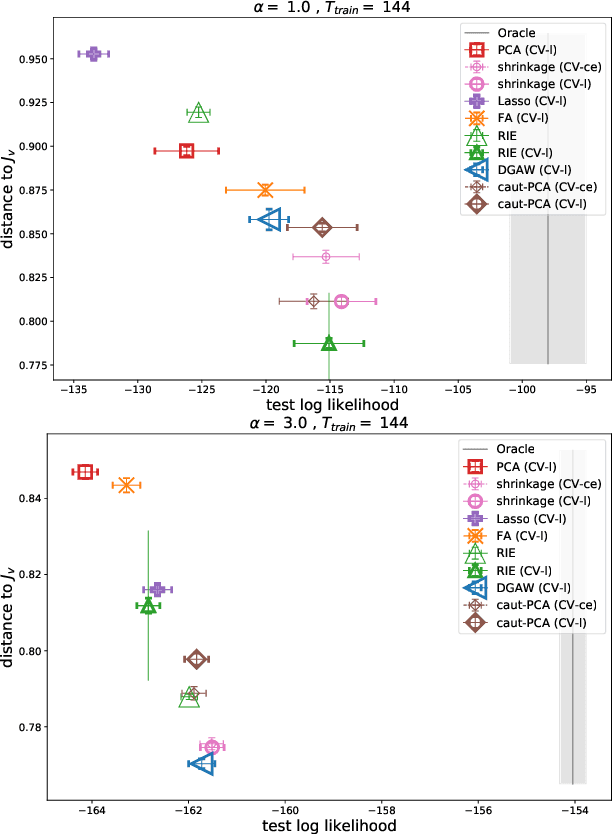
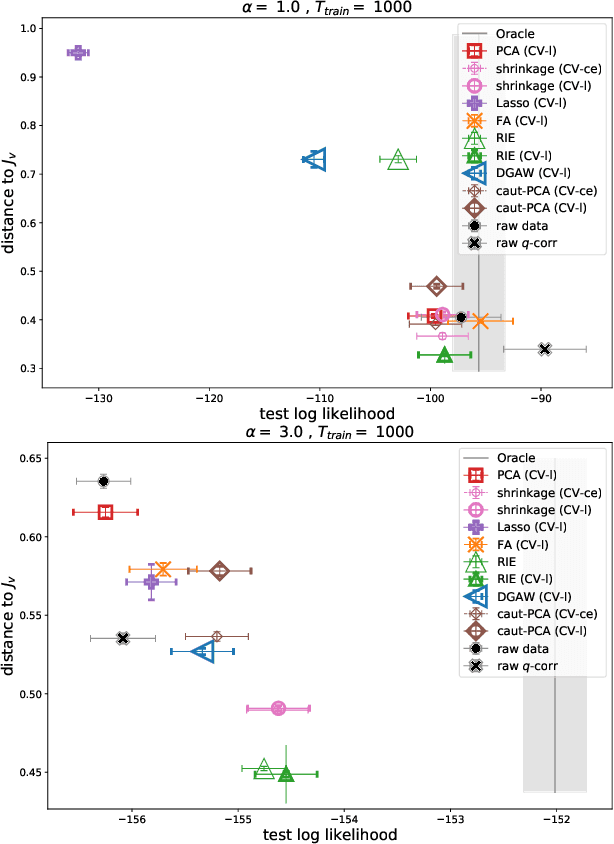
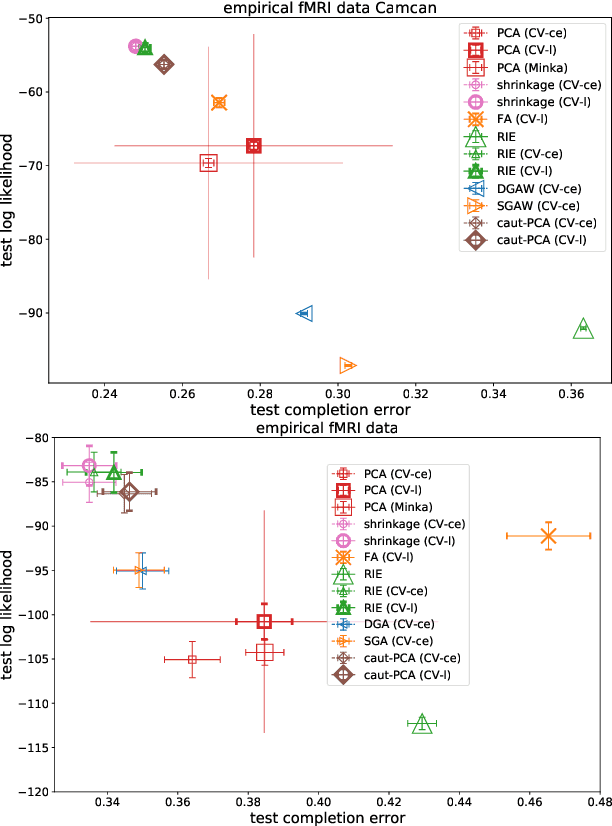
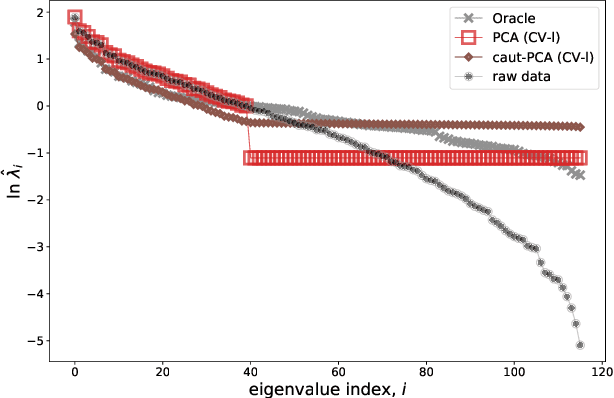
We present a comparison between various algorithms of inference of covariance and precision matrices in small datasets of real vectors, of the typical length and dimension of human brain activity time series retrieved by functional Magnetic Resonance Imaging (fMRI). Assuming a Gaussian model underlying the neural activity, the problem consists in denoising the empirically observed matrices in order to obtain a better estimator of the true precision and covariance matrices. We consider several standard noise-cleaning algorithms and compare them on two types of datasets. The first type are time series of fMRI brain activity of human subjects at rest. The second type are synthetic time series sampled from a generative Gaussian model of which we can vary the fraction of dimensions per sample q = N/T and the strength of off-diagonal correlations. The reliability of each algorithm is assessed in terms of test-set likelihood and, in the case of synthetic data, of the distance from the true precision matrix. We observe that the so called Optimal Rotationally Invariant Estimator, based on Random Matrix Theory, leads to a significantly lower distance from the true precision matrix in synthetic data, and higher test likelihood in natural fMRI data. We propose a variant of the Optimal Rotationally Invariant Estimator in which one of its parameters is optimised by cross-validation. In the severe undersampling regime (large q) typical of fMRI series, it outperforms all the other estimators. We furthermore propose a simple algorithm based on an iterative likelihood gradient ascent, providing an accurate estimation for weakly correlated datasets.
Neural Continuous-Discrete State Space Models for Irregularly-Sampled Time Series
Jan 31, 2023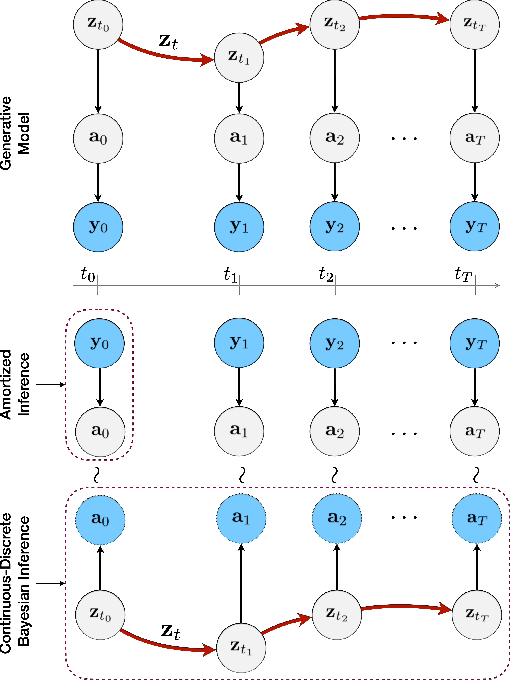

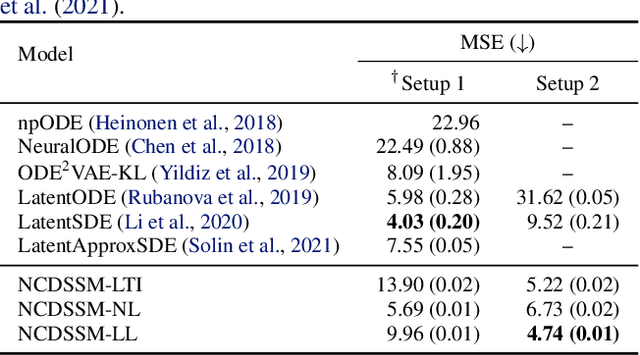

Learning accurate predictive models of real-world dynamic phenomena (e.g., climate, biological) remains a challenging task. One key issue is that the data generated by both natural and artificial processes often comprise time series that are irregularly sampled and/or contain missing observations. In this work, we propose the Neural Continuous-Discrete State Space Model (NCDSSM) for continuous-time modeling of time series through discrete-time observations. NCDSSM employs auxiliary variables to disentangle recognition from dynamics, thus requiring amortized inference only for the auxiliary variables. Leveraging techniques from continuous-discrete filtering theory, we demonstrate how to perform accurate Bayesian inference for the dynamic states. We propose three flexible parameterizations of the latent dynamics and an efficient training objective that marginalizes the dynamic states during inference. Empirical results on multiple benchmark datasets across various domains show improved imputation and forecasting performance of NCDSSM over existing models.
Multilingual Clinical NER: Translation or Cross-lingual Transfer?
Jun 07, 2023
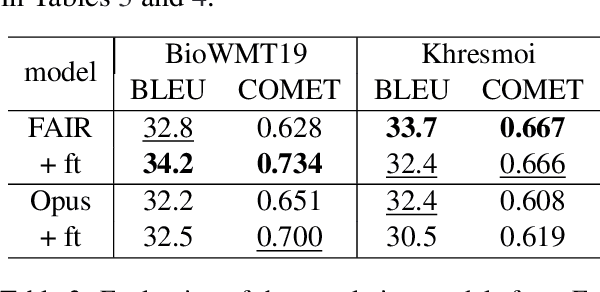
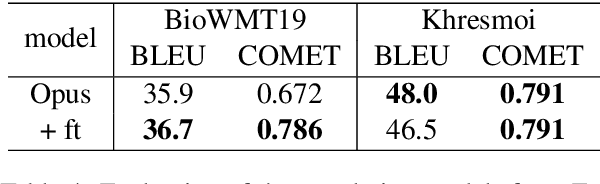
Natural language tasks like Named Entity Recognition (NER) in the clinical domain on non-English texts can be very time-consuming and expensive due to the lack of annotated data. Cross-lingual transfer (CLT) is a way to circumvent this issue thanks to the ability of multilingual large language models to be fine-tuned on a specific task in one language and to provide high accuracy for the same task in another language. However, other methods leveraging translation models can be used to perform NER without annotated data in the target language, by either translating the training set or test set. This paper compares cross-lingual transfer with these two alternative methods, to perform clinical NER in French and in German without any training data in those languages. To this end, we release MedNERF a medical NER test set extracted from French drug prescriptions and annotated with the same guidelines as an English dataset. Through extensive experiments on this dataset and on a German medical dataset (Frei and Kramer, 2021), we show that translation-based methods can achieve similar performance to CLT but require more care in their design. And while they can take advantage of monolingual clinical language models, those do not guarantee better results than large general-purpose multilingual models, whether with cross-lingual transfer or translation.
Analysing the Robustness of NSGA-II under Noise
Jun 07, 2023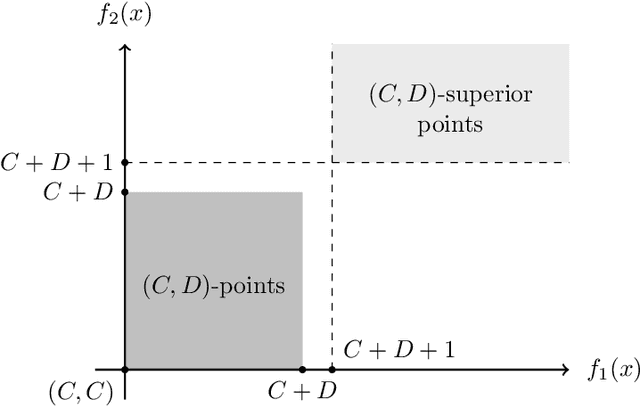
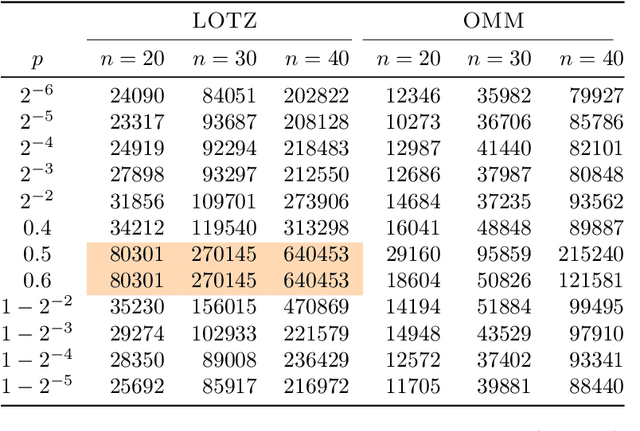

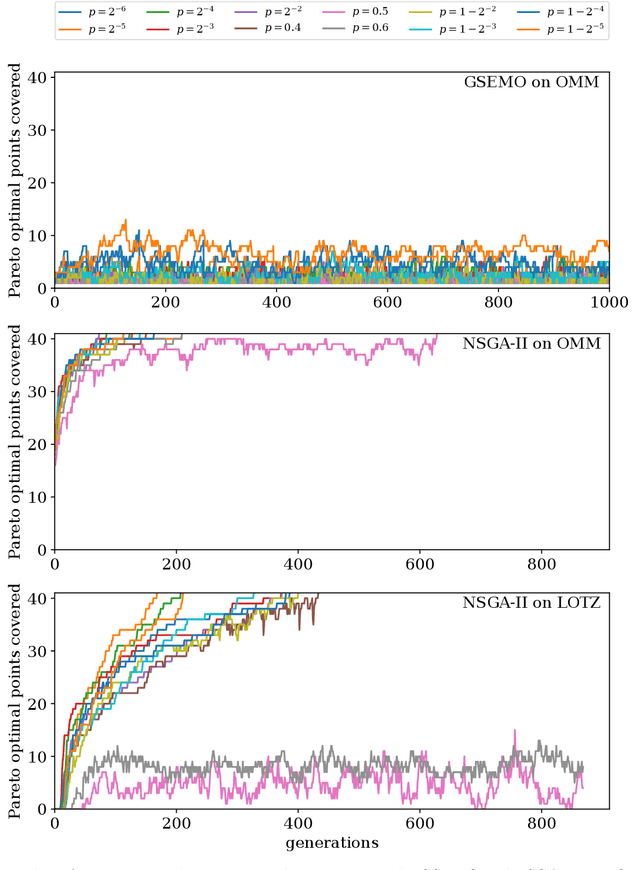
Runtime analysis has produced many results on the efficiency of simple evolutionary algorithms like the (1+1) EA, and its analogue called GSEMO in evolutionary multiobjective optimisation (EMO). Recently, the first runtime analyses of the famous and highly cited EMO algorithm NSGA-II have emerged, demonstrating that practical algorithms with thousands of applications can be rigorously analysed. However, these results only show that NSGA-II has the same performance guarantees as GSEMO and it is unclear how and when NSGA-II can outperform GSEMO. We study this question in noisy optimisation and consider a noise model that adds large amounts of posterior noise to all objectives with some constant probability $p$ per evaluation. We show that GSEMO fails badly on every noisy fitness function as it tends to remove large parts of the population indiscriminately. In contrast, NSGA-II is able to handle the noise efficiently on \textsc{LeadingOnesTrailingZeroes} when $p<1/2$, as the algorithm is able to preserve useful search points even in the presence of noise. We identify a phase transition at $p=1/2$ where the expected time to cover the Pareto front changes from polynomial to exponential. To our knowledge, this is the first proof that NSGA-II can outperform GSEMO and the first runtime analysis of NSGA-II in noisy optimisation.
Mixture-of-Supernets: Improving Weight-Sharing Supernet Training with Architecture-Routed Mixture-of-Experts
Jun 08, 2023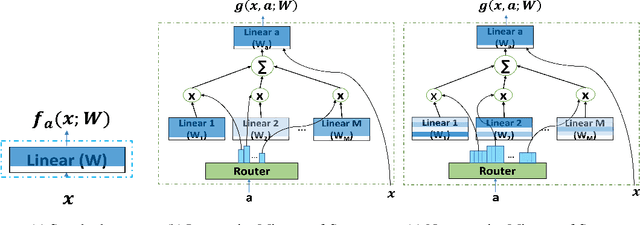


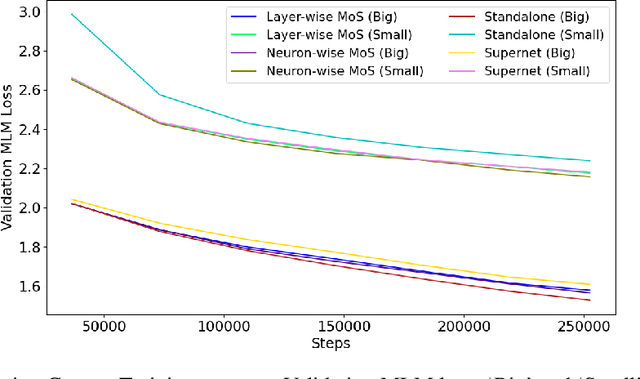
Weight-sharing supernet has become a vital component for performance estimation in the state-of-the-art (SOTA) neural architecture search (NAS) frameworks. Although supernet can directly generate different subnetworks without retraining, there is no guarantee for the quality of these subnetworks because of weight sharing. In NLP tasks such as machine translation and pre-trained language modeling, we observe that given the same model architecture, there is a large performance gap between supernet and training from scratch. Hence, supernet cannot be directly used and retraining is necessary after finding the optimal architectures. In this work, we propose mixture-of-supernets, a generalized supernet formulation where mixture-of-experts (MoE) is adopted to enhance the expressive power of the supernet model, with negligible training overhead. In this way, different subnetworks do not share the model weights directly, but through an architecture-based routing mechanism. As a result, model weights of different subnetworks are customized towards their specific architectures and the weight generation is learned by gradient descent. Compared to existing weight-sharing supernet for NLP, our method can minimize the retraining time, greatly improving training efficiency. In addition, the proposed method achieves the SOTA performance in NAS for building fast machine translation models, yielding better latency-BLEU tradeoff compared to HAT, state-of-the-art NAS for MT. We also achieve the SOTA performance in NAS for building memory-efficient task-agnostic BERT models, outperforming NAS-BERT and AutoDistil in various model sizes.
GPT Self-Supervision for a Better Data Annotator
Jun 08, 2023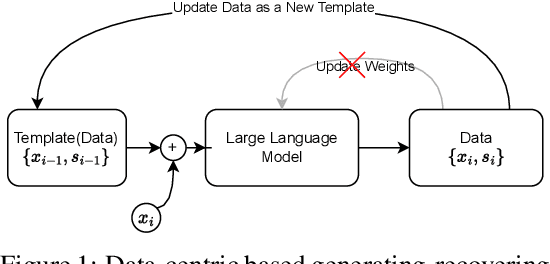
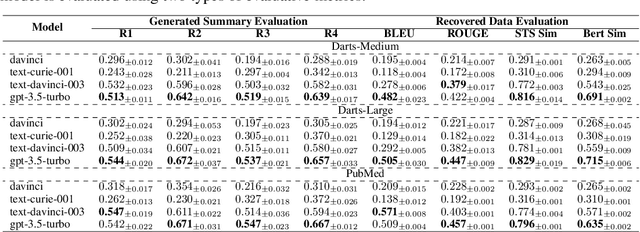
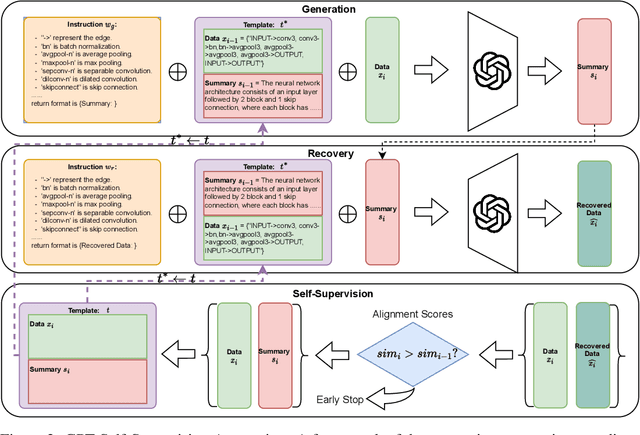

The task of annotating data into concise summaries poses a significant challenge across various domains, frequently requiring the allocation of significant time and specialized knowledge by human experts. Despite existing efforts to use large language models for annotation tasks, significant problems such as limited applicability to unlabeled data, the absence of self-supervised methods, and the lack of focus on complex structured data still persist. In this work, we propose a GPT self-supervision annotation method, which embodies a generating-recovering paradigm that leverages the one-shot learning capabilities of the Generative Pretrained Transformer (GPT). The proposed approach comprises a one-shot tuning phase followed by a generation phase. In the one-shot tuning phase, we sample a data from the support set as part of the prompt for GPT to generate a textual summary, which is then used to recover the original data. The alignment score between the recovered and original data serves as a self-supervision navigator to refine the process. In the generation stage, the optimally selected one-shot sample serves as a template in the prompt and is applied to generating summaries from challenging datasets. The annotation performance is evaluated by tuning several human feedback reward networks and by calculating alignment scores between original and recovered data at both sentence and structure levels. Our self-supervised annotation method consistently achieves competitive scores, convincingly demonstrating its robust strength in various data-to-summary annotation tasks.
Whitening-based Contrastive Learning of Sentence Embeddings
Jun 08, 2023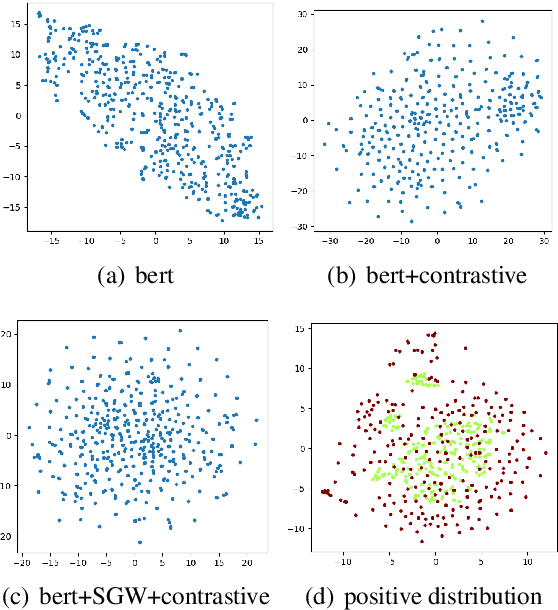
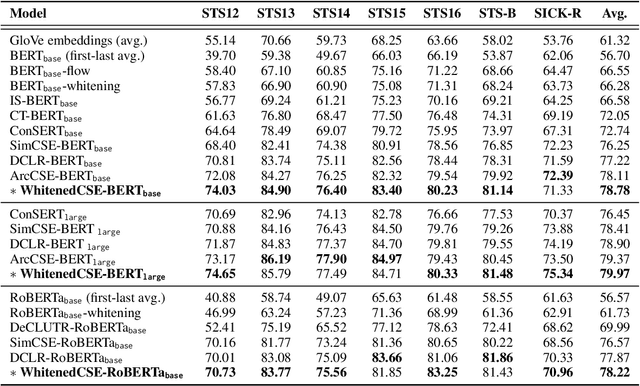
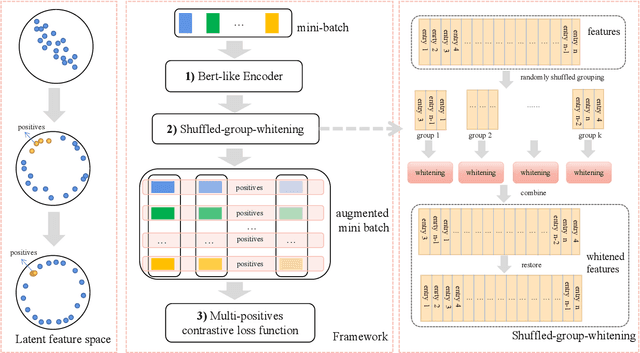
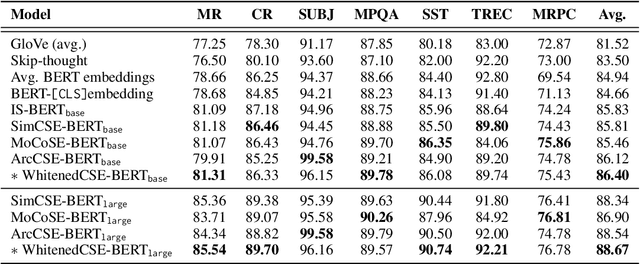
This paper presents a whitening-based contrastive learning method for sentence embedding learning (WhitenedCSE), which combines contrastive learning with a novel shuffled group whitening. Generally, contrastive learning pulls distortions of a single sample (i.e., positive samples) close and push negative samples far away, correspondingly facilitating the alignment and uniformity in the feature space. A popular alternative to the "pushing'' operation is whitening the feature space, which scatters all the samples for uniformity. Since the whitening and the contrastive learning have large redundancy w.r.t. the uniformity, they are usually used separately and do not easily work together. For the first time, this paper integrates whitening into the contrastive learning scheme and facilitates two benefits. 1) Better uniformity. We find that these two approaches are not totally redundant but actually have some complementarity due to different uniformity mechanism. 2) Better alignment. We randomly divide the feature into multiple groups along the channel axis and perform whitening independently within each group. By shuffling the group division, we derive multiple distortions of a single sample and thus increase the positive sample diversity. Consequently, using multiple positive samples with enhanced diversity further improves contrastive learning due to better alignment. Extensive experiments on seven semantic textual similarity tasks show our method achieves consistent improvement over the contrastive learning baseline and sets new states of the art, e.g., 78.78\% (+2.53\% based on BERT\ba) Spearman correlation on STS tasks.
CS-TRD: a Cross Sections Tree Ring Detection method
May 18, 2023


This work describes a Tree Ring Detection method for complete Cross-Sections of trees (CS-TRD). The method is based on the detection, processing, and connection of edges corresponding to the tree's growth rings. The method depends on the parameters for the Canny Devernay edge detector ($\sigma$ and two thresholds), a resize factor, the number of rays, and the pith location. The first five parameters are fixed by default. The pith location can be marked manually or using an automatic pith detection algorithm. Besides the pith localization, the CS-TRD method is fully automated and achieves an F-Score of 89\% in the UruDendro dataset (of Pinus Taeda) with a mean execution time of 17 seconds and of 97\% in the Kennel dataset (of Abies Alba) with an average execution time 11 seconds.
Double-Iterative Gaussian Process Regression for Modeling Error Compensation in Autonomous Racing
May 12, 2023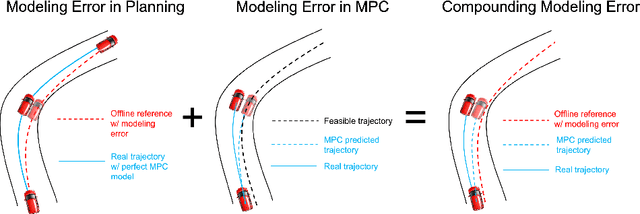
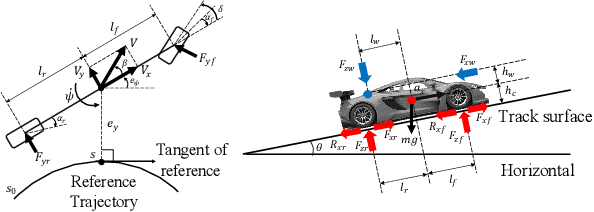
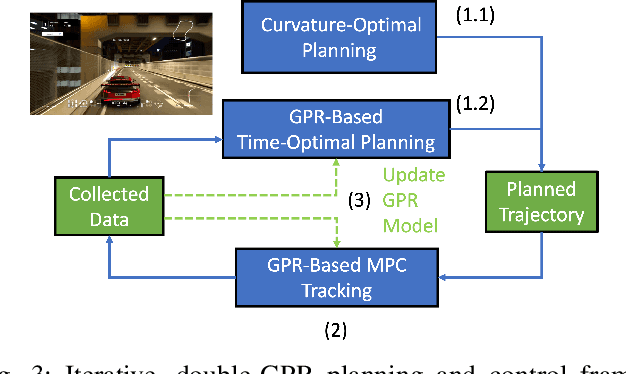

Autonomous racing control is a challenging research problem as vehicles are pushed to their limits of handling to achieve an optimal lap time; therefore, vehicles exhibit highly nonlinear and complex dynamics. Difficult-to-model effects, such as drifting, aerodynamics, chassis weight transfer, and suspension can lead to infeasible and suboptimal trajectories. While offline planning allows optimizing a full reference trajectory for the minimum lap time objective, such modeling discrepancies are particularly detrimental when using offline planning, as planning model errors compound with controller modeling errors. Gaussian Process Regression (GPR) can compensate for modeling errors. However, previous works primarily focus on modeling error in real-time control without consideration for how the model used in offline planning can affect the overall performance. In this work, we propose a double-GPR error compensation algorithm to reduce model uncertainties; specifically, we compensate both the planner's model and controller's model with two respective GPR-based error compensation functions. Furthermore, we design an iterative framework to re-collect error-rich data using the racing control system. We test our method in the high-fidelity racing simulator Gran Turismo Sport (GTS); we find that our iterative, double-GPR compensation functions improve racing performance and iteration stability in comparison to a single compensation function applied merely for real-time control.