 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Traversability Estimation for Wild Visual Navigation
May 16, 2023
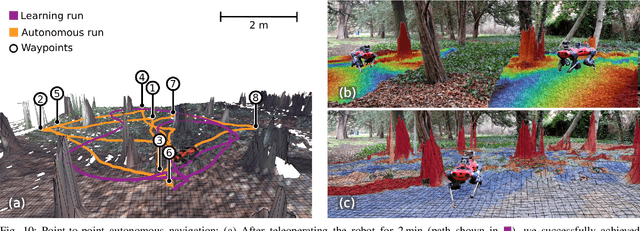
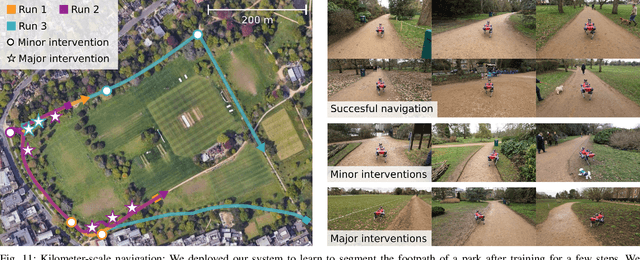
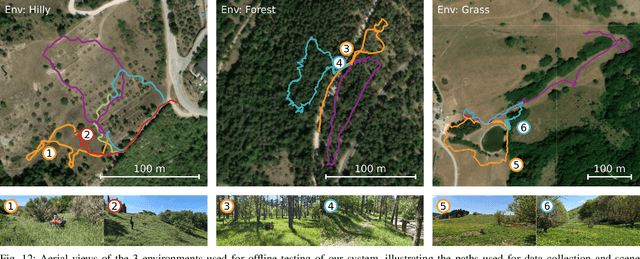

Natural environments such as forests and grasslands are challenging for robotic navigation because of the false perception of rigid obstacles from high grass, twigs, or bushes. In this work, we propose Wild Visual Navigation (WVN), an online self-supervised learning system for traversability estimation which uses only vision. The system is able to continuously adapt from a short human demonstration in the field. It leverages high-dimensional features from self-supervised visual transformer models, with an online scheme for supervision generation that runs in real-time on the robot. We demonstrate the advantages of our approach with experiments and ablation studies in challenging environments in forests, parks, and grasslands. Our system is able to bootstrap the traversable terrain segmentation in less than 5 min of in-field training time, enabling the robot to navigate in complex outdoor terrains - negotiating obstacles in high grass as well as a 1.4 km footpath following. While our experiments were executed with a quadruped robot, ANYmal, the approach presented can generalize to any ground robot.
Self-Aware Trajectory Prediction for Safe Autonomous Driving
May 16, 2023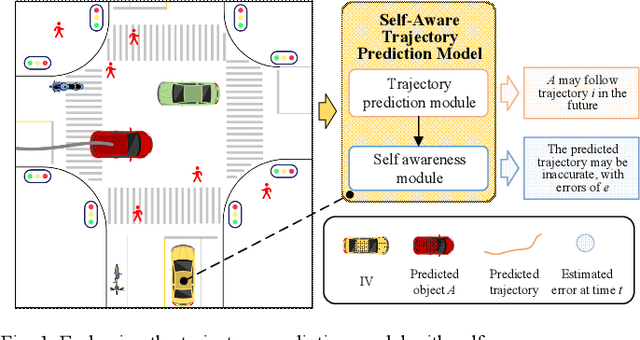
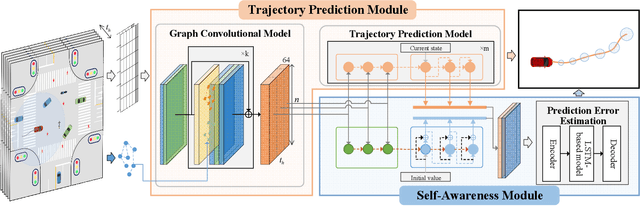
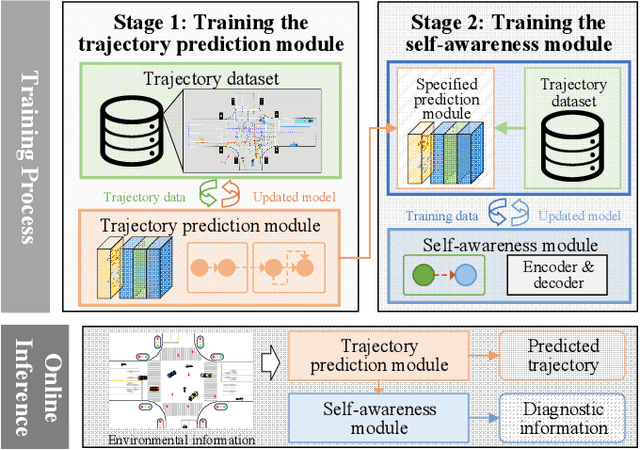
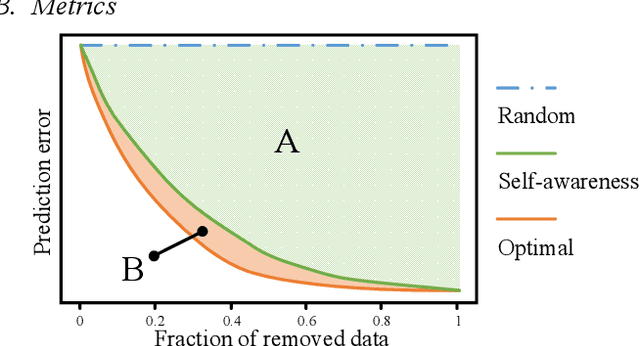
Trajectory prediction is one of the key components of the autonomous driving software stack. Accurate prediction for the future movement of surrounding traffic participants is an important prerequisite for ensuring the driving efficiency and safety of intelligent vehicles. Trajectory prediction algorithms based on artificial intelligence have been widely studied and applied in recent years and have achieved remarkable results. However, complex artificial intelligence models are uncertain and difficult to explain, so they may face unintended failures when applied in the real world. In this paper, a self-aware trajectory prediction method is proposed. By introducing a self-awareness module and a two-stage training process, the original trajectory prediction module's performance is estimated online, to facilitate the system to deal with the possible scenario of insufficient prediction function in time, and create conditions for the realization of safe and reliable autonomous driving. Comprehensive experiments and analysis are performed, and the proposed method performed well in terms of self-awareness, memory footprint, and real-time performance, showing that it may serve as a promising paradigm for safe autonomous driving.
Counterfactual Outcome Prediction using Structured State Space Model
May 16, 2023Counterfactual outcome prediction in longitudinal data has recently gained attention due to its potential applications in healthcare and social sciences. In this paper, we explore the use of the state space model, a popular sequence model, for this task. Specifically, we compare the performance of two models: Treatment Effect Neural Controlled Differential Equation (TE-CDE) and structured state space model (S4Model). While TE-CDE uses controlled differential equations to address time-dependent confounding, it suffers from optimization issues and slow training. In contrast, S4Model is more efficient at modeling long-range dependencies and easier to train. We evaluate the models on a simulated lung tumor growth dataset and find that S4Model outperforms TE-CDE with 1.63x reduction in per epoch training time and 10x better normalized mean squared error. Additionally, S4Model is more stable during training and less sensitive to weight initialization than TE-CDE. Our results suggest that the state space model may be a promising approach for counterfactual outcome prediction in longitudinal data, with S4Model offering a more efficient and effective alternative to TE-CDE.
A Neural State-Space Model Approach to Efficient Speech Separation
May 26, 2023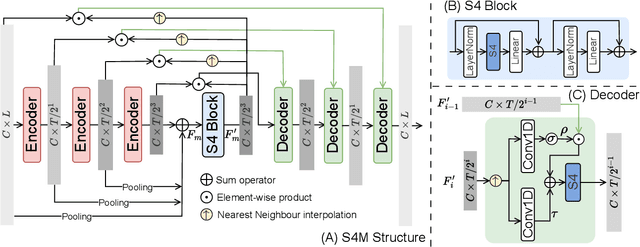
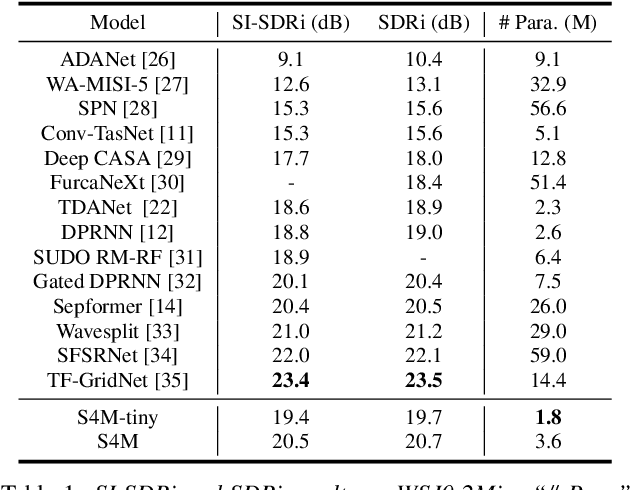
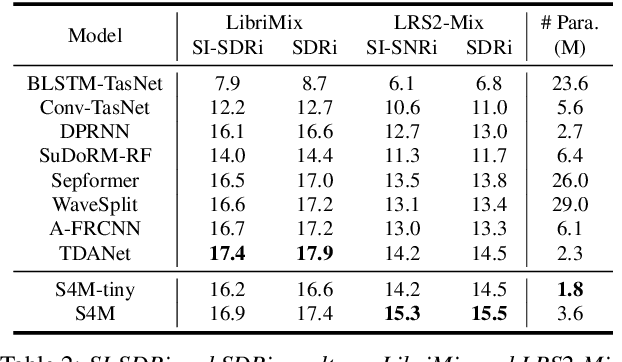
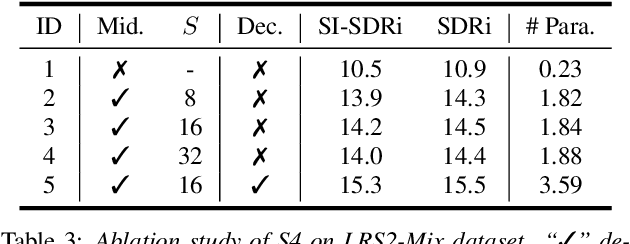
In this work, we introduce S4M, a new efficient speech separation framework based on neural state-space models (SSM). Motivated by linear time-invariant systems for sequence modeling, our SSM-based approach can efficiently model input signals into a format of linear ordinary differential equations (ODEs) for representation learning. To extend the SSM technique into speech separation tasks, we first decompose the input mixture into multi-scale representations with different resolutions. This mechanism enables S4M to learn globally coherent separation and reconstruction. The experimental results show that S4M performs comparably to other separation backbones in terms of SI-SDRi, while having a much lower model complexity with significantly fewer trainable parameters. In addition, our S4M-tiny model (1.8M parameters) even surpasses attention-based Sepformer (26.0M parameters) in noisy conditions with only 9.2 of multiply-accumulate operation (MACs).
Gender, Smoking History and Age Prediction from Laryngeal Images
May 26, 2023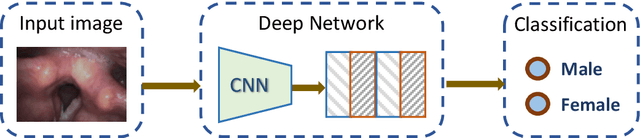
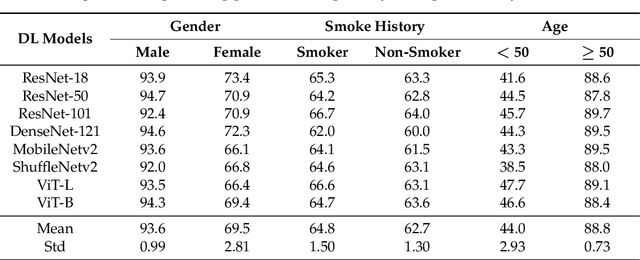
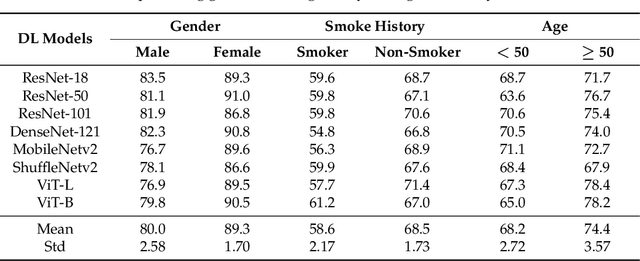
Flexible laryngoscopy is commonly performed by otolaryngologists to detect laryngeal diseases and to recognize potentially malignant lesions. Recently, researchers have introduced machine learning techniques to facilitate automated diagnosis using laryngeal images and achieved promising results. Diagnostic performance can be improved when patients' demographic information is incorporated into models. However, manual entry of patient data is time consuming for clinicians. In this study, we made the first endeavor to employ deep learning models to predict patient demographic information to improve detector model performance. The overall accuracy for gender, smoking history, and age was 85.5%, 65.2%, and 75.9%, respectively. We also created a new laryngoscopic image set for machine learning study and benchmarked the performance of 8 classical deep learning models based on CNNs and Transformers. The results can be integrated into current learning models to improve their performance by incorporating the patient's demographic information.
Best Arm Identification in Bandits with Limited Precision Sampling
May 10, 2023We study best arm identification in a variant of the multi-armed bandit problem where the learner has limited precision in arm selection. The learner can only sample arms via certain exploration bundles, which we refer to as boxes. In particular, at each sampling epoch, the learner selects a box, which in turn causes an arm to get pulled as per a box-specific probability distribution. The pulled arm and its instantaneous reward are revealed to the learner, whose goal is to find the best arm by minimising the expected stopping time, subject to an upper bound on the error probability. We present an asymptotic lower bound on the expected stopping time, which holds as the error probability vanishes. We show that the optimal allocation suggested by the lower bound is, in general, non-unique and therefore challenging to track. We propose a modified tracking-based algorithm to handle non-unique optimal allocations, and demonstrate that it is asymptotically optimal. We also present non-asymptotic lower and upper bounds on the stopping time in the simpler setting when the arms accessible from one box do not overlap with those of others.
Transfer Learning for Real-time Deployment of a Screening Tool for Depression Detection Using Actigraphy
Mar 14, 2023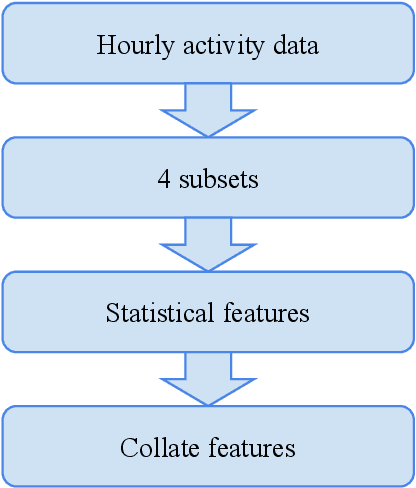
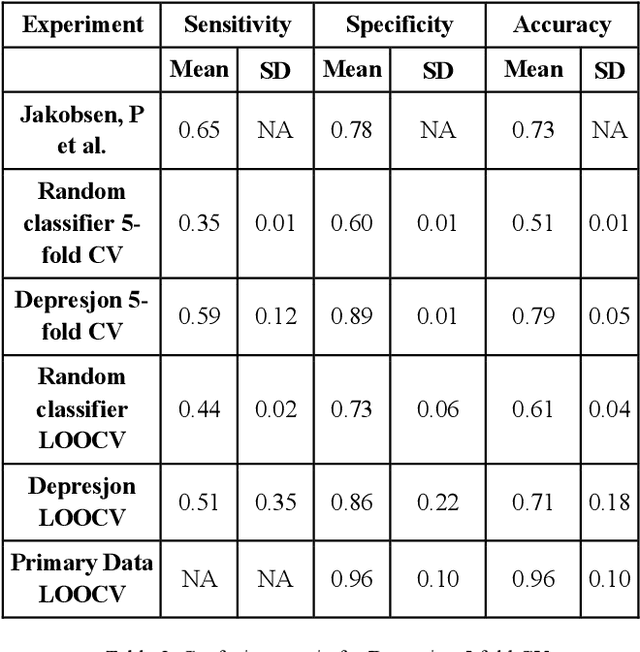
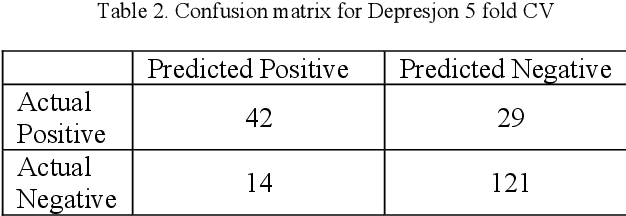
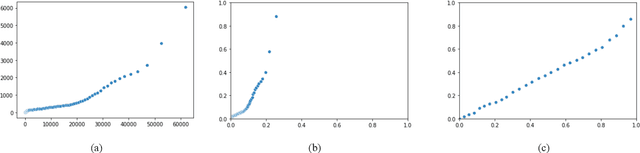
Automated depression screening and diagnosis is a highly relevant problem today. There are a number of limitations of the traditional depression detection methods, namely, high dependence on clinicians and biased self-reporting. In recent years, research has suggested strong potential in machine learning (ML) based methods that make use of the user's passive data collected via wearable devices. However, ML is data hungry. Especially in the healthcare domain primary data collection is challenging. In this work, we present an approach based on transfer learning, from a model trained on a secondary dataset, for the real time deployment of the depression screening tool based on the actigraphy data of users. This approach enables machine learning modelling even with limited primary data samples. A modified version of leave one out cross validation approach performed on the primary set resulted in mean accuracy of 0.96, where in each iteration one subject's data from the primary set was set aside for testing.
Machine Learning Approach for Cancer Entities Association and Classification
May 30, 2023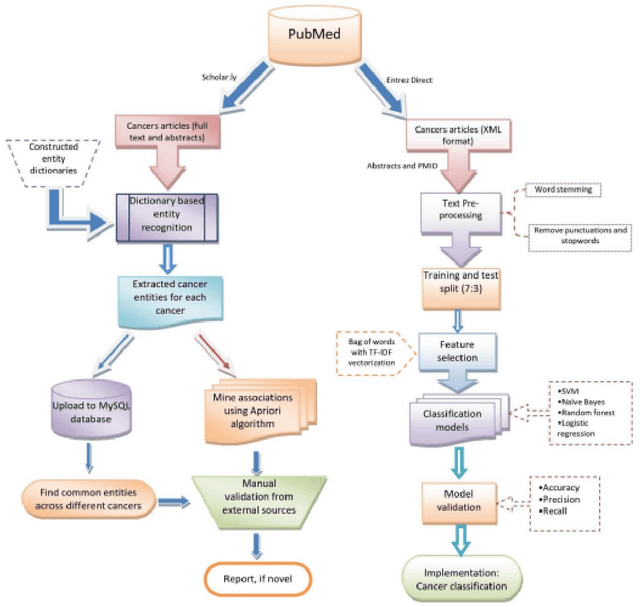
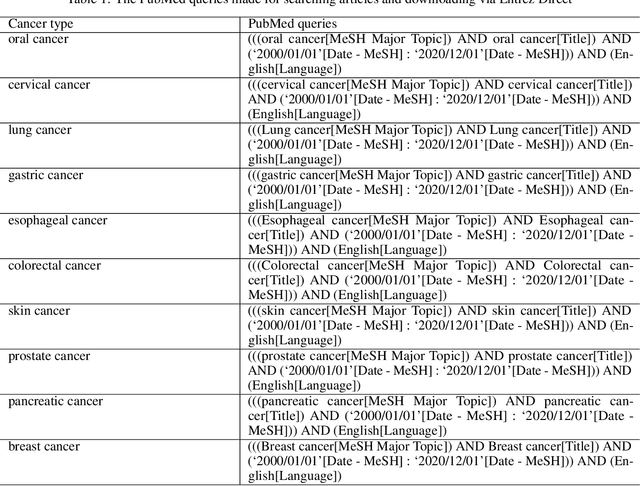
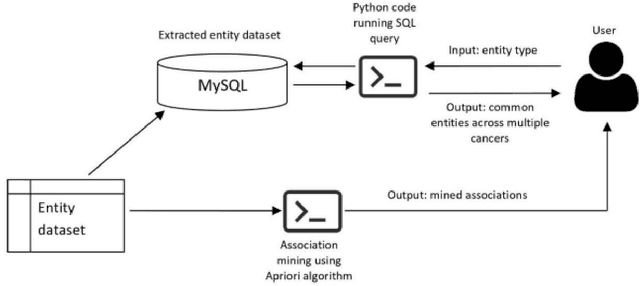
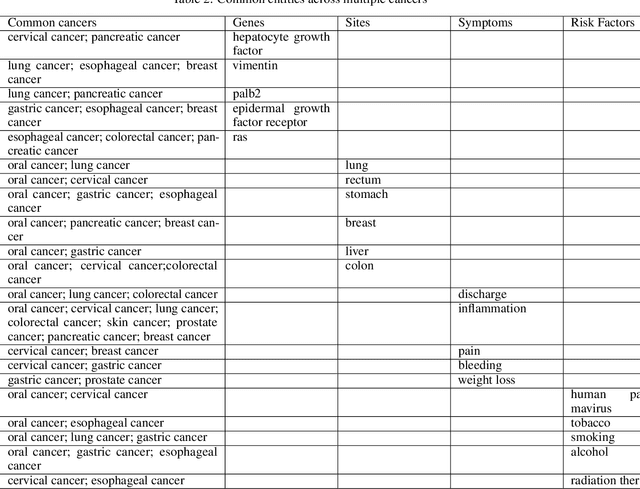
According to the World Health Organization (WHO), cancer is the second leading cause of death globally. Scientific research on different types of cancers grows at an ever-increasing rate, publishing large volumes of research articles every year. The insight information and the knowledge of the drug, diagnostics, risk, symptoms, treatments, etc., related to genes are significant factors that help explore and advance the cancer research progression. Manual screening of such a large volume of articles is very laborious and time-consuming to formulate any hypothesis. The study uses the two most non-trivial NLP, Natural Language Processing functions, Entity Recognition, and text classification to discover knowledge from biomedical literature. Named Entity Recognition (NER) recognizes and extracts the predefined entities related to cancer from unstructured text with the support of a user-friendly interface and built-in dictionaries. Text classification helps to explore the insights into the text and simplifies data categorization, querying, and article screening. Machine learning classifiers are also used to build the classification model and Structured Query Languages (SQL) is used to identify the hidden relations that may lead to significant predictions.
Voxel2Hemodynamics: An End-to-end Deep Learning Method for Predicting Coronary Artery Hemodynamics
May 30, 2023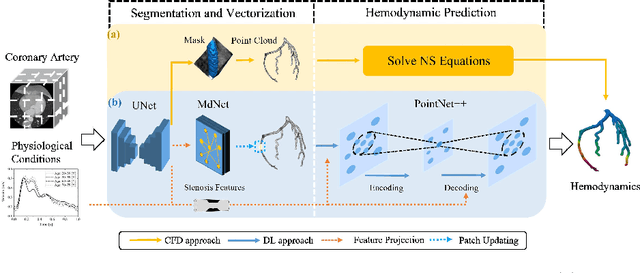

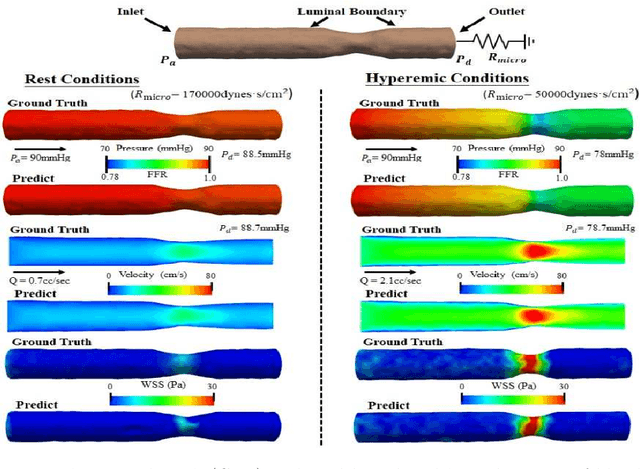
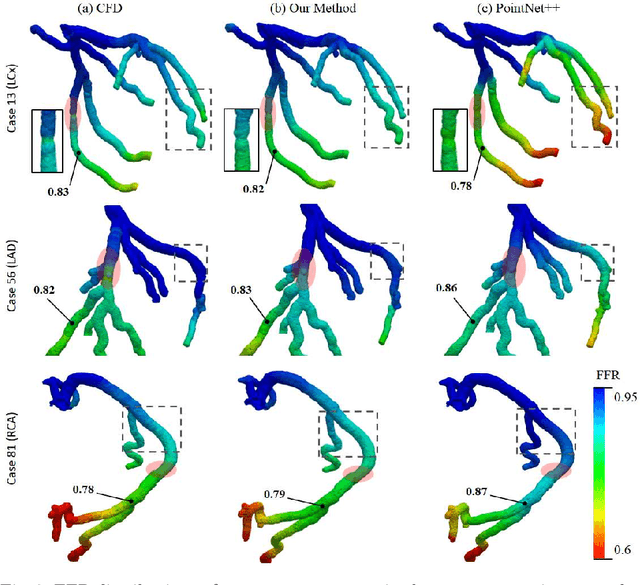
Local hemodynamic forces play an important role in determining the functional significance of coronary arterial stenosis and understanding the mechanism of coronary disease progression. Computational fluid dynamics (CFD) have been widely performed to simulate hemodynamics non-invasively from coronary computed tomography angiography (CCTA) images. However, accurate computational analysis is still limited by the complex construction of patient-specific modeling and time-consuming computation. In this work, we proposed an end-to-end deep learning framework, which could predict the coronary artery hemodynamics from CCTA images. The model was trained on the hemodynamic data obtained from 3D simulations of synthetic and real datasets. Extensive experiments demonstrated that the predicted hemdynamic distributions by our method agreed well with the CFD-derived results. Quantitatively, the proposed method has the capability of predicting the fractional flow reserve with an average error of 0.5\% and 2.5\% for the synthetic dataset and real dataset, respectively. Particularly, our method achieved much better accuracy for the real dataset compared to PointNet++ with the point cloud input. This study demonstrates the feasibility and great potential of our end-to-end deep learning method as a fast and accurate approach for hemodynamic analysis.
Multi-modal Queried Object Detection in the Wild
May 30, 2023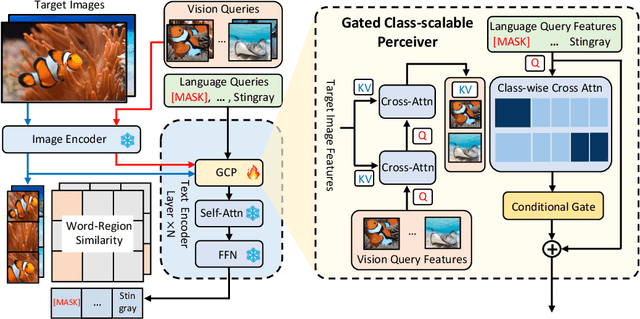
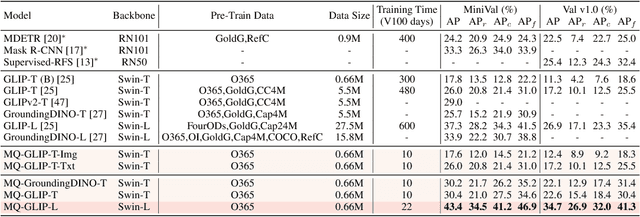
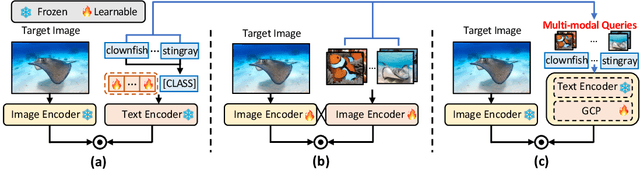
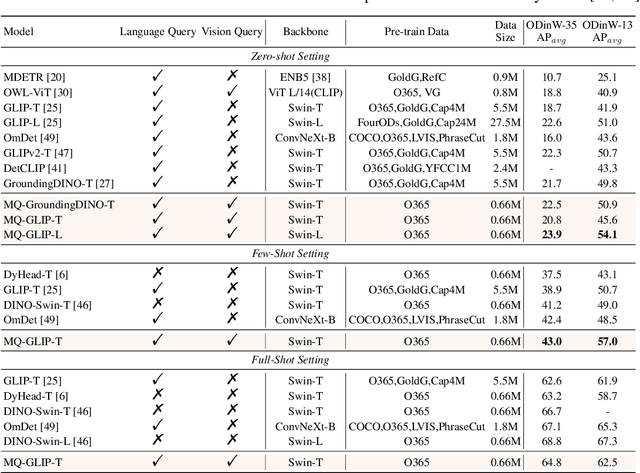
We introduce MQ-Det, an efficient architecture and pre-training strategy design to utilize both textual description with open-set generalization and visual exemplars with rich description granularity as category queries, namely, Multi-modal Queried object Detection, for real-world detection with both open-vocabulary categories and various granularity. MQ-Det incorporates vision queries into existing well-established language-queried-only detectors. A plug-and-play gated class-scalable perceiver module upon the frozen detector is proposed to augment category text with class-wise visual information. To address the learning inertia problem brought by the frozen detector, a vision conditioned masked language prediction strategy is proposed. MQ-Det's simple yet effective architecture and training strategy design is compatible with most language-queried object detectors, thus yielding versatile applications. Experimental results demonstrate that multi-modal queries largely boost open-world detection. For instance, MQ-Det significantly improves the state-of-the-art open-set detector GLIP by +7.8% zero-shot AP on the LVIS benchmark and averagely +6.3% AP on 13 few-shot downstream tasks, with merely 3% pre-training time required by GLIP. Code is available at https://github.com/YifanXu74/MQ-Det.