 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Context-Preserving Two-Stage Video Domain Translation for Portrait Stylization
May 30, 2023

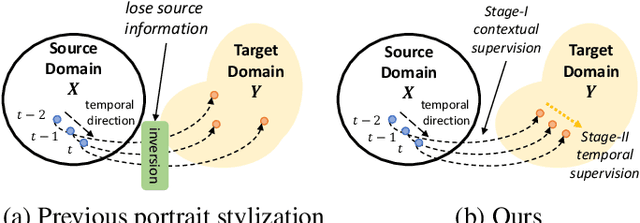


Portrait stylization, which translates a real human face image into an artistically stylized image, has attracted considerable interest and many prior works have shown impressive quality in recent years. However, despite their remarkable performances in the image-level translation tasks, prior methods show unsatisfactory results when they are applied to the video domain. To address the issue, we propose a novel two-stage video translation framework with an objective function which enforces a model to generate a temporally coherent stylized video while preserving context in the source video. Furthermore, our model runs in real-time with the latency of 0.011 seconds per frame and requires only 5.6M parameters, and thus is widely applicable to practical real-world applications.
Simulation of a first prototypical 3D solution for Indoor Localization based on Directed and Reflected Signals
May 30, 2023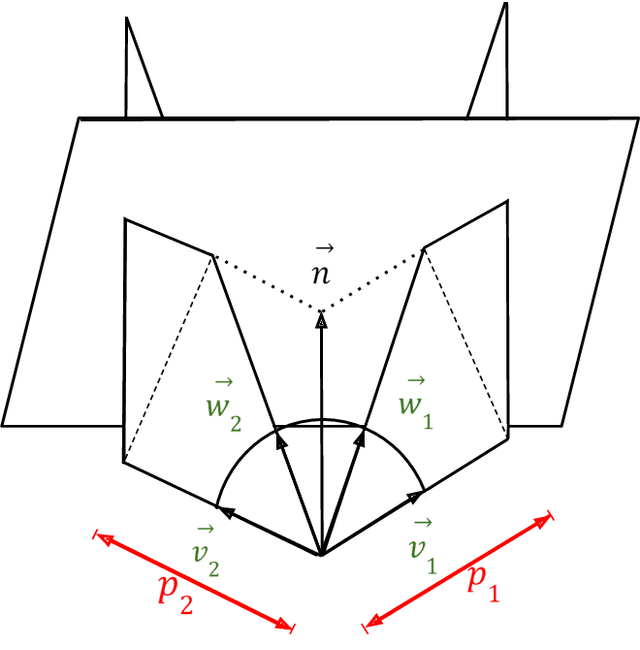
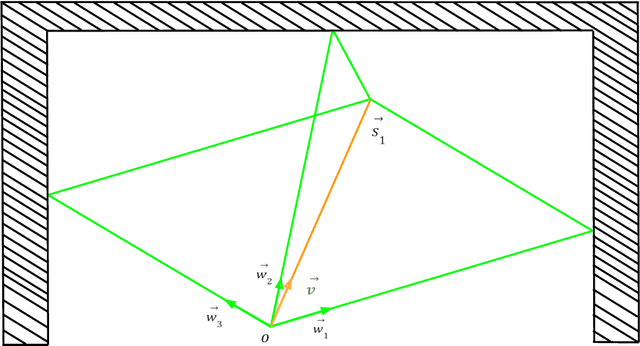
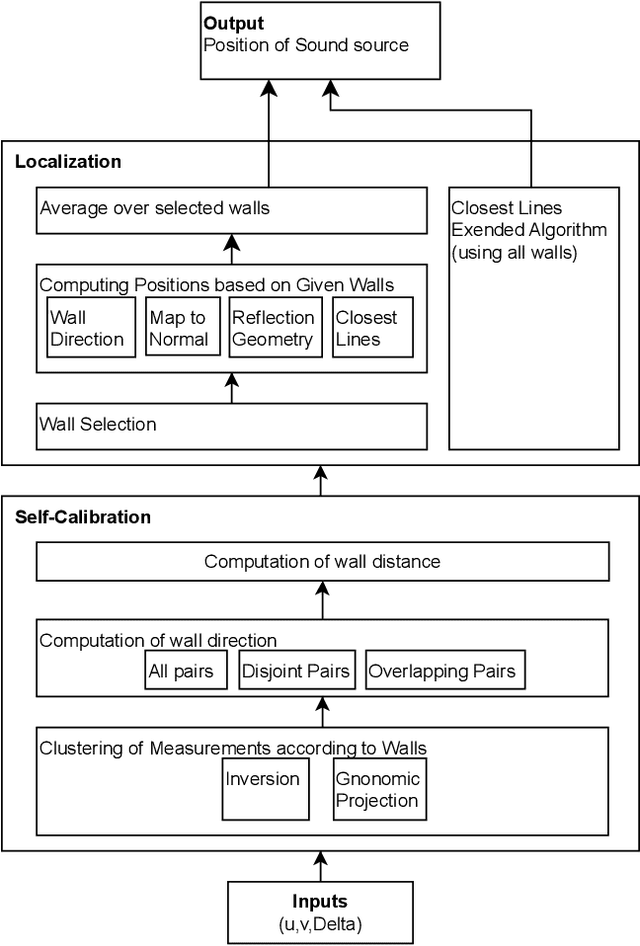
We introduce a solution for a specific case of Indoor Localization which involves a directed signal, a reflected signal from the wall and the time difference between them. This solution includes robust localization with a given wall, finding the right wall from a group of walls, obtaining the reflecting wall from measurements, using averaging techniques for improving measurements with errors and successfully grouping measurements regarding reflecting walls. It also includes performing self-calibration by computation of wall distance and direction introducing algorithms such as All pairs, Disjoint pairs and Overlapping pairs and clustering walls based on Inversion and Gnomonic Projection. Several of these algorithms are then compared in order to ameliorate the effects of measurement errors.
Back to Patterns: Efficient Japanese Morphological Analysis with Feature-Sequence Trie
May 30, 2023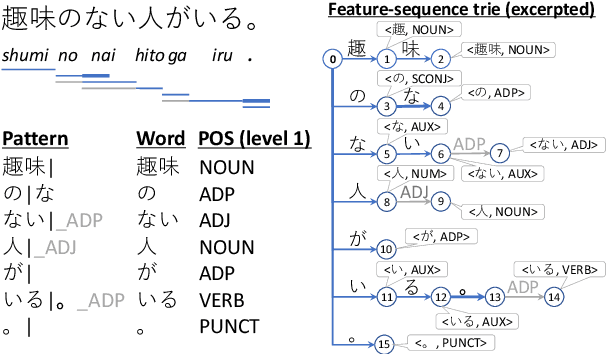
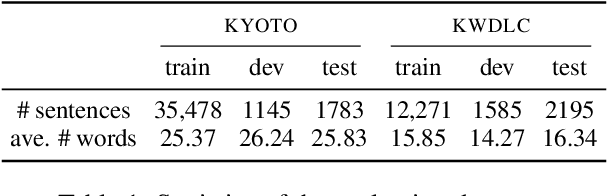
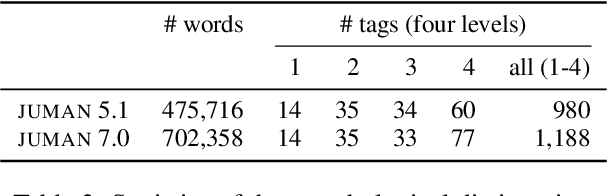

Accurate neural models are much less efficient than non-neural models and are useless for processing billions of social media posts or handling user queries in real time with a limited budget. This study revisits the fastest pattern-based NLP methods to make them as accurate as possible, thus yielding a strikingly simple yet surprisingly accurate morphological analyzer for Japanese. The proposed method induces reliable patterns from a morphological dictionary and annotated data. Experimental results on two standard datasets confirm that the method exhibits comparable accuracy to learning-based baselines, while boasting a remarkable throughput of over 1,000,000 sentences per second on a single modern CPU. The source code is available at https://www.tkl.iis.u-tokyo.ac.jp/~ynaga/jagger/
On the Identifiability of Markov Switching Models
May 26, 2023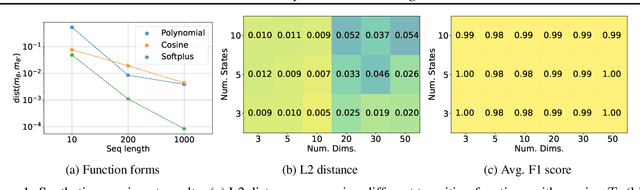
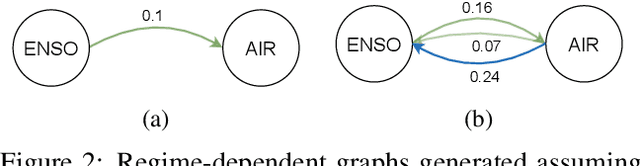
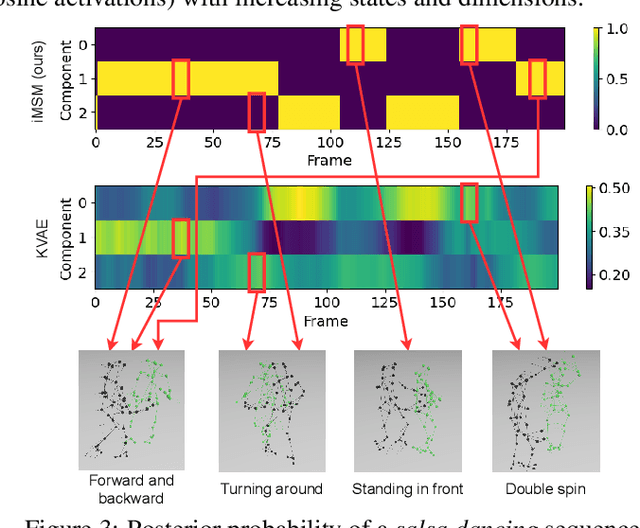
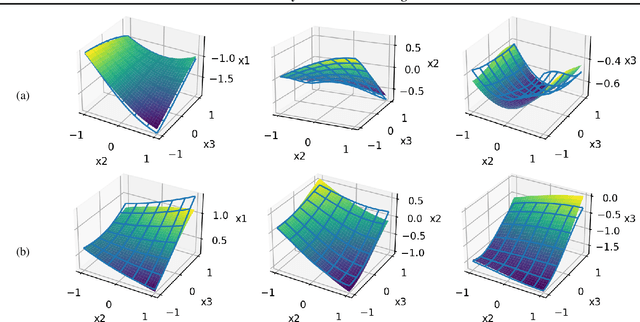
Identifiability of latent variable models has recently gained interest in terms of its applications to interpretability or out of distribution generalisation. In this work, we study identifiability of Markov Switching Models as a first step towards extending recent results to sequential latent variable models. We present identifiability conditions within first-order Markov dependency structures, and parametrise the transition distribution via non-linear Gaussians. Our experiments showcase the applicability of our approach for regime-dependent causal discovery and high-dimensional time series segmentation.
CEN-HDR: Computationally Efficient neural Network for real-time High Dynamic Range imaging
Feb 10, 2023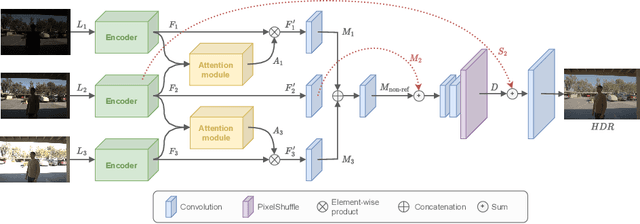
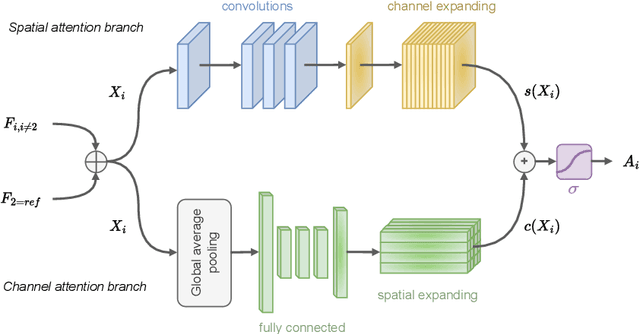
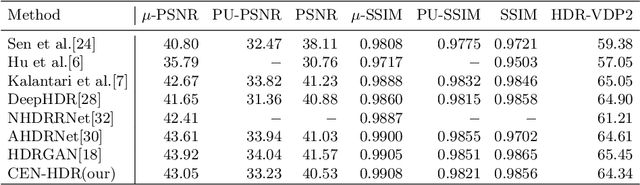
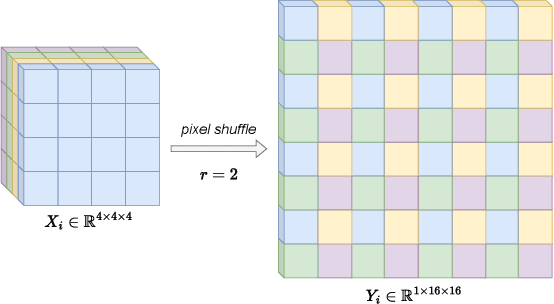
High dynamic range (HDR) imaging is still a challenging task in modern digital photography. Recent research proposes solutions that provide high-quality acquisition but at the cost of a very large number of operations and a slow inference time that prevent the implementation of these solutions on lightweight real-time systems. In this paper, we propose CEN-HDR, a new computationally efficient neural network by providing a novel architecture based on a light attention mechanism and sub-pixel convolution operations for real-time HDR imaging. We also provide an efficient training scheme by applying network compression using knowledge distillation. We performed extensive qualitative and quantitative comparisons to show that our approach produces competitive results in image quality while being faster than state-of-the-art solutions, allowing it to be practically deployed under real-time constraints. Experimental results show our method obtains a score of 43.04 mu-PSNR on the Kalantari2017 dataset with a framerate of 33 FPS using a Macbook M1 NPU.
Policy Synthesis and Reinforcement Learning for Discounted LTL
May 29, 2023

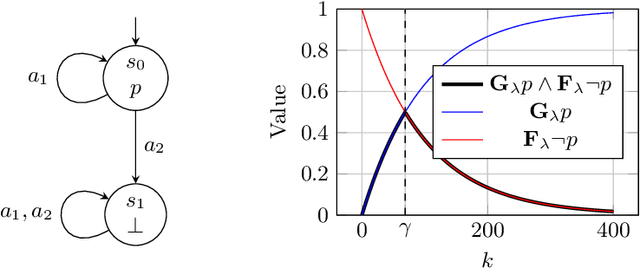
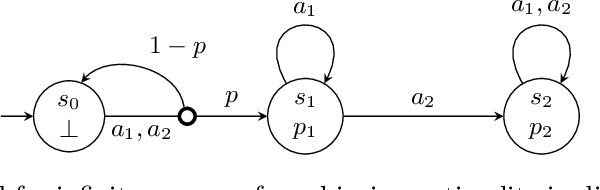
The difficulty of manually specifying reward functions has led to an interest in using linear temporal logic (LTL) to express objectives for reinforcement learning (RL). However, LTL has the downside that it is sensitive to small perturbations in the transition probabilities, which prevents probably approximately correct (PAC) learning without additional assumptions. Time discounting provides a way of removing this sensitivity, while retaining the high expressivity of the logic. We study the use of discounted LTL for policy synthesis in Markov decision processes with unknown transition probabilities, and show how to reduce discounted LTL to discounted-sum reward via a reward machine when all discount factors are identical.
Deep Imputation of Missing Values in Time Series Health Data: A Review with Benchmarking
Feb 10, 2023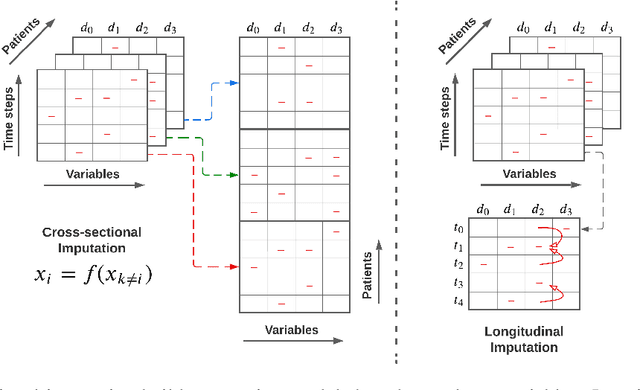
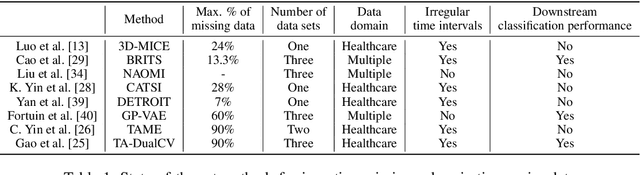
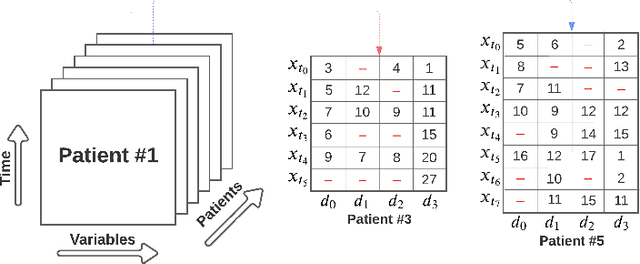

The imputation of missing values in multivariate time series data has been explored using a few recently proposed deep learning methods. The evaluation of these state-of-the-art methods is limited to one or two data sets, low missing rates, and completely random missing value types. These limited experiments do not comprehensively evaluate imputation methods on realistic data scenarios with varying missing rates and not-at-random missing types. This survey takes a data-centric approach to benchmark state-of-the-art deep imputation methods across five time series health data sets and six experimental conditions. Our extensive analysis reveals that no single imputation method outperforms the others on all five data sets. The imputation performance depends on data types, individual variable statistics, missing value rates, and types. In this context, state-of-the-art methods jointly perform cross-sectional (across variables) and longitudinal (across time) imputations of missing values in time series data. However, variables with high cross-correlation can be better imputed by cross-sectional imputation methods alone. In contrast, the ones with time series sensor signals may be better imputed by longitudinal imputation methods alone. The findings of this study emphasize the importance of considering data specifics when choosing a missing value imputation method for multivariate time series data.
Synchro-Transient-Extracting Transform for the Analysis of Signals with Both Harmonic and Impulsive Components
Jun 02, 2023Time-frequency analysis (TFA) techniques play an increasingly important role in the field of machine fault diagnosis attributing to their superiority in dealing with nonstationary signals. Synchroextracting transform (SET) and transient-extracting transform (TET) are two newly emerging techniques that can produce energy concentrated representation for nonstationary signals. However, SET and TET are only suitable for processing harmonic signals and impulsive signals, respectively. This poses a challenge for each of these two techniques when a signal contains both harmonic and impulsive components. In this paper, we propose a new TFA technique to solve this problem. The technique aims to combine the advantages of SET and TET to generate energy concentrated representations for both harmonic and impulsive components of the signal. Furthermore, we theoretically demonstrate that the proposed technique retains the signal reconstruction capability. The effectiveness of the proposed technique is verified using numerical and real-world signals.
SAPI: Surroundings-Aware Vehicle Trajectory Prediction at Intersections
Jun 02, 2023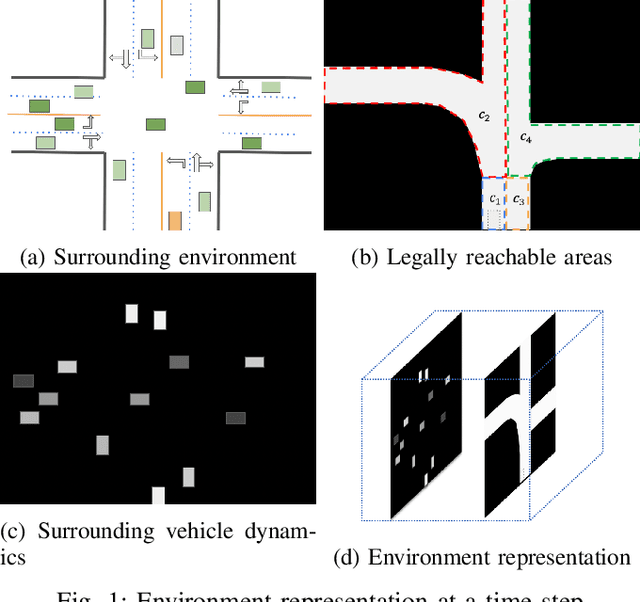
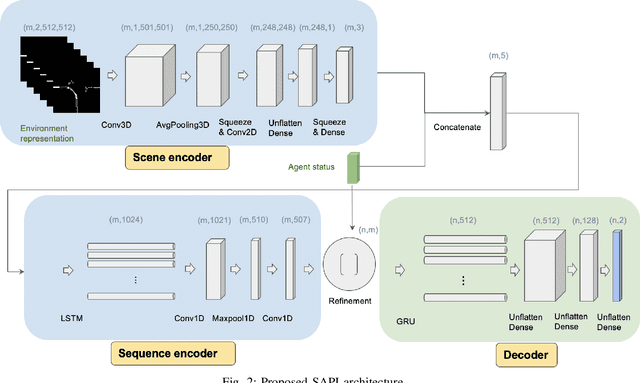
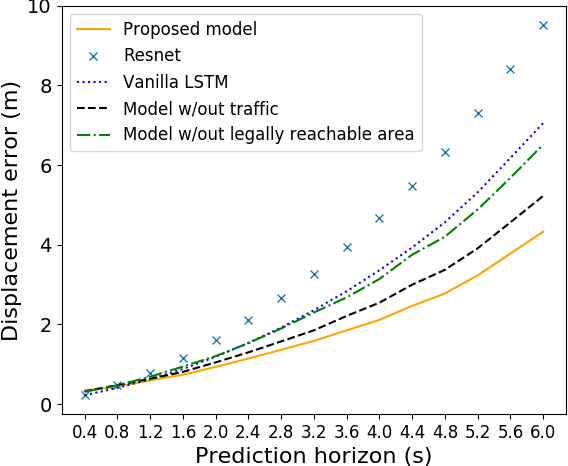
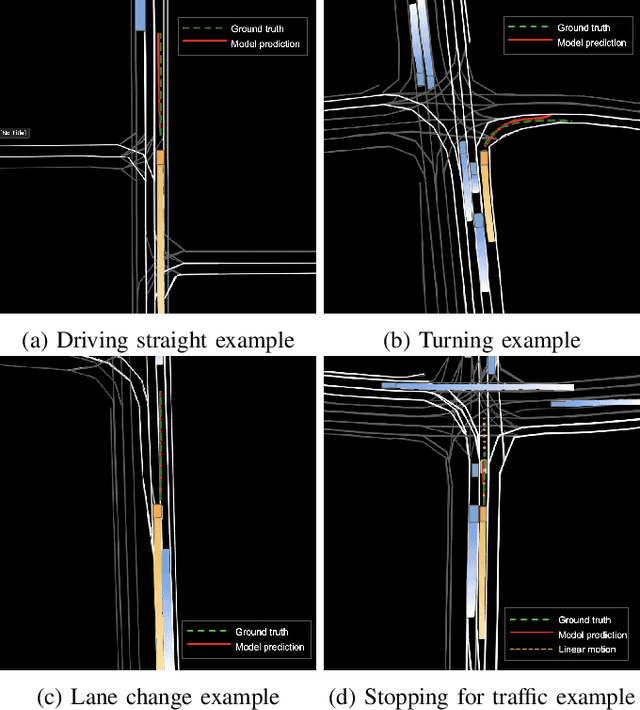
In this work we propose a deep learning model, i.e., SAPI, to predict vehicle trajectories at intersections. SAPI uses an abstract way to represent and encode surrounding environment by utilizing information from real-time map, right-of-way, and surrounding traffic. The proposed model consists of two convolutional network (CNN) and recurrent neural network (RNN)-based encoders and one decoder. A refiner is proposed to conduct a look-back operation inside the model, in order to make full use of raw history trajectory information. We evaluate SAPI on a proprietary dataset collected in real-world intersections through autonomous vehicles. It is demonstrated that SAPI shows promising performance when predicting vehicle trajectories at intersection, and outperforms benchmark methods. The average displacement error(ADE) and final displacement error(FDE) for 6-second prediction are 1.84m and 4.32m respectively. We also show that the proposed model can accurately predict vehicle trajectories in different scenarios.
Transforming ECG Diagnosis:An In-depth Review of Transformer-based DeepLearning Models in Cardiovascular Disease Detection
Jun 02, 2023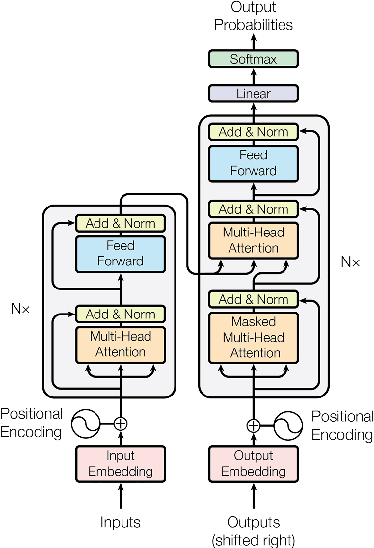
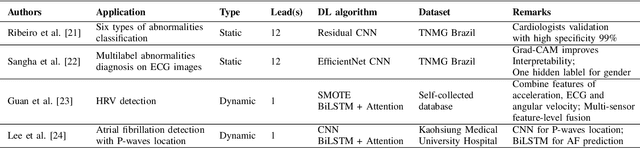
The emergence of deep learning has significantly enhanced the analysis of electrocardiograms (ECGs), a non-invasive method that is essential for assessing heart health. Despite the complexity of ECG interpretation, advanced deep learning models outperform traditional methods. However, the increasing complexity of ECG data and the need for real-time and accurate diagnosis necessitate exploring more robust architectures, such as transformers. Here, we present an in-depth review of transformer architectures that are applied to ECG classification. Originally developed for natural language processing, these models capture complex temporal relationships in ECG signals that other models might overlook. We conducted an extensive search of the latest transformer-based models and summarize them to discuss the advances and challenges in their application and suggest potential future improvements. This review serves as a valuable resource for researchers and practitioners and aims to shed light on this innovative application in ECG interpretation.