 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Mar 18, 2024

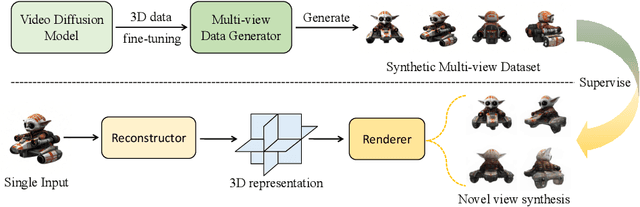
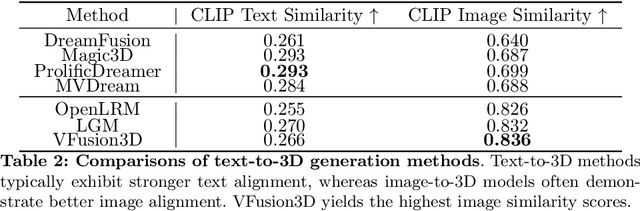

This paper presents a novel paradigm for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 70% of the time.
AutoHLS: Learning to Accelerate Design Space Exploration for HLS Designs
Mar 15, 2024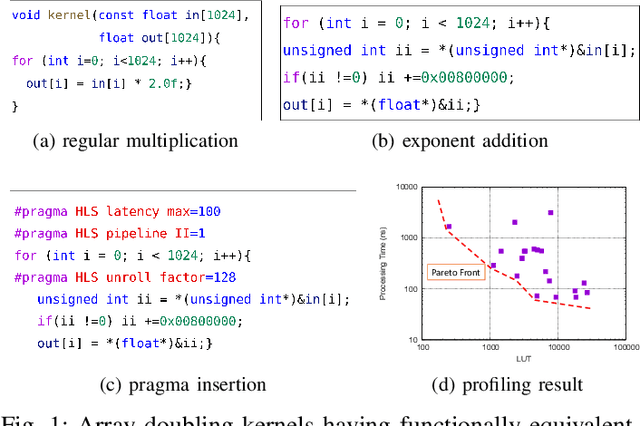
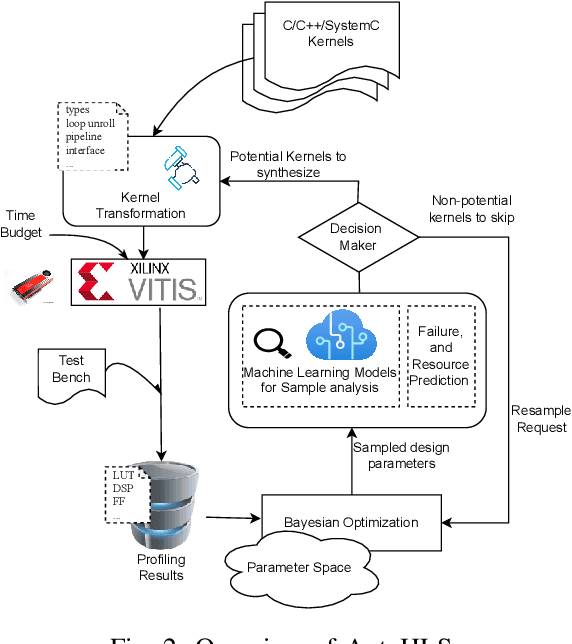
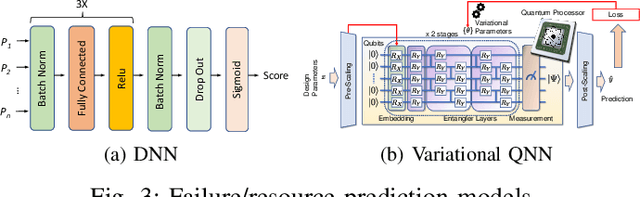
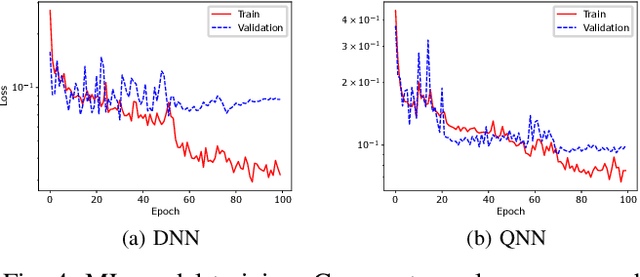
High-level synthesis (HLS) is a design flow that leverages modern language features and flexibility, such as complex data structures, inheritance, templates, etc., to prototype hardware designs rapidly. However, exploring various design space parameters can take much time and effort for hardware engineers to meet specific design specifications. This paper proposes a novel framework called AutoHLS, which integrates a deep neural network (DNN) with Bayesian optimization (BO) to accelerate HLS hardware design optimization. Our tool focuses on HLS pragma exploration and operation transformation. It utilizes integrated DNNs to predict synthesizability within a given FPGA resource budget. We also investigate the potential of emerging quantum neural networks (QNNs) instead of classical DNNs for the AutoHLS pipeline. Our experimental results demonstrate up to a 70-fold speedup in exploration time.
FAGH: Accelerating Federated Learning with Approximated Global Hessian
Mar 16, 2024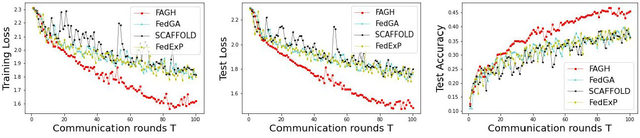
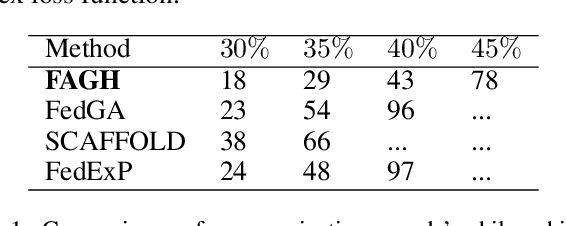
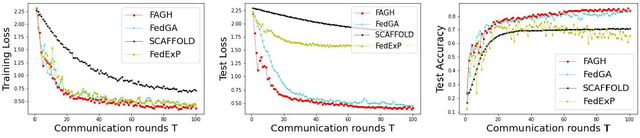

In federated learning (FL), the significant communication overhead due to the slow convergence speed of training the global model poses a great challenge. Specifically, a large number of communication rounds are required to achieve the convergence in FL. One potential solution is to employ the Newton-based optimization method for training, known for its quadratic convergence rate. However, the existing Newton-based FL training methods suffer from either memory inefficiency or high computational costs for local clients or the server. To address this issue, we propose an FL with approximated global Hessian (FAGH) method to accelerate FL training. FAGH leverages the first moment of the approximated global Hessian and the first moment of the global gradient to train the global model. By harnessing the approximated global Hessian curvature, FAGH accelerates the convergence of global model training, leading to the reduced number of communication rounds and thus the shortened training time. Experimental results verify FAGH's effectiveness in decreasing the number of communication rounds and the time required to achieve the pre-specified objectives of the global model performance in terms of training and test losses as well as test accuracy. Notably, FAGH outperforms several state-of-the-art FL training methods.
FL-GUARD: A Holistic Framework for Run-Time Detection and Recovery of Negative Federated Learning
Mar 07, 2024Federated learning (FL) is a promising approach for learning a model from data distributed on massive clients without exposing data privacy. It works effectively in the ideal federation where clients share homogeneous data distribution and learning behavior. However, FL may fail to function appropriately when the federation is not ideal, amid an unhealthy state called Negative Federated Learning (NFL), in which most clients gain no benefit from participating in FL. Many studies have tried to address NFL. However, their solutions either (1) predetermine to prevent NFL in the entire learning life-cycle or (2) tackle NFL in the aftermath of numerous learning rounds. Thus, they either (1) indiscriminately incur extra costs even if FL can perform well without such costs or (2) waste numerous learning rounds. Additionally, none of the previous work takes into account the clients who may be unwilling/unable to follow the proposed NFL solutions when using those solutions to upgrade an FL system in use. This paper introduces FL-GUARD, a holistic framework that can be employed on any FL system for tackling NFL in a run-time paradigm. That is, to dynamically detect NFL at the early stage (tens of rounds) of learning and then to activate recovery measures when necessary. Specifically, we devise a cost-effective NFL detection mechanism, which relies on an estimation of performance gain on clients. Only when NFL is detected, we activate the NFL recovery process, in which each client learns in parallel an adapted model when training the global model. Extensive experiment results confirm the effectiveness of FL-GUARD in detecting NFL and recovering from NFL to a healthy learning state. We also show that FL-GUARD is compatible with previous NFL solutions and robust against clients unwilling/unable to take any recovery measures.
Context-based Fast Recommendation Strategy for Long User Behavior Sequence in Meituan Waimai
Mar 19, 2024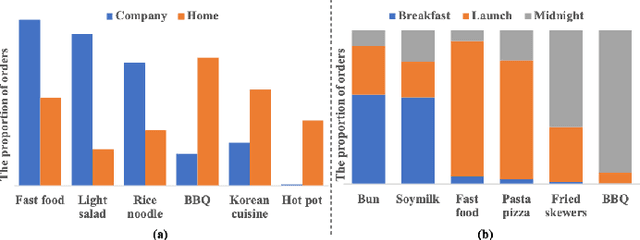
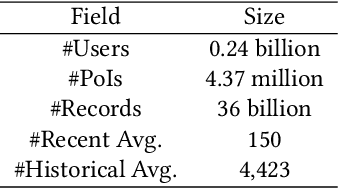
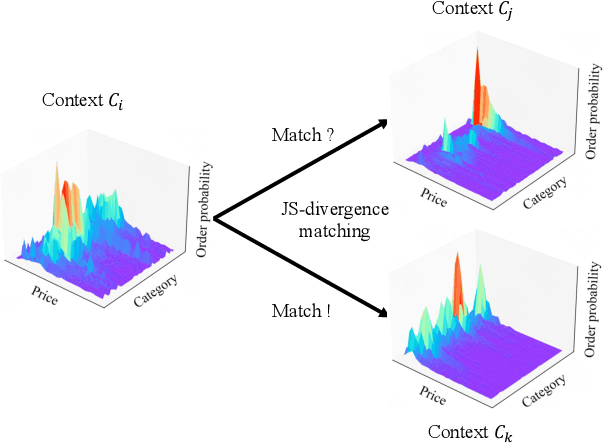
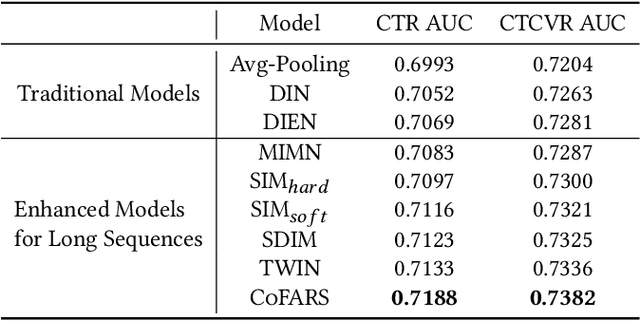
In the recommender system of Meituan Waimai, we are dealing with ever-lengthening user behavior sequences, which pose an increasing challenge to modeling user preference effectively. Existing sequential recommendation models often fail to capture long-term dependencies or are too complex, complicating the fulfillment of Meituan Waimai's unique business needs. To better model user interests, we consider selecting relevant sub-sequences from users' extensive historical behaviors based on their preferences. In this specific scenario, we've noticed that the contexts in which users interact have a significant impact on their preferences. For this purpose, we introduce a novel method called Context-based Fast Recommendation Strategy to tackle the issue of long sequences. We first identify contexts that share similar user preferences with the target context and then locate the corresponding PoIs based on these identified contexts. This approach eliminates the necessity to select a sub-sequence for every candidate PoI, thereby avoiding high time complexity. Specifically, we implement a prototype-based approach to pinpoint contexts that mirror similar user preferences. To amplify accuracy and interpretability, we employ JS divergence of PoI attributes such as categories and prices as a measure of similarity between contexts. A temporal graph integrating both prototype and context nodes helps incorporate temporal information. We then identify appropriate prototypes considering both target contexts and short-term user preferences. Following this, we utilize contexts aligned with these prototypes to generate a sub-sequence, aimed at predicting CTR and CTCVR scores with target attention. Since its inception in 2023, this strategy has been adopted in Meituan Waimai's display recommender system, leading to a 4.6% surge in CTR and a 4.2% boost in GMV.
Fast Personalized Text-to-Image Syntheses With Attention Injection
Mar 17, 2024
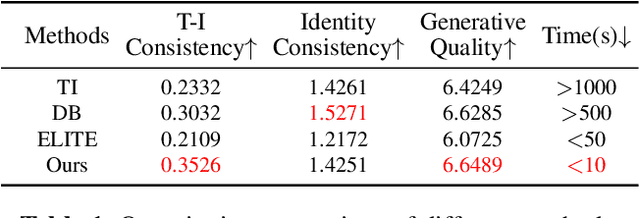
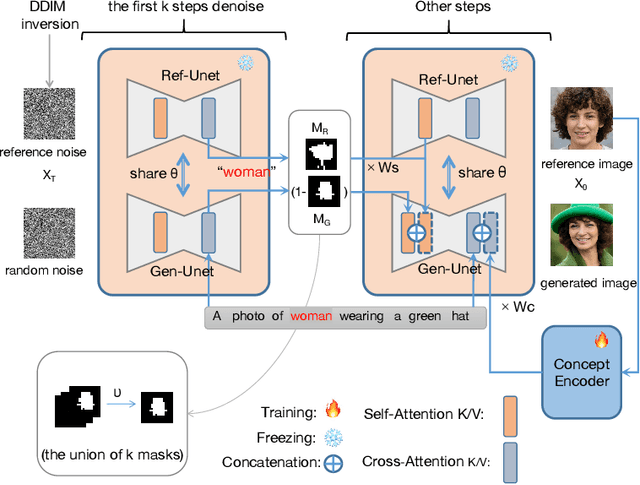
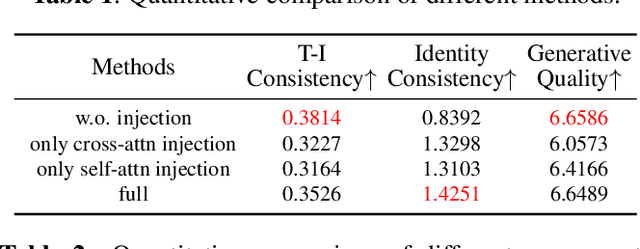
Currently, personalized image generation methods mostly require considerable time to finetune and often overfit the concept resulting in generated images that are similar to custom concepts but difficult to edit by prompts. We propose an effective and fast approach that could balance the text-image consistency and identity consistency of the generated image and reference image. Our method can generate personalized images without any fine-tuning while maintaining the inherent text-to-image generation ability of diffusion models. Given a prompt and a reference image, we merge the custom concept into generated images by manipulating cross-attention and self-attention layers of the original diffusion model to generate personalized images that match the text description. Comprehensive experiments highlight the superiority of our method.
MKF-ADS: Multi-Knowledge Fusion Based Self-supervised Anomaly Detection System for Control Area Network
Mar 15, 2024
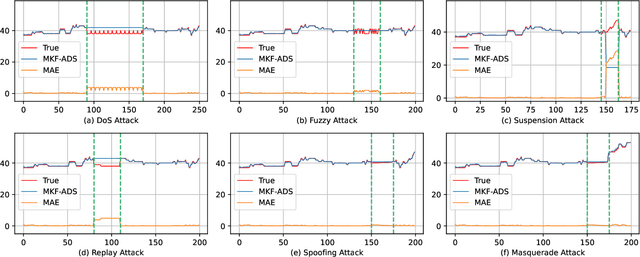
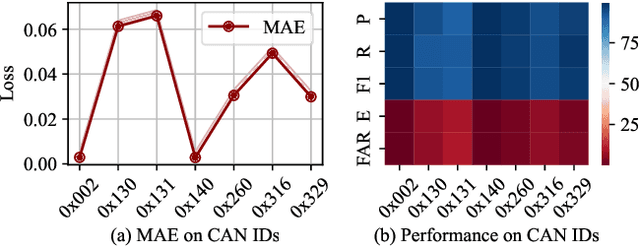
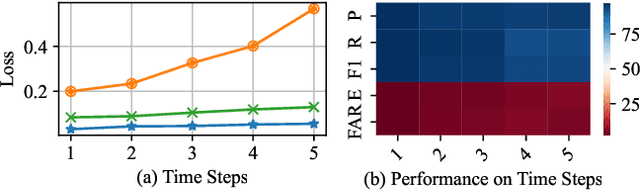
Control Area Network (CAN) is an essential communication protocol that interacts between Electronic Control Units (ECUs) in the vehicular network. However, CAN is facing stringent security challenges due to innate security risks. Intrusion detection systems (IDSs) are a crucial safety component in remediating Vehicular Electronics and Systems vulnerabilities. However, existing IDSs fail to identify complexity attacks and have higher false alarms owing to capability bottleneck. In this paper, we propose a self-supervised multi-knowledge fused anomaly detection model, called MKF-ADS. Specifically, the method designs an integration framework, including spatial-temporal correlation with an attention mechanism (STcAM) module and patch sparse-transformer module (PatchST). The STcAM with fine-pruning uses one-dimensional convolution (Conv1D) to extract spatial features and subsequently utilizes the Bidirectional Long Short Term Memory (Bi-LSTM) to extract the temporal features, where the attention mechanism will focus on the important time steps. Meanwhile, the PatchST captures the combined contextual features from independent univariate time series. Finally, the proposed method is based on knowledge distillation to STcAM as a student model for learning intrinsic knowledge and cross the ability to mimic PatchST. We conduct extensive experiments on six simulation attack scenarios across various CAN IDs and time steps, and two real attack scenarios, which present a competitive prediction and detection performance. Compared with the baseline in the same paradigm, the error rate and FAR are 2.62\% and 2.41\% and achieve a promising F1-score of 97.3\%.
Semantic-Enhanced Representation Learning for Road Networks with Temporal Dynamics
Mar 18, 2024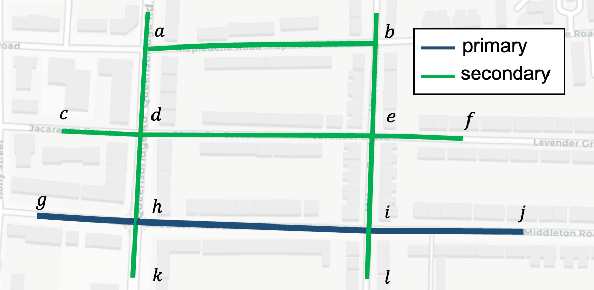
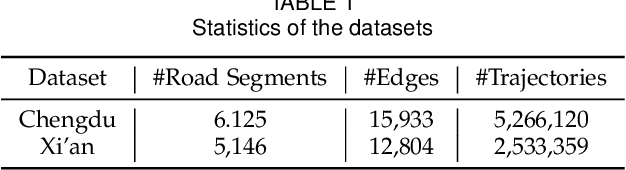
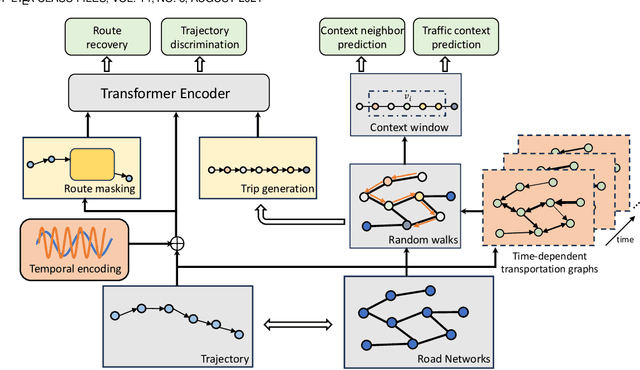
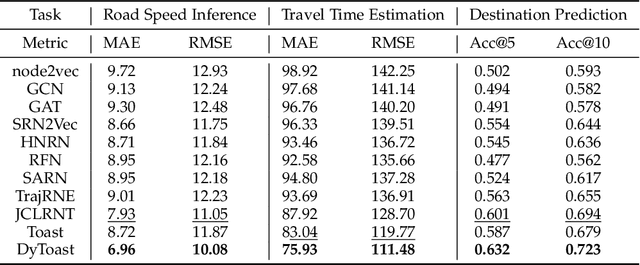
In this study, we introduce a novel framework called Toast for learning general-purpose representations of road networks, along with its advanced counterpart DyToast, designed to enhance the integration of temporal dynamics to boost the performance of various time-sensitive downstream tasks. Specifically, we propose to encode two pivotal semantic characteristics intrinsic to road networks: traffic patterns and traveling semantics. To achieve this, we refine the skip-gram module by incorporating auxiliary objectives aimed at predicting the traffic context associated with a target road segment. Moreover, we leverage trajectory data and design pre-training strategies based on Transformer to distill traveling semantics on road networks. DyToast further augments this framework by employing unified trigonometric functions characterized by their beneficial properties, enabling the capture of temporal evolution and dynamic nature of road networks more effectively. With these proposed techniques, we can obtain representations that encode multi-faceted aspects of knowledge within road networks, applicable across both road segment-based applications and trajectory-based applications. Extensive experiments on two real-world datasets across three tasks demonstrate that our proposed framework consistently outperforms the state-of-the-art baselines by a significant margin.
TrajectoryNAS: A Neural Architecture Search for Trajectory Prediction
Mar 18, 2024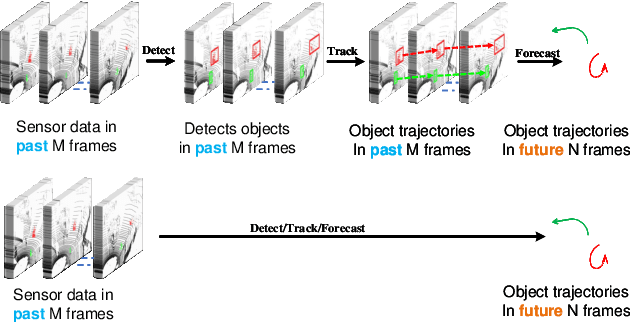
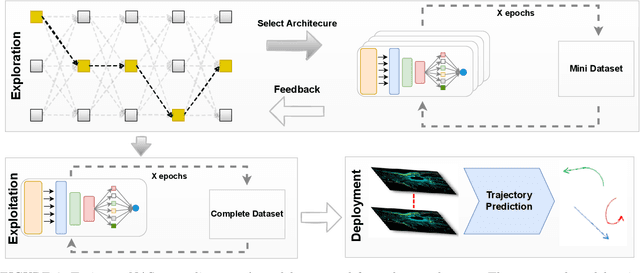

Autonomous driving systems are a rapidly evolving technology that enables driverless car production. Trajectory prediction is a critical component of autonomous driving systems, enabling cars to anticipate the movements of surrounding objects for safe navigation. Trajectory prediction using Lidar point-cloud data performs better than 2D images due to providing 3D information. However, processing point-cloud data is more complicated and time-consuming than 2D images. Hence, state-of-the-art 3D trajectory predictions using point-cloud data suffer from slow and erroneous predictions. This paper introduces TrajectoryNAS, a pioneering method that focuses on utilizing point cloud data for trajectory prediction. By leveraging Neural Architecture Search (NAS), TrajectoryNAS automates the design of trajectory prediction models, encompassing object detection, tracking, and forecasting in a cohesive manner. This approach not only addresses the complex interdependencies among these tasks but also emphasizes the importance of accuracy and efficiency in trajectory modeling. Through empirical studies, TrajectoryNAS demonstrates its effectiveness in enhancing the performance of autonomous driving systems, marking a significant advancement in the field.Experimental results reveal that TrajcetoryNAS yield a minimum of 4.8 higger accuracy and 1.1* lower latency over competing methods on the NuScenes dataset.
Motion and temporal B0 shift corrections for quantitative susceptibility mapping (QSM) and R2* mapping using dual-echo spiral navigators and conjugate-phase reconstruction
Mar 18, 2024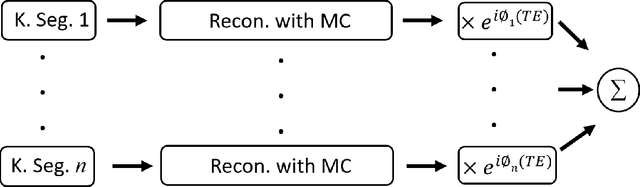
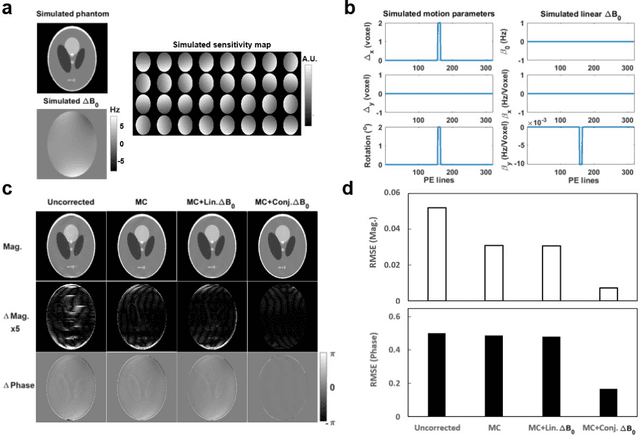
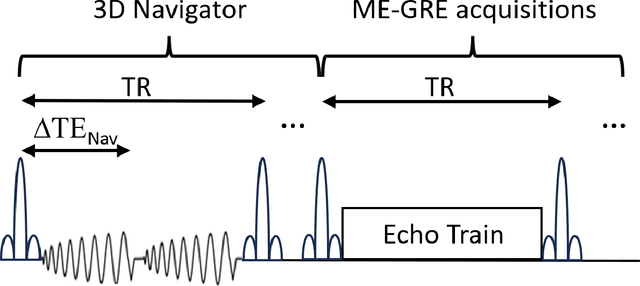
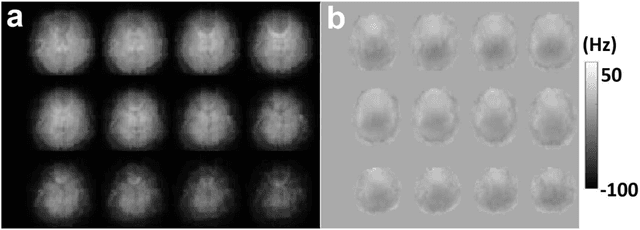
Purpose: To develop an efficient navigator-based motion and temporal B0 shift correction technique for 3D multi-echo gradient-echo (ME-GRE) MRI for quantitative susceptibility mapping (QSM) and R2* mapping. Theory and Methods: A dual-echo 3D spiral navigator was designed to interleave with the Cartesian ME-GRE acquisitions, allowing the acquisition of both low- and high-echo time signals. We additionally designed a novel conjugate-phase based reconstruction method for the joint correction of motion and temporal B0 shifts. We performed both numerical simulation and in vivo human scans to assess the performance of the methods. Results: Numerical simulation and human brain scans demonstrated that the proposed technique successfully corrected artifacts induced by both head motions and temporal B0 changes. Efficient B0-change correction with conjugate-phase reconstruction can be performed on less than 10 clustered k-space segments. In vivo scans showed that combining temporal B0 correction with motion correction further reduced artifacts and improved image quality in both R2* and QSM images. Conclusion: Our proposed approach of using 3D spiral navigators and a novel conjugate-phase reconstruction method can improve susceptibility-related measurements using MR.