 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Representation Learning on Hyper-Relational and Numeric Knowledge Graphs with Transformers
Jun 01, 2023
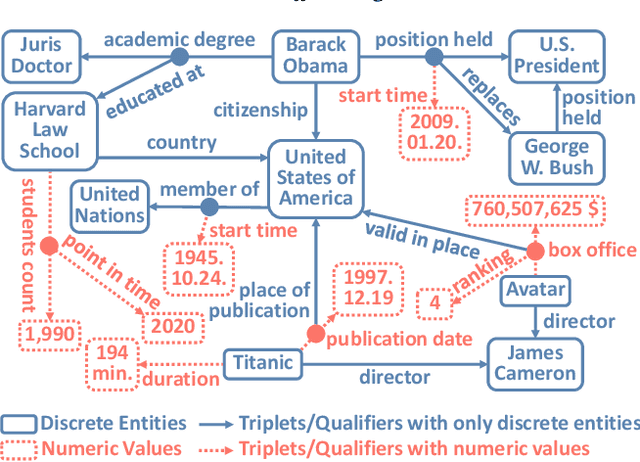
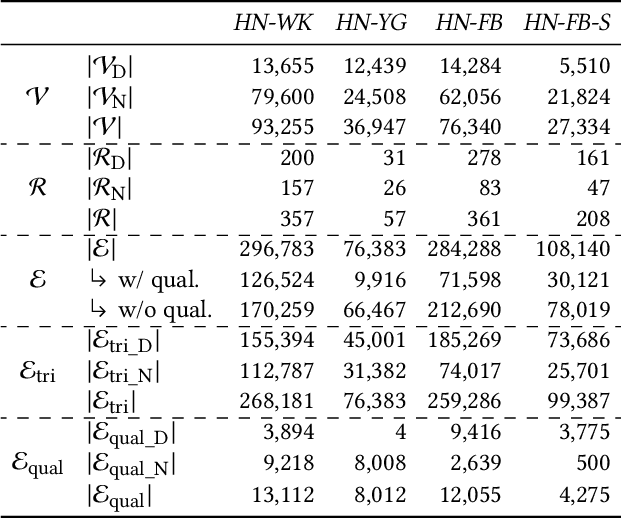
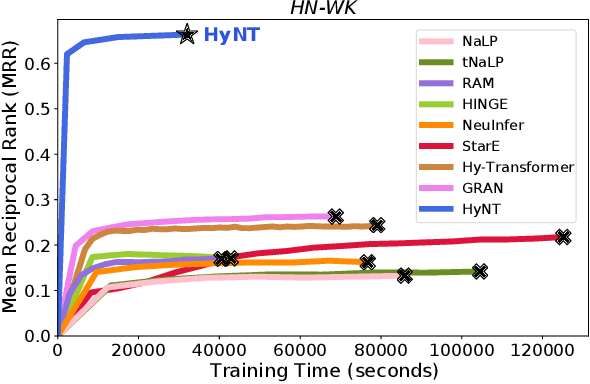
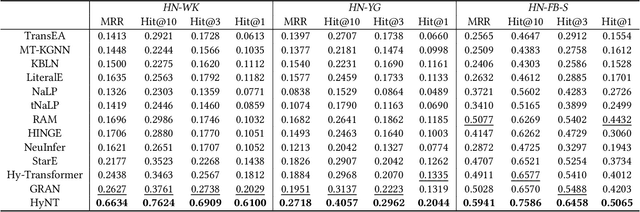
A hyper-relational knowledge graph has been recently studied where a triplet is associated with a set of qualifiers; a qualifier is composed of a relation and an entity, providing auxiliary information for a triplet. While existing hyper-relational knowledge graph embedding methods assume that the entities are discrete objects, some information should be represented using numeric values, e.g., (J.R.R., was born in, 1892). Also, a triplet (J.R.R., educated at, Oxford Univ.) can be associated with a qualifier such as (start time, 1911). In this paper, we propose a unified framework named HyNT that learns representations of a hyper-relational knowledge graph containing numeric literals in either triplets or qualifiers. We define a context transformer and a prediction transformer to learn the representations based not only on the correlations between a triplet and its qualifiers but also on the numeric information. By learning compact representations of triplets and qualifiers and feeding them into the transformers, we reduce the computation cost of using transformers. Using HyNT, we can predict missing numeric values in addition to missing entities or relations in a hyper-relational knowledge graph. Experimental results show that HyNT significantly outperforms state-of-the-art methods on real-world datasets.
Low-Light Image Enhancement with Wavelet-based Diffusion Models
Jun 01, 2023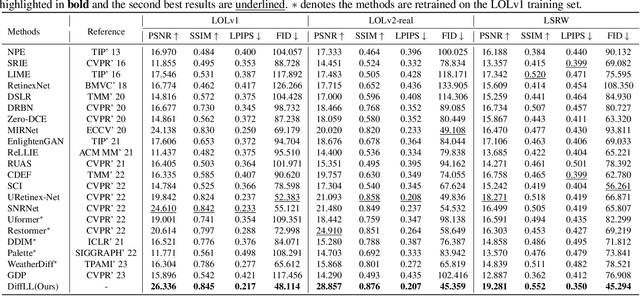
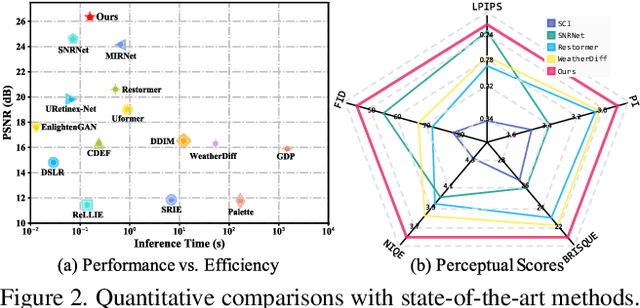
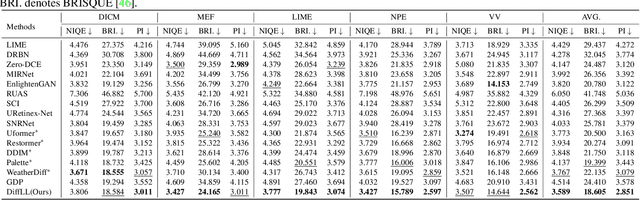
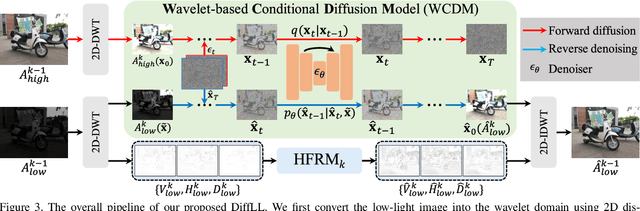
Diffusion models have achieved promising results in image restoration tasks, yet suffer from time-consuming, excessive computational resource consumption, and unstable restoration. To address these issues, we propose a robust and efficient Diffusion-based Low-Light image enhancement approach, dubbed DiffLL. Specifically, we present a wavelet-based conditional diffusion model (WCDM) that leverages the generative power of diffusion models to produce results with satisfactory perceptual fidelity. Additionally, it also takes advantage of the strengths of wavelet transformation to greatly accelerate inference and reduce computational resource usage without sacrificing information. To avoid chaotic content and diversity, we perform both forward diffusion and reverse denoising in the training phase of WCDM, enabling the model to achieve stable denoising and reduce randomness during inference. Moreover, we further design a high-frequency restoration module (HFRM) that utilizes the vertical and horizontal details of the image to complement the diagonal information for better fine-grained restoration. Extensive experiments on publicly available real-world benchmarks demonstrate that our method outperforms the existing state-of-the-art methods both quantitatively and visually, and it achieves remarkable improvements in efficiency compared to previous diffusion-based methods. In addition, we empirically show that the application for low-light face detection also reveals the latent practical values of our method.
Adversarial-Aware Deep Learning System based on a Secondary Classical Machine Learning Verification Approach
Jun 01, 2023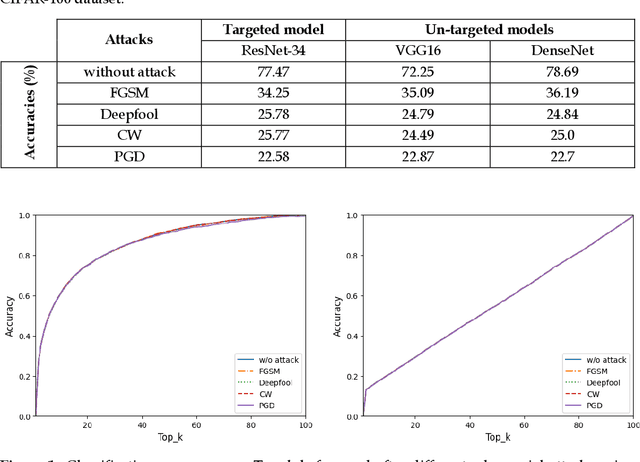
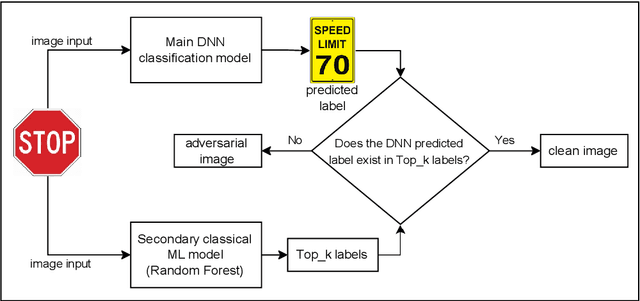

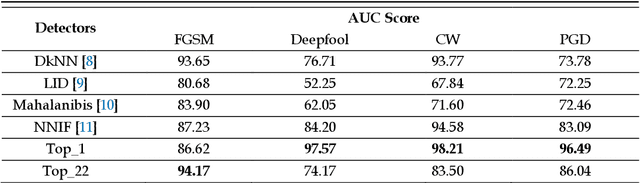
Deep learning models have been used in creating various effective image classification applications. However, they are vulnerable to adversarial attacks that seek to misguide the models into predicting incorrect classes. Our study of major adversarial attack models shows that they all specifically target and exploit the neural networking structures in their designs. This understanding makes us develop a hypothesis that most classical machine learning models, such as Random Forest (RF), are immune to adversarial attack models because they do not rely on neural network design at all. Our experimental study of classical machine learning models against popular adversarial attacks supports this hypothesis. Based on this hypothesis, we propose a new adversarial-aware deep learning system by using a classical machine learning model as the secondary verification system to complement the primary deep learning model in image classification. Although the secondary classical machine learning model has less accurate output, it is only used for verification purposes, which does not impact the output accuracy of the primary deep learning model, and at the same time, can effectively detect an adversarial attack when a clear mismatch occurs. Our experiments based on CIFAR-100 dataset show that our proposed approach outperforms current state-of-the-art adversarial defense systems.
(Almost) Provable Error Bounds Under Distribution Shift via Disagreement Discrepancy
Jun 01, 2023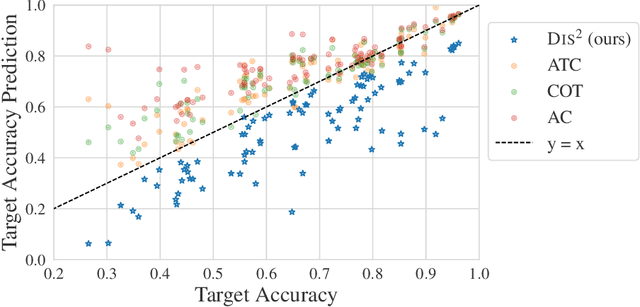
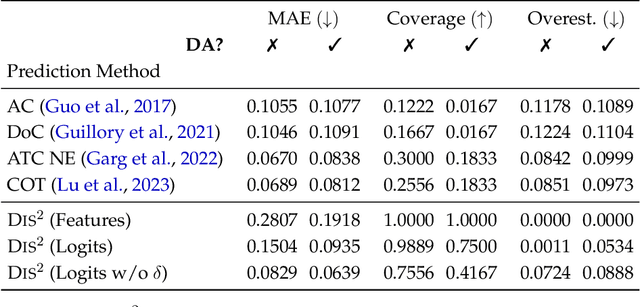
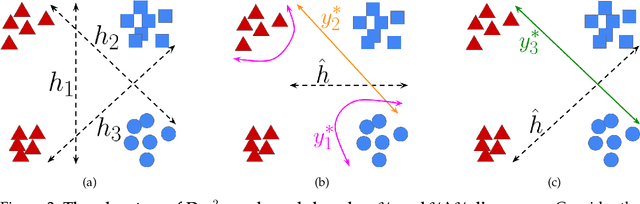
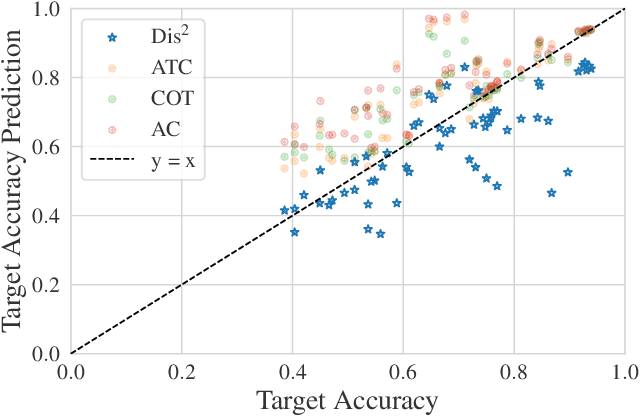
We derive an (almost) guaranteed upper bound on the error of deep neural networks under distribution shift using unlabeled test data. Prior methods either give bounds that are vacuous in practice or give estimates that are accurate on average but heavily underestimate error for a sizeable fraction of shifts. In particular, the latter only give guarantees based on complex continuous measures such as test calibration -- which cannot be identified without labels -- and are therefore unreliable. Instead, our bound requires a simple, intuitive condition which is well justified by prior empirical works and holds in practice effectively 100% of the time. The bound is inspired by $\mathcal{H}\Delta\mathcal{H}$-divergence but is easier to evaluate and substantially tighter, consistently providing non-vacuous guarantees. Estimating the bound requires optimizing one multiclass classifier to disagree with another, for which some prior works have used sub-optimal proxy losses; we devise a "disagreement loss" which is theoretically justified and performs better in practice. We expect this loss can serve as a drop-in replacement for future methods which require maximizing multiclass disagreement. Across a wide range of benchmarks, our method gives valid error bounds while achieving average accuracy comparable to competitive estimation baselines. Code is publicly available at https://github.com/erosenfeld/disagree_discrep .
Attribute-Efficient PAC Learning of Low-Degree Polynomial Threshold Functions with Nasty Noise
Jun 01, 2023The concept class of low-degree polynomial threshold functions (PTFs) plays a fundamental role in machine learning. In this paper, we study PAC learning of $K$-sparse degree-$d$ PTFs on $\mathbb{R}^n$, where any such concept depends only on $K$ out of $n$ attributes of the input. Our main contribution is a new algorithm that runs in time $({nd}/{\epsilon})^{O(d)}$ and under the Gaussian marginal distribution, PAC learns the class up to error rate $\epsilon$ with $O(\frac{K^{4d}}{\epsilon^{2d}} \cdot \log^{5d} n)$ samples even when an $\eta \leq O(\epsilon^d)$ fraction of them are corrupted by the nasty noise of Bshouty et al. (2002), possibly the strongest corruption model. Prior to this work, attribute-efficient robust algorithms are established only for the special case of sparse homogeneous halfspaces. Our key ingredients are: 1) a structural result that translates the attribute sparsity to a sparsity pattern of the Chow vector under the basis of Hermite polynomials, and 2) a novel attribute-efficient robust Chow vector estimation algorithm which uses exclusively a restricted Frobenius norm to either certify a good approximation or to validate a sparsity-induced degree-$2d$ polynomial as a filter to detect corrupted samples.
Autism Disease Detection Using Transfer Learning Techniques: Performance Comparison Between Central Processing Unit vs Graphics Processing Unit Functions for Neural Networks
Jun 01, 2023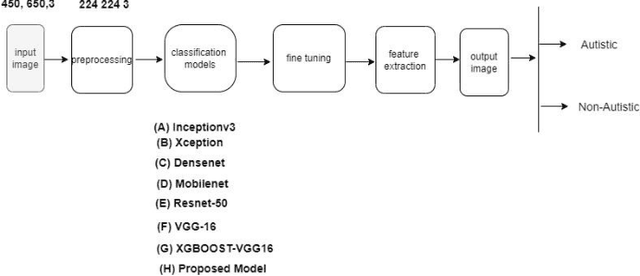

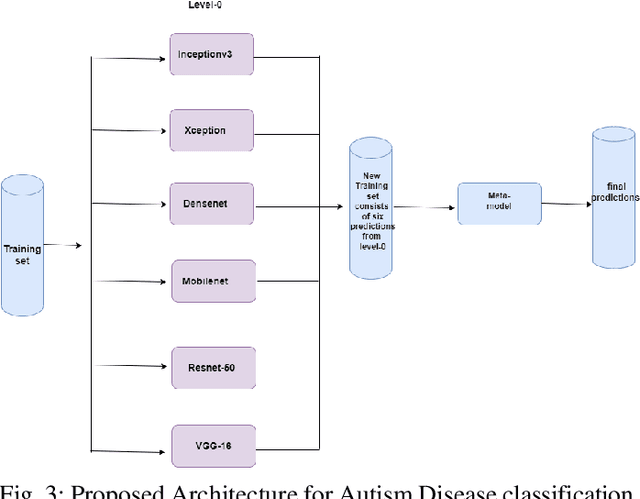
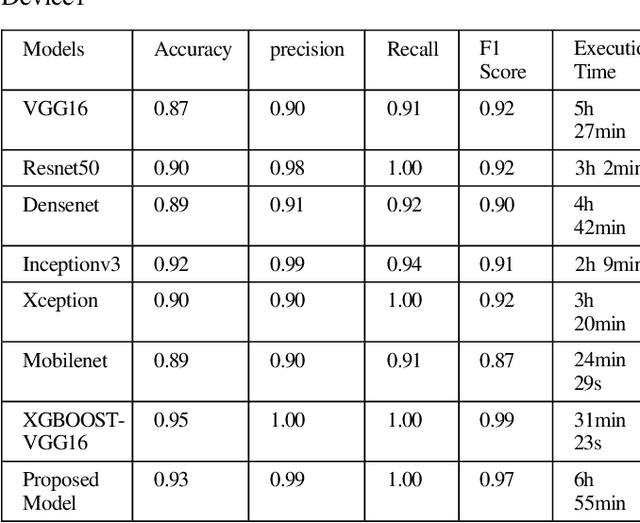
Neural network approaches are machine learning methods that are widely used in various domains, such as healthcare and cybersecurity. Neural networks are especially renowned for their ability to deal with image datasets. During the training process with images, various fundamental mathematical operations are performed in the neural network. These operations include several algebraic and mathematical functions, such as derivatives, convolutions, and matrix inversions and transpositions. Such operations demand higher processing power than what is typically required for regular computer usage. Since CPUs are built with serial processing, they are not appropriate for handling large image datasets. On the other hand, GPUs have parallel processing capabilities and can provide higher speed. This paper utilizes advanced neural network techniques, such as VGG16, Resnet50, Densenet, Inceptionv3, Xception, Mobilenet, XGBOOST VGG16, and our proposed models, to compare CPU and GPU resources. We implemented a system for classifying Autism disease using face images of autistic and non-autistic children to compare performance during testing. We used evaluation matrices such as Accuracy, F1 score, Precision, Recall, and Execution time. It was observed that GPU outperformed CPU in all tests conducted. Moreover, the performance of the neural network models in terms of accuracy increased on GPU compared to CPU.
Hawkes Process Based on Controlled Differential Equations
May 18, 2023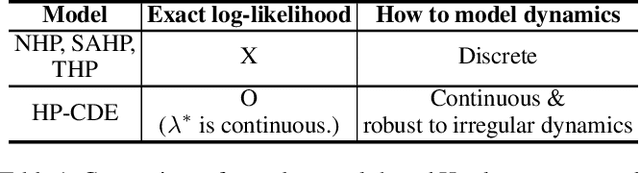
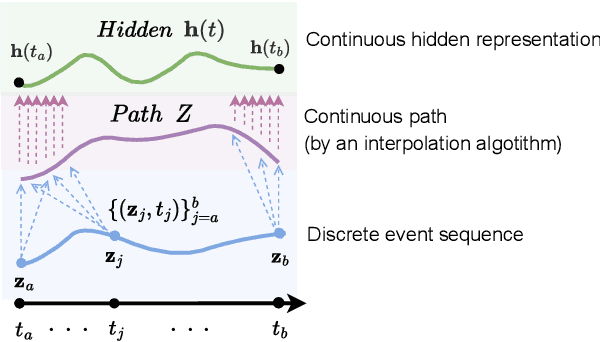
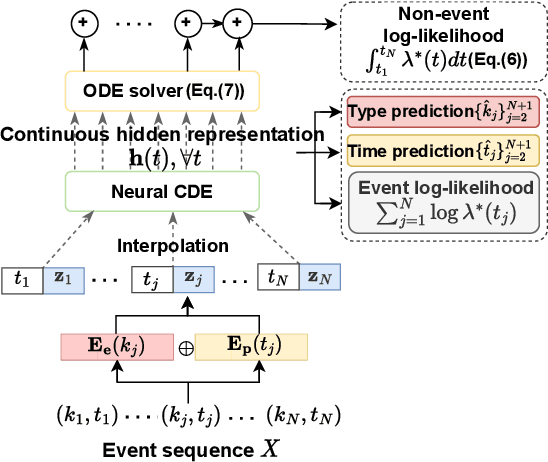
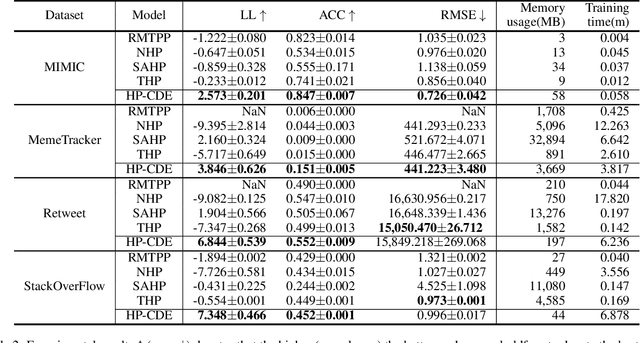
Hawkes processes are a popular framework to model the occurrence of sequential events, i.e., occurrence dynamics, in several fields such as social diffusion. In real-world scenarios, the inter-arrival time among events is irregular. However, existing neural network-based Hawkes process models not only i) fail to capture such complicated irregular dynamics, but also ii) resort to heuristics to calculate the log-likelihood of events since they are mostly based on neural networks designed for regular discrete inputs. To this end, we present the concept of Hawkes process based on controlled differential equations (HP-CDE), by adopting the neural controlled differential equation (neural CDE) technology which is an analogue to continuous RNNs. Since HP-CDE continuously reads data, i) irregular time-series datasets can be properly treated preserving their uneven temporal spaces, and ii) the log-likelihood can be exactly computed. Moreover, as both Hawkes processes and neural CDEs are first developed to model complicated human behavioral dynamics, neural CDE-based Hawkes processes are successful in modeling such occurrence dynamics. In our experiments with 4 real-world datasets, our method outperforms existing methods by non-trivial margins.
MM Algorithms to Estimate Parameters in Continuous-time Markov Chains
Feb 16, 2023
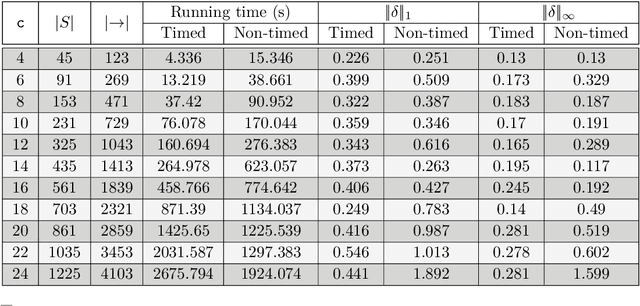


Continuous-time Markov chains (CTMCs) are popular modeling formalism that constitutes the underlying semantics for real-time probabilistic systems such as queuing networks, stochastic process algebras, and calculi for systems biology. Prism and Storm are popular model checking tools that provide a number of powerful analysis techniques for CTMCs. These tools accept models expressed as the parallel composition of a number of modules interacting with each other. The outcome of the analysis is strongly dependent on the parameter values used in the model which govern the timing and probability of events of the resulting CTMC. However, for some applications, parameter values have to be empirically estimated from partially-observable executions. In this work, we address the problem of estimating parameter values of CTMCs expressed as Prism models from a number of partially-observable executions. We introduce the class parametric CTMCs -- CTMCs where transition rates are polynomial functions over a set of parameters -- as an abstraction of CTMCs covering a large class of Prism models. Then, building on a theory of algorithms known by the initials MM, for minorization-maximization, we present iterative maximum likelihood estimation algorithms for parametric CTMCs covering two learning scenarios: when both state-labels and dwell times are observable, or just state-labels are. We conclude by illustrating the use of our technique in a simple but non-trivial case study: the analysis of the spread of COVID-19 in presence of lockdown countermeasures.
Efficient Multi-Grained Knowledge Reuse for Class Incremental Segmentation
Jun 03, 2023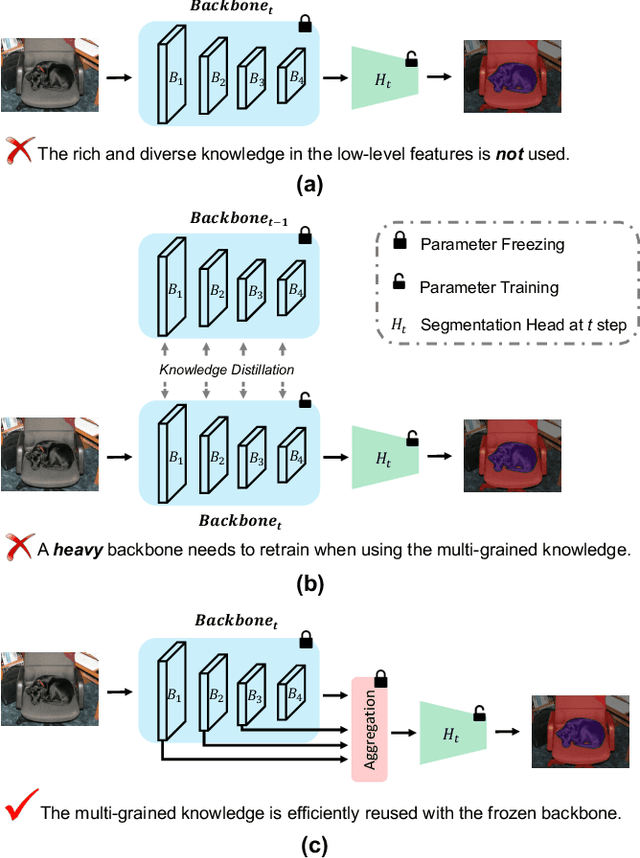

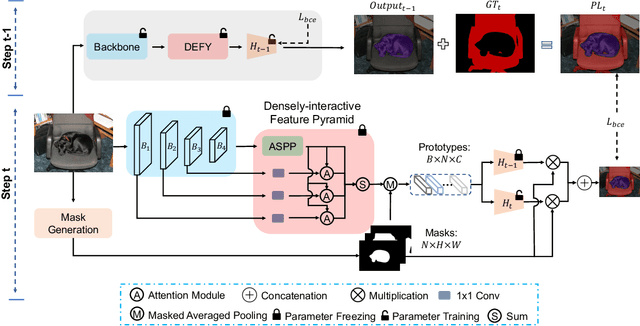

Class Incremental Semantic Segmentation (CISS) has been a trend recently due to its great significance in real-world applications. Although the existing CISS methods demonstrate remarkable performance, they either leverage the high-level knowledge (feature) only while neglecting the rich and diverse knowledge in the low-level features, leading to poor old knowledge preservation and weak new knowledge exploration; or use multi-level features for knowledge distillation by retraining a heavy backbone, which is computationally intensive. In this paper, we for the first time propose to efficiently reuse the multi-grained knowledge for CISS by fusing multi-level features with the frozen backbone and show a simple aggregation of varying-level features, i.e., naive feature pyramid, can boost the performance significantly. We further introduce a novel densely-interactive feature pyramid (DEFY) module that enhances the fusion of high- and low-level features by enabling their dense interaction. Specifically, DEFY establishes a per-pixel relationship between pairs of feature maps, allowing for multi-pair outputs to be aggregated. This results in improved semantic segmentation by leveraging the complementary information from multi-level features. We show that DEFY can be effortlessly integrated into three representative methods for performance enhancement. Our method yields a new state-of-the-art performance when combined with the current SOTA by notably averaged mIoU gains on two widely used benchmarks, i.e., 2.5% on PASCAL VOC 2012 and 2.3% on ADE20K.
Relieving Triplet Ambiguity: Consensus Network for Language-Guided Image Retrieval
Jun 03, 2023
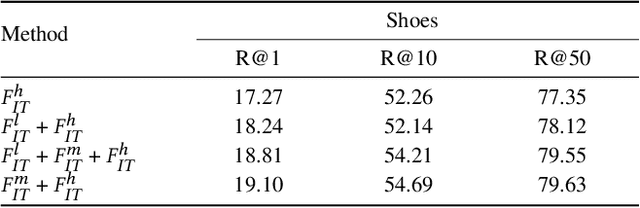
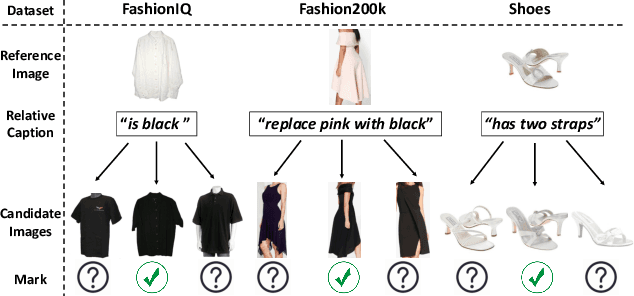

Language-guided image retrieval enables users to search for images and interact with the retrieval system more naturally and expressively by using a reference image and a relative caption as a query. Most existing studies mainly focus on designing image-text composition architecture to extract discriminative visual-linguistic relations. Despite great success, we identify an inherent problem that obstructs the extraction of discriminative features and considerably compromises model training: \textbf{triplet ambiguity}. This problem stems from the annotation process wherein annotators view only one triplet at a time. As a result, they often describe simple attributes, such as color, while neglecting fine-grained details like location and style. This leads to multiple false-negative candidates matching the same modification text. We propose a novel Consensus Network (Css-Net) that self-adaptively learns from noisy triplets to minimize the negative effects of triplet ambiguity. Inspired by the psychological finding that groups perform better than individuals, Css-Net comprises 1) a consensus module featuring four distinct compositors that generate diverse fused image-text embeddings and 2) a Kullback-Leibler divergence loss, which fosters learning among the compositors, enabling them to reduce biases learned from noisy triplets and reach a consensus. The decisions from four compositors are weighted during evaluation to further achieve consensus. Comprehensive experiments on three datasets demonstrate that Css-Net can alleviate triplet ambiguity, achieving competitive performance on benchmarks, such as $+2.77\%$ R@10 and $+6.67\%$ R@50 on FashionIQ.