 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Importance attribution in neural networks by means of persistence landscapes of time series
Feb 06, 2023
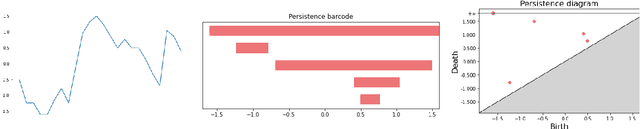
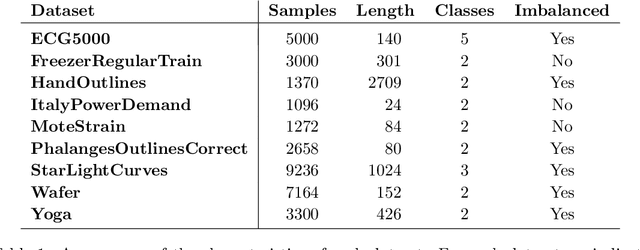

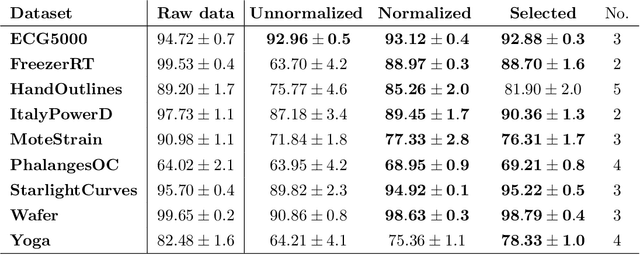
We propose and implement a method to analyze time series with a neural network using a matrix of area-normalized persistence landscapes obtained through topological data analysis. We include a gating layer in the network's architecture that is able to identify the most relevant landscape levels for the classification task, thus working as an importance attribution system. Next, we perform a matching between the selected landscape functions and the corresponding critical points of the original time series. From this matching we are able to reconstruct an approximate shape of the time series that gives insight into the classification decision. We test this technique with input data from a dataset of electrocardiographic signals.
Transactional Python for Durable Machine Learning: Vision, Challenges, and Feasibility
May 15, 2023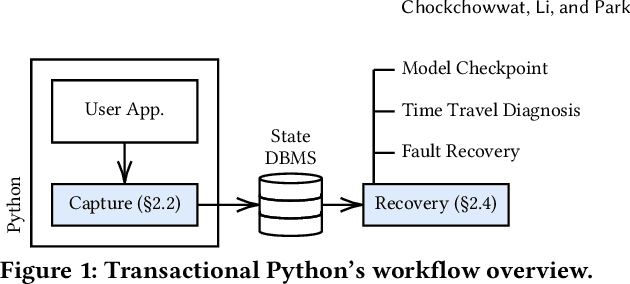
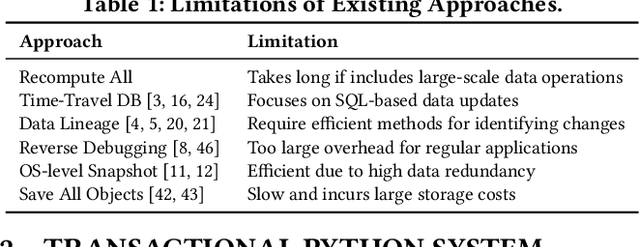
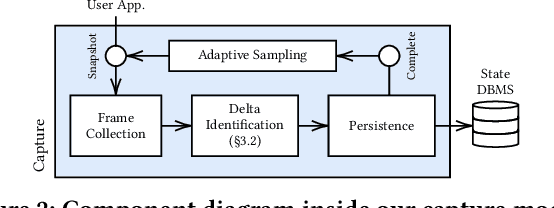
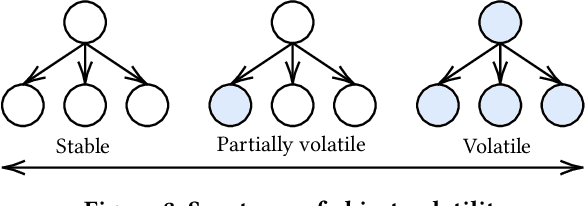
In machine learning (ML), Python serves as a convenient abstraction for working with key libraries such as PyTorch, scikit-learn, and others. Unlike DBMS, however, Python applications may lose important data, such as trained models and extracted features, due to machine failures or human errors, leading to a waste of time and resources. Specifically, they lack four essential properties that could make ML more reliable and user-friendly -- durability, atomicity, replicability, and time-versioning (DART). This paper presents our vision of Transactional Python that provides DART without any code modifications to user programs or the Python kernel, by non-intrusively monitoring application states at the object level and determining a minimal amount of information sufficient to reconstruct a whole application. Our evaluation of a proof-of-concept implementation with public PyTorch and scikit-learn applications shows that DART can be offered with overheads ranging 1.5%--15.6%.
Computation with Sequences in the Brain
Jun 06, 2023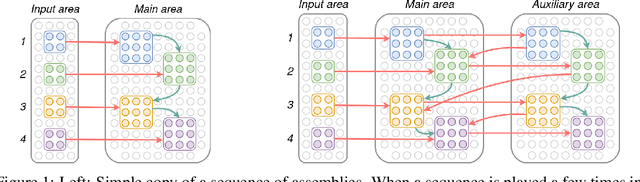
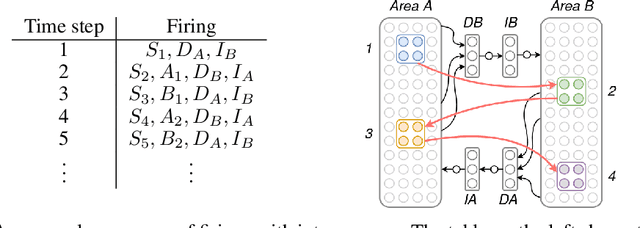
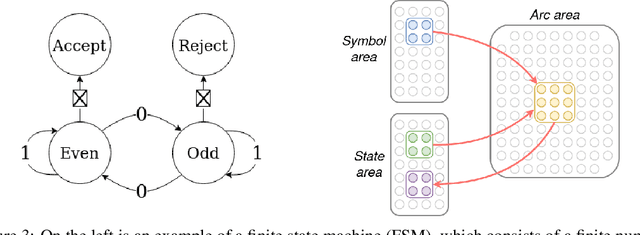
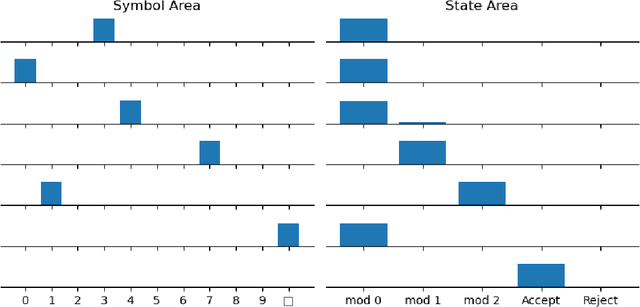
Even as machine learning exceeds human-level performance on many applications, the generality, robustness, and rapidity of the brain's learning capabilities remain unmatched. How cognition arises from neural activity is a central open question in neuroscience, inextricable from the study of intelligence itself. A simple formal model of neural activity was proposed in Papadimitriou [2020] and has been subsequently shown, through both mathematical proofs and simulations, to be capable of implementing certain simple cognitive operations via the creation and manipulation of assemblies of neurons. However, many intelligent behaviors rely on the ability to recognize, store, and manipulate temporal sequences of stimuli (planning, language, navigation, to list a few). Here we show that, in the same model, time can be captured naturally as precedence through synaptic weights and plasticity, and, as a result, a range of computations on sequences of assemblies can be carried out. In particular, repeated presentation of a sequence of stimuli leads to the memorization of the sequence through corresponding neural assemblies: upon future presentation of any stimulus in the sequence, the corresponding assembly and its subsequent ones will be activated, one after the other, until the end of the sequence. Finally, we show that any finite state machine can be learned in a similar way, through the presentation of appropriate patterns of sequences. Through an extension of this mechanism, the model can be shown to be capable of universal computation. We support our analysis with a number of experiments to probe the limits of learning in this model in key ways. Taken together, these results provide a concrete hypothesis for the basis of the brain's remarkable abilities to compute and learn, with sequences playing a vital role.
Streaming LifeLong Learning With Any-Time Inference
Jan 27, 2023
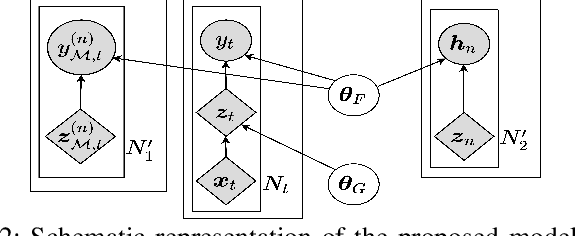
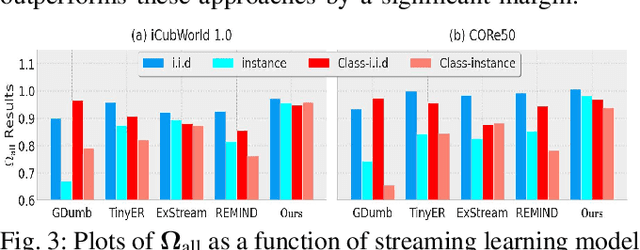

Despite rapid advancements in lifelong learning (LLL) research, a large body of research mainly focuses on improving the performance in the existing \textit{static} continual learning (CL) setups. These methods lack the ability to succeed in a rapidly changing \textit{dynamic} environment, where an AI agent needs to quickly learn new instances in a `single pass' from the non-i.i.d (also possibly temporally contiguous/coherent) data streams without suffering from catastrophic forgetting. For practical applicability, we propose a novel lifelong learning approach, which is streaming, i.e., a single input sample arrives in each time step, single pass, class-incremental, and subject to be evaluated at any moment. To address this challenging setup and various evaluation protocols, we propose a Bayesian framework, that enables fast parameter update, given a single training example, and enables any-time inference. We additionally propose an implicit regularizer in the form of snap-shot self-distillation, which effectively minimizes the forgetting further. We further propose an effective method that efficiently selects a subset of samples for online memory rehearsal and employs a new replay buffer management scheme that significantly boosts the overall performance. Our empirical evaluations and ablations demonstrate that the proposed method outperforms the prior works by large margins.
Efficient Diffusion Policies for Offline Reinforcement Learning
May 31, 2023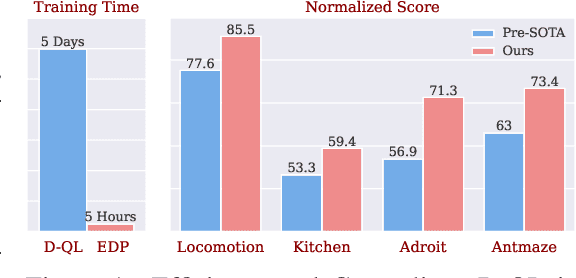
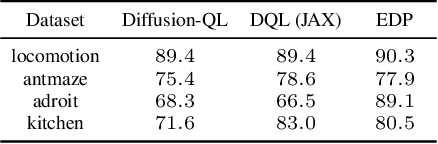
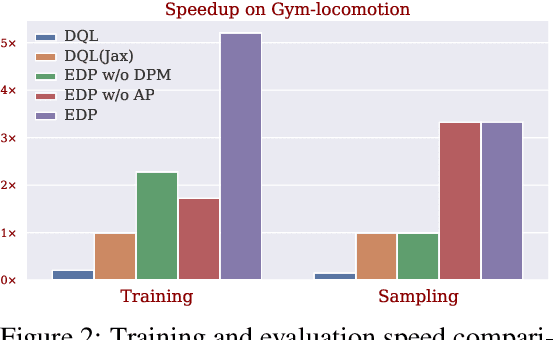
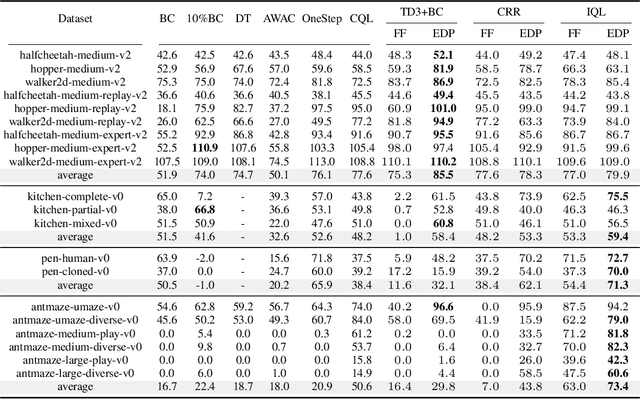
Offline reinforcement learning (RL) aims to learn optimal policies from offline datasets, where the parameterization of policies is crucial but often overlooked. Recently, Diffsuion-QL significantly boosts the performance of offline RL by representing a policy with a diffusion model, whose success relies on a parametrized Markov Chain with hundreds of steps for sampling. However, Diffusion-QL suffers from two critical limitations. 1) It is computationally inefficient to forward and backward through the whole Markov chain during training. 2) It is incompatible with maximum likelihood-based RL algorithms (e.g., policy gradient methods) as the likelihood of diffusion models is intractable. Therefore, we propose efficient diffusion policy (EDP) to overcome these two challenges. EDP approximately constructs actions from corrupted ones at training to avoid running the sampling chain. We conduct extensive experiments on the D4RL benchmark. The results show that EDP can reduce the diffusion policy training time from 5 days to 5 hours on gym-locomotion tasks. Moreover, we show that EDP is compatible with various offline RL algorithms (TD3, CRR, and IQL) and achieves new state-of-the-art on D4RL by large margins over previous methods. Our code is available at https://github.com/sail-sg/edp.
TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
May 31, 2023

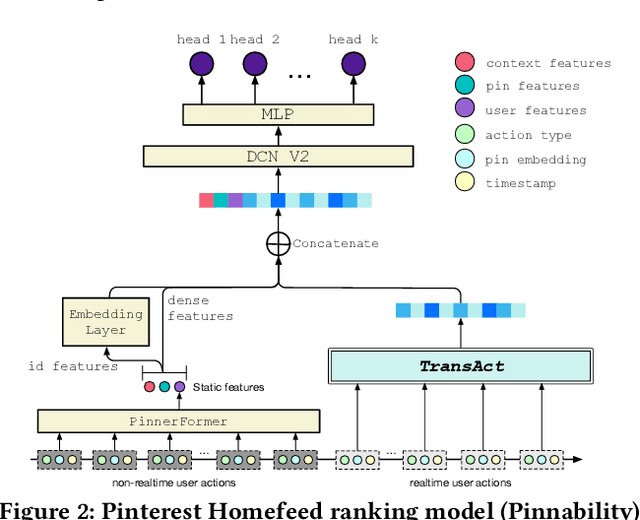

Sequential models that encode user activity for next action prediction have become a popular design choice for building web-scale personalized recommendation systems. Traditional methods of sequential recommendation either utilize end-to-end learning on realtime user actions, or learn user representations separately in an offline batch-generated manner. This paper (1) presents Pinterest's ranking architecture for Homefeed, our personalized recommendation product and the largest engagement surface; (2) proposes TransAct, a sequential model that extracts users' short-term preferences from their realtime activities; (3) describes our hybrid approach to ranking, which combines end-to-end sequential modeling via TransAct with batch-generated user embeddings. The hybrid approach allows us to combine the advantages of responsiveness from learning directly on realtime user activity with the cost-effectiveness of batch user representations learned over a longer time period. We describe the results of ablation studies, the challenges we faced during productionization, and the outcome of an online A/B experiment, which validates the effectiveness of our hybrid ranking model. We further demonstrate the effectiveness of TransAct on other surfaces such as contextual recommendations and search. Our model has been deployed to production in Homefeed, Related Pins, Notifications, and Search at Pinterest.
AQE: Argument Quadruplet Extraction via a Quad-Tagging Augmented Generative Approach
May 31, 2023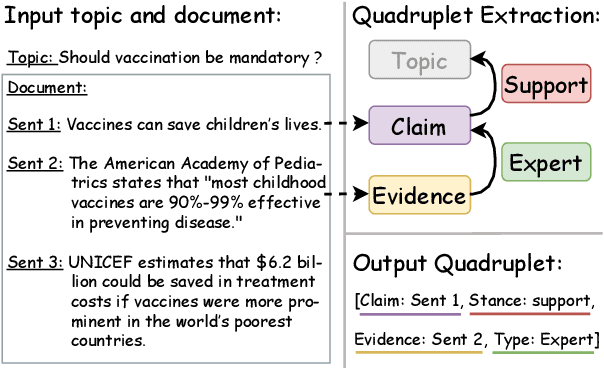
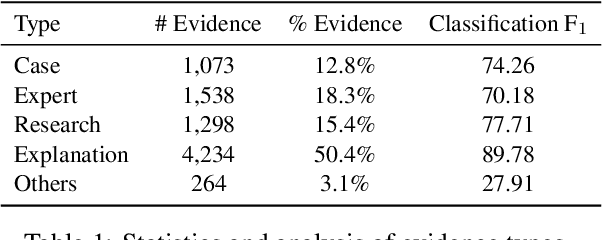
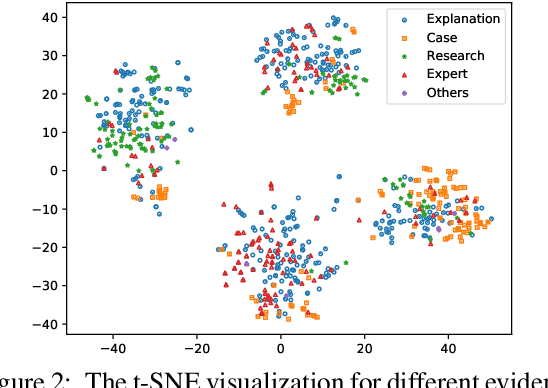
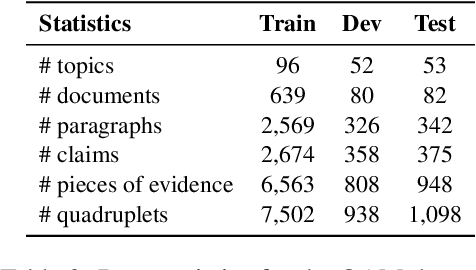
Argument mining involves multiple sub-tasks that automatically identify argumentative elements, such as claim detection, evidence extraction, stance classification, etc. However, each subtask alone is insufficient for a thorough understanding of the argumentative structure and reasoning process. To learn a complete view of an argument essay and capture the interdependence among argumentative components, we need to know what opinions people hold (i.e., claims), why those opinions are valid (i.e., supporting evidence), which source the evidence comes from (i.e., evidence type), and how those claims react to the debating topic (i.e., stance). In this work, we for the first time propose a challenging argument quadruplet extraction task (AQE), which can provide an all-in-one extraction of four argumentative components, i.e., claims, evidence, evidence types, and stances. To support this task, we construct a large-scale and challenging dataset. However, there is no existing method that can solve the argument quadruplet extraction. To fill this gap, we propose a novel quad-tagging augmented generative approach, which leverages a quadruplet tagging module to augment the training of the generative framework. The experimental results on our dataset demonstrate the empirical superiority of our proposed approach over several strong baselines.
ROSARL: Reward-Only Safe Reinforcement Learning
May 31, 2023
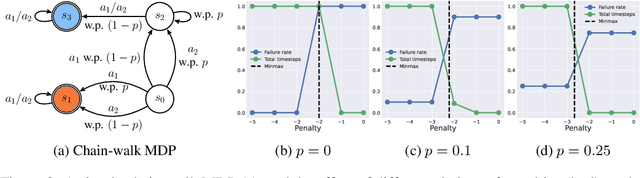
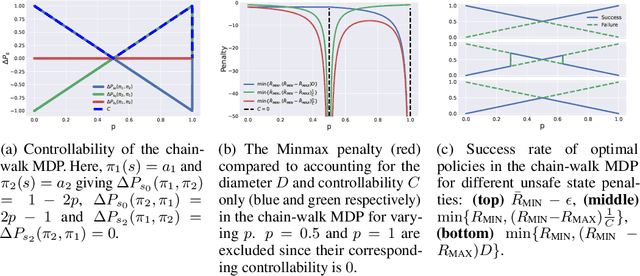

An important problem in reinforcement learning is designing agents that learn to solve tasks safely in an environment. A common solution is for a human expert to define either a penalty in the reward function or a cost to be minimised when reaching unsafe states. However, this is non-trivial, since too small a penalty may lead to agents that reach unsafe states, while too large a penalty increases the time to convergence. Additionally, the difficulty in designing reward or cost functions can increase with the complexity of the problem. Hence, for a given environment with a given set of unsafe states, we are interested in finding the upper bound of rewards at unsafe states whose optimal policies minimise the probability of reaching those unsafe states, irrespective of task rewards. We refer to this exact upper bound as the "Minmax penalty", and show that it can be obtained by taking into account both the controllability and diameter of an environment. We provide a simple practical model-free algorithm for an agent to learn this Minmax penalty while learning the task policy, and demonstrate that using it leads to agents that learn safe policies in high-dimensional continuous control environments.
Dynamic Graph Representation Learning for Depression Screening with Transformer
May 10, 2023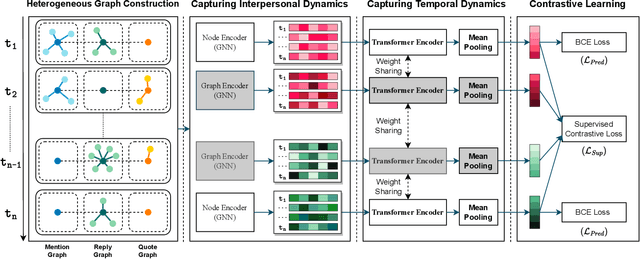

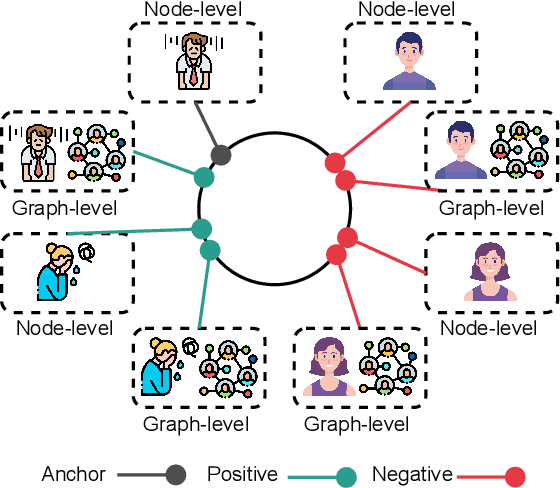

Early detection of mental disorder is crucial as it enables prompt intervention and treatment, which can greatly improve outcomes for individuals suffering from debilitating mental affliction. The recent proliferation of mental health discussions on social media platforms presents research opportunities to investigate mental health and potentially detect instances of mental illness. However, existing depression detection methods are constrained due to two major limitations: (1) the reliance on feature engineering and (2) the lack of consideration for time-varying factors. Specifically, these methods require extensive feature engineering and domain knowledge, which heavily rely on the amount, quality, and type of user-generated content. Moreover, these methods ignore the important impact of time-varying factors on depression detection, such as the dynamics of linguistic patterns and interpersonal interactive behaviors over time on social media (e.g., replies, mentions, and quote-tweets). To tackle these limitations, we propose an early depression detection framework, ContrastEgo treats each user as a dynamic time-evolving attributed graph (ego-network) and leverages supervised contrastive learning to maximize the agreement of users' representations at different scales while minimizing the agreement of users' representations to differentiate between depressed and control groups. ContrastEgo embraces four modules, (1) constructing users' heterogeneous interactive graphs, (2) extracting the representations of users' interaction snapshots using graph neural networks, (3) modeling the sequences of snapshots using attention mechanism, and (4) depression detection using contrastive learning. Extensive experiments on Twitter data demonstrate that ContrastEgo significantly outperforms the state-of-the-art methods in terms of all the effectiveness metrics in various experimental settings.
Hawkes Process Based on Controlled Differential Equations
May 18, 2023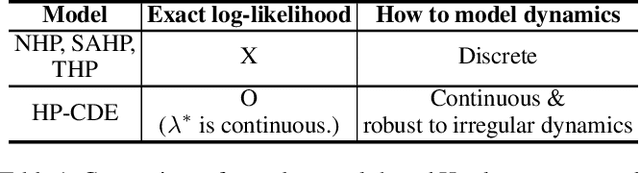
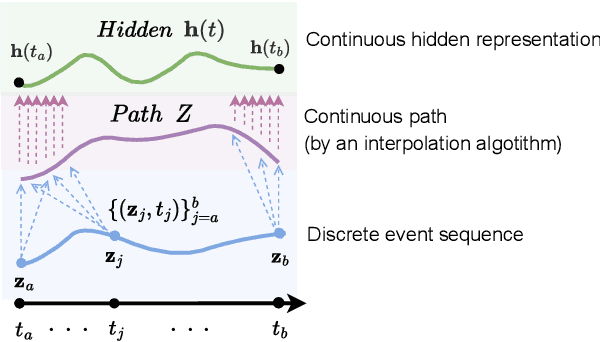
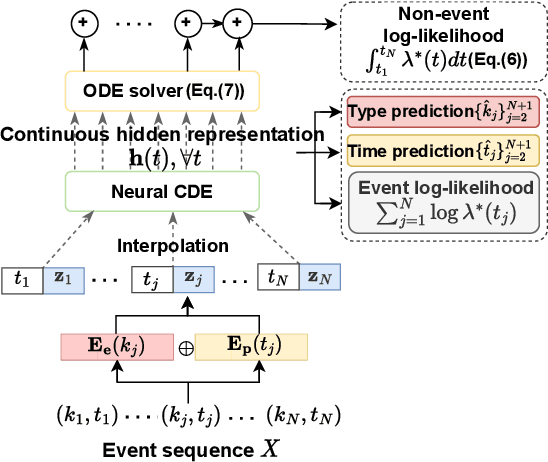
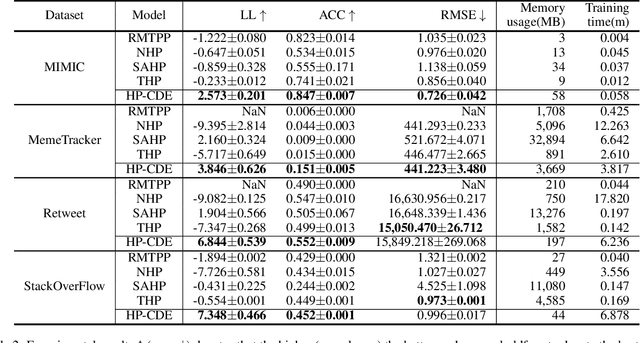
Hawkes processes are a popular framework to model the occurrence of sequential events, i.e., occurrence dynamics, in several fields such as social diffusion. In real-world scenarios, the inter-arrival time among events is irregular. However, existing neural network-based Hawkes process models not only i) fail to capture such complicated irregular dynamics, but also ii) resort to heuristics to calculate the log-likelihood of events since they are mostly based on neural networks designed for regular discrete inputs. To this end, we present the concept of Hawkes process based on controlled differential equations (HP-CDE), by adopting the neural controlled differential equation (neural CDE) technology which is an analogue to continuous RNNs. Since HP-CDE continuously reads data, i) irregular time-series datasets can be properly treated preserving their uneven temporal spaces, and ii) the log-likelihood can be exactly computed. Moreover, as both Hawkes processes and neural CDEs are first developed to model complicated human behavioral dynamics, neural CDE-based Hawkes processes are successful in modeling such occurrence dynamics. In our experiments with 4 real-world datasets, our method outperforms existing methods by non-trivial margins.