 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sit Back and Relax: Learning to Drive Incrementally in All Weather Conditions
May 30, 2023
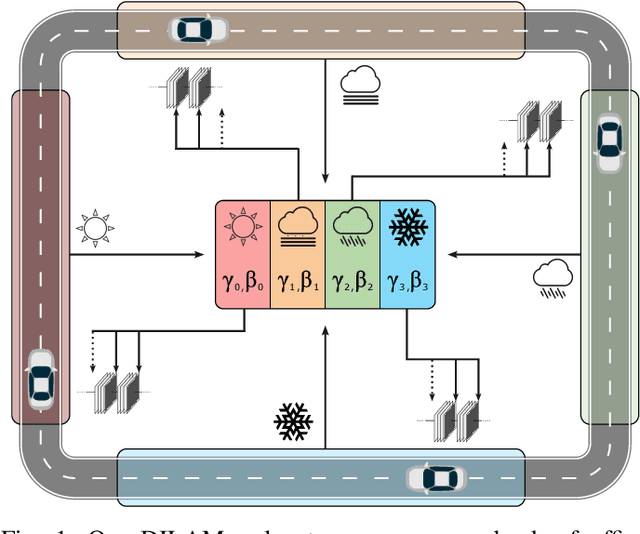
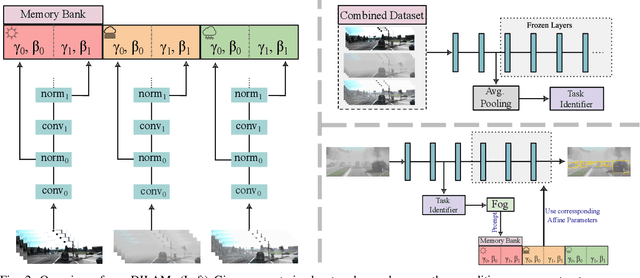
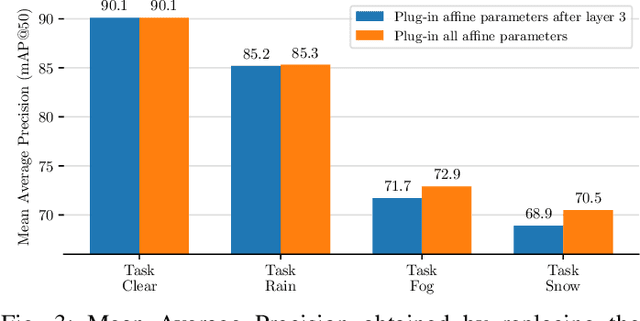
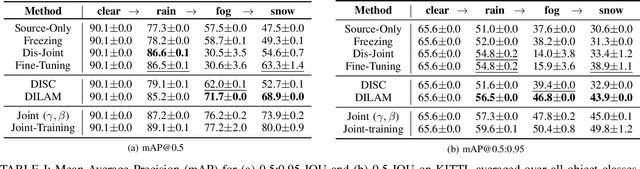
In autonomous driving scenarios, current object detection models show strong performance when tested in clear weather. However, their performance deteriorates significantly when tested in degrading weather conditions. In addition, even when adapted to perform robustly in a sequence of different weather conditions, they are often unable to perform well in all of them and suffer from catastrophic forgetting. To efficiently mitigate forgetting, we propose Domain-Incremental Learning through Activation Matching (DILAM), which employs unsupervised feature alignment to adapt only the affine parameters of a clear weather pre-trained network to different weather conditions. We propose to store these affine parameters as a memory bank for each weather condition and plug-in their weather-specific parameters during driving (i.e. test time) when the respective weather conditions are encountered. Our memory bank is extremely lightweight, since affine parameters account for less than 2% of a typical object detector. Furthermore, contrary to previous domain-incremental learning approaches, we do not require the weather label when testing and propose to automatically infer the weather condition by a majority voting linear classifier.
Prompt-based Tuning of Transformer Models for Multi-Center Medical Image Segmentation
May 30, 2023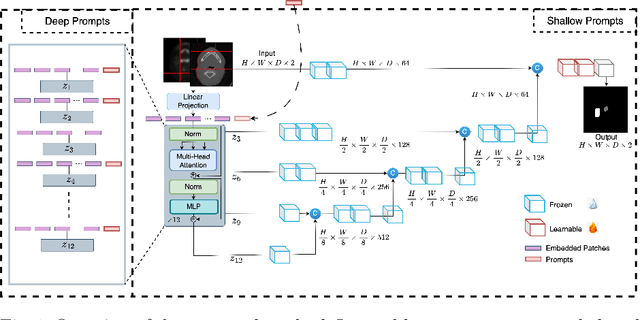

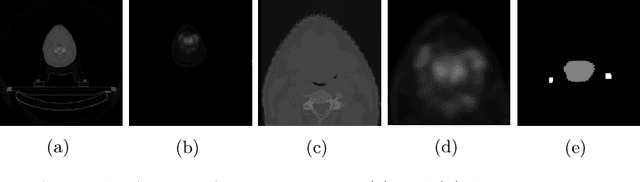
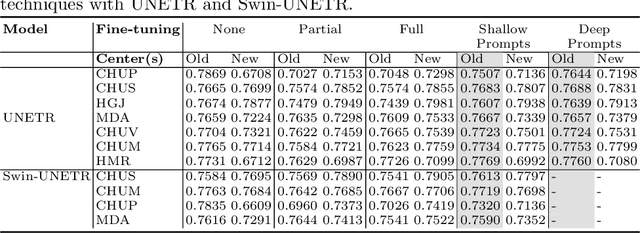
Medical image segmentation is a vital healthcare endeavor requiring precise and efficient models for appropriate diagnosis and treatment. Vision transformer-based segmentation models have shown great performance in accomplishing this task. However, to build a powerful backbone, the self-attention block of ViT requires large-scale pre-training data. The present method of modifying pre-trained models entails updating all or some of the backbone parameters. This paper proposes a novel fine-tuning strategy for adapting a pretrained transformer-based segmentation model on data from a new medical center. This method introduces a small number of learnable parameters, termed prompts, into the input space (less than 1\% of model parameters) while keeping the rest of the model parameters frozen. Extensive studies employing data from new unseen medical centers show that prompts-based fine-tuning of medical segmentation models provides excellent performance on the new center data with a negligible drop on the old centers. Additionally, our strategy delivers great accuracy with minimum re-training on new center data, significantly decreasing the computational and time costs of fine-tuning pre-trained models.
Understanding temporally weakly supervised training: A case study for keyword spotting
May 30, 2023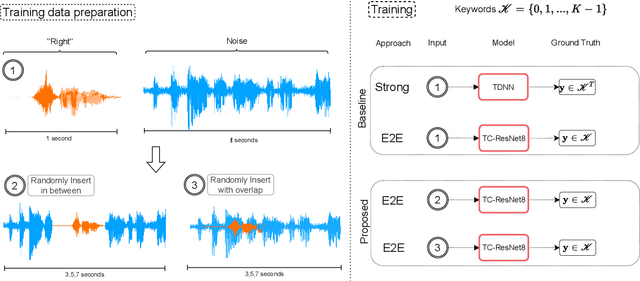

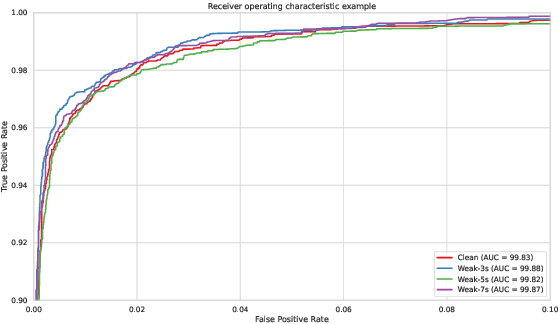
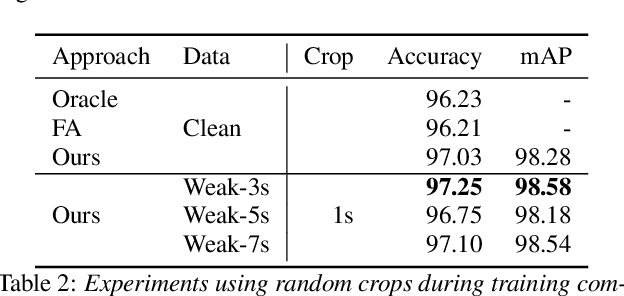
The currently most prominent algorithm to train keyword spotting (KWS) models with deep neural networks (DNNs) requires strong supervision i.e., precise knowledge of the spoken keyword location in time. Thus, most KWS approaches treat the presence of redundant data, such as noise, within their training set as an obstacle. A common training paradigm to deal with data redundancies is to use temporally weakly supervised learning, which only requires providing labels on a coarse scale. This study explores the limits of DNN training using temporally weak labeling with applications in KWS. We train a simple end-to-end classifier on the common Google Speech Commands dataset with increased difficulty by randomly appending and adding noise to the training dataset. Our results indicate that temporally weak labeling can achieve comparable results to strongly supervised baselines while having a less stringent labeling requirement. In the presence of noise, weakly supervised models are capable to localize and extract target keywords without explicit supervision, leading to a performance increase compared to strongly supervised approaches.
Competing for Shareable Arms in Multi-Player Multi-Armed Bandits
May 30, 2023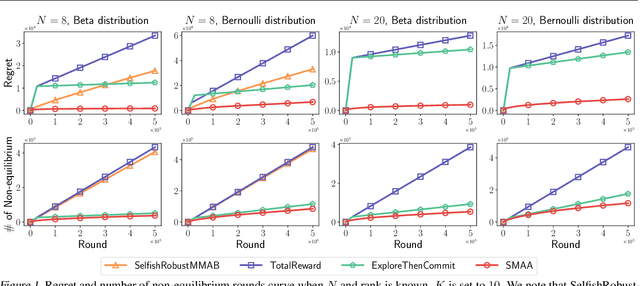
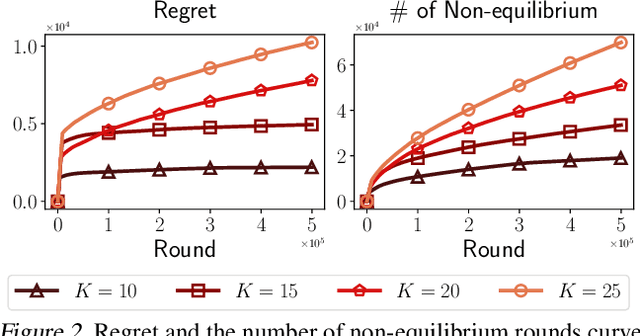
Competitions for shareable and limited resources have long been studied with strategic agents. In reality, agents often have to learn and maximize the rewards of the resources at the same time. To design an individualized competing policy, we model the competition between agents in a novel multi-player multi-armed bandit (MPMAB) setting where players are selfish and aim to maximize their own rewards. In addition, when several players pull the same arm, we assume that these players averagely share the arms' rewards by expectation. Under this setting, we first analyze the Nash equilibrium when arms' rewards are known. Subsequently, we propose a novel SelfishMPMAB with Averaging Allocation (SMAA) approach based on the equilibrium. We theoretically demonstrate that SMAA could achieve a good regret guarantee for each player when all players follow the algorithm. Additionally, we establish that no single selfish player can significantly increase their rewards through deviation, nor can they detrimentally affect other players' rewards without incurring substantial losses for themselves. We finally validate the effectiveness of the method in extensive synthetic experiments.
High-Gain Disturbance Observer for Robust Trajectory Tracking of Quadrotors
May 30, 2023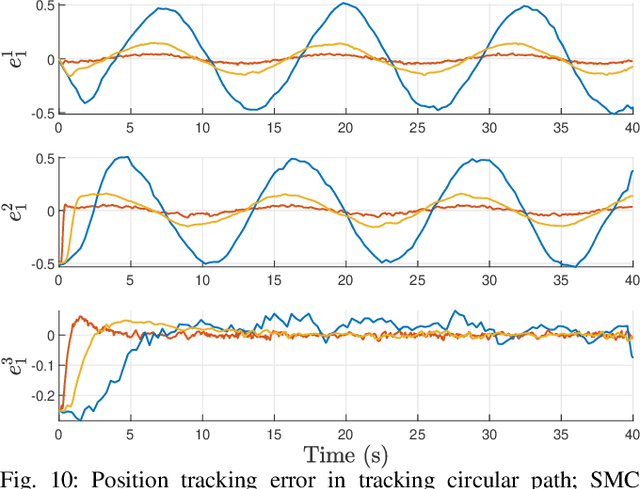
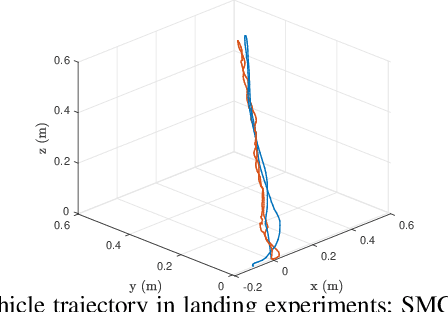
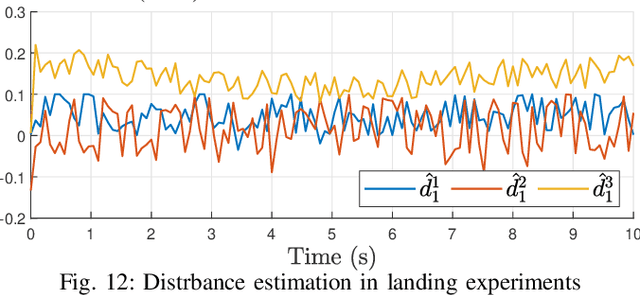
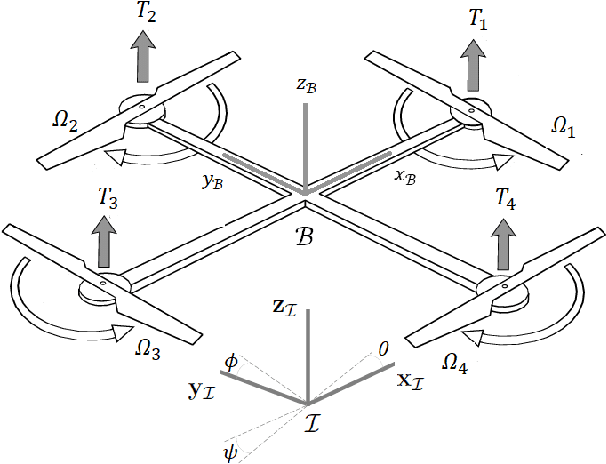
This paper presents a simple method to boost the robustness of quadrotors in trajectory tracking. The presented method features a high-gain disturbance observer (HGDO) that provides disturbance estimates in real-time. The estimates are then used in a trajectory control law to compensate for disturbance effects. We present theoretical convergence results showing that the proposed HGDO can quickly converge to an adjustable neighborhood of actual disturbance values. We will then integrate the disturbance estimates with a typical robust trajectory controller, namely sliding mode control (SMC), and present Lyapunov stability analysis to establish the boundedness of trajectory tracking errors. However, our stability analysis can be easily extended to other Lyapunov-based controllers to develop different HGDO-based controllers with formal stability guarantees. We evaluate the proposed HGDO-based control method using both simulation and laboratory experiments in various scenarios and in the presence of external disturbances. Our results indicate that the addition of HGDO to a quadrotor trajectory controller can significantly improve the accuracy and precision of trajectory tracking in the presence of external disturbances.
Prediction Error-based Classification for Class-Incremental Learning
May 30, 2023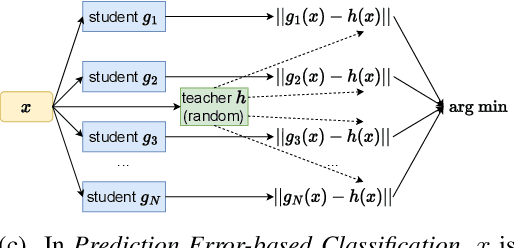
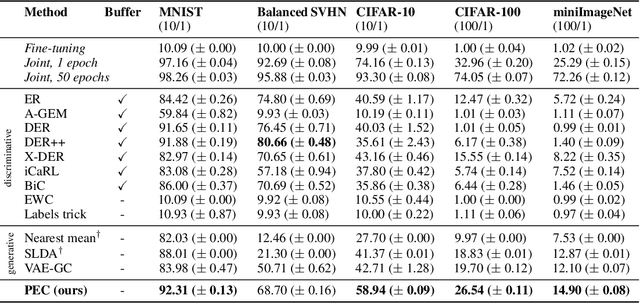
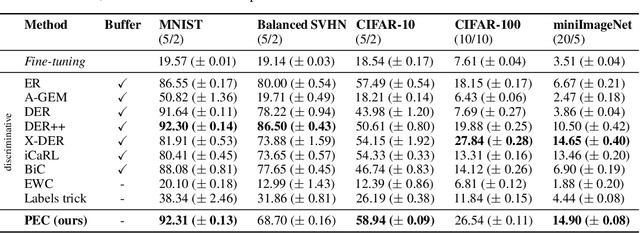
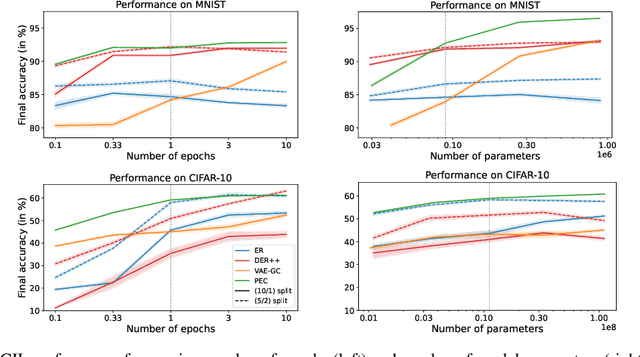
Class-incremental learning (CIL) is a particularly challenging variant of continual learning, where the goal is to learn to discriminate between all classes presented in an incremental fashion. Existing approaches often suffer from excessive forgetting and imbalance of the scores assigned to classes that have not been seen together during training. In this study, we introduce a novel approach, Prediction Error-based Classification (PEC), which differs from traditional discriminative and generative classification paradigms. PEC computes a class score by measuring the prediction error of a model trained to replicate the outputs of a frozen random neural network on data from that class. The method can be interpreted as approximating a classification rule based on Gaussian Process posterior variance. PEC offers several practical advantages, including sample efficiency, ease of tuning, and effectiveness even when data are presented one class at a time. Our empirical results show that PEC performs strongly in single-pass-through-data CIL, outperforming other rehearsal-free baselines in all cases and rehearsal-based methods with moderate replay buffer size in most cases across multiple benchmarks.
Generating synthetic multi-dimensional molecular-mediator time series data for artificial intelligence-based disease trajectory forecasting and drug development digital twins: Considerations
Mar 16, 2023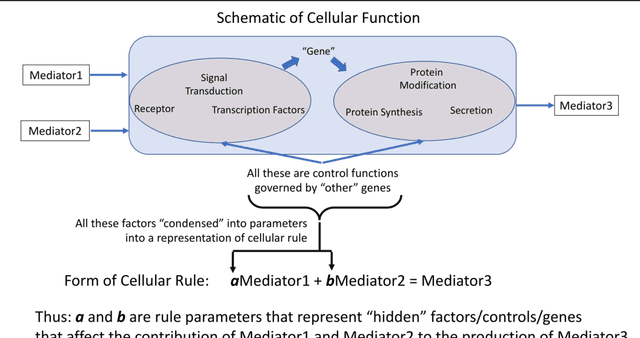
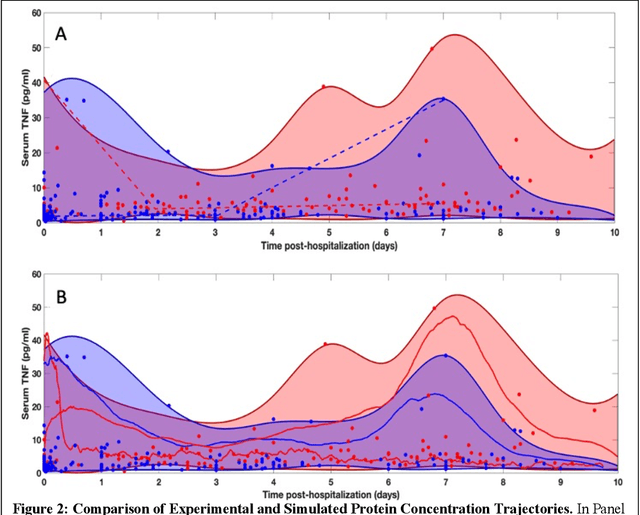
The use of synthetic data is recognized as a crucial step in the development of neural network-based Artificial Intelligence (AI) systems. While the methods for generating synthetic data for AI applications in other domains have a role in certain biomedical AI systems, primarily related to image processing, there is a critical gap in the generation of time series data for AI tasks where it is necessary to know how the system works. This is most pronounced in the ability to generate synthetic multi-dimensional molecular time series data (SMMTSD); this is the type of data that underpins research into biomarkers and mediator signatures for forecasting various diseases and is an essential component of the drug development pipeline. We argue the insufficiency of statistical and data-centric machine learning (ML) means of generating this type of synthetic data is due to a combination of factors: perpetual data sparsity due to the Curse of Dimensionality, the inapplicability of the Central Limit Theorem, and the limits imposed by the Causal Hierarchy Theorem. Alternatively, we present a rationale for using complex multi-scale mechanism-based simulation models, constructed and operated on to account for epistemic incompleteness and the need to provide maximal expansiveness in concordance with the Principle of Maximal Entropy. These procedures provide for the generation of SMMTD that minimizes the known shortcomings associated with neural network AI systems, namely overfitting and lack of generalizability. The generation of synthetic data that accounts for the identified factors of multi-dimensional time series data is an essential capability for the development of mediator-biomarker based AI forecasting systems, and therapeutic control development and optimization through systems like Drug Development Digital Twins.
Recovering Sparse and Interpretable Subgroups with Heterogeneous Treatment Effects with Censored Time-to-Event Outcomes
Feb 24, 2023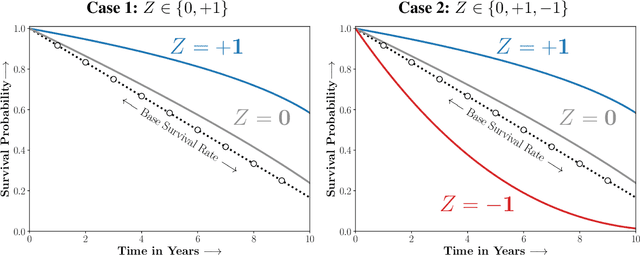
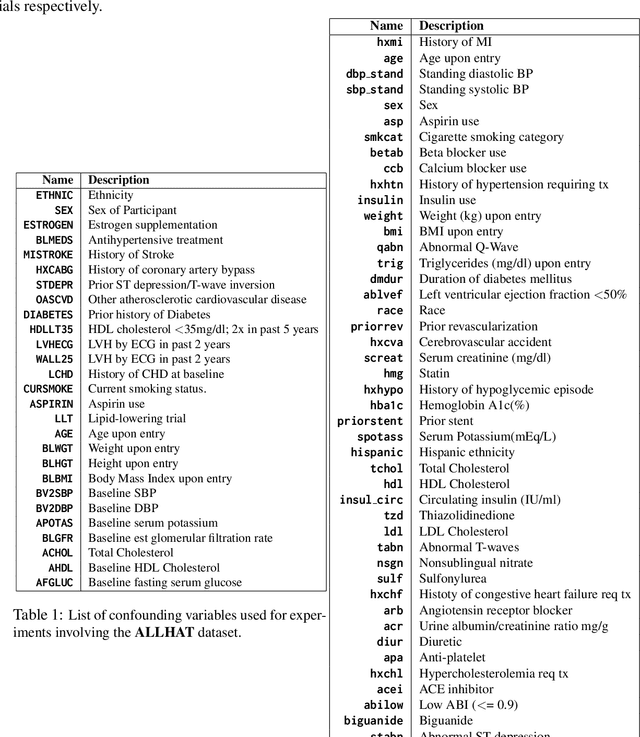
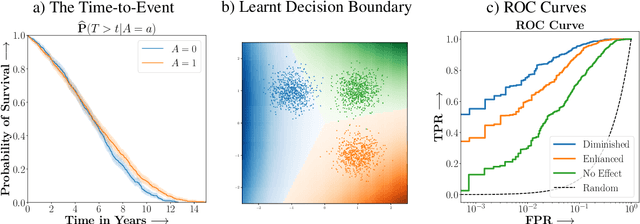
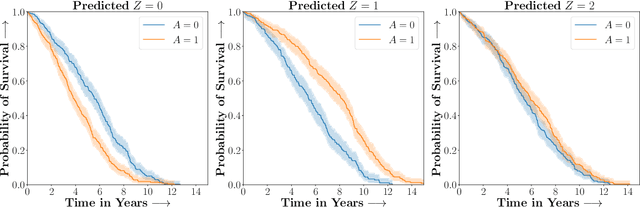
Studies involving both randomized experiments as well as observational data typically involve time-to-event outcomes such as time-to-failure, death or onset of an adverse condition. Such outcomes are typically subject to censoring due to loss of follow-up and established statistical practice involves comparing treatment efficacy in terms of hazard ratios between the treated and control groups. In this paper we propose a statistical approach to recovering sparse phenogroups (or subtypes) that demonstrate differential treatment effects as compared to the study population. Our approach involves modelling the data as a mixture while enforcing parameter shrinkage through structured sparsity regularization. We propose a novel inference procedure for the proposed model and demonstrate its efficacy in recovering sparse phenotypes across large landmark real world clinical studies in cardiovascular health.
Computation with Sequences in the Brain
Jun 06, 2023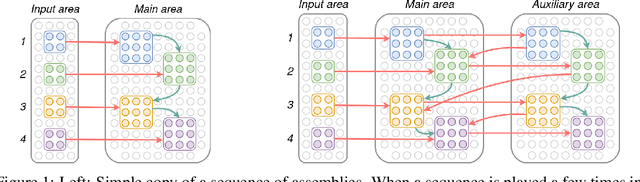
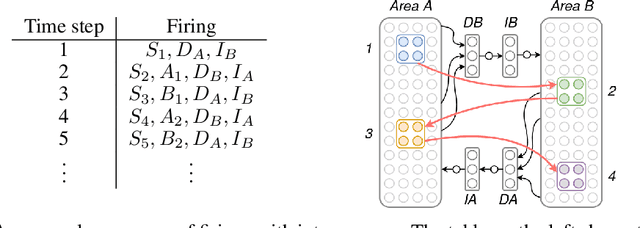
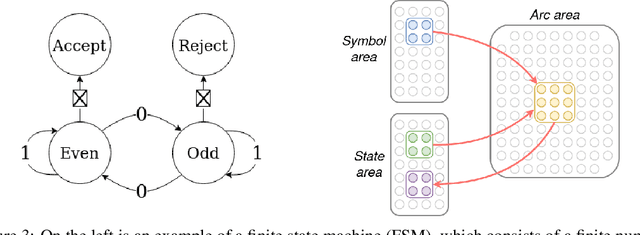
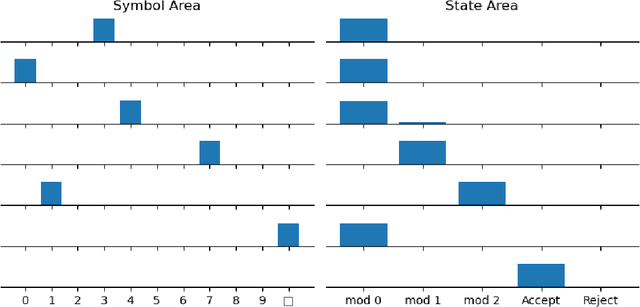
Even as machine learning exceeds human-level performance on many applications, the generality, robustness, and rapidity of the brain's learning capabilities remain unmatched. How cognition arises from neural activity is a central open question in neuroscience, inextricable from the study of intelligence itself. A simple formal model of neural activity was proposed in Papadimitriou [2020] and has been subsequently shown, through both mathematical proofs and simulations, to be capable of implementing certain simple cognitive operations via the creation and manipulation of assemblies of neurons. However, many intelligent behaviors rely on the ability to recognize, store, and manipulate temporal sequences of stimuli (planning, language, navigation, to list a few). Here we show that, in the same model, time can be captured naturally as precedence through synaptic weights and plasticity, and, as a result, a range of computations on sequences of assemblies can be carried out. In particular, repeated presentation of a sequence of stimuli leads to the memorization of the sequence through corresponding neural assemblies: upon future presentation of any stimulus in the sequence, the corresponding assembly and its subsequent ones will be activated, one after the other, until the end of the sequence. Finally, we show that any finite state machine can be learned in a similar way, through the presentation of appropriate patterns of sequences. Through an extension of this mechanism, the model can be shown to be capable of universal computation. We support our analysis with a number of experiments to probe the limits of learning in this model in key ways. Taken together, these results provide a concrete hypothesis for the basis of the brain's remarkable abilities to compute and learn, with sequences playing a vital role.
Transactional Python for Durable Machine Learning: Vision, Challenges, and Feasibility
May 15, 2023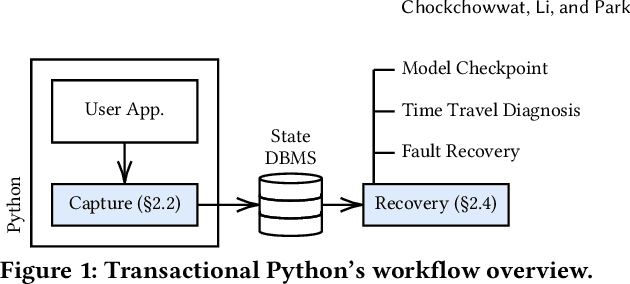
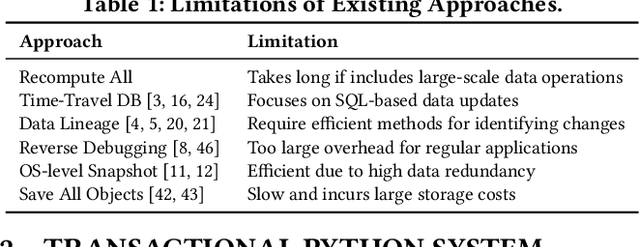
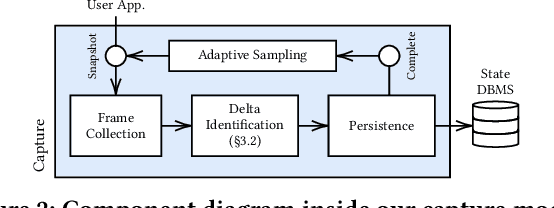
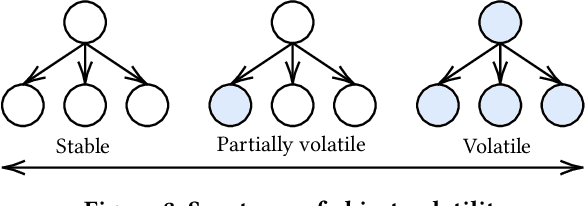
In machine learning (ML), Python serves as a convenient abstraction for working with key libraries such as PyTorch, scikit-learn, and others. Unlike DBMS, however, Python applications may lose important data, such as trained models and extracted features, due to machine failures or human errors, leading to a waste of time and resources. Specifically, they lack four essential properties that could make ML more reliable and user-friendly -- durability, atomicity, replicability, and time-versioning (DART). This paper presents our vision of Transactional Python that provides DART without any code modifications to user programs or the Python kernel, by non-intrusively monitoring application states at the object level and determining a minimal amount of information sufficient to reconstruct a whole application. Our evaluation of a proof-of-concept implementation with public PyTorch and scikit-learn applications shows that DART can be offered with overheads ranging 1.5%--15.6%.