 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Hardware and Software Platform for Aerial Object Localization
May 29, 2023
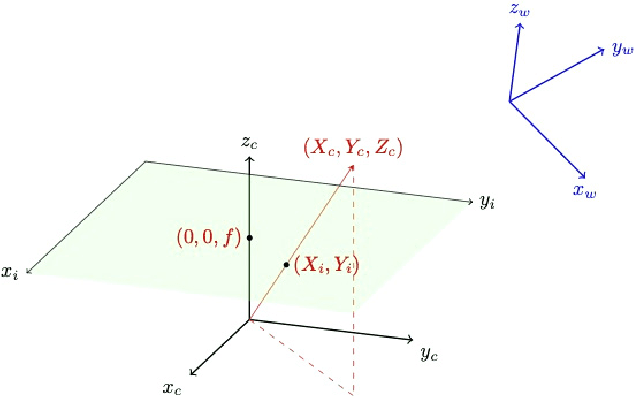

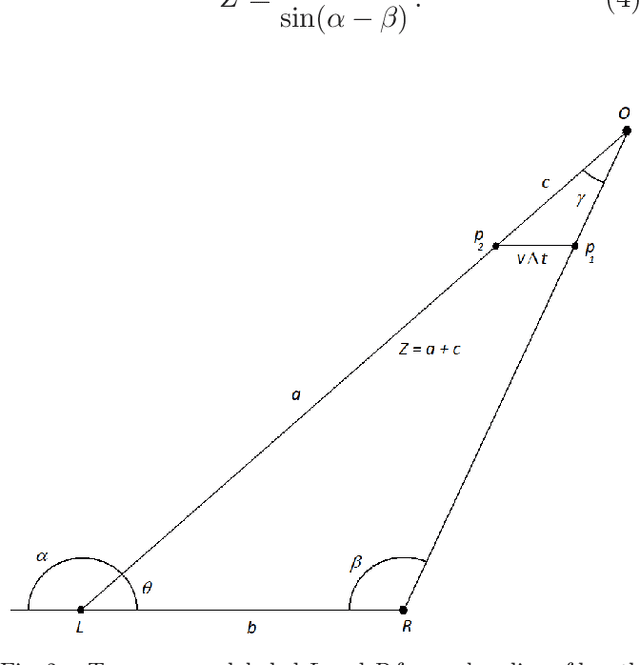
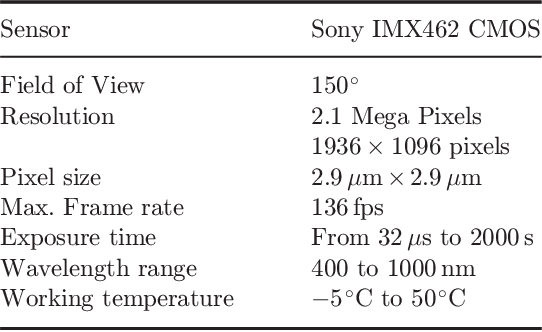
To date, there are little reliable data on the position, velocity and acceleration characteristics of Unidentified Aerial Phenomena (UAP). The dual hardware and software system described in this document provides a means to address this gap. We describe a weatherized multi-camera system which can capture images in the visible, infrared and near infrared wavelengths. We then describe the software we will use to calibrate the cameras and to robustly localize objects-of-interest in three dimensions. We show how object localizations captured over time will be used to compute the velocity and acceleration of airborne objects.
Metamathematics of Algorithmic Composition
May 24, 2023This essay recounts my personal journey towards a deeper understanding of the mathematical foundations of algorithmic music composition. I do not spend much time on specific mathematical algorithms used by composers; rather, I focus on general issues such as fundamental limits and possibilities, by analogy with metalogic, metamathematics, and computability theory. I discuss implications from these foundations for the future of algorithmic composition.
MoDAR: Using Motion Forecasting for 3D Object Detection in Point Cloud Sequences
Jun 05, 2023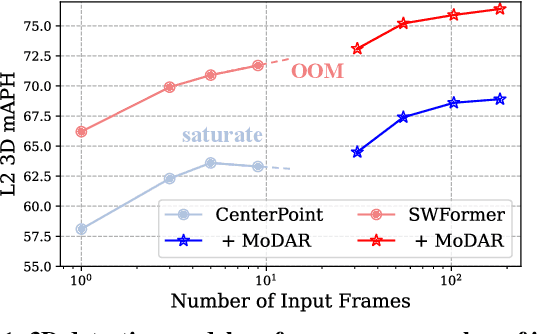
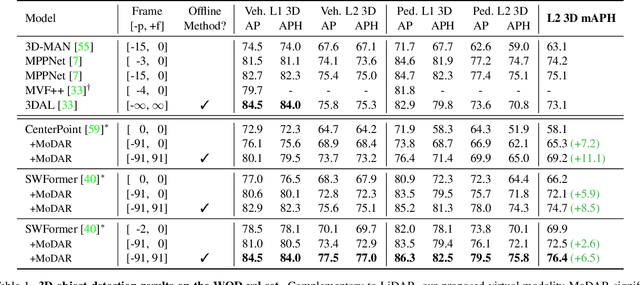
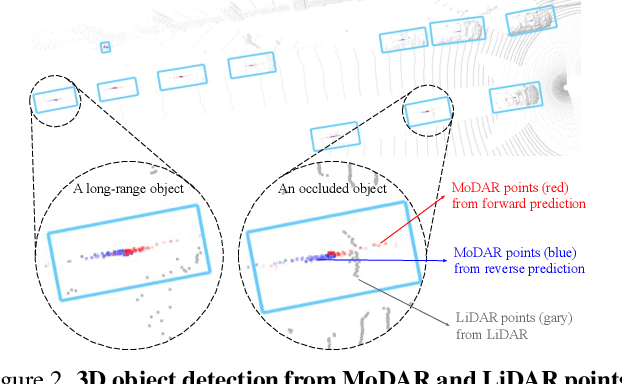
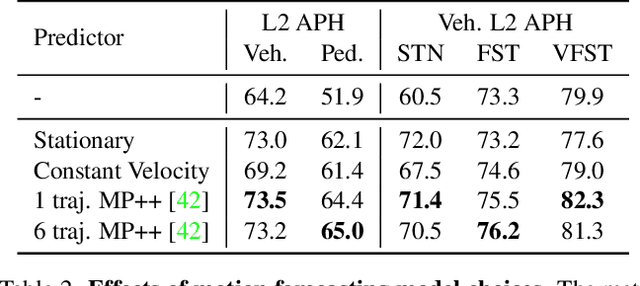
Occluded and long-range objects are ubiquitous and challenging for 3D object detection. Point cloud sequence data provide unique opportunities to improve such cases, as an occluded or distant object can be observed from different viewpoints or gets better visibility over time. However, the efficiency and effectiveness in encoding long-term sequence data can still be improved. In this work, we propose MoDAR, using motion forecasting outputs as a type of virtual modality, to augment LiDAR point clouds. The MoDAR modality propagates object information from temporal contexts to a target frame, represented as a set of virtual points, one for each object from a waypoint on a forecasted trajectory. A fused point cloud of both raw sensor points and the virtual points can then be fed to any off-the-shelf point-cloud based 3D object detector. Evaluated on the Waymo Open Dataset, our method significantly improves prior art detectors by using motion forecasting from extra-long sequences (e.g. 18 seconds), achieving new state of the arts, while not adding much computation overhead.
Towards Anytime Classification in Early-Exit Architectures by Enforcing Conditional Monotonicity
Jun 05, 2023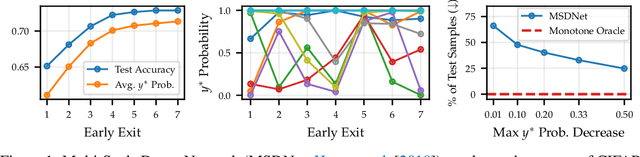
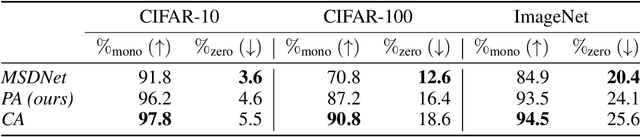
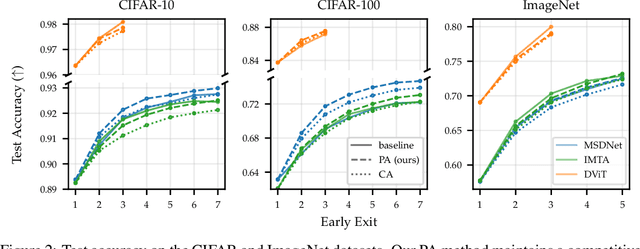
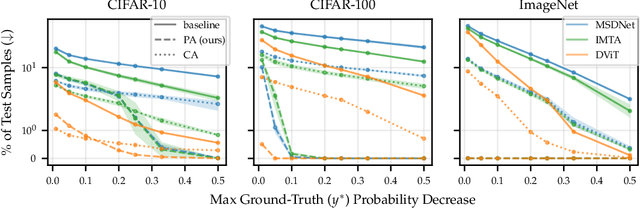
Modern predictive models are often deployed to environments in which computational budgets are dynamic. Anytime algorithms are well-suited to such environments as, at any point during computation, they can output a prediction whose quality is a function of computation time. Early-exit neural networks have garnered attention in the context of anytime computation due to their capability to provide intermediate predictions at various stages throughout the network. However, we demonstrate that current early-exit networks are not directly applicable to anytime settings, as the quality of predictions for individual data points is not guaranteed to improve with longer computation. To address this shortcoming, we propose an elegant post-hoc modification, based on the Product-of-Experts, that encourages an early-exit network to become gradually confident. This gives our deep models the property of conditional monotonicity in the prediction quality -- an essential stepping stone towards truly anytime predictive modeling using early-exit architectures. Our empirical results on standard image-classification tasks demonstrate that such behaviors can be achieved while preserving competitive accuracy on average.
End-to-End Word-Level Pronunciation Assessment with MASK Pre-training
Jun 05, 2023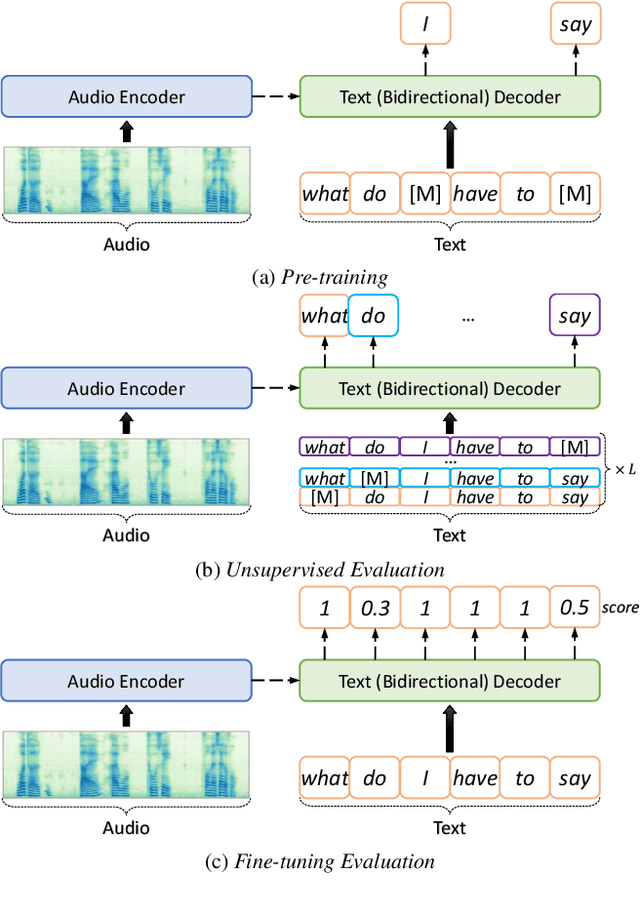
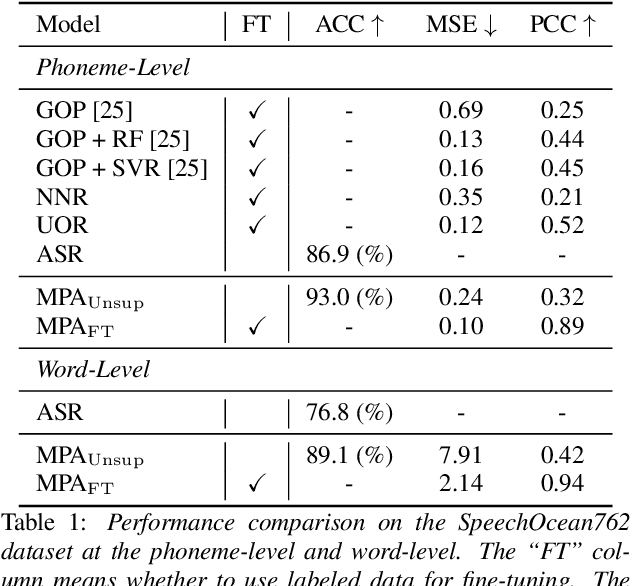
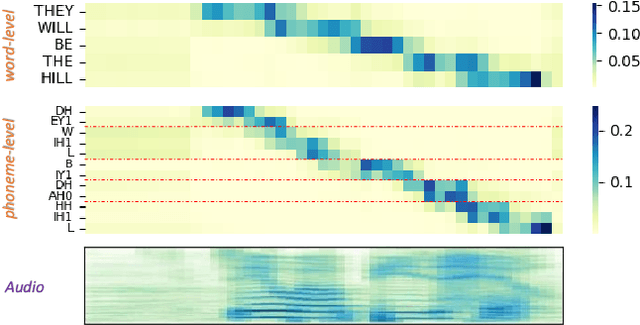
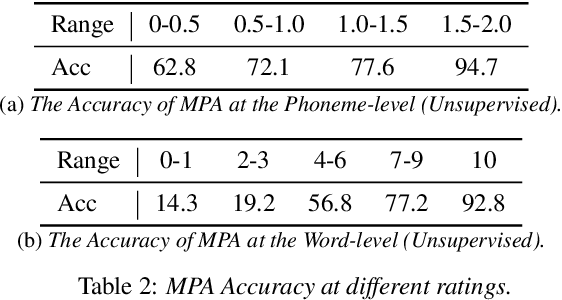
Pronunciation assessment is a major challenge in the computer-aided pronunciation training system, especially at the word (phoneme)-level. To obtain word (phoneme)-level scores, current methods usually rely on aligning components to obtain acoustic features of each word (phoneme), which limits the performance of assessment to the accuracy of alignments. Therefore, to address this problem, we propose a simple yet effective method, namely \underline{M}asked pre-training for \underline{P}ronunciation \underline{A}ssessment (MPA). Specifically, by incorporating a mask-predict strategy, our MPA supports end-to-end training without leveraging any aligning components and can solve misalignment issues to a large extent during prediction. Furthermore, we design two evaluation strategies to enable our model to conduct assessments in both unsupervised and supervised settings. Experimental results on SpeechOcean762 dataset demonstrate that MPA could achieve better performance than previous methods, without any explicit alignment. In spite of this, MPA still has some limitations, such as requiring more inference time and reference text. They expect to be addressed in future work.
Detecting individual-level infections using sparse group-testing through graph-coupled hidden Markov models
Jun 05, 2023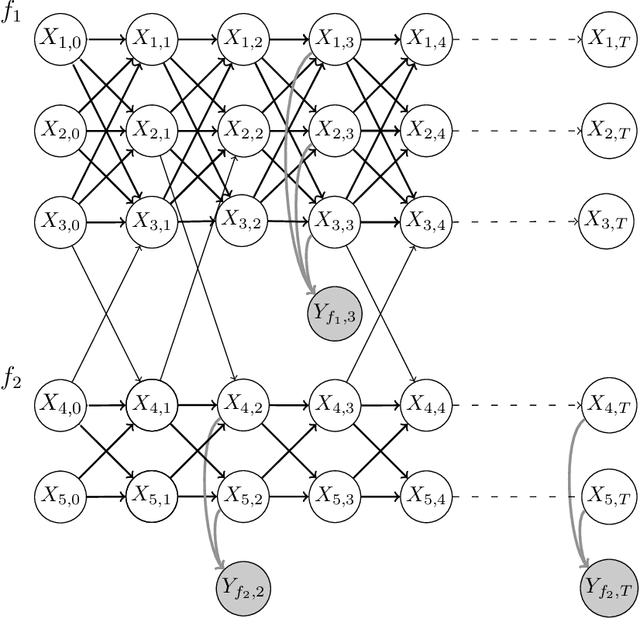

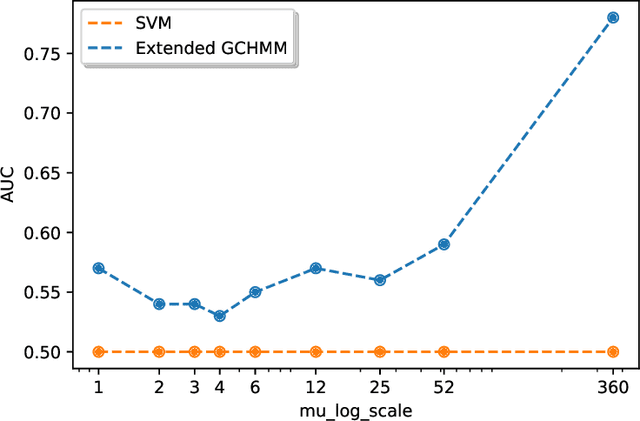
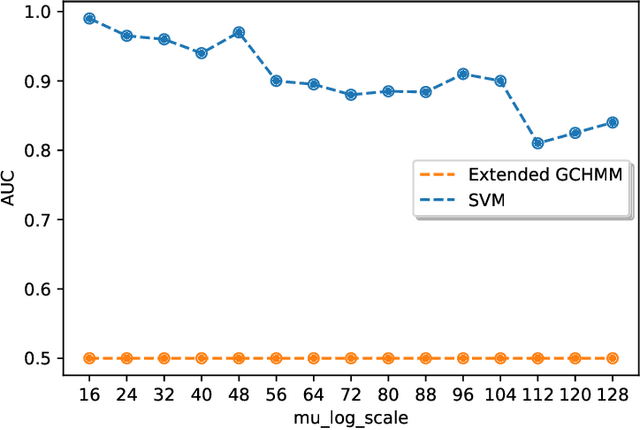
Identifying the infection status of each individual during infectious diseases informs public health management. However, performing frequent individual-level tests may not be feasible. Instead, sparse and sometimes group-level tests are performed. Determining the infection status of individuals using sparse group-level tests remains an open problem. We have tackled this problem by extending graph-coupled hidden Markov models with individuals infection statuses as the hidden states and the group test results as the observations. We fitted the model to simulation datasets using the Gibbs sampling method. The model performed about 0.55 AUC for low testing frequencies and increased to 0.80 AUC in the case where the groups were tested every day. The model was separately tested on a daily basis case to predict the statuses over time and after 15 days of the beginning of the spread, which resulted in 0.98 AUC at day 16 and remained above 0.80 AUC until day 128. Therefore, although dealing with sparse tests remains unsolved, the results open the possibility of using initial group screenings during pandemics to accurately estimate individuals infection statuses.
Enhanced Distribution Modelling via Augmented Architectures For Neural ODE Flows
Jun 05, 2023

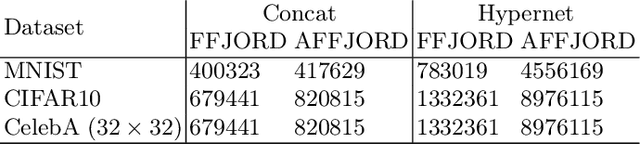
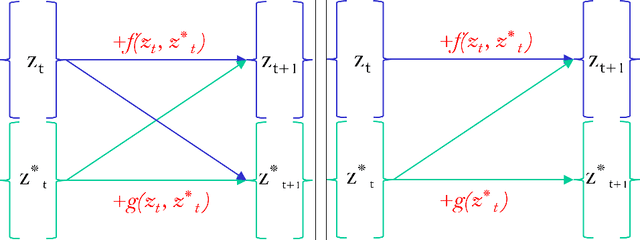
While the neural ODE formulation of normalizing flows such as in FFJORD enables us to calculate the determinants of free form Jacobians in O(D) time, the flexibility of the transformation underlying neural ODEs has been shown to be suboptimal. In this paper, we present AFFJORD, a neural ODE-based normalizing flow which enhances the representation power of FFJORD by defining the neural ODE through special augmented transformation dynamics which preserve the topology of the space. Furthermore, we derive the Jacobian determinant of the general augmented form by generalizing the chain rule in the continuous sense into the Cable Rule, which expresses the forward sensitivity of ODEs with respect to their initial conditions. The cable rule gives an explicit expression for the Jacobian of a neural ODE transformation, and provides an elegant proof of the instantaneous change of variable. Our experimental results on density estimation in synthetic and high dimensional data, such as MNIST, CIFAR-10 and CelebA 32x32, show that AFFJORD outperforms the baseline FFJORD through the improved flexibility of the underlying vector field.
On Emergence of Clean-Priority Learning in Early Stopped Neural Networks
Jun 05, 2023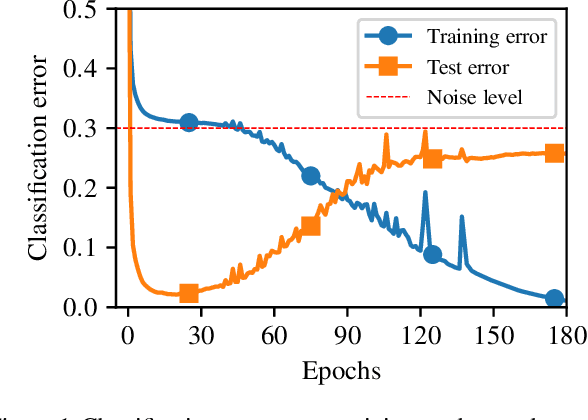
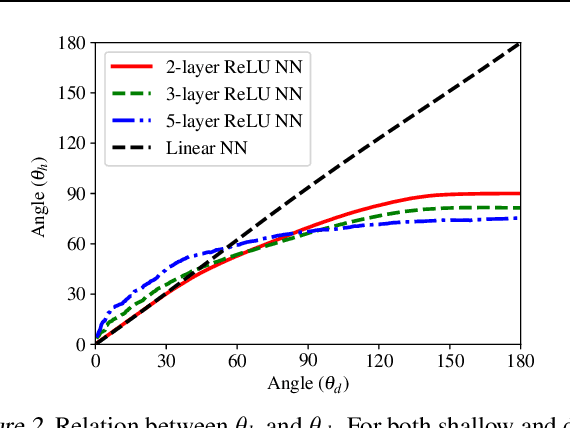
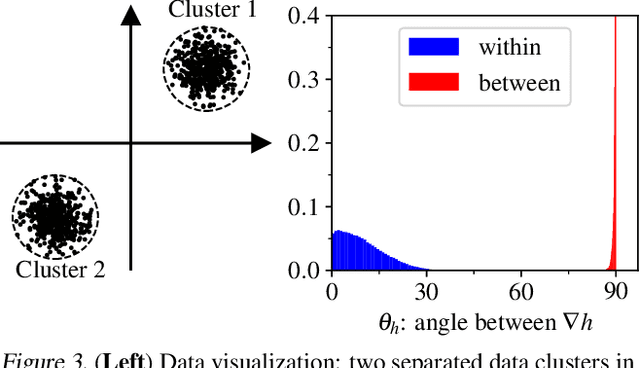
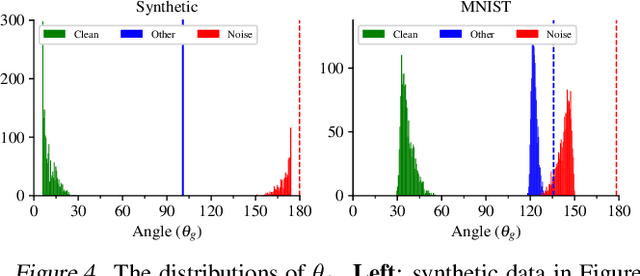
When random label noise is added to a training dataset, the prediction error of a neural network on a label-noise-free test dataset initially improves during early training but eventually deteriorates, following a U-shaped dependence on training time. This behaviour is believed to be a result of neural networks learning the pattern of clean data first and fitting the noise later in the training, a phenomenon that we refer to as clean-priority learning. In this study, we aim to explore the learning dynamics underlying this phenomenon. We theoretically demonstrate that, in the early stage of training, the update direction of gradient descent is determined by the clean subset of training data, leaving the noisy subset has minimal to no impact, resulting in a prioritization of clean learning. Moreover, we show both theoretically and experimentally, as the clean-priority learning goes on, the dominance of the gradients of clean samples over those of noisy samples diminishes, and finally results in a termination of the clean-priority learning and fitting of the noisy samples.
Finite Expression Methods for Discovering Physical Laws from Data
May 15, 2023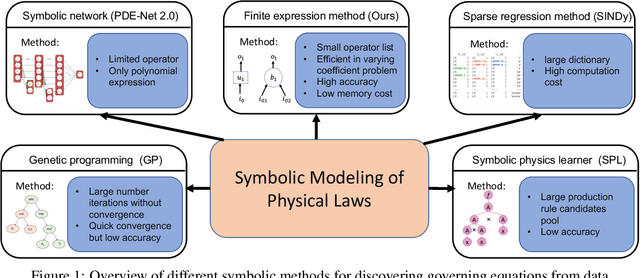
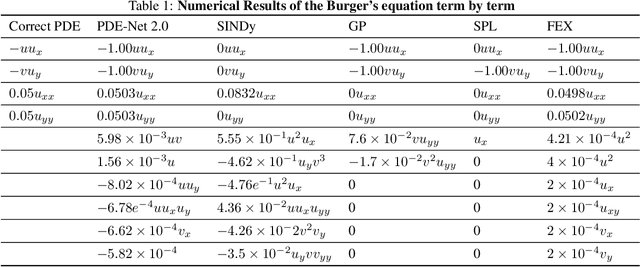
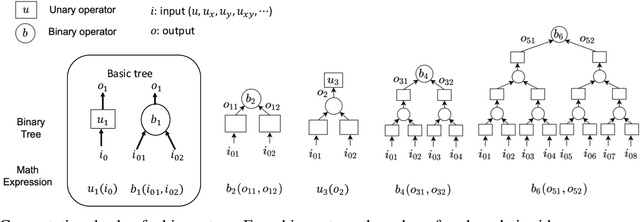
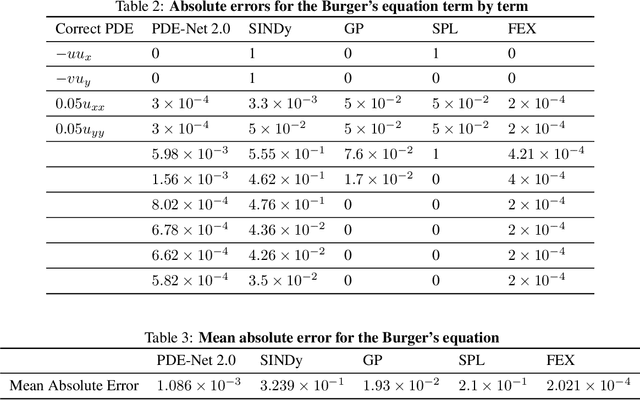
Nonlinear dynamics is a pervasive phenomenon observed in various scientific and engineering disciplines. However, uncovering analytical expressions that describe nonlinear dynamics from limited data remains a challenging and essential task. In this paper, we propose a new deep symbolic learning method called the ``finite expression method'' (FEX) to identify the governing equations within the space of functions containing a finite set of analytic expressions, based on observed dynamic data. The core idea is to leverage FEX to generate analytical expressions of the governing equations by learning the derivatives of partial differential equation (PDE) solutions using convolutions. Our numerical results demonstrate that FEX outperforms all existing methods (such as PDE-Net, SINDy, GP, and SPL) in terms of numerical performance across various problems, including time-dependent PDE problems and nonlinear dynamical systems with time-varying coefficients. Furthermore, the results highlight that FEX exhibits flexibility and expressive power in accurately approximating symbolic governing equations, while maintaining low memory and favorable time complexity.
Domain Adaptation for Time Series Under Feature and Label Shifts
Feb 06, 2023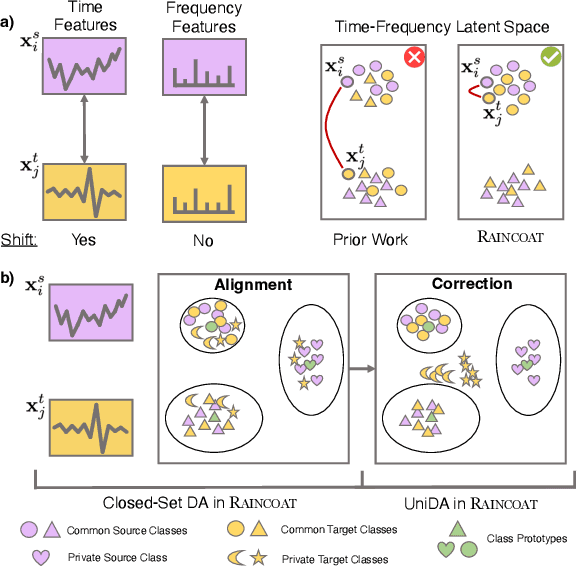
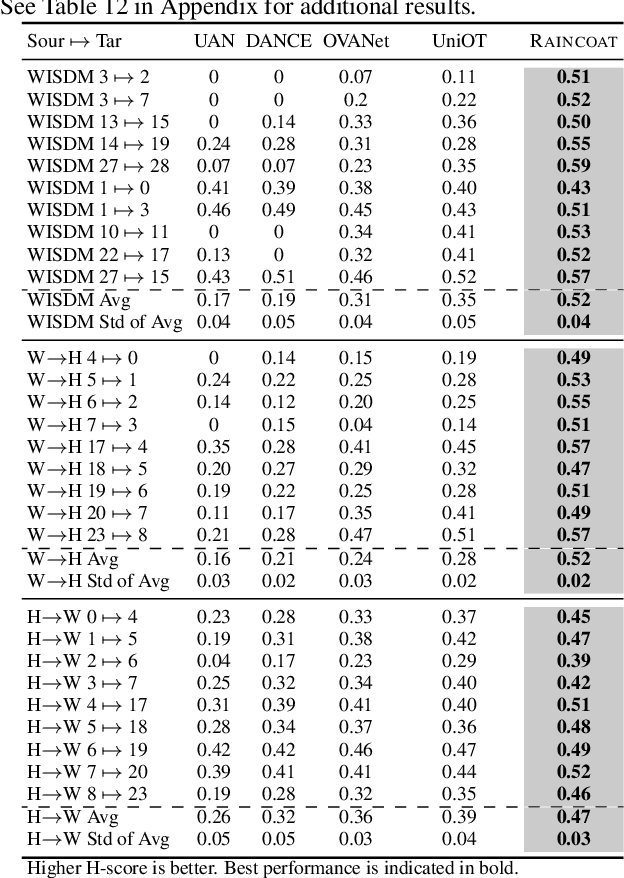
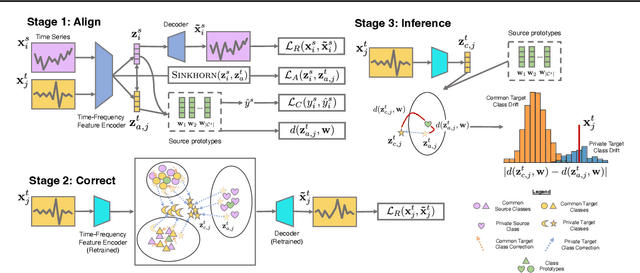

The transfer of models trained on labeled datasets in a source domain to unlabeled target domains is made possible by unsupervised domain adaptation (UDA). However, when dealing with complex time series models, the transferability becomes challenging due to the dynamic temporal structure that varies between domains, resulting in feature shifts and gaps in the time and frequency representations. Furthermore, tasks in the source and target domains can have vastly different label distributions, making it difficult for UDA to mitigate label shifts and recognize labels that only exist in the target domain. We present RAINCOAT, the first model for both closed-set and universal DA on complex time series. RAINCOAT addresses feature and label shifts by considering both temporal and frequency features, aligning them across domains, and correcting for misalignments to facilitate the detection of private labels. Additionally,RAINCOAT improves transferability by identifying label shifts in target domains. Our experiments with 5 datasets and 13 state-of-the-art UDA methods demonstrate that RAINCOAT can achieve an improvement in performance of up to 16.33%, and can effectively handle both closed-set and universal adaptation.