 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Music Mode: Transforming Robot Movement into Music Increases Likability and Perceived Intelligence
Jun 05, 2023
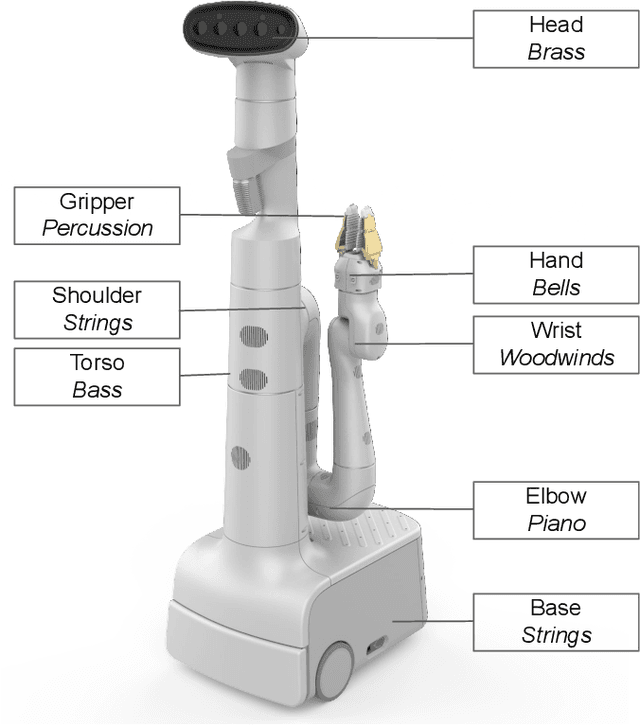
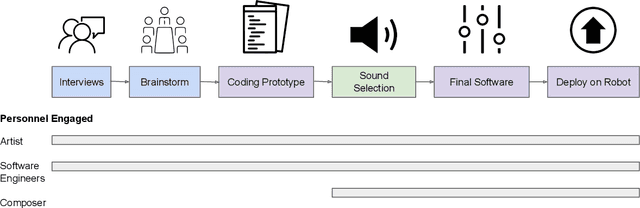
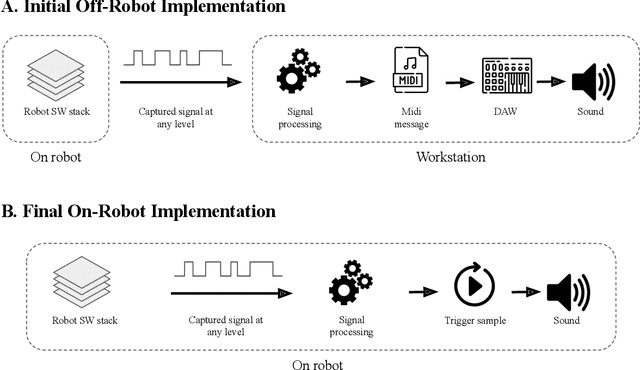
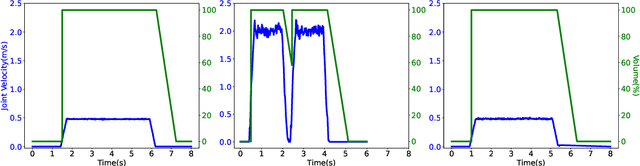
As robots enter everyday spaces like offices, the sounds they create affect how they are perceived. We present "Music Mode", a novel mapping between a robot's joint motions and sounds, programmed by artists and engineers to make the robot generate music as it moves. Two experiments were designed to characterize the effect of this musical augmentation on human users. In the first experiment, a robot performed three tasks while playing three different sound mappings. Results showed that participants observing the robot perceived it as more safe, animate, intelligent, anthropomorphic, and likable when playing the Music Mode Orchestral software. To test whether the results of the first experiment were due to the Music Mode algorithm, rather than music alone, we conducted a second experiment. Here the robot performed the same three tasks, while a participant observed via video, but the Orchestral music was either linked to its movement or random. Participants rated the robots as more intelligent when the music was linked to the movement. Robots using Music Mode logged approximately two hundred hours of operation while navigating, wiping tables, and sorting trash, and bystander comments made during this operating time served as an embedded case study. The contributions are: (1) an interdisciplinary choreographic, musical, and coding design process to develop a real-world robot sound feature, (2) a technical implementation for movement-based sound generation, and (3) two experiments and an embedded case study of robots running this feature during daily work activities that resulted in increased likeability and perceived intelligence of the robot.
Inter Subject Emotion Recognition Using Spatio-Temporal Features From EEG Signal
May 27, 2023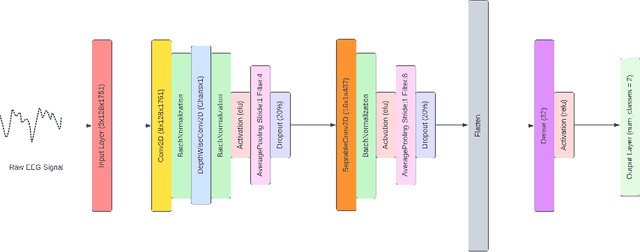

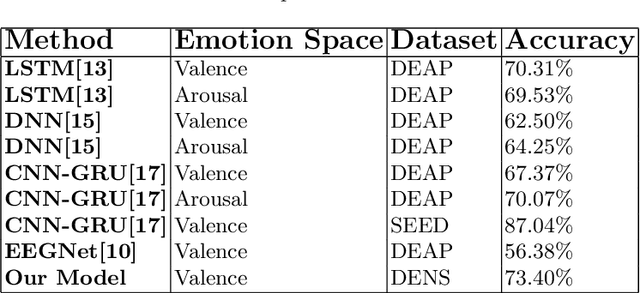
Inter-subject or subject-independent emotion recognition has been a challenging task in affective computing. This work is about an easy-to-implement emotion recognition model that classifies emotions from EEG signals subject independently. It is based on the famous EEGNet architecture, which is used in EEG-related BCIs. We used the Dataset on Emotion using Naturalistic Stimuli (DENS) dataset. The dataset contains the Emotional Events -- the precise information of the emotion timings that participants felt. The model is a combination of regular, depthwise and separable convolution layers of CNN to classify the emotions. The model has the capacity to learn the spatial features of the EEG channels and the temporal features of the EEG signals variability with time. The model is evaluated for the valence space ratings. The model achieved an accuracy of 73.04%.
A new method using deep transfer learning on ECG to predict the response to cardiac resynchronization therapy
Jun 02, 2023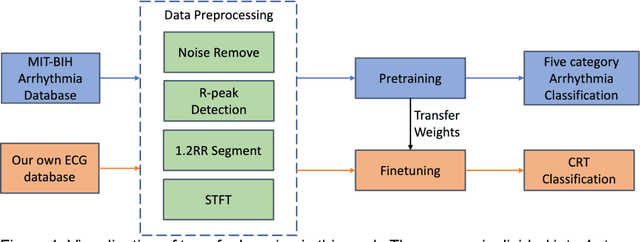
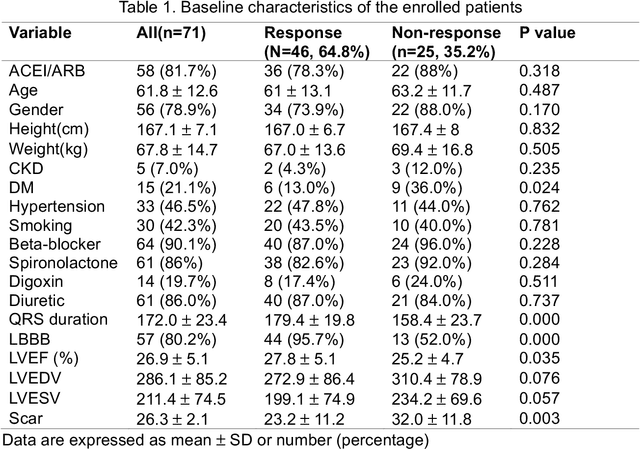
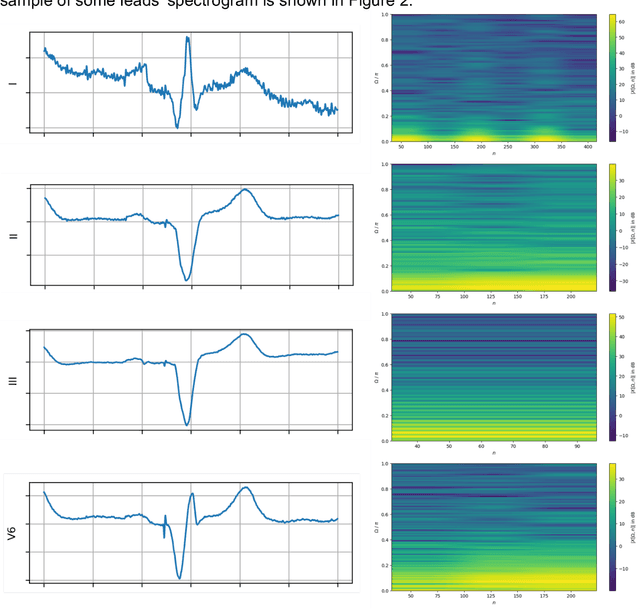
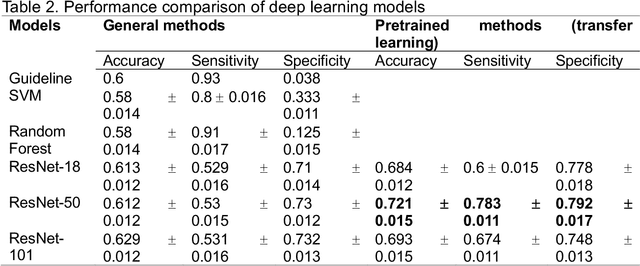
Background: Cardiac resynchronization therapy (CRT) has emerged as an effective treatment for heart failure patients with electrical dyssynchrony. However, accurately predicting which patients will respond to CRT remains a challenge. This study explores the application of deep transfer learning techniques to train a predictive model for CRT response. Methods: In this study, the short-time Fourier transform (STFT) technique was employed to transform ECG signals into two-dimensional images. A transfer learning approach was then applied on the MIT-BIT ECG database to pre-train a convolutional neural network (CNN) model. The model was fine-tuned to extract relevant features from the ECG images, and then tested on our dataset of CRT patients to predict their response. Results: Seventy-one CRT patients were enrolled in this study. The transfer learning model achieved an accuracy of 72% in distinguishing responders from non-responders in the local dataset. Furthermore, the model showed good sensitivity (0.78) and specificity (0.79) in identifying CRT responders. The performance of our model outperformed clinic guidelines and traditional machine learning approaches. Conclusion: The utilization of ECG images as input and leveraging the power of transfer learning allows for improved accuracy in identifying CRT responders. This approach offers potential for enhancing patient selection and improving outcomes of CRT.
An OPC UA-based industrial Big Data architecture
Jun 02, 2023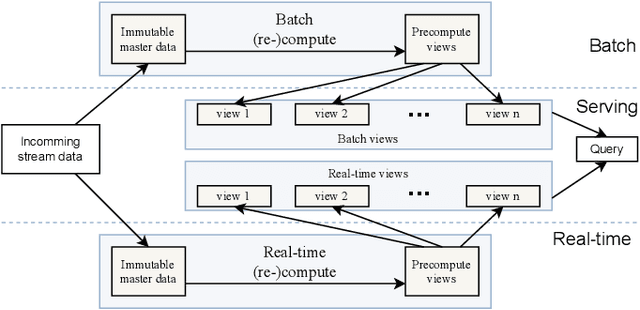
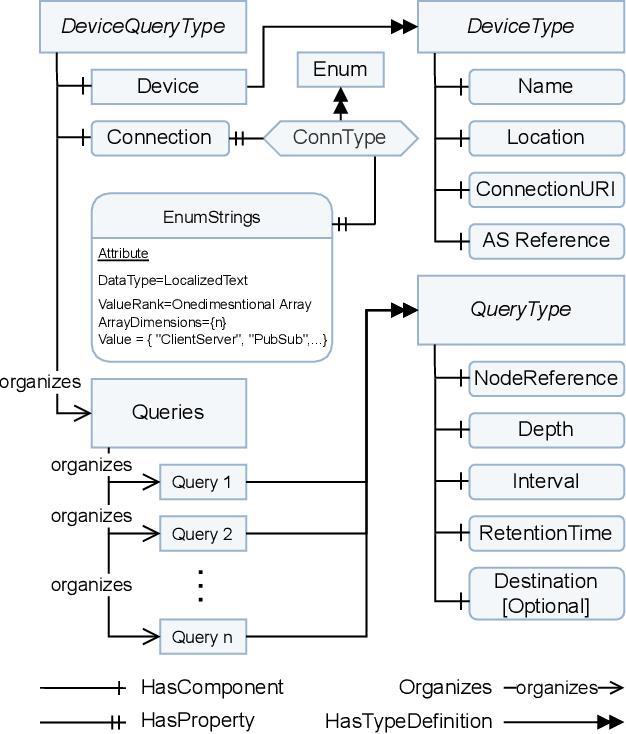
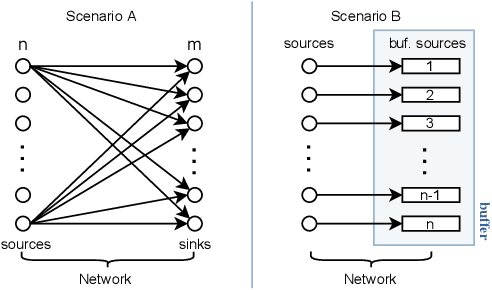
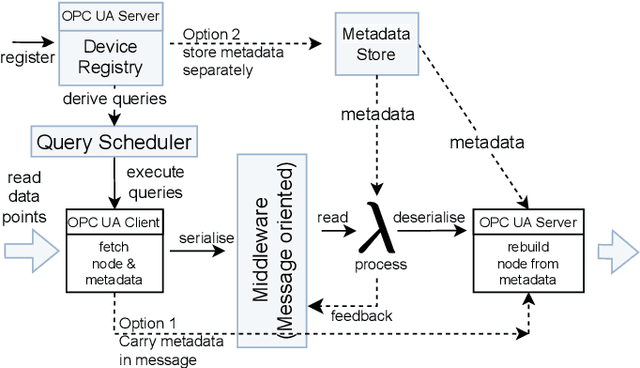
Industry 4.0 factories are complex and data-driven. Data is yielded from many sources, including sensors, PLCs, and other devices, but also from IT, like ERP or CRM systems. We ask how to collect and process this data in a way, such that it includes metadata and can be used for industrial analytics or to derive intelligent support systems. This paper describes a new, query model based approach, which uses a big data architecture to capture data from various sources using OPC UA as a foundation. It buffers and preprocesses the information for the purpose of harmonizing and providing a holistic state space of a factory, as well as mappings to the current state of a production site. That information can be made available to multiple processing sinks, decoupled from the data sources, which enables them to work with the information without interfering with devices of the production, disturbing the network devices they are working in, or influencing the production process negatively. Metadata and connected semantic information is kept throughout the process, allowing to feed algorithms with meaningful data, so that it can be accessed in its entirety to perform time series analysis, machine learning or similar evaluations as well as replaying the data from the buffer for repeatable simulations.
Is Generative Modeling-based Stylization Necessary for Domain Adaptation in Regression Tasks?
Jun 02, 2023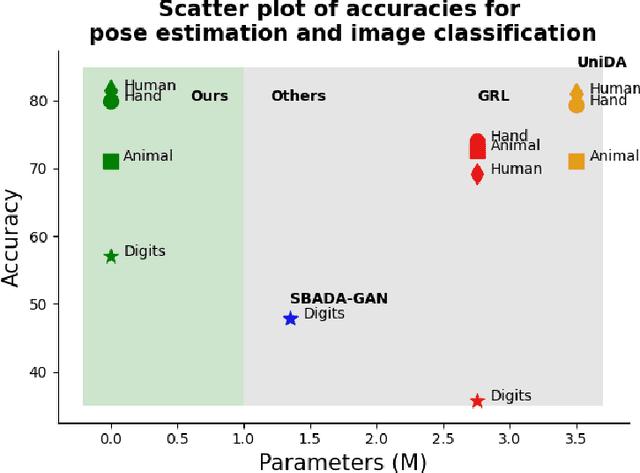
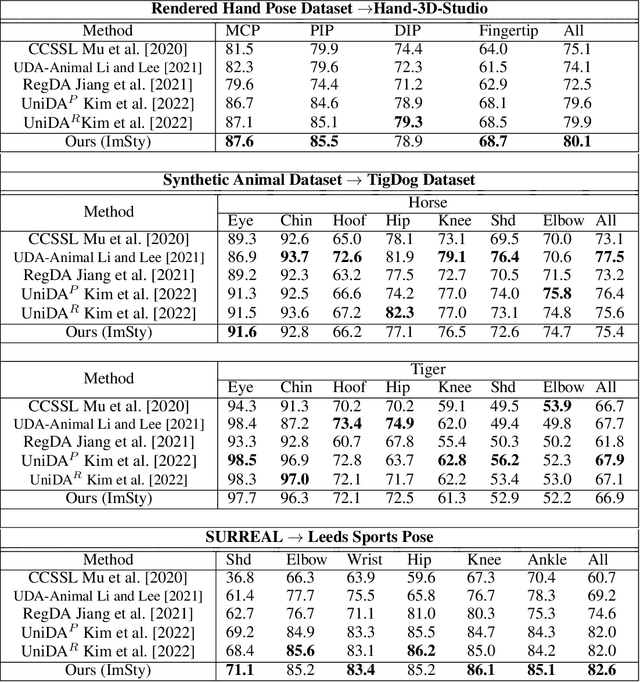
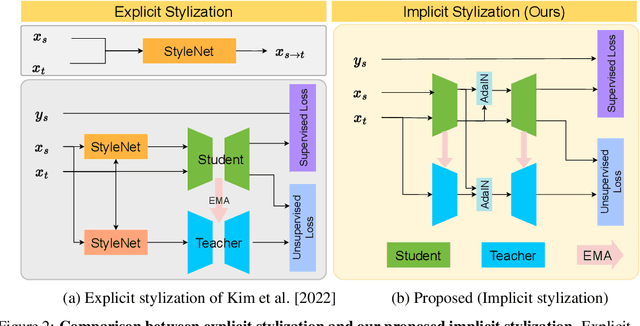

Unsupervised domain adaptation (UDA) aims to bridge the gap between source and target domains in the absence of target domain labels using two main techniques: input-level alignment (such as generative modeling and stylization) and feature-level alignment (which matches the distribution of the feature maps, e.g. gradient reversal layers). Motivated from the success of generative modeling for image classification, stylization-based methods were recently proposed for regression tasks, such as pose estimation. However, use of input-level alignment via generative modeling and stylization incur additional overhead and computational complexity which limit their use in real-world DA tasks. To investigate the role of input-level alignment for DA, we ask the following question: Is generative modeling-based stylization necessary for visual domain adaptation in regression? Surprisingly, we find that input-alignment has little effect on regression tasks as compared to classification. Based on these insights, we develop a non-parametric feature-level domain alignment method -- Implicit Stylization (ImSty) -- which results in consistent improvements over SOTA regression task, without the need for computationally intensive stylization and generative modeling. Our work conducts a critical evaluation of the role of generative modeling and stylization, at a time when these are also gaining popularity for domain generalization.
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation
Jun 02, 2023
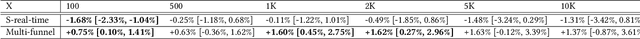
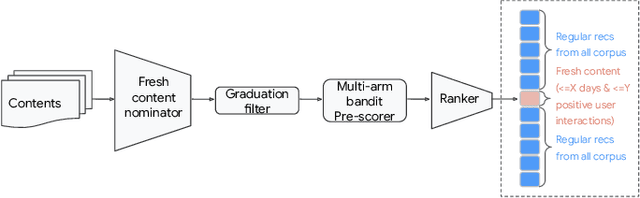

Recommendation system serves as a conduit connecting users to an incredibly large, diverse and ever growing collection of contents. In practice, missing information on fresh (and tail) contents needs to be filled in order for them to be exposed and discovered by their audience. We here share our success stories in building a dedicated fresh content recommendation stack on a large commercial platform. To nominate fresh contents, we built a multi-funnel nomination system that combines (i) a two-tower model with strong generalization power for coverage, and (ii) a sequence model with near real-time update on user feedback for relevance. The multi-funnel setup effectively balances between coverage and relevance. An in-depth study uncovers the relationship between user activity level and their proximity toward fresh contents, which further motivates a contextual multi-funnel setup. Nominated fresh candidates are then scored and ranked by systems considering prediction uncertainty to further bootstrap content with less exposure. We evaluate the benefits of the dedicated fresh content recommendation stack, and the multi-funnel nomination system in particular, through user corpus co-diverted live experiments. We conduct multiple rounds of live experiments on a commercial platform serving billion of users demonstrating efficacy of our proposed methods.
Theoretical Behavior of XAI Methods in the Presence of Suppressor Variables
Jun 02, 2023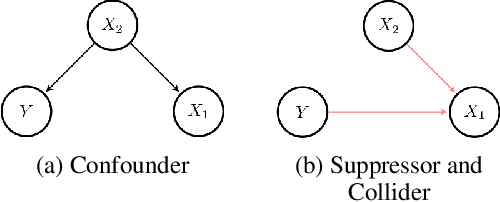
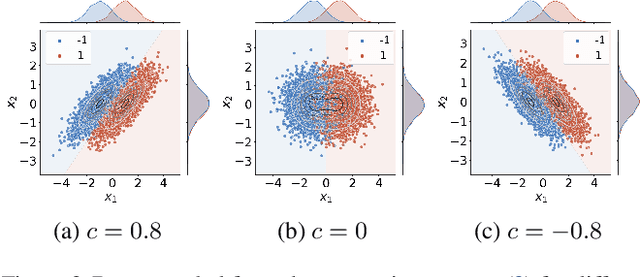
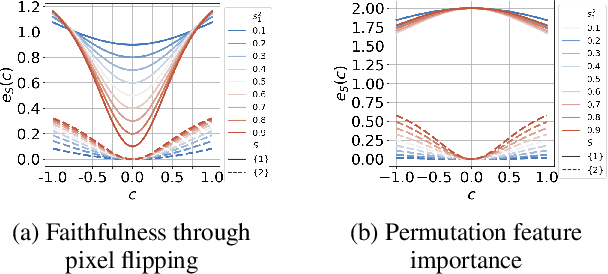
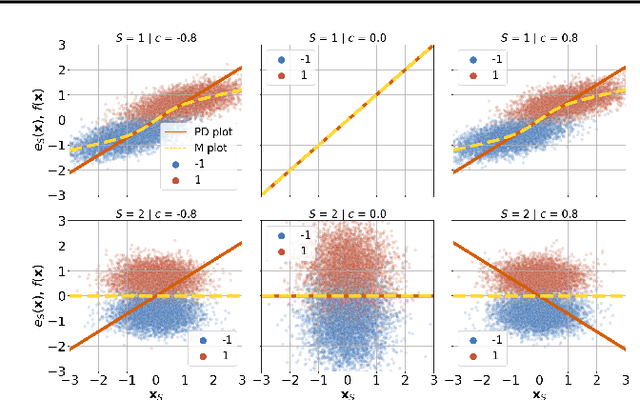
In recent years, the community of 'explainable artificial intelligence' (XAI) has created a vast body of methods to bridge a perceived gap between model 'complexity' and 'interpretability'. However, a concrete problem to be solved by XAI methods has not yet been formally stated. As a result, XAI methods are lacking theoretical and empirical evidence for the 'correctness' of their explanations, limiting their potential use for quality-control and transparency purposes. At the same time, Haufe et al. (2014) showed, using simple toy examples, that even standard interpretations of linear models can be highly misleading. Specifically, high importance may be attributed to so-called suppressor variables lacking any statistical relation to the prediction target. This behavior has been confirmed empirically for a large array of XAI methods in Wilming et al. (2022). Here, we go one step further by deriving analytical expressions for the behavior of a variety of popular XAI methods on a simple two-dimensional binary classification problem involving Gaussian class-conditional distributions. We show that the majority of the studied approaches will attribute non-zero importance to a non-class-related suppressor feature in the presence of correlated noise. This poses important limitations on the interpretations and conclusions that the outputs of these XAI methods can afford.
Federated Learning of Models Pre-Trained on Different Features with Consensus Graphs
Jun 02, 2023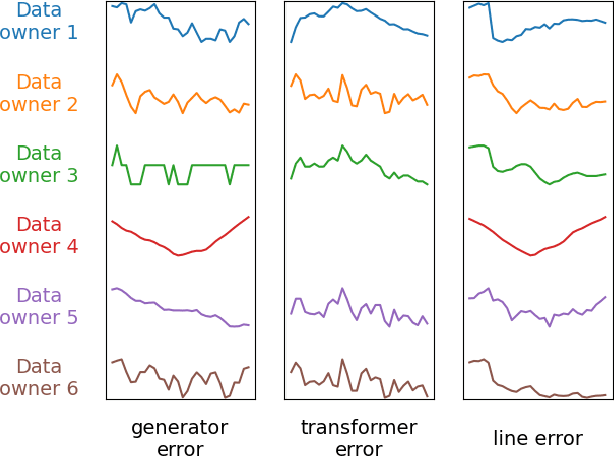
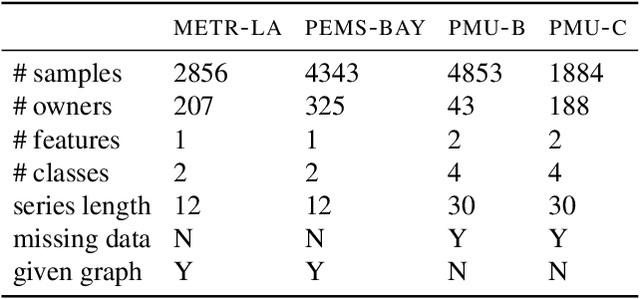
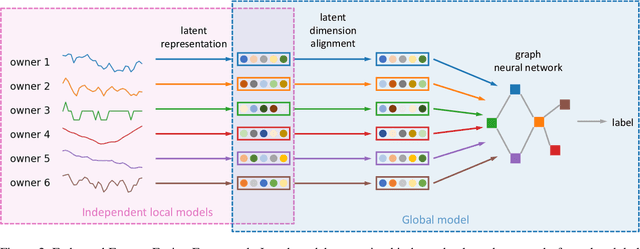
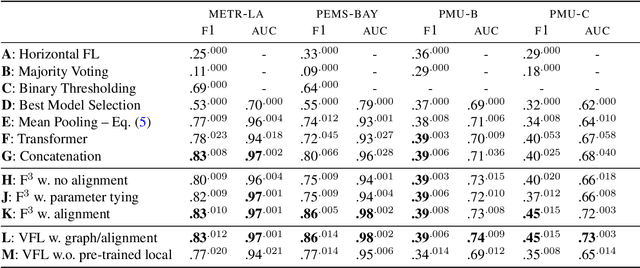
Learning an effective global model on private and decentralized datasets has become an increasingly important challenge of machine learning when applied in practice. Existing distributed learning paradigms, such as Federated Learning, enable this via model aggregation which enforces a strong form of modeling homogeneity and synchronicity across clients. This is however not suitable to many practical scenarios. For example, in distributed sensing, heterogeneous sensors reading data from different views of the same phenomenon would need to use different models for different data modalities. Local learning therefore happens in isolation but inference requires merging the local models to achieve consensus. To enable consensus among local models, we propose a feature fusion approach that extracts local representations from local models and incorporates them into a global representation that improves the prediction performance. Achieving this requires addressing two non-trivial problems. First, we need to learn an alignment between similar feature components which are arbitrarily arranged across clients to enable representation aggregation. Second, we need to learn a consensus graph that captures the high-order interactions between local feature spaces and how to combine them to achieve a better prediction. This paper presents solutions to these problems and demonstrates them in real-world applications on time series data such as power grids and traffic networks.
Recurrences reveal shared causal drivers of complex time series
Jan 31, 2023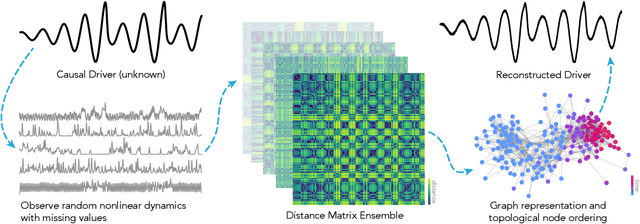
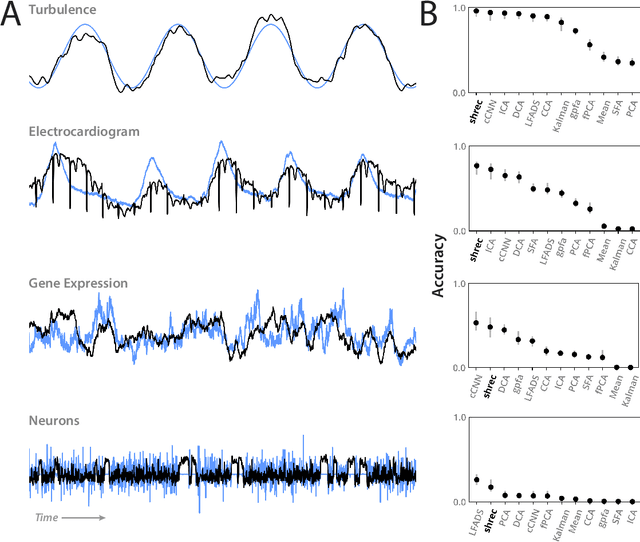
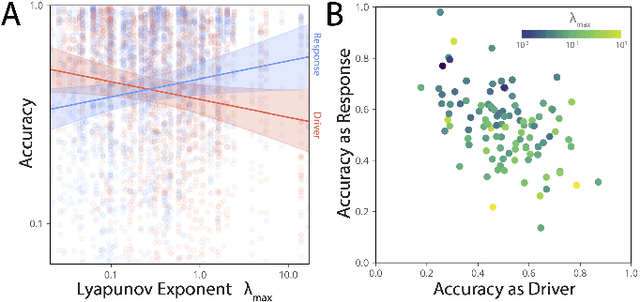
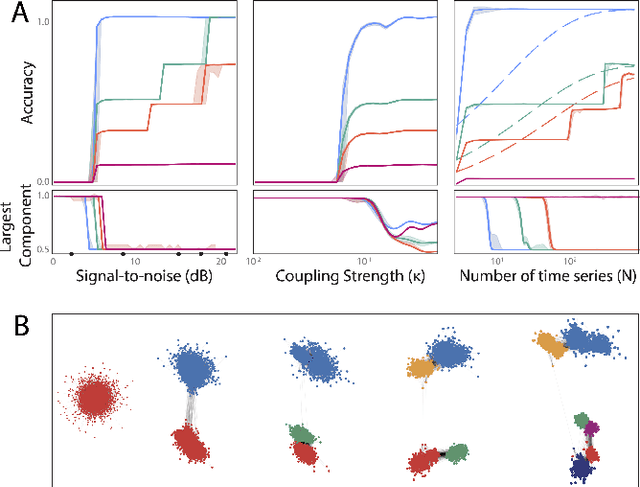
Many experimental time series measurements share an unobserved causal driver. Examples include genes targeted by transcription factors, ocean flows influenced by large-scale atmospheric currents, and motor circuits steered by descending neurons. Reliably inferring this unseen driving force is necessary to understand the intermittent nature of top-down control schemes in diverse biological and engineered systems. Here, we introduce a new unsupervised learning algorithm that uses recurrences in time series measurements to gradually reconstruct an unobserved driving signal. Drawing on the mathematical theory of skew-product dynamical systems, we identify recurrence events shared across response time series, which implicitly define a recurrence graph with glass-like structure. As the amount or quality of observed data improves, this recurrence graph undergoes a percolation transition manifesting as weak ergodicity breaking for random walks on the induced landscape -- revealing the shared driver's dynamics, even in the presence of strongly corrupted or noisy measurements. Across several thousand random dynamical systems, we empirically quantify the dependence of reconstruction accuracy on the rate of information transfer from a chaotic driver to the response systems, and we find that effective reconstruction proceeds through gradual approximation of the driver's dominant unstable periodic orbits. Through extensive benchmarks against classical and neural-network-based signal processing techniques, we demonstrate our method's strong ability to extract causal driving signals from diverse real-world datasets spanning neuroscience, genomics, fluid dynamics, and physiology.
Convex Geometric Trajectory Tracking using Lie Algebraic MPC for Autonomous Marine Vehicles
May 15, 2023
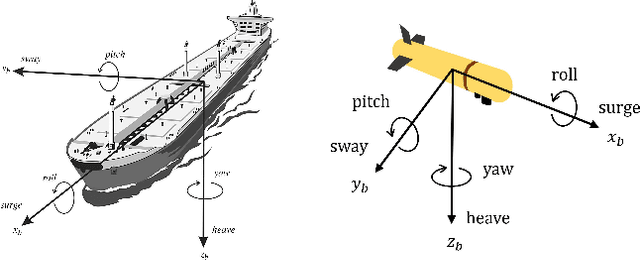
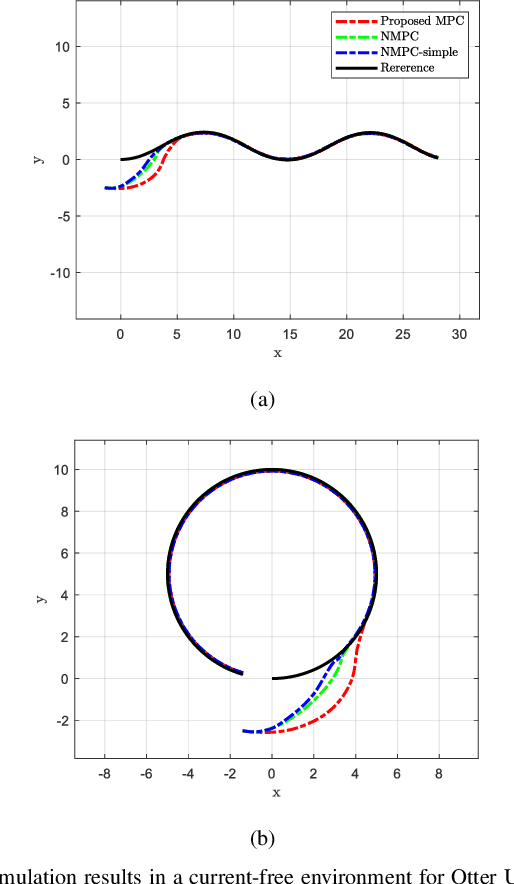
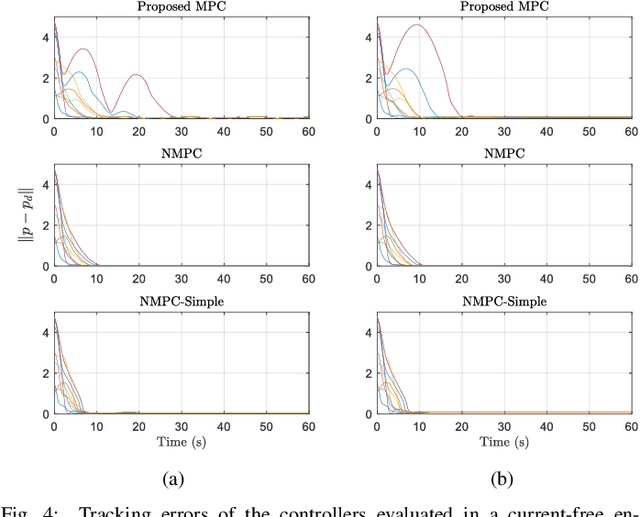
Controlling marine vehicles in challenging environments is a complex task due to the presence of nonlinear hydrodynamics and uncertain external disturbances. Despite nonlinear model predictive control (MPC) showing potential in addressing these issues, its practical implementation is often constrained by computational limitations. In this paper, we propose an efficient controller for trajectory tracking of marine vehicles by employing a convex error-state MPC on the Lie group. By leveraging the inherent geometric properties of the Lie group, we can construct globally valid error dynamics and formulate a quadratic programming-based optimization problem. Our proposed MPC demonstrates effectiveness in trajectory tracking through extensive-numerical simulations, including scenarios involving ocean currents. Notably, our method substantially reduces computation time compared to nonlinear MPC, making it well-suited for real-time control applications with long prediction horizons or involving small marine vehicles.