 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Integrated Sensing, Navigation, and Communication for Secure UAV Networks with a Mobile Eavesdropper
May 22, 2023
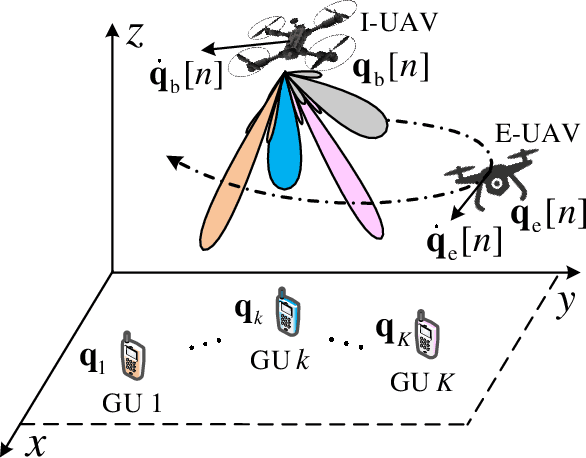
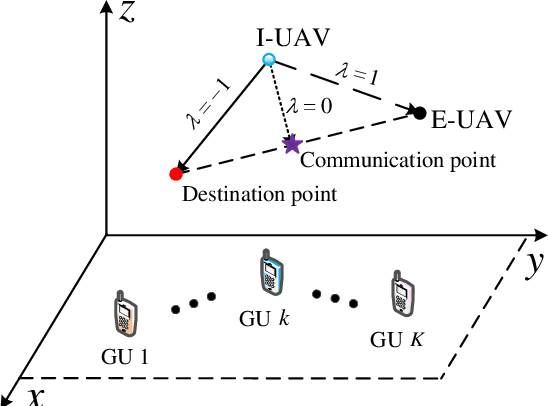
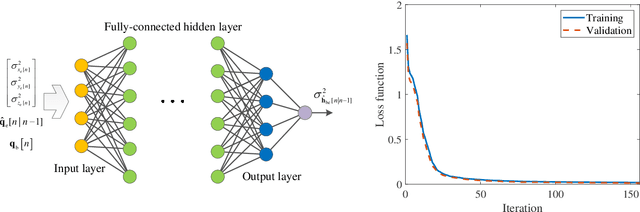
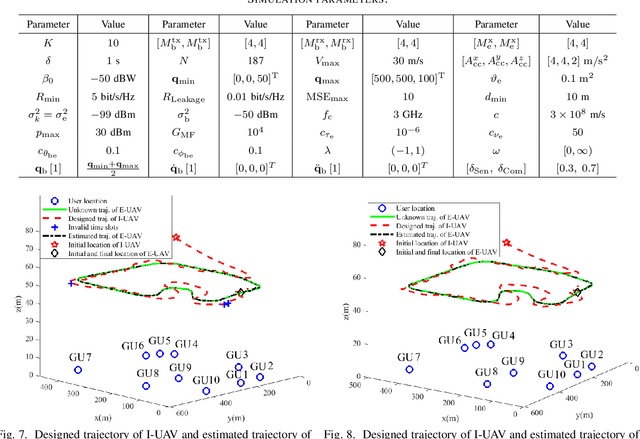
This paper proposes an integrated sensing, navigation, and communication (ISNC) framework for safeguarding unmanned aerial vehicle (UAV)-enabled wireless networks against a mobile eavesdropping UAV (E-UAV). To cope with the mobility of the E-UAV, the proposed framework advocates the dual use of artificial noise transmitted by the information UAV (I-UAV) for simultaneous jamming and sensing to facilitate navigation and secure communication. In particular, the I-UAV communicates with legitimate downlink ground users, while avoiding potential information leakage by emitting jamming signals, and estimates the state of the E-UAV with an extended Kalman filter based on the backscattered jamming signals. Exploiting the estimated state of the E-UAV in the previous time slot, the I-UAV determines its flight planning strategy, predicts the wiretap channel, and designs its communication resource allocation policy for the next time slot. To circumvent the severe coupling between these three tasks, a divide-and-conquer approach is adopted. The online navigation design has the objective to minimize the distance between the I-UAV and a pre-defined destination point considering kinematic and geometric constraints. Subsequently, given the predicted wiretap channel, the robust resource allocation design is formulated as an optimization problem to achieve the optimal trade-off between sensing and communication in the next time slot, while taking into account the wiretap channel prediction error and the quality-of-service (QoS) requirements of secure communication. Simulation results demonstrate the superior performance of the proposed design compared with baseline schemes and validate the benefits of integrating sensing and navigation into secure UAV communication systems.
Multi-granulariy Time-based Transformer for Knowledge Tracing
Apr 11, 2023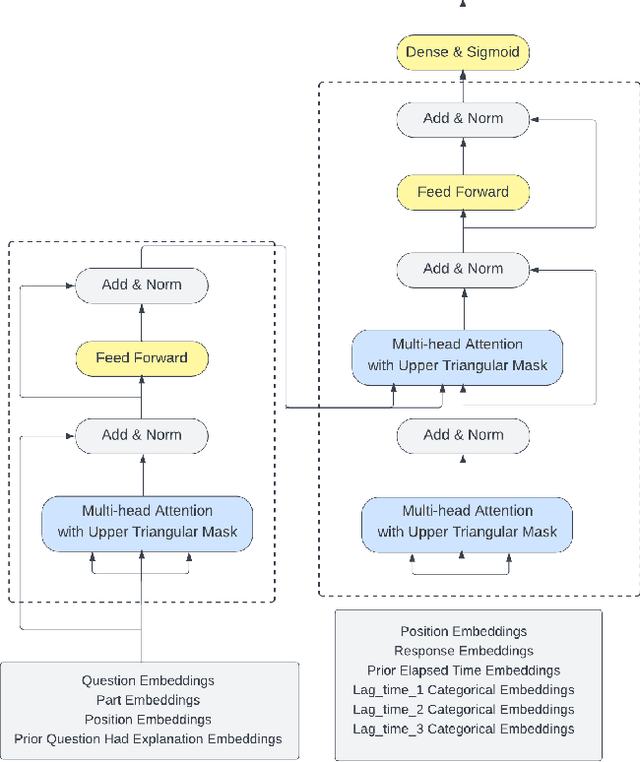

In this paper, we present a transformer architecture for predicting student performance on standardized tests. Specifically, we leverage students historical data, including their past test scores, study habits, and other relevant information, to create a personalized model for each student. We then use these models to predict their future performance on a given test. Applying this model to the RIIID dataset, we demonstrate that using multiple granularities for temporal features as the decoder input significantly improve model performance. Our results also show the effectiveness of our approach, with substantial improvements over the LightGBM method. Our work contributes to the growing field of AI in education, providing a scalable and accurate tool for predicting student outcomes.
Computer-Vision Based Real Time Waypoint Generation for Autonomous Vineyard Navigation with Quadruped Robots
May 02, 2023



The VINUM project seeks to address the shortage of skilled labor in modern vineyards by introducing a cutting-edge mobile robotic solution. Leveraging the capabilities of the quadruped robot, HyQReal, this system, equipped with arm and vision sensors, offers autonomous navigation and winter pruning of grapevines reducing the need for human intervention. At the heart of this approach lies an architecture that empowers the robot to easily navigate vineyards, identify grapevines with unparalleled accuracy, and approach them for pruning with precision. A state machine drives the process, deftly switching between various stages to ensure seamless and efficient task completion. The system's performance was assessed through experimentation, focusing on waypoint precision and optimizing the robot's workspace for single-plant operations. Results indicate that the architecture is highly reliable, with a mean error of 21.5cm and a standard deviation of 17.6cm for HyQReal. However, improvements in grapevine detection accuracy are necessary for optimal performance. This work is based on a computer-vision-based navigation method for quadruped robots in vineyards, opening up new possibilities for selective task automation. The system's architecture works well in ideal weather conditions, generating and arriving at precise waypoints that maximize the attached robotic arm's workspace. This work is an extension of our short paper presented at the Italian Conference on Robotics and Intelligent Machines (I-RIM).
Large Language Models Converge on Brain-Like Word Representations
Jun 02, 2023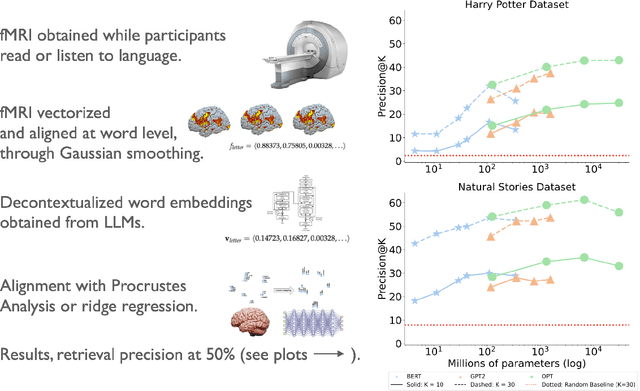
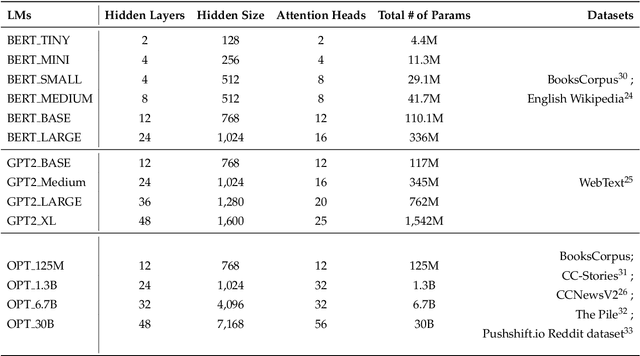
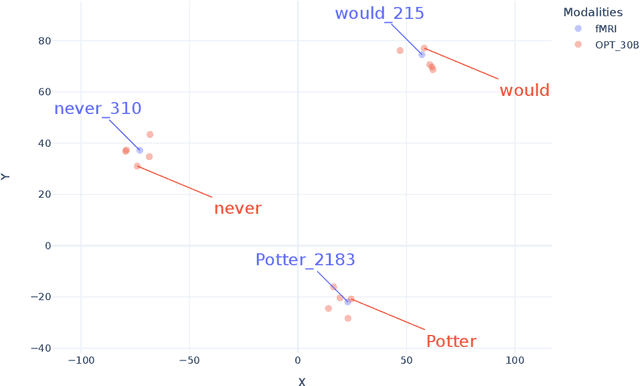
One of the greatest puzzles of all time is how understanding arises from neural mechanics. Our brains are networks of billions of biological neurons transmitting chemical and electrical signals along their connections. Large language models are networks of millions or billions of digital neurons, implementing functions that read the output of other functions in complex networks. The failure to see how meaning would arise from such mechanics has led many cognitive scientists and philosophers to various forms of dualism -- and many artificial intelligence researchers to dismiss large language models as stochastic parrots or jpeg-like compressions of text corpora. We show that human-like representations arise in large language models. Specifically, the larger neural language models get, the more their representations are structurally similar to neural response measurements from brain imaging.
Empowering Molecule Discovery for Molecule-Caption Translation with Large Language Models: A ChatGPT Perspective
Jun 11, 2023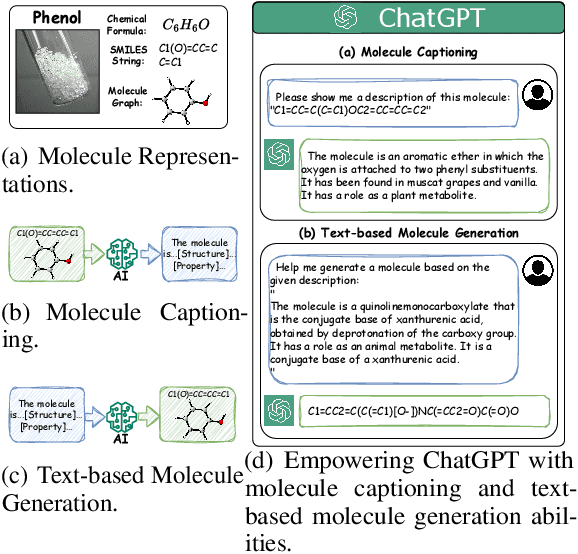

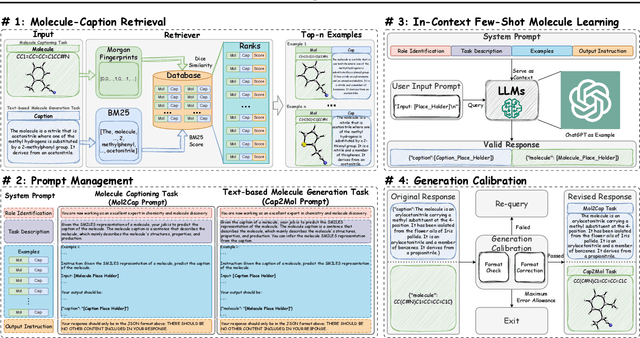

Molecule discovery plays a crucial role in various scientific fields, advancing the design of tailored materials and drugs. Traditional methods for molecule discovery follow a trial-and-error process, which are both time-consuming and costly, while computational approaches such as artificial intelligence (AI) have emerged as revolutionary tools to expedite various tasks, like molecule-caption translation. Despite the importance of molecule-caption translation for molecule discovery, most of the existing methods heavily rely on domain experts, require excessive computational cost, and suffer from poor performance. On the other hand, Large Language Models (LLMs), like ChatGPT, have shown remarkable performance in various cross-modal tasks due to their great powerful capabilities in natural language understanding, generalization, and reasoning, which provides unprecedented opportunities to advance molecule discovery. To address the above limitations, in this work, we propose a novel LLMs-based framework (\textbf{MolReGPT}) for molecule-caption translation, where a retrieval-based prompt paradigm is introduced to empower molecule discovery with LLMs like ChatGPT without fine-tuning. More specifically, MolReGPT leverages the principle of molecular similarity to retrieve similar molecules and their text descriptions from a local database to ground the generation of LLMs through in-context few-shot molecule learning. We evaluate the effectiveness of MolReGPT via molecule-caption translation, which includes molecule understanding and text-based molecule generation. Experimental results show that MolReGPT outperforms fine-tuned models like MolT5-base without any additional training. To the best of our knowledge, MolReGPT is the first work to leverage LLMs in molecule-caption translation for advancing molecule discovery.
Instructed Diffuser with Temporal Condition Guidance for Offline Reinforcement Learning
Jun 08, 2023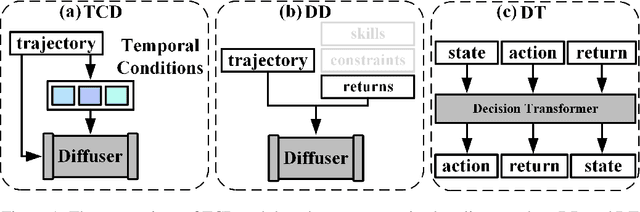
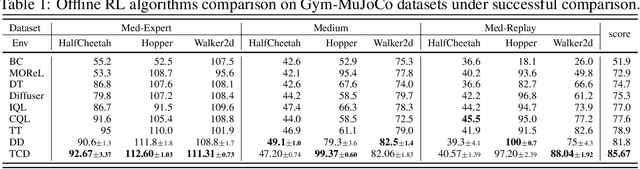
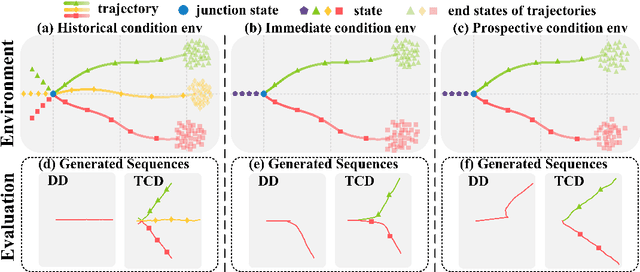
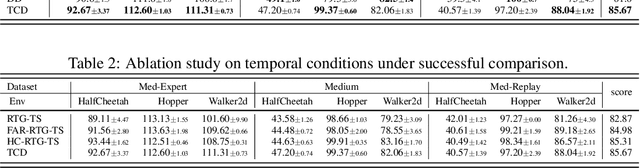
Recent works have shown the potential of diffusion models in computer vision and natural language processing. Apart from the classical supervised learning fields, diffusion models have also shown strong competitiveness in reinforcement learning (RL) by formulating decision-making as sequential generation. However, incorporating temporal information of sequential data and utilizing it to guide diffusion models to perform better generation is still an open challenge. In this paper, we take one step forward to investigate controllable generation with temporal conditions that are refined from temporal information. We observe the importance of temporal conditions in sequential generation in sufficient explorative scenarios and provide a comprehensive discussion and comparison of different temporal conditions. Based on the observations, we propose an effective temporally-conditional diffusion model coined Temporally-Composable Diffuser (TCD), which extracts temporal information from interaction sequences and explicitly guides generation with temporal conditions. Specifically, we separate the sequences into three parts according to time expansion and identify historical, immediate, and prospective conditions accordingly. Each condition preserves non-overlapping temporal information of sequences, enabling more controllable generation when we jointly use them to guide the diffuser. Finally, we conduct extensive experiments and analysis to reveal the favorable applicability of TCD in offline RL tasks, where our method reaches or matches the best performance compared with prior SOTA baselines.
EXOT: Exit-aware Object Tracker for Safe Robotic Manipulation of Moving Object
Jun 08, 2023
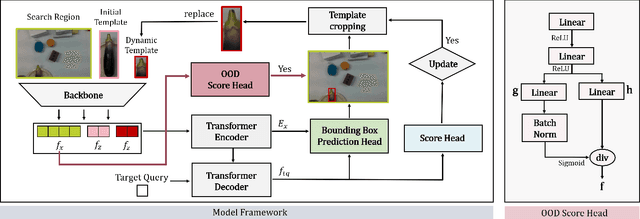

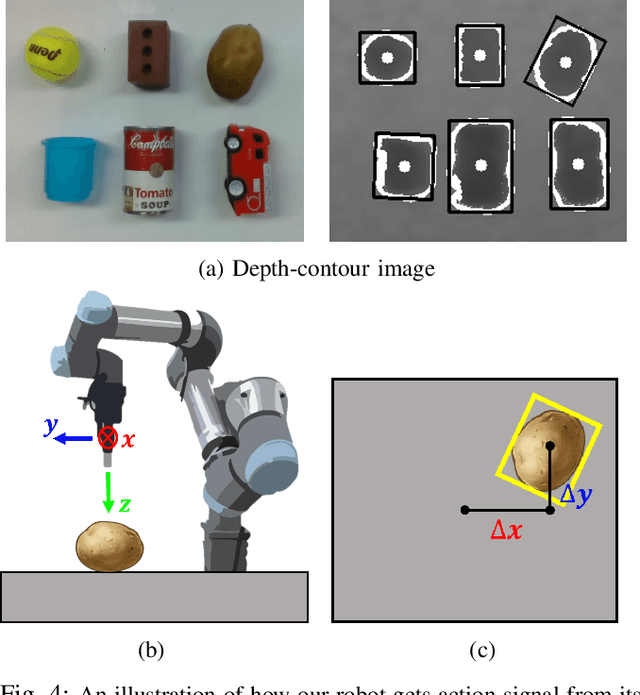
Current robotic hand manipulation narrowly operates with objects in predictable positions in limited environments. Thus, when the location of the target object deviates severely from the expected location, a robot sometimes responds in an unexpected way, especially when it operates with a human. For safe robot operation, we propose the EXit-aware Object Tracker (EXOT) on a robot hand camera that recognizes an object's absence during manipulation. The robot decides whether to proceed by examining the tracker's bounding box output containing the target object. We adopt an out-of-distribution classifier for more accurate object recognition since trackers can mistrack a background as a target object. To the best of our knowledge, our method is the first approach of applying an out-of-distribution classification technique to a tracker output. We evaluate our method on the first-person video benchmark dataset, TREK-150, and on the custom dataset, RMOT-223, that we collect from the UR5e robot. Then we test our tracker on the UR5e robot in real-time with a conveyor-belt sushi task, to examine the tracker's ability to track target dishes and to determine the exit status. Our tracker shows 38% higher exit-aware performance than a baseline method. The dataset and the code will be released at https://github.com/hskAlena/EXOT.
Sensing-based Beamforming Design for Joint Performance Enhancement of RIS-Aided ISAC Systems
Jun 08, 2023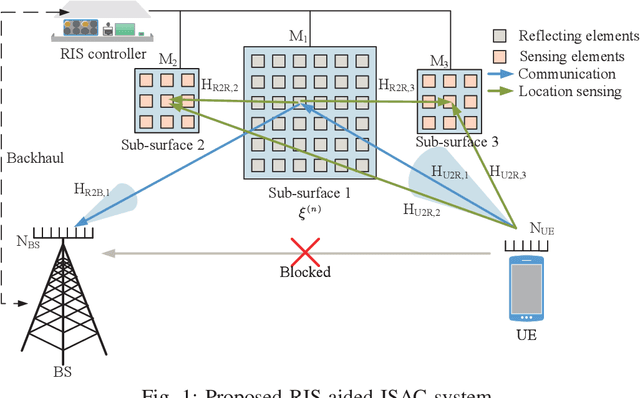
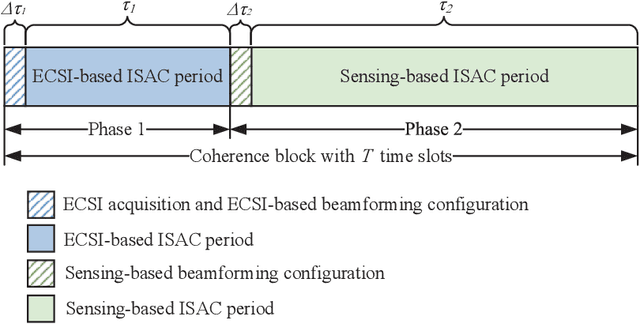

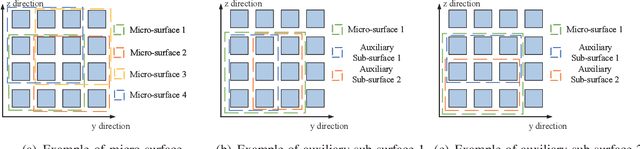
Reconfigurable intelligent surface (RIS) has shown its great potential in facilitating device-based integrated sensing and communication (ISAC), where sensing and communication tasks are mostly conducted on different time-frequency resources. While the more challenging scenarios of simultaneous sensing and communication (SSC) have so far drawn little attention. In this paper, we propose a novel RIS-aided ISAC framework where the inherent location information in the received communication signals from a blind-zone user equipment is exploited to enable SSC. We first design a two-phase ISAC transmission protocol. In the first phase, communication and coarse-grained location sensing are performed concurrently by exploiting the very limited channel state information, while in the second phase, by using the coarse-grained sensing information obtained from the first phase, simple-yet-efficient sensing-based beamforming designs are proposed to realize both higher-rate communication and fine-grained location sensing. We demonstrate that our proposed framework can achieve almost the same performance as the communication-only frameworks, while providing up to millimeter-level positioning accuracy. In addition, we show how the communication and sensing performance can be simultaneously boosted through our proposed sensing-based beamforming designs. The results presented in this work provide valuable insights into the design and implementation of other ISAC systems considering SSC.
Look Beneath the Surface: Exploiting Fundamental Symmetry for Sample-Efficient Offline RL
Jun 08, 2023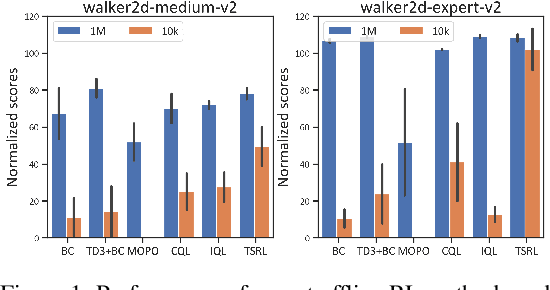
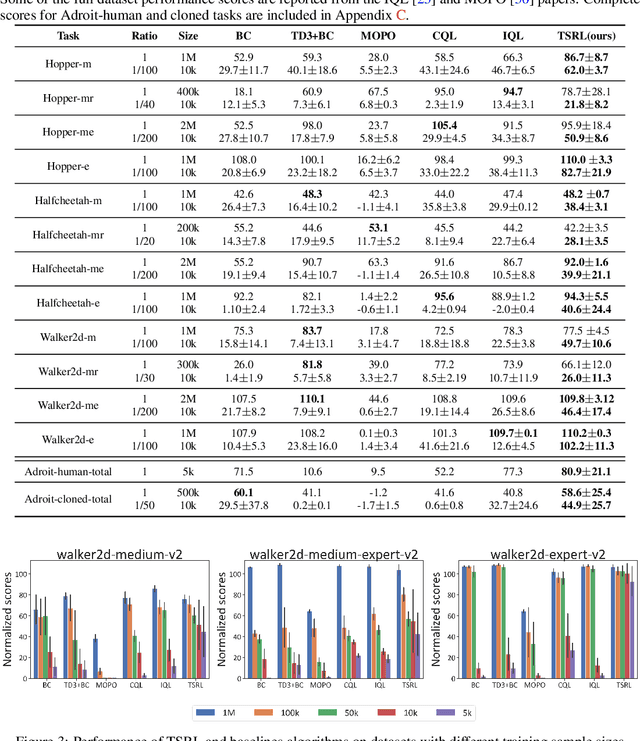
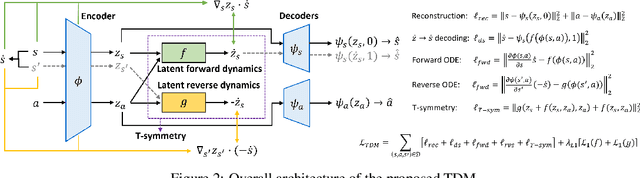

Offline reinforcement learning (RL) offers an appealing approach to real-world tasks by learning policies from pre-collected datasets without interacting with the environment. However, the performance of existing offline RL algorithms heavily depends on the scale and state-action space coverage of datasets. Real-world data collection is often expensive and uncontrollable, leading to small and narrowly covered datasets and posing significant challenges for practical deployments of offline RL. In this paper, we provide a new insight that leveraging the fundamental symmetry of system dynamics can substantially enhance offline RL performance under small datasets. Specifically, we propose a Time-reversal symmetry (T-symmetry) enforced Dynamics Model (TDM), which establishes consistency between a pair of forward and reverse latent dynamics. TDM provides both well-behaved representations for small datasets and a new reliability measure for OOD samples based on compliance with the T-symmetry. These can be readily used to construct a new offline RL algorithm (TSRL) with less conservative policy constraints and a reliable latent space data augmentation procedure. Based on extensive experiments, we find TSRL achieves great performance on small benchmark datasets with as few as 1% of the original samples, which significantly outperforms the recent offline RL algorithms in terms of data efficiency and generalizability.
Continual Learning with Pretrained Backbones by Tuning in the Input Space
Jun 08, 2023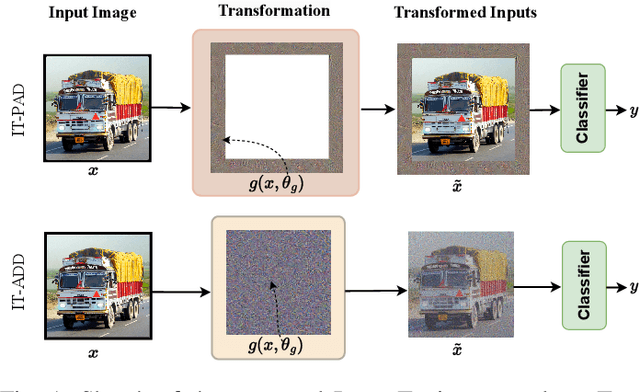
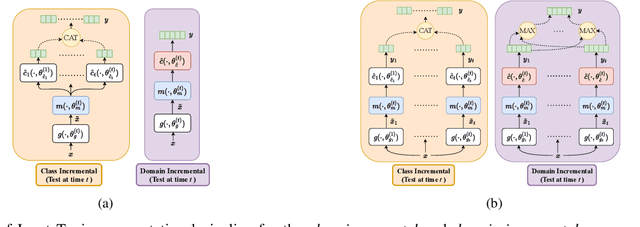
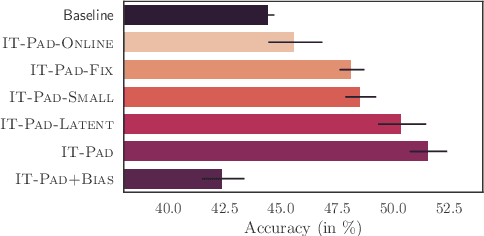
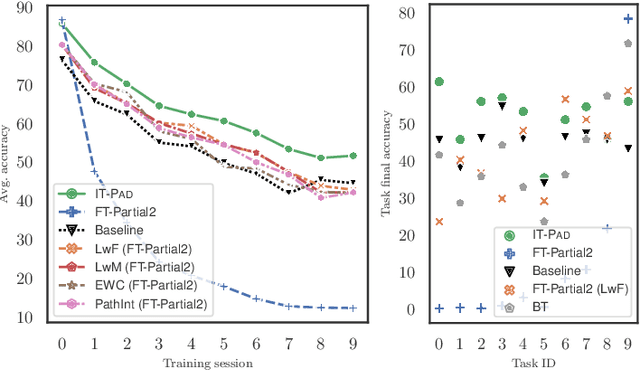
The intrinsic difficulty in adapting deep learning models to non-stationary environments limits the applicability of neural networks to real-world tasks. This issue is critical in practical supervised learning settings, such as the ones in which a pre-trained model computes projections toward a latent space where different task predictors are sequentially learned over time. As a matter of fact, incrementally fine-tuning the whole model to better adapt to new tasks usually results in catastrophic forgetting, with decreasing performance over the past experiences and losing valuable knowledge from the pre-training stage. In this paper, we propose a novel strategy to make the fine-tuning procedure more effective, by avoiding to update the pre-trained part of the network and learning not only the usual classification head, but also a set of newly-introduced learnable parameters that are responsible for transforming the input data. This process allows the network to effectively leverage the pre-training knowledge and find a good trade-off between plasticity and stability with modest computational efforts, thus especially suitable for on-the-edge settings. Our experiments on four image classification problems in a continual learning setting confirm the quality of the proposed approach when compared to several fine-tuning procedures and to popular continual learning methods.