 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ORRN: An ODE-based Recursive Registration Network for Deformable Respiratory Motion Estimation with Lung 4DCT Images
May 24, 2023
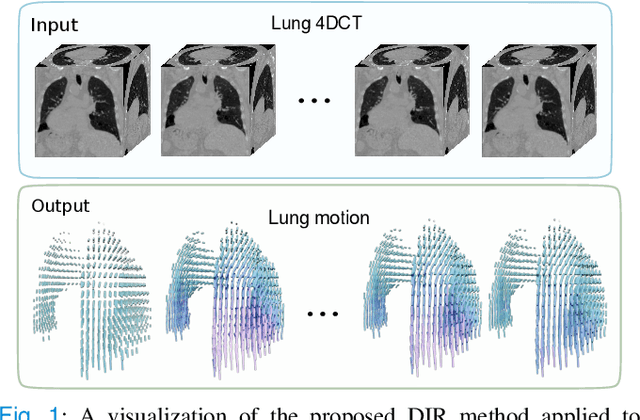
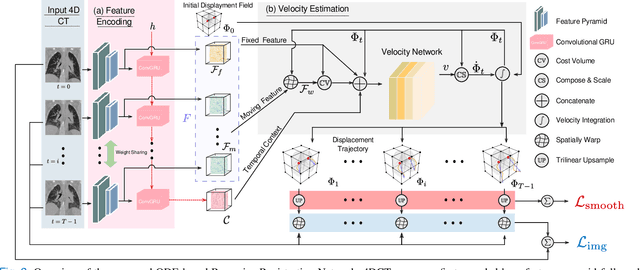
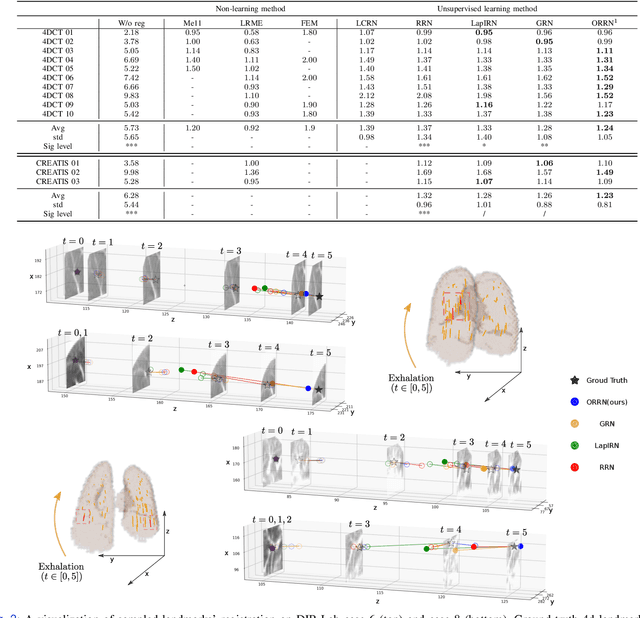
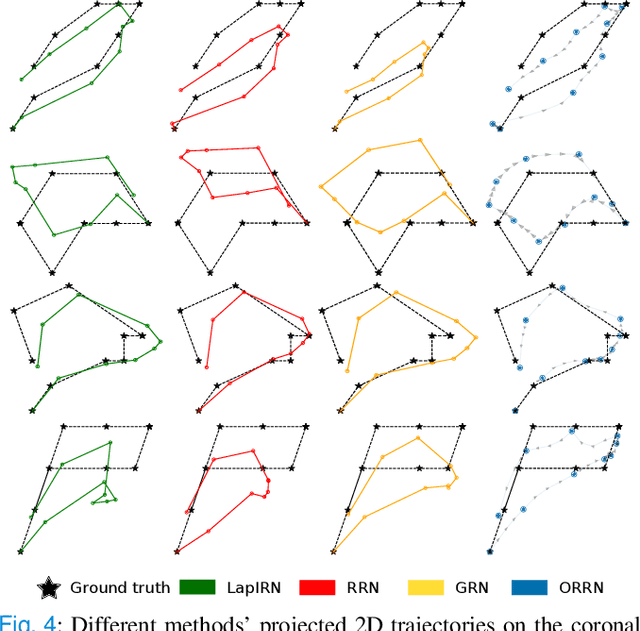
Deformable Image Registration (DIR) plays a significant role in quantifying deformation in medical data. Recent Deep Learning methods have shown promising accuracy and speedup for registering a pair of medical images. However, in 4D (3D + time) medical data, organ motion, such as respiratory motion and heart beating, can not be effectively modeled by pair-wise methods as they were optimized for image pairs but did not consider the organ motion patterns necessary when considering 4D data. This paper presents ORRN, an Ordinary Differential Equations (ODE)-based recursive image registration network. Our network learns to estimate time-varying voxel velocities for an ODE that models deformation in 4D image data. It adopts a recursive registration strategy to progressively estimate a deformation field through ODE integration of voxel velocities. We evaluate the proposed method on two publicly available lung 4DCT datasets, DIRLab and CREATIS, for two tasks: 1) registering all images to the extreme inhale image for 3D+t deformation tracking and 2) registering extreme exhale to inhale phase images. Our method outperforms other learning-based methods in both tasks, producing the smallest Target Registration Error of 1.24mm and 1.26mm, respectively. Additionally, it produces less than 0.001\% unrealistic image folding, and the computation speed is less than 1 second for each CT volume. ORRN demonstrates promising registration accuracy, deformation plausibility, and computation efficiency on group-wise and pair-wise registration tasks. It has significant implications in enabling fast and accurate respiratory motion estimation for treatment planning in radiation therapy or robot motion planning in thoracic needle insertion.
Behavior quantification as the missing link between fields: Tools for digital psychiatry and their role in the future of neurobiology
May 24, 2023The great behavioral heterogeneity observed between individuals with the same psychiatric disorder and even within one individual over time complicates both clinical practice and biomedical research. However, modern technologies are an exciting opportunity to improve behavioral characterization. Existing psychiatry methods that are qualitative or unscalable, such as patient surveys or clinical interviews, can now be collected at a greater capacity and analyzed to produce new quantitative measures. Furthermore, recent capabilities for continuous collection of passive sensor streams, such as phone GPS or smartwatch accelerometer, open avenues of novel questioning that were previously entirely unrealistic. Their temporally dense nature enables a cohesive study of real-time neural and behavioral signals. To develop comprehensive neurobiological models of psychiatric disease, it will be critical to first develop strong methods for behavioral quantification. There is huge potential in what can theoretically be captured by current technologies, but this in itself presents a large computational challenge -- one that will necessitate new data processing tools, new machine learning techniques, and ultimately a shift in how interdisciplinary work is conducted. In my thesis, I detail research projects that take different perspectives on digital psychiatry, subsequently tying ideas together with a concluding discussion on the future of the field. I also provide software infrastructure where relevant, with extensive documentation. Major contributions include scientific arguments and proof of concept results for daily free-form audio journals as an underappreciated psychiatry research datatype, as well as novel stability theorems and pilot empirical success for a proposed multi-area recurrent neural network architecture.
Reconstruction, forecasting, and stability of chaotic dynamics from partial data
May 24, 2023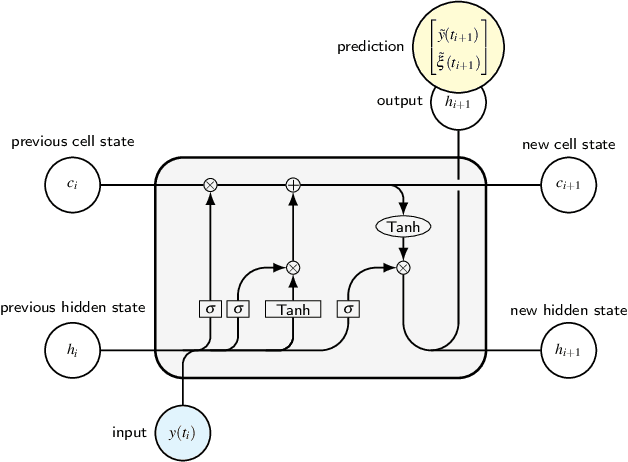
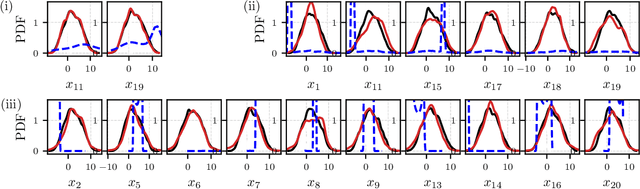
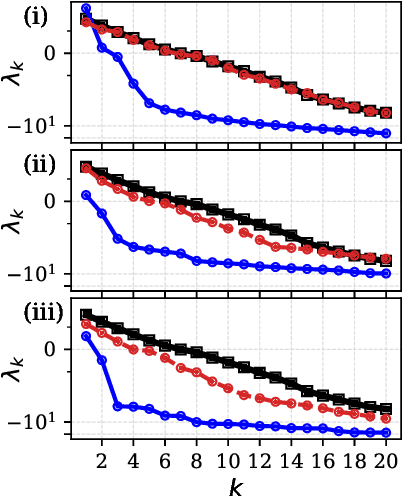
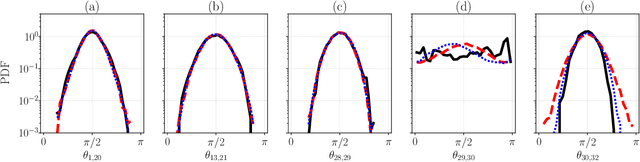
The forecasting and computation of the stability of chaotic systems from partial observations are tasks for which traditional equation-based methods may not be suitable. In this computational paper, we propose data-driven methods to (i) infer the dynamics of unobserved (hidden) chaotic variables (full-state reconstruction); (ii) time forecast the evolution of the full state; and (iii) infer the stability properties of the full state. The tasks are performed with long short-term memory (LSTM) networks, which are trained with observations (data) limited to only part of the state: (i) the low-to-high resolution LSTM (LH-LSTM), which takes partial observations as training input, and requires access to the full system state when computing the loss; and (ii) the physics-informed LSTM (PI-LSTM), which is designed to combine partial observations with the integral formulation of the dynamical system's evolution equations. First, we derive the Jacobian of the LSTMs. Second, we analyse a chaotic partial differential equation, the Kuramoto-Sivashinsky (KS), and the Lorenz-96 system. We show that the proposed networks can forecast the hidden variables, both time-accurately and statistically. The Lyapunov exponents and covariant Lyapunov vectors, which characterize the stability of the chaotic attractors, are correctly inferred from partial observations. Third, the PI-LSTM outperforms the LH-LSTM by successfully reconstructing the hidden chaotic dynamics when the input dimension is smaller or similar to the Kaplan-Yorke dimension of the attractor. This work opens new opportunities for reconstructing the full state, inferring hidden variables, and computing the stability of chaotic systems from partial data.
On the Minimax Regret for Online Learning with Feedback Graphs
May 24, 2023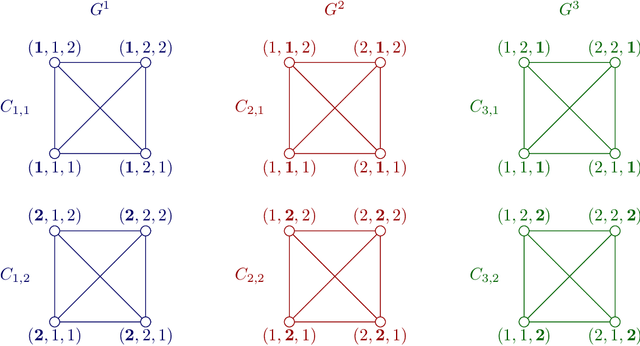
In this work, we improve on the upper and lower bounds for the regret of online learning with strongly observable undirected feedback graphs. The best known upper bound for this problem is $\mathcal{O}\bigl(\sqrt{\alpha T\ln K}\bigr)$, where $K$ is the number of actions, $\alpha$ is the independence number of the graph, and $T$ is the time horizon. The $\sqrt{\ln K}$ factor is known to be necessary when $\alpha = 1$ (the experts case). On the other hand, when $\alpha = K$ (the bandits case), the minimax rate is known to be $\Theta\bigl(\sqrt{KT}\bigr)$, and a lower bound $\Omega\bigl(\sqrt{\alpha T}\bigr)$ is known to hold for any $\alpha$. Our improved upper bound $\mathcal{O}\bigl(\sqrt{\alpha T(1+\ln(K/\alpha))}\bigr)$ holds for any $\alpha$ and matches the lower bounds for bandits and experts, while interpolating intermediate cases. To prove this result, we use FTRL with $q$-Tsallis entropy for a carefully chosen value of $q \in [1/2, 1)$ that varies with $\alpha$. The analysis of this algorithm requires a new bound on the variance term in the regret. We also show how to extend our techniques to time-varying graphs, without requiring prior knowledge of their independence numbers. Our upper bound is complemented by an improved $\Omega\bigl(\sqrt{\alpha T(\ln K)/(\ln\alpha)}\bigr)$ lower bound for all $\alpha > 1$, whose analysis relies on a novel reduction to multitask learning. This shows that a logarithmic factor is necessary as soon as $\alpha < K$.
Pilot Design and Doubly-Selective Channel Estimation for Faster-than-Nyquist Signaling
May 24, 2023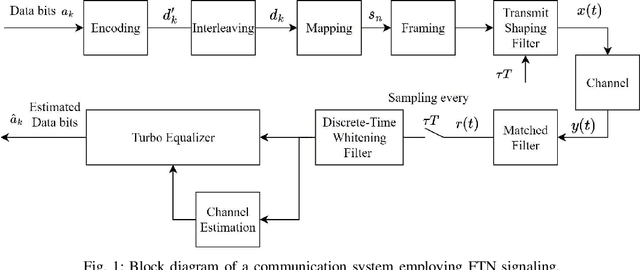
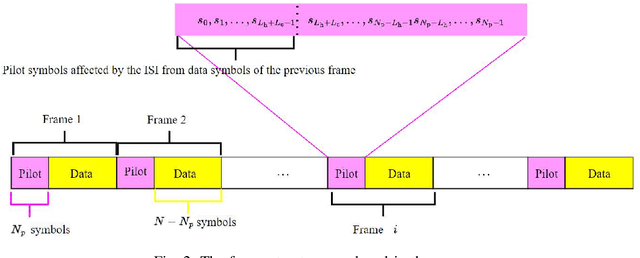
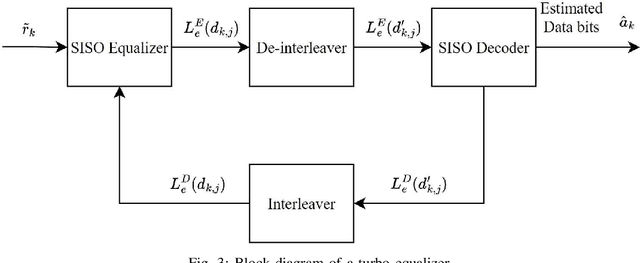
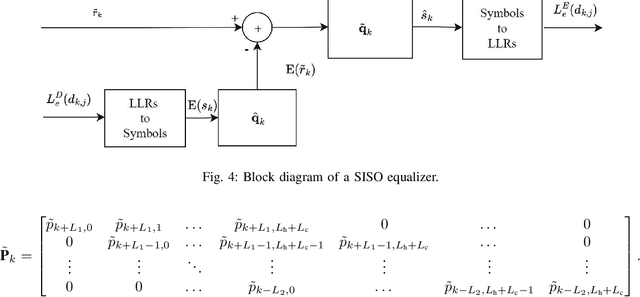
Being capable of enhancing the spectral efficiency (SE), faster-than-Nyquist (FTN) signaling is a promising approach for wireless communication systems. This paper investigates the doubly-selective (i.e., time- and frequency-selective) channel estimation and data detection of FTN signaling. We consider the intersymbol interference (ISI) resulting from both the FTN signaling and the frequency-selective channel and adopt an efficient frame structure with reduced overhead. We propose a novel channel estimation technique of FTN signaling based on the least sum of squared errors (LSSE) approach to estimate the complex channel coefficients at the pilot locations within the frame. In particular, we find the optimal pilot sequence that minimizes the mean square error (MSE) of the channel estimation. To address the time-selective nature of the channel, we use a low-complexity linear interpolation to track the complex channel coefficients at the data symbols locations within the frame. To detect the data symbols of FTN signaling, we adopt a turbo equalization technique based on a linear soft-input soft-output (SISO) minimum mean square error (MMSE) equalizer. Simulation results show that the MSE of the proposed FTN signaling channel estimation employing the designed optimal pilot sequence is lower than its counterpart designed for conventional Nyquist transmission. The bit error rate (BER) of the FTN signaling employing the proposed optimal pilot sequence shows improvement compared to the FTN signaling employing the conventional Nyquist pilot sequence. Additionally, for the same SE, the proposed FTN signaling channel estimation employing the designed optimal pilot sequence shows better performance when compared to competing techniques from the literature.
The NTK approximation is valid for longer than you think
May 22, 2023We study when the neural tangent kernel (NTK) approximation is valid for training a model with the square loss. In the lazy training setting of Chizat et al. 2019, we show that rescaling the model by a factor of $\alpha = O(T)$ suffices for the NTK approximation to be valid until training time $T$. Our bound is tight and improves on the previous bound of Chizat et al. 2019, which required a larger rescaling factor of $\alpha = O(T^2)$.
River of No Return: Graph Percolation Embeddings for Efficient Knowledge Graph Reasoning
May 17, 2023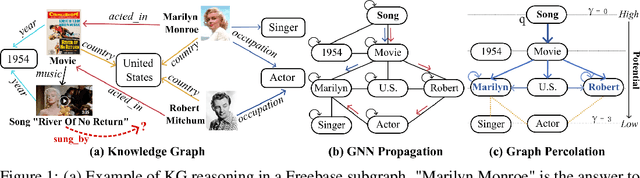
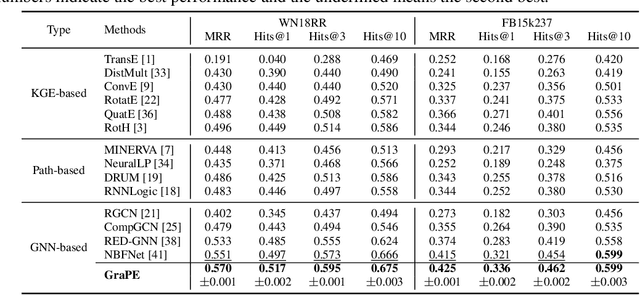

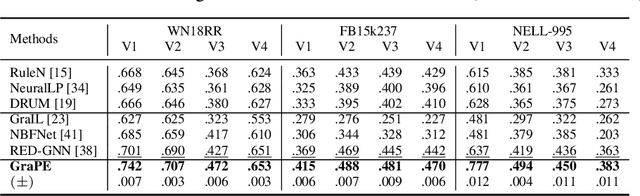
We study Graph Neural Networks (GNNs)-based embedding techniques for knowledge graph (KG) reasoning. For the first time, we link the path redundancy issue in the state-of-the-art KG reasoning models based on path encoding and message passing to the transformation error in model training, which brings us new theoretical insights into KG reasoning, as well as high efficacy in practice. On the theoretical side, we analyze the entropy of transformation error in KG paths and point out query-specific redundant paths causing entropy increases. These findings guide us to maintain the shortest paths and remove redundant paths for minimized-entropy message passing. To achieve this goal, on the practical side, we propose an efficient Graph Percolation Process motivated by the percolation model in Fluid Mechanics, and design a lightweight GNN-based KG reasoning framework called Graph Percolation Embeddings (GraPE). GraPE outperforms previous state-of-the-art methods in both transductive and inductive reasoning tasks while requiring fewer training parameters and less inference time.
Guiding Pseudo-labels with Uncertainty Estimation for Test-Time Adaptation
Mar 07, 2023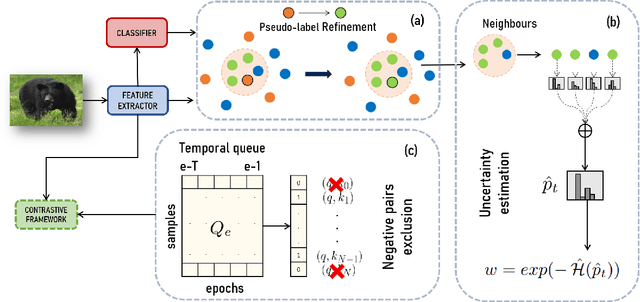
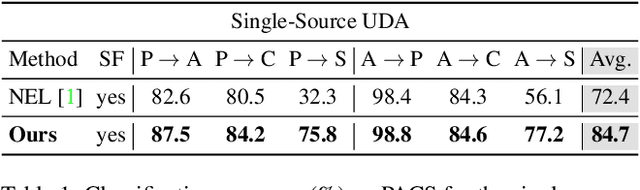
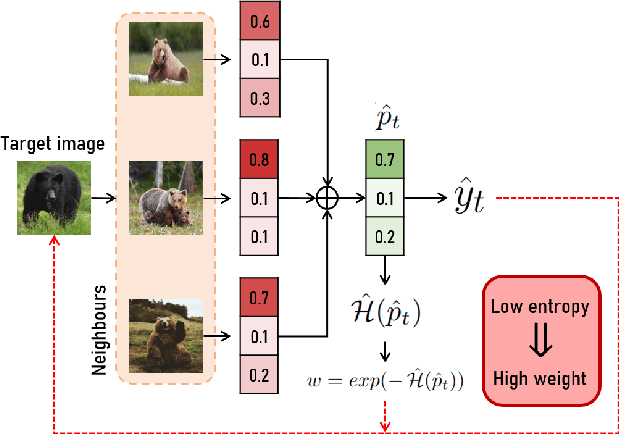
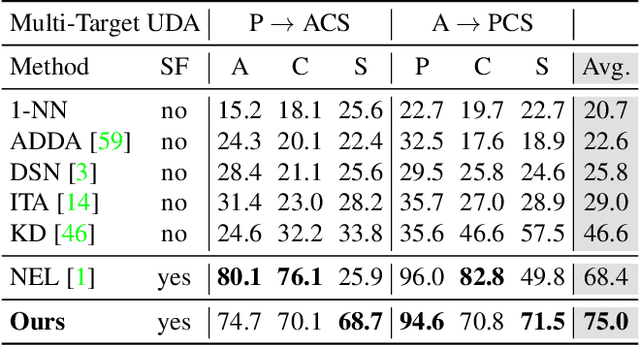
Standard Unsupervised Domain Adaptation (UDA) methods assume the availability of both source and target data during the adaptation. In this work, we investigate the Test-Time Adaptation (TTA), a specific case of UDA where a model is adapted to a target domain without access to source data. We propose a novel approach for the TTA setting based on a loss reweighting strategy that brings robustness against the noise that inevitably affects the pseudo-labels. The classification loss is reweighted based on the reliability of the pseudo-labels that is measured by estimating their uncertainty. Guided by such reweighting strategy, the pseudo-labels are progressively refined by aggregating knowledge from neighbouring samples. Furthermore, a self-supervised contrastive framework is leveraged as a target space regulariser to enhance such knowledge aggregation. A novel negative pairs exclusion strategy is proposed to identify and exclude negative pairs made of samples sharing the same class, even in presence of some noise in the pseudo-labels. Our method outperforms previous methods on three major benchmarks by a large margin. We set the new TTA state-of-the-art on VisDA-C and DomainNet with a performance gain of +1.8\% on both benchmarks and on PACS with +12.3\% in the single-source setting and +6.6\% in\ multi-target adaptation. Additional analyses demonstrate that the proposed approach is robust to the noise, which results in significantly more accurate pseudo-labels compared to state-of-the-art approaches.
Generative Diffusion for 3D Turbulent Flows
May 29, 2023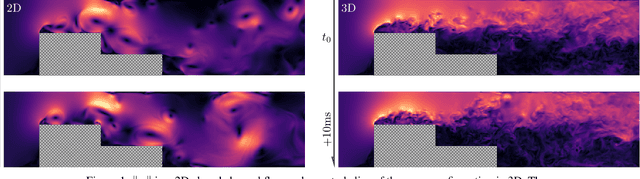
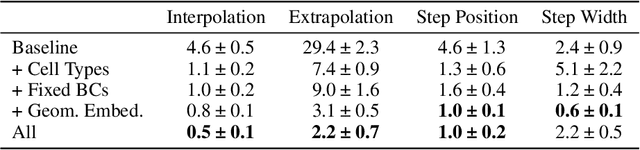
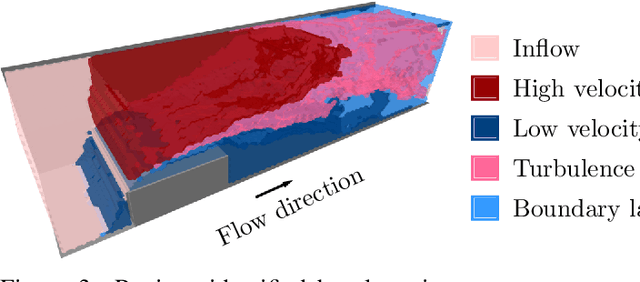
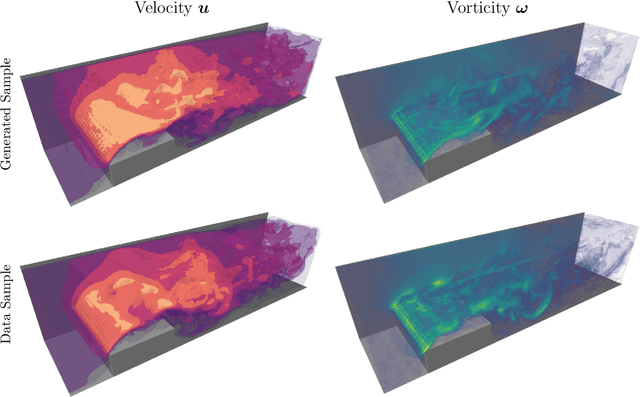
Turbulent flows are well known to be chaotic and hard to predict; however, their dynamics differ between two and three dimensions. While 2D turbulence tends to form large, coherent structures, in three dimensions vortices cascade to smaller and smaller scales. This cascade creates many fast-changing, small-scale structures and amplifies the unpredictability, making regression-based methods infeasible. We propose the first generative model for forced turbulence in arbitrary 3D geometries and introduce a sample quality metric for turbulent flows based on the Wasserstein distance of the generated velocity-vorticity distribution. In several experiments, we show that our generative diffusion model circumvents the unpredictability of turbulent flows and produces high-quality samples based solely on geometric information. Furthermore, we demonstrate that our model beats an industrial-grade numerical solver in the time to generate a turbulent flow field from scratch by an order of magnitude.
Sequential Condition Evolved Interaction Knowledge Graph for Traditional Chinese Medicine Recommendation
May 29, 2023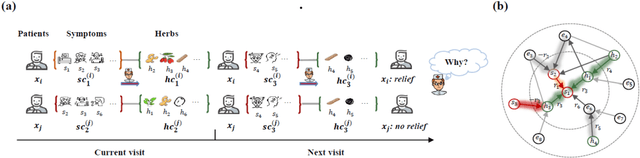
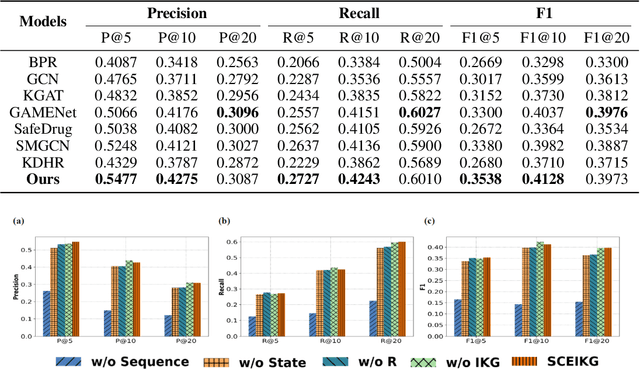
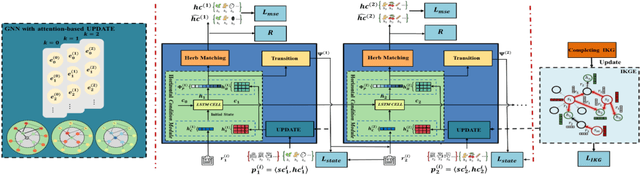
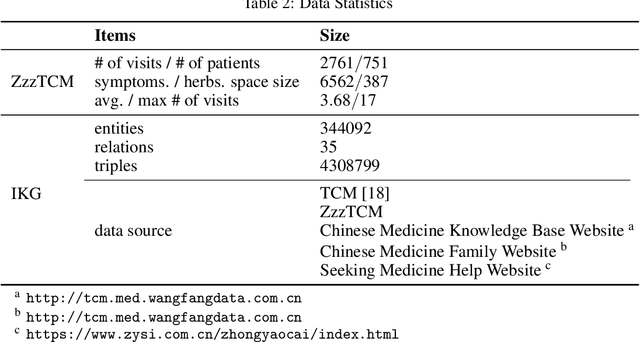
Traditional Chinese Medicine (TCM) has a rich history of utilizing natural herbs to treat a diversity of illnesses. In practice, TCM diagnosis and treatment are highly personalized and organically holistic, requiring comprehensive consideration of the patient's state and symptoms over time. However, existing TCM recommendation approaches overlook the changes in patient status and only explore potential patterns between symptoms and prescriptions. In this paper, we propose a novel Sequential Condition Evolved Interaction Knowledge Graph (SCEIKG), a framework that treats the model as a sequential prescription-making problem by considering the dynamics of the patient's condition across multiple visits. In addition, we incorporate an interaction knowledge graph to enhance the accuracy of recommendations by considering the interactions between different herbs and the patient's condition. Experimental results on a real-world dataset demonstrate that our approach outperforms existing TCM recommendation methods, achieving state-of-the-art performance.