 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Transformer-based Hyper-parameter Optimization for Resource-constrained IoT Environments
Mar 18, 2024
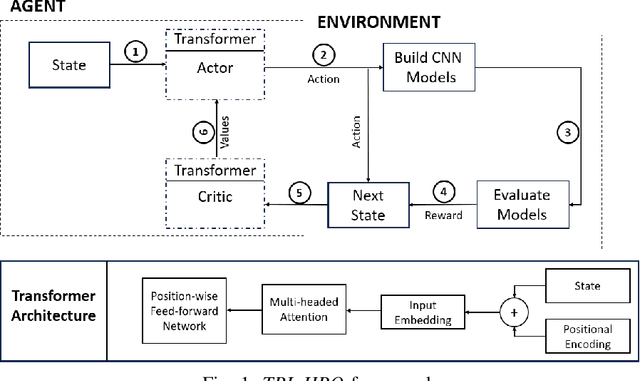
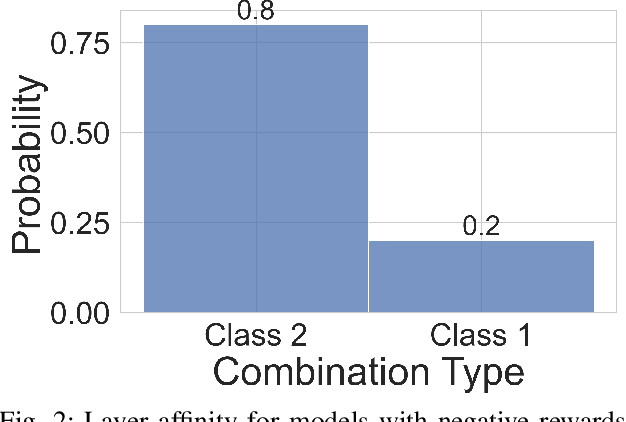
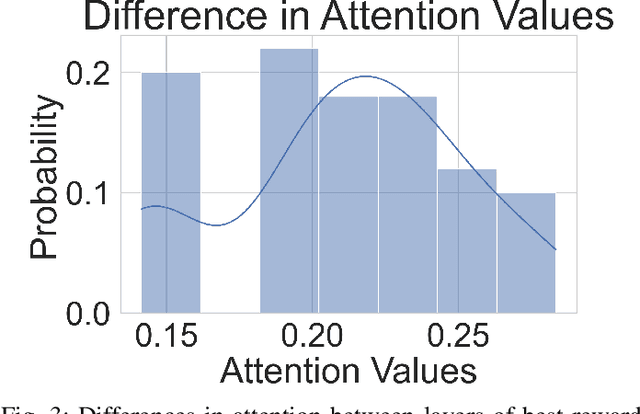
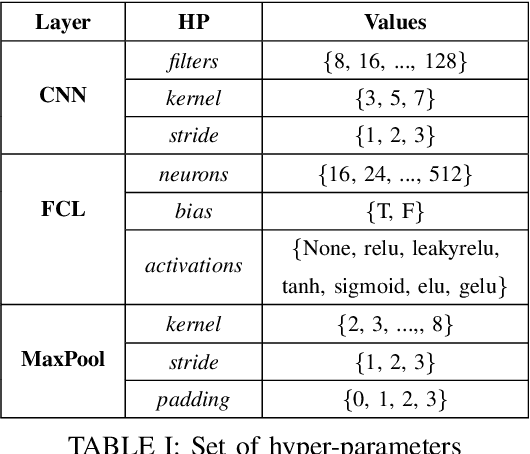
The hyper-parameter optimization (HPO) process is imperative for finding the best-performing Convolutional Neural Networks (CNNs). The automation process of HPO is characterized by its sizable computational footprint and its lack of transparency; both important factors in a resource-constrained Internet of Things (IoT) environment. In this paper, we address these problems by proposing a novel approach that combines transformer architecture and actor-critic Reinforcement Learning (RL) model, TRL-HPO, equipped with multi-headed attention that enables parallelization and progressive generation of layers. These assumptions are founded empirically by evaluating TRL-HPO on the MNIST dataset and comparing it with state-of-the-art approaches that build CNN models from scratch. The results show that TRL-HPO outperforms the classification results of these approaches by 6.8% within the same time frame, demonstrating the efficiency of TRL-HPO for the HPO process. The analysis of the results identifies the main culprit for performance degradation attributed to stacking fully connected layers. This paper identifies new avenues for improving RL-based HPO processes in resource-constrained environments.
FLex: Joint Pose and Dynamic Radiance Fields Optimization for Stereo Endoscopic Videos
Mar 18, 2024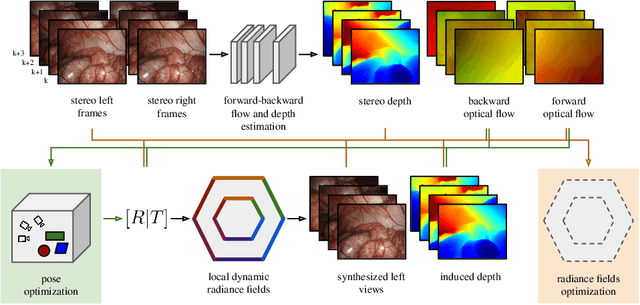
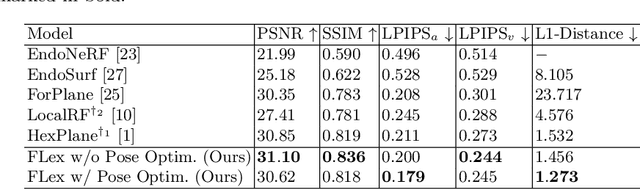
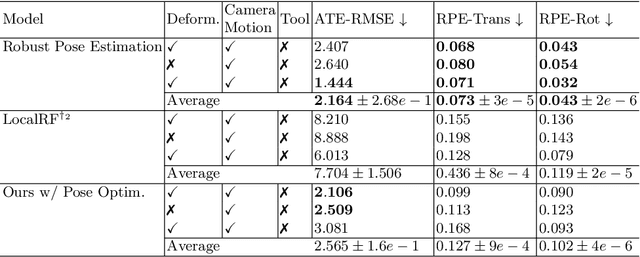
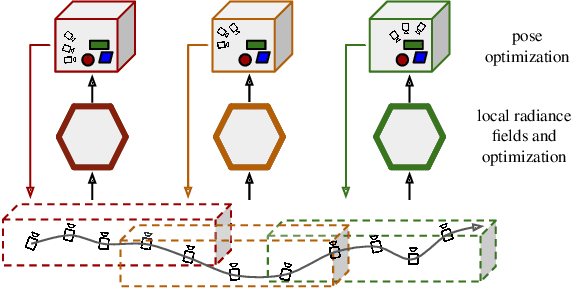
Reconstruction of endoscopic scenes is an important asset for various medical applications, from post-surgery analysis to educational training. Neural rendering has recently shown promising results in endoscopic reconstruction with deforming tissue. However, the setup has been restricted to a static endoscope, limited deformation, or required an external tracking device to retrieve camera pose information of the endoscopic camera. With FLex we adress the challenging setup of a moving endoscope within a highly dynamic environment of deforming tissue. We propose an implicit scene separation into multiple overlapping 4D neural radiance fields (NeRFs) and a progressive optimization scheme jointly optimizing for reconstruction and camera poses from scratch. This improves the ease-of-use and allows to scale reconstruction capabilities in time to process surgical videos of 5,000 frames and more; an improvement of more than ten times compared to the state of the art while being agnostic to external tracking information. Extensive evaluations on the StereoMIS dataset show that FLex significantly improves the quality of novel view synthesis while maintaining competitive pose accuracy.
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
Mar 18, 2024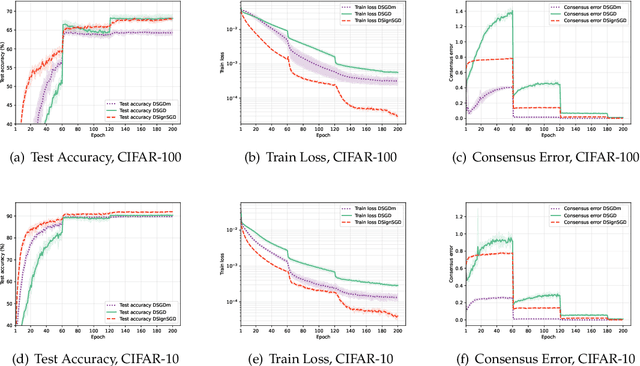
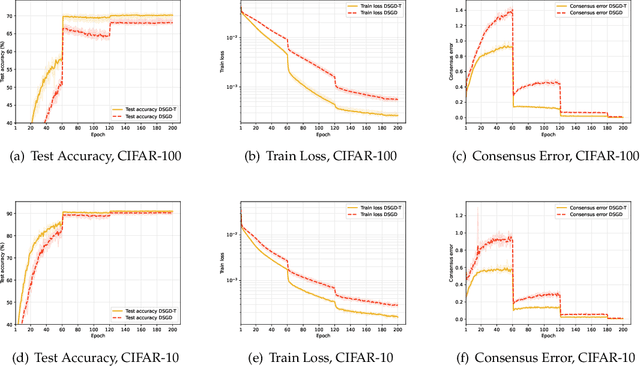
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework, named DSM, to analyze the global convergence of decentralized stochastic subgradient methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework encompasses a wide range of existing efficient decentralized subgradient methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGDm). In addition, we introduce SignSGD employing the sign map to regularize the update directions in DSGDm, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient methods with convergence guarantees in the training of nonsmooth neural networks.
Better (pseudo-)labels for semi-supervised instance segmentation
Mar 18, 2024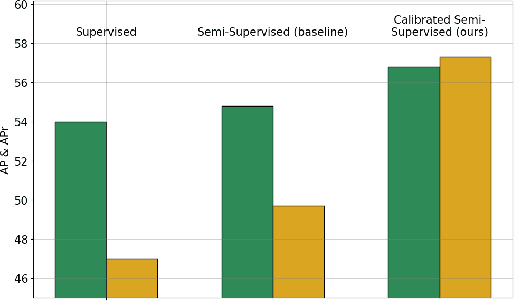
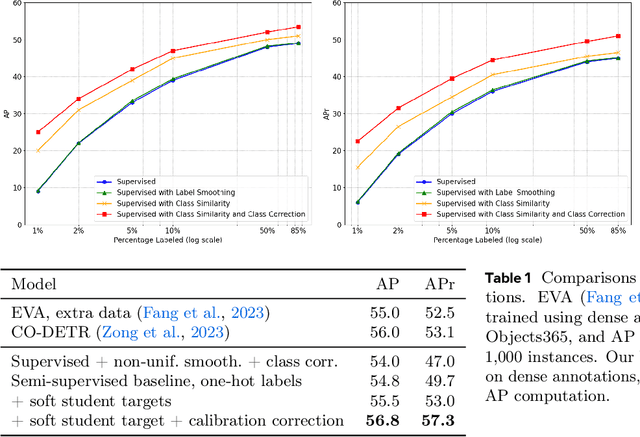
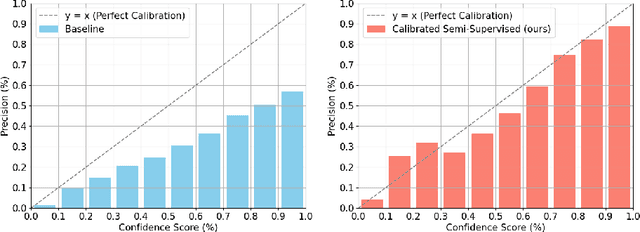
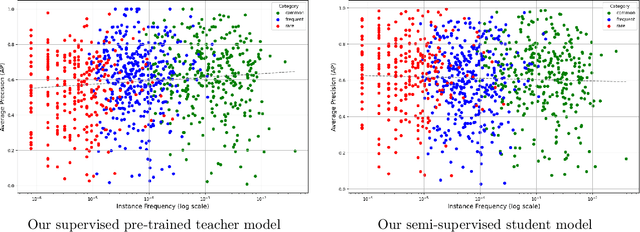
Despite the availability of large datasets for tasks like image classification and image-text alignment, labeled data for more complex recognition tasks, such as detection and segmentation, is less abundant. In particular, for instance segmentation annotations are time-consuming to produce, and the distribution of instances is often highly skewed across classes. While semi-supervised teacher-student distillation methods show promise in leveraging vast amounts of unlabeled data, they suffer from miscalibration, resulting in overconfidence in frequently represented classes and underconfidence in rarer ones. Additionally, these methods encounter difficulties in efficiently learning from a limited set of examples. We introduce a dual-strategy to enhance the teacher model's training process, substantially improving the performance on few-shot learning. Secondly, we propose a calibration correction mechanism that that enables the student model to correct the teacher's calibration errors. Using our approach, we observed marked improvements over a state-of-the-art supervised baseline performance on the LVIS dataset, with an increase of 2.8% in average precision (AP) and 10.3% gain in AP for rare classes.
TCNet: Continuous Sign Language Recognition from Trajectories and Correlated Regions
Mar 18, 2024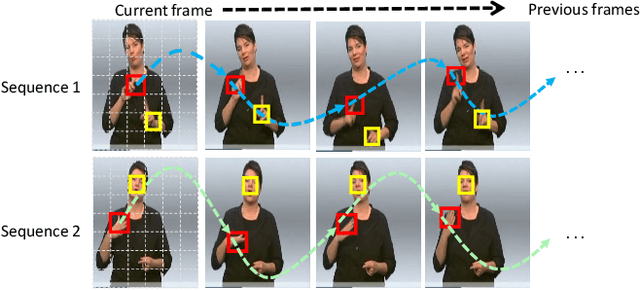
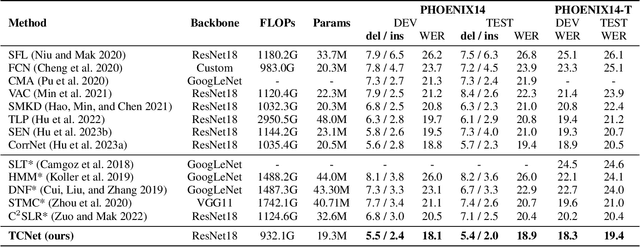
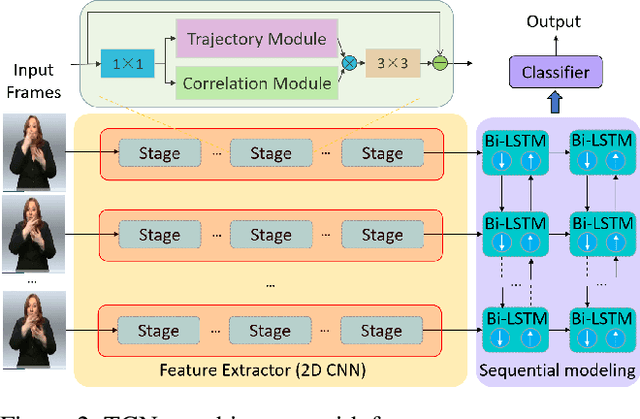
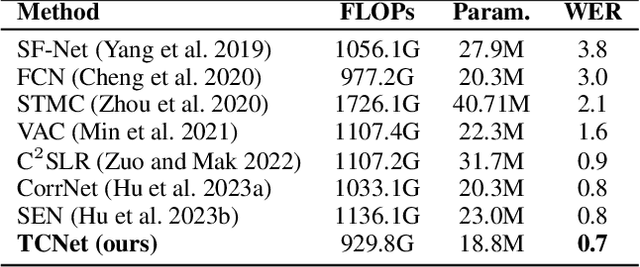
A key challenge in continuous sign language recognition (CSLR) is to efficiently capture long-range spatial interactions over time from the video input. To address this challenge, we propose TCNet, a hybrid network that effectively models spatio-temporal information from Trajectories and Correlated regions. TCNet's trajectory module transforms frames into aligned trajectories composed of continuous visual tokens. In addition, for a query token, self-attention is learned along the trajectory. As such, our network can also focus on fine-grained spatio-temporal patterns, such as finger movements, of a specific region in motion. TCNet's correlation module uses a novel dynamic attention mechanism that filters out irrelevant frame regions. Additionally, it assigns dynamic key-value tokens from correlated regions to each query. Both innovations significantly reduce the computation cost and memory. We perform experiments on four large-scale datasets: PHOENIX14, PHOENIX14-T, CSL, and CSL-Daily, respectively. Our results demonstrate that TCNet consistently achieves state-of-the-art performance. For example, we improve over the previous state-of-the-art by 1.5% and 1.0% word error rate on PHOENIX14 and PHOENIX14-T, respectively.
Binary Noise for Binary Tasks: Masked Bernoulli Diffusion for Unsupervised Anomaly Detection
Mar 18, 2024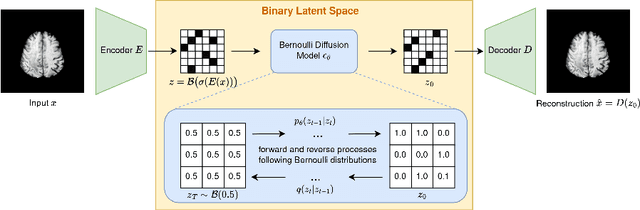
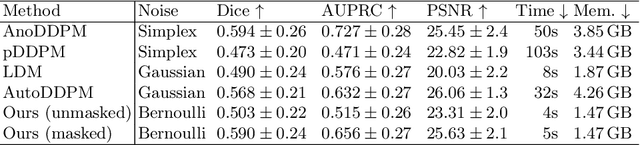
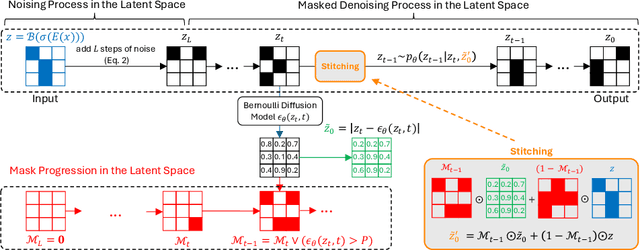
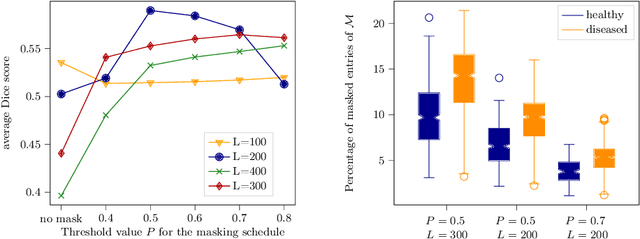
The high performance of denoising diffusion models for image generation has paved the way for their application in unsupervised medical anomaly detection. As diffusion-based methods require a lot of GPU memory and have long sampling times, we present a novel and fast unsupervised anomaly detection approach based on latent Bernoulli diffusion models. We first apply an autoencoder to compress the input images into a binary latent representation. Next, a diffusion model that follows a Bernoulli noise schedule is employed to this latent space and trained to restore binary latent representations from perturbed ones. The binary nature of this diffusion model allows us to identify entries in the latent space that have a high probability of flipping their binary code during the denoising process, which indicates out-of-distribution data. We propose a masking algorithm based on these probabilities, which improves the anomaly detection scores. We achieve state-of-the-art performance compared to other diffusion-based unsupervised anomaly detection algorithms while significantly reducing sampling time and memory consumption. The code is available at https://github.com/JuliaWolleb/Anomaly_berdiff.
Semantic Prompting with Image-Token for Continual Learning
Mar 18, 2024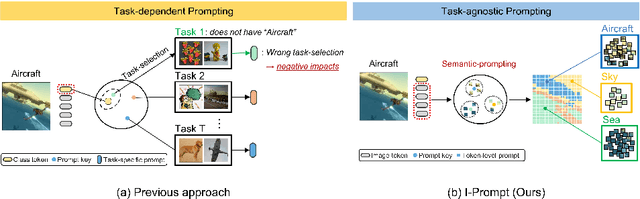
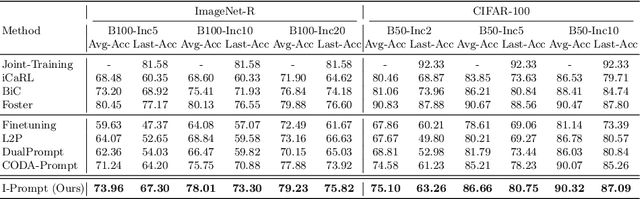
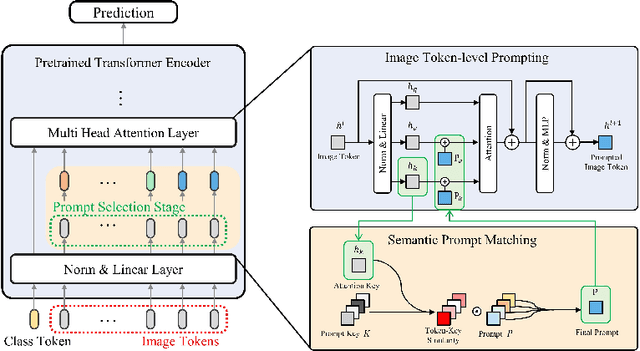
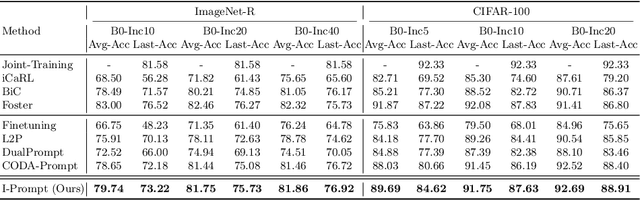
Continual learning aims to refine model parameters for new tasks while retaining knowledge from previous tasks. Recently, prompt-based learning has emerged to leverage pre-trained models to be prompted to learn subsequent tasks without the reliance on the rehearsal buffer. Although this approach has demonstrated outstanding results, existing methods depend on preceding task-selection process to choose appropriate prompts. However, imperfectness in task-selection may lead to negative impacts on the performance particularly in the scenarios where the number of tasks is large or task distributions are imbalanced. To address this issue, we introduce I-Prompt, a task-agnostic approach focuses on the visual semantic information of image tokens to eliminate task prediction. Our method consists of semantic prompt matching, which determines prompts based on similarities between tokens, and image token-level prompting, which applies prompts directly to image tokens in the intermediate layers. Consequently, our method achieves competitive performance on four benchmarks while significantly reducing training time compared to state-of-the-art methods. Moreover, we demonstrate the superiority of our method across various scenarios through extensive experiments.
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Mar 18, 2024
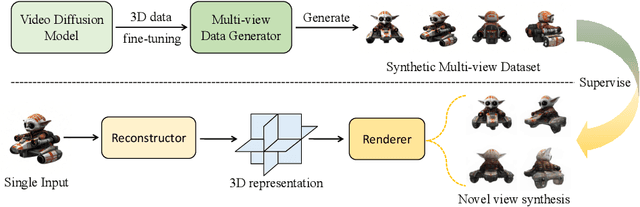
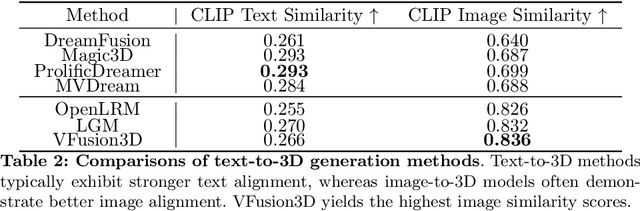

This paper presents a novel paradigm for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 70% of the time.
Smart Resource Allocation at mmWave/THz Frequencies with Cooperative Rate-Splitting
Mar 14, 2024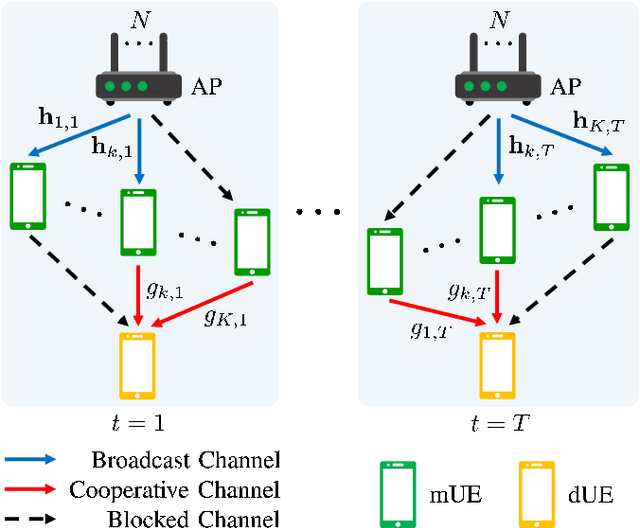
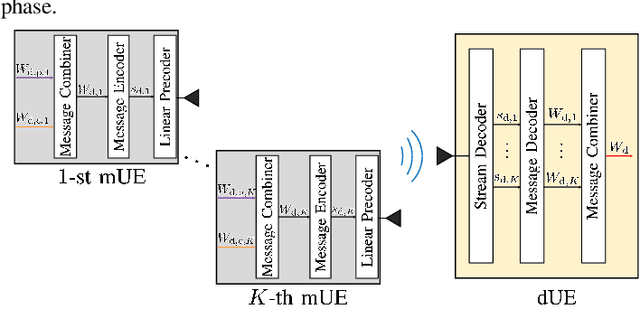
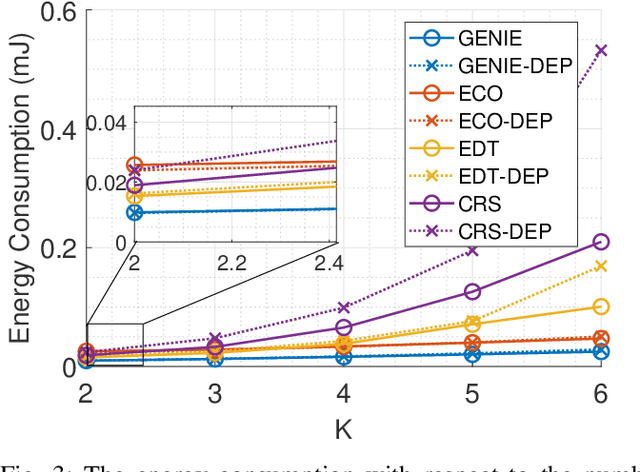
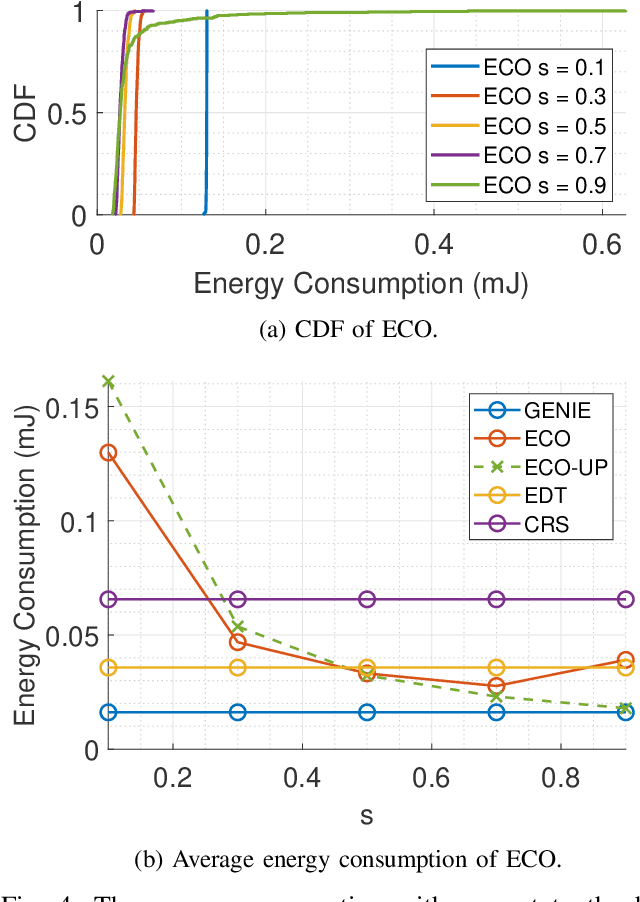
In this paper, we propose algorithms to minimize the energy consumption in millimeter wave/terahertz multi-user downlink communication systems. To ensure coverage in blockage-vulnerable high frequency systems, we consider cooperative rate-splitting (CRS) and transmission over multiple time blocks, where via CRS, multiple users cooperate to assist a blocked user. Moreover, we show that transmission over multiple time blocks provides benefits through smart resource allocation. We first propose a communication framework named improved distinct extraction-based CRS (iDeCRS) that utilizes the benefits of rate-splitting. With our transmission framework, we derive a performance benchmark assuming genie channel state information (CSI), i.e., the channels of the present and future time blocks are known, denoted as GENIE. Using the results from GENIE, we derive a novel efficiency constrained optimization (ECO) algorithm assuming instantaneous CSI. In addition, a simple but effective even data transmission (EDT) algorithm that promotes steady transmission along the time blocks is proposed. Simulation results show that ECO and EDT have satisfactory performances compared to GENIE. The results also show that ECO outperforms EDT when many users are cooperating, and vise versa.
Context-based Fast Recommendation Strategy for Long User Behavior Sequence in Meituan Waimai
Mar 19, 2024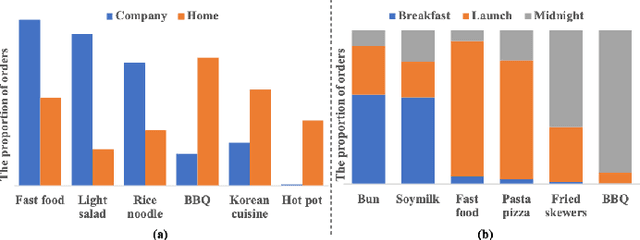
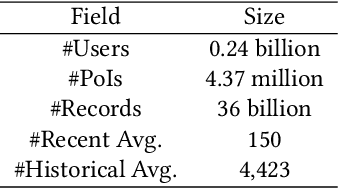
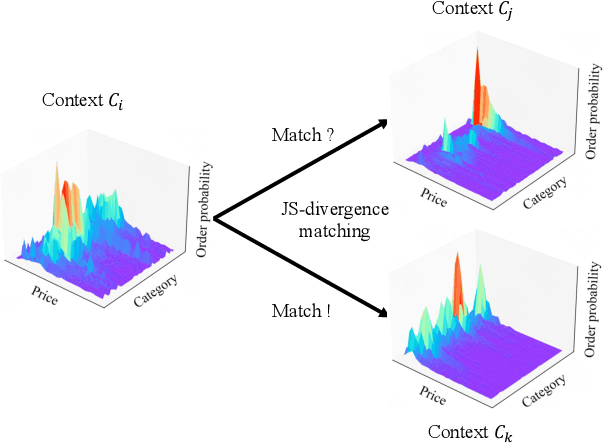
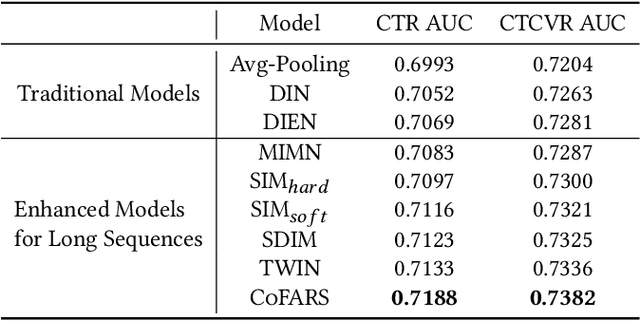
In the recommender system of Meituan Waimai, we are dealing with ever-lengthening user behavior sequences, which pose an increasing challenge to modeling user preference effectively. Existing sequential recommendation models often fail to capture long-term dependencies or are too complex, complicating the fulfillment of Meituan Waimai's unique business needs. To better model user interests, we consider selecting relevant sub-sequences from users' extensive historical behaviors based on their preferences. In this specific scenario, we've noticed that the contexts in which users interact have a significant impact on their preferences. For this purpose, we introduce a novel method called Context-based Fast Recommendation Strategy to tackle the issue of long sequences. We first identify contexts that share similar user preferences with the target context and then locate the corresponding PoIs based on these identified contexts. This approach eliminates the necessity to select a sub-sequence for every candidate PoI, thereby avoiding high time complexity. Specifically, we implement a prototype-based approach to pinpoint contexts that mirror similar user preferences. To amplify accuracy and interpretability, we employ JS divergence of PoI attributes such as categories and prices as a measure of similarity between contexts. A temporal graph integrating both prototype and context nodes helps incorporate temporal information. We then identify appropriate prototypes considering both target contexts and short-term user preferences. Following this, we utilize contexts aligned with these prototypes to generate a sub-sequence, aimed at predicting CTR and CTCVR scores with target attention. Since its inception in 2023, this strategy has been adopted in Meituan Waimai's display recommender system, leading to a 4.6% surge in CTR and a 4.2% boost in GMV.