 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detection
Jun 06, 2023

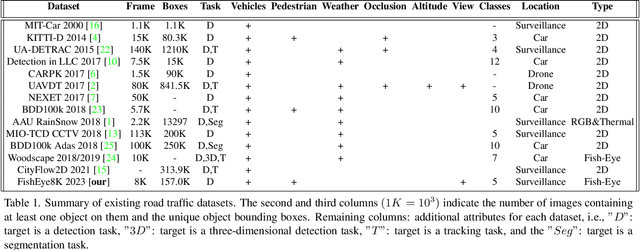
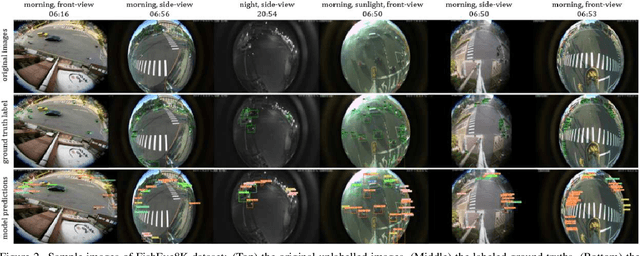
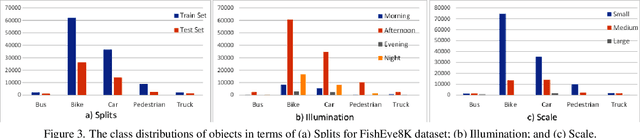
With the advance of AI, road object detection has been a prominent topic in computer vision, mostly using perspective cameras. Fisheye lens provides omnidirectional wide coverage for using fewer cameras to monitor road intersections, however with view distortions. To our knowledge, there is no existing open dataset prepared for traffic surveillance on fisheye cameras. This paper introduces an open FishEye8K benchmark dataset for road object detection tasks, which comprises 157K bounding boxes across five classes (Pedestrian, Bike, Car, Bus, and Truck). In addition, we present benchmark results of State-of-The-Art (SoTA) models, including variations of YOLOv5, YOLOR, YOLO7, and YOLOv8. The dataset comprises 8,000 images recorded in 22 videos using 18 fisheye cameras for traffic monitoring in Hsinchu, Taiwan, at resolutions of 1080$\times$1080 and 1280$\times$1280. The data annotation and validation process were arduous and time-consuming, due to the ultra-wide panoramic and hemispherical fisheye camera images with large distortion and numerous road participants, particularly people riding scooters. To avoid bias, frames from a particular camera were assigned to either the training or test sets, maintaining a ratio of about 70:30 for both the number of images and bounding boxes in each class. Experimental results show that YOLOv8 and YOLOR outperform on input sizes 640$\times$640 and 1280$\times$1280, respectively. The dataset will be available on GitHub with PASCAL VOC, MS COCO, and YOLO annotation formats. The FishEye8K benchmark will provide significant contributions to the fisheye video analytics and smart city applications.
SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds
Jun 03, 2023
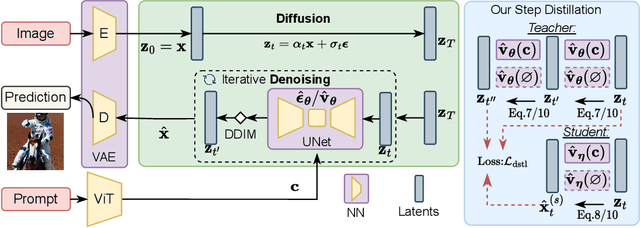
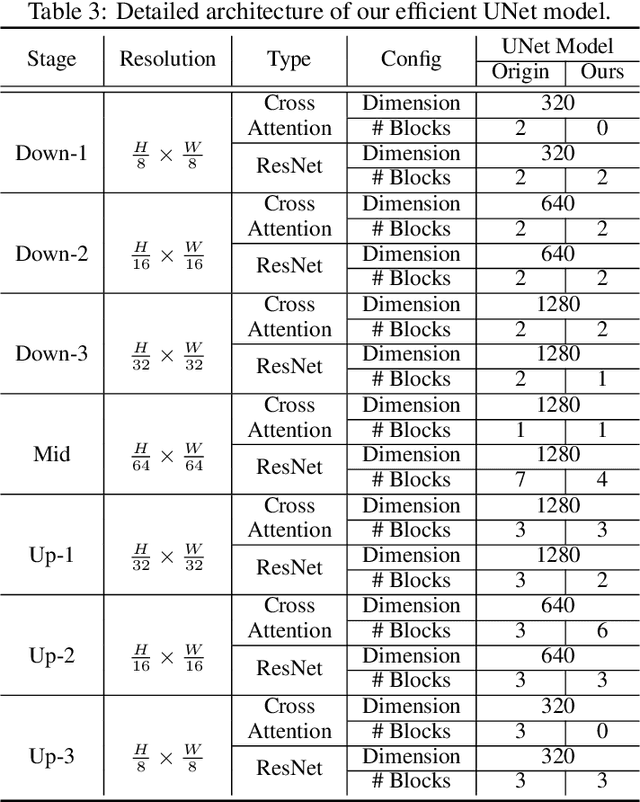
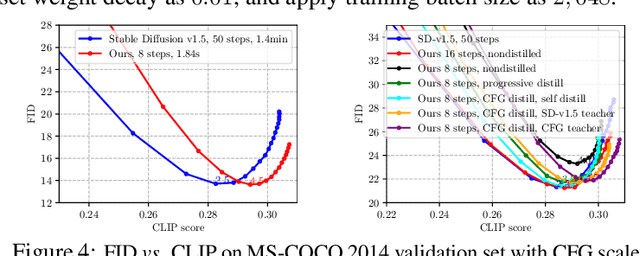
Text-to-image diffusion models can create stunning images from natural language descriptions that rival the work of professional artists and photographers. However, these models are large, with complex network architectures and tens of denoising iterations, making them computationally expensive and slow to run. As a result, high-end GPUs and cloud-based inference are required to run diffusion models at scale. This is costly and has privacy implications, especially when user data is sent to a third party. To overcome these challenges, we present a generic approach that, for the first time, unlocks running text-to-image diffusion models on mobile devices in less than $2$ seconds. We achieve so by introducing efficient network architecture and improving step distillation. Specifically, we propose an efficient UNet by identifying the redundancy of the original model and reducing the computation of the image decoder via data distillation. Further, we enhance the step distillation by exploring training strategies and introducing regularization from classifier-free guidance. Our extensive experiments on MS-COCO show that our model with $8$ denoising steps achieves better FID and CLIP scores than Stable Diffusion v$1.5$ with $50$ steps. Our work democratizes content creation by bringing powerful text-to-image diffusion models to the hands of users.
JGAT: a joint spatio-temporal graph attention model for brain decoding
Jun 03, 2023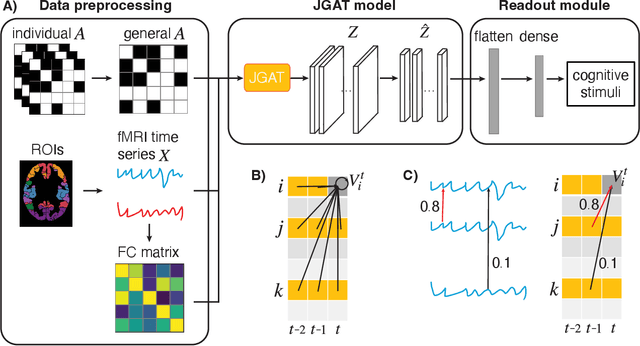
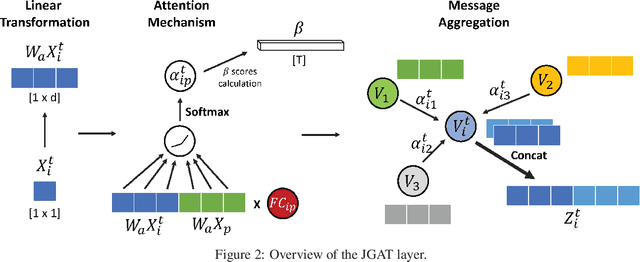
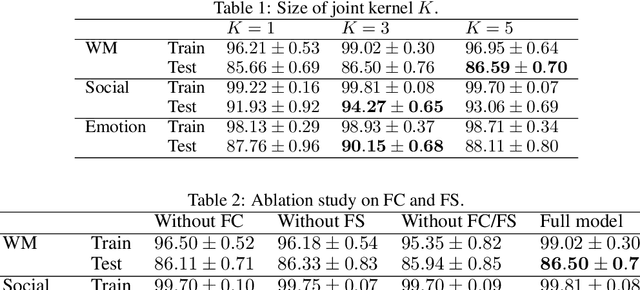
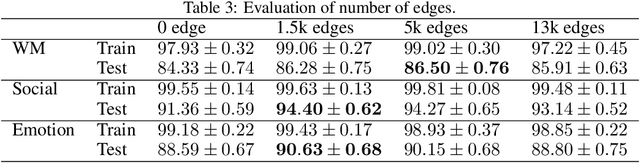
The decoding of brain neural networks has been an intriguing topic in neuroscience for a well-rounded understanding of different types of brain disorders and cognitive stimuli. Integrating different types of connectivity, e.g., Functional Connectivity (FC) and Structural Connectivity (SC), from multi-modal imaging techniques can take their complementary information into account and therefore have the potential to get better decoding capability. However, traditional approaches for integrating FC and SC overlook the dynamical variations, which stand a great chance to over-generalize the brain neural network. In this paper, we propose a Joint kernel Graph Attention Network (JGAT), which is a new multi-modal temporal graph attention network framework. It integrates the data from functional Magnetic Resonance Images (fMRI) and Diffusion Weighted Imaging (DWI) while preserving the dynamic information at the same time. We conduct brain-decoding tasks with our JGAT on four independent datasets: three of 7T fMRI datasets from the Human Connectome Project (HCP) and one from animal neural recordings. Furthermore, with Attention Scores (AS) and Frame Scores (FS) computed and learned from the model, we can locate several informative temporal segments and build meaningful dynamical pathways along the temporal domain for the HCP datasets. The URL to the code of JGAT model: https://github.com/BRAINML-GT/JGAT.
Understanding the Impact of Competing Events on Heterogeneous Treatment Effect Estimation from Time-to-Event Data
Feb 23, 2023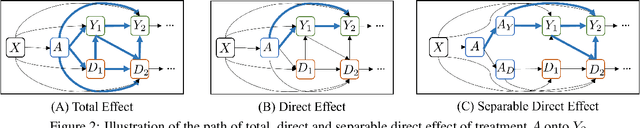
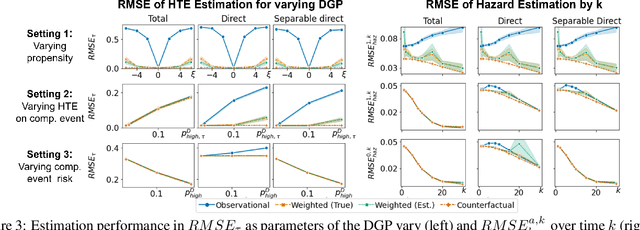
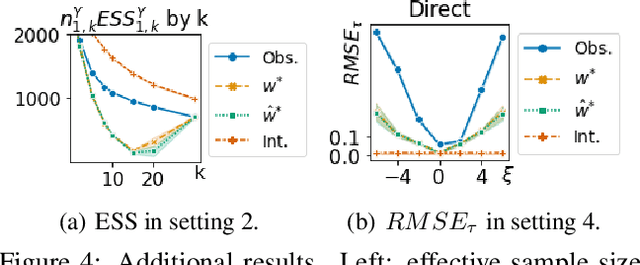
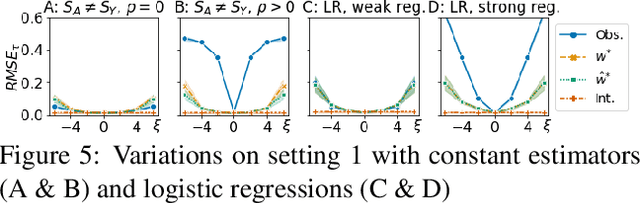
We study the problem of inferring heterogeneous treatment effects (HTEs) from time-to-event data in the presence of competing events. Albeit its great practical relevance, this problem has received little attention compared to its counterparts studying HTE estimation without time-to-event data or competing events. We take an outcome modeling approach to estimating HTEs, and consider how and when existing prediction models for time-to-event data can be used as plug-in estimators for potential outcomes. We then investigate whether competing events present new challenges for HTE estimation -- in addition to the standard confounding problem --, and find that, because there are multiple definitions of causal effects in this setting -- namely total, direct and separable effects --, competing events can act as an additional source of covariate shift depending on the desired treatment effect interpretation and associated estimand. We theoretically analyze and empirically illustrate when and how these challenges play a role when using generic machine learning prediction models for the estimation of HTEs.
It's Just a Matter of Time: Detecting Depression with Time-Enriched Multimodal Transformers
Jan 13, 2023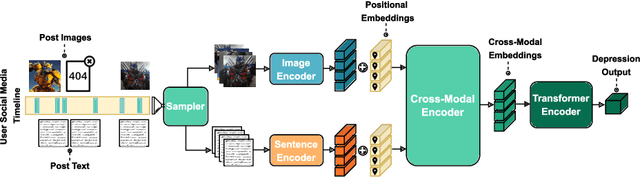
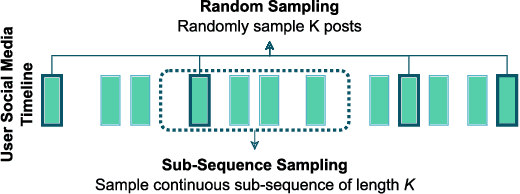
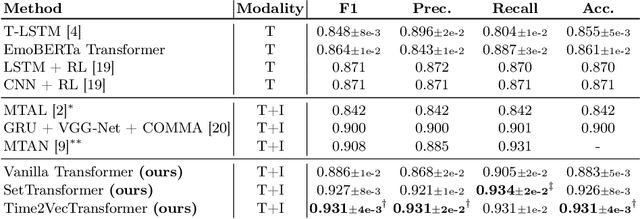

Depression detection from user-generated content on the internet has been a long-lasting topic of interest in the research community, providing valuable screening tools for psychologists. The ubiquitous use of social media platforms lays out the perfect avenue for exploring mental health manifestations in posts and interactions with other users. Current methods for depression detection from social media mainly focus on text processing, and only a few also utilize images posted by users. In this work, we propose a flexible time-enriched multimodal transformer architecture for detecting depression from social media posts, using pretrained models for extracting image and text embeddings. Our model operates directly at the user-level, and we enrich it with the relative time between posts by using time2vec positional embeddings. Moreover, we propose another model variant, which can operate on randomly sampled and unordered sets of posts to be more robust to dataset noise. We show that our method, using EmoBERTa and CLIP embeddings, surpasses other methods on two multimodal datasets, obtaining state-of-the-art results of 0.931 F1 score on a popular multimodal Twitter dataset, and 0.902 F1 score on the only multimodal Reddit dataset.
AutoExp: A multidisciplinary, multi-sensor framework to evaluate human activities in self-driving cars
Jun 05, 2023

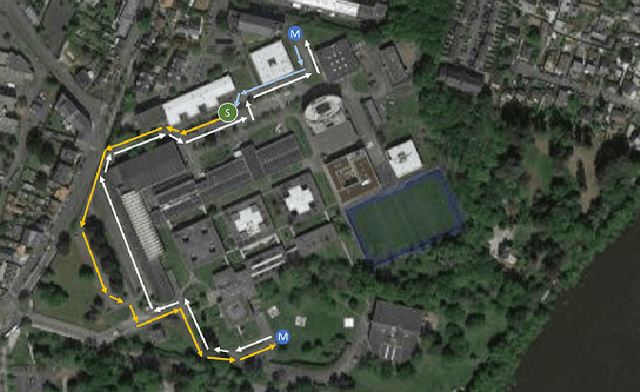
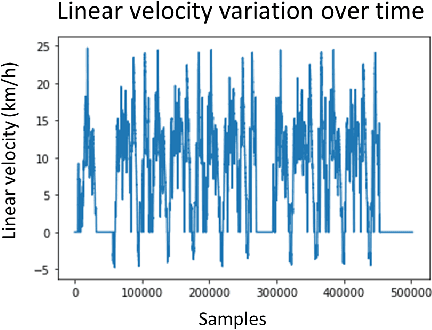
The adoption of self-driving cars will certainly revolutionize our lives, even though they may take more time to become fully autonomous than initially predicted. The first vehicles are already present in certain cities of the world, as part of experimental robot-taxi services. However, most existing studies focus on the navigation part of such vehicles. We currently miss methods, datasets, and studies to assess the in-cabin human component of the adoption of such technology in real-world conditions. This paper proposes an experimental framework to study the activities of occupants of self-driving cars using a multidisciplinary approach (computer vision associated with human and social sciences), particularly non-driving related activities. The framework is composed of an experimentation scenario, and a data acquisition module. We seek firstly to capture real-world data about the usage of the vehicle in the nearest possible, real-world conditions, and secondly to create a dataset containing in-cabin human activities to foster the development and evaluation of computer vision algorithms. The acquisition module records multiple views of the front seats of the vehicle (Intel RGB-D and GoPro cameras); in addition to survey data about the internal states and attitudes of participants towards this type of vehicle before, during, and after the experimentation. We evaluated the proposed framework with the realization of real-world experimentation with 30 participants (1 hour each) to study the acceptance of SDCs of SAE level 4.
LightCTS: A Lightweight Framework for Correlated Time Series Forecasting
Feb 27, 2023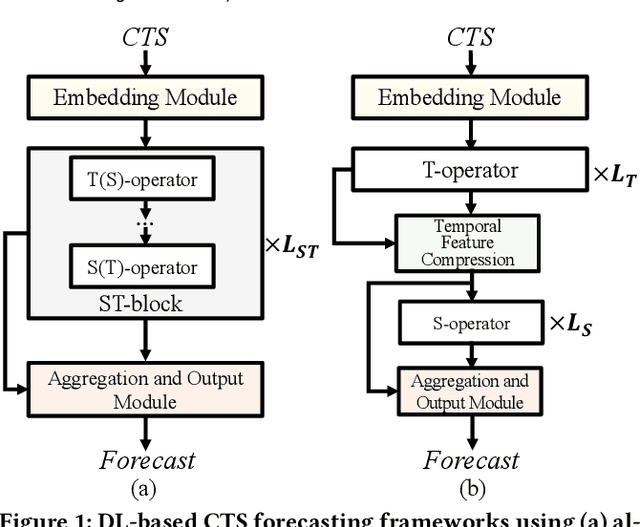


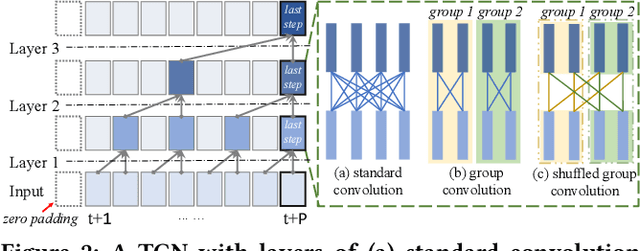
Correlated time series (CTS) forecasting plays an essential role in many practical applications, such as traffic management and server load control. Many deep learning models have been proposed to improve the accuracy of CTS forecasting. However, while models have become increasingly complex and computationally intensive, they struggle to improve accuracy. Pursuing a different direction, this study aims instead to enable much more efficient, lightweight models that preserve accuracy while being able to be deployed on resource-constrained devices. To achieve this goal, we characterize popular CTS forecasting models and yield two observations that indicate directions for lightweight CTS forecasting. On this basis, we propose the LightCTS framework that adopts plain stacking of temporal and spatial operators instead of alternate stacking that is much more computationally expensive. Moreover, LightCTS features light temporal and spatial operator modules, called L-TCN and GL-Former, that offer improved computational efficiency without compromising their feature extraction capabilities. LightCTS also encompasses a last-shot compression scheme to reduce redundant temporal features and speed up subsequent computations. Experiments with single-step and multi-step forecasting benchmark datasets show that LightCTS is capable of nearly state-of-the-art accuracy at much reduced computational and storage overheads.
rPPG-MAE: Self-supervised Pre-training with Masked Autoencoders for Remote Physiological Measurement
Jun 04, 2023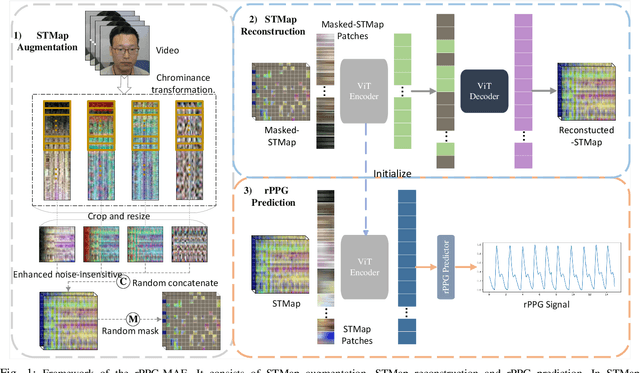
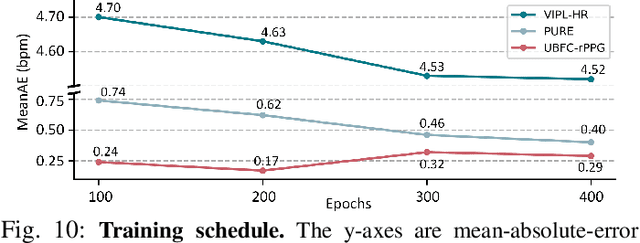
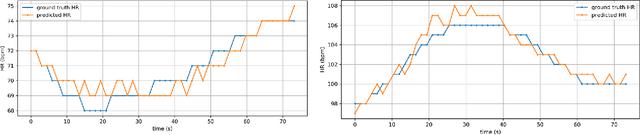
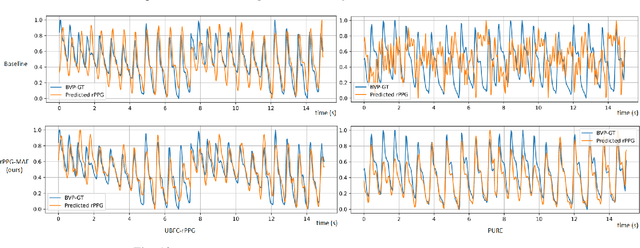
Remote photoplethysmography (rPPG) is an important technique for perceiving human vital signs, which has received extensive attention. For a long time, researchers have focused on supervised methods that rely on large amounts of labeled data. These methods are limited by the requirement for large amounts of data and the difficulty of acquiring ground truth physiological signals. To address these issues, several self-supervised methods based on contrastive learning have been proposed. However, they focus on the contrastive learning between samples, which neglect the inherent self-similar prior in physiological signals and seem to have a limited ability to cope with noisy. In this paper, a linear self-supervised reconstruction task was designed for extracting the inherent self-similar prior in physiological signals. Besides, a specific noise-insensitive strategy was explored for reducing the interference of motion and illumination. The proposed framework in this paper, namely rPPG-MAE, demonstrates excellent performance even on the challenging VIPL-HR dataset. We also evaluate the proposed method on two public datasets, namely PURE and UBFC-rPPG. The results show that our method not only outperforms existing self-supervised methods but also exceeds the state-of-the-art (SOTA) supervised methods. One important observation is that the quality of the dataset seems more important than the size in self-supervised pre-training of rPPG. The source code is released at https://github.com/linuxsino/rPPG-MAE.
Fast Continual Multi-View Clustering with Incomplete Views
Jun 04, 2023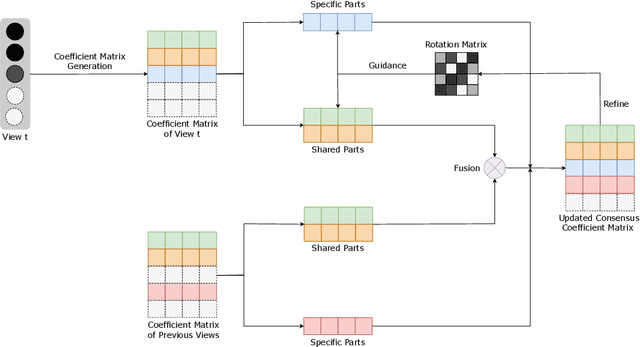

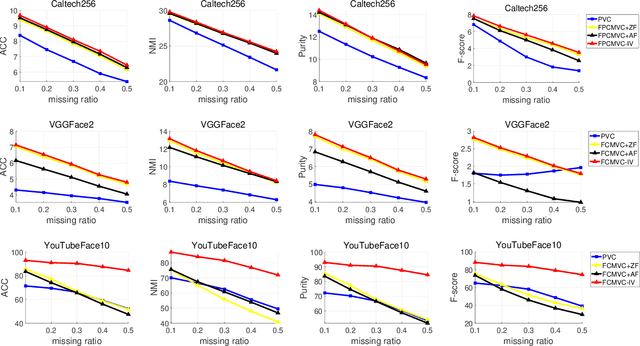
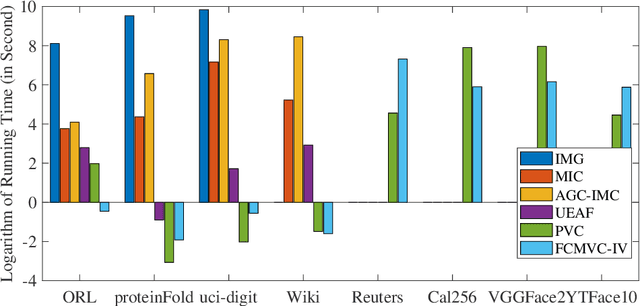
Multi-view clustering (MVC) has gained broad attention owing to its capacity to exploit consistent and complementary information across views. This paper focuses on a challenging issue in MVC called the incomplete continual data problem (ICDP). In specific, most existing algorithms assume that views are available in advance and overlook the scenarios where data observations of views are accumulated over time. Due to privacy considerations or memory limitations, previous views cannot be stored in these situations. Some works are proposed to handle it, but all fail to address incomplete views. Such an incomplete continual data problem (ICDP) in MVC is tough to solve since incomplete information with continual data increases the difficulty of extracting consistent and complementary knowledge among views. We propose Fast Continual Multi-View Clustering with Incomplete Views (FCMVC-IV) to address it. Specifically, it maintains a consensus coefficient matrix and updates knowledge with the incoming incomplete view rather than storing and recomputing all the data matrices. Considering that the views are incomplete, the newly collected view might contain samples that have yet to appear; two indicator matrices and a rotation matrix are developed to match matrices with different dimensions. Besides, we design a three-step iterative algorithm to solve the resultant problem in linear complexity with proven convergence. Comprehensive experiments on various datasets show the superiority of FCMVC-IV.
Embracing Compact and Robust Architectures for Multi-Exposure Image Fusion
May 20, 2023
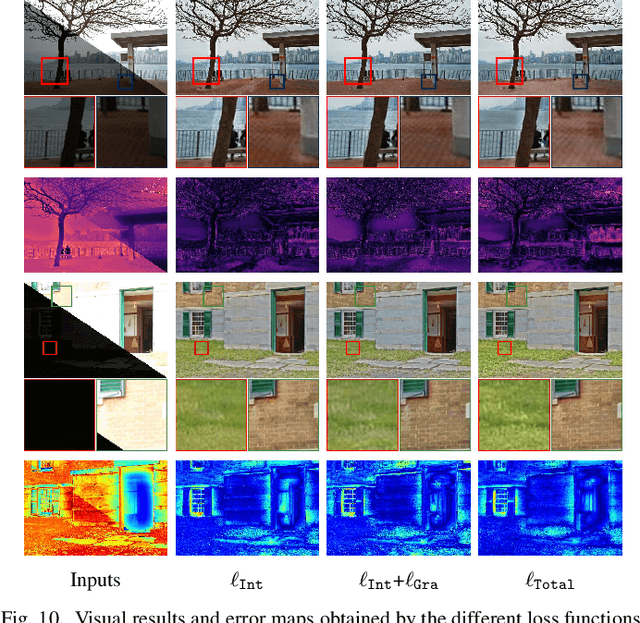
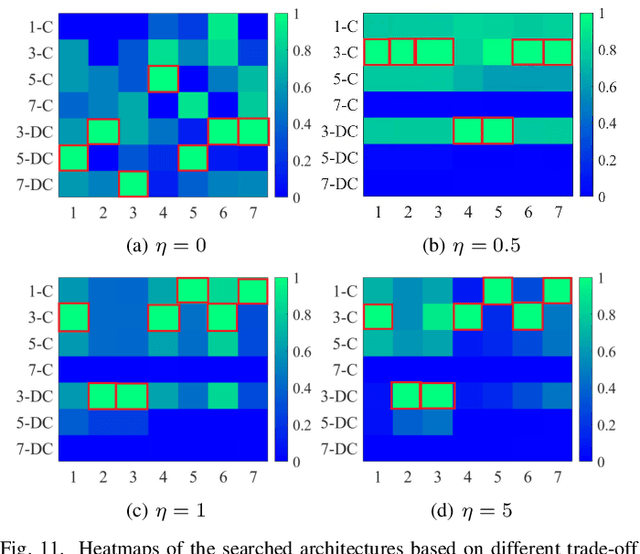
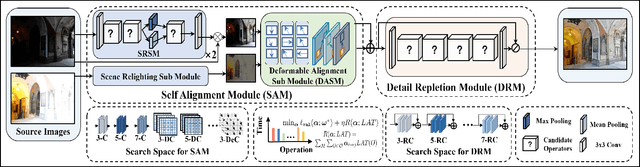
In recent years, deep learning-based methods have achieved remarkable progress in multi-exposure image fusion. However, existing methods rely on aligned image pairs, inevitably generating artifacts when faced with device shaking in real-world scenarios. Moreover, these learning-based methods are built on handcrafted architectures and operations by increasing network depth or width, neglecting different exposure characteristics. As a result, these direct cascaded architectures with redundant parameters fail to achieve highly effective inference time and lead to massive computation. To alleviate these issues, in this paper, we propose a search-based paradigm, involving self-alignment and detail repletion modules for robust multi-exposure image fusion. By utilizing scene relighting and deformable convolutions, the self-alignment module can accurately align images despite camera movement. Furthermore, by imposing a hardware-sensitive constraint, we introduce neural architecture search to discover compact and efficient networks, investigating effective feature representation for fusion. We realize the state-of-the-art performance in comparison to various competitive schemes, yielding a 4.02% and 29.34% improvement in PSNR for general and misaligned scenarios, respectively, while reducing inference time by 68.1%. The source code will be available at https://github.com/LiuZhu-CV/CRMEF.