 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ORRN: An ODE-based Recursive Registration Network for Deformable Respiratory Motion Estimation with Lung 4DCT Images
May 25, 2023
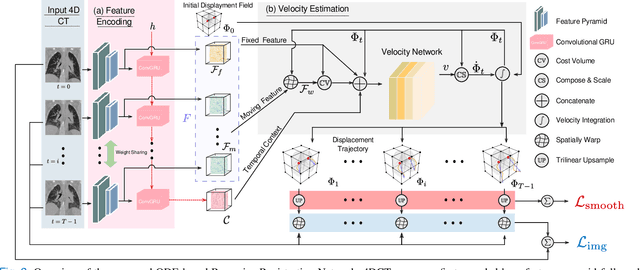
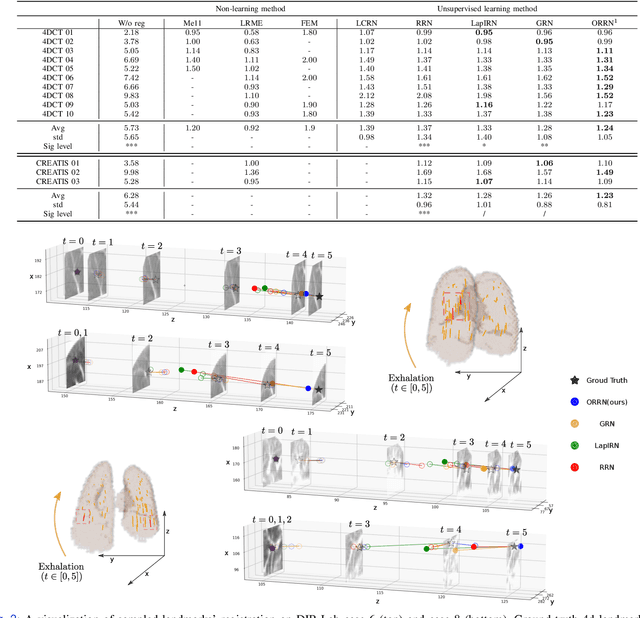
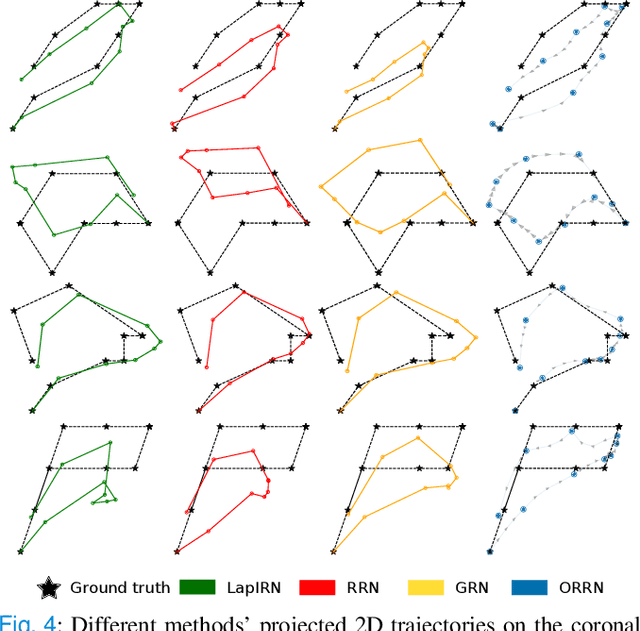
Deformable Image Registration (DIR) plays a significant role in quantifying deformation in medical data. Recent Deep Learning methods have shown promising accuracy and speedup for registering a pair of medical images. However, in 4D (3D + time) medical data, organ motion, such as respiratory motion and heart beating, can not be effectively modeled by pair-wise methods as they were optimized for image pairs but did not consider the organ motion patterns necessary when considering 4D data. This paper presents ORRN, an Ordinary Differential Equations (ODE)-based recursive image registration network. Our network learns to estimate time-varying voxel velocities for an ODE that models deformation in 4D image data. It adopts a recursive registration strategy to progressively estimate a deformation field through ODE integration of voxel velocities. We evaluate the proposed method on two publicly available lung 4DCT datasets, DIRLab and CREATIS, for two tasks: 1) registering all images to the extreme inhale image for 3D+t deformation tracking and 2) registering extreme exhale to inhale phase images. Our method outperforms other learning-based methods in both tasks, producing the smallest Target Registration Error of 1.24mm and 1.26mm, respectively. Additionally, it produces less than 0.001\% unrealistic image folding, and the computation speed is less than 1 second for each CT volume. ORRN demonstrates promising registration accuracy, deformation plausibility, and computation efficiency on group-wise and pair-wise registration tasks. It has significant implications in enabling fast and accurate respiratory motion estimation for treatment planning in radiation therapy or robot motion planning in thoracic needle insertion.
LCDnet: A Lightweight Crowd Density Estimation Model for Real-time Video Surveillance
Feb 10, 2023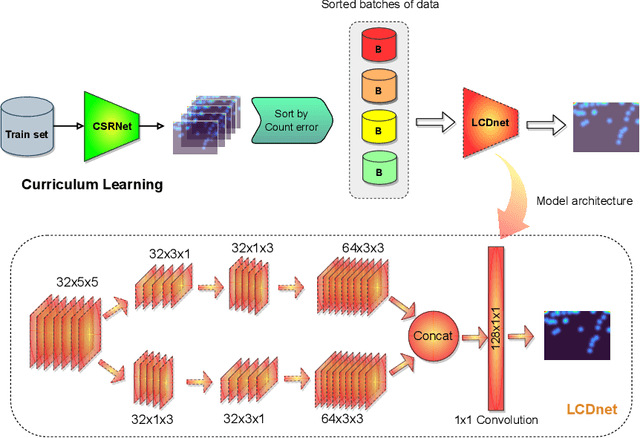
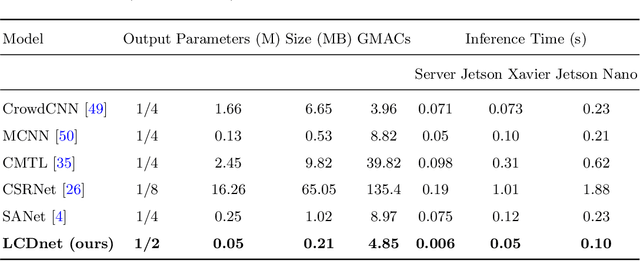

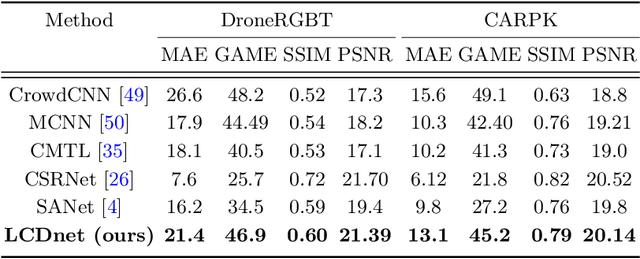
Automatic crowd counting using density estimation has gained significant attention in computer vision research. As a result, a large number of crowd counting and density estimation models using convolution neural networks (CNN) have been published in the last few years. These models have achieved good accuracy over benchmark datasets. However, attempts to improve the accuracy often lead to higher complexity in these models. In real-time video surveillance applications using drones with limited computing resources, deep models incur intolerable higher inference delay. In this paper, we propose (i) a Lightweight Crowd Density estimation model (LCDnet) for real-time video surveillance, and (ii) an improved training method using curriculum learning (CL). LCDnet is trained using CL and evaluated over two benchmark datasets i.e., DroneRGBT and CARPK. Results are compared with existing crowd models. Our evaluation shows that the LCDnet achieves a reasonably good accuracy while significantly reducing the inference time and memory requirement and thus can be deployed over edge devices with very limited computing resources.
Maskomaly:Zero-Shot Mask Anomaly Segmentation
May 26, 2023
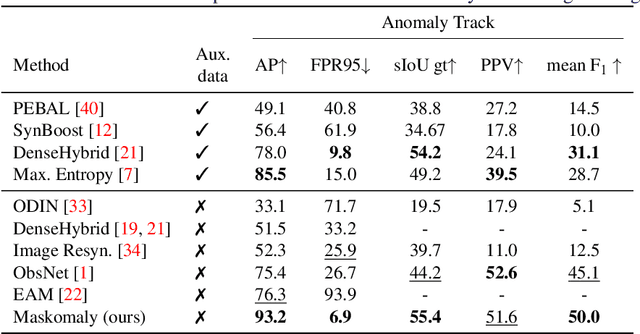
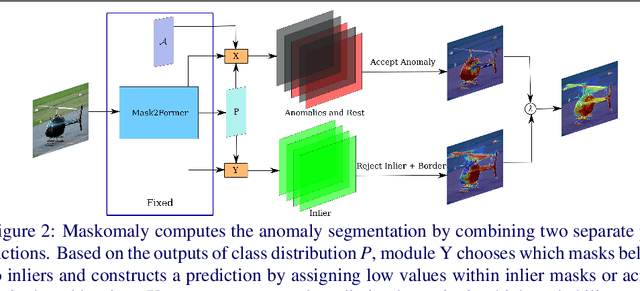
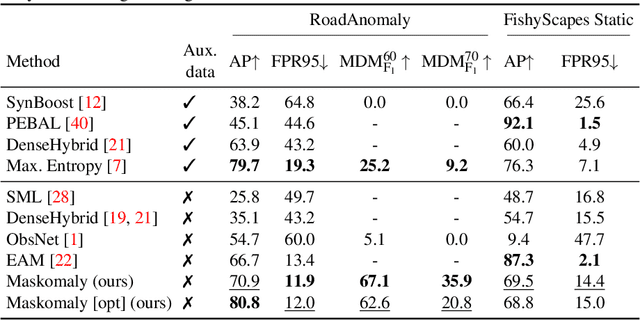
We present a simple and practical framework for anomaly segmentation called Maskomaly. It builds upon mask-based standard semantic segmentation networks by adding a simple inference-time post-processing step which leverages the raw mask outputs of such networks. Maskomaly does not require additional training and only adds a small computational overhead to inference. Most importantly, it does not require anomalous data at training. We show top results for our method on SMIYC, RoadAnomaly, and StreetHazards. On the most central benchmark, SMIYC, Maskomaly outperforms all directly comparable approaches. Further, we introduce a novel metric that benefits the development of robust anomaly segmentation methods and demonstrate its informativeness on RoadAnomaly.
Policy Synthesis and Reinforcement Learning for Discounted LTL
May 26, 2023

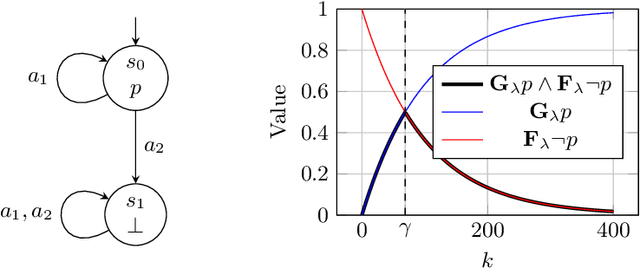
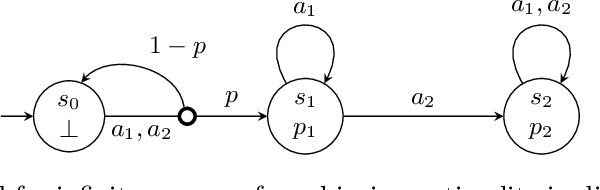
The difficulty of manually specifying reward functions has led to an interest in using linear temporal logic (LTL) to express objectives for reinforcement learning (RL). However, LTL has the downside that it is sensitive to small perturbations in the transition probabilities, which prevents probably approximately correct (PAC) learning without additional assumptions. Time discounting provides a way of removing this sensitivity, while retaining the high expressivity of the logic. We study the use of discounted LTL for policy synthesis in Markov decision processes with unknown transition probabilities, and show how to reduce discounted LTL to discounted-sum reward via a reward machine when all discount factors are identical.
Passive Mechanical Vibration Processor for Wireless Vibration Sensing
May 18, 2023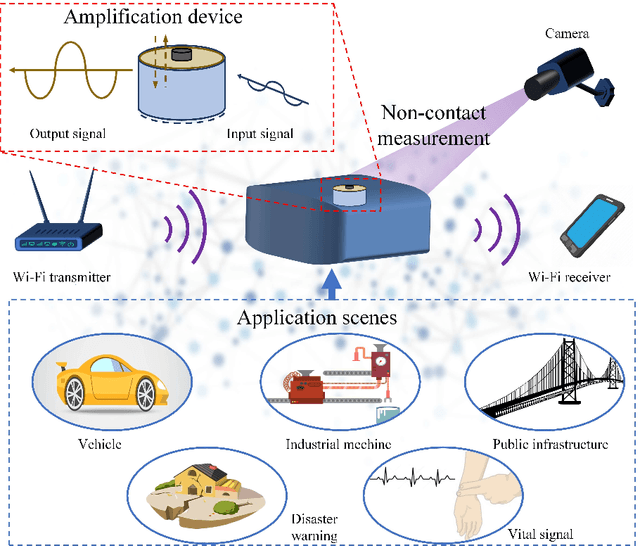
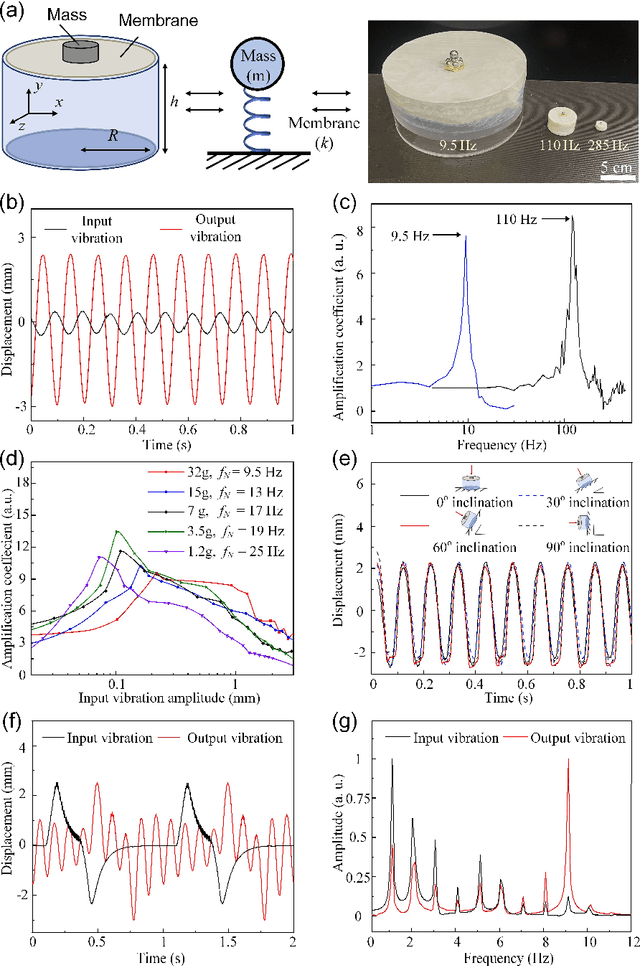
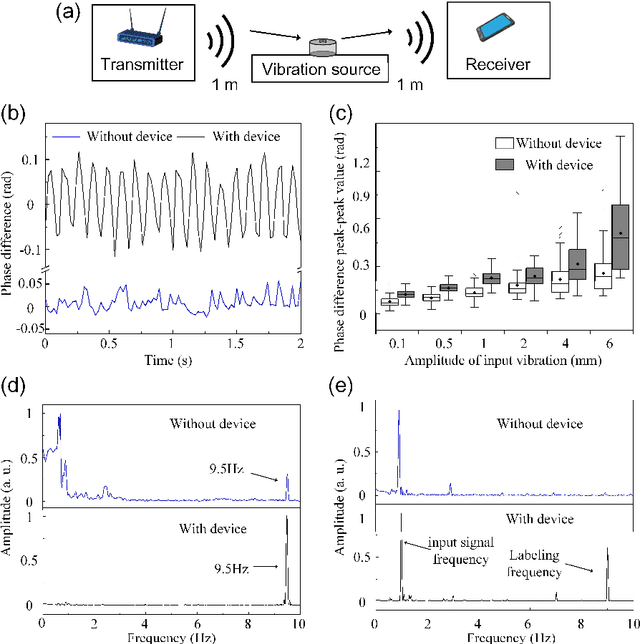
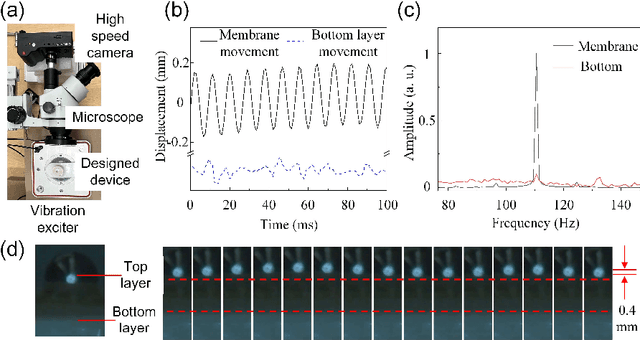
Real-time, low-cost, and wireless mechanical vibration monitoring is necessary for industrial applications to track the operation status of equipment, environmental applications to proactively predict natural disasters, as well as day-to-day applications such as vital sign monitoring. Despite this urgent need, existing solutions, such as laser vibrometers, commercial Wi-Fi devices, and cameras, lack wide practical deployment due to their limited sensitivity and functionality. In this work, we propose and verify that a fully passive, resonance-based vibration processing device attached to the vibrating surface can improve the sensitivity of wireless vibration measurement methods by more than 10 times at designated frequencies. Additionally, the device realizes an analog real-time vibration filtering/labeling effect, and the device also provides a platform for surface editing, which adds more functionalities to the current non-contact sensing systems. Finally, the working frequency of the device is widely adjustable over orders of magnitudes, broadening its applicability to different applications.
Non-Parametric Learning of Stochastic Differential Equations with Fast Rates of Convergence
May 24, 2023We propose a novel non-parametric learning paradigm for the identification of drift and diffusion coefficients of non-linear stochastic differential equations, which relies upon discrete-time observations of the state. The key idea essentially consists of fitting a RKHS-based approximation of the corresponding Fokker-Planck equation to such observations, yielding theoretical estimates of learning rates which, unlike previous works, become increasingly tighter when the regularity of the unknown drift and diffusion coefficients becomes higher. Our method being kernel-based, offline pre-processing may in principle be profitably leveraged to enable efficient numerical implementation.
Runtime Monitoring of Dynamic Fairness Properties
May 08, 2023
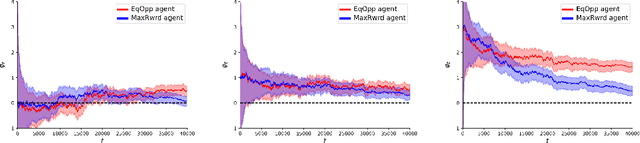
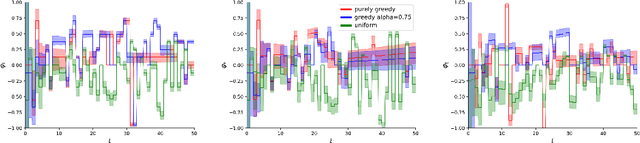
A machine-learned system that is fair in static decision-making tasks may have biased societal impacts in the long-run. This may happen when the system interacts with humans and feedback patterns emerge, reinforcing old biases in the system and creating new biases. While existing works try to identify and mitigate long-run biases through smart system design, we introduce techniques for monitoring fairness in real time. Our goal is to build and deploy a monitor that will continuously observe a long sequence of events generated by the system in the wild, and will output, with each event, a verdict on how fair the system is at the current point in time. The advantages of monitoring are two-fold. Firstly, fairness is evaluated at run-time, which is important because unfair behaviors may not be eliminated a priori, at design-time, due to partial knowledge about the system and the environment, as well as uncertainties and dynamic changes in the system and the environment, such as the unpredictability of human behavior. Secondly, monitors are by design oblivious to how the monitored system is constructed, which makes them suitable to be used as trusted third-party fairness watchdogs. They function as computationally lightweight statistical estimators, and their correctness proofs rely on the rigorous analysis of the stochastic process that models the assumptions about the underlying dynamics of the system. We show, both in theory and experiments, how monitors can warn us (1) if a bank's credit policy over time has created an unfair distribution of credit scores among the population, and (2) if a resource allocator's allocation policy over time has made unfair allocations. Our experiments demonstrate that the monitors introduce very low overhead. We believe that runtime monitoring is an important and mathematically rigorous new addition to the fairness toolbox.
Adapting Multi-Lingual ASR Models for Handling Multiple Talkers
May 30, 2023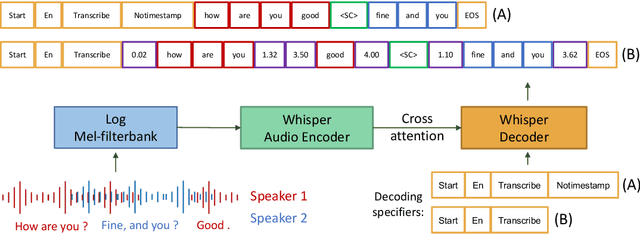
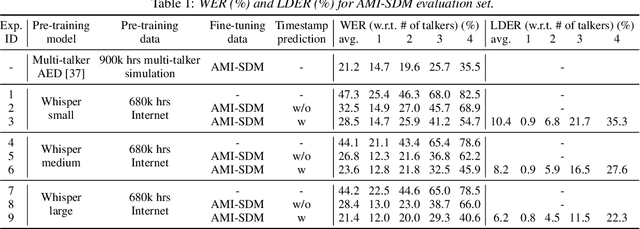
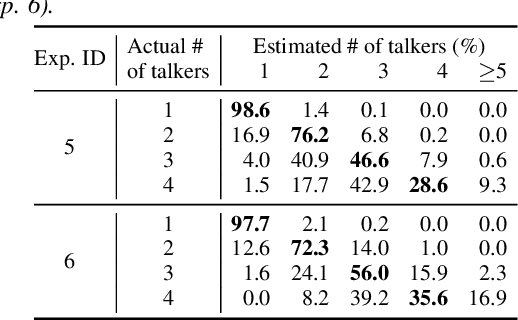
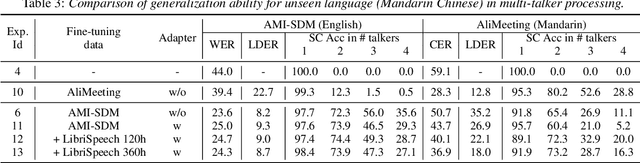
State-of-the-art large-scale universal speech models (USMs) show a decent automatic speech recognition (ASR) performance across multiple domains and languages. However, it remains a challenge for these models to recognize overlapped speech, which is often seen in meeting conversations. We propose an approach to adapt USMs for multi-talker ASR. We first develop an enhanced version of serialized output training to jointly perform multi-talker ASR and utterance timestamp prediction. That is, we predict the ASR hypotheses for all speakers, count the speakers, and estimate the utterance timestamps at the same time. We further introduce a lightweight adapter module to maintain the multilingual property of the USMs even when we perform the adaptation with only a single language. Experimental results obtained using the AMI and AliMeeting corpora show that our proposed approach effectively transfers the USMs to a strong multilingual multi-talker ASR model with timestamp prediction capability.
Auto-tune: PAC-Bayes Optimization over Prior and Posterior for Neural Networks
May 30, 2023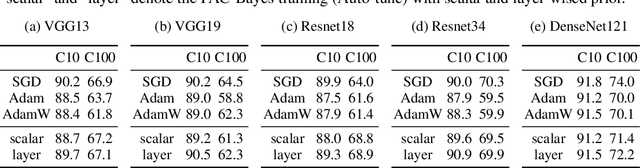
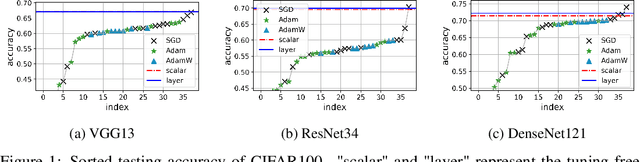
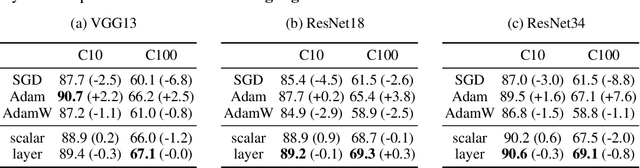
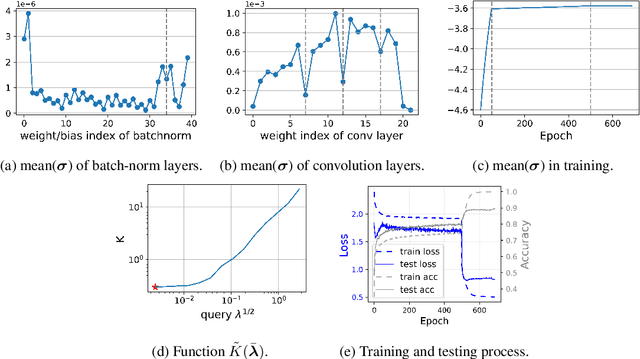
It is widely recognized that the generalization ability of neural networks can be greatly enhanced through carefully designing the training procedure. The current state-of-the-art training approach involves utilizing stochastic gradient descent (SGD) or Adam optimization algorithms along with a combination of additional regularization techniques such as weight decay, dropout, or noise injection. Optimal generalization can only be achieved by tuning a multitude of hyperparameters through grid search, which can be time-consuming and necessitates additional validation datasets. To address this issue, we introduce a practical PAC-Bayes training framework that is nearly tuning-free and requires no additional regularization while achieving comparable testing performance to that of SGD/Adam after a complete grid search and with extra regularizations. Our proposed algorithm demonstrates the remarkable potential of PAC training to achieve state-of-the-art performance on deep neural networks with enhanced robustness and interpretability.
Weakly-supervised forced alignment of disfluent speech using phoneme-level modeling
May 30, 2023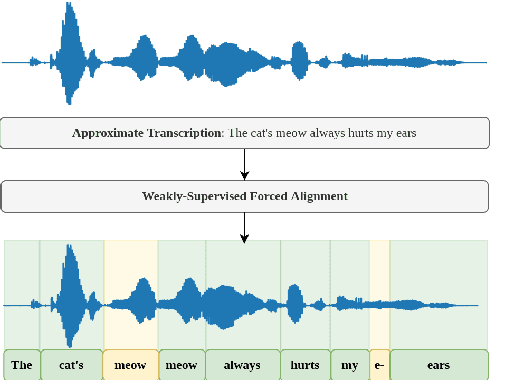

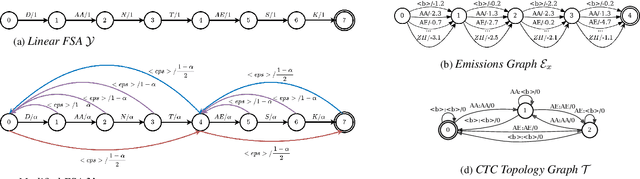
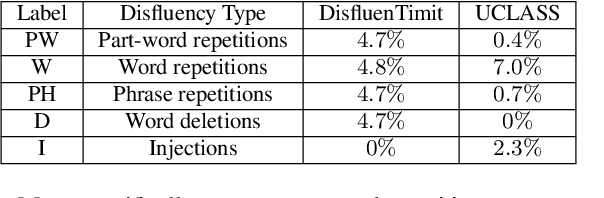
The study of speech disorders can benefit greatly from time-aligned data. However, audio-text mismatches in disfluent speech cause rapid performance degradation for modern speech aligners, hindering the use of automatic approaches. In this work, we propose a simple and effective modification of alignment graph construction of CTC-based models using Weighted Finite State Transducers. The proposed weakly-supervised approach alleviates the need for verbatim transcription of speech disfluencies for forced alignment. During the graph construction, we allow the modeling of common speech disfluencies, i.e. repetitions and omissions. Further, we show that by assessing the degree of audio-text mismatch through the use of Oracle Error Rate, our method can be effectively used in the wild. Our evaluation on a corrupted version of the TIMIT test set and the UCLASS dataset shows significant improvements, particularly for recall, achieving a 23-25% relative improvement over our baselines.