 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Semantic Variation Prediction using the Distribution of Sibling Embeddings
May 15, 2023
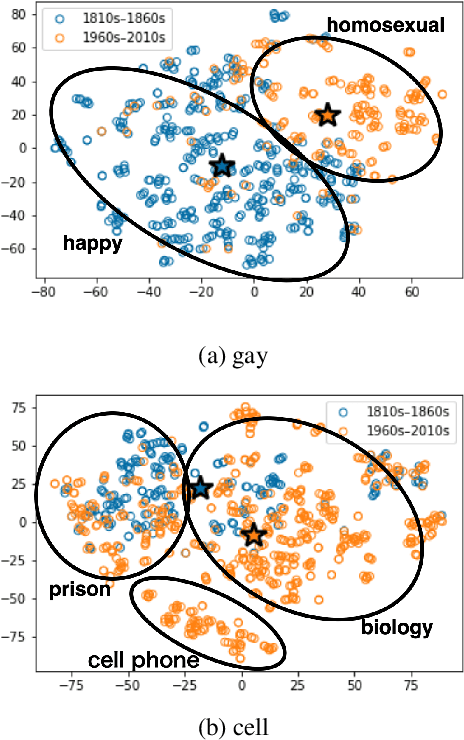

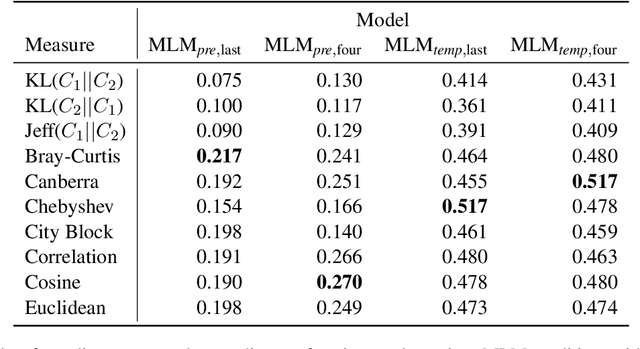
Languages are dynamic entities, where the meanings associated with words constantly change with time. Detecting the semantic variation of words is an important task for various NLP applications that must make time-sensitive predictions. Existing work on semantic variation prediction have predominantly focused on comparing some form of an averaged contextualised representation of a target word computed from a given corpus. However, some of the previously associated meanings of a target word can become obsolete over time (e.g. meaning of gay as happy), while novel usages of existing words are observed (e.g. meaning of cell as a mobile phone). We argue that mean representations alone cannot accurately capture such semantic variations and propose a method that uses the entire cohort of the contextualised embeddings of the target word, which we refer to as the sibling distribution. Experimental results on SemEval-2020 Task 1 benchmark dataset for semantic variation prediction show that our method outperforms prior work that consider only the mean embeddings, and is comparable to the current state-of-the-art. Moreover, a qualitative analysis shows that our method detects important semantic changes in words that are not captured by the existing methods. Source code is available at https://github.com/a1da4/svp-gauss .
Online Sequence Clustering Algorithm for Video Trajectory Analysis
May 15, 2023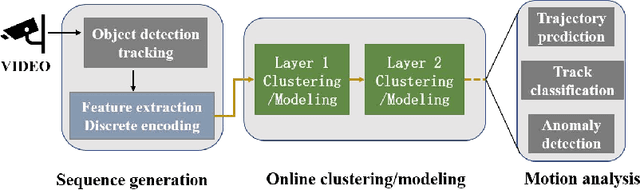
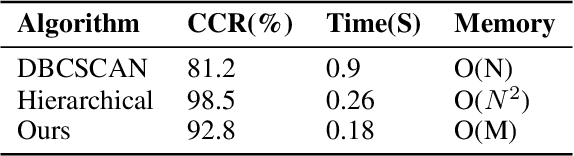
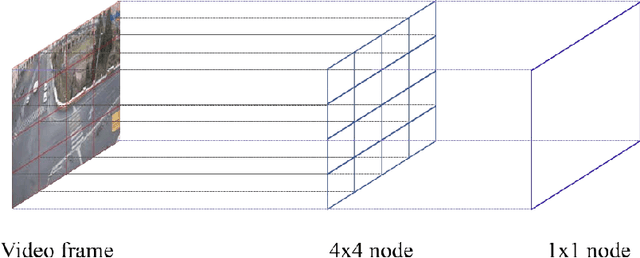
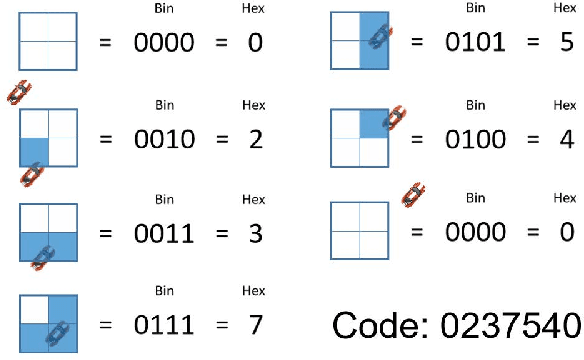
Target tracking and trajectory modeling have important applications in surveillance video analysis and have received great attention in the fields of road safety and community security. In this work, we propose a lightweight real-time video analysis scheme that uses a model learned from motion patterns to monitor the behavior of objects, which can be used for applications such as real-time representation and prediction. The proposed sequence clustering algorithm based on discrete sequences makes the system have continuous online learning ability. The intrinsic repeatability of the target object trajectory is used to automatically construct the behavioral model in the three processes of feature extraction, cluster learning, and model application. In addition to the discretization of trajectory features and simple model applications, this paper focuses on online clustering algorithms and their incremental learning processes. Finally, through the learning of the trajectory model of the actual surveillance video image, the feasibility of the algorithm is verified. And the characteristics and performance of the clustering algorithm are discussed in the analysis. This scheme has real-time online learning and processing of motion models while avoiding a large number of arithmetic operations, which is more in line with the application scenarios of front-end intelligent perception.
A Polynomial Time, Pure Differentially Private Estimator for Binary Product Distributions
Apr 19, 2023We present the first $\varepsilon$-differentially private, computationally efficient algorithm that estimates the means of product distributions over $\{0,1\}^d$ accurately in total-variation distance, whilst attaining the optimal sample complexity to within polylogarithmic factors. The prior work had either solved this problem efficiently and optimally under weaker notions of privacy, or had solved it optimally while having exponential running times.
Testing of Deep Reinforcement Learning Agents with Surrogate Models
May 22, 2023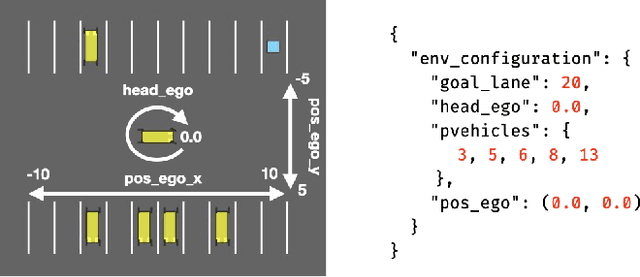
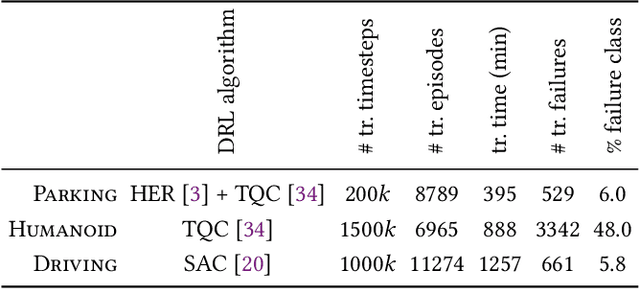
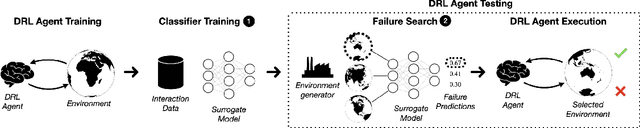
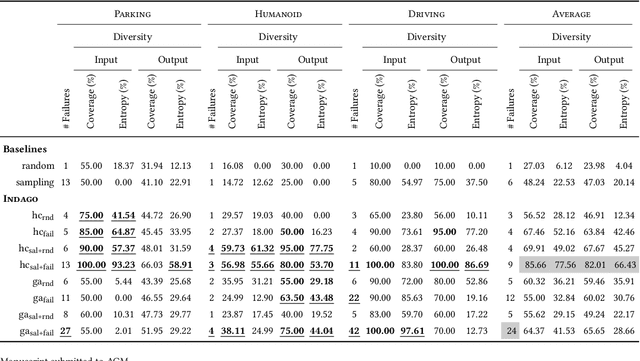
Deep Reinforcement Learning (DRL) has received a lot of attention from the research community in recent years. As the technology moves away from game playing to practical contexts, such as autonomous vehicles and robotics, it is crucial to evaluate the quality of DRL agents. In this paper, we propose a search-based approach to test such agents. Our approach, implemented in a tool called Indago, trains a classifier on failure and non-failure environment configurations resulting from the DRL training process. The classifier is used at testing time as a surrogate model for the DRL agent execution in the environment, predicting the extent to which a given environment configuration induces a failure of the DRL agent under test. Indeed, the failure prediction acts as a fitness function, in order to guide the generation towards failure environment configurations, while saving computation time by deferring the execution of the DRL agent in the environment to those configurations that are more likely to expose failures. Experimental results show that our search-based approach finds 50% more failures of the DRL agent than state-of-the-art techniques. Moreover, such failure environment configurations, as well as the behaviours of the DRL agent induced by them, are significantly more diverse.
Discounted Thompson Sampling for Non-Stationary Bandit Problems
May 22, 2023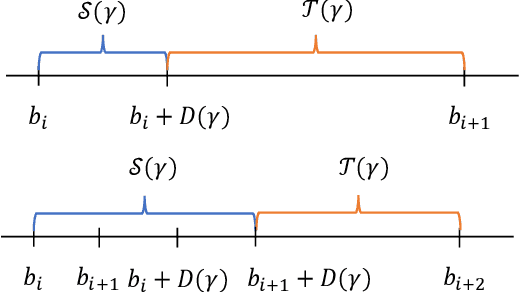
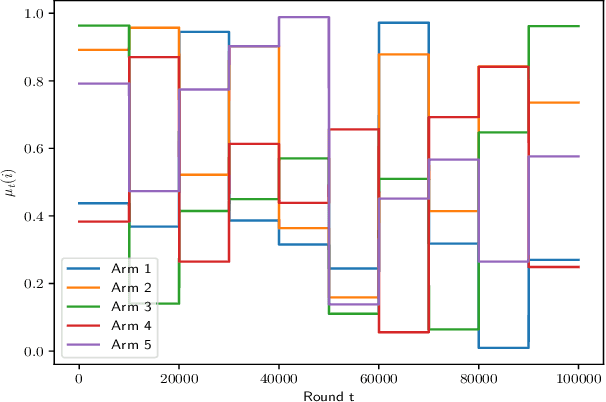
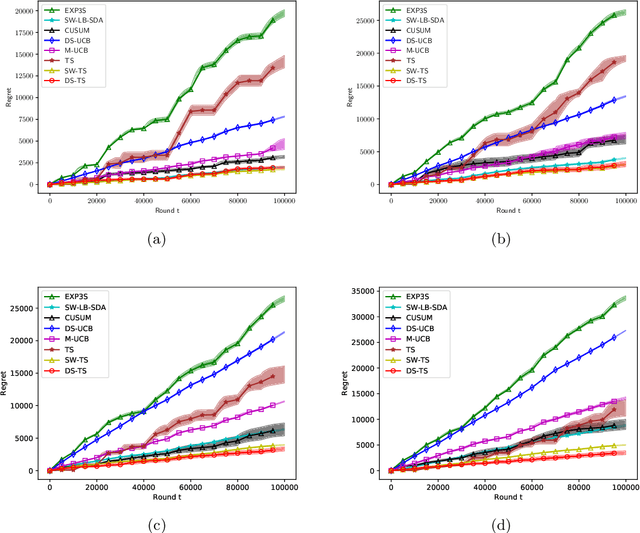
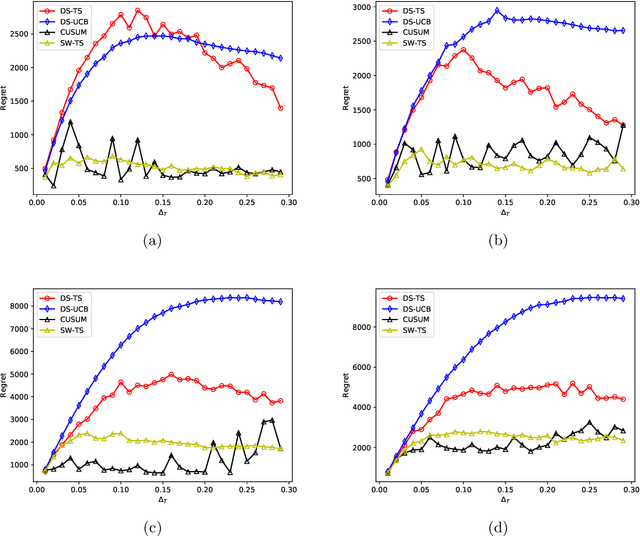
Non-stationary multi-armed bandit (NS-MAB) problems have recently received significant attention. NS-MAB are typically modelled in two scenarios: abruptly changing, where reward distributions remain constant for a certain period and change at unknown time steps, and smoothly changing, where reward distributions evolve smoothly based on unknown dynamics. In this paper, we propose Discounted Thompson Sampling (DS-TS) with Gaussian priors to address both non-stationary settings. Our algorithm passively adapts to changes by incorporating a discounted factor into Thompson Sampling. DS-TS method has been experimentally validated, but analysis of the regret upper bound is currently lacking. Under mild assumptions, we show that DS-TS with Gaussian priors can achieve nearly optimal regret bound on the order of $\tilde{O}(\sqrt{TB_T})$ for abruptly changing and $\tilde{O}(T^{\beta})$ for smoothly changing, where $T$ is the number of time steps, $B_T$ is the number of breakpoints, $\beta$ is associated with the smoothly changing environment and $\tilde{O}$ hides the parameters independent of $T$ as well as logarithmic terms. Furthermore, empirical comparisons between DS-TS and other non-stationary bandit algorithms demonstrate its competitive performance. Specifically, when prior knowledge of the maximum expected reward is available, DS-TS has the potential to outperform state-of-the-art algorithms.
Learning Pedestrian Actions to Ensure Safe Autonomous Driving
May 22, 2023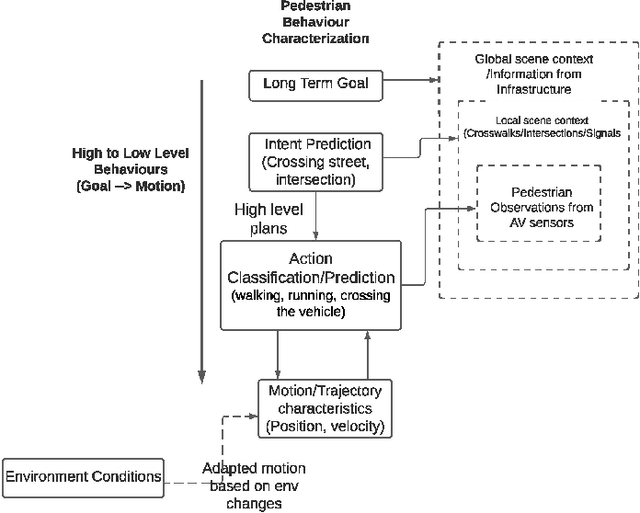
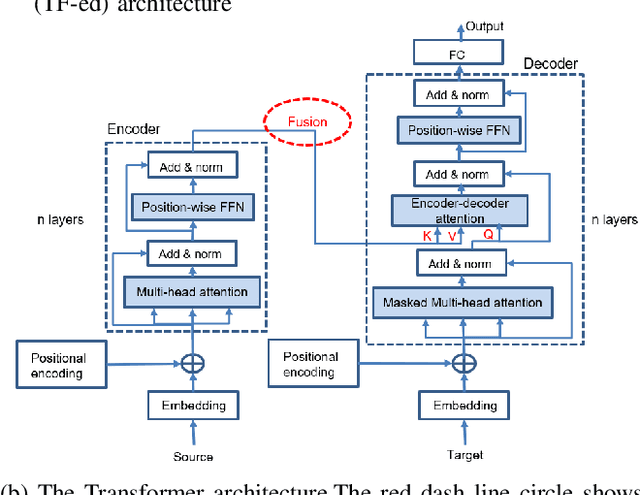
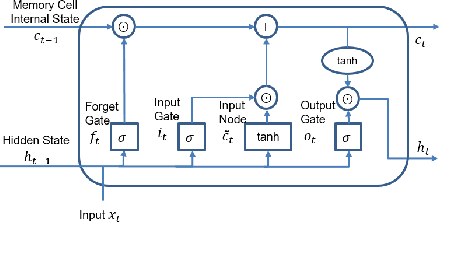

To ensure safe autonomous driving in urban environments with complex vehicle-pedestrian interactions, it is critical for Autonomous Vehicles (AVs) to have the ability to predict pedestrians' short-term and immediate actions in real-time. In recent years, various methods have been developed to study estimating pedestrian behaviors for autonomous driving scenarios, but there is a lack of clear definitions for pedestrian behaviors. In this work, the literature gaps are investigated and a taxonomy is presented for pedestrian behavior characterization. Further, a novel multi-task sequence to sequence Transformer encoders-decoders (TF-ed) architecture is proposed for pedestrian action and trajectory prediction using only ego vehicle camera observations as inputs. The proposed approach is compared against an existing LSTM encoders decoders (LSTM-ed) architecture for action and trajectory prediction. The performance of both models is evaluated on the publicly available Joint Attention Autonomous Driving (JAAD) dataset, CARLA simulation data as well as real-time self-driving shuttle data collected on university campus. Evaluation results illustrate that the proposed method reaches an accuracy of 81% on action prediction task on JAAD testing data and outperforms the LSTM-ed by 7.4%, while LSTM counterpart performs much better on trajectory prediction task for a prediction sequence length of 25 frames.
CrowdWeb: A Visualization Tool for Mobility Patterns in Smart Cities
May 22, 2023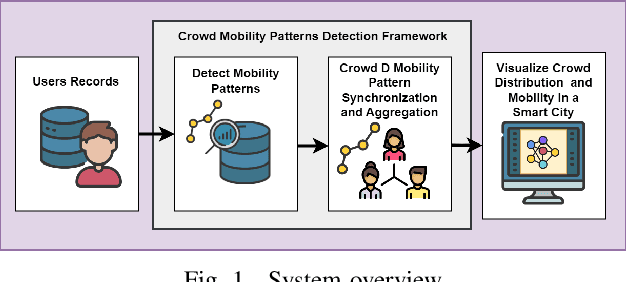
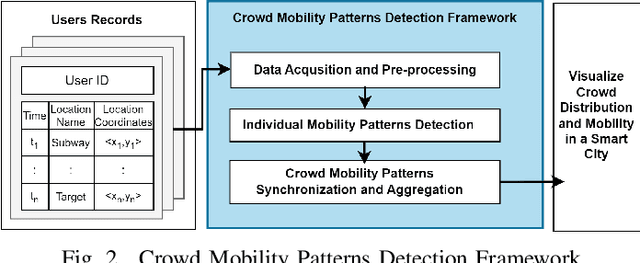
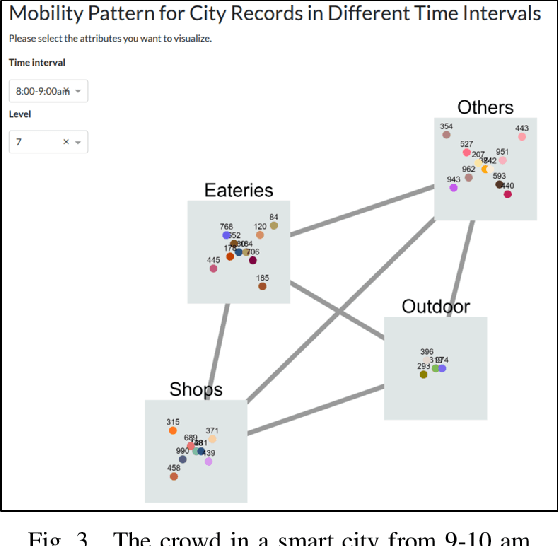
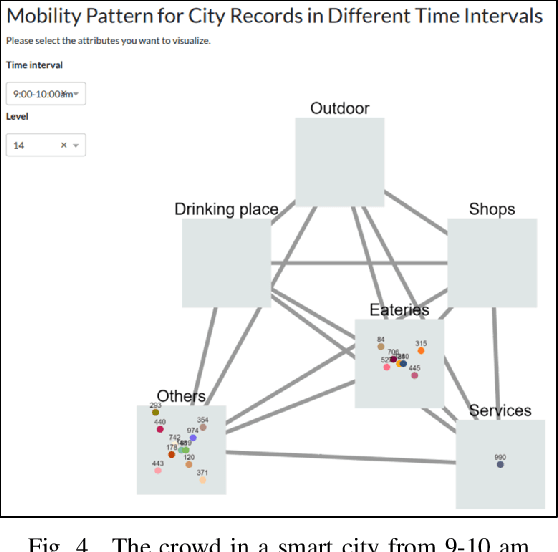
Human mobility patterns refer to the regularities and trends in the way people move, travel, or navigate through different geographical locations over time. Detecting human mobility patterns is essential for a variety of applications, including smart cities, transportation management, and disaster response. The accuracy of current mobility prediction models is less than 25%. The low accuracy is mainly due to the fluid nature of human movement. Typically, humans do not adhere to rigid patterns in their daily activities, making it difficult to identify hidden regularities in their data. To address this issue, we proposed a web platform to visualize human mobility patterns by abstracting the locations into a set of places to detect more realistic patterns. However, the platform was initially designed to detect individual mobility patterns, making it unsuitable for representing the crowd in a smart city scale. Therefore, we extend the platform to visualize the mobility of multiple users from a city-scale perspective. Our platform allows users to visualize a graph of visited places based on their historical records using a modified PrefixSpan approach. Additionally, the platform synchronizes, aggregates, and displays crowd mobility patterns across various time intervals within a smart city. We showcase our platform using a real dataset.
Online Learning in Multi-unit Auctions
May 27, 2023
We consider repeated multi-unit auctions with uniform pricing, which are widely used in practice for allocating goods such as carbon licenses. In each round, $K$ identical units of a good are sold to a group of buyers that have valuations with diminishing marginal returns. The buyers submit bids for the units, and then a price $p$ is set per unit so that all the units are sold. We consider two variants of the auction, where the price is set to the $K$-th highest bid and $(K+1)$-st highest bid, respectively. We analyze the properties of this auction in both the offline and online settings. In the offline setting, we consider the problem that one player $i$ is facing: given access to a data set that contains the bids submitted by competitors in past auctions, find a bid vector that maximizes player $i$'s cumulative utility on the data set. We design a polynomial time algorithm for this problem, by showing it is equivalent to finding a maximum-weight path on a carefully constructed directed acyclic graph. In the online setting, the players run learning algorithms to update their bids as they participate in the auction over time. Based on our offline algorithm, we design efficient online learning algorithms for bidding. The algorithms have sublinear regret, under both full information and bandit feedback structures. We complement our online learning algorithms with regret lower bounds. Finally, we analyze the quality of the equilibria in the worst case through the lens of the core solution concept in the game among the bidders. We show that the $(K+1)$-st price format is susceptible to collusion among the bidders; meanwhile, the $K$-th price format does not have this issue.
Improving Handwritten OCR with Training Samples Generated by Glyph Conditional Denoising Diffusion Probabilistic Model
May 31, 2023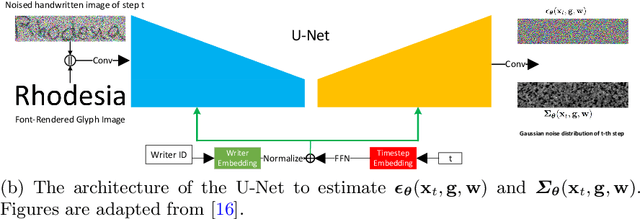
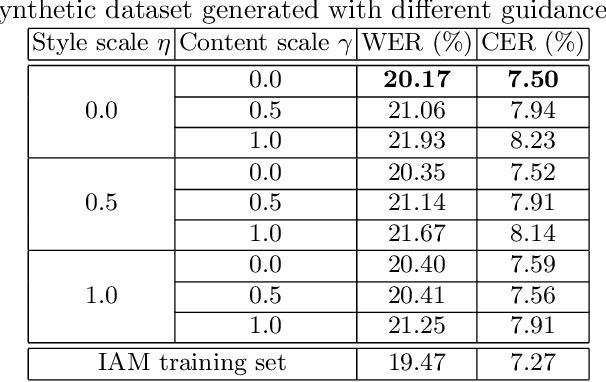

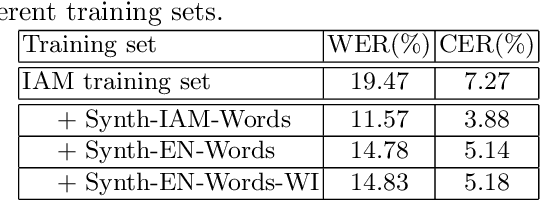
Constructing a highly accurate handwritten OCR system requires large amounts of representative training data, which is both time-consuming and expensive to collect. To mitigate the issue, we propose a denoising diffusion probabilistic model (DDPM) to generate training samples. This model conditions on a printed glyph image and creates mappings between printed characters and handwritten images, thus enabling the generation of photo-realistic handwritten samples with diverse styles and unseen text contents. However, the text contents in synthetic images are not always consistent with the glyph conditional images, leading to unreliable labels of synthetic samples. To address this issue, we further propose a progressive data filtering strategy to add those samples with a high confidence of correctness to the training set. Experimental results on IAM benchmark task show that OCR model trained with augmented DDPM-synthesized training samples can achieve about 45% relative word error rate reduction compared with the one trained on real data only.
Evaluating GPT's Programming Capability through CodeWars' Katas
May 31, 2023
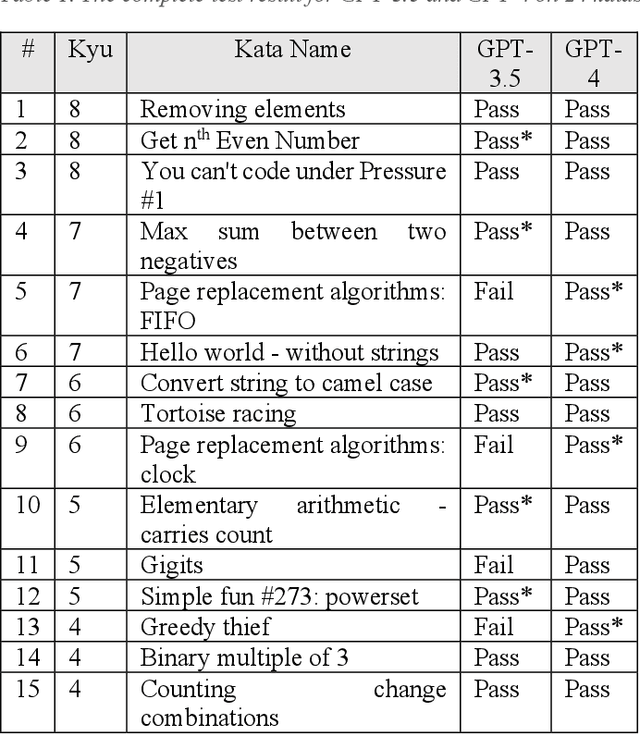
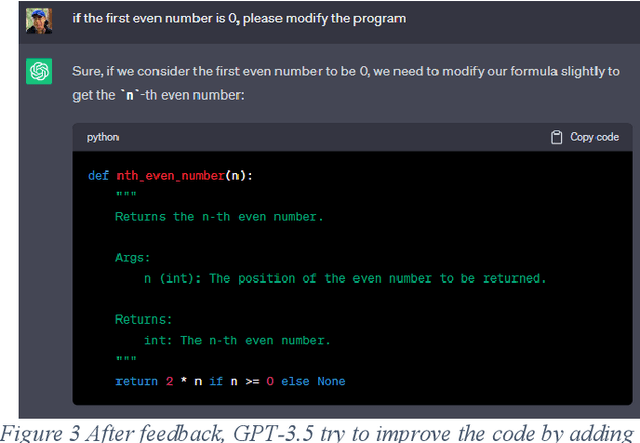
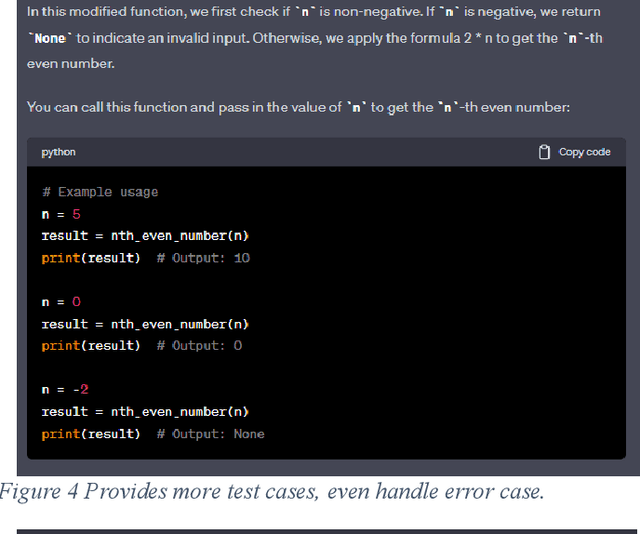
In the burgeoning field of artificial intelligence (AI), understanding the capabilities and limitations of programming-oriented models is crucial. This paper presents a novel evaluation of the programming proficiency of Generative Pretrained Transformer (GPT) models, specifically GPT-3.5 and GPT-4, against coding problems of varying difficulty levels drawn from Codewars. The experiments reveal a distinct boundary at the 3kyu level, beyond which these GPT models struggle to provide solutions. These findings led to the proposal of a measure for coding problem complexity that incorporates both problem difficulty and the time required for solution. The research emphasizes the need for validation and creative thinking capabilities in AI models to better emulate human problem-solving techniques. Future work aims to refine this proposed complexity measure, enhance AI models with these suggested capabilities, and develop an objective measure for programming problem difficulty. The results of this research offer invaluable insights for improving AI programming capabilities and advancing the frontier of AI problem-solving abilities.