 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Sequence Clustering Algorithm for Video Trajectory Analysis
May 15, 2023
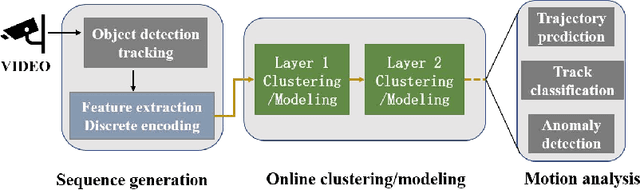
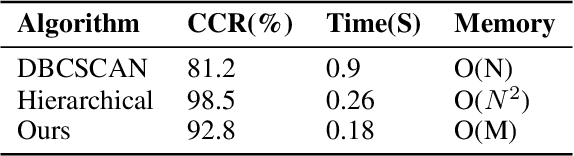
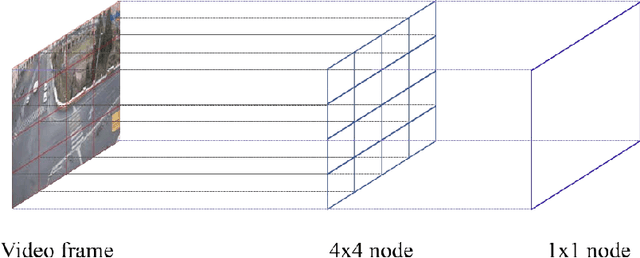
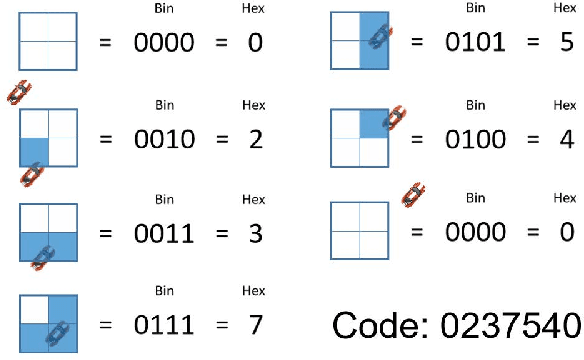
Target tracking and trajectory modeling have important applications in surveillance video analysis and have received great attention in the fields of road safety and community security. In this work, we propose a lightweight real-time video analysis scheme that uses a model learned from motion patterns to monitor the behavior of objects, which can be used for applications such as real-time representation and prediction. The proposed sequence clustering algorithm based on discrete sequences makes the system have continuous online learning ability. The intrinsic repeatability of the target object trajectory is used to automatically construct the behavioral model in the three processes of feature extraction, cluster learning, and model application. In addition to the discretization of trajectory features and simple model applications, this paper focuses on online clustering algorithms and their incremental learning processes. Finally, through the learning of the trajectory model of the actual surveillance video image, the feasibility of the algorithm is verified. And the characteristics and performance of the clustering algorithm are discussed in the analysis. This scheme has real-time online learning and processing of motion models while avoiding a large number of arithmetic operations, which is more in line with the application scenarios of front-end intelligent perception.
Interactive Neural Resonators
May 24, 2023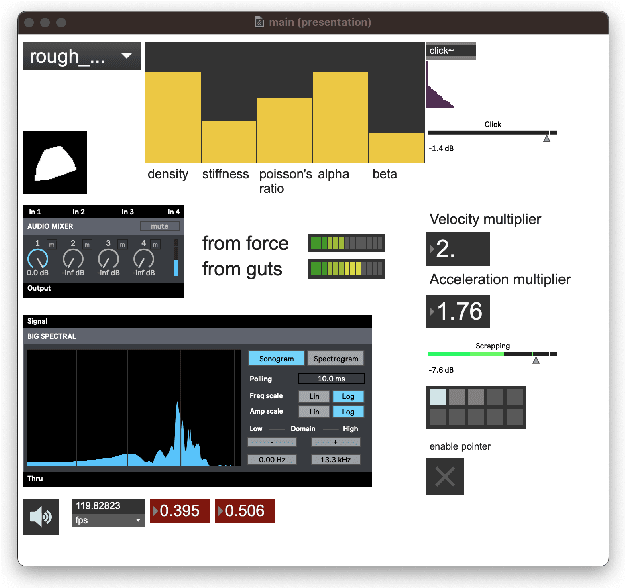
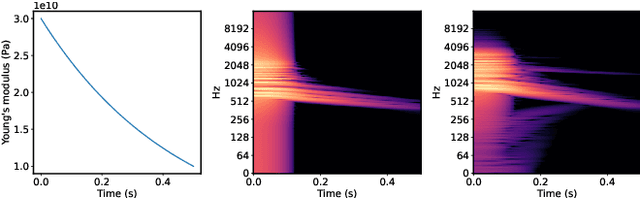
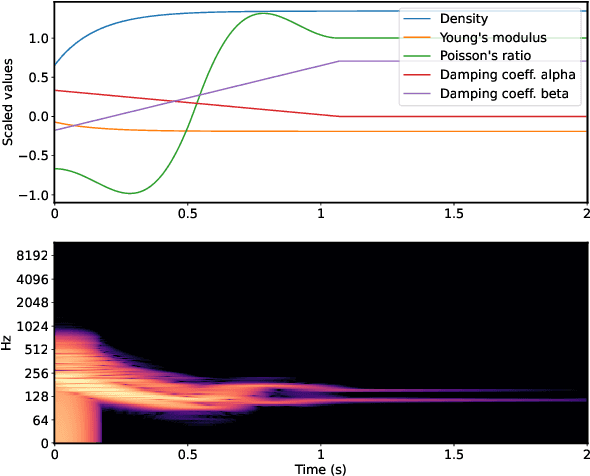
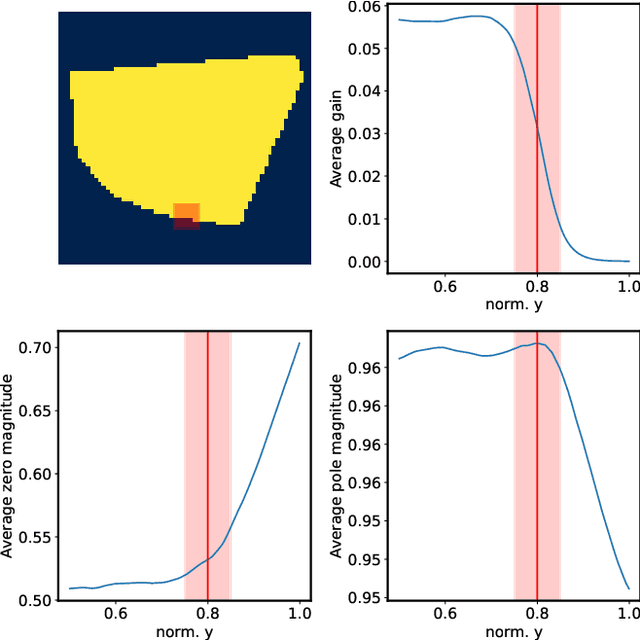
In this work, we propose a method for the controllable synthesis of real-time contact sounds using neural resonators. Previous works have used physically inspired statistical methods and physical modelling for object materials and excitation signals. Our method incorporates differentiable second-order resonators and estimates their coefficients using a neural network that is conditioned on physical parameters. This allows for interactive dynamic control and the generation of novel sounds in an intuitive manner. We demonstrate the practical implementation of our method and explore its potential creative applications.
Impact of translation on biomedical information extraction from real-life clinical notes
Jun 03, 2023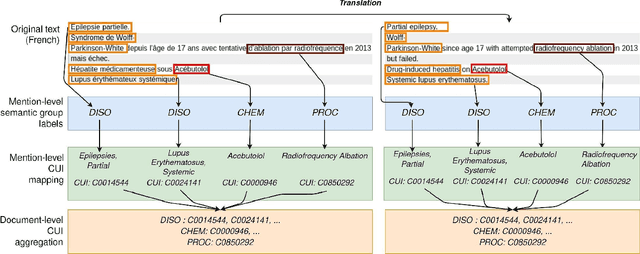
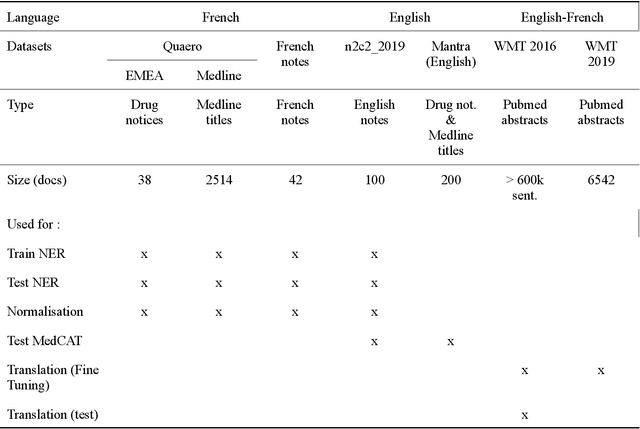
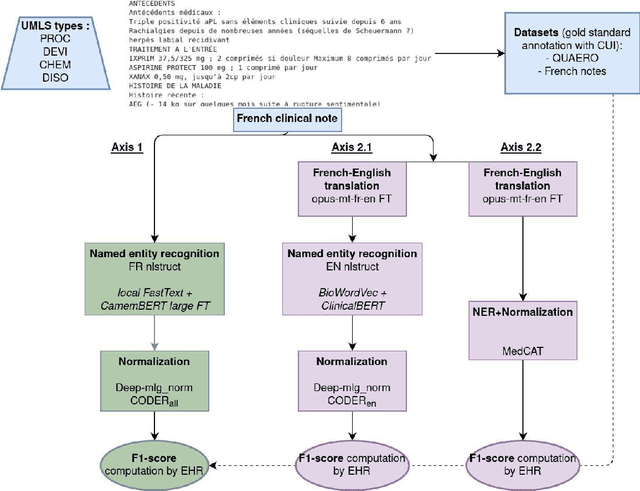
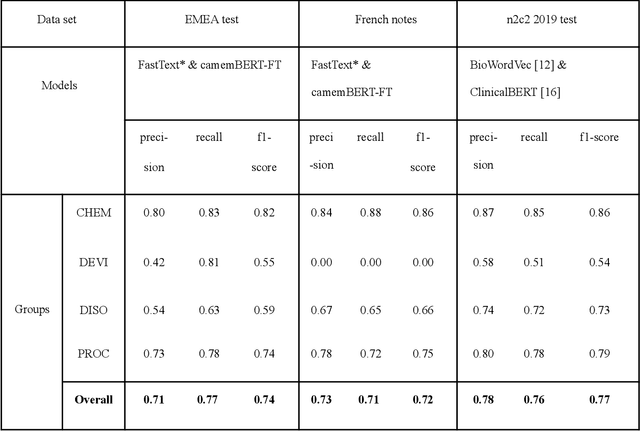
The objective of our study is to determine whether using English tools to extract and normalize French medical concepts on translations provides comparable performance to French models trained on a set of annotated French clinical notes. We compare two methods: a method involving French language models and a method involving English language models. For the native French method, the Named Entity Recognition (NER) and normalization steps are performed separately. For the translated English method, after the first translation step, we compare a two-step method and a terminology-oriented method that performs extraction and normalization at the same time. We used French, English and bilingual annotated datasets to evaluate all steps (NER, normalization and translation) of our algorithms. Concerning the results, the native French method performs better than the translated English one with a global f1 score of 0.51 [0.47;0.55] against 0.39 [0.34;0.44] and 0.38 [0.36;0.40] for the two English methods tested. In conclusion, despite the recent improvement of the translation models, there is a significant performance difference between the two approaches in favor of the native French method which is more efficient on French medical texts, even with few annotated documents.
A Conditional Generative Chatbot using Transformer Model
Jun 03, 2023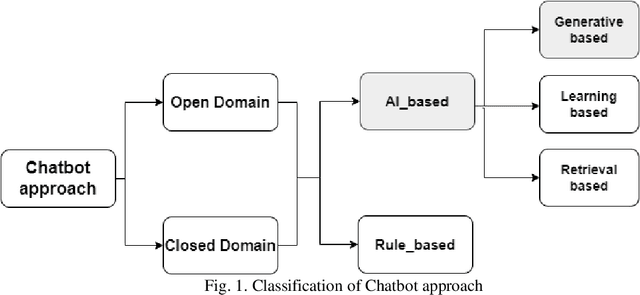
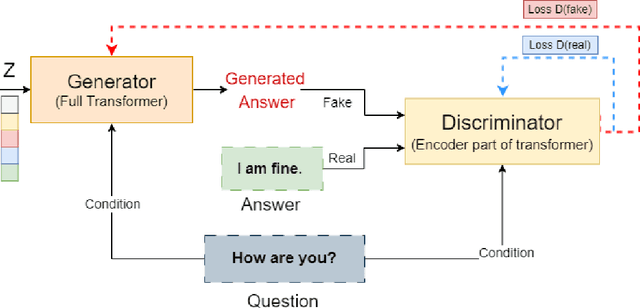
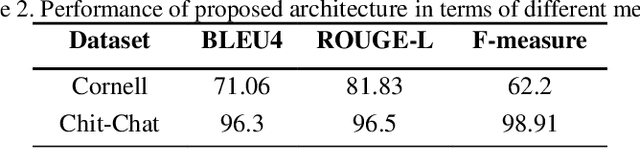
A Chatbot serves as a communication tool between a human user and a machine to achieve an appropriate answer based on the human input. In more recent approaches, a combination of Natural Language Processing and sequential models are used to build a generative Chatbot. The main challenge of these models is their sequential nature, which leads to less accurate results. To tackle this challenge, in this paper, a novel end-to-end architecture is proposed using conditional Wasserstein Generative Adversarial Networks and a transformer model for answer generation in Chatbots. While the generator of the proposed model consists of a full transformer model to generate an answer, the discriminator includes only the encoder part of a transformer model followed by a classifier. To the best of our knowledge, this is the first time that a generative Chatbot is proposed using the embedded transformer in both generator and discriminator models. Relying on the parallel computing of the transformer model, the results of the proposed model on the Cornell Movie-Dialog corpus and the Chit-Chat datasets confirm the superiority of the proposed model compared to state-of-the-art alternatives using different evaluation metrics.
AlerTiger: Deep Learning for AI Model Health Monitoring at LinkedIn
Jun 03, 2023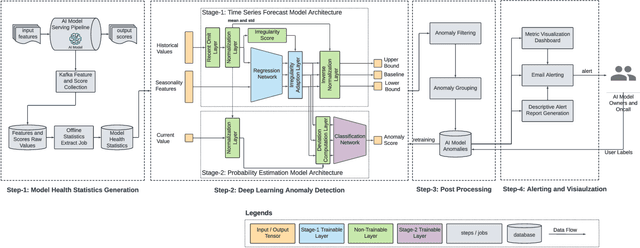
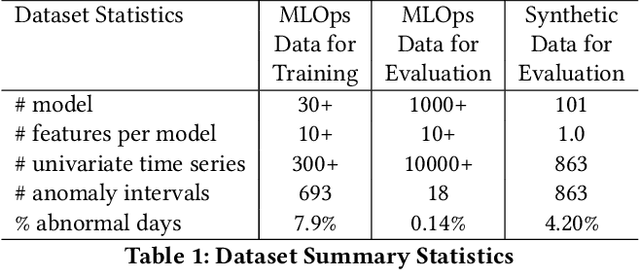
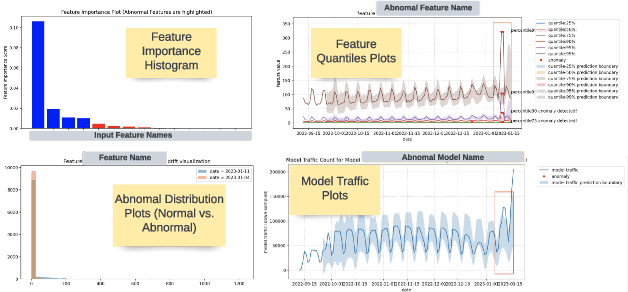
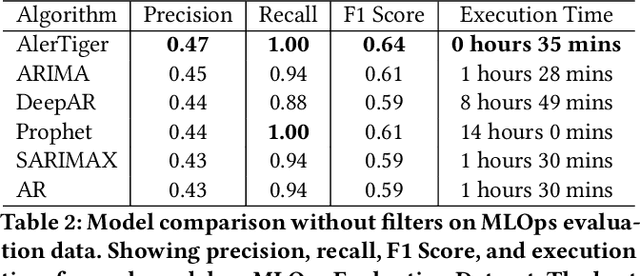
Data-driven companies use AI models extensively to develop products and intelligent business solutions, making the health of these models crucial for business success. Model monitoring and alerting in industries pose unique challenges, including a lack of clear model health metrics definition, label sparsity, and fast model iterations that result in short-lived models and features. As a product, there are also requirements for scalability, generalizability, and explainability. To tackle these challenges, we propose AlerTiger, a deep-learning-based MLOps model monitoring system that helps AI teams across the company monitor their AI models' health by detecting anomalies in models' input features and output score over time. The system consists of four major steps: model statistics generation, deep-learning-based anomaly detection, anomaly post-processing, and user alerting. Our solution generates three categories of statistics to indicate AI model health, offers a two-stage deep anomaly detection solution to address label sparsity and attain the generalizability of monitoring new models, and provides holistic reports for actionable alerts. This approach has been deployed to most of LinkedIn's production AI models for over a year and has identified several model issues that later led to significant business metric gains after fixing.
DTW-SiameseNet: Dynamic Time Warped Siamese Network for Mispronunciation Detection and Correction
Mar 01, 2023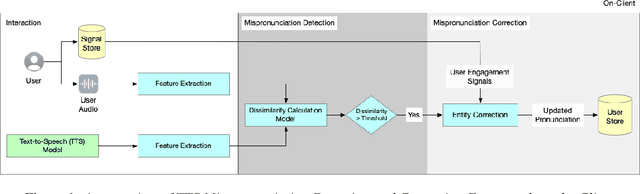
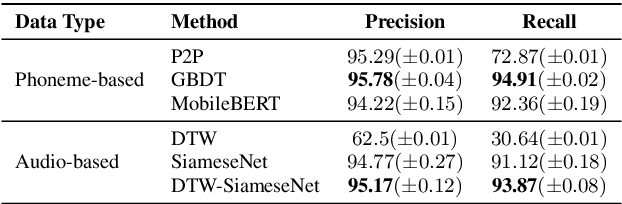

Personal Digital Assistants (PDAs) - such as Siri, Alexa and Google Assistant, to name a few - play an increasingly important role to access information and complete tasks spanning multiple domains, and by diverse groups of users. A text-to-speech (TTS) module allows PDAs to interact in a natural, human-like manner, and play a vital role when the interaction involves people with visual impairments or other disabilities. To cater to the needs of a diverse set of users, inclusive TTS is important to recognize and pronounce correctly text in different languages and dialects. Despite great progress in speech synthesis, the pronunciation accuracy of named entities in a multi-lingual setting still has a large room for improvement. Existing approaches to correct named entity (NE) mispronunciations, like retraining Grapheme-to-Phoneme (G2P) models, or maintaining a TTS pronunciation dictionary, require expensive annotation of the ground truth pronunciation, which is also time consuming. In this work, we present a highly-precise, PDA-compatible pronunciation learning framework for the task of TTS mispronunciation detection and correction. In addition, we also propose a novel mispronunciation detection model called DTW-SiameseNet, which employs metric learning with a Siamese architecture for Dynamic Time Warping (DTW) with triplet loss. We demonstrate that a locale-agnostic, privacy-preserving solution to the problem of TTS mispronunciation detection is feasible. We evaluate our approach on a real-world dataset, and a corpus of NE pronunciations of an anonymized audio dataset of person names recorded by participants from 10 different locales. Human evaluation shows our proposed approach improves pronunciation accuracy on average by ~6% compared to strong phoneme-based and audio-based baselines.
Real-Time Speech Enhancement Using Spectral Subtraction with Minimum Statistics and Spectral Floor
Feb 20, 2023
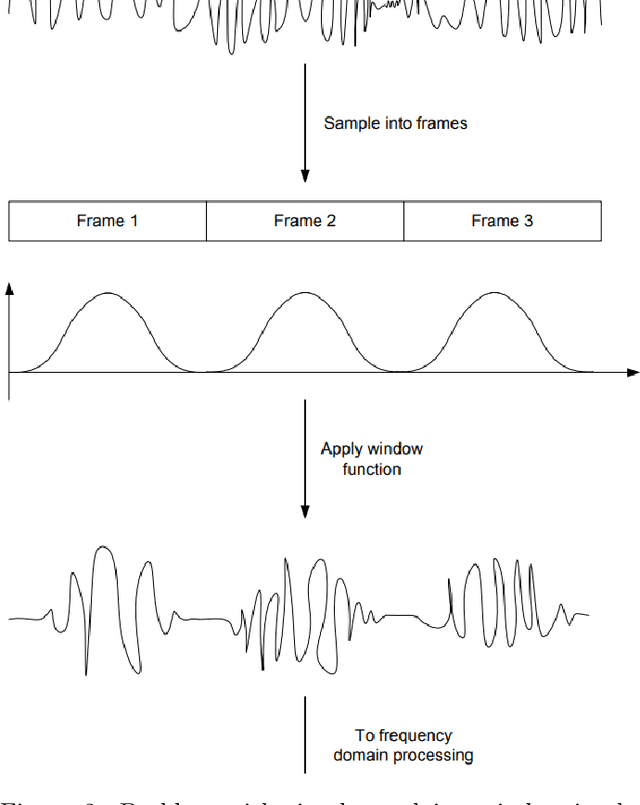
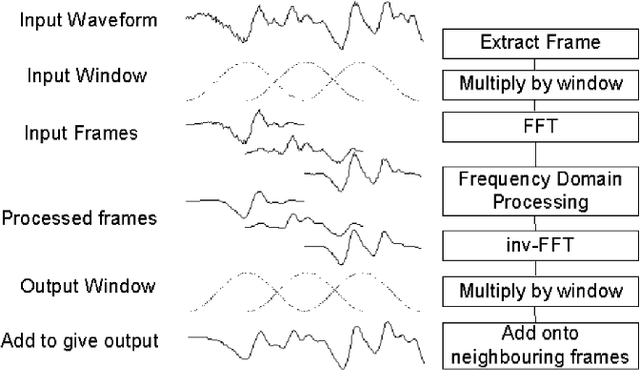
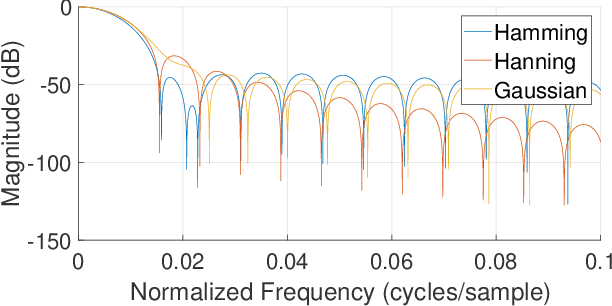
An initial real-time speech enhancement method is presented to reduce the effects of additive noise. The method operates in the frequency domain and is a form of spectral subtraction. Initially, minimum statistics are used to generate an estimate of the noise signal in the frequency domain. The use of minimum statistics avoids the need for a voice activity detector (VAD) which has proven to be challenging to create. As minimum statistics are used, the noise signal estimate must be multiplied by a scaling factor before subtraction from the noise corrupted speech signal can take place. A spectral floor is applied to the difference to suppress the effects of "musical noise". Finally, a series of further enhancements are considered to reduce the effects of residual noise even further. These methods are compared using time-frequency plots to create the final speech enhancement design
SLOTH: Structured Learning and Task-based Optimization for Time Series Forecasting on Hierarchies
Feb 27, 2023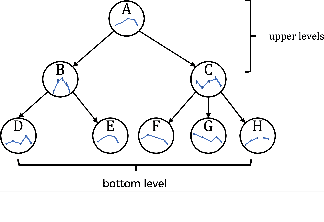
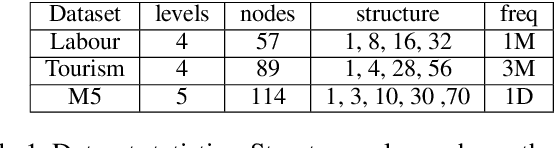
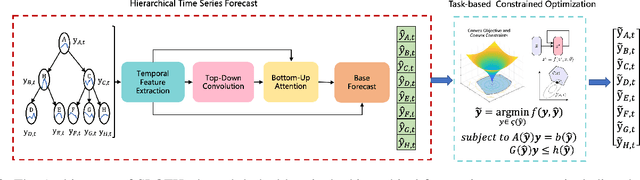
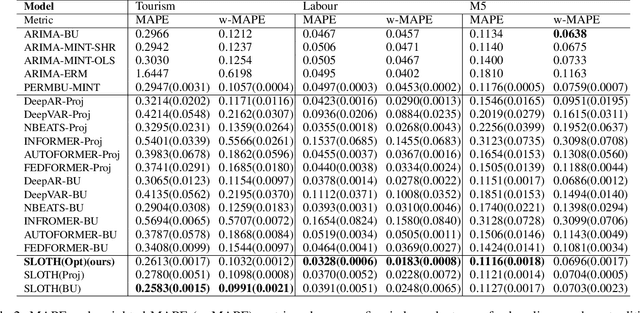
Multivariate time series forecasting with hierarchical structure is widely used in real-world applications, e.g., sales predictions for the geographical hierarchy formed by cities, states, and countries. The hierarchical time series (HTS) forecasting includes two sub-tasks, i.e., forecasting and reconciliation. In the previous works, hierarchical information is only integrated in the reconciliation step to maintain coherency, but not in forecasting step for accuracy improvement. In this paper, we propose two novel tree-based feature integration mechanisms, i.e., top-down convolution and bottom-up attention to leverage the information of the hierarchical structure to improve the forecasting performance. Moreover, unlike most previous reconciliation methods which either rely on strong assumptions or focus on coherent constraints only,we utilize deep neural optimization networks, which not only achieve coherency without any assumptions, but also allow more flexible and realistic constraints to achieve task-based targets, e.g., lower under-estimation penalty and meaningful decision-making loss to facilitate the subsequent downstream tasks. Experiments on real-world datasets demonstrate that our tree-based feature integration mechanism achieves superior performances on hierarchical forecasting tasks compared to the state-of-the-art methods, and our neural optimization networks can be applied to real-world tasks effectively without any additional effort under coherence and task-based constraints
On Performance Discrepancies Across Local Homophily Levels in Graph Neural Networks
Jun 08, 2023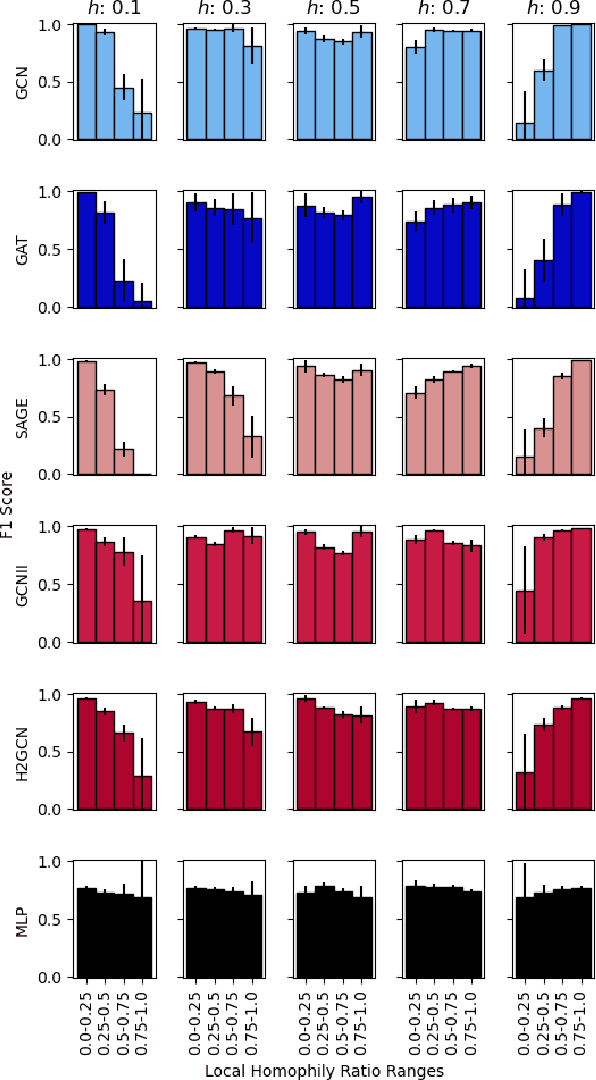
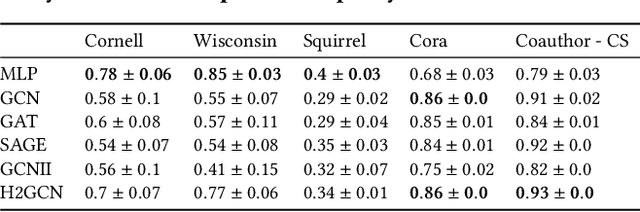
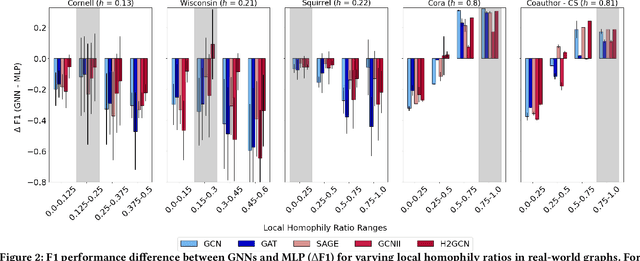
Research on GNNs has highlighted a relationship between high homophily (i.e., the tendency for nodes of a similar class to connect) and strong predictive performance in node classification. However, recent research has found the relationship to be more nuanced, demonstrating that even simple GNNs can learn in certain heterophilous settings. To bridge the gap between these findings, we revisit the assumptions made in previous works and identify that datasets are often treated as having a constant homophily level across nodes. To align closer to real-world datasets, we theoretically and empirically study the performance of GNNs when the local homophily level of a node deviates at test-time from the global homophily level of its graph. To aid our theoretical analysis, we introduce a new parameter to the preferential attachment model commonly used in homophily analysis to enable the control of local homophily levels in generated graphs, enabling a systematic empirical study on how local homophily can impact performance. We additionally perform a granular analysis on a number of real-world datasets with varying global homophily levels. Across our theoretical and empirical results, we find that (a)~ GNNs can fail to generalize to test nodes that deviate from the global homophily of a graph, (b)~ high local homophily does not necessarily confer high performance for a node, and (c)~ GNN models designed to handle heterophily are able to perform better across varying heterophily ranges irrespective of the dataset's global homophily. These findings point towards a GNN's over-reliance on the global homophily used for training and motivates the need to design GNNs that can better generalize across large local homophily ranges.
DeCoR: Defy Knowledge Forgetting by Predicting Earlier Audio Codes
May 29, 2023
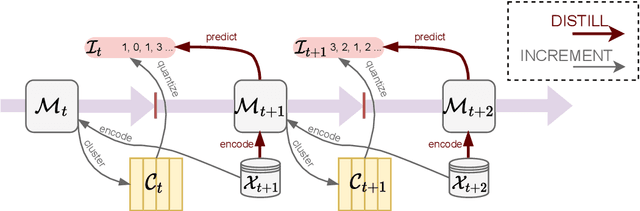
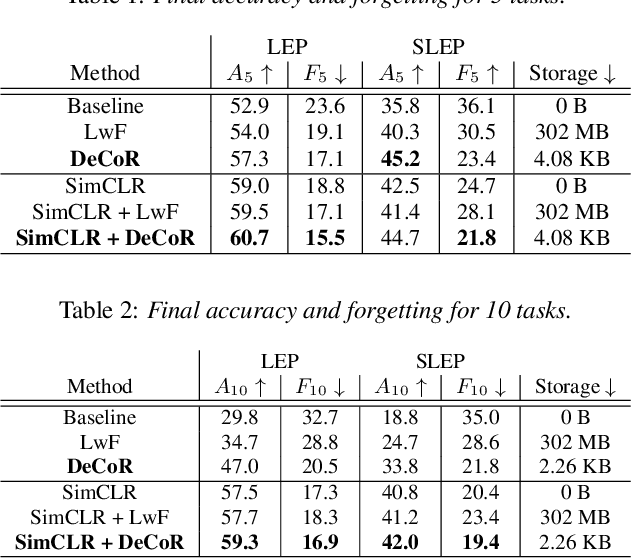
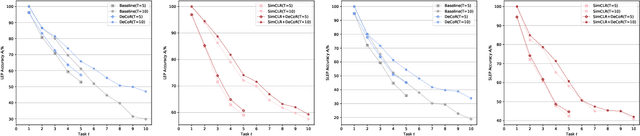
Lifelong audio feature extraction involves learning new sound classes incrementally, which is essential for adapting to new data distributions over time. However, optimizing the model only on new data can lead to catastrophic forgetting of previously learned tasks, which undermines the model's ability to perform well over the long term. This paper introduces a new approach to continual audio representation learning called DeCoR. Unlike other methods that store previous data, features, or models, DeCoR indirectly distills knowledge from an earlier model to the latest by predicting quantization indices from a delayed codebook. We demonstrate that DeCoR improves acoustic scene classification accuracy and integrates well with continual self-supervised representation learning. Our approach introduces minimal storage and computation overhead, making it a lightweight and efficient solution for continual learning.