 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Conditional Generative Chatbot using Transformer Model
Jun 03, 2023
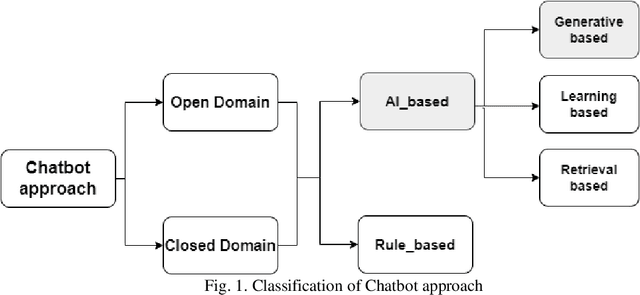
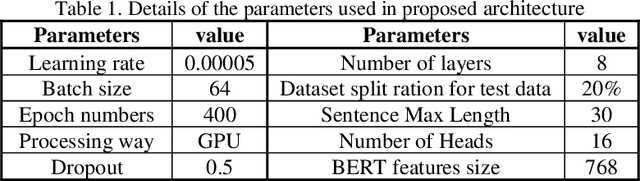
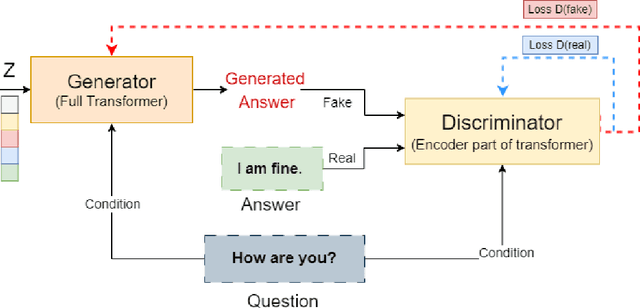
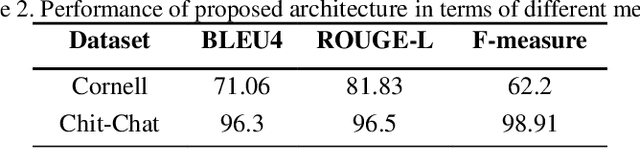
A Chatbot serves as a communication tool between a human user and a machine to achieve an appropriate answer based on the human input. In more recent approaches, a combination of Natural Language Processing and sequential models are used to build a generative Chatbot. The main challenge of these models is their sequential nature, which leads to less accurate results. To tackle this challenge, in this paper, a novel end-to-end architecture is proposed using conditional Wasserstein Generative Adversarial Networks and a transformer model for answer generation in Chatbots. While the generator of the proposed model consists of a full transformer model to generate an answer, the discriminator includes only the encoder part of a transformer model followed by a classifier. To the best of our knowledge, this is the first time that a generative Chatbot is proposed using the embedded transformer in both generator and discriminator models. Relying on the parallel computing of the transformer model, the results of the proposed model on the Cornell Movie-Dialog corpus and the Chit-Chat datasets confirm the superiority of the proposed model compared to state-of-the-art alternatives using different evaluation metrics.
Impact of translation on biomedical information extraction from real-life clinical notes
Jun 03, 2023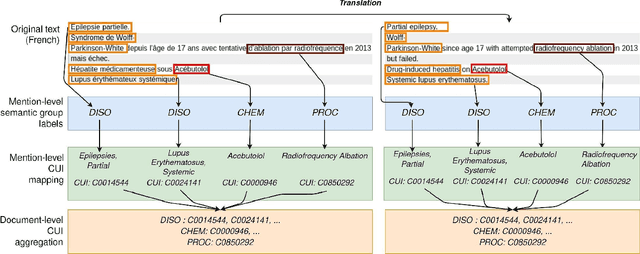
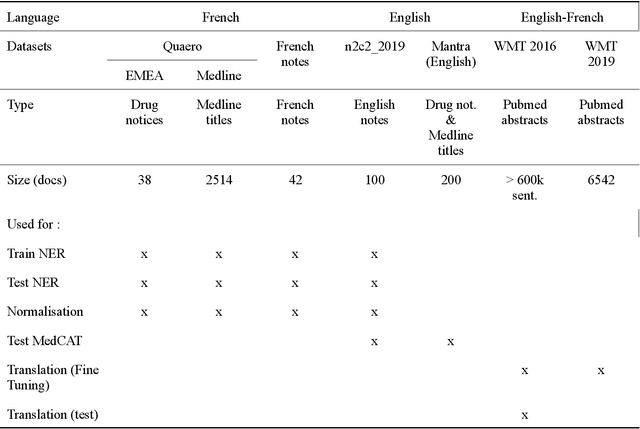
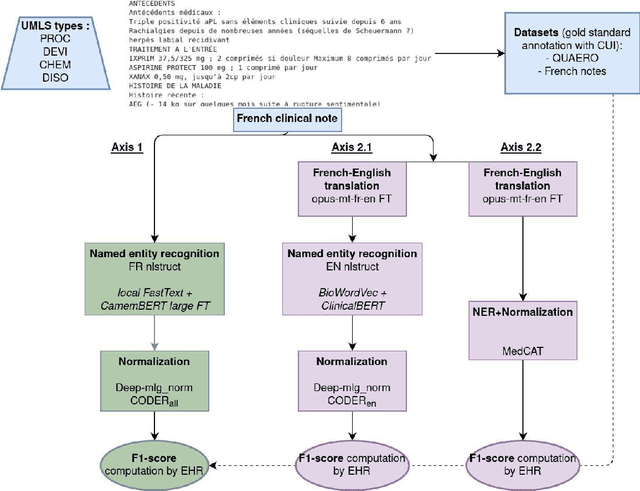
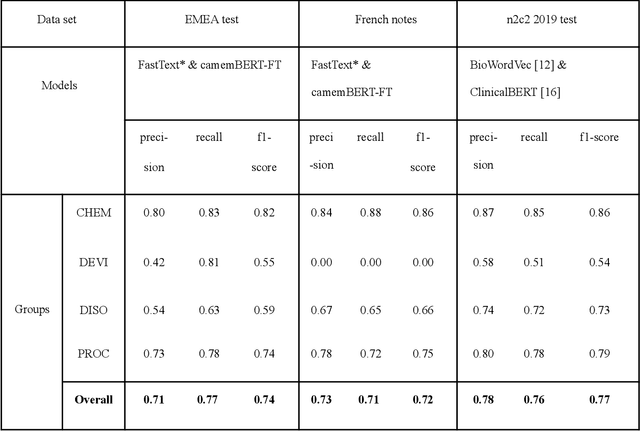
The objective of our study is to determine whether using English tools to extract and normalize French medical concepts on translations provides comparable performance to French models trained on a set of annotated French clinical notes. We compare two methods: a method involving French language models and a method involving English language models. For the native French method, the Named Entity Recognition (NER) and normalization steps are performed separately. For the translated English method, after the first translation step, we compare a two-step method and a terminology-oriented method that performs extraction and normalization at the same time. We used French, English and bilingual annotated datasets to evaluate all steps (NER, normalization and translation) of our algorithms. Concerning the results, the native French method performs better than the translated English one with a global f1 score of 0.51 [0.47;0.55] against 0.39 [0.34;0.44] and 0.38 [0.36;0.40] for the two English methods tested. In conclusion, despite the recent improvement of the translation models, there is a significant performance difference between the two approaches in favor of the native French method which is more efficient on French medical texts, even with few annotated documents.
Actor-Critic Methods using Physics-Informed Neural Networks: Control of a 1D PDE Model for Fluid-Cooled Battery Packs
May 18, 2023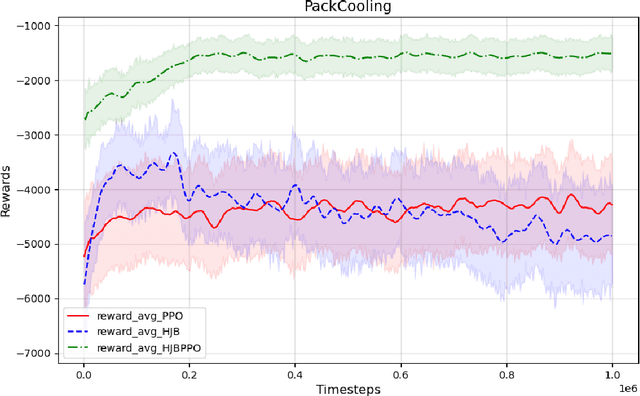
This paper proposes an actor-critic algorithm for controlling the temperature of a battery pack using a cooling fluid. This is modeled by a coupled 1D partial differential equation (PDE) with a controlled advection term that determines the speed of the cooling fluid. The Hamilton-Jacobi-Bellman (HJB) equation is a PDE that evaluates the optimality of the value function and determines an optimal controller. We propose an algorithm that treats the value network as a Physics-Informed Neural Network (PINN) to solve for the continuous-time HJB equation rather than a discrete-time Bellman optimality equation, and we derive an optimal controller for the environment that we exploit to achieve optimal control. Our experiments show that a hybrid-policy method that updates the value network using the HJB equation and updates the policy network identically to PPO achieves the best results in the control of this PDE system.
Terraforming -- Environment Manipulation during Disruptions for Multi-Agent Pickup and Delivery
May 19, 2023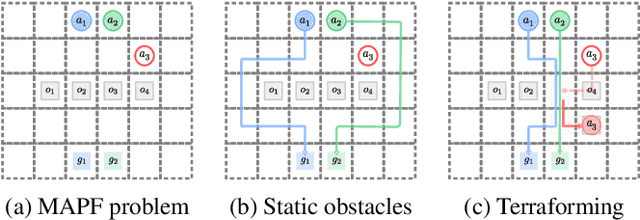
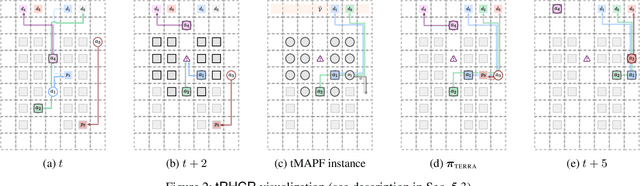
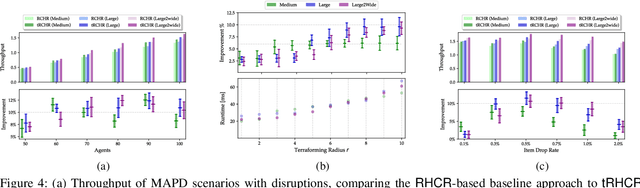
In automated warehouses, teams of mobile robots fulfill the packaging process by transferring inventory pods to designated workstations while navigating narrow aisles formed by tightly packed pods. This problem is typically modeled as a Multi-Agent Pickup and Delivery (MAPD) problem, which is then solved by repeatedly planning collision-free paths for agents on a fixed graph, as in the Rolling-Horizon Collision Resolution (RHCR) algorithm. However, existing approaches make the limiting assumption that agents are only allowed to move pods that correspond to their current task, while considering the other pods as stationary obstacles (even though all pods are movable). This behavior can result in unnecessarily long paths which could otherwise be avoided by opening additional corridors via pod manipulation. To this end, we explore the implications of allowing agents the flexibility of dynamically relocating pods. We call this new problem Terraforming MAPD (tMAPD) and develop an RHCR-based approach to tackle it. As the extra flexibility of terraforming comes at a significant computational cost, we utilize this capability judiciously by identifying situations where it could make a significant impact on the solution quality. In particular, we invoke terraforming in response to disruptions that often occur in automated warehouses, e.g., when an item is dropped from a pod or when agents malfunction. Empirically, using our approach for tMAPD, where disruptions are modeled via a stochastic process, we improve throughput by over 10%, reduce the maximum service time (the difference between the drop-off time and the pickup time of a pod) by more than 50%, without drastically increasing the runtime, compared to the MAPD setting.
Embracing Uncertainty: Adaptive Vague Preference Policy Learning for Multi-round Conversational Recommendation
Jun 07, 2023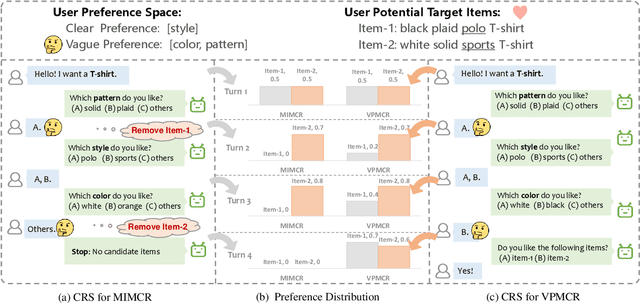
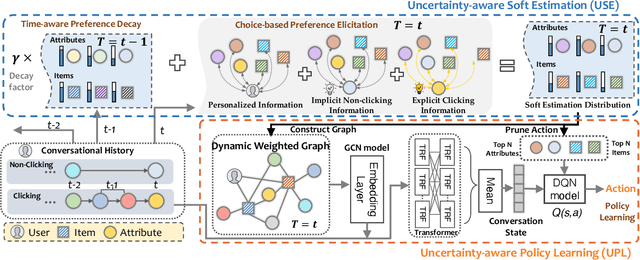
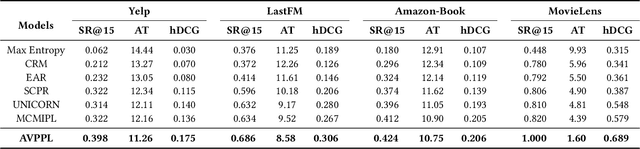
Conversational recommendation systems (CRS) effectively address information asymmetry by dynamically eliciting user preferences through multi-turn interactions. Existing CRS widely assumes that users have clear preferences. Under this assumption, the agent will completely trust the user feedback and treat the accepted or rejected signals as strong indicators to filter items and reduce the candidate space, which may lead to the problem of over-filtering. However, in reality, users' preferences are often vague and volatile, with uncertainty about their desires and changing decisions during interactions. To address this issue, we introduce a novel scenario called Vague Preference Multi-round Conversational Recommendation (VPMCR), which considers users' vague and volatile preferences in CRS.VPMCR employs a soft estimation mechanism to assign a non-zero confidence score for all candidate items to be displayed, naturally avoiding the over-filtering problem. In the VPMCR setting, we introduce an solution called Adaptive Vague Preference Policy Learning (AVPPL), which consists of two main components: Uncertainty-aware Soft Estimation (USE) and Uncertainty-aware Policy Learning (UPL). USE estimates the uncertainty of users' vague feedback and captures their dynamic preferences using a choice-based preferences extraction module and a time-aware decaying strategy. UPL leverages the preference distribution estimated by USE to guide the conversation and adapt to changes in users' preferences to make recommendations or ask for attributes. Our extensive experiments demonstrate the effectiveness of our method in the VPMCR scenario, highlighting its potential for practical applications and improving the overall performance and applicability of CRS in real-world settings, particularly for users with vague or dynamic preferences.
A novel deeponet model for learning moving-solution operators with applications to earthquake hypocenter localization
Jun 07, 2023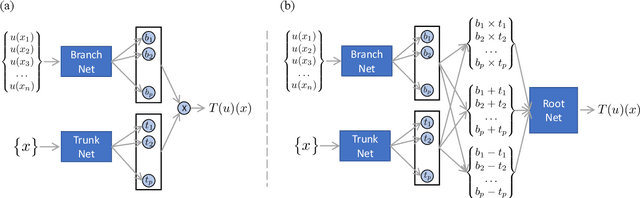
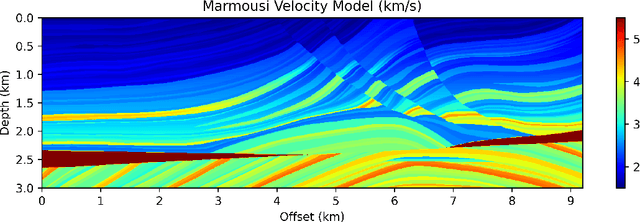
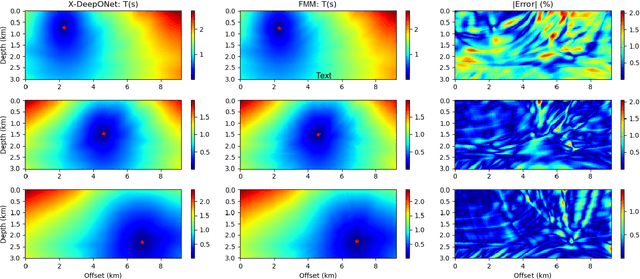
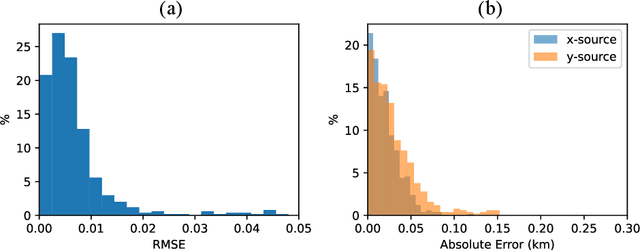
Seismicity induced by human activities poses a significant threat to public safety, emphasizing the need for accurate and timely earthquake hypocenter localization. In this study, we introduce X-DeepONet, a novel variant of deep operator networks (DeepONets), for learning moving-solution operators of parametric partial differential equations (PDEs), with application to real-time earthquake localization. Leveraging the power of neural operators, X-DeepONet learns to estimate traveltime fields associated with earthquake sources by incorporating information from seismic arrival times and velocity models. Similar to the DeepONet, X-DeepONet includes a trunk net and a branch net. Additionally, we introduce a root network that not only takes the standard DeepONet's multiplication operator as input, it also takes addition and subtraction operators. We show that for problems with moving fields, the standard multiplication operation of DeepONet is insufficient to capture field relocation, while addition and subtraction operators along with the eXtended root significantly improve its accuracy both under data-driven (supervised) and physics-informed (unsupervised) training. We demonstrate the effectiveness of X-DeepONet through various experiments, including scenarios with variable velocity models and arrival times. The results show remarkable accuracy in earthquake localization, even for heterogeneous and complex velocity models. The proposed framework also exhibits excellent generalization capabilities and robustness against noisy arrival times. The method provides a computationally efficient approach for quantifying uncertainty in hypocenter locations resulting from traveltime pick errors and velocity model variations. Our results underscore X-DeepONet's potential to improve seismic monitoring systems, aiding the development of early warning systems for seismic hazard mitigation.
CDLT: A Dataset with Concept Drift and Long-Tailed Distribution for Fine-Grained Visual Categorization
Jun 04, 2023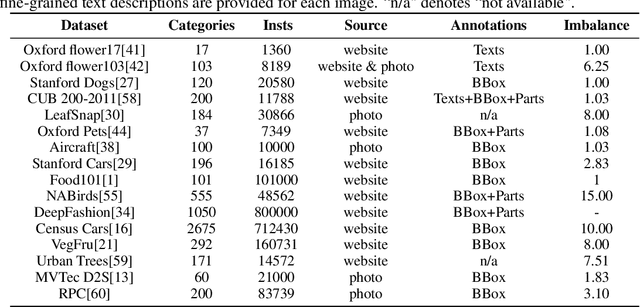


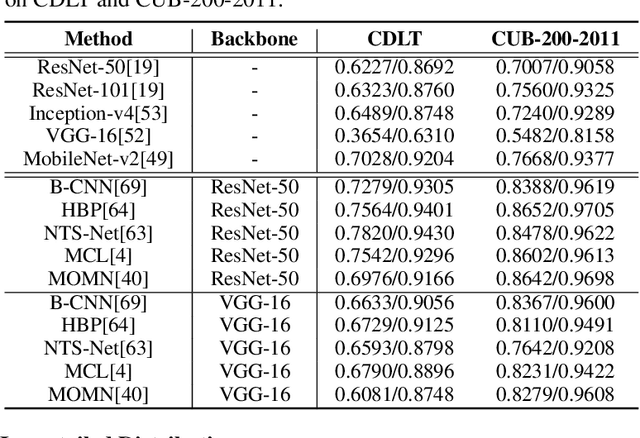
Data is the foundation for the development of computer vision, and the establishment of datasets plays an important role in advancing the techniques of fine-grained visual categorization~(FGVC). In the existing FGVC datasets used in computer vision, it is generally assumed that each collected instance has fixed characteristics and the distribution of different categories is relatively balanced. In contrast, the real world scenario reveals the fact that the characteristics of instances tend to vary with time and exhibit a long-tailed distribution. Hence, the collected datasets may mislead the optimization of the fine-grained classifiers, resulting in unpleasant performance in real applications. Starting from the real-world conditions and to promote the practical progress of fine-grained visual categorization, we present a Concept Drift and Long-Tailed Distribution dataset. Specifically, the dataset is collected by gathering 11195 images of 250 instances in different species for 47 consecutive months in their natural contexts. The collection process involves dozens of crowd workers for photographing and domain experts for labelling. Extensive baseline experiments using the state-of-the-art fine-grained classification models demonstrate the issues of concept drift and long-tailed distribution existed in the dataset, which require the attention of future researches.
EfficientSRFace: An Efficient Network with Super-Resolution Enhancement for Accurate Face Detection
Jun 04, 2023
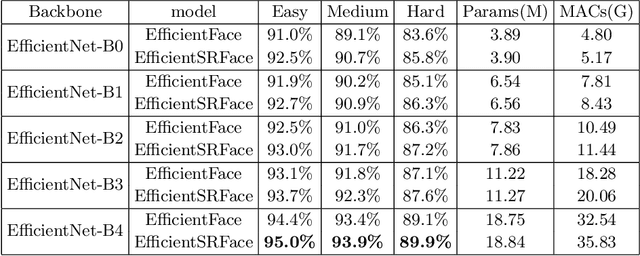
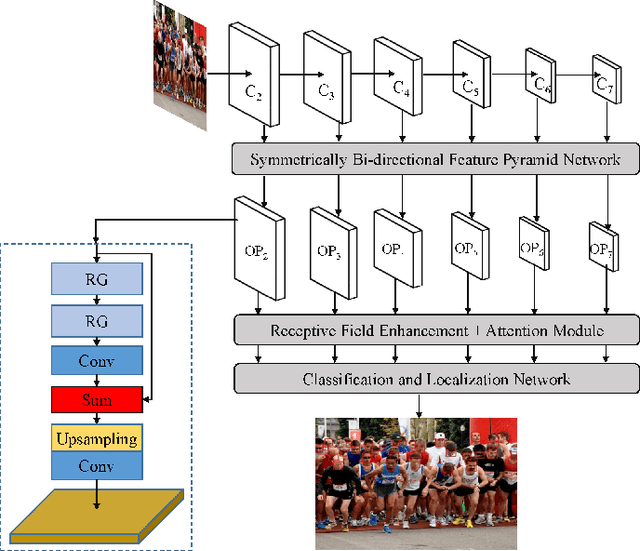
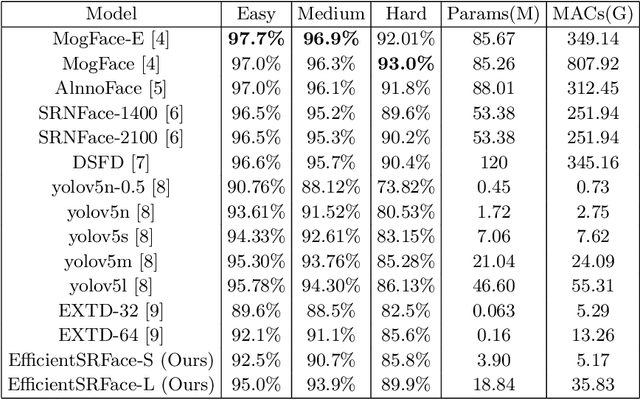
In face detection, low-resolution faces, such as numerous small faces of a human group in a crowded scene, are common in dense face prediction tasks. They usually contain limited visual clues and make small faces less distinguishable from the other small objects, which poses great challenge to accurate face detection. Although deep convolutional neural network has significantly promoted the research on face detection recently, current deep face detectors rarely take into account low-resolution faces and are still vulnerable to the real-world scenarios where massive amount of low-resolution faces exist. Consequently, they usually achieve degraded performance for low-resolution face detection. In order to alleviate this problem, we develop an efficient detector termed EfficientSRFace by introducing a feature-level super-resolution reconstruction network for enhancing the feature representation capability of the model. This module plays an auxiliary role in the training process, and can be removed during the inference without increasing the inference time. Extensive experiments on public benchmarking datasets, such as FDDB and WIDER Face, show that the embedded image super-resolution module can significantly improve the detection accuracy at the cost of a small amount of additional parameters and computational overhead, while helping our model achieve competitive performance compared with the state-of-the-arts methods.
The Power Of Simplicity: Why Simple Linear Models Outperform Complex Machine Learning Techniques -- Case Of Breast Cancer Diagnosis
Jun 04, 2023
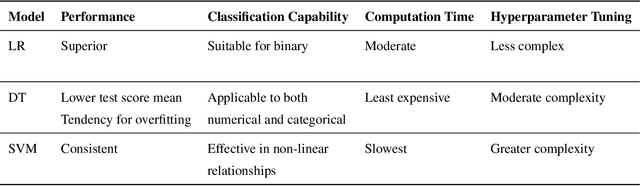
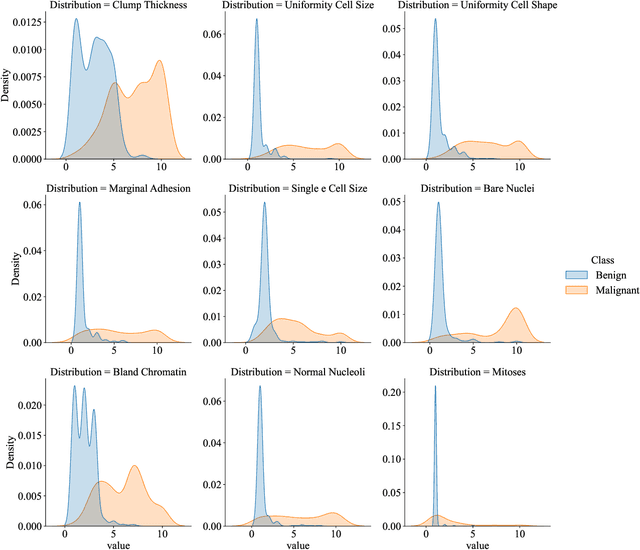
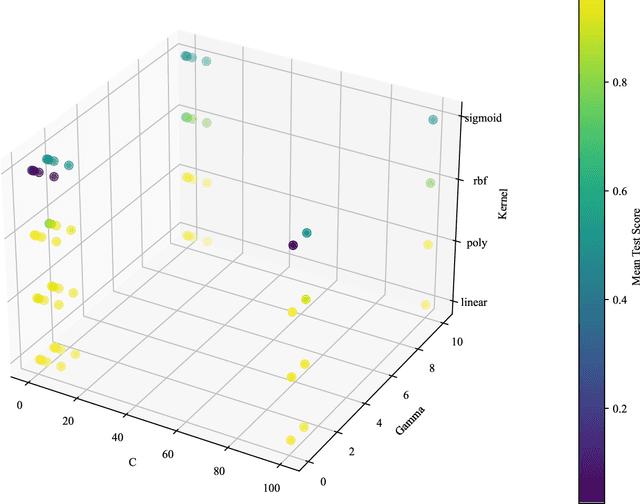
This research paper investigates the effectiveness of simple linear models versus complex machine learning techniques in breast cancer diagnosis, emphasizing the importance of interpretability and computational efficiency in the medical domain. We focus on Logistic Regression (LR), Decision Trees (DT), and Support Vector Machines (SVM) and optimize their performance using the UCI Machine Learning Repository dataset. Our findings demonstrate that the simpler linear model, LR, outperforms the more complex DT and SVM techniques, with a test score mean of 97.28%, a standard deviation of 1.62%, and a computation time of 35.56 ms. In comparison, DT achieved a test score mean of 93.73%, and SVM had a test score mean of 96.44%. The superior performance of LR can be attributed to its simplicity and interpretability, which provide a clear understanding of the relationship between input features and the outcome. This is particularly valuable in the medical domain, where interpretability is crucial for decision-making. Moreover, the computational efficiency of LR offers advantages in terms of scalability and real-world applicability. The results of this study highlight the power of simplicity in the context of breast cancer diagnosis and suggest that simpler linear models like LR can be more effective, interpretable, and computationally efficient than their complex counterparts, making them a more suitable choice for medical applications.
Predicting Unplanned Readmissions in the Intensive Care Unit: A Multimodality Evaluation
May 14, 2023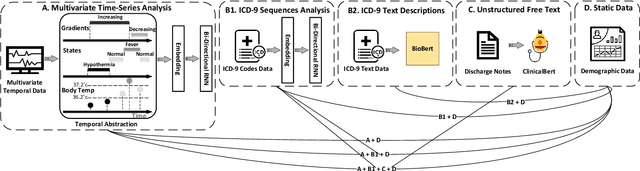
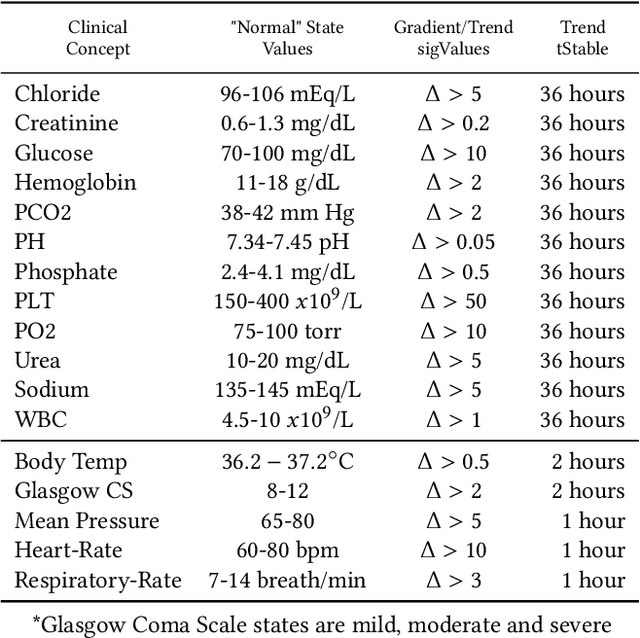

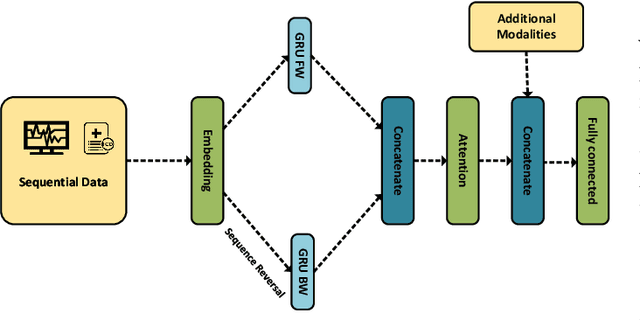
A hospital readmission is when a patient who was discharged from the hospital is admitted again for the same or related care within a certain period. Hospital readmissions are a significant problem in the healthcare domain, as they lead to increased hospitalization costs, decreased patient satisfaction, and increased risk of adverse outcomes such as infections, medication errors, and even death. The problem of hospital readmissions is particularly acute in intensive care units (ICUs), due to the severity of the patients' conditions, and the substantial risk of complications. Predicting Unplanned Readmissions in ICUs is a challenging task, as it involves analyzing different data modalities, such as static data, unstructured free text, sequences of diagnoses and procedures, and multivariate time-series. Here, we investigate the effectiveness of each data modality separately, then alongside with others, using state-of-the-art machine learning approaches in time-series analysis and natural language processing. Using our evaluation process, we are able to determine the contribution of each data modality, and for the first time in the context of readmission, establish a hierarchy of their predictive value. Additionally, we demonstrate the impact of Temporal Abstractions in enhancing the performance of time-series approaches to readmission prediction. Due to conflicting definitions in the literature, we also provide a clear definition of the term Unplanned Readmission to enhance reproducibility and consistency of future research and to prevent any potential misunderstandings that could result from diverse interpretations of the term. Our experimental results on a large benchmark clinical data set show that Discharge Notes written by physicians, have better capabilities for readmission prediction than all other modalities.