 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming
Jun 08, 2023
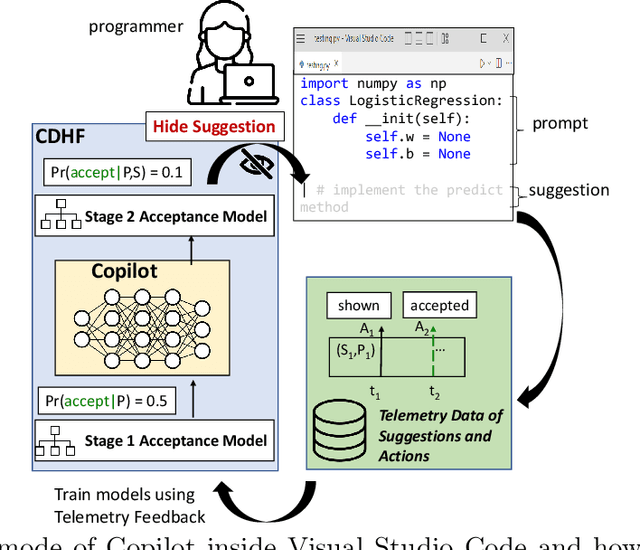
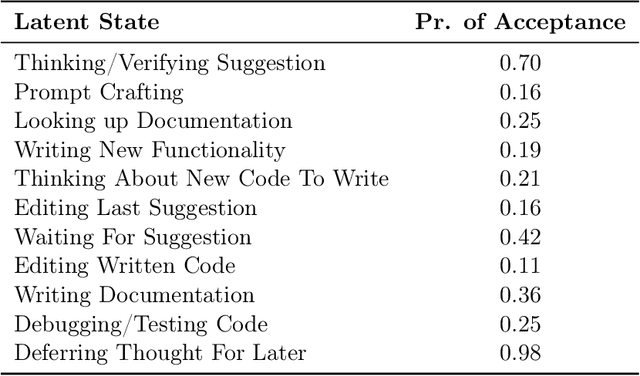
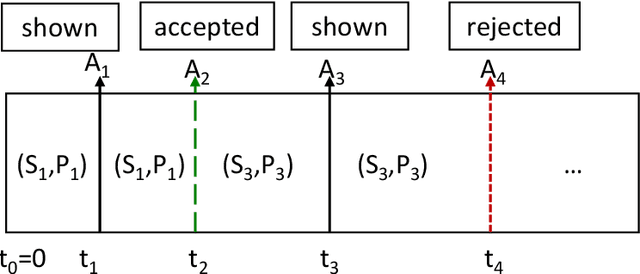
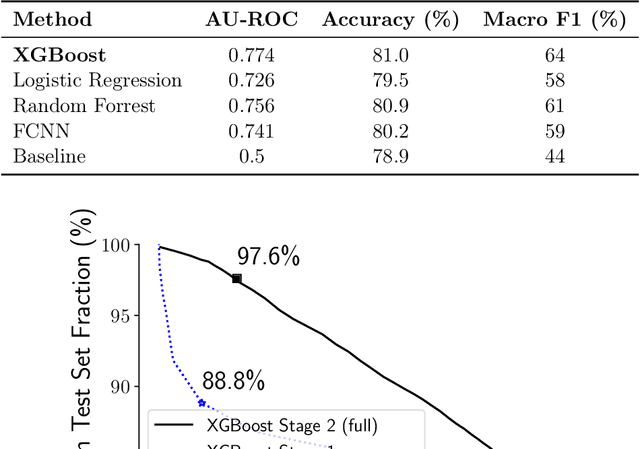
AI powered code-recommendation systems, such as Copilot and CodeWhisperer, provide code suggestions inside a programmer's environment (e.g., an IDE) with the aim to improve their productivity. Since, in these scenarios, programmers accept and reject suggestions, ideally, such a system should use this feedback in furtherance of this goal. In this work we leverage prior data of programmers interacting with Copilot to develop interventions that can save programmer time. We propose a utility theory framework, which models this interaction with programmers and decides when and which suggestions to display. Our framework Conditional suggestion Display from Human Feedback (CDHF) is based on predictive models of programmer actions. Using data from 535 programmers we build models that predict the likelihood of suggestion acceptance. In a retrospective evaluation on real-world programming tasks solved with AI-assisted programming, we find that CDHF can achieve favorable tradeoffs. Our findings show the promise of integrating human feedback to improve interaction with large language models in scenarios such as programming and possibly writing tasks.
Scalable and Adaptive Log-based Anomaly Detection with Expert in the Loop
Jun 08, 2023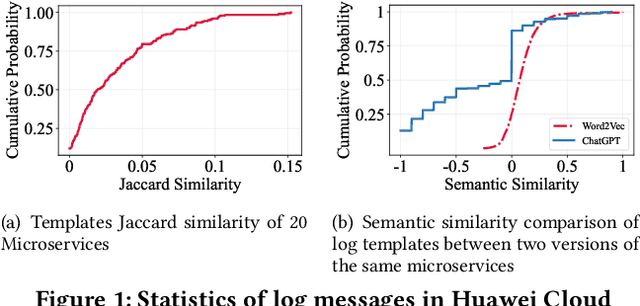
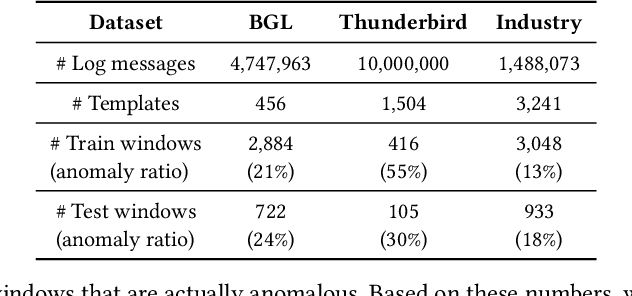

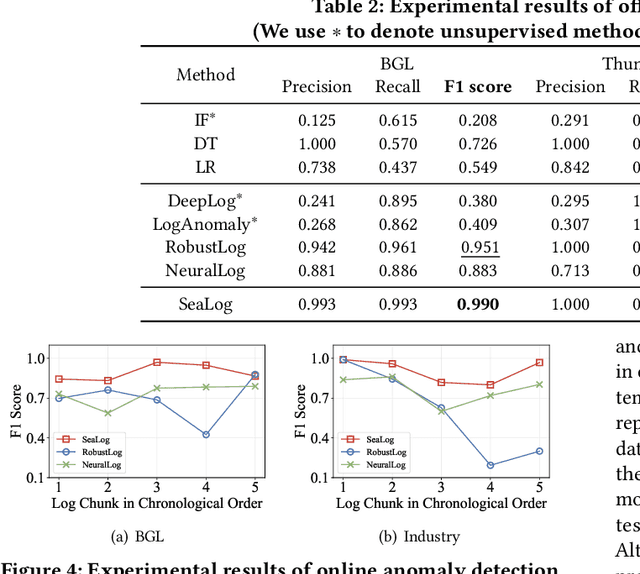
System logs play a critical role in maintaining the reliability of software systems. Fruitful studies have explored automatic log-based anomaly detection and achieved notable accuracy on benchmark datasets. However, when applied to large-scale cloud systems, these solutions face limitations due to high resource consumption and lack of adaptability to evolving logs. In this paper, we present an accurate, lightweight, and adaptive log-based anomaly detection framework, referred to as SeaLog. Our method introduces a Trie-based Detection Agent (TDA) that employs a lightweight, dynamically-growing trie structure for real-time anomaly detection. To enhance TDA's accuracy in response to evolving log data, we enable it to receive feedback from experts. Interestingly, our findings suggest that contemporary large language models, such as ChatGPT, can provide feedback with a level of consistency comparable to human experts, which can potentially reduce manual verification efforts. We extensively evaluate SeaLog on two public datasets and an industrial dataset. The results show that SeaLog outperforms all baseline methods in terms of effectiveness, runs 2X to 10X faster and only consumes 5% to 41% of the memory resource.
Advancing Italian Biomedical Information Extraction with Large Language Models: Methodological Insights and Multicenter Practical Application
Jun 08, 2023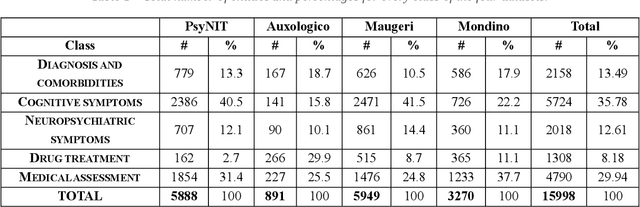
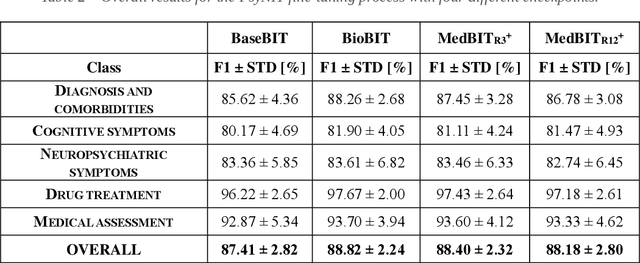
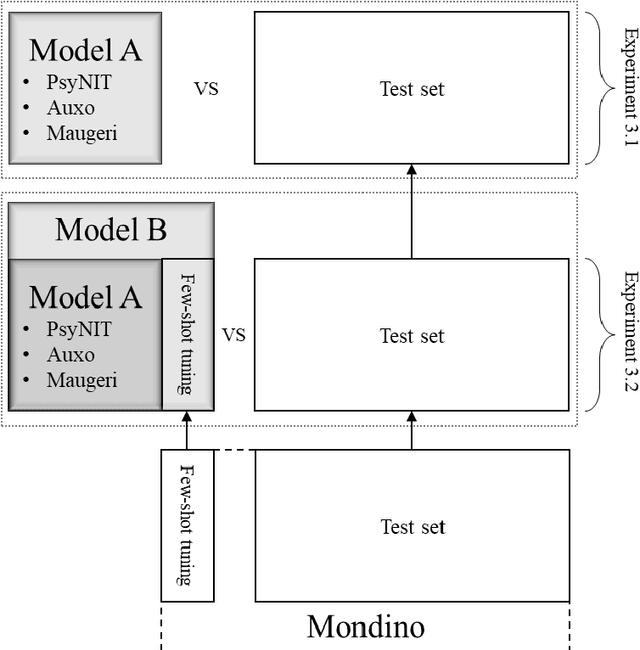
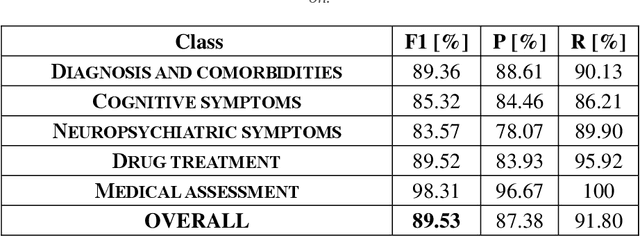
The introduction of computerized medical records in hospitals has reduced burdensome operations like manual writing and information fetching. However, the data contained in medical records are still far underutilized, primarily because extracting them from unstructured textual medical records takes time and effort. Information Extraction, a subfield of Natural Language Processing, can help clinical practitioners overcome this limitation, using automated text-mining pipelines. In this work, we created the first Italian neuropsychiatric Named Entity Recognition dataset, PsyNIT, and used it to develop a Large Language Model for this task. Moreover, we conducted several experiments with three external independent datasets to implement an effective multicenter model, with overall F1-score 84.77%, Precision 83.16%, Recall 86.44%. The lessons learned are: (i) the crucial role of a consistent annotation process and (ii) a fine-tuning strategy that combines classical methods with a "few-shot" approach. This allowed us to establish methodological guidelines that pave the way for future implementations in this field and allow Italian hospitals to tap into important research opportunities.
Utterance Emotion Dynamics in Children's Poems: Emotional Changes Across Age
Jun 08, 2023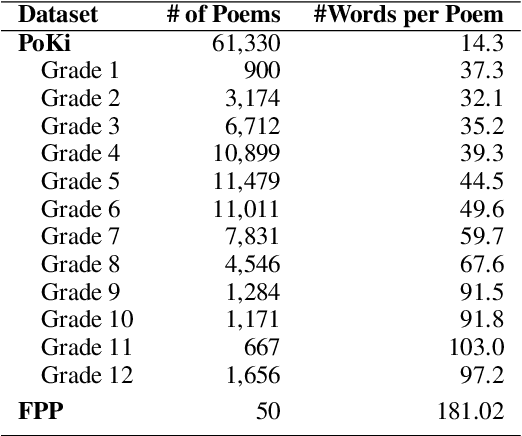
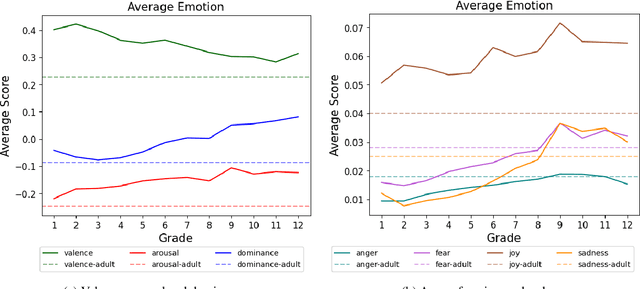
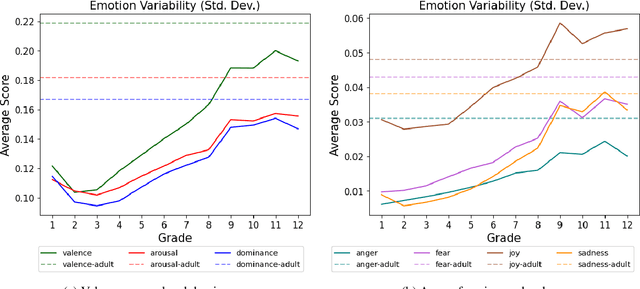

Emerging psychopathology studies are showing that patterns of changes in emotional state -- emotion dynamics -- are associated with overall well-being and mental health. More recently, there has been some work in tracking emotion dynamics through one's utterances, allowing for data to be collected on a larger scale across time and people. However, several questions about how emotion dynamics change with age, especially in children, and when determined through children's writing, remain unanswered. In this work, we use both a lexicon and a machine learning based approach to quantify characteristics of emotion dynamics determined from poems written by children of various ages. We show that both approaches point to similar trends: consistent increasing intensities for some emotions (e.g., anger, fear, joy, sadness, arousal, and dominance) with age and a consistent decreasing valence with age. We also find increasing emotional variability, rise rates (i.e., emotional reactivity), and recovery rates (i.e., emotional regulation) with age. These results act as a useful baselines for further research in how patterns of emotions expressed by children change with age, and their association with mental health.
Orthogonal Sampling based Broad-Band Signal Generation with Low-Bandwidth Electronics
Jun 08, 2023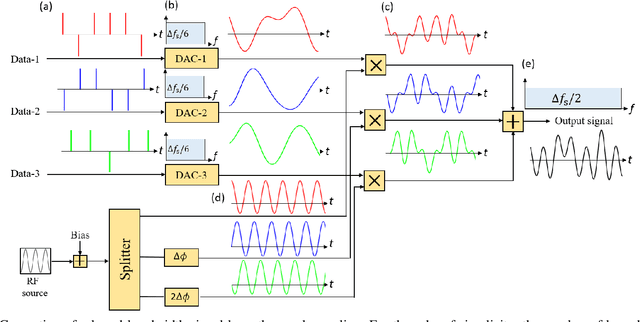
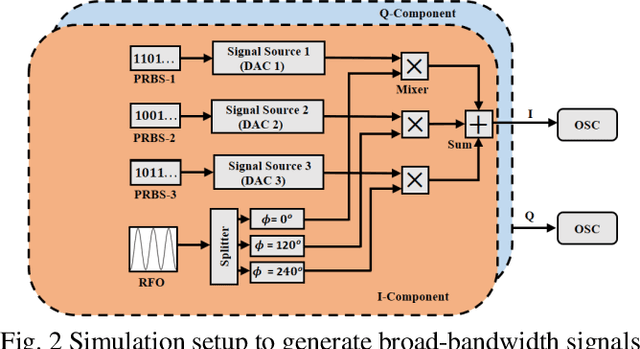
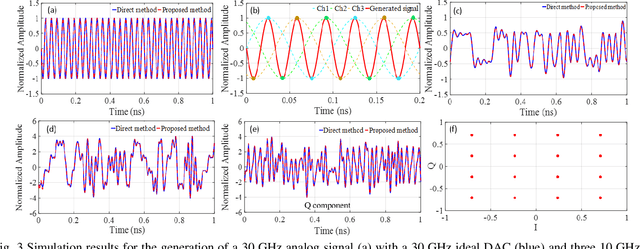
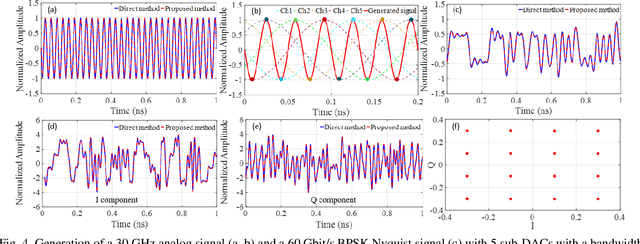
High-bandwidth signals are needed in many applications like radar, sensing, measurement and communications. Especially in optical networks, the sampling rate and analog bandwidth of digital-to-analog converters (DACs) is a bottleneck for further increasing data rates. To circumvent the sampling rate and bandwidth problem of electronic DACs, we demonstrate the generation of wide-band signals with low-bandwidth electronics. This generation is based on orthogonal sampling with sinc-pulse sequences in N parallel branches. The method not only reduces the sampling rate and bandwidth, at the same time the effective number of bits (ENOB) is improved, dramatically reducing the requirements on the electronic signal processing. In proof of concept experiments the generation of analog signals, as well as Nyquist shaped and normal data will be shown. In simulations we investigate the performance of 60 GHz data generation by 20 and 12 GHz electronics. The method can easily be integrated together with already existing electronic DAC designs and would be of great interest for all high-bandwidth applications.
Creating Disasters: Recession Forecasting with GAN-Generated Synthetic Time Series Data
Feb 21, 2023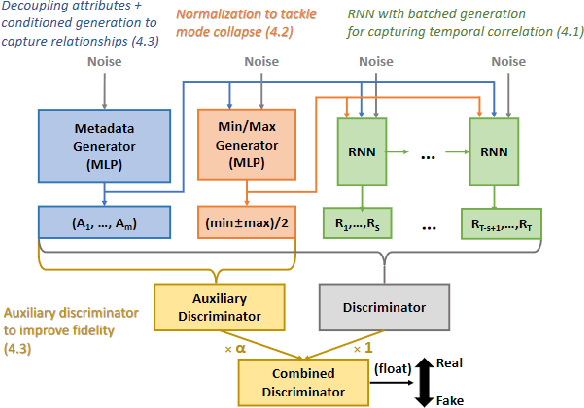
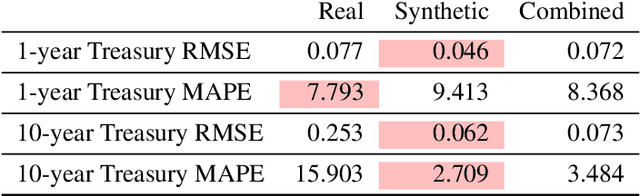
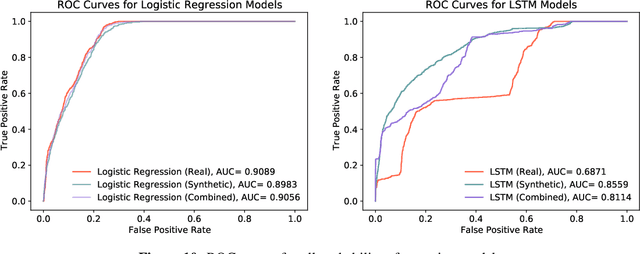
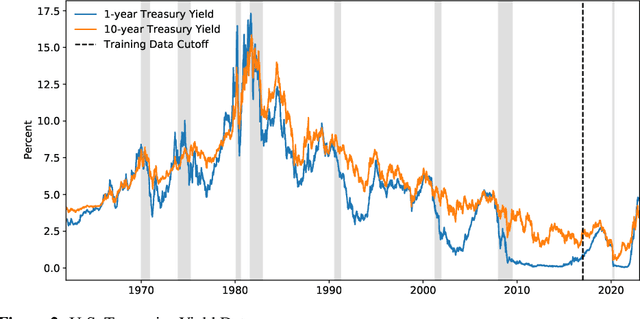
A common problem when forecasting rare events, such as recessions, is limited data availability. Recent advancements in deep learning and generative adversarial networks (GANs) make it possible to produce high-fidelity synthetic data in large quantities. This paper uses a model called DoppelGANger, a GAN tailored to producing synthetic time series data, to generate synthetic Treasury yield time series and associated recession indicators. It is then shown that short-range forecasting performance for Treasury yields is improved for models trained on synthetic data relative to models trained only on real data. Finally, synthetic recession conditions are produced and used to train classification models to predict the probability of a future recession. It is shown that training models on synthetic recessions can improve a model's ability to predict future recessions over a model trained only on real data.
To Re-transmit or Not to Re-transmit for Freshness
May 17, 2023We consider a time slotted communication network with a base station (BS) and a user. At each time slot a fresh update packet arrives at the BS with probability $p>0$. When the BS transmits an update packet for the first time, it goes through with a success probability of $q_1$. In all subsequent re-transmissions, the packet goes through with a success probability of $q_2$ where $q_2>q_1$, due to the accumulation of observations at the receiver used to decode the packet. When the packet goes through the first time, the age of the user drops to 1, while when the packet goes through in subsequent transmissions, the age of the user drops to the age of the packet since its generation. Thus, when the BS is in the process of re-transmitting an old packet, if it receives a new packet, it has to decide whether to re-transmit the old packet with higher probability of successful transmission but resulting in higher age, or to transmit the new packet which will result in a lower age upon successful reception but this will happen with lower probability. In this paper, we provide an optimal algorithm to solve this problem.
Sequence-to-Sequence Forecasting-aided State Estimation for Power Systems
May 22, 2023Power system state forecasting has gained more attention in real-time operations recently. Unique challenges to energy systems are emerging with the massive deployment of renewable energy resources. As a result, power system state forecasting are becoming more crucial for monitoring, operating and securing modern power systems. This paper proposes an end-to-end deep learning framework to accurately predict multi-step power system state estimations in real-time. In our model, we employ a sequence-to-sequence framework to allow for multi-step forecasting. Bidirectional gated recurrent units (BiGRUs) are incorporated into the model to achieve high prediction accuracy. The dominant performance of our model is validated using real dataset. Experimental results show the superiority of our model in predictive power compared to existing alternatives.
Towards Building Voice-based Conversational Recommender Systems: Datasets, Potential Solutions, and Prospects
Jun 14, 2023
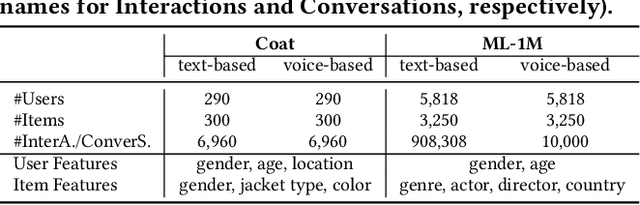
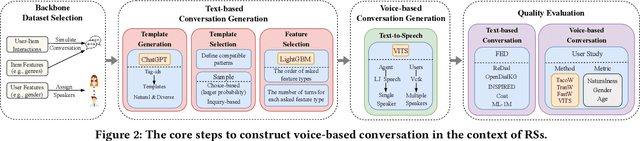
Conversational recommender systems (CRSs) have become crucial emerging research topics in the field of RSs, thanks to their natural advantages of explicitly acquiring user preferences via interactive conversations and revealing the reasons behind recommendations. However, the majority of current CRSs are text-based, which is less user-friendly and may pose challenges for certain users, such as those with visual impairments or limited writing and reading abilities. Therefore, for the first time, this paper investigates the potential of voice-based CRS (VCRSs) to revolutionize the way users interact with RSs in a natural, intuitive, convenient, and accessible fashion. To support such studies, we create two VCRSs benchmark datasets in the e-commerce and movie domains, after realizing the lack of such datasets through an exhaustive literature review. Specifically, we first empirically verify the benefits and necessity of creating such datasets. Thereafter, we convert the user-item interactions to text-based conversations through the ChatGPT-driven prompts for generating diverse and natural templates, and then synthesize the corresponding audios via the text-to-speech model. Meanwhile, a number of strategies are delicately designed to ensure the naturalness and high quality of voice conversations. On this basis, we further explore the potential solutions and point out possible directions to build end-to-end VCRSs by seamlessly extracting and integrating voice-based inputs, thus delivering performance-enhanced, self-explainable, and user-friendly VCRSs. Our study aims to establish the foundation and motivate further pioneering research in the emerging field of VCRSs. This aligns with the principles of explainable AI and AI for social good, viz., utilizing technology's potential to create a fair, sustainable, and just world.
Sequential Monte Carlo Steering of Large Language Models using Probabilistic Programs
Jun 05, 2023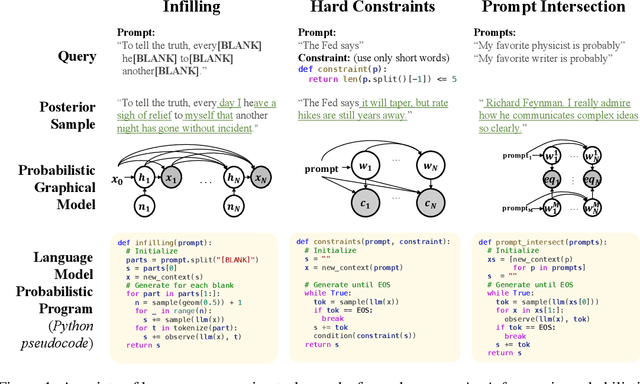

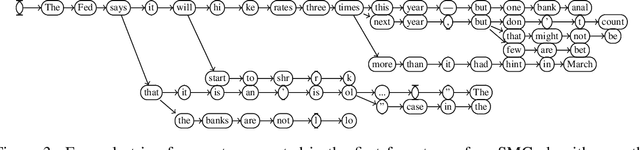
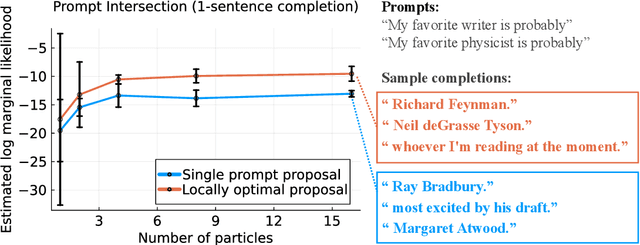
Even after fine-tuning and reinforcement learning, large language models (LLMs) can be difficult, if not impossible, to control reliably with prompts alone. We propose a new inference-time approach to enforcing syntactic and semantic constraints on the outputs of LLMs, called sequential Monte Carlo (SMC) steering. The key idea is to specify language generation tasks as posterior inference problems in a class of discrete probabilistic sequence models, and replace standard decoding with sequential Monte Carlo inference. For a computational cost similar to that of beam search, SMC can steer LLMs to solve diverse tasks, including infilling, generation under syntactic constraints, and prompt intersection. To facilitate experimentation with SMC steering, we present a probabilistic programming library, LLaMPPL (https://github.com/probcomp/LLaMPPL), for concisely specifying new generation tasks as language model probabilistic programs, and automating steering of LLaMA-family Transformers.