 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Embedded Named Entity Recognition using Probing Classifiers
Mar 18, 2024
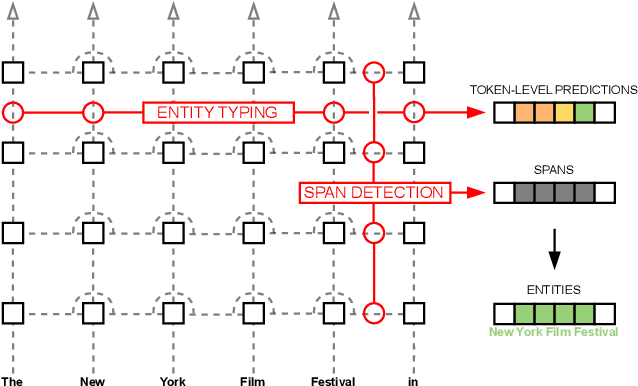
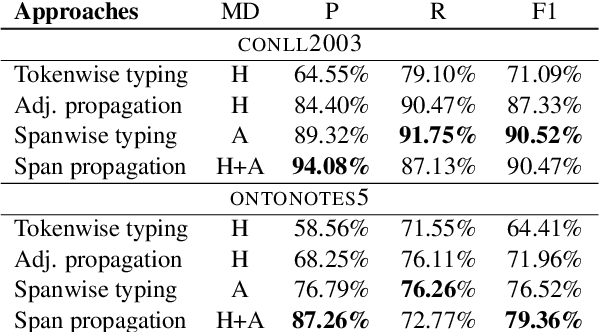
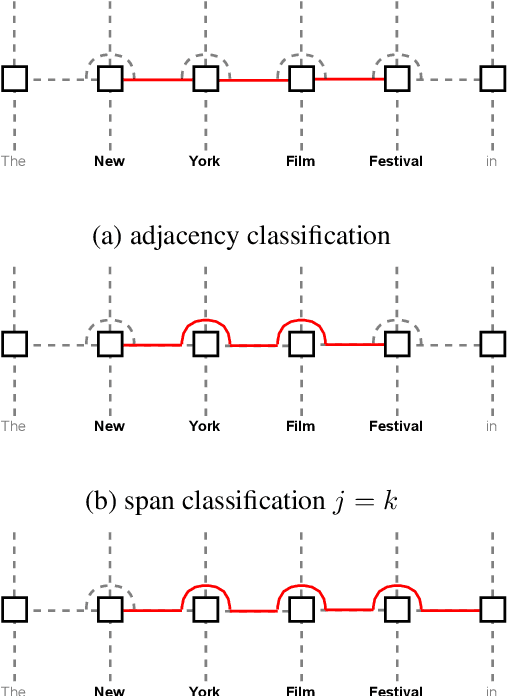
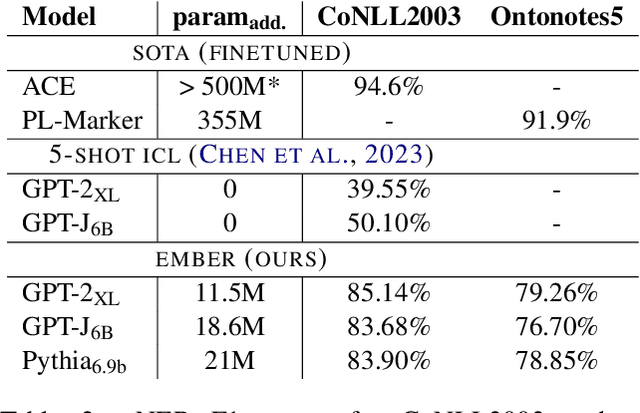
Extracting semantic information from generated text is a useful tool for applications such as automated fact checking or retrieval augmented generation. Currently, this requires either separate models during inference, which increases computational cost, or destructive fine-tuning of the language model. Instead, we propose directly embedding information extraction capabilities into pre-trained language models using probing classifiers, enabling efficient simultaneous text generation and information extraction. For this, we introduce an approach called EMBER and show that it enables named entity recognition in decoder-only language models without fine-tuning them and while incurring minimal additional computational cost at inference time. Specifically, our experiments using GPT-2 show that EMBER maintains high token generation rates during streaming text generation, with only a negligible decrease in speed of around 1% compared to a 43.64% slowdown measured for a baseline using a separate NER model. Code and data are available at https://github.com/nicpopovic/EMBER.
NEDS-SLAM: A Novel Neural Explicit Dense Semantic SLAM Framework using 3D Gaussian Splatting
Mar 18, 2024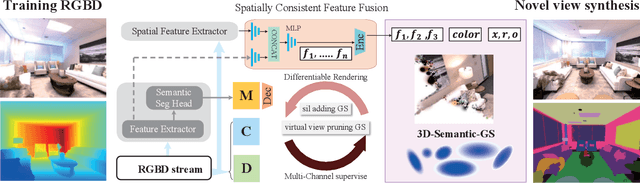
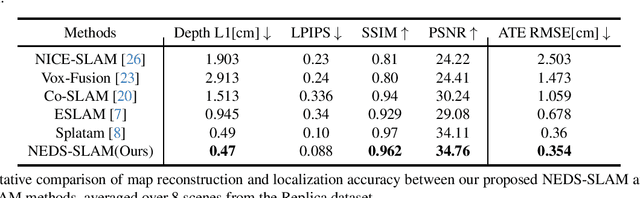
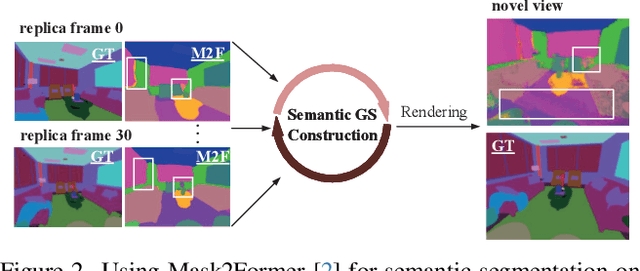
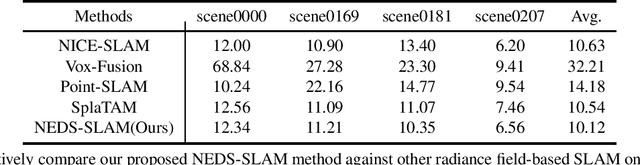
We propose NEDS-SLAM, an Explicit Dense semantic SLAM system based on 3D Gaussian representation, that enables robust 3D semantic mapping, accurate camera tracking, and high-quality rendering in real-time. In the system, we propose a Spatially Consistent Feature Fusion model to reduce the effect of erroneous estimates from pre-trained segmentation head on semantic reconstruction, achieving robust 3D semantic Gaussian mapping. Additionally, we employ a lightweight encoder-decoder to compress the high-dimensional semantic features into a compact 3D Gaussian representation, mitigating the burden of excessive memory consumption. Furthermore, we leverage the advantage of 3D Gaussian splatting, which enables efficient and differentiable novel view rendering, and propose a Virtual Camera View Pruning method to eliminate outlier GS points, thereby effectively enhancing the quality of scene representations. Our NEDS-SLAM method demonstrates competitive performance over existing dense semantic SLAM methods in terms of mapping and tracking accuracy on Replica and ScanNet datasets, while also showing excellent capabilities in 3D dense semantic mapping.
Optimal and Adaptive Non-Stationary Dueling Bandits Under a Generalized Borda Criterion
Mar 19, 2024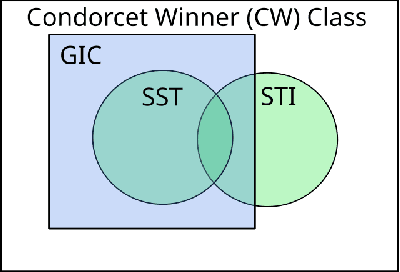

In dueling bandits, the learner receives preference feedback between arms, and the regret of an arm is defined in terms of its suboptimality to a winner arm. The more challenging and practically motivated non-stationary variant of dueling bandits, where preferences change over time, has been the focus of several recent works (Saha and Gupta, 2022; Buening and Saha, 2023; Suk and Agarwal, 2023). The goal is to design algorithms without foreknowledge of the amount of change. The bulk of known results here studies the Condorcet winner setting, where an arm preferred over any other exists at all times. Yet, such a winner may not exist and, to contrast, the Borda version of this problem (which is always well-defined) has received little attention. In this work, we establish the first optimal and adaptive Borda dynamic regret upper bound, which highlights fundamental differences in the learnability of severe non-stationarity between Condorcet vs. Borda regret objectives in dueling bandits. Surprisingly, our techniques for non-stationary Borda dueling bandits also yield improved rates within the Condorcet winner setting, and reveal new preference models where tighter notions of non-stationarity are adaptively learnable. This is accomplished through a novel generalized Borda score framework which unites the Borda and Condorcet problems, thus allowing reduction of Condorcet regret to a Borda-like task. Such a generalization was not previously known and is likely to be of independent interest.
Digital Twin-Driven Reinforcement Learning for Obstacle Avoidance in Robot Manipulators: A Self-Improving Online Training Framework
Mar 19, 2024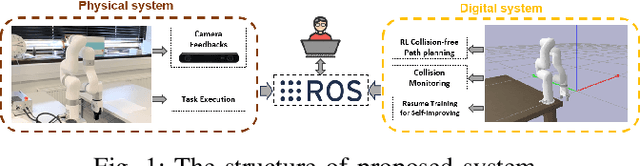
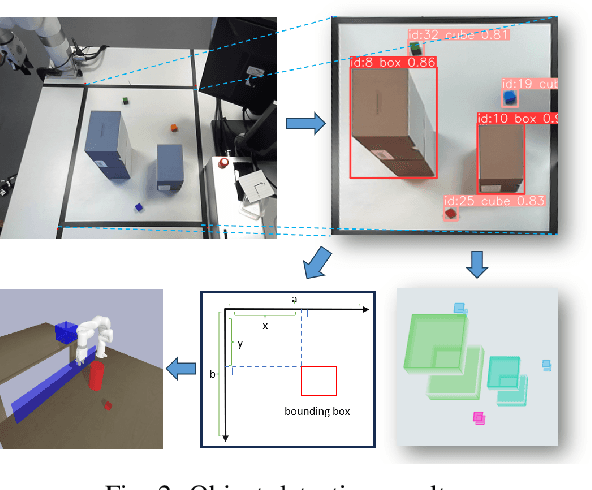
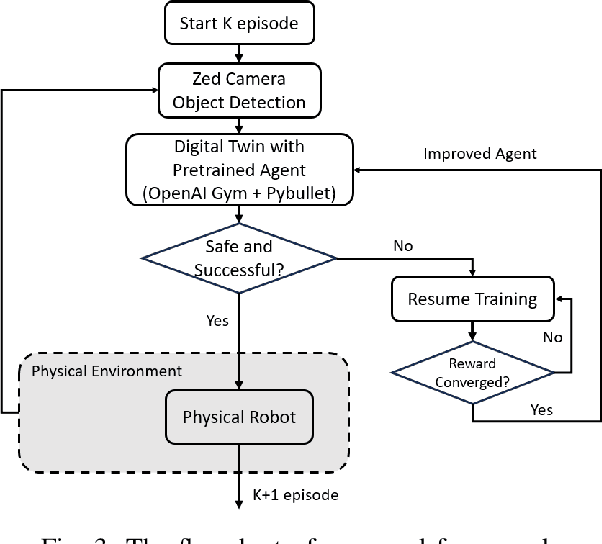

The evolution and growing automation of collaborative robots introduce more complexity and unpredictability to systems, highlighting the crucial need for robot's adaptability and flexibility to address the increasing complexities of their environment. In typical industrial production scenarios, robots are often required to be re-programmed when facing a more demanding task or even a few changes in workspace conditions. To increase productivity, efficiency and reduce human effort in the design process, this paper explores the potential of using digital twin combined with Reinforcement Learning (RL) to enable robots to generate self-improving collision-free trajectories in real time. The digital twin, acting as a virtual counterpart of the physical system, serves as a 'forward run' for monitoring, controlling, and optimizing the physical system in a safe and cost-effective manner. The physical system sends data to synchronize the digital system through the video feeds from cameras, which allows the virtual robot to update its observation and policy based on real scenarios. The bidirectional communication between digital and physical systems provides a promising platform for hardware-in-the-loop RL training through trial and error until the robot successfully adapts to its new environment. The proposed online training framework is demonstrated on the Unfactory Xarm5 collaborative robot, where the robot end-effector aims to reach the target position while avoiding obstacles. The experiment suggest that proposed framework is capable of performing policy online training, and that there remains significant room for improvement.
FUELVISION: A Multimodal Data Fusion and Multimodel Ensemble Algorithm for Wildfire Fuels Mapping
Mar 19, 2024Accurate assessment of fuel conditions is a prerequisite for fire ignition and behavior prediction, and risk management. The method proposed herein leverages diverse data sources including Landsat-8 optical imagery, Sentinel-1 (C-band) Synthetic Aperture Radar (SAR) imagery, PALSAR (L-band) SAR imagery, and terrain features to capture comprehensive information about fuel types and distributions. An ensemble model was trained to predict landscape-scale fuels such as the 'Scott and Burgan 40' using the as-received Forest Inventory and Analysis (FIA) field survey plot data obtained from the USDA Forest Service. However, this basic approach yielded relatively poor results due to the inadequate amount of training data. Pseudo-labeled and fully synthetic datasets were developed using generative AI approaches to address the limitations of ground truth data availability. These synthetic datasets were used for augmenting the FIA data from California to enhance the robustness and coverage of model training. The use of an ensemble of methods including deep learning neural networks, decision trees, and gradient boosting offered a fuel mapping accuracy of nearly 80\%. Through extensive experimentation and evaluation, the effectiveness of the proposed approach was validated for regions of the 2021 Dixie and Caldor fires. Comparative analyses against high-resolution data from the National Agriculture Imagery Program (NAIP) and timber harvest maps affirmed the robustness and reliability of the proposed approach, which is capable of near-real-time fuel mapping.
Omni-Recon: Towards General-Purpose Neural Radiance Fields for Versatile 3D Applications
Mar 17, 2024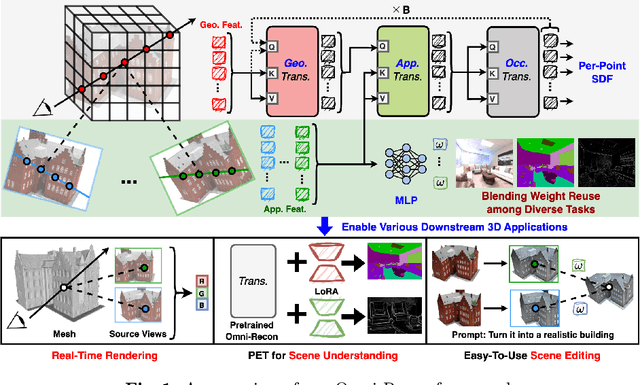
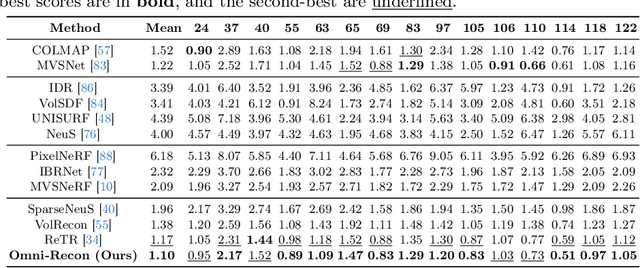
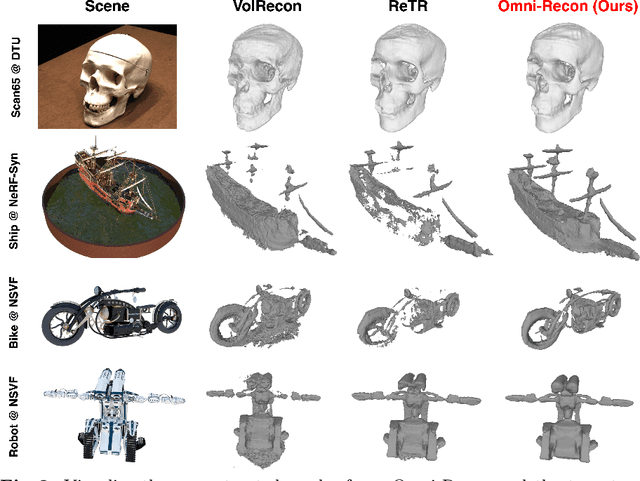

Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.
Optimistic Verifiable Training by Controlling Hardware Nondeterminism
Mar 16, 2024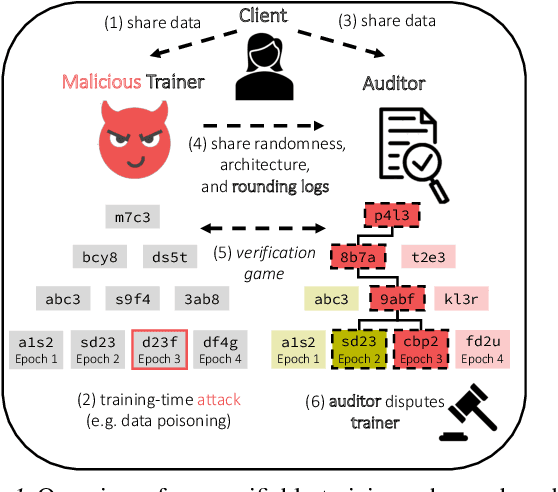



The increasing compute demands of AI systems has led to the emergence of services that train models on behalf of clients lacking necessary resources. However, ensuring correctness of training and guarding against potential training-time attacks, such as data poisoning, poses challenges. Existing works on verifiable training largely fall into two classes: proof-based systems, which struggle to scale due to requiring cryptographic techniques, and "optimistic" methods that consider a trusted third-party auditor who replicates the training process. A key challenge with the latter is that hardware nondeterminism between GPU types during training prevents an auditor from replicating the training process exactly, and such schemes are therefore non-robust. We propose a method that combines training in a higher precision than the target model, rounding after intermediate computation steps, and storing rounding decisions based on an adaptive thresholding procedure, to successfully control for nondeterminism. Across three different NVIDIA GPUs (A40, Titan XP, RTX 2080 Ti), we achieve exact training replication at FP32 precision for both full-training and fine-tuning of ResNet-50 (23M) and GPT-2 (117M) models. Our verifiable training scheme significantly decreases the storage and time costs compared to proof-based systems.
Efficient Trajectory Forecasting and Generation with Conditional Flow Matching
Mar 16, 2024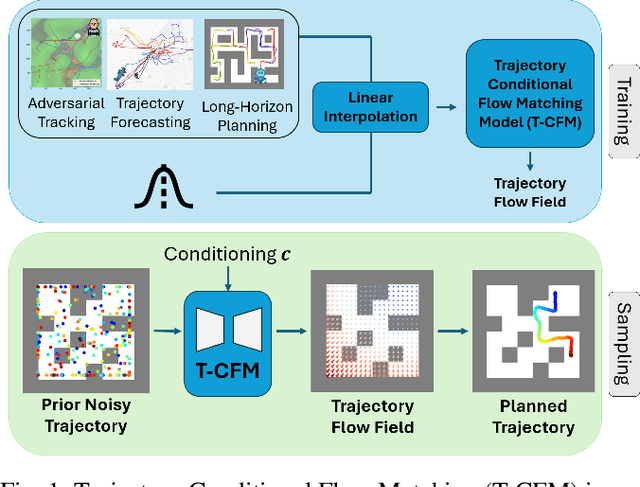
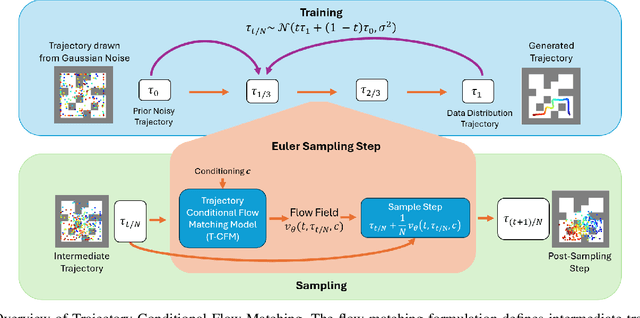
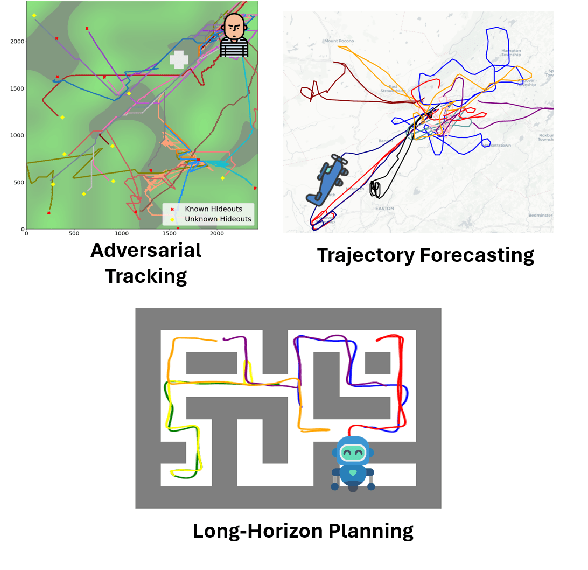
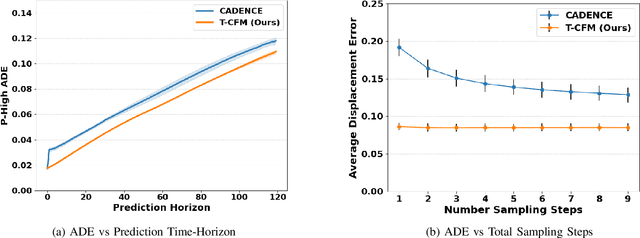
Trajectory prediction and generation are vital for autonomous robots navigating dynamic environments. While prior research has typically focused on either prediction or generation, our approach unifies these tasks to provide a versatile framework and achieve state-of-the-art performance. Diffusion models, which are currently state-of-the-art for learned trajectory generation in long-horizon planning and offline reinforcement learning tasks, rely on a computationally intensive iterative sampling process. This slow process impedes the dynamic capabilities of robotic systems. In contrast, we introduce Trajectory Conditional Flow Matching (T-CFM), a novel data-driven approach that utilizes flow matching techniques to learn a solver time-varying vector field for efficient and fast trajectory generation. We demonstrate the effectiveness of T-CFM on three separate tasks: adversarial tracking, real-world aircraft trajectory forecasting, and long-horizon planning. Our model outperforms state-of-the-art baselines with an increase of 35% in predictive accuracy and 142% increase in planning performance. Notably, T-CFM achieves up to 100$\times$ speed-up compared to diffusion-based models without sacrificing accuracy, which is crucial for real-time decision making in robotics.
A Parallel Workflow for Polar Sea-Ice Classification using Auto-labeling of Sentinel-2 Imagery
Mar 19, 2024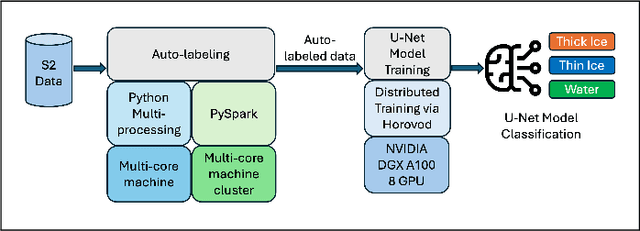
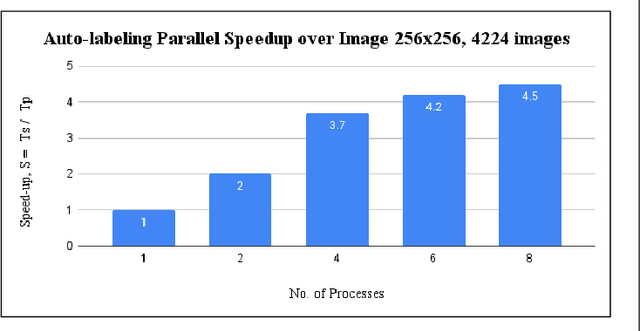
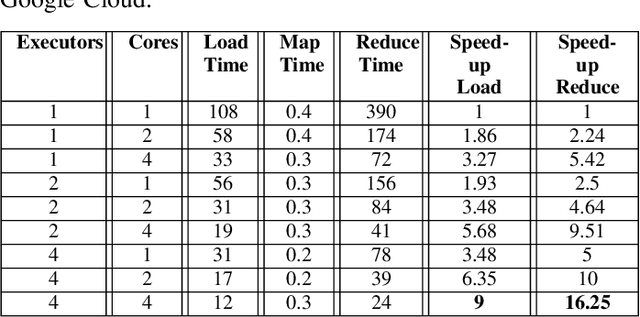
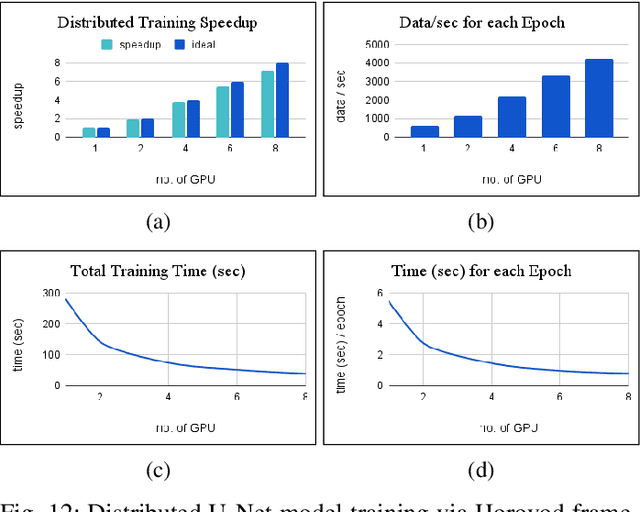
The observation of the advancing and retreating pattern of polar sea ice cover stands as a vital indicator of global warming. This research aims to develop a robust, effective, and scalable system for classifying polar sea ice as thick/snow-covered, young/thin, or open water using Sentinel-2 (S2) images. Since the S2 satellite is actively capturing high-resolution imagery over the earth's surface, there are lots of images that need to be classified. One major obstacle is the absence of labeled S2 training data (images) to act as the ground truth. We demonstrate a scalable and accurate method for segmenting and automatically labeling S2 images using carefully determined color thresholds. We employ a parallel workflow using PySpark to scale and achieve 9-fold data loading and 16-fold map-reduce speedup on auto-labeling S2 images based on thin cloud and shadow-filtered color-based segmentation to generate label data. The auto-labeled data generated from this process are then employed to train a U-Net machine learning model, resulting in good classification accuracy. As training the U-Net classification model is computationally heavy and time-consuming, we distribute the U-Net model training to scale it over 8 GPUs using the Horovod framework over a DGX cluster with a 7.21x speedup without affecting the accuracy of the model. Using the Antarctic's Ross Sea region as an example, the U-Net model trained on auto-labeled data achieves a classification accuracy of 98.97% for auto-labeled training datasets when the thin clouds and shadows from the S2 images are filtered out.
Yell At Your Robot: Improving On-the-Fly from Language Corrections
Mar 19, 2024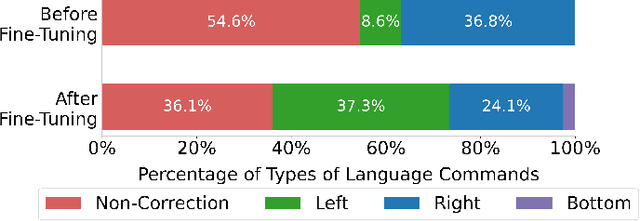



Hierarchical policies that combine language and low-level control have been shown to perform impressively long-horizon robotic tasks, by leveraging either zero-shot high-level planners like pretrained language and vision-language models (LLMs/VLMs) or models trained on annotated robotic demonstrations. However, for complex and dexterous skills, attaining high success rates on long-horizon tasks still represents a major challenge -- the longer the task is, the more likely it is that some stage will fail. Can humans help the robot to continuously improve its long-horizon task performance through intuitive and natural feedback? In this paper, we make the following observation: high-level policies that index into sufficiently rich and expressive low-level language-conditioned skills can be readily supervised with human feedback in the form of language corrections. We show that even fine-grained corrections, such as small movements ("move a bit to the left"), can be effectively incorporated into high-level policies, and that such corrections can be readily obtained from humans observing the robot and making occasional suggestions. This framework enables robots not only to rapidly adapt to real-time language feedback, but also incorporate this feedback into an iterative training scheme that improves the high-level policy's ability to correct errors in both low-level execution and high-level decision-making purely from verbal feedback. Our evaluation on real hardware shows that this leads to significant performance improvement in long-horizon, dexterous manipulation tasks without the need for any additional teleoperation. Videos and code are available at https://yay-robot.github.io/.