 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhance-NeRF: Multiple Performance Evaluation for Neural Radiance Fields
Jun 08, 2023
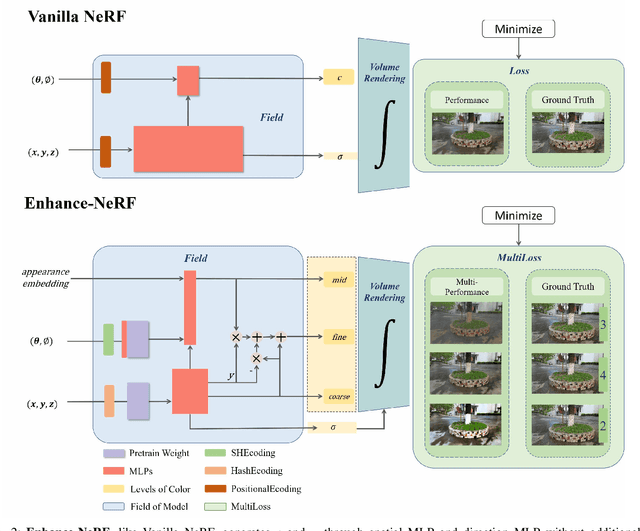



The quality of three-dimensional reconstruction is a key factor affecting the effectiveness of its application in areas such as virtual reality (VR) and augmented reality (AR) technologies. Neural Radiance Fields (NeRF) can generate realistic images from any viewpoint. It simultaneously reconstructs the shape, lighting, and materials of objects, and without surface defects, which breaks down the barrier between virtuality and reality. The potential spatial correspondences displayed by NeRF between reconstructed scenes and real-world scenes offer a wide range of practical applications possibilities. Despite significant progress in 3D reconstruction since NeRF were introduced, there remains considerable room for exploration and experimentation. NeRF-based models are susceptible to interference issues caused by colored "fog" noise. Additionally, they frequently encounter instabilities and failures while attempting to reconstruct unbounded scenes. Moreover, the model takes a significant amount of time to converge, making it even more challenging to use in such scenarios. Our approach, coined Enhance-NeRF, which adopts joint color to balance low and high reflectivity objects display, utilizes a decoding architecture with prior knowledge to improve recognition, and employs multi-layer performance evaluation mechanisms to enhance learning capacity. It achieves reconstruction of outdoor scenes within one hour under single-card condition. Based on experimental results, Enhance-NeRF partially enhances fitness capability and provides some support to outdoor scene reconstruction. The Enhance-NeRF method can be used as a plug-and-play component, making it easy to integrate with other NeRF-based models. The code is available at: https://github.com/TANQIanQ/Enhance-NeRF
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
Jun 08, 2023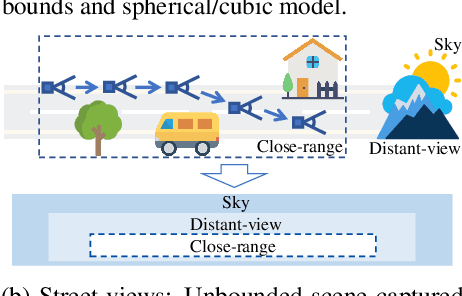
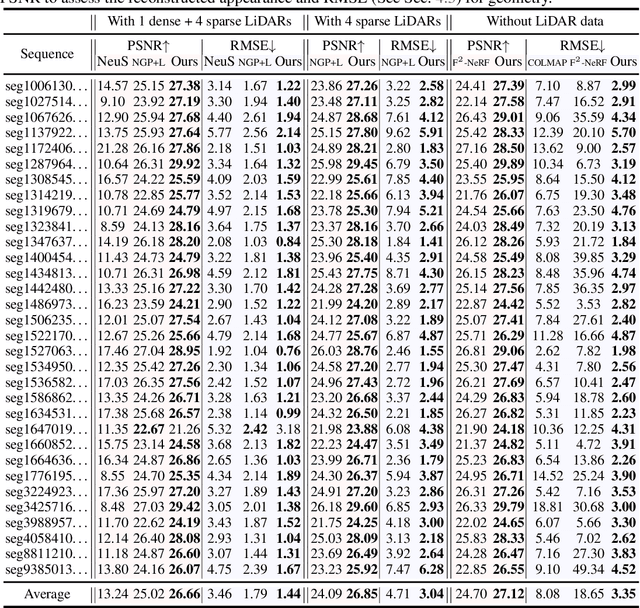


We present a novel multi-view implicit surface reconstruction technique, termed StreetSurf, that is readily applicable to street view images in widely-used autonomous driving datasets, such as Waymo-perception sequences, without necessarily requiring LiDAR data. As neural rendering research expands rapidly, its integration into street views has started to draw interests. Existing approaches on street views either mainly focus on novel view synthesis with little exploration of the scene geometry, or rely heavily on dense LiDAR data when investigating reconstruction. Neither of them investigates multi-view implicit surface reconstruction, especially under settings without LiDAR data. Our method extends prior object-centric neural surface reconstruction techniques to address the unique challenges posed by the unbounded street views that are captured with non-object-centric, long and narrow camera trajectories. We delimit the unbounded space into three parts, close-range, distant-view and sky, with aligned cuboid boundaries, and adapt cuboid/hyper-cuboid hash-grids along with road-surface initialization scheme for finer and disentangled representation. To further address the geometric errors arising from textureless regions and insufficient viewing angles, we adopt geometric priors that are estimated using general purpose monocular models. Coupled with our implementation of efficient and fine-grained multi-stage ray marching strategy, we achieve state of the art reconstruction quality in both geometry and appearance within only one to two hours of training time with a single RTX3090 GPU for each street view sequence. Furthermore, we demonstrate that the reconstructed implicit surfaces have rich potential for various downstream tasks, including ray tracing and LiDAR simulation.
AircraftVerse: A Large-Scale Multimodal Dataset of Aerial Vehicle Designs
Jun 08, 2023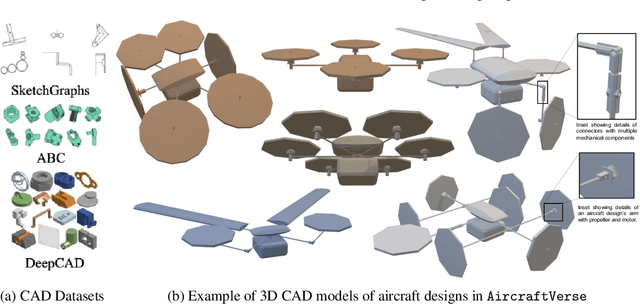
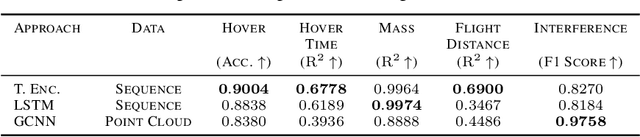
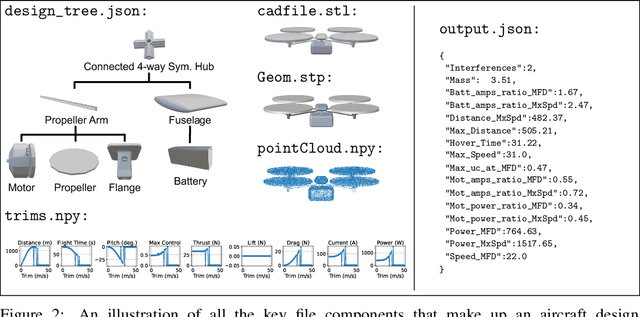

We present AircraftVerse, a publicly available aerial vehicle design dataset. Aircraft design encompasses different physics domains and, hence, multiple modalities of representation. The evaluation of these cyber-physical system (CPS) designs requires the use of scientific analytical and simulation models ranging from computer-aided design tools for structural and manufacturing analysis, computational fluid dynamics tools for drag and lift computation, battery models for energy estimation, and simulation models for flight control and dynamics. AircraftVerse contains 27,714 diverse air vehicle designs - the largest corpus of engineering designs with this level of complexity. Each design comprises the following artifacts: a symbolic design tree describing topology, propulsion subsystem, battery subsystem, and other design details; a STandard for the Exchange of Product (STEP) model data; a 3D CAD design using a stereolithography (STL) file format; a 3D point cloud for the shape of the design; and evaluation results from high fidelity state-of-the-art physics models that characterize performance metrics such as maximum flight distance and hover-time. We also present baseline surrogate models that use different modalities of design representation to predict design performance metrics, which we provide as part of our dataset release. Finally, we discuss the potential impact of this dataset on the use of learning in aircraft design and, more generally, in CPS. AircraftVerse is accompanied by a data card, and it is released under Creative Commons Attribution-ShareAlike (CC BY-SA) license. The dataset is hosted at https://zenodo.org/record/6525446, baseline models and code at https://github.com/SRI-CSL/AircraftVerse, and the dataset description at https://aircraftverse.onrender.com/.
How Can We Train Deep Learning Models Across Clouds and Continents? An Experimental Study
Jun 05, 2023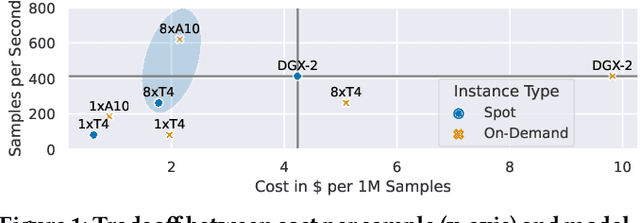
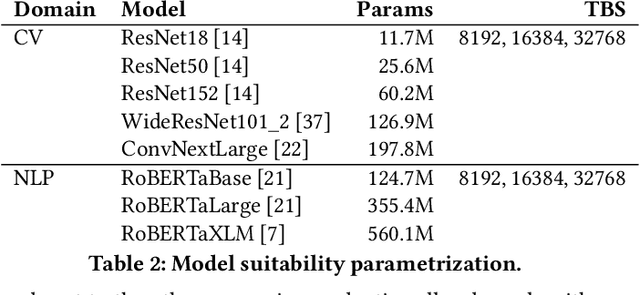
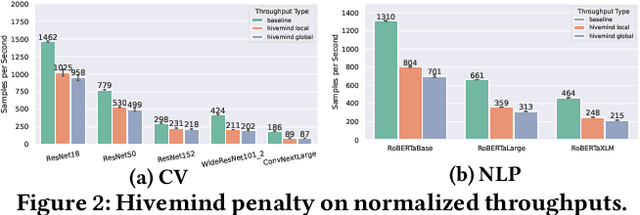
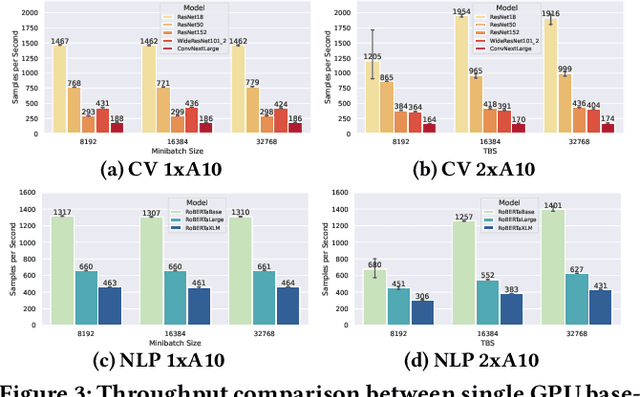
Training deep learning models in the cloud or on dedicated hardware is expensive. A more cost-efficient option are hyperscale clouds offering spot instances, a cheap but ephemeral alternative to on-demand resources. As spot instance availability can change depending on the time of day, continent, and cloud provider, it could be more cost-efficient to distribute resources over the world. Still, it has not been investigated whether geo-distributed, data-parallel spot deep learning training could be a more cost-efficient alternative to centralized training. This paper aims to answer the question: Can deep learning models be cost-efficiently trained on a global market of spot VMs spanning different data centers and cloud providers? To provide guidance, we extensively evaluate the cost and throughput implications of training in different zones, continents, and clouds for representative CV and NLP models. To expand the current training options further, we compare the scalability potential for hybrid-cloud scenarios by adding cloud resources to on-premise hardware to improve training throughput. Finally, we show how leveraging spot instance pricing enables a new cost-efficient way to train models with multiple cheap VMs, trumping both more centralized and powerful hardware and even on-demand cloud offerings at competitive prices.
Enhance Diffusion to Improve Robust Generalization
Jun 05, 2023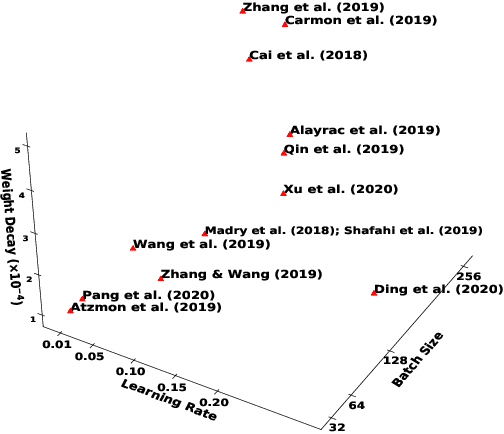
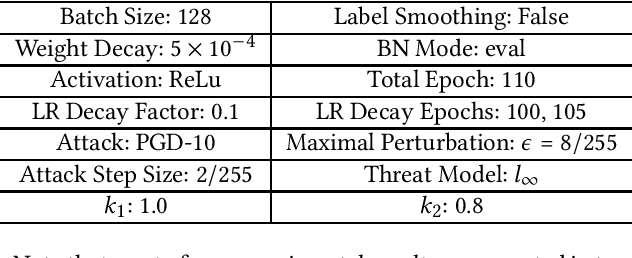
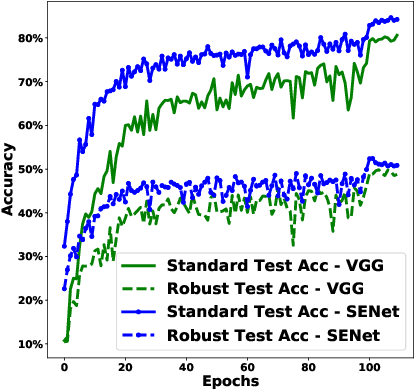
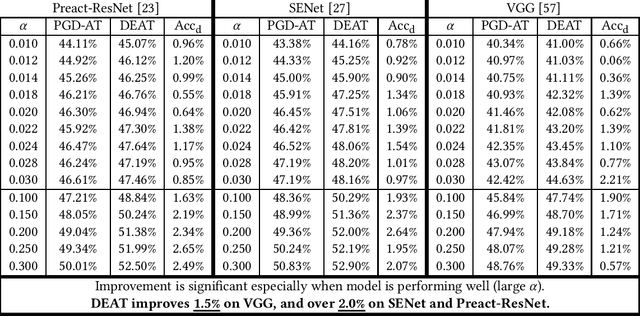
Deep neural networks are susceptible to human imperceptible adversarial perturbations. One of the strongest defense mechanisms is \emph{Adversarial Training} (AT). In this paper, we aim to address two predominant problems in AT. First, there is still little consensus on how to set hyperparameters with a performance guarantee for AT research, and customized settings impede a fair comparison between different model designs in AT research. Second, the robustly trained neural networks struggle to generalize well and suffer from tremendous overfitting. This paper focuses on the primary AT framework - Projected Gradient Descent Adversarial Training (PGD-AT). We approximate the dynamic of PGD-AT by a continuous-time Stochastic Differential Equation (SDE), and show that the diffusion term of this SDE determines the robust generalization. An immediate implication of this theoretical finding is that robust generalization is positively correlated with the ratio between learning rate and batch size. We further propose a novel approach, \emph{Diffusion Enhanced Adversarial Training} (DEAT), to manipulate the diffusion term to improve robust generalization with virtually no extra computational burden. We theoretically show that DEAT obtains a tighter generalization bound than PGD-AT. Our empirical investigation is extensive and firmly attests that DEAT universally outperforms PGD-AT by a significant margin.
Unsupervised haze removal from underwater images
Jun 05, 2023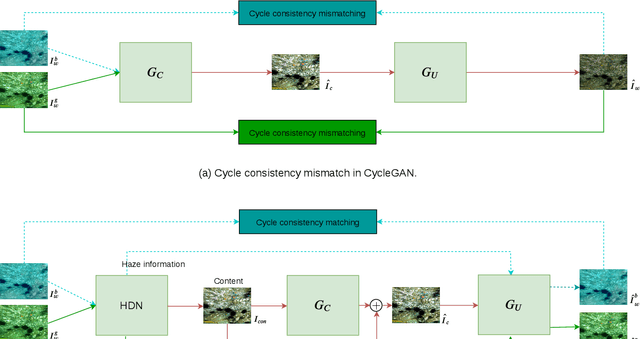

Several supervised networks exist that remove haze information from underwater images using paired datasets and pixel-wise loss functions. However, training these networks requires large amounts of paired data which is cumbersome, complex and time-consuming. Also, directly using adversarial and cycle consistency loss functions for unsupervised learning is inaccurate as the underlying mapping from clean to underwater images is one-to-many, resulting in an inaccurate constraint on the cycle consistency loss. To address these issues, we propose a new method to remove haze from underwater images using unpaired data. Our model disentangles haze and content information from underwater images using a Haze Disentanglement Network (HDN). The disentangled content is used by a restoration network to generate a clean image using adversarial losses. The disentangled haze is then used as a guide for underwater image regeneration resulting in a strong constraint on cycle consistency loss and improved performance gains. Different ablation studies show that the haze and content from underwater images are effectively separated. Exhaustive experiments reveal that accurate cycle consistency constraint and the proposed network architecture play an important role in yielding enhanced results. Experiments on UFO-120, UWNet, UWScenes, and UIEB underwater datasets indicate that the results of our method outperform prior art both visually and quantitatively.
CEN-HDR: Computationally Efficient neural Network for real-time High Dynamic Range imaging
Feb 10, 2023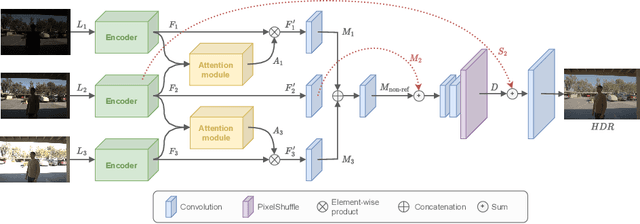
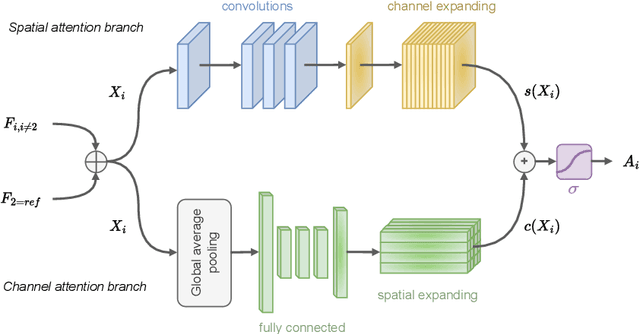
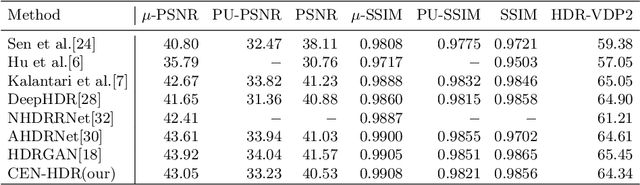
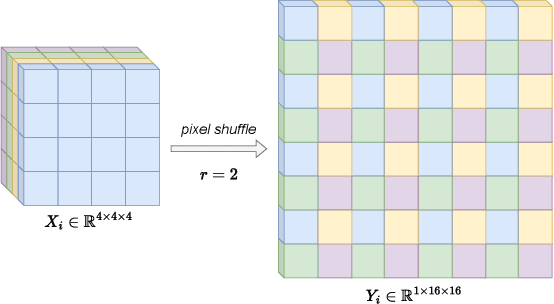
High dynamic range (HDR) imaging is still a challenging task in modern digital photography. Recent research proposes solutions that provide high-quality acquisition but at the cost of a very large number of operations and a slow inference time that prevent the implementation of these solutions on lightweight real-time systems. In this paper, we propose CEN-HDR, a new computationally efficient neural network by providing a novel architecture based on a light attention mechanism and sub-pixel convolution operations for real-time HDR imaging. We also provide an efficient training scheme by applying network compression using knowledge distillation. We performed extensive qualitative and quantitative comparisons to show that our approach produces competitive results in image quality while being faster than state-of-the-art solutions, allowing it to be practically deployed under real-time constraints. Experimental results show our method obtains a score of 43.04 mu-PSNR on the Kalantari2017 dataset with a framerate of 33 FPS using a Macbook M1 NPU.
Recent applications of machine learning, remote sensing, and iot approaches in yield prediction: a critical review
Jun 07, 2023

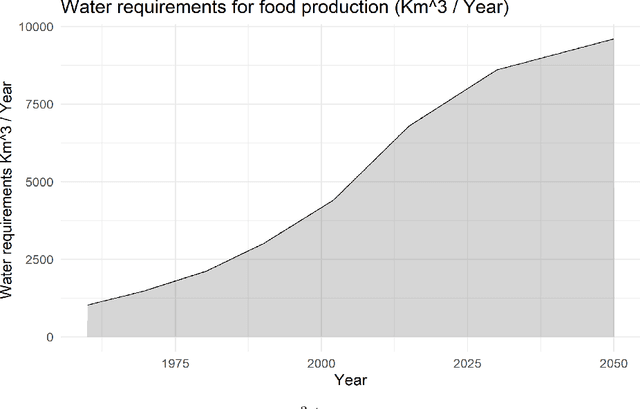
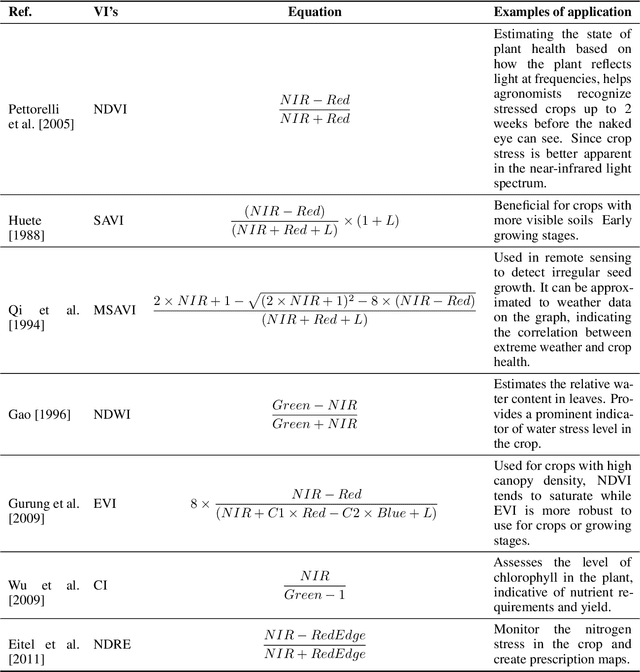
The integration of remote sensing and machine learning in agriculture is transforming the industry by providing insights and predictions through data analysis. This combination leads to improved yield prediction and water management, resulting in increased efficiency, better yields, and more sustainable agricultural practices. Achieving the United Nations' Sustainable Development Goals, especially "zero hunger," requires the investigation of crop yield and precipitation gaps, which can be accomplished through, the usage of artificial intelligence (AI), machine learning (ML), remote sensing (RS), and the internet of things (IoT). By integrating these technologies, a robust agricultural mobile or web application can be developed, providing farmers and decision-makers with valuable information and tools for improving crop management and increasing efficiency. Several studies have investigated these new technologies and their potential for diverse tasks such as crop monitoring, yield prediction, irrigation management, etc. Through a critical review, this paper reviews relevant articles that have used RS, ML, cloud computing, and IoT in crop yield prediction. It reviews the current state-of-the-art in this field by critically evaluating different machine-learning approaches proposed in the literature for crop yield prediction and water management. It provides insights into how these methods can improve decision-making in agricultural production systems. This work will serve as a compendium for those interested in yield prediction in terms of primary literature but, most importantly, what approaches can be used for real-time and robust prediction.
IsoEx: an explainable unsupervised approach to process event logs cyber investigation
Jun 07, 2023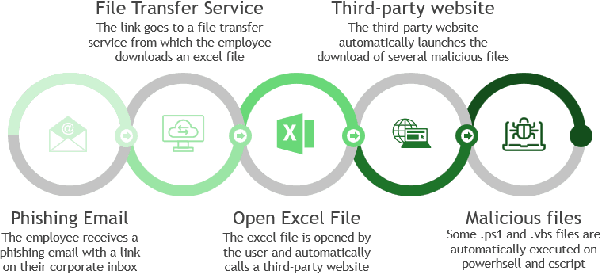
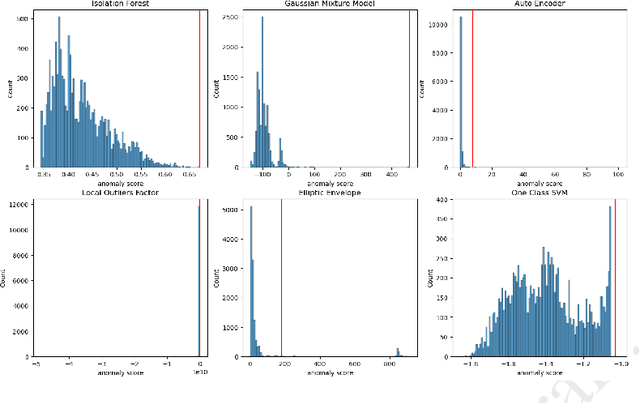
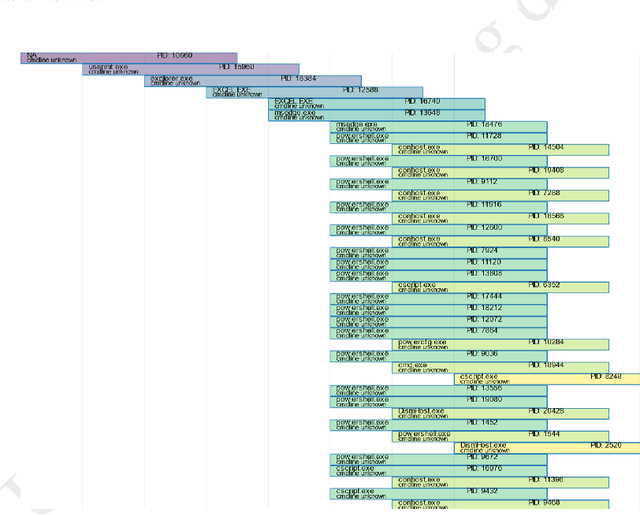
39 seconds. That is the timelapse between two consecutive cyber attacks as of 2023. Meaning that by the time you are done reading this abstract, about 1 or 2 additional cyber attacks would have occurred somewhere in the world. In this context of highly increased frequency of cyber threats, Security Operation Centers (SOC) and Computer Emergency Response Teams (CERT) can be overwhelmed. In order to relieve the cybersecurity teams in their investigative effort and help them focus on more added-value tasks, machine learning approaches and methods started to emerge. This paper introduces a novel method, IsoEx, for detecting anomalous and potentially problematic command lines during the investigation of contaminated devices. IsoEx is built around a set of features that leverages the log structure of the command line, as well as its parent/child relationship, to achieve a greater accuracy than traditional methods. To detect anomalies, IsoEx resorts to an unsupervised anomaly detection technique that is both highly sensitive and lightweight. A key contribution of the paper is its emphasis on interpretability, achieved through the features themselves and the application of eXplainable Artificial Intelligence (XAI) techniques and visualizations. This is critical to ensure the adoption of the method by SOC and CERT teams, as the paper argues that the current literature on machine learning for log investigation has not adequately addressed the issue of explainability. This method was proven efficient in a real-life environment as it was built to support a company\'s SOC and CERT
Change Diffusion: Change Detection Map Generation Based on Difference-Feature Guided DDPM
Jun 06, 2023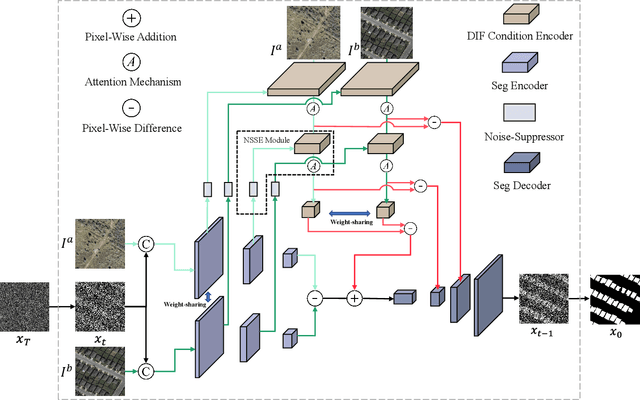
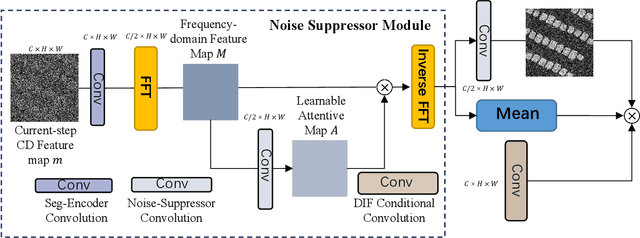


Deep learning (DL) approaches based on CNN-purely or Transformer networks have demonstrated promising results in bitemporal change detection (CD). However, their performance is limited by insufficient contextual information aggregation, as they struggle to fully capture the implicit contextual dependency relationships among feature maps at different levels. Additionally, researchers have utilized pre-trained denoising diffusion probabilistic models (DDPMs) for training lightweight CD classifiers. Nevertheless, training a DDPM to generate intricately detailed, multi-channel remote sensing images requires months of training time and a substantial volume of unlabeled remote sensing datasets, making it significantly more complex than generating a single-channel change map. To overcome these challenges, we propose a novel end-to-end DDPM-based model architecture called change-aware diffusion model (CADM), which can be trained using a limited annotated dataset quickly. Furthermore, we introduce dynamic difference conditional encoding to enhance step-wise regional attention in DDPM for bitemporal images in CD datasets. This method establishes state-adaptive conditions for each sampling step, emphasizing two main innovative points of our model: 1) its end-to-end nature and 2) difference conditional encoding. We evaluate CADM on four remote sensing CD tasks with different ground scenarios, including CDD, WHU, Levier, and GVLM. Experimental results demonstrate that CADM significantly outperforms state-of-the-art methods, indicating the generalization and effectiveness of the proposed model.