 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reliable and Interpretable Drift Detection in Streams of Short Texts
May 28, 2023
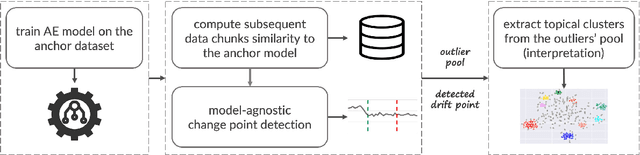

Data drift is the change in model input data that is one of the key factors leading to machine learning models performance degradation over time. Monitoring drift helps detecting these issues and preventing their harmful consequences. Meaningful drift interpretation is a fundamental step towards effective re-training of the model. In this study we propose an end-to-end framework for reliable model-agnostic change-point detection and interpretation in large task-oriented dialog systems, proven effective in multiple customer deployments. We evaluate our approach and demonstrate its benefits with a novel variant of intent classification training dataset, simulating customer requests to a dialog system. We make the data publicly available.
Low Rank Matrix Completion via Robust Alternating Minimization in Nearly Linear Time
Feb 21, 2023Given a matrix $M\in \mathbb{R}^{m\times n}$, the low rank matrix completion problem asks us to find a rank-$k$ approximation of $M$ as $UV^\top$ for $U\in \mathbb{R}^{m\times k}$ and $V\in \mathbb{R}^{n\times k}$ by only observing a few entries masked by a binary matrix $P_{\Omega}\in \{0, 1 \}^{m\times n}$. As a particular instance of the weighted low rank approximation problem, solving low rank matrix completion is known to be computationally hard even to find an approximate solution [RSW16]. However, due to its practical importance, many heuristics have been proposed for this problem. In the seminal work of Jain, Netrapalli, and Sanghavi [JNS13], they show that the alternating minimization framework provides provable guarantees for low rank matrix completion problem whenever $M$ admits an incoherent low rank factorization. Unfortunately, their algorithm requires solving two exact multiple response regressions per iteration and their analysis is non-robust as they exploit the structure of the exact solution. In this paper, we take a major step towards a more efficient and robust alternating minimization framework for low rank matrix completion. Our main result is a robust alternating minimization algorithm that can tolerate moderate errors even though the regressions are solved approximately. Consequently, we also significantly improve the running time of [JNS13] from $\widetilde{O}(mnk^2 )$ to $\widetilde{O}(mnk )$ which is nearly linear in the problem size, as verifying the low rank approximation takes $O(mnk)$ time. Our core algorithmic building block is a high accuracy regression solver that solves the regression in nearly linear time per iteration.
An Ensemble Deep Learning Approach for COVID-19 Severity Prediction Using Chest CT Scans
May 17, 2023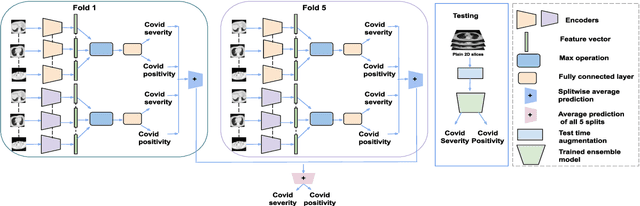
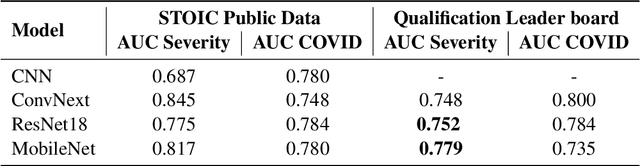

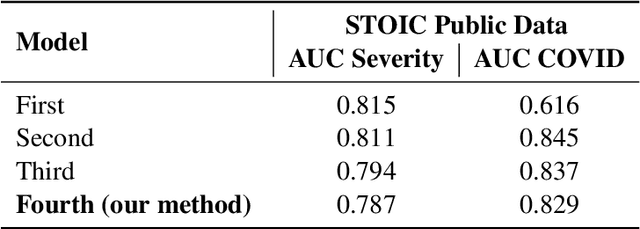
Chest X-rays have been widely used for COVID-19 screening; however, 3D computed tomography (CT) is a more effective modality. We present our findings on COVID-19 severity prediction from chest CT scans using the STOIC dataset. We developed an ensemble deep learning based model that incorporates multiple neural networks to improve predictions. To address data imbalance, we used slicing functions and data augmentation. We further improved performance using test time data augmentation. Our approach which employs a simple yet effective ensemble of deep learning-based models with strong test time augmentations, achieved results comparable to more complex methods and secured the fourth position in the STOIC2021 COVID-19 AI Challenge. Our code is available on online: at: https://github.com/aleemsidra/stoic2021- baseline-finalphase-main.
SlothSpeech: Denial-of-service Attack Against Speech Recognition Models
Jun 01, 2023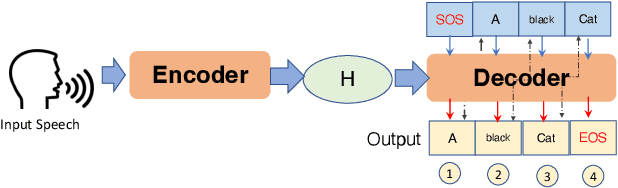
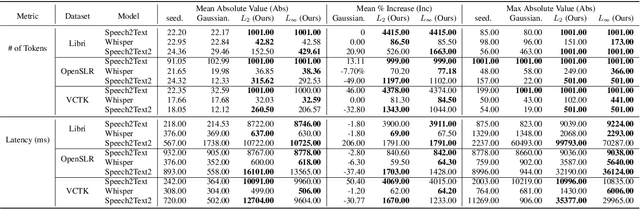
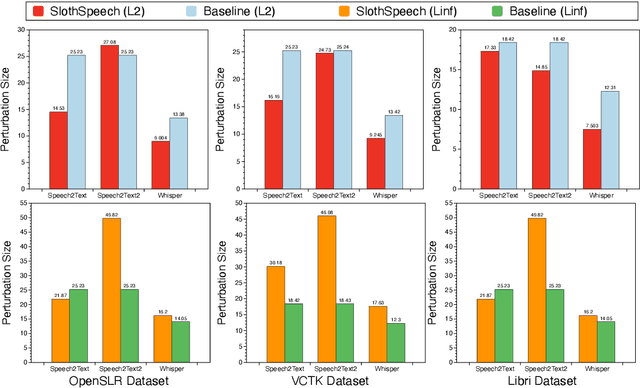
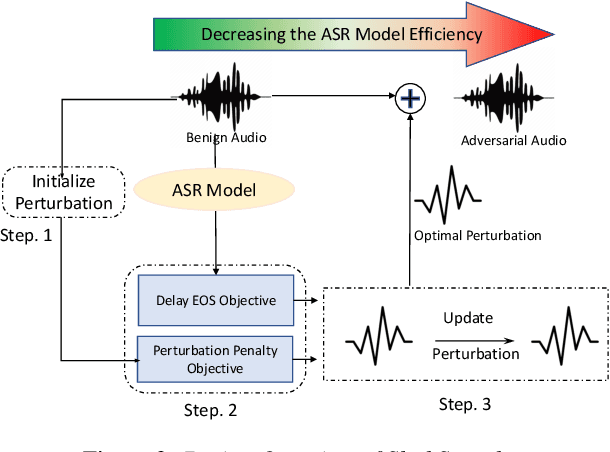
Deep Learning (DL) models have been popular nowadays to execute different speech-related tasks, including automatic speech recognition (ASR). As ASR is being used in different real-time scenarios, it is important that the ASR model remains efficient against minor perturbations to the input. Hence, evaluating efficiency robustness of the ASR model is the need of the hour. We show that popular ASR models like Speech2Text model and Whisper model have dynamic computation based on different inputs, causing dynamic efficiency. In this work, we propose SlothSpeech, a denial-of-service attack against ASR models, which exploits the dynamic behaviour of the model. SlothSpeech uses the probability distribution of the output text tokens to generate perturbations to the audio such that efficiency of the ASR model is decreased. We find that SlothSpeech generated inputs can increase the latency up to 40X times the latency induced by benign input.
A Neural RDE-based model for solving path-dependent PDEs
Jun 01, 2023
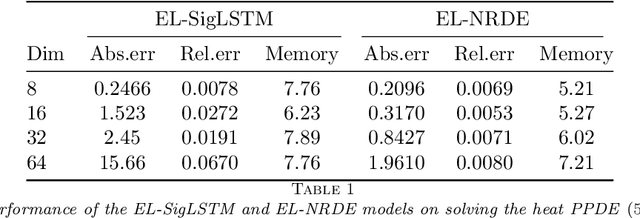
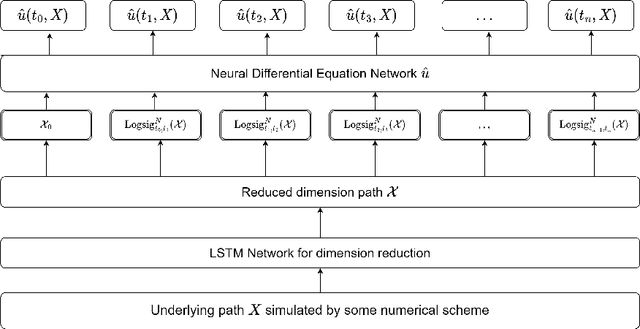
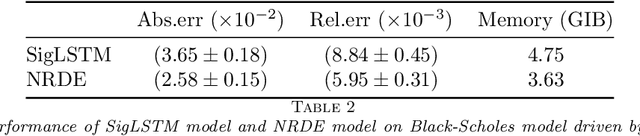
The concept of the path-dependent partial differential equation (PPDE) was first introduced in the context of path-dependent derivatives in financial markets. Its semilinear form was later identified as a non-Markovian backward stochastic differential equation (BSDE). Compared to the classical PDE, the solution of a PPDE involves an infinite-dimensional spatial variable, making it challenging to approximate, if not impossible. In this paper, we propose a neural rough differential equation (NRDE)-based model to learn PPDEs, which effectively encodes the path information through the log-signature feature while capturing the fundamental dynamics. The proposed continuous-time model for the PPDE solution offers the benefits of efficient memory usage and the ability to scale with dimensionality. Several numerical experiments, provided to validate the performance of the proposed model in comparison to the strong baseline in the literature, are used to demonstrate its effectiveness.
Differential Diffusion: Giving Each Pixel Its Strength
Jun 01, 2023



Text-based image editing has advanced significantly in recent years. With the rise of diffusion models, image editing via textual instructions has become ubiquitous. Unfortunately, current models lack the ability to customize the quantity of the change per pixel or per image fragment, resorting to changing the entire image in an equal amount, or editing a specific region using a binary mask. In this paper, we suggest a new framework which enables the user to customize the quantity of change for each image fragment, thereby enhancing the flexibility and verbosity of modern diffusion models. Our framework does not require model training or fine-tuning, but instead performs everything at inference time, making it easily applicable to an existing model. We show both qualitatively and quantitatively that our method allows better controllability and can produce results which are unattainable by existing models. Our code is available at: https://github.com/exx8/differential-diffusion
Collision Detection for Modular Robots -- it is easy to cause collisions and hard to avoid them
May 01, 2023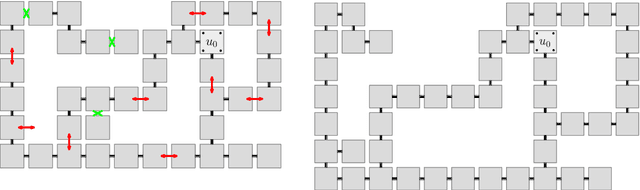
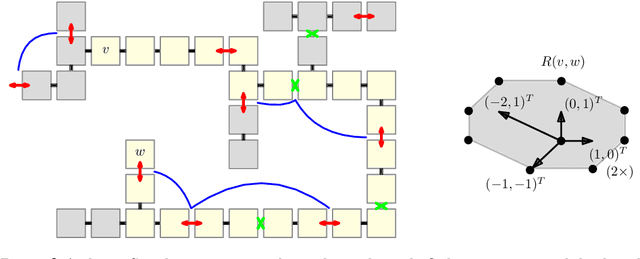
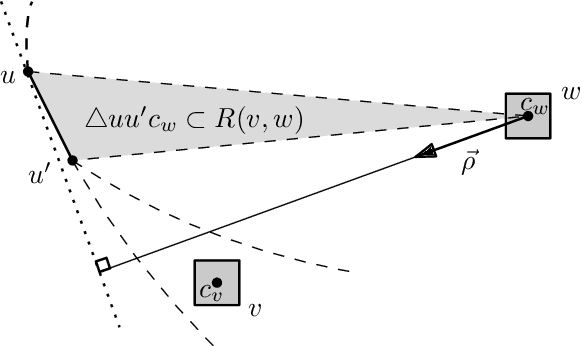
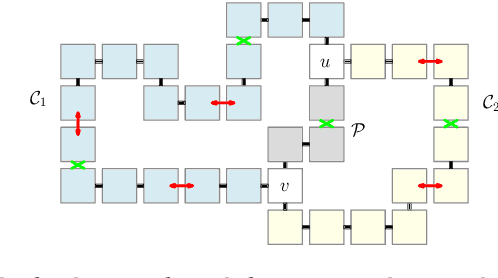
We consider geometric collision-detection problems for modular reconfigurable robots. Assuming the nodes (modules) are connected squares on a grid, we investigate the complexity of deciding whether collisions may occur, or can be avoided, if a set of expansion and contraction operations is executed. We study both discrete- and continuous-time models, and allow operations to be coupled into a single parallel group. Our algorithms to decide if a collision may occur run in $O(n^2\log^2 n)$ time, $O(n^2)$ time, or $O(n\log^2 n)$ time, depending on the presence and type of coupled operations, in a continuous-time model for a modular robot with $n$ nodes. To decide if collisions can be avoided, we show that a very restricted version is already NP-complete in the discrete-time model, while the same problem is polynomial in the continuous-time model. A less restricted version is NP-hard in the continuous-time model.
ACI-BENCH: a Novel Ambient Clinical Intelligence Dataset for Benchmarking Automatic Visit Note Generation
Jun 03, 2023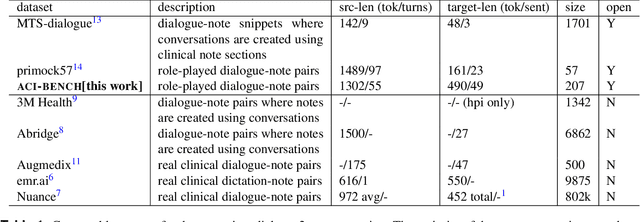
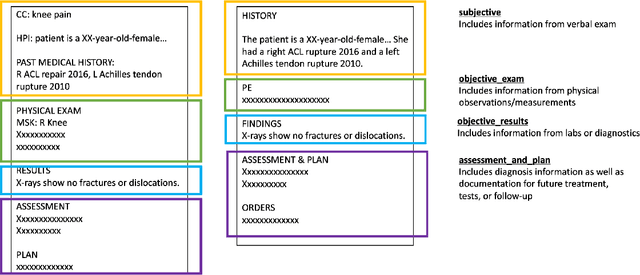
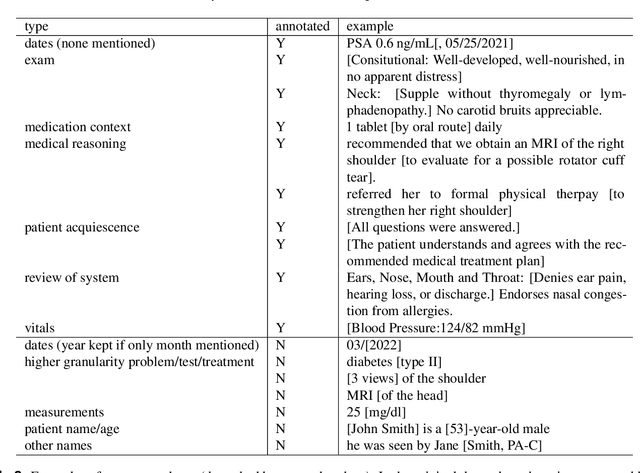
Recent immense breakthroughs in generative models such as in GPT4 have precipitated re-imagined ubiquitous usage of these models in all applications. One area that can benefit by improvements in artificial intelligence (AI) is healthcare. The note generation task from doctor-patient encounters, and its associated electronic medical record documentation, is one of the most arduous time-consuming tasks for physicians. It is also a natural prime potential beneficiary to advances in generative models. However with such advances, benchmarking is more critical than ever. Whether studying model weaknesses or developing new evaluation metrics, shared open datasets are an imperative part of understanding the current state-of-the-art. Unfortunately as clinic encounter conversations are not routinely recorded and are difficult to ethically share due to patient confidentiality, there are no sufficiently large clinic dialogue-note datasets to benchmark this task. Here we present the Ambient Clinical Intelligence Benchmark (ACI-BENCH) corpus, the largest dataset to date tackling the problem of AI-assisted note generation from visit dialogue. We also present the benchmark performances of several common state-of-the-art approaches.
Noise-cleaning the precision matrix of fMRI time series
Feb 06, 2023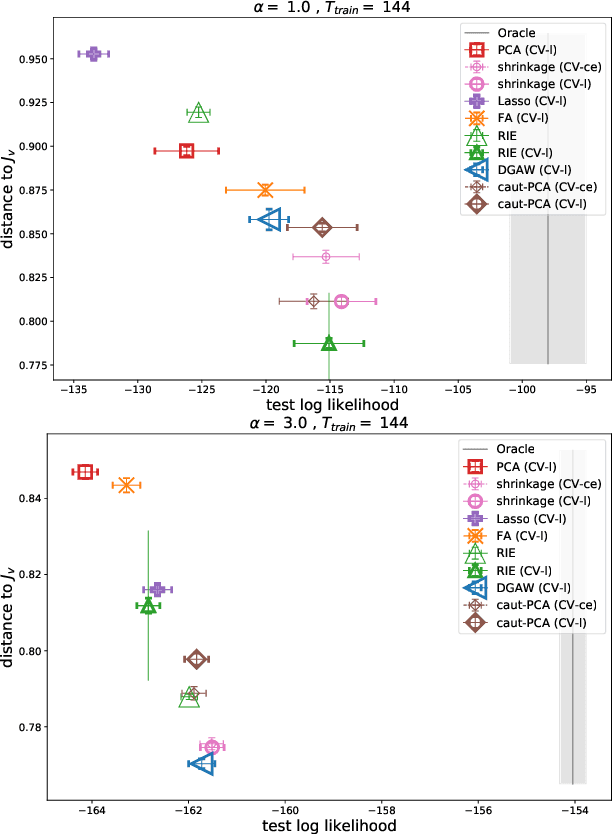
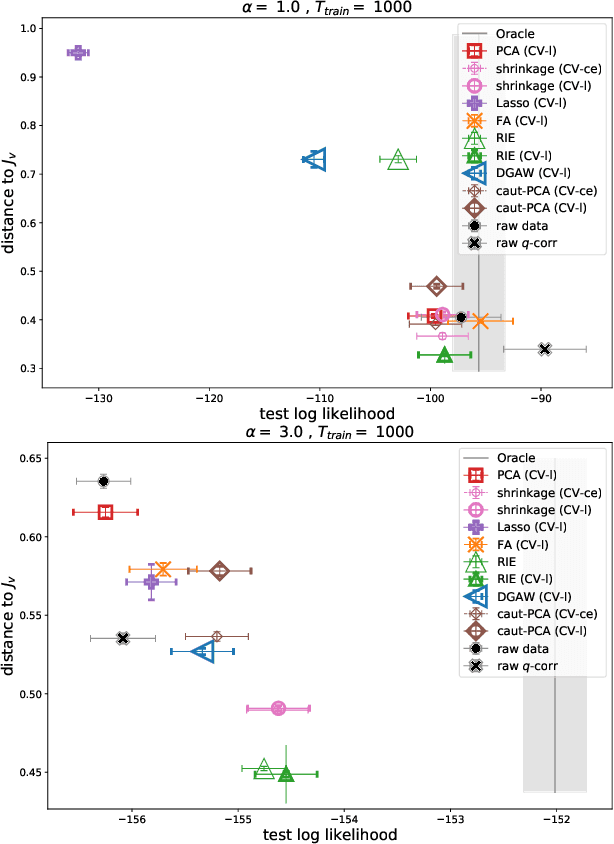
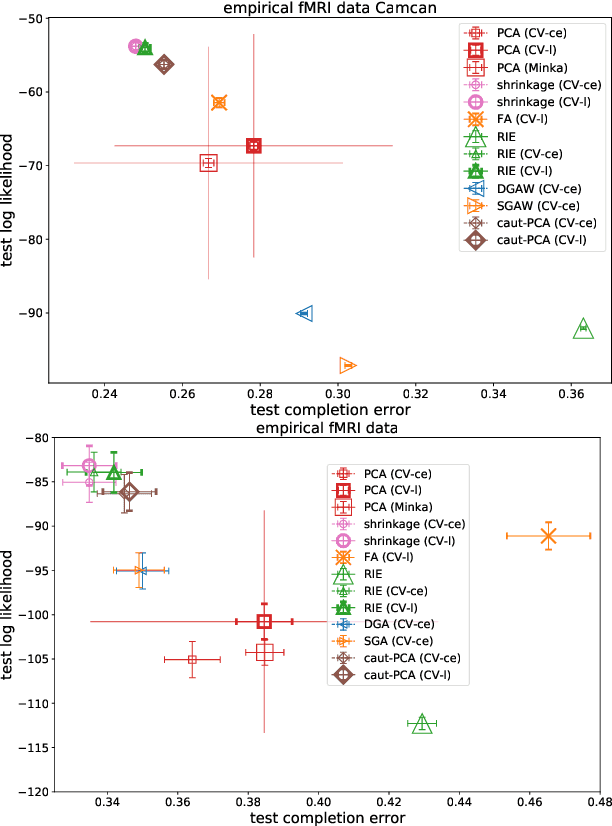
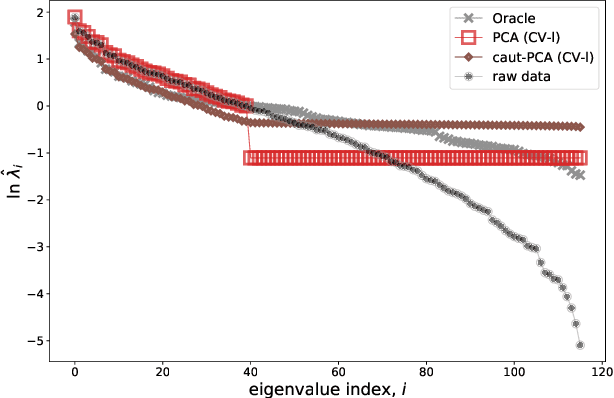
We present a comparison between various algorithms of inference of covariance and precision matrices in small datasets of real vectors, of the typical length and dimension of human brain activity time series retrieved by functional Magnetic Resonance Imaging (fMRI). Assuming a Gaussian model underlying the neural activity, the problem consists in denoising the empirically observed matrices in order to obtain a better estimator of the true precision and covariance matrices. We consider several standard noise-cleaning algorithms and compare them on two types of datasets. The first type are time series of fMRI brain activity of human subjects at rest. The second type are synthetic time series sampled from a generative Gaussian model of which we can vary the fraction of dimensions per sample q = N/T and the strength of off-diagonal correlations. The reliability of each algorithm is assessed in terms of test-set likelihood and, in the case of synthetic data, of the distance from the true precision matrix. We observe that the so called Optimal Rotationally Invariant Estimator, based on Random Matrix Theory, leads to a significantly lower distance from the true precision matrix in synthetic data, and higher test likelihood in natural fMRI data. We propose a variant of the Optimal Rotationally Invariant Estimator in which one of its parameters is optimised by cross-validation. In the severe undersampling regime (large q) typical of fMRI series, it outperforms all the other estimators. We furthermore propose a simple algorithm based on an iterative likelihood gradient ascent, providing an accurate estimation for weakly correlated datasets.
Neural Continuous-Discrete State Space Models for Irregularly-Sampled Time Series
Jan 31, 2023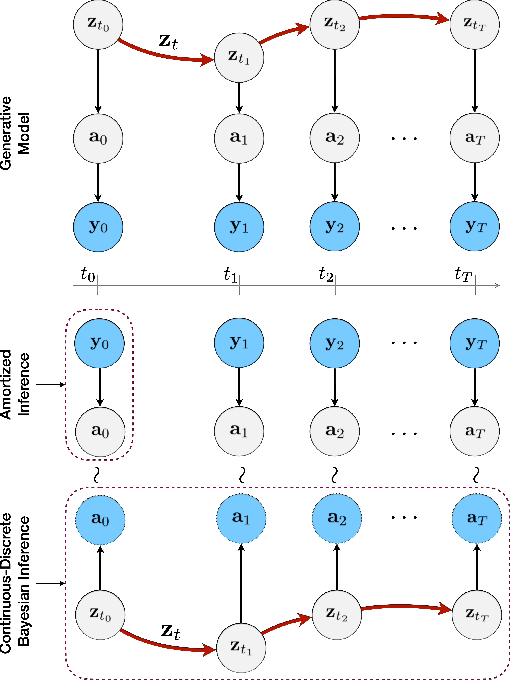

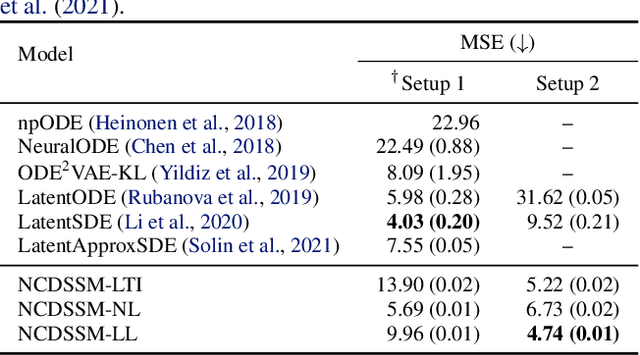

Learning accurate predictive models of real-world dynamic phenomena (e.g., climate, biological) remains a challenging task. One key issue is that the data generated by both natural and artificial processes often comprise time series that are irregularly sampled and/or contain missing observations. In this work, we propose the Neural Continuous-Discrete State Space Model (NCDSSM) for continuous-time modeling of time series through discrete-time observations. NCDSSM employs auxiliary variables to disentangle recognition from dynamics, thus requiring amortized inference only for the auxiliary variables. Leveraging techniques from continuous-discrete filtering theory, we demonstrate how to perform accurate Bayesian inference for the dynamic states. We propose three flexible parameterizations of the latent dynamics and an efficient training objective that marginalizes the dynamic states during inference. Empirical results on multiple benchmark datasets across various domains show improved imputation and forecasting performance of NCDSSM over existing models.