 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tackling Heavy-Tailed Rewards in Reinforcement Learning with Function Approximation: Minimax Optimal and Instance-Dependent Regret Bounds
Jun 12, 2023

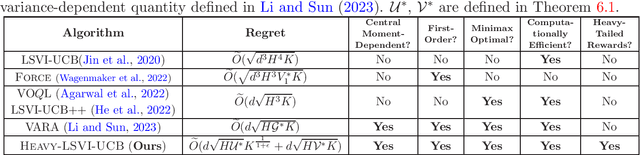
While numerous works have focused on devising efficient algorithms for reinforcement learning (RL) with uniformly bounded rewards, it remains an open question whether sample or time-efficient algorithms for RL with large state-action space exist when the rewards are \emph{heavy-tailed}, i.e., with only finite $(1+\epsilon)$-th moments for some $\epsilon\in(0,1]$. In this work, we address the challenge of such rewards in RL with linear function approximation. We first design an algorithm, \textsc{Heavy-OFUL}, for heavy-tailed linear bandits, achieving an \emph{instance-dependent} $T$-round regret of $\tilde{O}\big(d T^{\frac{1-\epsilon}{2(1+\epsilon)}} \sqrt{\sum_{t=1}^T \nu_t^2} + d T^{\frac{1-\epsilon}{2(1+\epsilon)}}\big)$, the \emph{first} of this kind. Here, $d$ is the feature dimension, and $\nu_t^{1+\epsilon}$ is the $(1+\epsilon)$-th central moment of the reward at the $t$-th round. We further show the above bound is minimax optimal when applied to the worst-case instances in stochastic and deterministic linear bandits. We then extend this algorithm to the RL settings with linear function approximation. Our algorithm, termed as \textsc{Heavy-LSVI-UCB}, achieves the \emph{first} computationally efficient \emph{instance-dependent} $K$-episode regret of $\tilde{O}(d \sqrt{H \mathcal{U}^*} K^\frac{1}{1+\epsilon} + d \sqrt{H \mathcal{V}^* K})$. Here, $H$ is length of the episode, and $\mathcal{U}^*, \mathcal{V}^*$ are instance-dependent quantities scaling with the central moment of reward and value functions, respectively. We also provide a matching minimax lower bound $\Omega(d H K^{\frac{1}{1+\epsilon}} + d \sqrt{H^3 K})$ to demonstrate the optimality of our algorithm in the worst case. Our result is achieved via a novel robust self-normalized concentration inequality that may be of independent interest in handling heavy-tailed noise in general online regression problems.
Multilingual Clinical NER: Translation or Cross-lingual Transfer?
Jun 07, 2023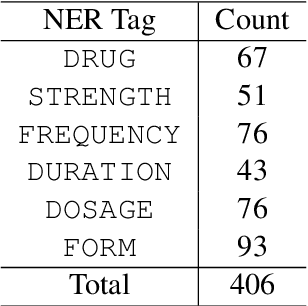
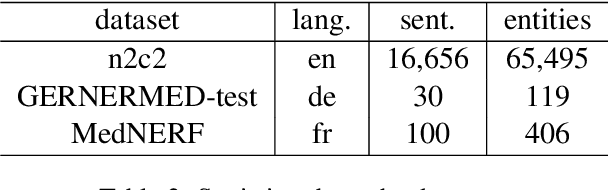
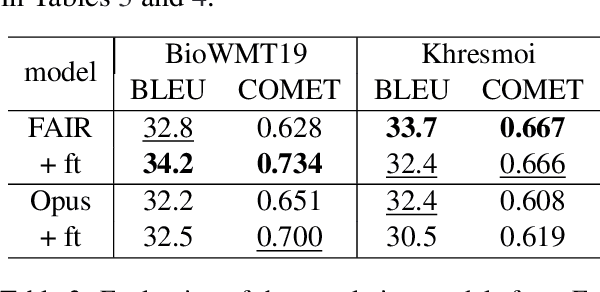
Natural language tasks like Named Entity Recognition (NER) in the clinical domain on non-English texts can be very time-consuming and expensive due to the lack of annotated data. Cross-lingual transfer (CLT) is a way to circumvent this issue thanks to the ability of multilingual large language models to be fine-tuned on a specific task in one language and to provide high accuracy for the same task in another language. However, other methods leveraging translation models can be used to perform NER without annotated data in the target language, by either translating the training set or test set. This paper compares cross-lingual transfer with these two alternative methods, to perform clinical NER in French and in German without any training data in those languages. To this end, we release MedNERF a medical NER test set extracted from French drug prescriptions and annotated with the same guidelines as an English dataset. Through extensive experiments on this dataset and on a German medical dataset (Frei and Kramer, 2021), we show that translation-based methods can achieve similar performance to CLT but require more care in their design. And while they can take advantage of monolingual clinical language models, those do not guarantee better results than large general-purpose multilingual models, whether with cross-lingual transfer or translation.
Analysing the Robustness of NSGA-II under Noise
Jun 07, 2023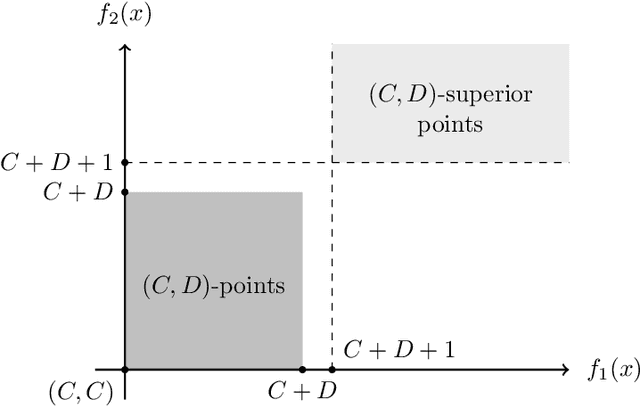
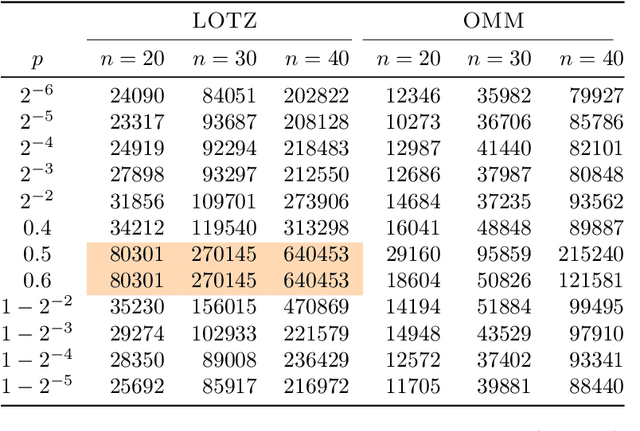

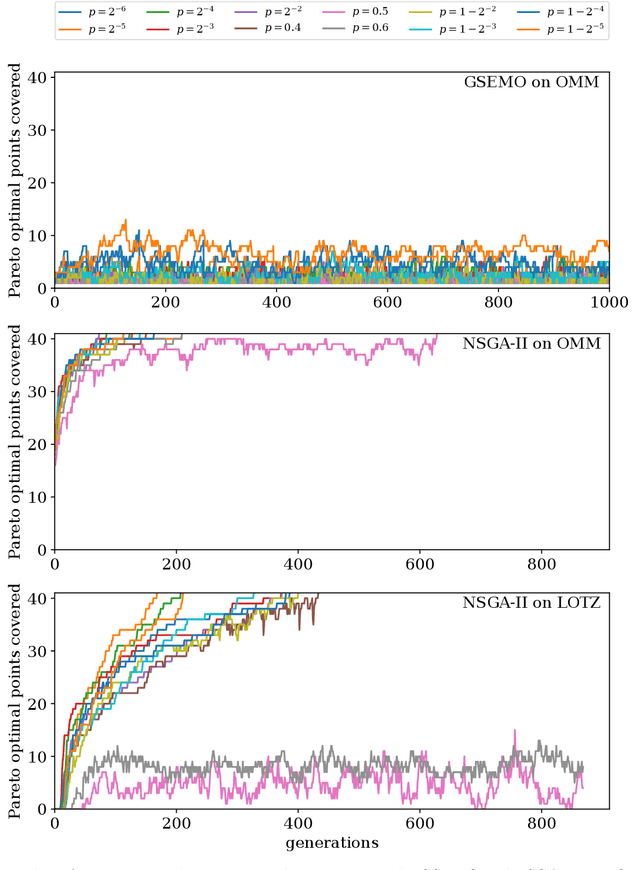
Runtime analysis has produced many results on the efficiency of simple evolutionary algorithms like the (1+1) EA, and its analogue called GSEMO in evolutionary multiobjective optimisation (EMO). Recently, the first runtime analyses of the famous and highly cited EMO algorithm NSGA-II have emerged, demonstrating that practical algorithms with thousands of applications can be rigorously analysed. However, these results only show that NSGA-II has the same performance guarantees as GSEMO and it is unclear how and when NSGA-II can outperform GSEMO. We study this question in noisy optimisation and consider a noise model that adds large amounts of posterior noise to all objectives with some constant probability $p$ per evaluation. We show that GSEMO fails badly on every noisy fitness function as it tends to remove large parts of the population indiscriminately. In contrast, NSGA-II is able to handle the noise efficiently on \textsc{LeadingOnesTrailingZeroes} when $p<1/2$, as the algorithm is able to preserve useful search points even in the presence of noise. We identify a phase transition at $p=1/2$ where the expected time to cover the Pareto front changes from polynomial to exponential. To our knowledge, this is the first proof that NSGA-II can outperform GSEMO and the first runtime analysis of NSGA-II in noisy optimisation.
Five A$^{+}$ Network: You Only Need 9K Parameters for Underwater Image Enhancement
May 15, 2023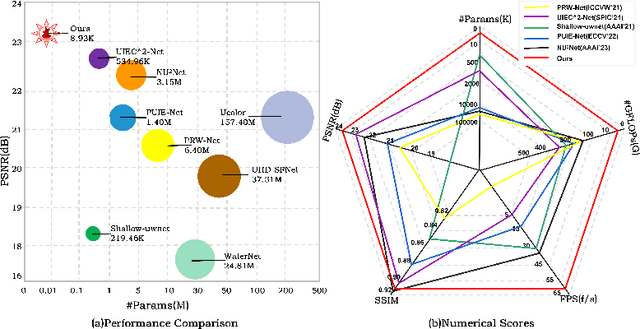
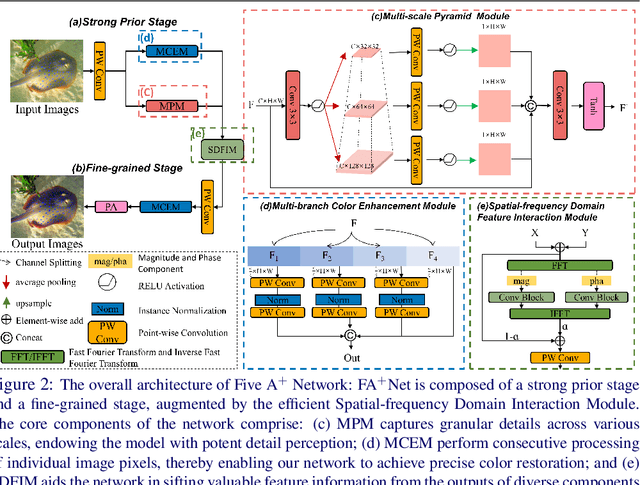

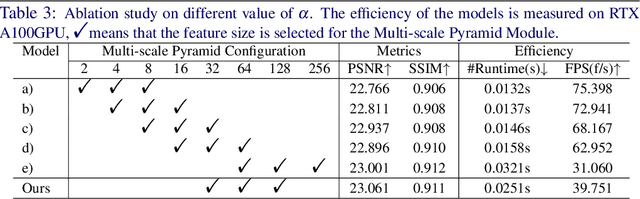
A lightweight underwater image enhancement network is of great significance for resource-constrained platforms, but balancing model size, computational efficiency, and enhancement performance has proven difficult for previous approaches. In this work, we propose the Five A$^{+}$ Network (FA$^{+}$Net), a highly efficient and lightweight real-time underwater image enhancement network with only $\sim$ 9k parameters and $\sim$ 0.01s processing time. The FA$^{+}$Net employs a two-stage enhancement structure. The strong prior stage aims to decompose challenging underwater degradations into sub-problems, while the fine-grained stage incorporates multi-branch color enhancement module and pixel attention module to amplify the network's perception of details. To the best of our knowledge, FA$^{+}$Net is the only network with the capability of real-time enhancement of 1080P images. Thorough extensive experiments and comprehensive visual comparison, we show that FA$^{+}$Net outperforms previous approaches by obtaining state-of-the-art performance on multiple datasets while significantly reducing both parameter count and computational complexity. The code is open source at https://github.com/Owen718/FiveAPlus-Network.
Maximum Likelihood Training of Autoencoders
Jun 02, 2023

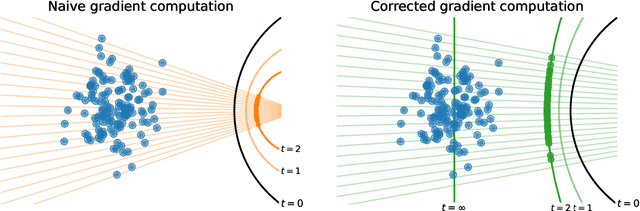
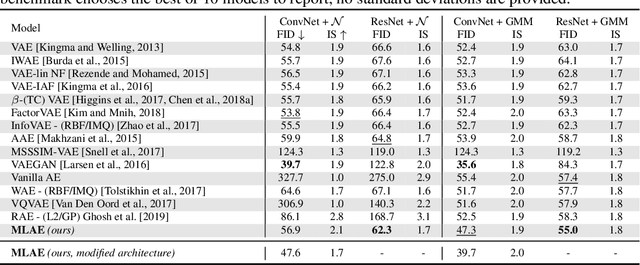
Maximum likelihood training has favorable statistical properties and is popular for generative modeling, especially with normalizing flows. On the other hand, generative autoencoders promise to be more efficient than normalizing flows due to the manifold hypothesis. In this work, we introduce successful maximum likelihood training of unconstrained autoencoders for the first time, bringing the two paradigms together. To do so, we identify and overcome two challenges: Firstly, existing maximum likelihood estimators for free-form networks are unacceptably slow, relying on iteration schemes whose cost scales linearly with latent dimension. We introduce an improved estimator which eliminates iteration, resulting in constant cost (roughly double the runtime per batch of a vanilla autoencoder). Secondly, we demonstrate that naively applying maximum likelihood to autoencoders can lead to divergent solutions and use this insight to motivate a stable maximum likelihood training objective. We perform extensive experiments on toy, tabular and image data, demonstrating the competitive performance of the resulting model. We call our model the maximum likelihood autoencoder (MLAE).
Symmetric Exploration in Combinatorial Optimization is Free!
Jun 02, 2023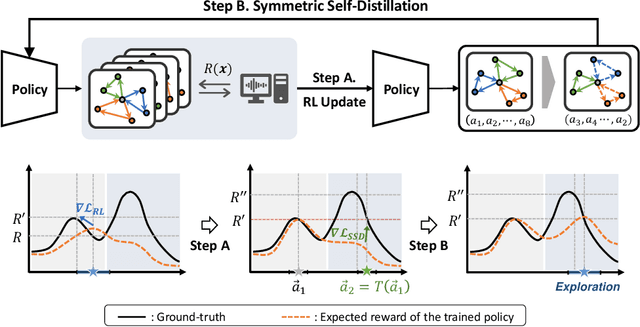
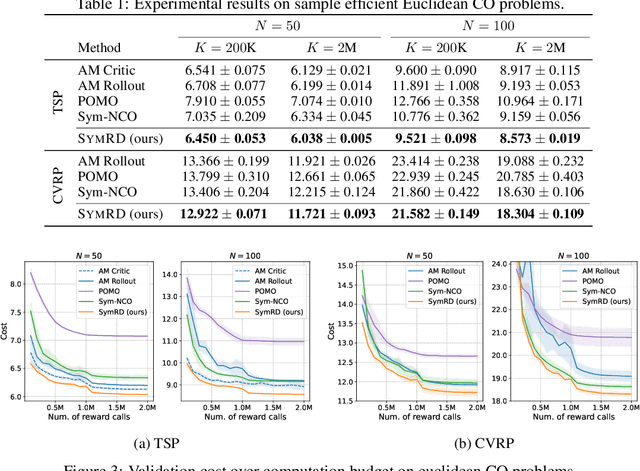
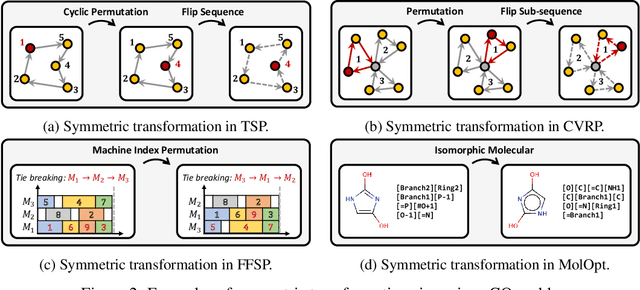
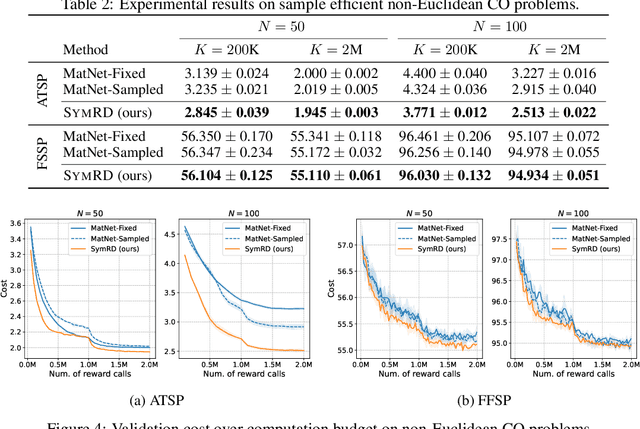
Recently, deep reinforcement learning (DRL) has shown promise in solving combinatorial optimization (CO) problems. However, they often require a large number of evaluations on the objective function, which can be time-consuming in real-world scenarios. To address this issue, we propose a "free" technique to enhance the performance of any deep reinforcement learning (DRL) solver by exploiting symmetry without requiring additional objective function evaluations. Our key idea is to augment the training of DRL-based combinatorial optimization solvers by reward-preserving transformations. The proposed algorithm is likely to be impactful since it is simple, easy to integrate with existing solvers, and applicable to a wide range of combinatorial optimization tasks. Extensive empirical evaluations on NP-hard routing optimization, scheduling optimization, and de novo molecular optimization confirm that our method effortlessly improves the sample efficiency of state-of-the-art DRL algorithms. Our source code is available at https://github.com/kaist-silab/sym-rd.
Adversarial Attack Based on Prediction-Correction
Jun 02, 2023
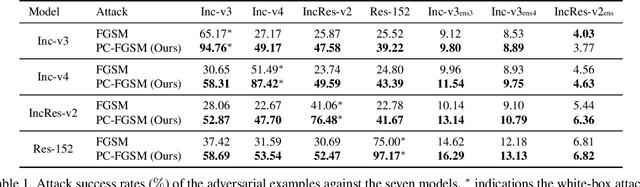
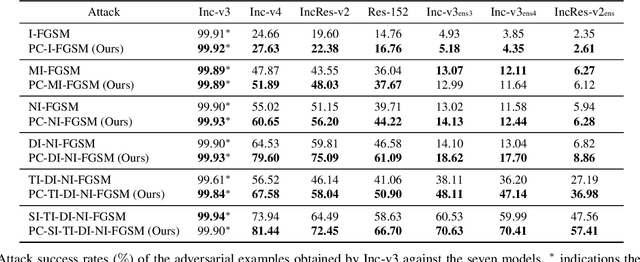
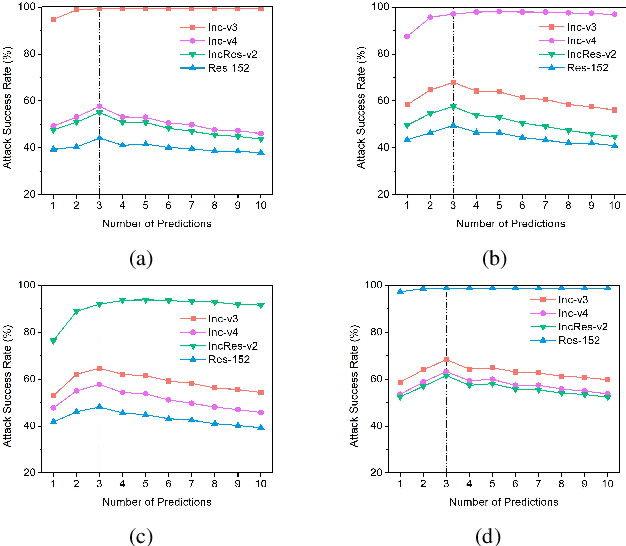
Deep neural networks (DNNs) are vulnerable to adversarial examples obtained by adding small perturbations to original examples. The added perturbations in existing attacks are mainly determined by the gradient of the loss function with respect to the inputs. In this paper, the close relationship between gradient-based attacks and the numerical methods for solving ordinary differential equation (ODE) is studied for the first time. Inspired by the numerical solution of ODE, a new prediction-correction (PC) based adversarial attack is proposed. In our proposed PC-based attack, some existing attack can be selected to produce a predicted example first, and then the predicted example and the current example are combined together to determine the added perturbations. The proposed method possesses good extensibility and can be applied to all available gradient-based attacks easily. Extensive experiments demonstrate that compared with the state-of-the-art gradient-based adversarial attacks, our proposed PC-based attacks have higher attack success rates, and exhibit better transferability.
Efficient RL with Impaired Observability: Learning to Act with Delayed and Missing State Observations
Jun 02, 2023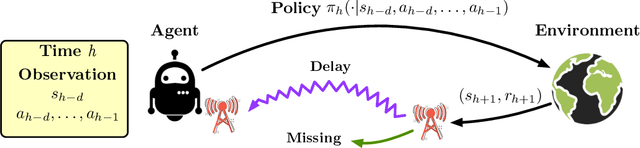
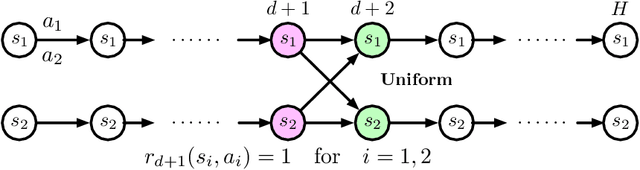
In real-world reinforcement learning (RL) systems, various forms of impaired observability can complicate matters. These situations arise when an agent is unable to observe the most recent state of the system due to latency or lossy channels, yet the agent must still make real-time decisions. This paper introduces a theoretical investigation into efficient RL in control systems where agents must act with delayed and missing state observations. We establish near-optimal regret bounds, of the form $\tilde{\mathcal{O}}(\sqrt{{\rm poly}(H) SAK})$, for RL in both the delayed and missing observation settings. Despite impaired observability posing significant challenges to the policy class and planning, our results demonstrate that learning remains efficient, with the regret bound optimally depending on the state-action size of the original system. Additionally, we provide a characterization of the performance of the optimal policy under impaired observability, comparing it to the optimal value obtained with full observability.
The Web Can Be Your Oyster for Improving Large Language Models
May 24, 2023Large language models (LLMs) encode a large amount of world knowledge. However, as such knowledge is frozen at the time of model training, the models become static and limited by the training data at that time. In order to further improve the capacity of LLMs for knowledge-intensive tasks, we consider augmenting LLMs with the large-scale web using search engine. Unlike previous augmentation sources (e.g., Wikipedia data dump), the web provides broader, more comprehensive and constantly updated information. In this paper, we present a web-augmented LLM UNIWEB, which is trained over 16 knowledge-intensive tasks in a unified text-to-text format. Instead of simply using the retrieved contents from web, our approach has made two major improvements. Firstly, we propose an adaptive search engine assisted learning method that can self-evaluate the confidence level of LLM's predictions, and adaptively determine when to refer to the web for more data, which can avoid useless or noisy augmentation from web. Secondly, we design a pretraining task, i.e., continual knowledge learning, based on salient spans prediction, to reduce the discrepancy between the encoded and retrieved knowledge. Experiments on a wide range of knowledge-intensive tasks show that our model significantly outperforms previous retrieval-augmented methods.
Explainability in Simplicial Map Neural Networks
May 29, 2023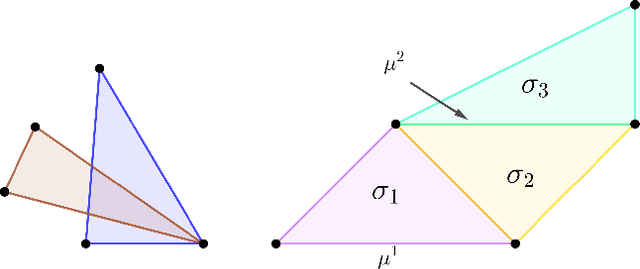
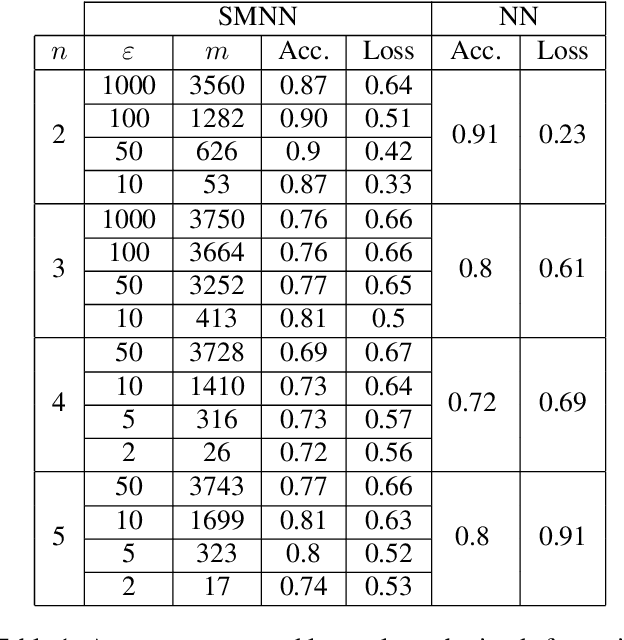
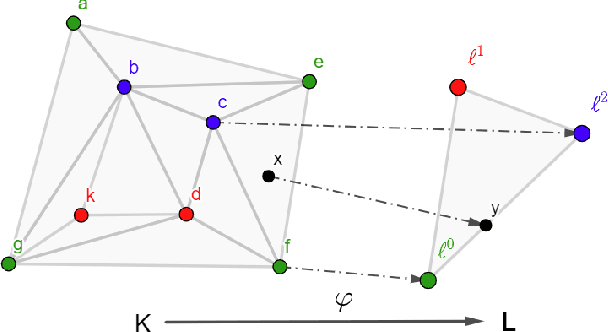
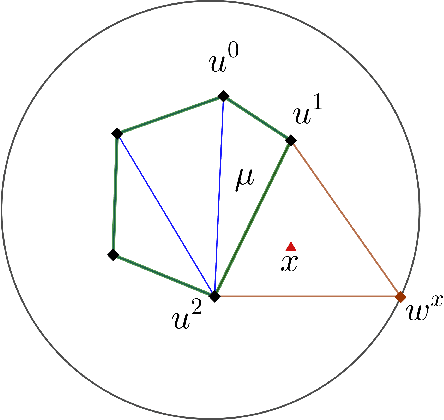
Simplicial map neural networks (SMNNs) are topology-based neural networks with interesting properties such as universal approximation capability and robustness to adversarial examples under appropriate conditions. However, SMNNs present some bottlenecks for their possible application in high dimensions. First, no SMNN training process has been defined so far. Second, SMNNs require the construction of a convex polytope surrounding the input dataset. In this paper, we propose a SMNN training procedure based on a support subset of the given dataset and a method based on projection to a hypersphere as a replacement for the convex polytope construction. In addition, the explainability capacity of SMNNs is also introduced for the first time in this paper.