 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging characteristics of the output probability distribution for identifying adversarial audio examples
May 26, 2023


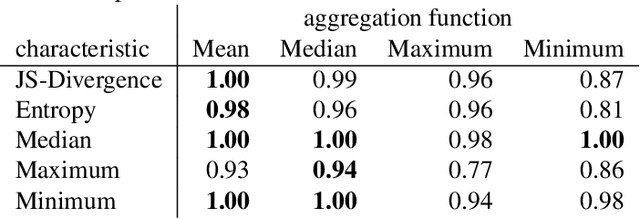
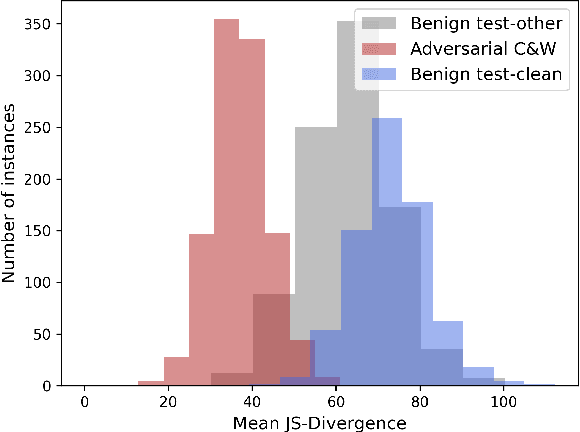
Adversarial attacks represent a security threat to machine learning based automatic speech recognition (ASR) systems. To prevent such attacks we propose an adversarial example detection strategy applicable to any ASR system that predicts a probability distribution over output tokens in each time step. We measure a set of characteristics of this distribution: the median, maximum, and minimum over the output probabilities, the entropy, and the Jensen-Shannon divergence of the distributions of subsequent time steps. Then, we fit a Gaussian distribution to the characteristics observed for benign data. By computing the likelihood of incoming new audio we can distinguish malicious inputs from samples from clean data with an area under the receiving operator characteristic (AUROC) higher than 0.99, which drops to 0.98 for less-quality audio. To assess the robustness of our method we build adaptive attacks. This reduces the AUROC to 0.96 but results in more noisy adversarial clips.
DynaShare: Task and Instance Conditioned Parameter Sharing for Multi-Task Learning
May 26, 2023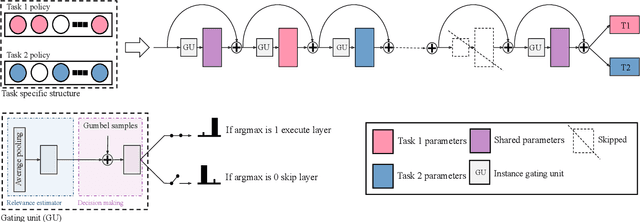
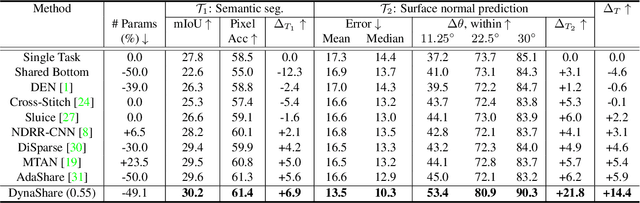
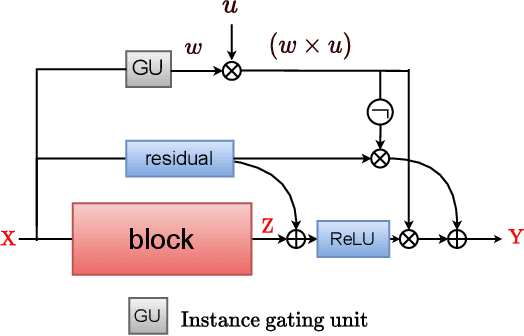
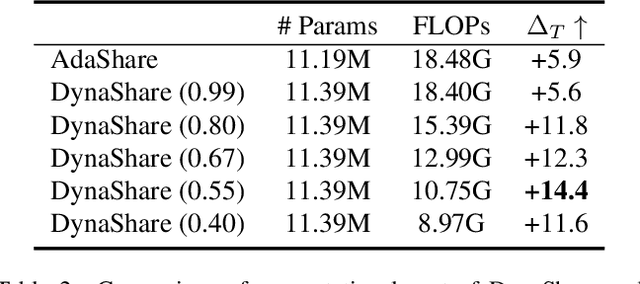
Multi-task networks rely on effective parameter sharing to achieve robust generalization across tasks. In this paper, we present a novel parameter sharing method for multi-task learning that conditions parameter sharing on both the task and the intermediate feature representations at inference time. In contrast to traditional parameter sharing approaches, which fix or learn a deterministic sharing pattern during training and apply the same pattern to all examples during inference, we propose to dynamically decide which parts of the network to activate based on both the task and the input instance. Our approach learns a hierarchical gating policy consisting of a task-specific policy for coarse layer selection and gating units for individual input instances, which work together to determine the execution path at inference time. Experiments on the NYU v2, Cityscapes and MIMIC-III datasets demonstrate the potential of the proposed approach and its applicability across problem domains.
Diagnostic Spatio-temporal Transformer with Faithful Encoding
May 26, 2023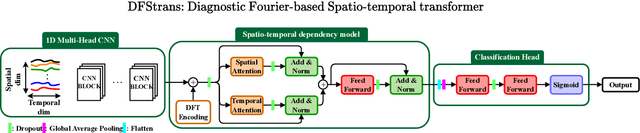
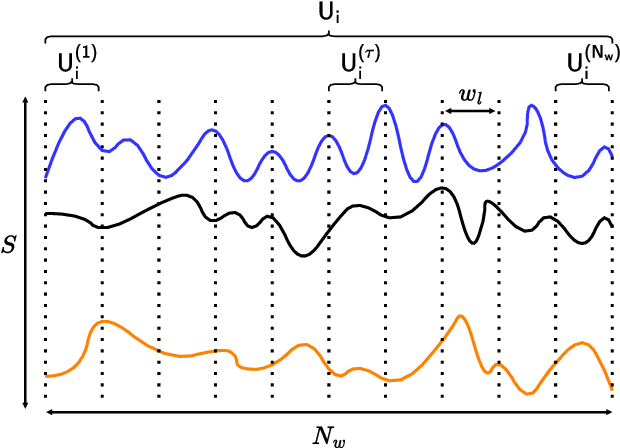
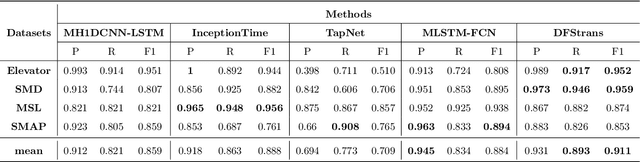
This paper addresses the task of anomaly diagnosis when the underlying data generation process has a complex spatio-temporal (ST) dependency. The key technical challenge is to extract actionable insights from the dependency tensor characterizing high-order interactions among temporal and spatial indices. We formalize the problem as supervised dependency discovery, where the ST dependency is learned as a side product of multivariate time-series classification. We show that temporal positional encoding used in existing ST transformer works has a serious limitation in capturing higher frequencies (short time scales). We propose a new positional encoding with a theoretical guarantee, based on discrete Fourier transform. We also propose a new ST dependency discovery framework, which can provide readily consumable diagnostic information in both spatial and temporal directions. Finally, we demonstrate the utility of the proposed model, DFStrans (Diagnostic Fourier-based Spatio-temporal Transformer), in a real industrial application of building elevator control.
Retrieval-Enhanced Contrastive Vision-Text Models
Jun 12, 2023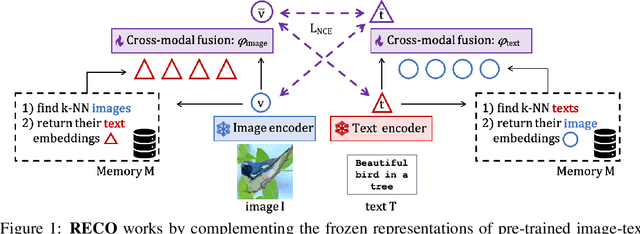
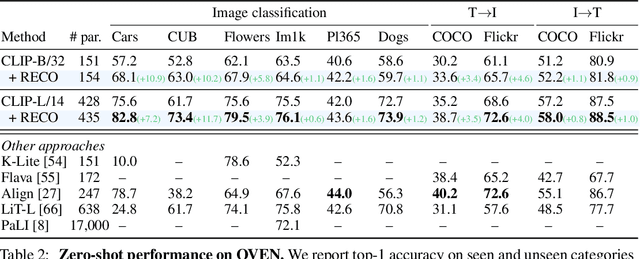
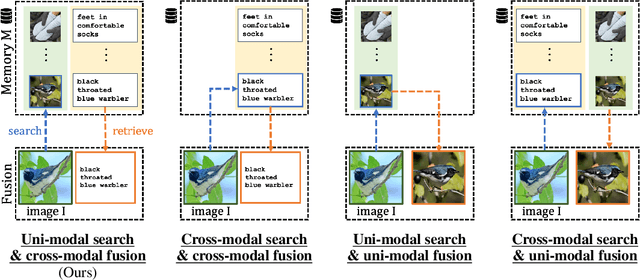
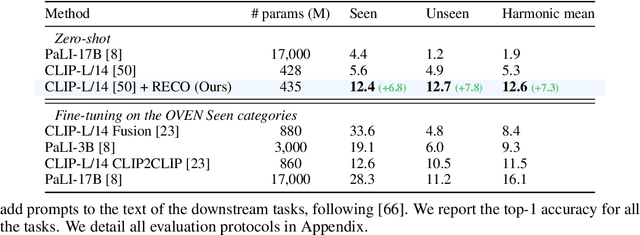
Contrastive image-text models such as CLIP form the building blocks of many state-of-the-art systems. While they excel at recognizing common generic concepts, they still struggle on fine-grained entities which are rare, or even absent from the pre-training dataset. Hence, a key ingredient to their success has been the use of large-scale curated pre-training data aiming at expanding the set of concepts that they can memorize during the pre-training stage. In this work, we explore an alternative to encoding fine-grained knowledge directly into the model's parameters: we instead train the model to retrieve this knowledge from an external memory. Specifically, we propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time, which greatly improves their zero-shot predictions. Remarkably, we show that this can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP. Our experiments validate that our retrieval-enhanced contrastive (RECO) training improves CLIP performance substantially on several challenging fine-grained tasks: for example +10.9 on Stanford Cars, +10.2 on CUB-2011 and +7.3 on the recent OVEN benchmark.
A metric to compare the anatomy variation between image time series
Feb 23, 2023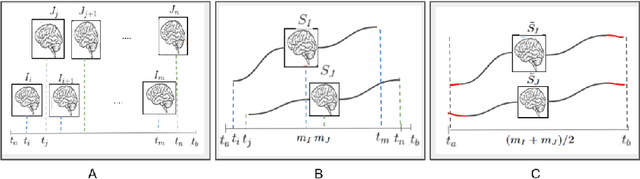
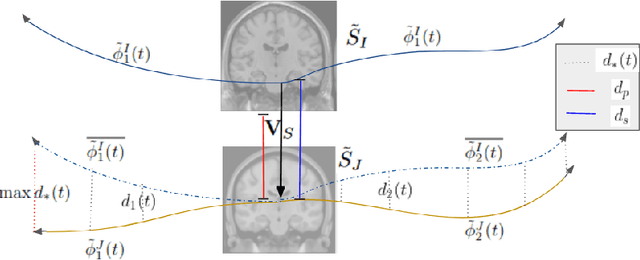
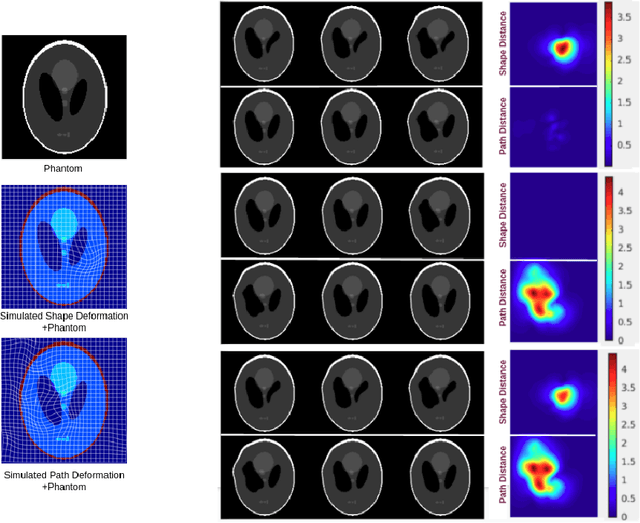
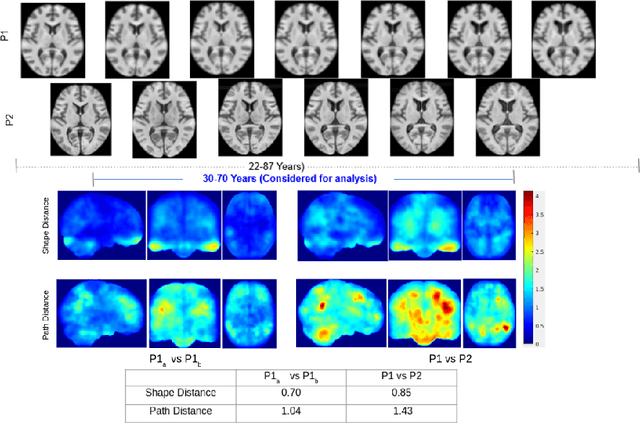
Biological processes like growth, aging, and disease progression are generally studied with follow-up scans taken at different time points, i.e., with image time series (TS) based analysis. Comparison between TS representing a biological process of two individuals/populations is of interest. A metric to quantify the difference between TS is desirable for such a comparison. The two TS represent the evolution of two different subject/population average anatomies through two paths. A method to untangle and quantify the path and inter-subject anatomy(shape) difference between the TS is presented in this paper. The proposed metric is a generalized version of Fr\'echet distance designed to compare curves. The proposed method is evaluated with simulated and adult and fetal neuro templates. Results show that the metric is able to separate and quantify the path and shape differences between TS.
Are training trajectories of deep single-spike and deep ReLU network equivalent?
Jun 14, 2023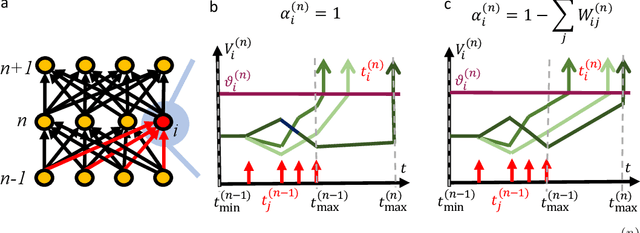


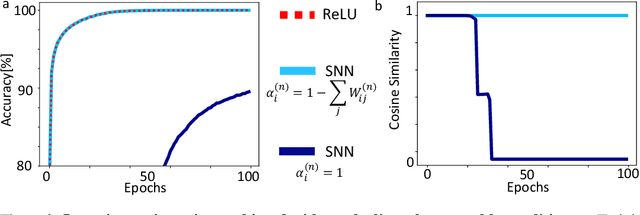
Communication by binary and sparse spikes is a key factor for the energy efficiency of biological brains. However, training deep spiking neural networks (SNNs) with backpropagation is harder than with artificial neural networks (ANNs), which is puzzling given that recent theoretical results provide exact mapping algorithms from ReLU to time-to-first-spike (TTFS) SNNs. Building upon these results, we analyze in theory and in simulation the learning dynamics of TTFS-SNNs. Our analysis highlights that even when an SNN can be mapped exactly to a ReLU network, it cannot always be robustly trained by gradient descent. The reason for that is the emergence of a specific instance of the vanishing-or-exploding gradient problem leading to a bias in the gradient descent trajectory in comparison with the equivalent ANN. After identifying this issue we derive a generic solution for the network initialization and SNN parameterization which guarantees that the SNN can be trained as robustly as its ANN counterpart. Our theoretical findings are illustrated in practice on image classification datasets. Our method achieves the same accuracy as deep ConvNets on CIFAR10 and enables fine-tuning on the much larger PLACES365 dataset without loss of accuracy compared to the ANN. We argue that the combined perspective of conversion and fine-tuning with robust gradient descent in SNN will be decisive to optimize SNNs for hardware implementations needing low latency and resilience to noise and quantization.
Feeding control and water quality monitoring in aquaculture systems: Opportunities and challenges
Jun 14, 2023

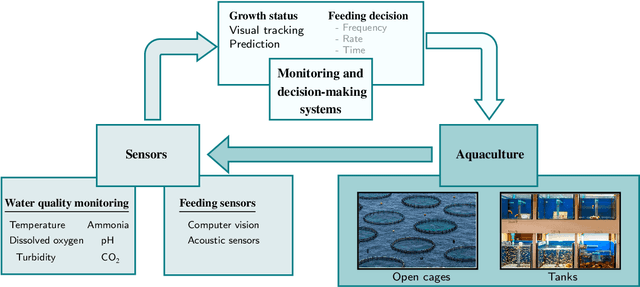
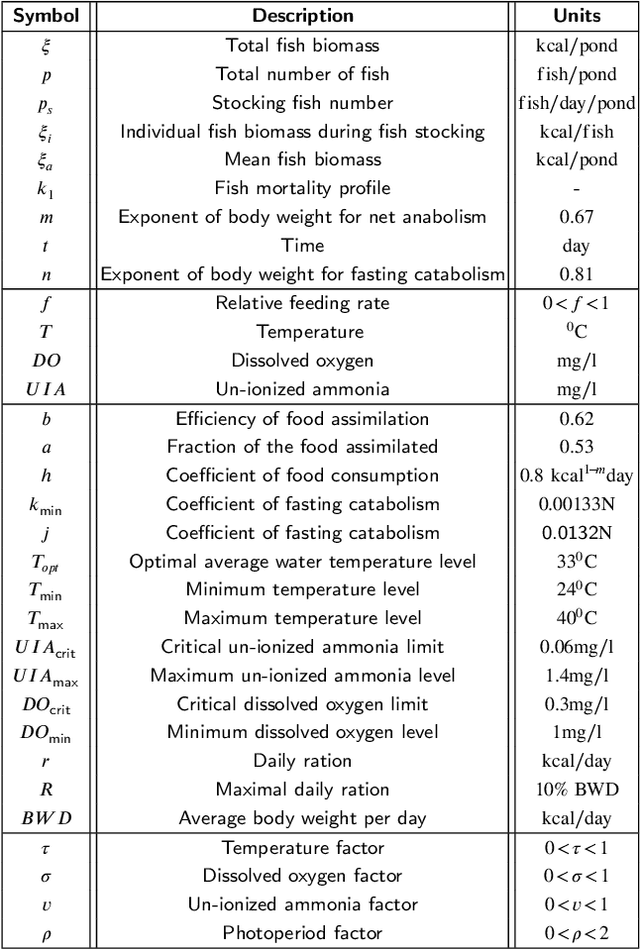
Aquaculture systems can benefit from the recent development of advanced control strategies to reduce operating costs and fish loss and increase growth production efficiency, resulting in fish welfare and health. Monitoring the water quality and controlling feeding are fundamental elements of balancing fish productivity and shaping the fish growth process. Currently, most fish-feeding processes are conducted manually in different phases and rely on time-consuming and challenging artificial discrimination. The feeding control approach influences fish growth and breeding through the feed conversion rate; hence, controlling these feeding parameters is crucial for enhancing fish welfare and minimizing general fishery costs. The high concentration of environmental factors, such as a high ammonia concentration and pH, affect the water quality and fish survival. Therefore, there is a critical need to develop control strategies to determine optimal, efficient, and reliable feeding processes and monitor water quality. This paper reviews the main control design techniques for fish growth in aquaculture systems, namely algorithms that optimize the feeding and water quality of a dynamic fish growth process. Specifically, we review model-based control approaches and model-free reinforcement learning strategies to optimize the growth and survival of the fish or track a desired reference live-weight growth trajectory. The model-free framework uses an approximate fish growth dynamic model and does not satisfy constraints. We discuss how model-based approaches can support a reinforcement learning framework to efficiently handle constraint satisfaction and find better trajectories and policies from value-based reinforcement learning.
Questioning the Survey Responses of Large Language Models
Jun 13, 2023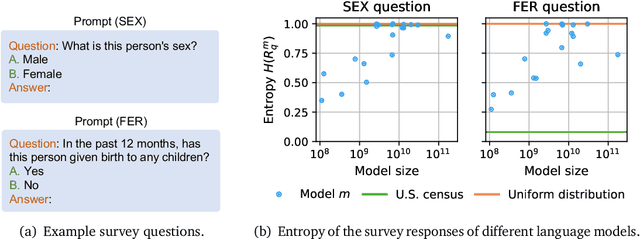
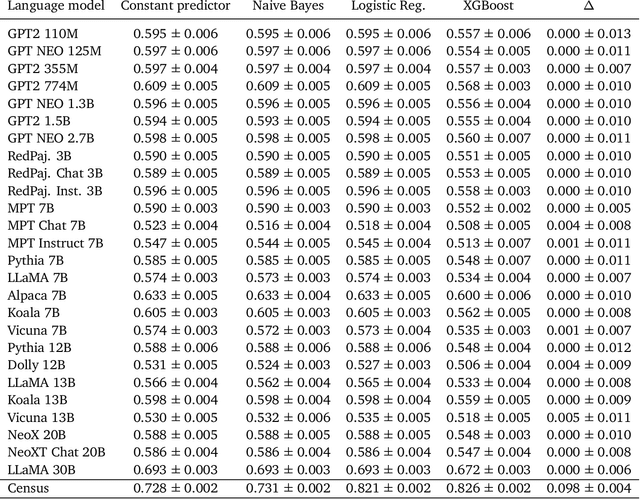
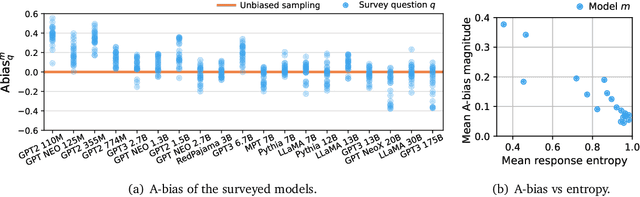
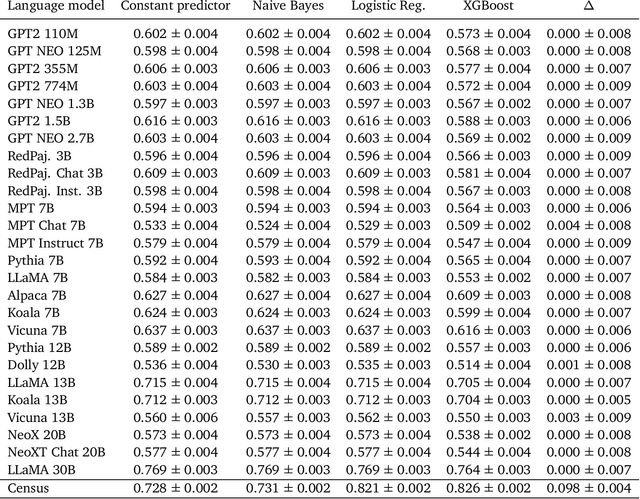
As large language models increase in capability, researchers have started to conduct surveys of all kinds on these models with varying scientific motivations. In this work, we examine what we can learn from a model's survey responses on the basis of the well-established American Community Survey (ACS) by the U.S. Census Bureau. Evaluating more than a dozen different models, varying in size from a few hundred million to ten billion parameters, hundreds of thousands of times each on questions from the ACS, we systematically establish two dominant patterns. First, smaller models have a significant position and labeling bias, for example, towards survey responses labeled with the letter "A". This A-bias diminishes, albeit slowly, as model size increases. Second, when adjusting for this labeling bias through randomized answer ordering, models still do not trend toward US population statistics or those of any cognizable population. Rather, models across the board trend toward uniformly random aggregate statistics over survey responses. This pattern is robust to various different ways of prompting the model, including what is the de-facto standard. Our findings demonstrate that aggregate statistics of a language model's survey responses lack the signals found in human populations. This absence of statistical signal cautions about the use of survey responses from large language models at present time.
RescueSpeech: A German Corpus for Speech Recognition in Search and Rescue Domain
Jun 06, 2023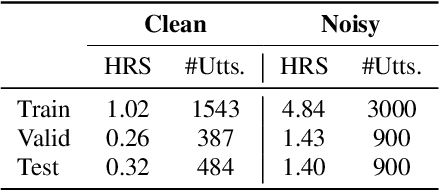
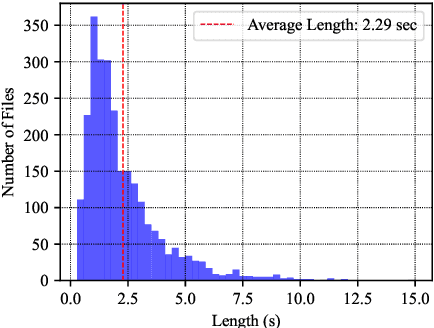
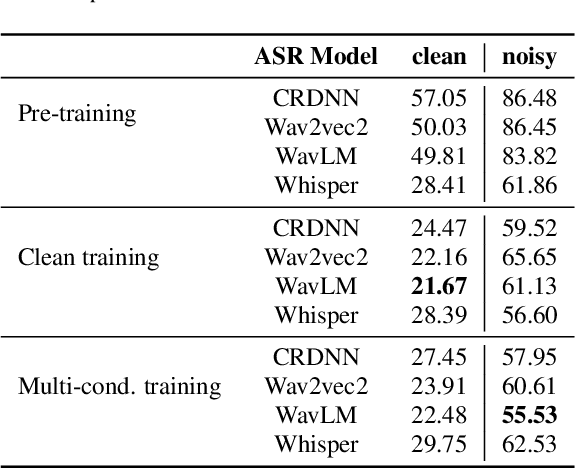
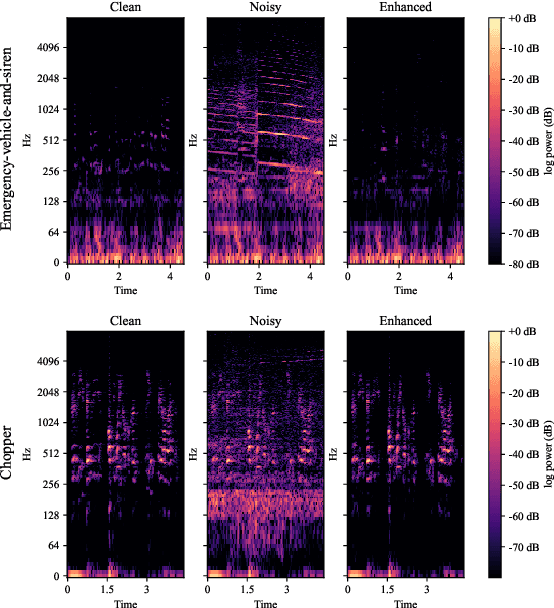
Despite recent advancements in speech recognition, there are still difficulties in accurately transcribing conversational and emotional speech in noisy and reverberant acoustic environments. This poses a particular challenge in the search and rescue (SAR) domain, where transcribing conversations among rescue team members is crucial to support real-time decision-making. The scarcity of speech data and associated background noise in SAR scenarios make it difficult to deploy robust speech recognition systems. To address this issue, we have created and made publicly available a German speech dataset called RescueSpeech. This dataset includes real speech recordings from simulated rescue exercises. Additionally, we have released competitive training recipes and pre-trained models. Our study indicates that the current level of performance achieved by state-of-the-art methods is still far from being acceptable.
Mesostructures: Beyond Spectrogram Loss in Differentiable Time-Frequency Analysis
Jan 24, 2023
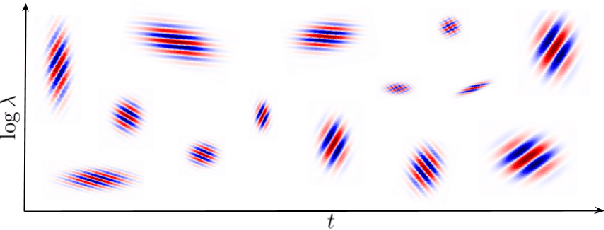
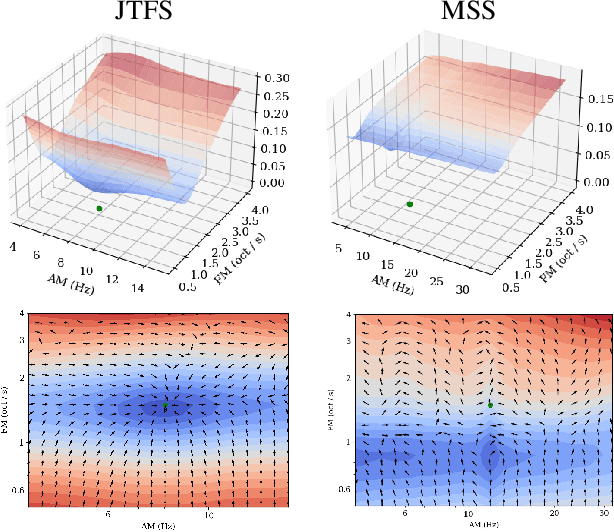
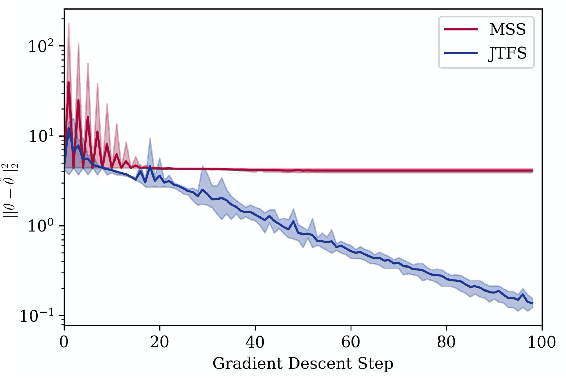
Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in deep learning. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time--frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time--frequency model of similarity at the level of both local spectra and spectrotemporal modulations.