 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UCTB: An Urban Computing Tool Box for Spatiotemporal Crowd Flow Prediction
Jun 07, 2023

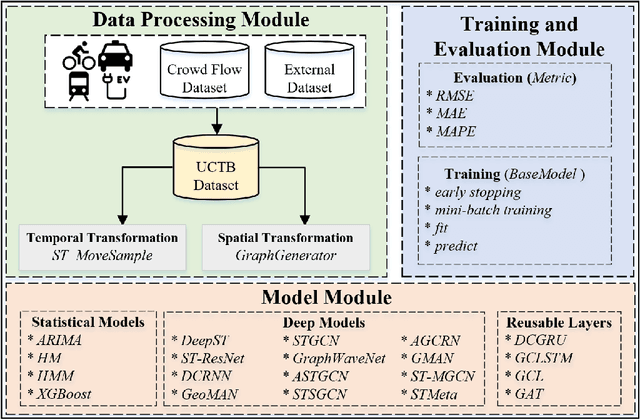


Spatiotemporal crowd flow prediction is one of the key technologies in smart cities. Currently, there are two major pain points that plague related research and practitioners. Firstly, crowd flow is related to multiple domain knowledge factors; however, due to the diversity of application scenarios, it is difficult for subsequent work to make reasonable and comprehensive use of domain knowledge. Secondly, with the development of deep learning technology, the implementation of relevant techniques has become increasingly complex; reproducing advanced models has become a time-consuming and increasingly cumbersome task. To address these issues, we design and implement a spatiotemporal crowd flow prediction toolbox called UCTB (Urban Computing Tool Box), which integrates multiple spatiotemporal domain knowledge and state-of-the-art models simultaneously. The relevant code and supporting documents have been open-sourced at https://github.com/uctb/UCTB.
Optimal Rates for Bandit Nonstochastic Control
May 24, 2023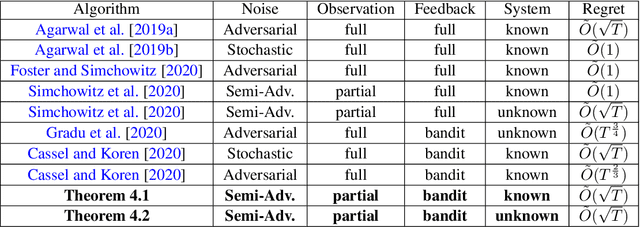
Linear Quadratic Regulator (LQR) and Linear Quadratic Gaussian (LQG) control are foundational and extensively researched problems in optimal control. We investigate LQR and LQG problems with semi-adversarial perturbations and time-varying adversarial bandit loss functions. The best-known sublinear regret algorithm of~\cite{gradu2020non} has a $T^{\frac{3}{4}}$ time horizon dependence, and its authors posed an open question about whether a tight rate of $\sqrt{T}$ could be achieved. We answer in the affirmative, giving an algorithm for bandit LQR and LQG which attains optimal regret (up to logarithmic factors) for both known and unknown systems. A central component of our method is a new scheme for bandit convex optimization with memory, which is of independent interest.
Leveraging Evolutionary Changes for Software Process Quality
Jun 15, 2023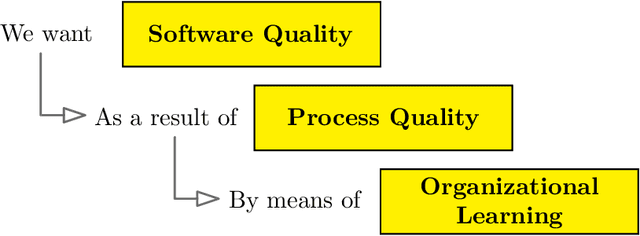
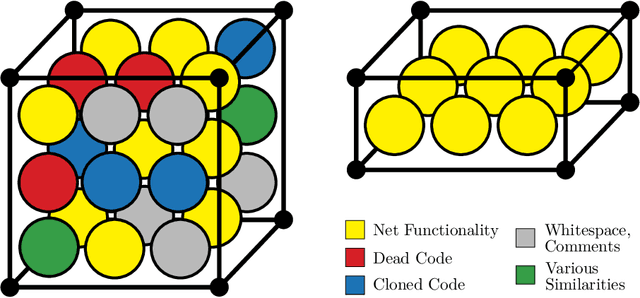
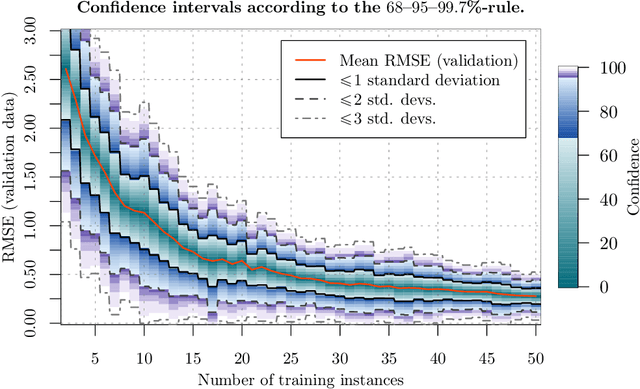
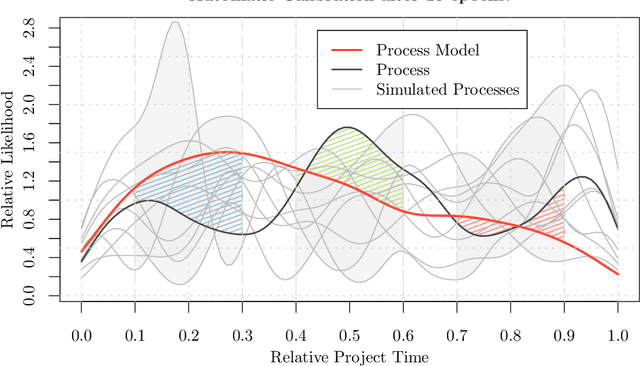
Real-world software applications must constantly evolve to remain relevant. This evolution occurs when developing new applications or adapting existing ones to meet new requirements, make corrections, or incorporate future functionality. Traditional methods of software quality control involve software quality models and continuous code inspection tools. These measures focus on directly assessing the quality of the software. However, there is a strong correlation and causation between the quality of the development process and the resulting software product. Therefore, improving the development process indirectly improves the software product, too. To achieve this, effective learning from past processes is necessary, often embraced through post mortem organizational learning. While qualitative evaluation of large artifacts is common, smaller quantitative changes captured by application lifecycle management are often overlooked. In addition to software metrics, these smaller changes can reveal complex phenomena related to project culture and management. Leveraging these changes can help detect and address such complex issues. Software evolution was previously measured by the size of changes, but the lack of consensus on a reliable and versatile quantification method prevents its use as a dependable metric. Different size classifications fail to reliably describe the nature of evolution. While application lifecycle management data is rich, identifying which artifacts can model detrimental managerial practices remains uncertain. Approaches such as simulation modeling, discrete events simulation, or Bayesian networks have only limited ability to exploit continuous-time process models of such phenomena. Even worse, the accessibility and mechanistic insight into such gray- or black-box models are typically very low. To address these challenges, we suggest leveraging objectively [...]
Efficient Token-Guided Image-Text Retrieval with Consistent Multimodal Contrastive Training
Jun 15, 2023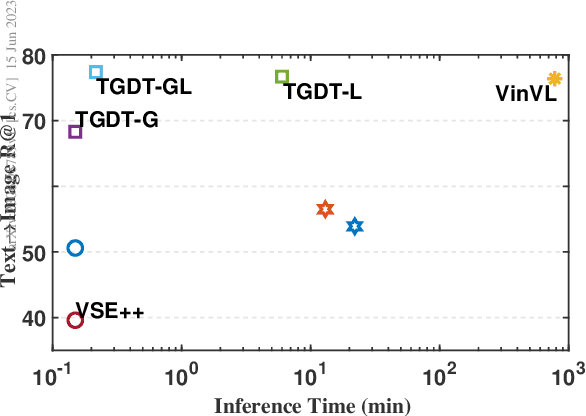
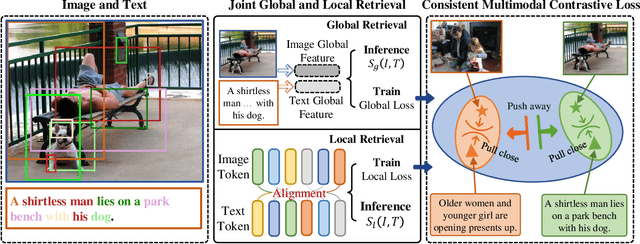
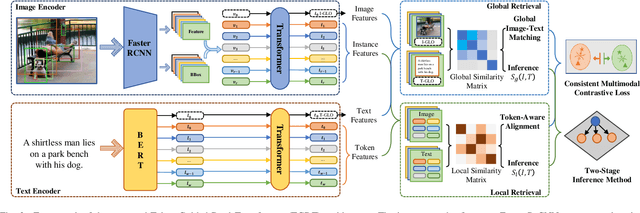
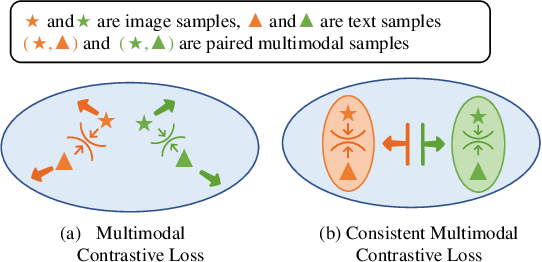
Image-text retrieval is a central problem for understanding the semantic relationship between vision and language, and serves as the basis for various visual and language tasks. Most previous works either simply learn coarse-grained representations of the overall image and text, or elaborately establish the correspondence between image regions or pixels and text words. However, the close relations between coarse- and fine-grained representations for each modality are important for image-text retrieval but almost neglected. As a result, such previous works inevitably suffer from low retrieval accuracy or heavy computational cost. In this work, we address image-text retrieval from a novel perspective by combining coarse- and fine-grained representation learning into a unified framework. This framework is consistent with human cognition, as humans simultaneously pay attention to the entire sample and regional elements to understand the semantic content. To this end, a Token-Guided Dual Transformer (TGDT) architecture which consists of two homogeneous branches for image and text modalities, respectively, is proposed for image-text retrieval. The TGDT incorporates both coarse- and fine-grained retrievals into a unified framework and beneficially leverages the advantages of both retrieval approaches. A novel training objective called Consistent Multimodal Contrastive (CMC) loss is proposed accordingly to ensure the intra- and inter-modal semantic consistencies between images and texts in the common embedding space. Equipped with a two-stage inference method based on the mixed global and local cross-modal similarity, the proposed method achieves state-of-the-art retrieval performances with extremely low inference time when compared with representative recent approaches.
Self-Knowledge Distillation for Surgical Phase Recognition
Jun 15, 2023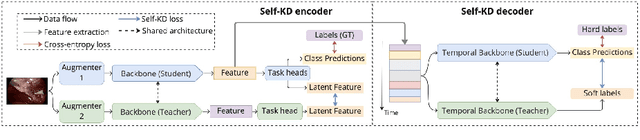
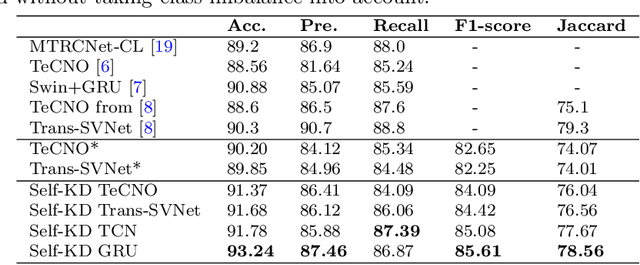
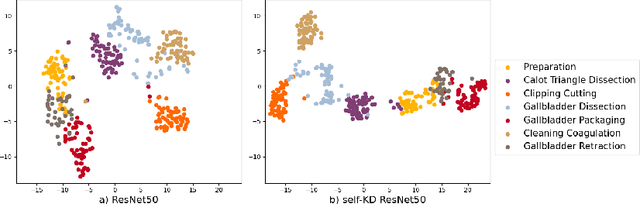
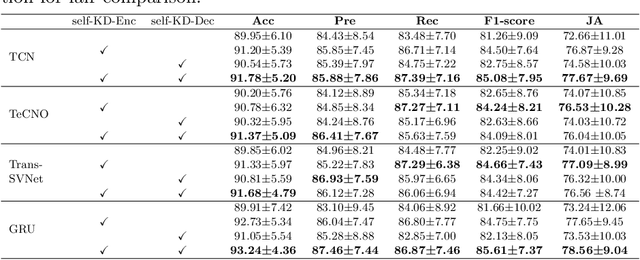
Purpose: Advances in surgical phase recognition are generally led by training deeper networks. Rather than going further with a more complex solution, we believe that current models can be exploited better. We propose a self-knowledge distillation framework that can be integrated into current state-of-the-art (SOTA) models without requiring any extra complexity to the models or annotations. Methods: Knowledge distillation is a framework for network regularization where knowledge is distilled from a teacher network to a student network. In self-knowledge distillation, the student model becomes the teacher such that the network learns from itself. Most phase recognition models follow an encoder-decoder framework. Our framework utilizes self-knowledge distillation in both stages. The teacher model guides the training process of the student model to extract enhanced feature representations from the encoder and build a more robust temporal decoder to tackle the over-segmentation problem. Results: We validate our proposed framework on the public dataset Cholec80. Our framework is embedded on top of four popular SOTA approaches and consistently improves their performance. Specifically, our best GRU model boosts performance by +3.33% accuracy and +3.95% F1-score over the same baseline model. Conclusion: We embed a self-knowledge distillation framework for the first time in the surgical phase recognition training pipeline. Experimental results demonstrate that our simple yet powerful framework can improve performance of existing phase recognition models. Moreover, our extensive experiments show that even with 75% of the training set we still achieve performance on par with the same baseline model trained on the full set.
ArchGym: An Open-Source Gymnasium for Machine Learning Assisted Architecture Design
Jun 15, 2023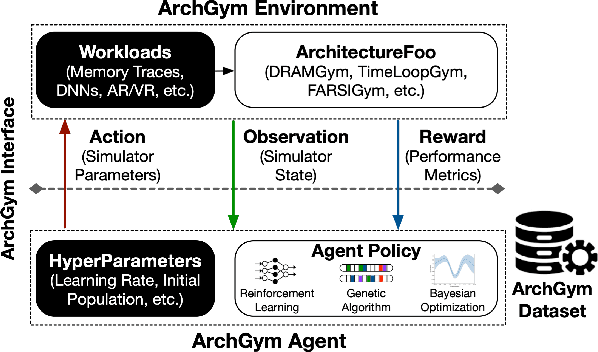
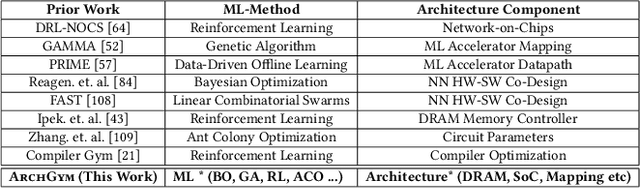
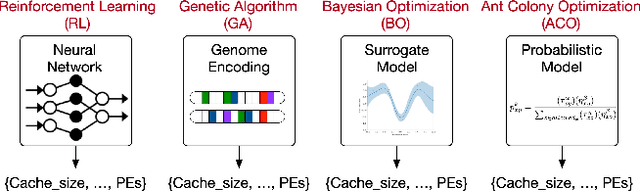

Machine learning is a prevalent approach to tame the complexity of design space exploration for domain-specific architectures. Using ML for design space exploration poses challenges. First, it's not straightforward to identify the suitable algorithm from an increasing pool of ML methods. Second, assessing the trade-offs between performance and sample efficiency across these methods is inconclusive. Finally, lack of a holistic framework for fair, reproducible, and objective comparison across these methods hinders progress of adopting ML-aided architecture design space exploration and impedes creating repeatable artifacts. To mitigate these challenges, we introduce ArchGym, an open-source gym and easy-to-extend framework that connects diverse search algorithms to architecture simulators. To demonstrate utility, we evaluate ArchGym across multiple vanilla and domain-specific search algorithms in designing custom memory controller, deep neural network accelerators, and custom SoC for AR/VR workloads, encompassing over 21K experiments. Results suggest that with unlimited samples, ML algorithms are equally favorable to meet user-defined target specification if hyperparameters are tuned; no solution is necessarily better than another (e.g., reinforcement learning vs. Bayesian methods). We coin the term hyperparameter lottery to describe the chance for a search algorithm to find an optimal design provided meticulously selected hyperparameters. The ease of data collection and aggregation in ArchGym facilitates research in ML-aided architecture design space exploration. As a case study, we show this advantage by developing a proxy cost model with an RMSE of 0.61% that offers a 2,000-fold reduction in simulation time. Code and data for ArchGym is available at https://bit.ly/ArchGym.
Robust Detection of Lead-Lag Relationships in Lagged Multi-Factor Models
May 11, 2023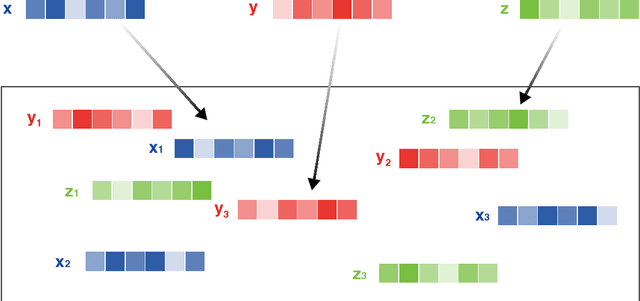

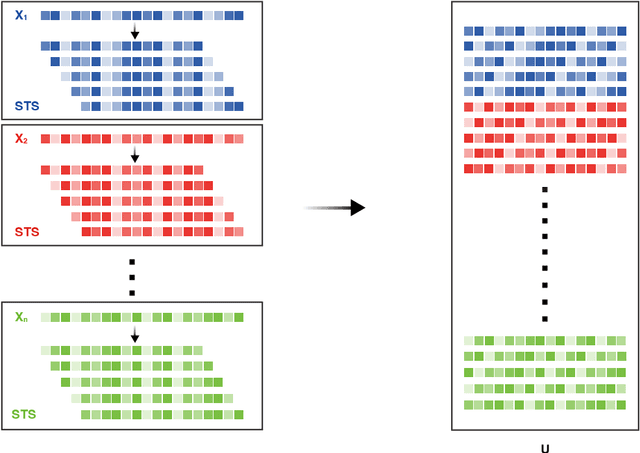
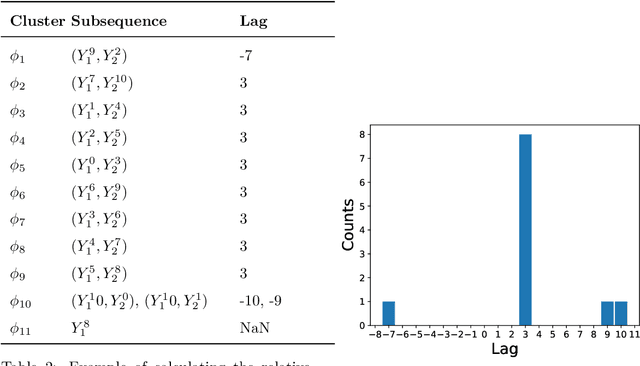
In multivariate time series systems, key insights can be obtained by discovering lead-lag relationships inherent in the data, which refer to the dependence between two time series shifted in time relative to one another, and which can be leveraged for the purposes of control, forecasting or clustering. We develop a clustering-driven methodology for the robust detection of lead-lag relationships in lagged multi-factor models. Within our framework, the envisioned pipeline takes as input a set of time series, and creates an enlarged universe of extracted subsequence time series from each input time series, by using a sliding window approach. We then apply various clustering techniques (e.g, K-means++ and spectral clustering), employing a variety of pairwise similarity measures, including nonlinear ones. Once the clusters have been extracted, lead-lag estimates across clusters are aggregated to enhance the identification of the consistent relationships in the original universe. Since multivariate time series are ubiquitous in a wide range of domains, we demonstrate that our method is not only able to robustly detect lead-lag relationships in financial markets, but can also yield insightful results when applied to an environmental data set.
Retrieval-Enhanced Contrastive Vision-Text Models
Jun 12, 2023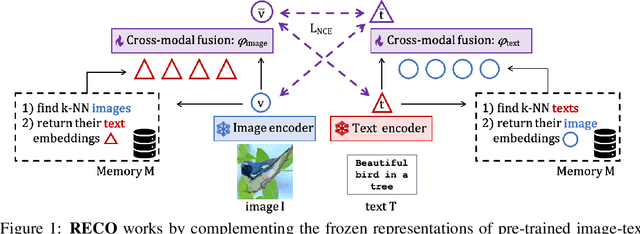
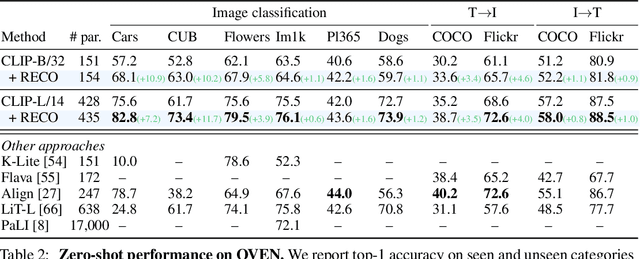
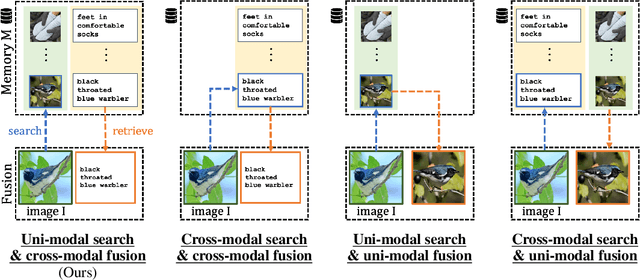
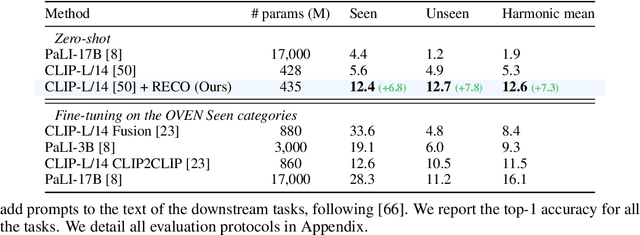
Contrastive image-text models such as CLIP form the building blocks of many state-of-the-art systems. While they excel at recognizing common generic concepts, they still struggle on fine-grained entities which are rare, or even absent from the pre-training dataset. Hence, a key ingredient to their success has been the use of large-scale curated pre-training data aiming at expanding the set of concepts that they can memorize during the pre-training stage. In this work, we explore an alternative to encoding fine-grained knowledge directly into the model's parameters: we instead train the model to retrieve this knowledge from an external memory. Specifically, we propose to equip existing vision-text models with the ability to refine their embedding with cross-modal retrieved information from a memory at inference time, which greatly improves their zero-shot predictions. Remarkably, we show that this can be done with a light-weight, single-layer, fusion transformer on top of a frozen CLIP. Our experiments validate that our retrieval-enhanced contrastive (RECO) training improves CLIP performance substantially on several challenging fine-grained tasks: for example +10.9 on Stanford Cars, +10.2 on CUB-2011 and +7.3 on the recent OVEN benchmark.
Are training trajectories of deep single-spike and deep ReLU network equivalent?
Jun 14, 2023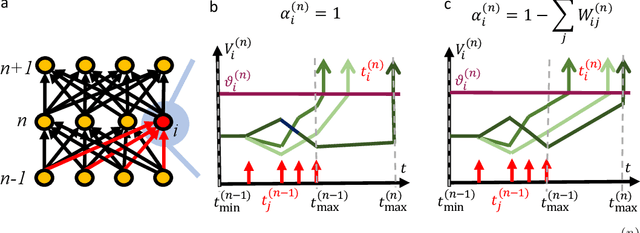


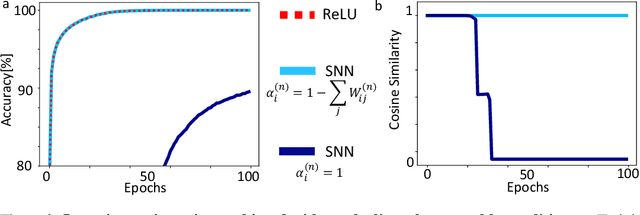
Communication by binary and sparse spikes is a key factor for the energy efficiency of biological brains. However, training deep spiking neural networks (SNNs) with backpropagation is harder than with artificial neural networks (ANNs), which is puzzling given that recent theoretical results provide exact mapping algorithms from ReLU to time-to-first-spike (TTFS) SNNs. Building upon these results, we analyze in theory and in simulation the learning dynamics of TTFS-SNNs. Our analysis highlights that even when an SNN can be mapped exactly to a ReLU network, it cannot always be robustly trained by gradient descent. The reason for that is the emergence of a specific instance of the vanishing-or-exploding gradient problem leading to a bias in the gradient descent trajectory in comparison with the equivalent ANN. After identifying this issue we derive a generic solution for the network initialization and SNN parameterization which guarantees that the SNN can be trained as robustly as its ANN counterpart. Our theoretical findings are illustrated in practice on image classification datasets. Our method achieves the same accuracy as deep ConvNets on CIFAR10 and enables fine-tuning on the much larger PLACES365 dataset without loss of accuracy compared to the ANN. We argue that the combined perspective of conversion and fine-tuning with robust gradient descent in SNN will be decisive to optimize SNNs for hardware implementations needing low latency and resilience to noise and quantization.
Feeding control and water quality monitoring in aquaculture systems: Opportunities and challenges
Jun 14, 2023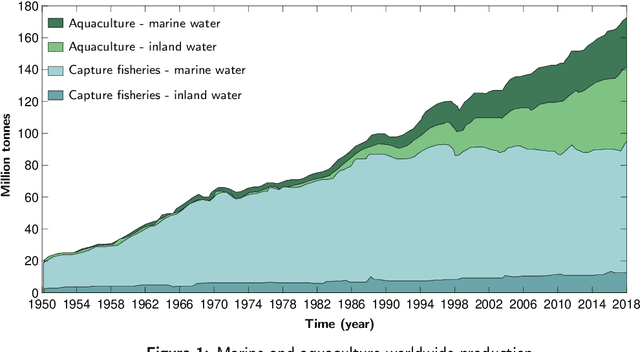

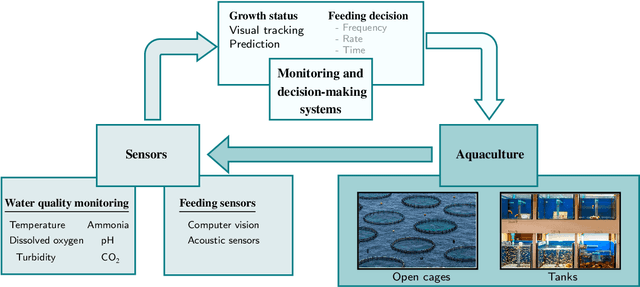
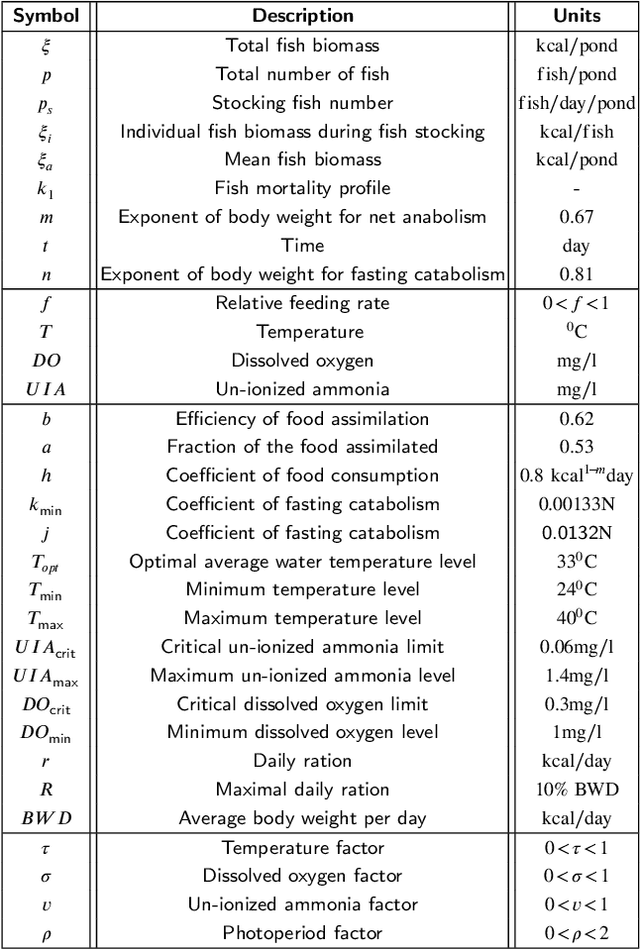
Aquaculture systems can benefit from the recent development of advanced control strategies to reduce operating costs and fish loss and increase growth production efficiency, resulting in fish welfare and health. Monitoring the water quality and controlling feeding are fundamental elements of balancing fish productivity and shaping the fish growth process. Currently, most fish-feeding processes are conducted manually in different phases and rely on time-consuming and challenging artificial discrimination. The feeding control approach influences fish growth and breeding through the feed conversion rate; hence, controlling these feeding parameters is crucial for enhancing fish welfare and minimizing general fishery costs. The high concentration of environmental factors, such as a high ammonia concentration and pH, affect the water quality and fish survival. Therefore, there is a critical need to develop control strategies to determine optimal, efficient, and reliable feeding processes and monitor water quality. This paper reviews the main control design techniques for fish growth in aquaculture systems, namely algorithms that optimize the feeding and water quality of a dynamic fish growth process. Specifically, we review model-based control approaches and model-free reinforcement learning strategies to optimize the growth and survival of the fish or track a desired reference live-weight growth trajectory. The model-free framework uses an approximate fish growth dynamic model and does not satisfy constraints. We discuss how model-based approaches can support a reinforcement learning framework to efficiently handle constraint satisfaction and find better trajectories and policies from value-based reinforcement learning.