 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ricci flow-based brain surface covariance descriptors for diagnosing Alzheimer's disease
Mar 18, 2024
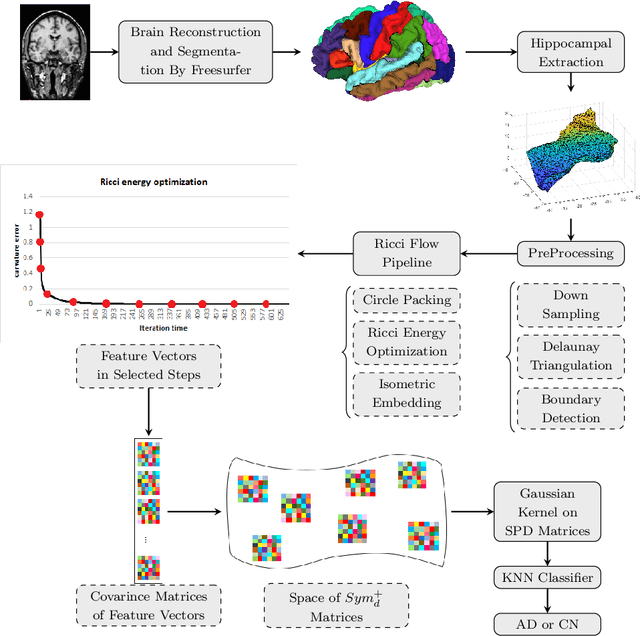
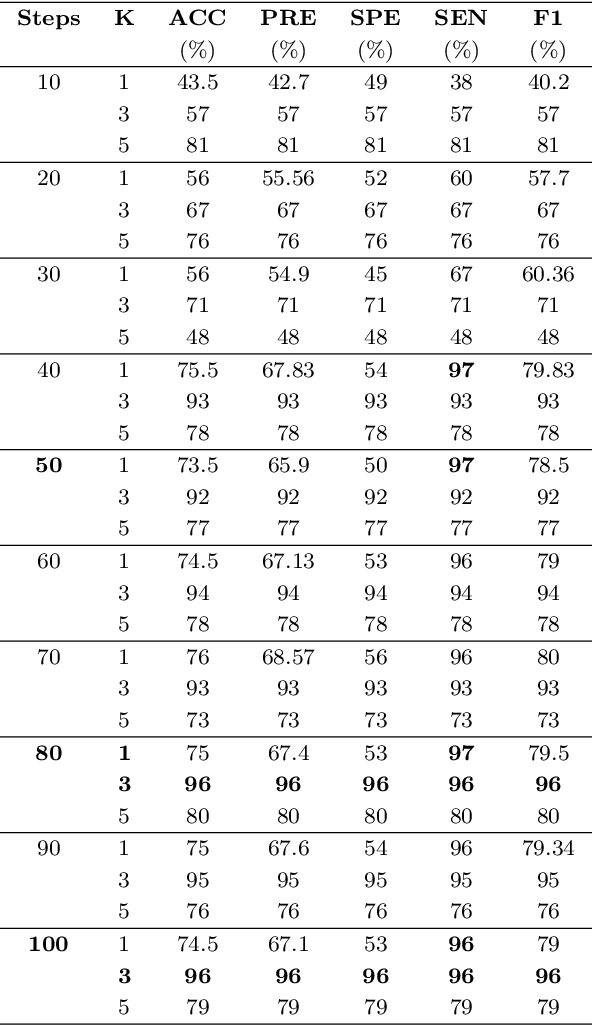
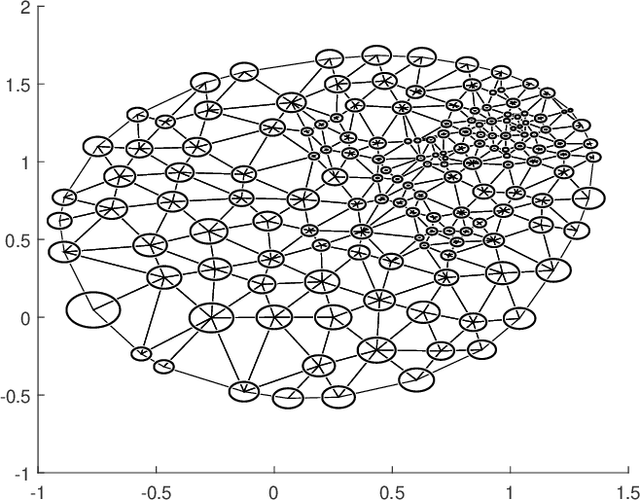

Automated feature extraction from MRI brain scans and diagnosis of Alzheimer's disease are ongoing challenges. With advances in 3D imaging technology, 3D data acquisition is becoming more viable and efficient than its 2D counterpart. Rather than using feature-based vectors, in this paper, for the first time, we suggest a pipeline to extract novel covariance-based descriptors from the cortical surface using the Ricci energy optimization. The covariance descriptors are components of the nonlinear manifold of symmetric positive-definite matrices, thus we focus on using the Gaussian radial basis function to apply manifold-based classification to the 3D shape problem. Applying this novel signature to the analysis of abnormal cortical brain morphometry allows for diagnosing Alzheimer's disease. Experimental studies performed on about two hundred 3D MRI brain models, gathered from Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate the effectiveness of our descriptors in achieving remarkable classification accuracy.
GetMesh: A Controllable Model for High-quality Mesh Generation and Manipulation
Mar 18, 2024
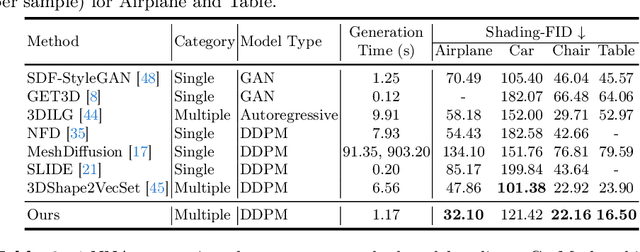
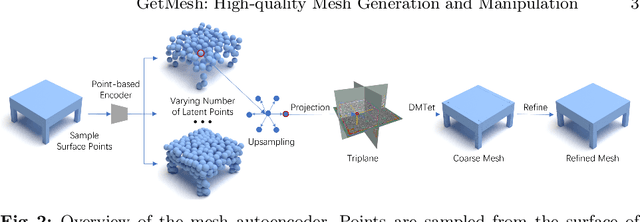
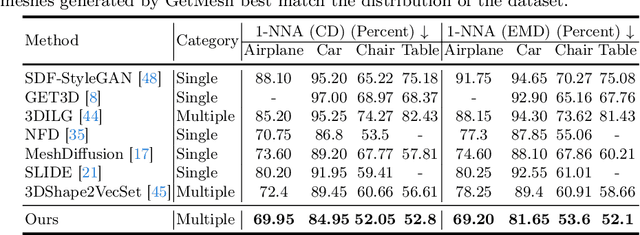
Mesh is a fundamental representation of 3D assets in various industrial applications, and is widely supported by professional softwares. However, due to its irregular structure, mesh creation and manipulation is often time-consuming and labor-intensive. In this paper, we propose a highly controllable generative model, GetMesh, for mesh generation and manipulation across different categories. By taking a varying number of points as the latent representation, and re-organizing them as triplane representation, GetMesh generates meshes with rich and sharp details, outperforming both single-category and multi-category counterparts. Moreover, it also enables fine-grained control over the generation process that previous mesh generative models cannot achieve, where changing global/local mesh topologies, adding/removing mesh parts, and combining mesh parts across categories can be intuitively, efficiently, and robustly accomplished by adjusting the number, positions or features of latent points. Project page is https://getmesh.github.io.
State space representations of the Roesser type for convolutional layers
Mar 18, 2024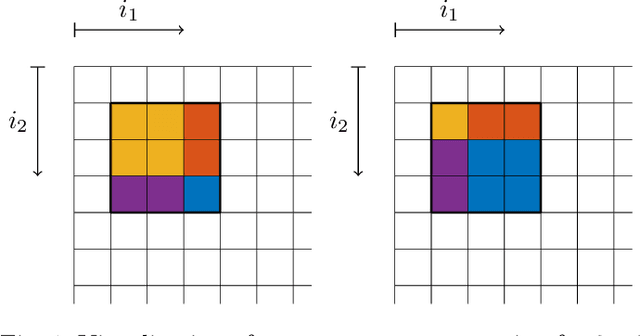
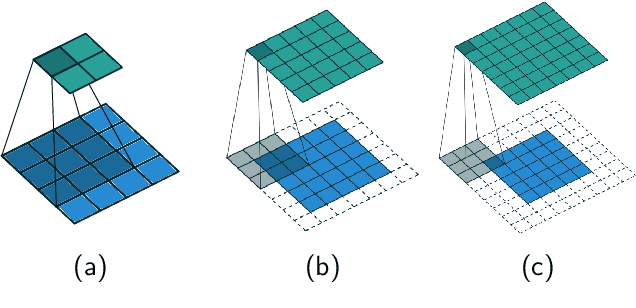
From the perspective of control theory, convolutional layers (of neural networks) are 2-D (or N-D) linear time-invariant dynamical systems. The usual representation of convolutional layers by the convolution kernel corresponds to the representation of a dynamical system by its impulse response. However, many analysis tools from control theory, e.g., involving linear matrix inequalities, require a state space representation. For this reason, we explicitly provide a state space representation of the Roesser type for 2-D convolutional layers with $c_\mathrm{in}r_1 + c_\mathrm{out}r_2$ states, where $c_\mathrm{in}$/$c_\mathrm{out}$ is the number of input/output channels of the layer and $r_1$/$r_2$ characterizes the width/length of the convolution kernel. This representation is shown to be minimal for $c_\mathrm{in} = c_\mathrm{out}$. We further construct state space representations for dilated, strided, and N-D convolutions.
State-Separated SARSA: A Practical Sequential Decision-Making Algorithm with Recovering Rewards
Mar 18, 2024
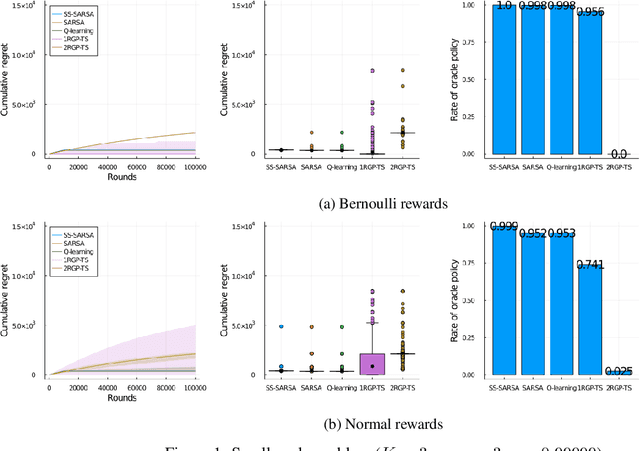
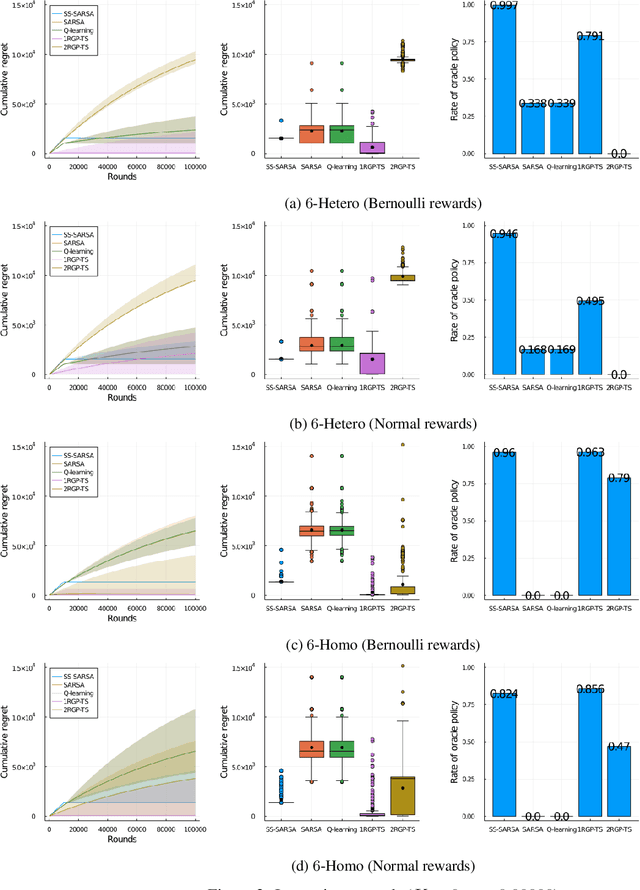
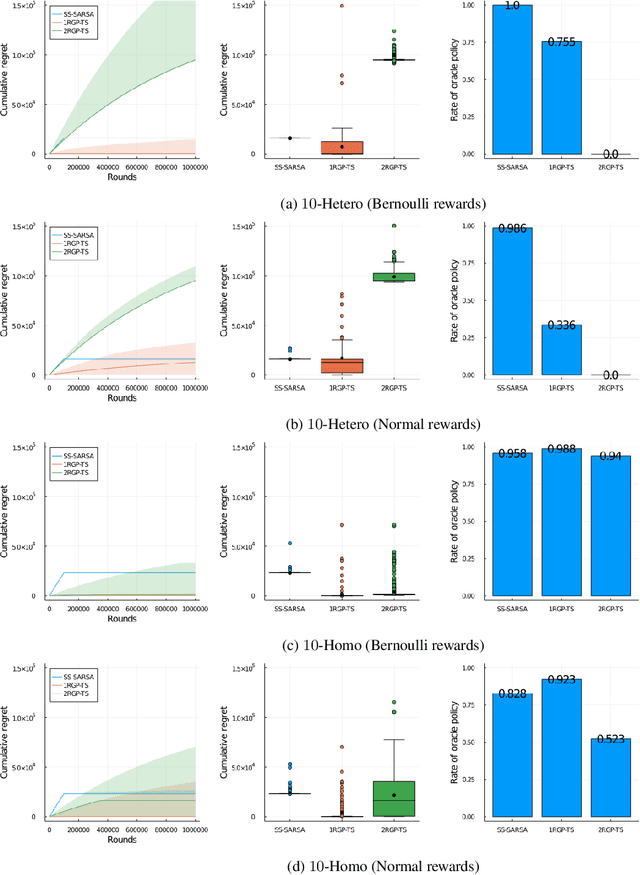
While many multi-armed bandit algorithms assume that rewards for all arms are constant across rounds, this assumption does not hold in many real-world scenarios. This paper considers the setting of recovering bandits (Pike-Burke & Grunewalder, 2019), where the reward depends on the number of rounds elapsed since the last time an arm was pulled. We propose a new reinforcement learning (RL) algorithm tailored to this setting, named the State-Separate SARSA (SS-SARSA) algorithm, which treats rounds as states. The SS-SARSA algorithm achieves efficient learning by reducing the number of state combinations required for Q-learning/SARSA, which often suffers from combinatorial issues for large-scale RL problems. Additionally, it makes minimal assumptions about the reward structure and offers lower computational complexity. Furthermore, we prove asymptotic convergence to an optimal policy under mild assumptions. Simulation studies demonstrate the superior performance of our algorithm across various settings.
Robust Co-Design of Canonical Underactuated Systems for Increased Certifiable Stability
Mar 16, 2024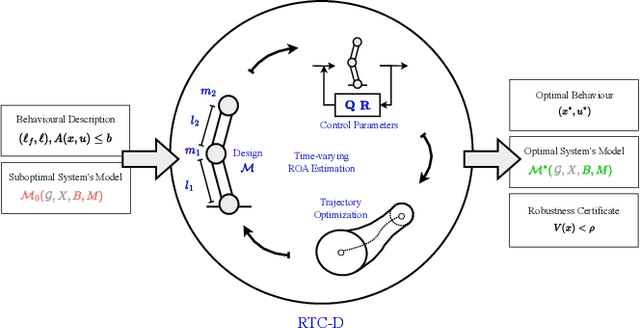
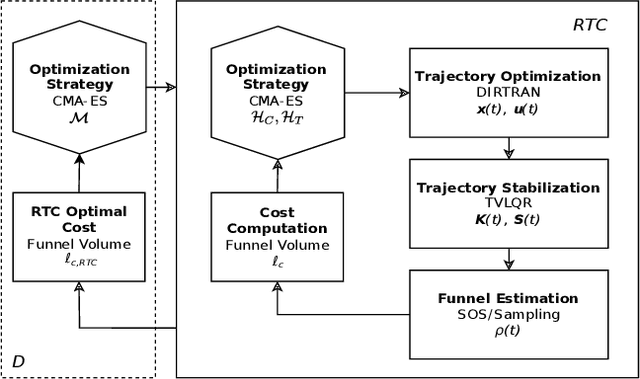

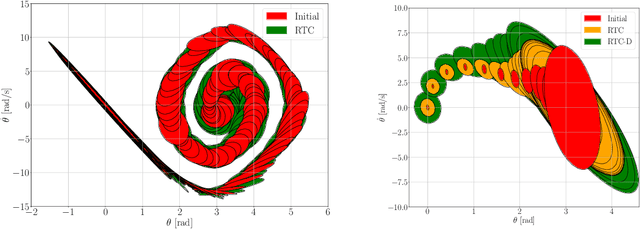
Optimal behaviours of a system to perform a specific task can be achieved by leveraging the coupling between trajectory optimization, stabilization, and design optimization. This approach is particularly advantageous for underactuated systems, which are systems that have fewer actuators than degrees of freedom and thus require for more elaborate control systems. This paper proposes a novel co-design algorithm, namely Robust Trajectory Control with Design optimization (RTC-D). An inner optimization layer (RTC) simultaneously performs direct transcription (DIRTRAN) to find a nominal trajectory while computing optimal hyperparameters for a stabilizing time-varying linear quadratic regulator (TVLQR). RTC-D augments RTC with a design optimization layer, maximizing the system's robustness through a time-varying Lyapunov-based region of attraction (ROA) analysis. This analysis provides a formal guarantee of stability for a set of off-nominal states. The proposed algorithm has been tested on two different underactuated systems: the torque-limited simple pendulum and the cart-pole. Extensive simulations of off-nominal initial conditions demonstrate improved robustness, while real-system experiments show increased insensitivity to torque disturbances.
Improving the Robustness of Dense Retrievers Against Typos via Multi-Positive Contrastive Learning
Mar 16, 2024Dense retrieval has become the new paradigm in passage retrieval. Despite its effectiveness on typo-free queries, it is not robust when dealing with queries that contain typos. Current works on improving the typo-robustness of dense retrievers combine (i) data augmentation to obtain the typoed queries during training time with (ii) additional robustifying subtasks that aim to align the original, typo-free queries with their typoed variants. Even though multiple typoed variants are available as positive samples per query, some methods assume a single positive sample and a set of negative ones per anchor and tackle the robustifying subtask with contrastive learning; therefore, making insufficient use of the multiple positives (typoed queries). In contrast, in this work, we argue that all available positives can be used at the same time and employ contrastive learning that supports multiple positives (multi-positive). Experimental results on two datasets show that our proposed approach of leveraging all positives simultaneously and employing multi-positive contrastive learning on the robustifying subtask yields improvements in robustness against using contrastive learning with a single positive.
FaceXFormer: A Unified Transformer for Facial Analysis
Mar 19, 2024
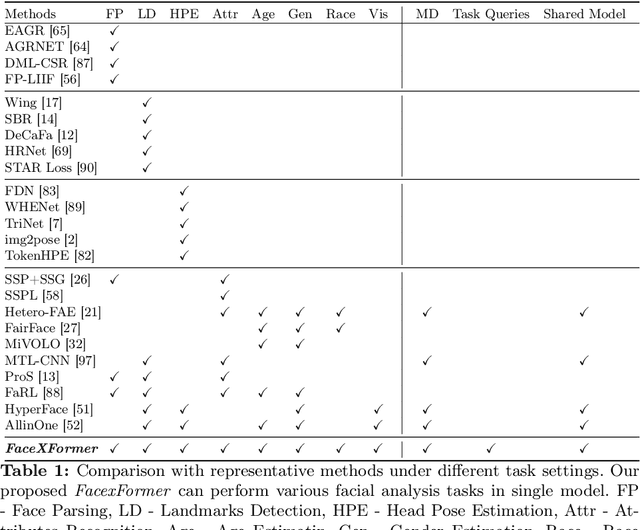
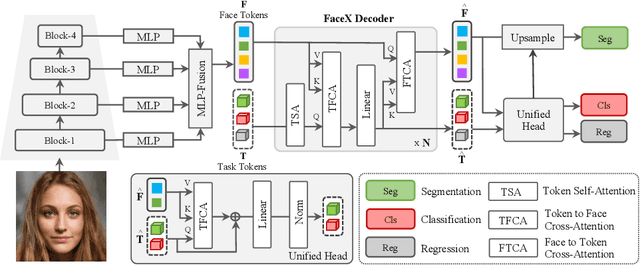
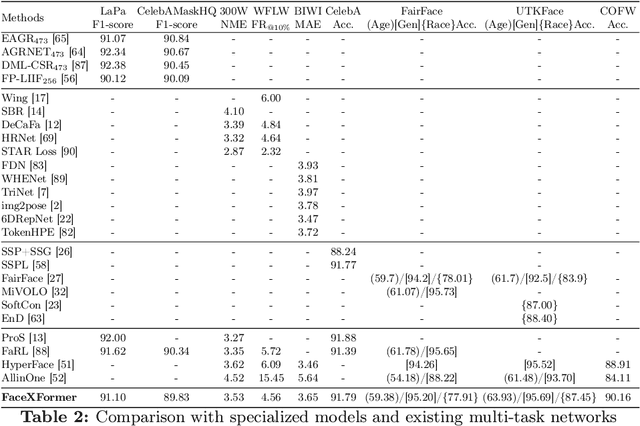
In this work, we introduce FaceXformer, an end-to-end unified transformer model for a comprehensive range of facial analysis tasks such as face parsing, landmark detection, head pose estimation, attributes recognition, and estimation of age, gender, race, and landmarks visibility. Conventional methods in face analysis have often relied on task-specific designs and preprocessing techniques, which limit their approach to a unified architecture. Unlike these conventional methods, our FaceXformer leverages a transformer-based encoder-decoder architecture where each task is treated as a learnable token, enabling the integration of multiple tasks within a single framework. Moreover, we propose a parameter-efficient decoder, FaceX, which jointly processes face and task tokens, thereby learning generalized and robust face representations across different tasks. To the best of our knowledge, this is the first work to propose a single model capable of handling all these facial analysis tasks using transformers. We conducted a comprehensive analysis of effective backbones for unified face task processing and evaluated different task queries and the synergy between them. We conduct experiments against state-of-the-art specialized models and previous multi-task models in both intra-dataset and cross-dataset evaluations across multiple benchmarks. Additionally, our model effectively handles images "in-the-wild," demonstrating its robustness and generalizability across eight different tasks, all while maintaining the real-time performance of 37 FPS.
ExACT: Language-guided Conceptual Reasoning and Uncertainty Estimation for Event-based Action Recognition and More
Mar 19, 2024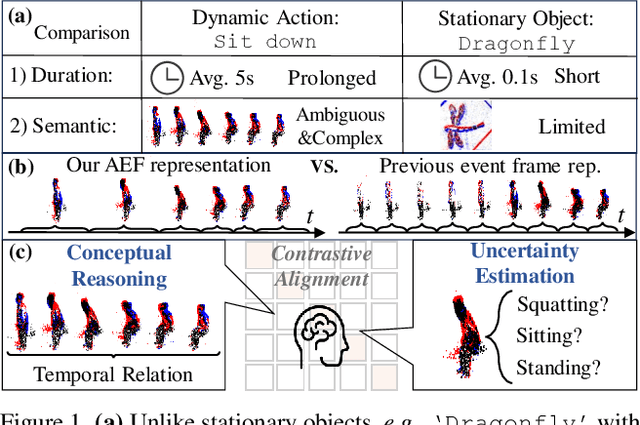
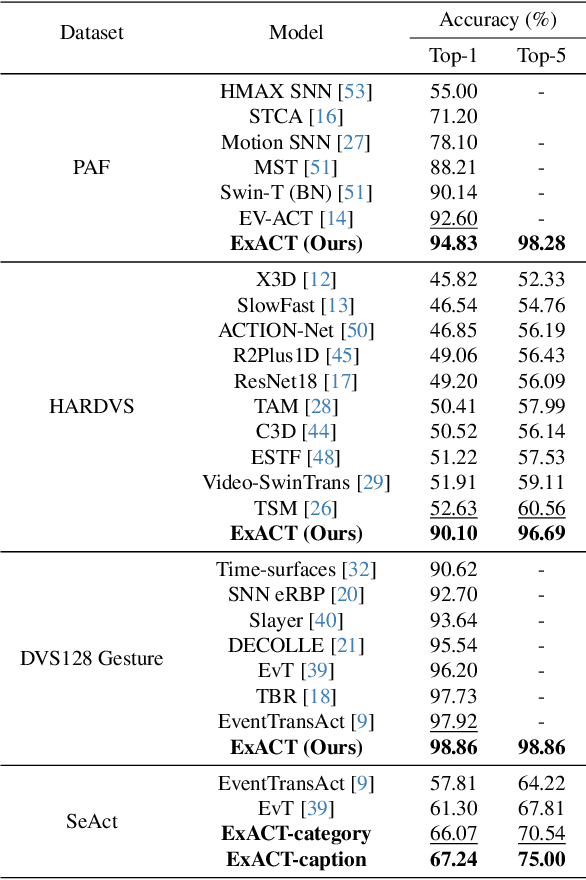
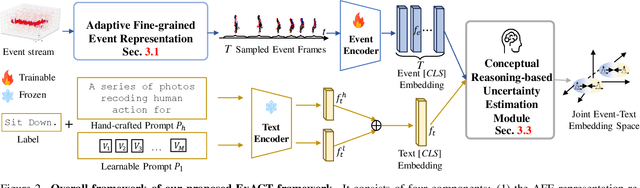
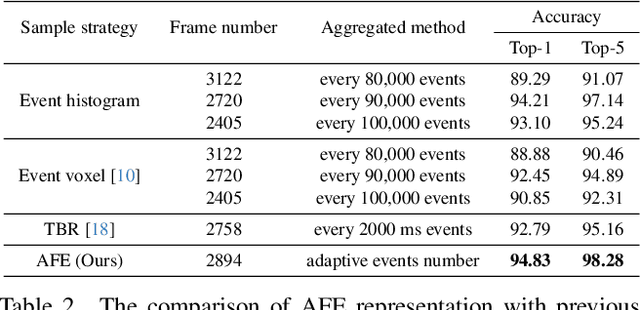
Event cameras have recently been shown beneficial for practical vision tasks, such as action recognition, thanks to their high temporal resolution, power efficiency, and reduced privacy concerns. However, current research is hindered by 1) the difficulty in processing events because of their prolonged duration and dynamic actions with complex and ambiguous semantics and 2) the redundant action depiction of the event frame representation with fixed stacks. We find language naturally conveys abundant semantic information, rendering it stunningly superior in reducing semantic uncertainty. In light of this, we propose ExACT, a novel approach that, for the first time, tackles event-based action recognition from a cross-modal conceptualizing perspective. Our ExACT brings two technical contributions. Firstly, we propose an adaptive fine-grained event (AFE) representation to adaptively filter out the repeated events for the stationary objects while preserving dynamic ones. This subtly enhances the performance of ExACT without extra computational cost. Then, we propose a conceptual reasoning-based uncertainty estimation module, which simulates the recognition process to enrich the semantic representation. In particular, conceptual reasoning builds the temporal relation based on the action semantics, and uncertainty estimation tackles the semantic uncertainty of actions based on the distributional representation. Experiments show that our ExACT achieves superior recognition accuracy of 94.83%(+2.23%), 90.10%(+37.47%) and 67.24% on PAF, HARDVS and our SeAct datasets respectively.
Molecular Classification Using Hyperdimensional Graph Classification
Mar 18, 2024
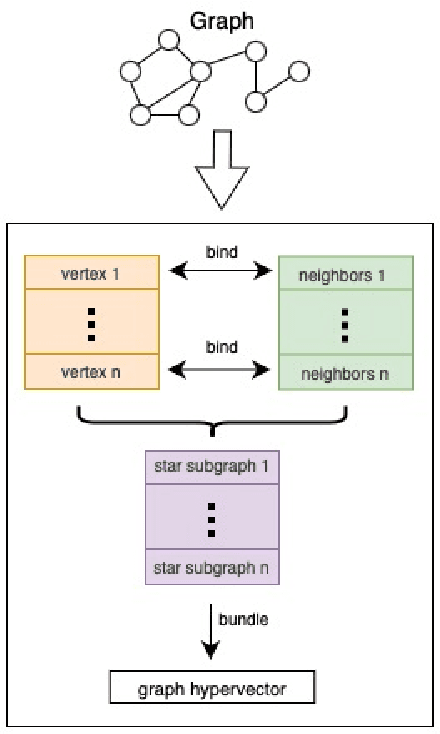
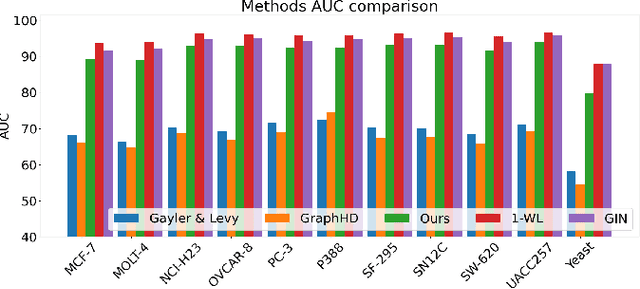
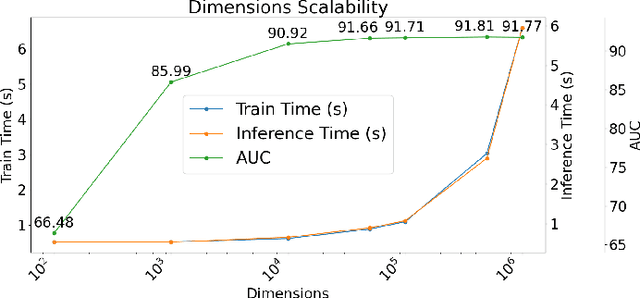
Our work introduces an innovative approach to graph learning by leveraging Hyperdimensional Computing. Graphs serve as a widely embraced method for conveying information, and their utilization in learning has gained significant attention. This is notable in the field of chemoinformatics, where learning from graph representations plays a pivotal role. An important application within this domain involves the identification of cancerous cells across diverse molecular structures. We propose an HDC-based model that demonstrates comparable Area Under the Curve results when compared to state-of-the-art models like Graph Neural Networks (GNNs) or the Weisfieler-Lehman graph kernel (WL). Moreover, it outperforms previously proposed hyperdimensional computing graph learning methods. Furthermore, it achieves noteworthy speed enhancements, boasting a 40x acceleration in the training phase and a 15x improvement in inference time compared to GNN and WL models. This not only underscores the efficacy of the HDC-based method, but also highlights its potential for expedited and resource-efficient graph learning.
DVN-SLAM: Dynamic Visual Neural SLAM Based on Local-Global Encoding
Mar 18, 2024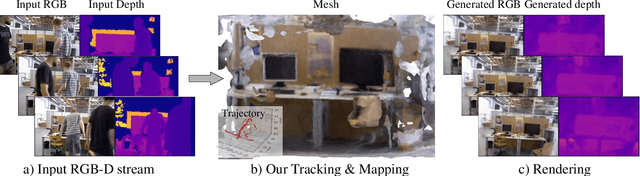
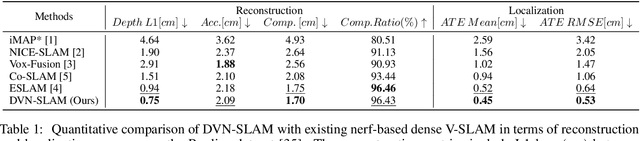
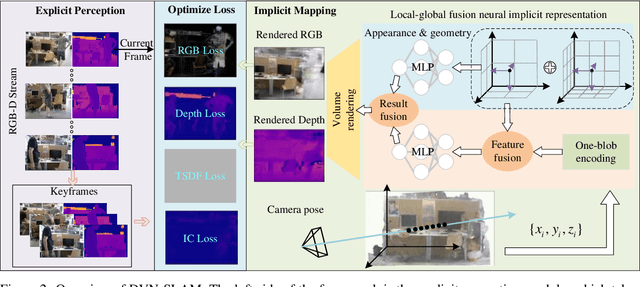
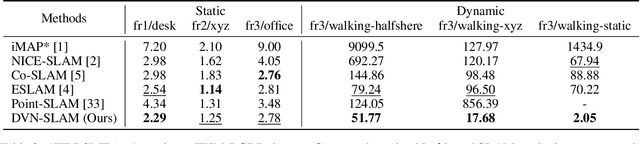
Recent research on Simultaneous Localization and Mapping (SLAM) based on implicit representation has shown promising results in indoor environments. However, there are still some challenges: the limited scene representation capability of implicit encodings, the uncertainty in the rendering process from implicit representations, and the disruption of consistency by dynamic objects. To address these challenges, we propose a real-time dynamic visual SLAM system based on local-global fusion neural implicit representation, named DVN-SLAM. To improve the scene representation capability, we introduce a local-global fusion neural implicit representation that enables the construction of an implicit map while considering both global structure and local details. To tackle uncertainties arising from the rendering process, we design an information concentration loss for optimization, aiming to concentrate scene information on object surfaces. The proposed DVN-SLAM achieves competitive performance in localization and mapping across multiple datasets. More importantly, DVN-SLAM demonstrates robustness in dynamic scenes, a trait that sets it apart from other NeRF-based methods.