 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Buying Information for Stochastic Optimization
Jun 06, 2023
Stochastic optimization is one of the central problems in Machine Learning and Theoretical Computer Science. In the standard model, the algorithm is given a fixed distribution known in advance. In practice though, one may acquire at a cost extra information to make better decisions. In this paper, we study how to buy information for stochastic optimization and formulate this question as an online learning problem. Assuming the learner has an oracle for the original optimization problem, we design a $2$-competitive deterministic algorithm and a $e/(e-1)$-competitive randomized algorithm for buying information. We show that this ratio is tight as the problem is equivalent to a robust generalization of the ski-rental problem, which we call super-martingale stopping. We also consider an adaptive setting where the learner can choose to buy information after taking some actions for the underlying optimization problem. We focus on the classic optimization problem, Min-Sum Set Cover, where the goal is to quickly find an action that covers a given request drawn from a known distribution. We provide an $8$-competitive algorithm running in polynomial time that chooses actions and decides when to buy information about the underlying request.
Counterfactual Explanations and Predictive Models to Enhance Clinical Decision-Making in Schizophrenia using Digital Phenotyping
Jun 06, 2023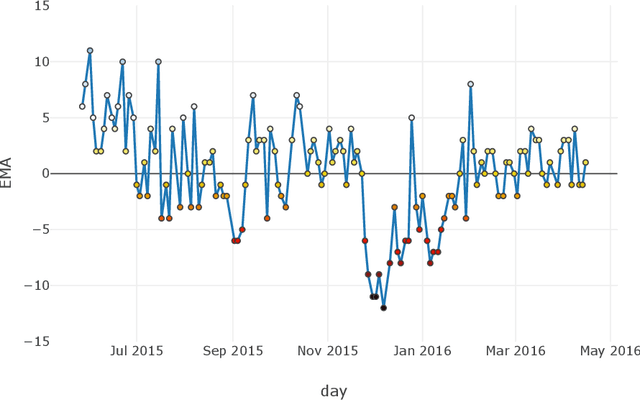

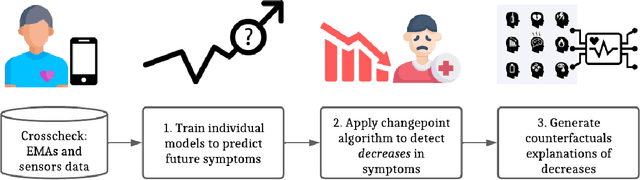
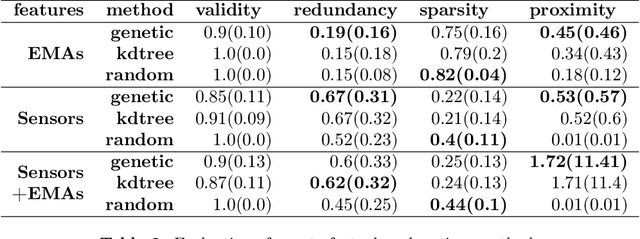
Clinical practice in psychiatry is burdened with the increased demand for healthcare services and the scarce resources available. New paradigms of health data powered with machine learning techniques could open the possibility to improve clinical workflow in critical stages of clinical assessment and treatment in psychiatry. In this work, we propose a machine learning system capable of predicting, detecting, and explaining individual changes in symptoms of patients with Schizophrenia by using behavioral digital phenotyping data. We forecast symptoms of patients with an error rate below 10%. The system detects decreases in symptoms using changepoint algorithms and uses counterfactual explanations as a recourse in a simulated continuous monitoring scenario in healthcare. Overall, this study offers valuable insights into the performance and potential of counterfactual explanations, predictive models, and change-point detection within a simulated clinical workflow. These findings lay the foundation for further research to explore additional facets of the workflow, aiming to enhance its effectiveness and applicability in real-world healthcare settings. By leveraging these components, the goal is to develop an actionable, interpretable, and trustworthy integrative decision support system that combines real-time clinical assessments with sensor-based inputs.
Rao-Blackwellized Particle Smoothing for Simultaneous Localization and Mapping
Jun 06, 2023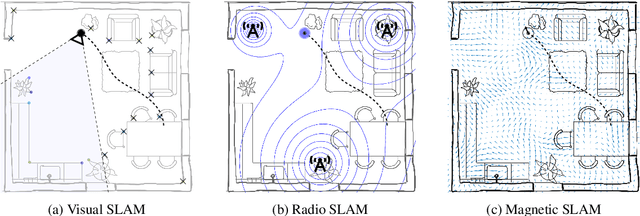
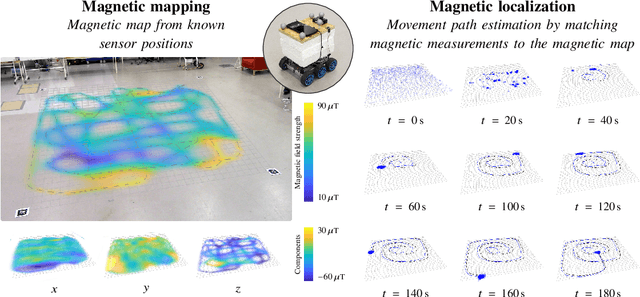
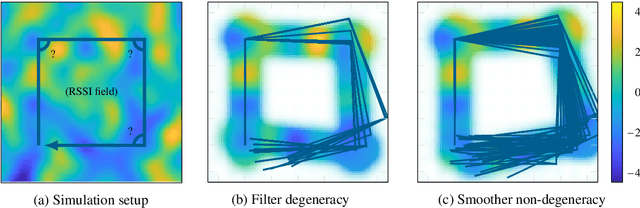
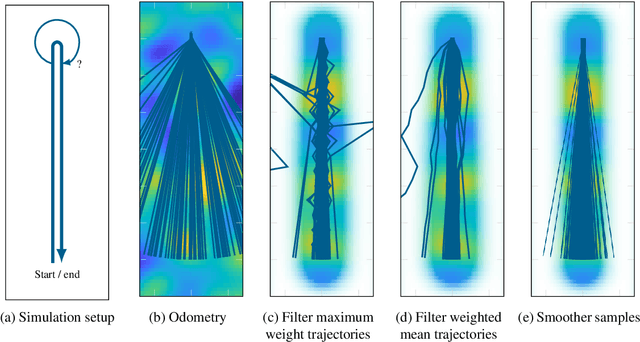
Simultaneous localization and mapping (SLAM) is the task of building a map representation of an unknown environment while it at the same time is used for positioning. A probabilistic interpretation of the SLAM task allows for incorporating prior knowledge and for operation under uncertainty. Contrary to the common practice of computing point estimates of the system states, we capture the full posterior density through approximate Bayesian inference. This dynamic learning task falls under state estimation, where the state-of-the-art is in sequential Monte Carlo methods that tackle the forward filtering problem. In this paper, we introduce a framework for probabilistic SLAM using particle smoothing that does not only incorporate observed data in current state estimates, but it also back-tracks the updated knowledge to correct for past drift and ambiguities in both the map and in the states. Our solution can efficiently handle both dense and sparse map representations by Rao-Blackwellization of conditionally linear and conditionally linearized models. We show through simulations and real-world experiments how the principles apply to radio (BLE/Wi-Fi), magnetic field, and visual SLAM. The proposed solution is general, efficient, and works well under confounding noise.
Fast Context Adaptation in Cost-Aware Continual Learning
Jun 06, 2023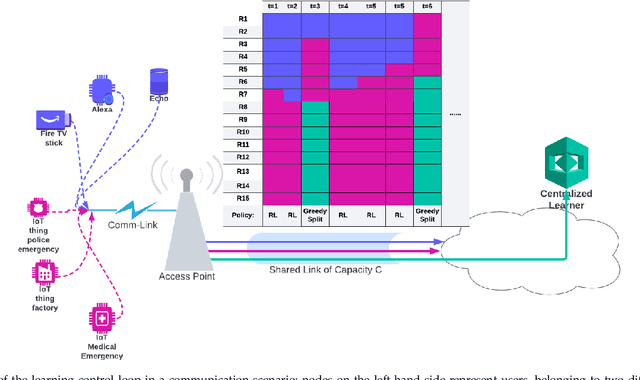
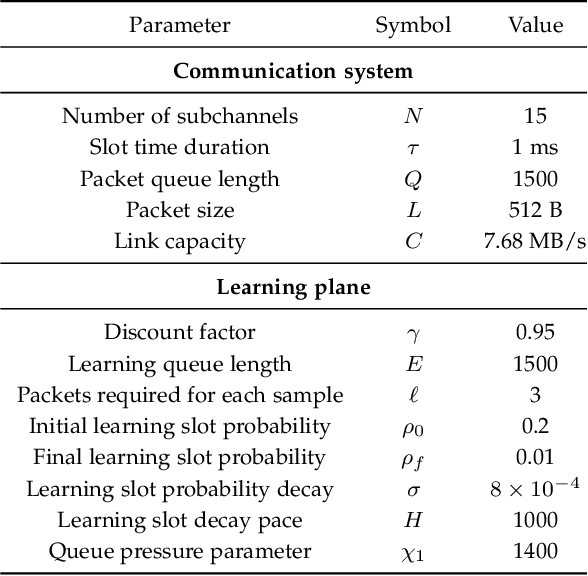
In the past few years, DRL has become a valuable solution to automatically learn efficient resource management strategies in complex networks with time-varying statistics. However, the increased complexity of 5G and Beyond networks requires correspondingly more complex learning agents and the learning process itself might end up competing with users for communication and computational resources. This creates friction: on the one hand, the learning process needs resources to quickly convergence to an effective strategy; on the other hand, the learning process needs to be efficient, i.e., take as few resources as possible from the user's data plane, so as not to throttle users' QoS. In this paper, we investigate this trade-off and propose a dynamic strategy to balance the resources assigned to the data plane and those reserved for learning. With the proposed approach, a learning agent can quickly converge to an efficient resource allocation strategy and adapt to changes in the environment as for the CL paradigm, while minimizing the impact on the users' QoS. Simulation results show that the proposed method outperforms static allocation methods with minimal learning overhead, almost reaching the performance of an ideal out-of-band CL solution.
A Novel Approach To User Agent String Parsing For Vulnerability Analysis Using Mutli-Headed Attention
Jun 06, 2023
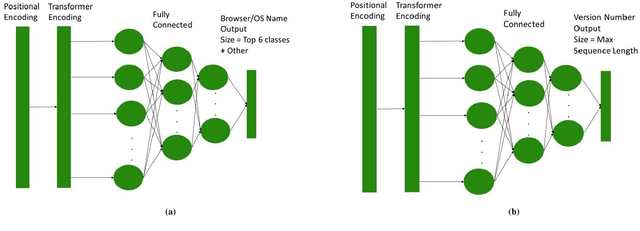
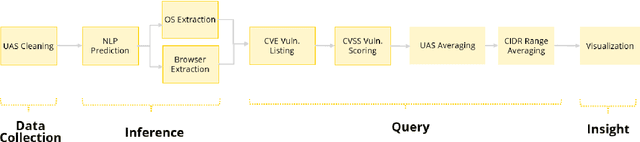

The increasing reliance on the internet has led to the proliferation of a diverse set of web-browsers and operating systems (OSs) capable of browsing the web. User agent strings (UASs) are a component of web browsing that are transmitted with every Hypertext Transfer Protocol (HTTP) request. They contain information about the client device and software, which is used by web servers for various purposes such as content negotiation and security. However, due to the proliferation of various browsers and devices, parsing UASs is a non-trivial task due to a lack of standardization of UAS formats. Current rules-based approaches are often brittle and can fail when encountering such non-standard formats. In this work, a novel methodology for parsing UASs using Multi-Headed Attention Based transformers is proposed. The proposed methodology exhibits strong performance in parsing a variety of UASs with differing formats. Furthermore, a framework to utilize parsed UASs to estimate the vulnerability scores for large sections of publicly visible IT networks or regions is also discussed. The methodology present here can also be easily extended or deployed for real-time parsing of logs in enterprise settings.
Large Language Models of Code Fail at Completing Code with Potential Bugs
Jun 06, 2023
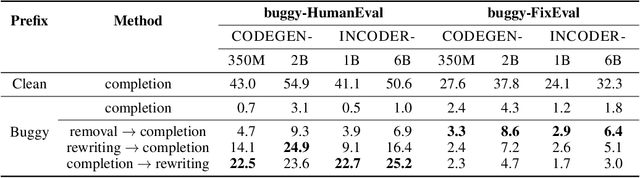
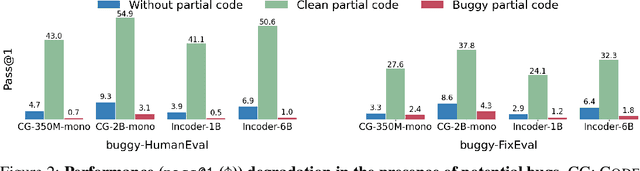

Large language models of code (Code-LLMs) have recently brought tremendous advances to code completion, a fundamental feature of programming assistance and code intelligence. However, most existing works ignore the possible presence of bugs in the code context for generation, which are inevitable in software development. Therefore, we introduce and study the buggy-code completion problem, inspired by the realistic scenario of real-time code suggestion where the code context contains potential bugs -- anti-patterns that can become bugs in the completed program. To systematically study the task, we introduce two datasets: one with synthetic bugs derived from semantics-altering operator changes (buggy-HumanEval) and one with realistic bugs derived from user submissions to coding problems (buggy-FixEval). We find that the presence of potential bugs significantly degrades the generation performance of the high-performing Code-LLMs. For instance, the passing rates of CodeGen-2B-mono on test cases of buggy-HumanEval drop more than 50% given a single potential bug in the context. Finally, we investigate several post-hoc methods for mitigating the adverse effect of potential bugs and find that there remains a large gap in post-mitigation performance.
A Modular Test Bed for Reinforcement Learning Incorporation into Industrial Applications
Jun 02, 2023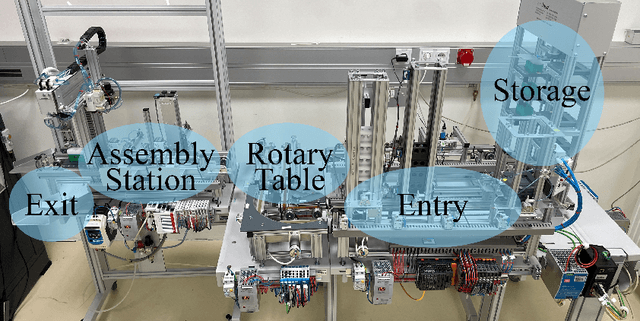
This application paper explores the potential of using reinforcement learning (RL) to address the demands of Industry 4.0, including shorter time-to-market, mass customization, and batch size one production. Specifically, we present a use case in which the task is to transport and assemble goods through a model factory following predefined rules. Each simulation run involves placing a specific number of goods of random color at the entry point. The objective is to transport the goods to the assembly station, where two rivets are installed in each product, connecting the upper part to the lower part. Following the installation of rivets, blue products must be transported to the exit, while green products are to be transported to storage. The study focuses on the application of reinforcement learning techniques to address this problem and improve the efficiency of the production process.
An Architecture for Deploying Reinforcement Learning in Industrial Environments
Jun 02, 2023Industry 4.0 is driven by demands like shorter time-to-market, mass customization of products, and batch size one production. Reinforcement Learning (RL), a machine learning paradigm shown to possess a great potential in improving and surpassing human level performance in numerous complex tasks, allows coping with the mentioned demands. In this paper, we present an OPC UA based Operational Technology (OT)-aware RL architecture, which extends the standard RL setting, combining it with the setting of digital twins. Moreover, we define an OPC UA information model allowing for a generalized plug-and-play like approach for exchanging the RL agent used. In conclusion, we demonstrate and evaluate the architecture, by creating a proof of concept. By means of solving a toy example, we show that this architecture can be used to determine the optimal policy using a real control system.
* This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in Computer Aided Systems Theory - EUROCAST 2022 and is available online at https://doi.org/10.1007/978-3-031-25312-6_67
Syntax-aware Hybrid prompt model for Few-shot multi-modal sentiment analysis
Jun 02, 2023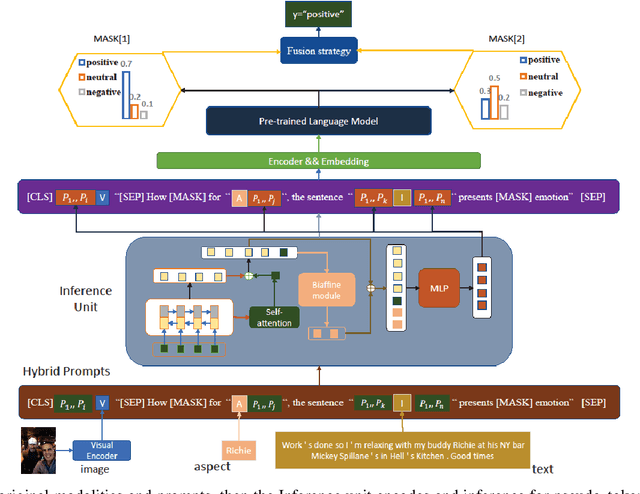

Multimodal Sentiment Analysis (MSA) has been a popular topic in natural language processing nowadays, at both sentence and aspect level. However, the existing approaches almost require large-size labeled datasets, which bring about large consumption of time and resources. Therefore, it is practical to explore the method for few-shot sentiment analysis in cross-modalities. Previous works generally execute on textual modality, using the prompt-based methods, mainly two types: hand-crafted prompts and learnable prompts. The existing approach in few-shot multi-modality sentiment analysis task has utilized both methods, separately. We further design a hybrid pattern that can combine one or more fixed hand-crafted prompts and learnable prompts and utilize the attention mechanisms to optimize the prompt encoder. The experiments on both sentence-level and aspect-level datasets prove that we get a significant outperformance.
Physics-Guided Graph Neural Networks for Real-time AC/DC Power Flow Analysis
Apr 29, 2023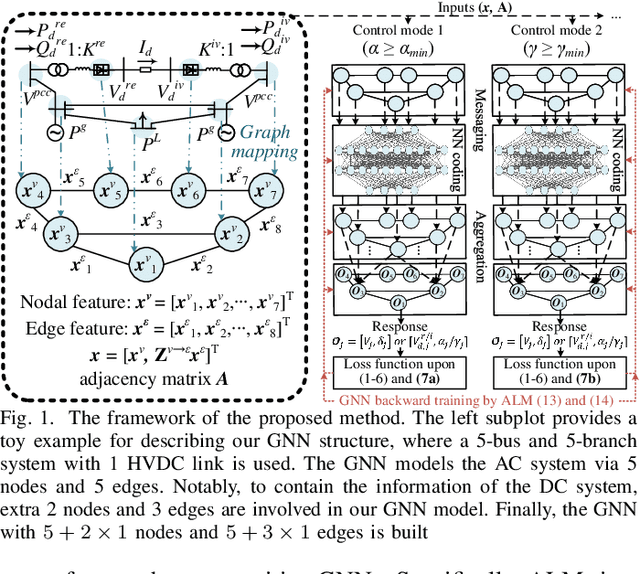
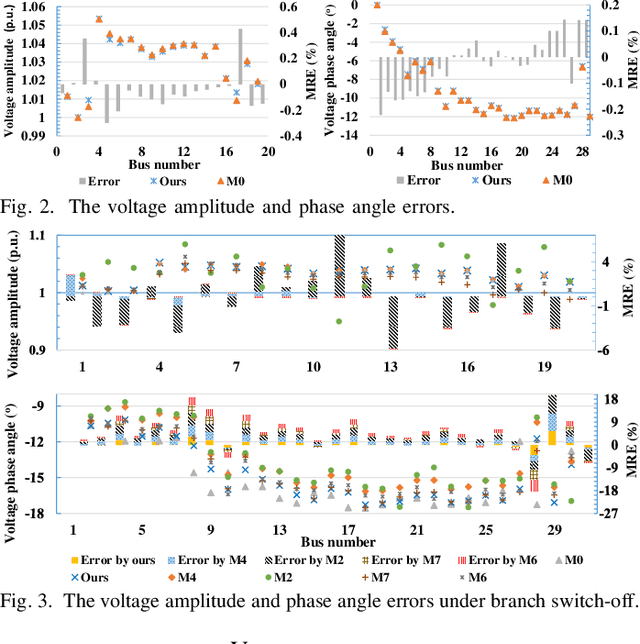
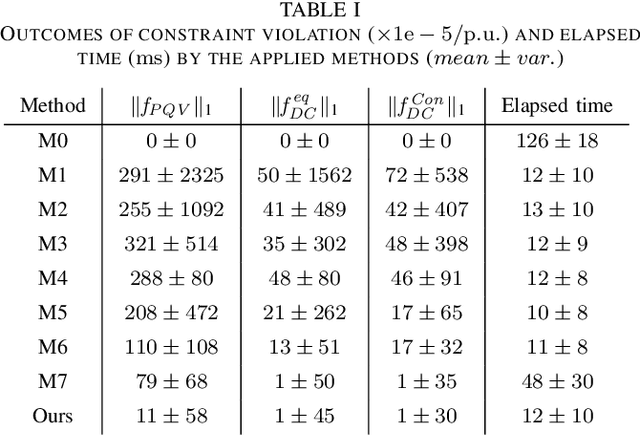
The increasing scale of alternating current and direct current (AC/DC) hybrid systems necessitates a faster power flow analysis tool than ever. This letter thus proposes a specific physics-guided graph neural network (PG-GNN). The tailored graph modelling of AC and DC grids is firstly advanced to enhance the topology adaptability of the PG-GNN. To eschew unreliable experience emulation from data, AC/DC physics are embedded in the PG-GNN using duality. Augmented Lagrangian method-based learning scheme is then presented to help the PG-GNN better learn nonconvex patterns in an unsupervised label-free manner. Multi-PG-GNN is finally conducted to master varied DC control modes. Case study shows that, relative to the other 7 data-driven rivals, only the proposed method matches the performance of the model-based benchmark, also beats it in computational efficiency beyond 10 times.